prml reading 1.1 - 1.2
TRANSCRIPT

PATTERN RECOGNITIONand MACHINE LEARNING
READING1.1 Example: Polynomial Curve Fitting
1.2 Probability Theory
GSIS Tohoku Univ. Tokuyama Lab. M1 Yu Ohori

1 Introduction
手書き数字 ( 𝟐𝟖 × 𝟐𝟖 px ) の認識
• 入力 𝐱 ∈ ℝ784
• 出力 𝑡 ∈ 0,1, … , 9訓練データ集合を用いてモデルを学習することで適切な分類が可能となる
2015/04/20 PRML Reading 2
Fig. 1.1 ( p. 1 )

1 Introduction
教師あり学習
• 訓練データ…入力ベクトルと目標ベクトル• クラス分類(目標ベクトル:離散)
• 回帰(目標ベクトル:連続)
教師なし学習
• 訓練データ…入力ベクトルのみ• クラスタリング
• 密度推定
強化学習
• ある状況下で報酬を最大にする適当な行動を見つける問題
2015/04/20 PRML Reading 3

1.1 Example: Polynomial Curve Fitting
Given
• 入力 𝑥 ∈ ℝ
• 入力データ集合 𝐱 = 𝑥1, … , 𝑥𝑁T
• 目標データ集合 𝐭 = 𝑡1, … , 𝑡𝑁T
Goal
• 目標変数 𝑡 を予測する
Approach
• 多項式曲線フィッティング
• 𝑦 𝑥, 𝐰 = 𝑗=0𝑀 𝜔𝑗𝑥
𝑗input variable 𝑥
targ
et
vari
ab
le 𝑡
model 𝑦 𝑥, 𝐰
2015/04/20 PRML Reading 4

最小二乗法
• 二乗和誤差関数を最小化してパラメータ𝐰を推定
𝐸 𝐰 =1
2
𝑛=1
𝑁
𝑦 𝑥𝑛, 𝐰 − 𝑡𝑛2
1.1 Example: Polynomial Curve Fitting
2015/04/20 PRML Reading 5
Fig. 1.3 ( p. 6 )

過学習
• モデルの次数 𝑀を変化
• データ集合のサイズ 𝑁を固定
1.1 Example: Polynomial Curve Fitting
2015/04/20 PRML Reading 6
Fig. 1.4 ( p. 6 )
ノイズに強く影響される(過学習)
sin 2𝜋𝑥 に最もよく当てはまる

