stanとrでベイズ統計モデリング読書会 chapter...
TRANSCRIPT

StanとRでベイズ統計モデリング読書会
Chapter 7(7.6-7.9)
回帰分析の悩みどころ~統計の力で歌うまになりたい~
Osaka.Stan #4
(2017/4/29)

自己紹介
紀ノ定保礼(Kinosada Yasunori)
− 静岡理工科大学情報学部 講師
− 研究領域:認知心理学・交通心理学
− 趣味:カラオケ

今回の発表について
本書のデータは使用していません
‒ 発表者自身の歌唱記録データ
‒ 注意点- 実際は同一人物(発表者)の時系列データですが,例示のため,全データ点が独立とみなして回帰分析したりしています
‒ 勉強中のため,間違いや「こうすればもっと面白い」という点があれば,ぜひご指摘ください
4章の内容と関連あり
←併せてご参照ください

7.6説明変数が多すぎる
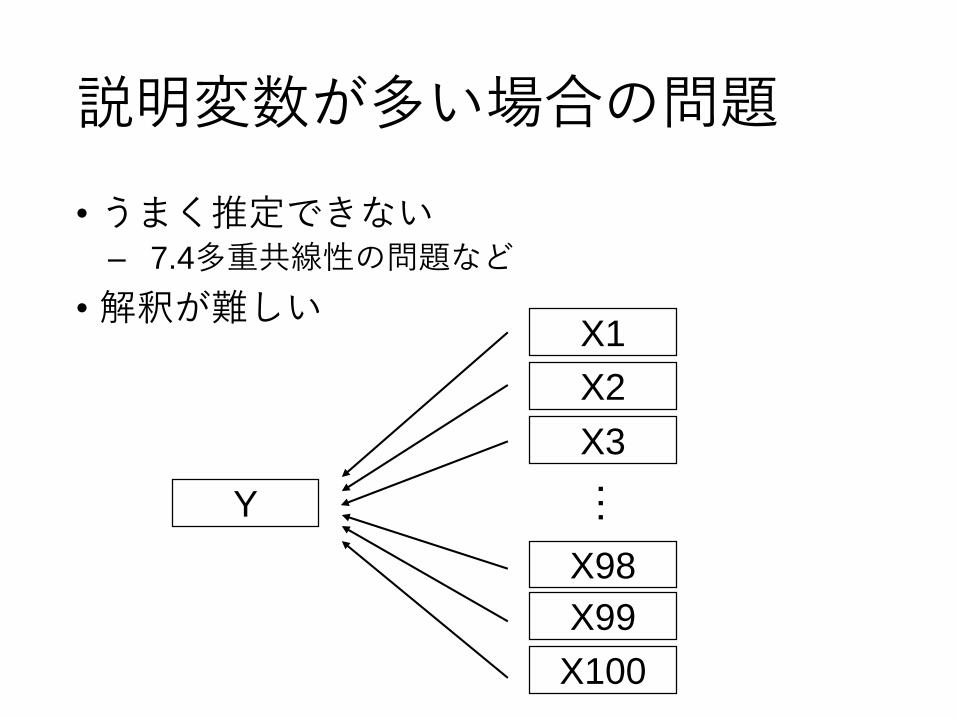
説明変数が多い場合の問題
• うまく推定できない– 7.4多重共線性の問題など
• 解釈が難しい
Y
X1
X2
X3
X98
X99
X100
…
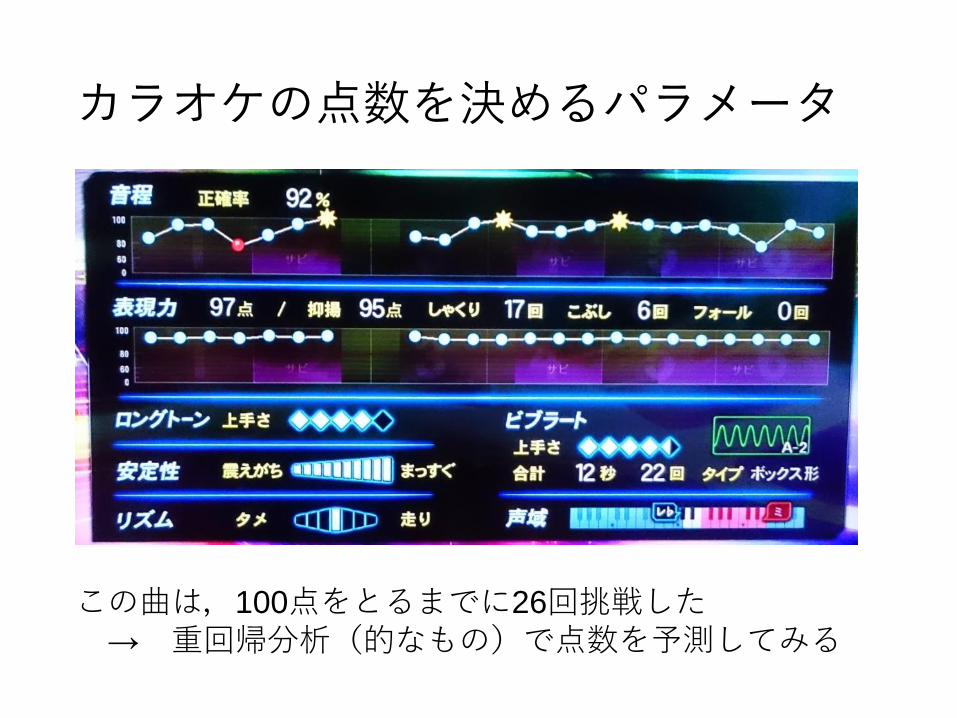
カラオケの点数を決めるパラメータ
この曲は,100点をとるまでに26回挑戦した→ 重回帰分析(的なもの)で点数を予測してみる