1.1 Example: Polynomial Curve Fitting
過学習
• モデルの次数 𝑀 を固定
• データ集合のサイズ 𝑁を変化
2015/04/20 PRML Reading 7
データ集合のサイズを増やすと過学習を
抑制できる
Fig. 1.6 ( p. 9 )
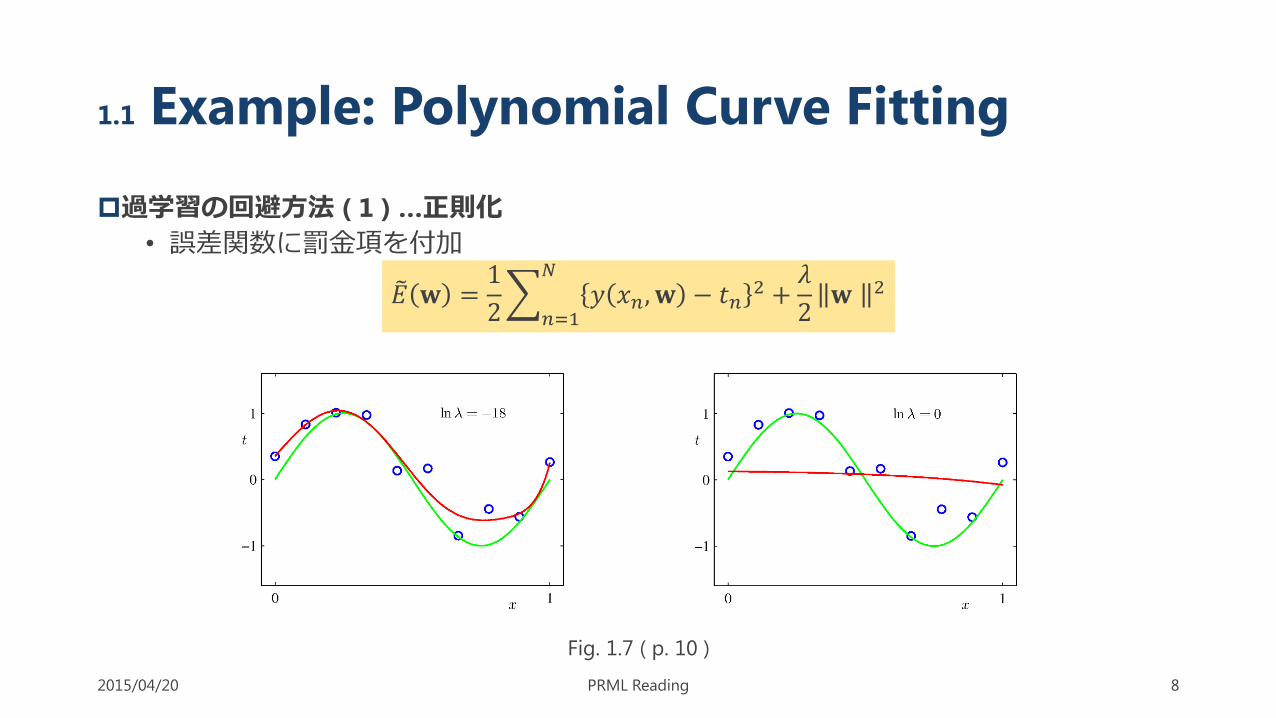
過学習の回避方法 ( 1 ) …正則化
• 誤差関数に罰金項を付加
𝐸 𝐰 =1
2
𝑛=1
𝑁
𝑦 𝑥𝑛, 𝐰 − 𝑡𝑛2 +
𝜆
2𝐰 2
1.1 Example: Polynomial Curve Fitting
2015/04/20 PRML Reading 8
Fig. 1.7 ( p. 10 )
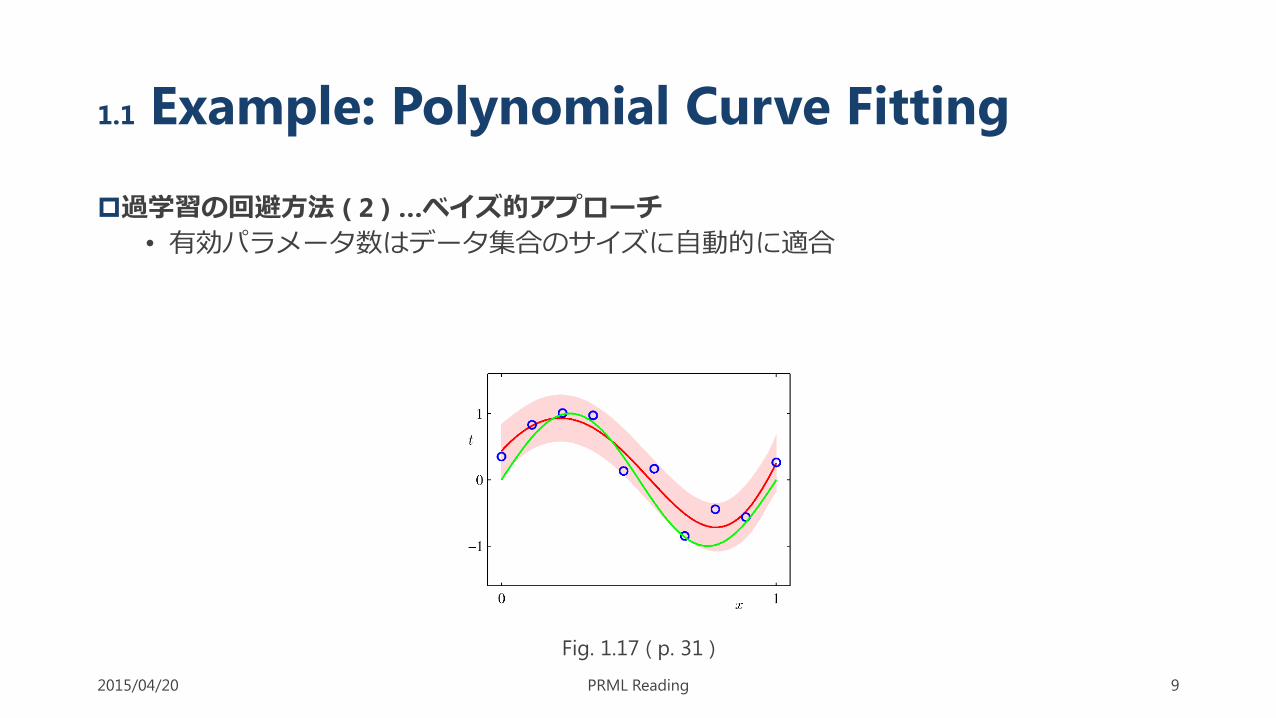
1.1 Example: Polynomial Curve Fitting
過学習の回避方法 ( 2 ) …ベイズ的アプローチ
• 有効パラメータ数はデータ集合のサイズに自動的に適合
2015/04/20 PRML Reading 9
Fig. 1.17 ( p. 31 )

1.2 Probability Theory
オレンジを選び出したとしてそれが青い箱から取り出されたものである確率は?
2015/04/20 PRML Reading 10
Fig. 1.9 ( p. 12 )
40% 60%

同時確率
𝑝 𝑋 = 𝑥𝑖 , 𝑌 = 𝑦𝑗 =𝑛𝑖𝑗
𝑁
1.2 Probability Theory
𝑛𝑖𝑗
𝑐𝑖
𝑟𝑗
𝑥𝑖
𝑦𝑗
Fig. 1.10 ( p. 13 )
2015/04/20 PRML Reading 11

周辺確率
𝑝 𝑋 = 𝑥𝑖 =𝑐𝑖
𝑁
1.2 Probability Theory
𝑛𝑖𝑗
𝑐𝑖
𝑟𝑗
𝑥𝑖
𝑦𝑗
Fig. 1.10 ( p. 13 )
2015/04/20 PRML Reading 12
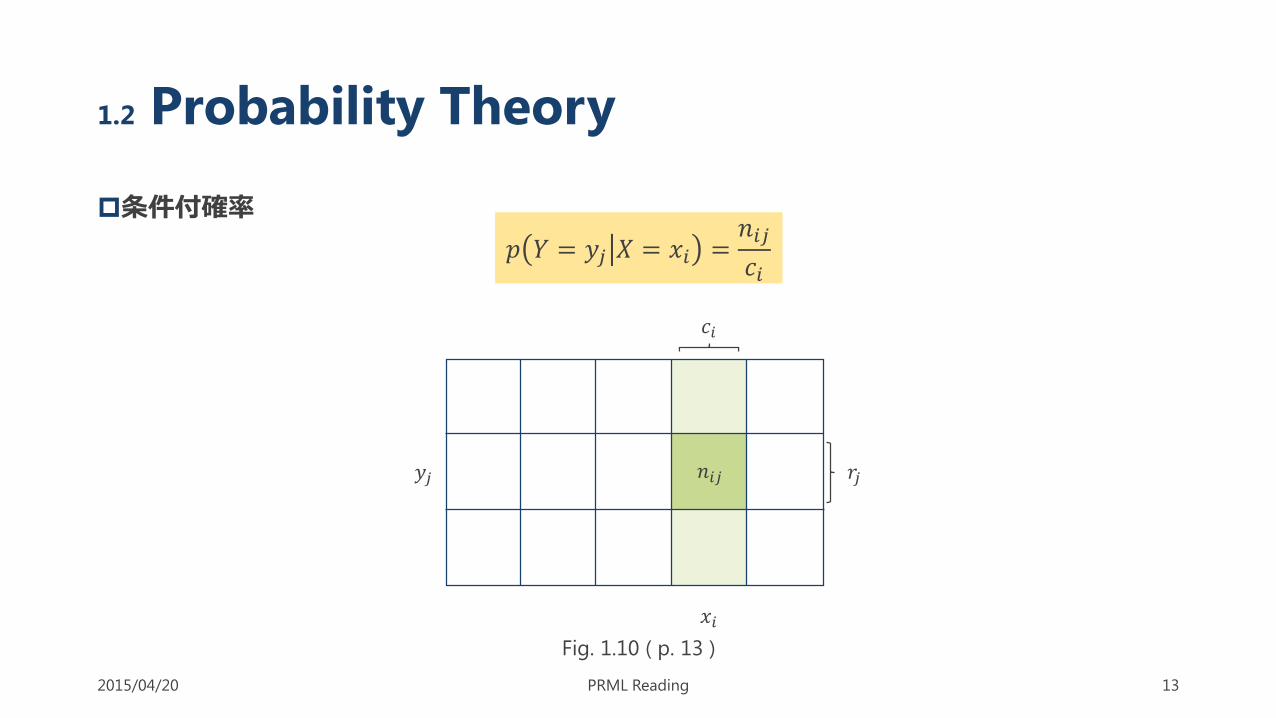
条件付確率
𝑝 𝑌 = 𝑦𝑗 𝑋 = 𝑥𝑖 =𝑛𝑖𝑗
𝑐𝑖
1.2 Probability Theory
𝑛𝑖𝑗
𝑐𝑖
𝑟𝑗
𝑥𝑖
𝑦𝑗
Fig. 1.10 ( p. 13 )
2015/04/20 PRML Reading 13

加法定理
𝑝 𝑋 = 𝑌𝑝 𝑋, 𝑌
乗法定理𝑝 𝑋, 𝑌 = 𝑝 𝑌 𝑋 𝑝 𝑋
ベイズの定理
𝑝 𝑌 𝑋 =𝑝 𝑋 𝑌 𝑝 𝑌
𝑝 𝑋
• 𝑝 𝑌 : 事前確率
• 𝑝 𝑌 𝑋 : 事後確率
• 𝑝 𝑋 𝑌 : 尤度関数
• 𝑝 𝑋 = 𝑌 𝑝 𝑋 𝑌 𝑝 𝑌 : 規格化定数
1.2 Probability Theory
2015/04/20 PRML Reading 14

1.2 Probability Theory
オレンジを選び出したとしてそれが青い箱から取り出されたものである確率は?
𝑝 𝑏 𝑜 =𝑝 𝑜 𝑏 𝑝 𝑏
𝑝 𝑜=
14
∙610
34
∙410
+14
∙610
=1
3
2015/04/20 PRML Reading 15
𝐵 = 𝑟𝑏
𝐹 = 𝑎𝑜
Fig. 1.9 ( p. 12 )
40% 60%

1.2.1 Probability density
確率密度
• 連続変数に関する確率記述
• 𝑝 𝑥 ∈ 𝑎, 𝑏 = 𝑎
𝑏𝑝 𝑥 ⅆ𝑥
• 非負条件 𝑝 𝑥 ≥ 0
• 規格化条件 −∞
∞𝑝 𝑥 ⅆ𝑥 = 1
累積分布関数
• 𝑃 𝑧 = −∞
𝑧𝑝 𝑥 ⅆ𝑥
2015/04/20 PRML Reading 16
Fig. 1.12 ( p. 17 )

1.2.2 Expectations and covariances
期待値
• ある関数 𝑓 𝑥 の確率分布 𝑝 𝑥 の下での平均値
• 離散変数の場合 𝔼 𝑓 = 𝑥 𝑝 𝑥 𝑓 𝑥
• 連続変数の場合 𝔼 𝑓 = 𝑝 𝑥 𝑓 𝑥 ⅆ𝑥
• 有限個の 𝑁 点を用いて近似 𝔼 𝑓 ≃1
𝑁 𝑛=1
𝑁 𝑓 𝑥𝑛
• 多変数関数の場合
• 𝔼𝑥 𝑓 𝑥, 𝑦 = 𝑥 𝑝 𝑥, 𝑦 𝑓 𝑥, 𝑦
• 𝔼𝑥,𝑦 𝑓 𝑥, 𝑦 = 𝑥 𝑦 𝑝 𝑥, 𝑦 𝑓 𝑥, 𝑦
• 𝔼𝑥 𝑓|𝑦 = 𝑥 𝑝 𝑥 𝑦 𝑓 𝑥
2015/04/20 PRML Reading 17

1.2.2 Expectations and covariances
分散
• 𝑓 𝑥 の期待値の周りでのばらつきの尺度
var 𝑓 = 𝔼 𝑓 𝑥 − 𝔼 𝑓 𝑥 2 = 𝔼 𝑓 𝑥 2 − 𝔼 𝑓 𝑥 2
共分散
• 一変量の場合
cov 𝑥, 𝑦 = 𝔼𝑥,𝑦 𝑥 − 𝔼 𝑥 𝑦 − 𝔼 𝑦 = 𝔼𝑥,𝑦 𝑥𝑦 − 𝔼 𝑥 𝔼 𝑦
• 多変量の場合
cov 𝐱, 𝐲 = 𝔼𝐱,𝐲 𝐱 − 𝔼 𝐱 𝐲T − 𝔼 𝐲T = 𝔼𝐱,𝐲 𝐱𝐲T − 𝔼 𝐱 𝔼 𝐲T
2015/04/20 PRML Reading 18

頻度主義的視点
• 確率=ランダムな繰返し試行の頻度
• 無限回の試行を前提
ベイズ的視点
• 確率=不確実性の度合い
• 新たな証拠が得られる度修正
𝑝 𝐰 𝒟 =𝑝 𝒟 𝐰 𝑝 𝐰
𝑝 𝒟• 𝑦 𝑥, 𝐰 = 𝑗=0
𝑀 𝜔𝑗𝑥𝑗 : 曲線
• 𝒟 = 𝑡1, … , 𝑡𝑁 : 観測データ
1.2.3 Bayesian probabilities
2015/04/20 PRML Reading 19
Thomas Bayes
1701 - 1761

一変量ガウス分布
𝒩 𝑥 𝜇, 𝜎2 = 2𝜋𝜎2 −12exp −
1
2𝜎2𝑥 − 𝜇 2
• 𝜇 = 𝔼 𝑥 : 平均
• 𝜎2 = var 𝑥 : 分散
• 𝜎 : 標準偏差
• 𝛽 =1
𝜎2 : 精度パラメータ
多変量ガウス分布
𝒩 𝐱 𝝁, 𝚺 = 2𝜋 𝐷 𝚺−
12exp −
1
2𝐱 − 𝝁 𝑇𝚺−1 𝒙 − 𝝁
• 𝝁 = 𝔼 𝐱 : 平均
• 𝚺 = cov 𝐱 : 共分散
1.2.4 The Gaussian distribution
2015/04/20 PRML Reading 20
Fig. 1.13 ( p. 25 )
© 2002 – 2003 NAKAGAWA Masao

1.2.4 The Gaussian distribution
最尤推定
• 観測データ集合 𝐱 = 𝑥1, … , 𝑥𝑁𝑇 をi.d.d と仮定
• 尤度関数 𝑝 𝐱 𝜇, 𝜎2 = 𝑛=1𝑁 𝒩 𝑥𝑛 𝜇, 𝜎2
• 対数尤度関数 ln 𝑝 𝐱 𝜇, 𝜎2 = −1
2𝜎2 𝑛=1
𝑁 ln 𝑥𝑛 − 𝜇 2 −𝑁
2ln 𝜎2 −
𝑁
2ln 2𝜋
• データ集合を生成したガウス分布のパラメータ 𝜇, 𝜎2 を推定
2015/04/20 PRML Reading 21
Fig. 1.14 ( p. 26 )

1.2.4 The Gaussian distribution
最尤推定
• 対数尤度関数を 𝜇 に関して最大化
• 𝜕
𝜕𝜇ln 𝑝 𝐱 𝜇, 𝜎2
𝜇=𝜇ML,𝜎=𝜎ML
= 0を解くと
• 𝜇ML =1
𝑁 𝑛=1
𝑁 𝑥𝑛 : サンプル平均
• 対数尤度関数を 𝜎2 に関して最大化
• 𝜕
𝜕𝜎ln 𝑝 𝐱 𝜇, 𝜎2
𝜇=𝜇ML,𝜎=𝜎ML
= 0を解くと
• 𝜎ML2 =
1
𝑁 𝑛=1
𝑁 ln 𝑥𝑛 − 𝜇ML2 : サンプル分散
2015/04/20 PRML Reading 22

1.2.5 Curve fitting re-visited
Given
• 入力 𝑥 ∈ ℝ• 入力データ集合 𝐱 = 𝑥1, … , 𝑥𝑁
T
• 目標データ集合 𝐭 = 𝑡1, … , 𝑡𝑁T
Goal
• 目標変数 𝑡 を予測する
Approach
• 多項式曲線フィッティング
• 𝑦 𝑥, 𝐰 = 𝑗=0𝑀 𝜔𝑗𝑥
𝑗
• 𝑝 𝑡 𝑥, 𝐰, 𝛽 = 𝒩 𝑡 𝑦 𝑥, 𝐰 , 𝛽−1
2015/04/20 PRML Reading 23
Fig. 1.16 ( p. 29 )
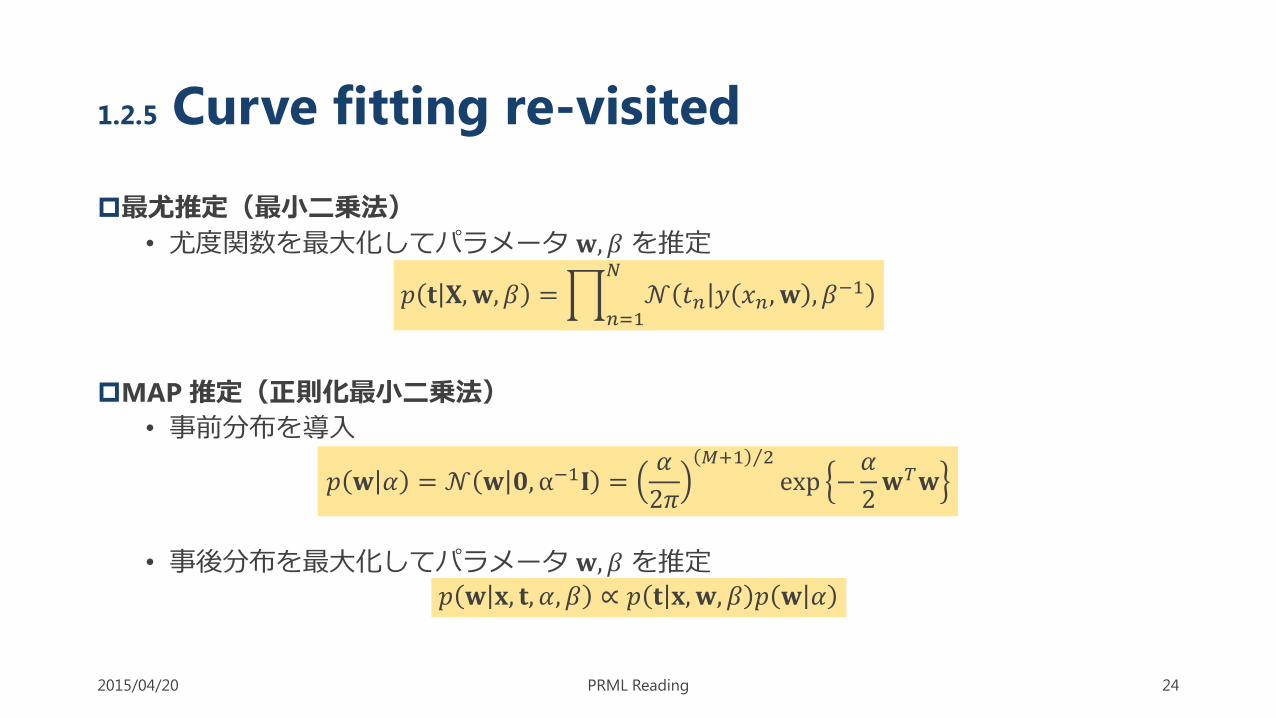
最尤推定(最小二乗法)
• 尤度関数を最大化してパラメータ 𝐰,𝛽 を推定
𝑝 𝐭 𝐗, 𝐰, 𝛽 = 𝑛=1
𝑁
𝒩 𝑡𝑛 𝑦 𝑥𝑛, 𝐰 , 𝛽−1
MAP 推定(正則化最小二乗法)
• 事前分布を導入
𝑝 𝐰 𝛼 = 𝒩 𝐰 𝟎, α−1𝐈 =𝛼
2𝜋
𝑀+1 2
exp −𝛼
2𝐰𝑇𝐰
• 事後分布を最大化してパラメータ 𝐰,𝛽 を推定
𝑝 𝐰 𝐱, 𝐭, 𝛼, 𝛽 ∝ 𝑝 𝐭 𝐱, 𝐰, 𝛽 𝑝 𝐰 𝛼
1.2.5 Curve fitting re-visited
2015/04/20 PRML Reading 24
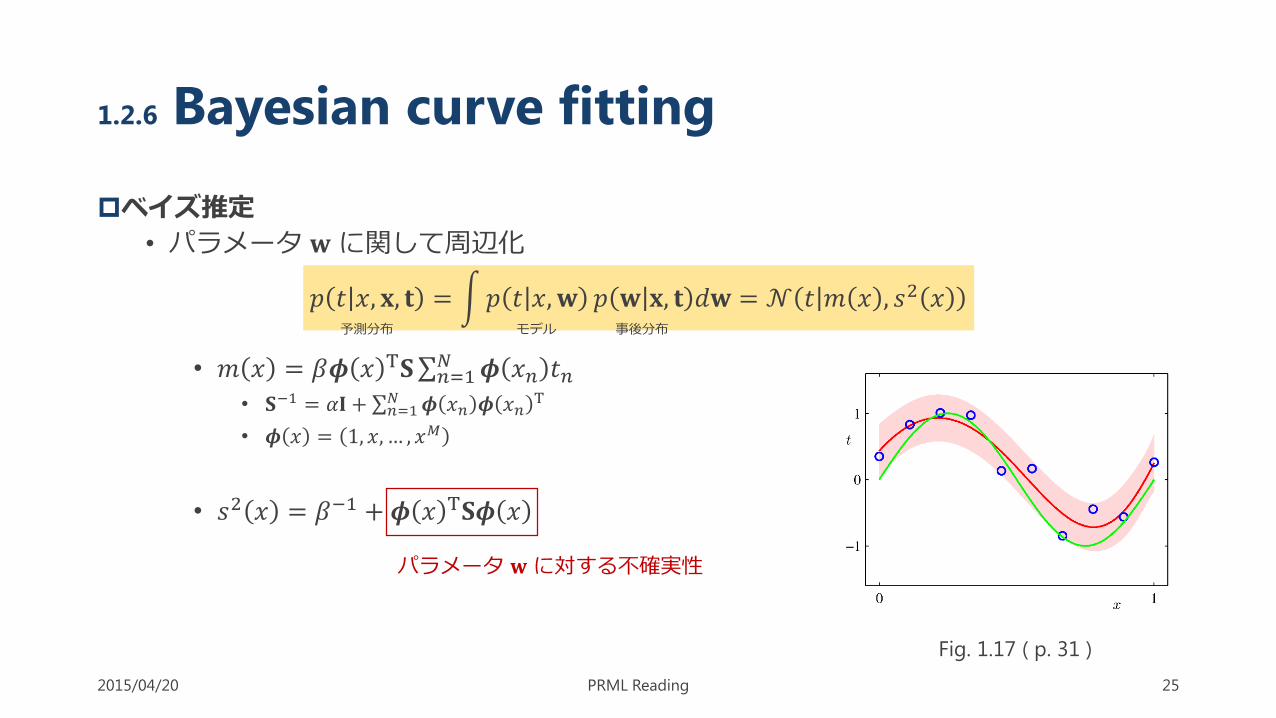
ベイズ推定
• パラメータ 𝐰に関して周辺化
𝑝 𝑡 𝑥, 𝐱, 𝐭 = 𝑝 𝑡 𝑥, 𝐰 𝑝 𝐰 𝐱, 𝐭 ⅆ𝐰 = 𝒩 𝑡 𝑚 𝑥 , 𝑠2 𝑥
• 𝑚 𝑥 = 𝛽𝝓 𝑥 T𝐒 𝑛=1𝑁 𝝓 𝑥𝑛 𝑡𝑛
• 𝐒−1 = 𝛼𝐈 + 𝑛=1𝑁 𝝓 𝑥𝑛 𝝓 𝑥𝑛
T
• 𝝓 𝑥 = 1, 𝑥, … , 𝑥𝑀
• 𝑠2 𝑥 = 𝛽−1 + 𝝓 𝑥 T𝐒𝝓 𝑥
1.2.6 Bayesian curve fitting
2015/04/20 PRML Reading 25
パラメータ 𝐰に対する不確実性
モデル 事後分布予測分布
Fig. 1.17 ( p. 31 )

Reference
Pattern Recognition and Machine Learning [ Christopher M. Bishop, 2006 ]
• English
• pp. 1 – 32
• Japanese ( vol. 1 )
• pp. 1 – 31
• Web site
• http://research.microsoft.com/en-us/um/people/cmbishop/prml/
2015/04/20 PRML Reading 26