(説明変数を行列形式でまとめる記法はStan超初心者講習スライドを参照)
karaoke.stanとして保存
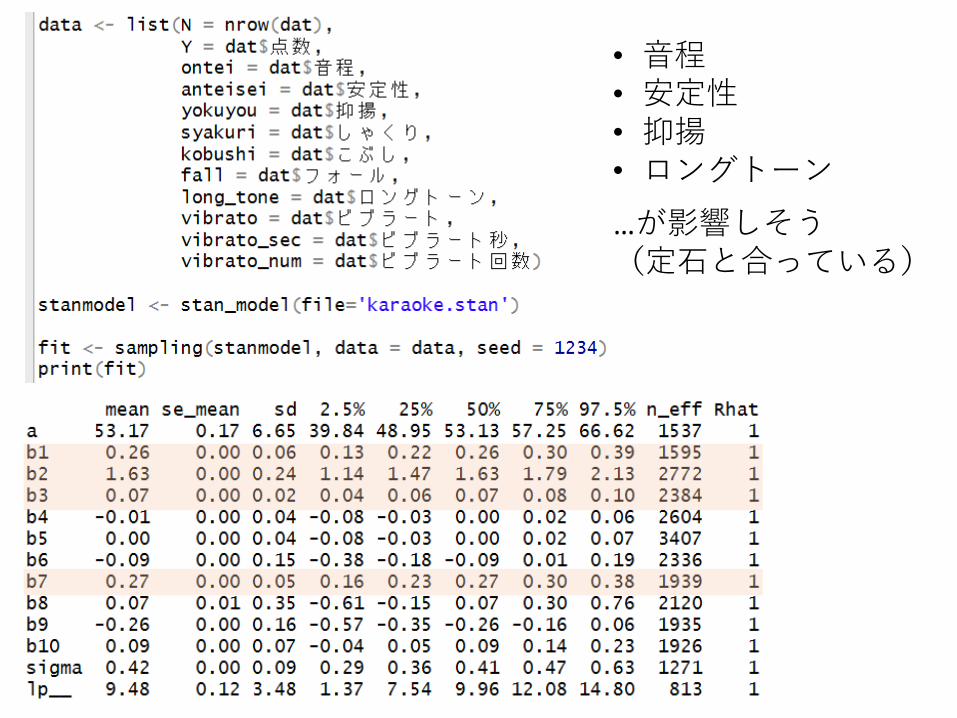
• 音程• 安定性• 抑揚• ロングトーン
…が影響しそう(定石と合っている)
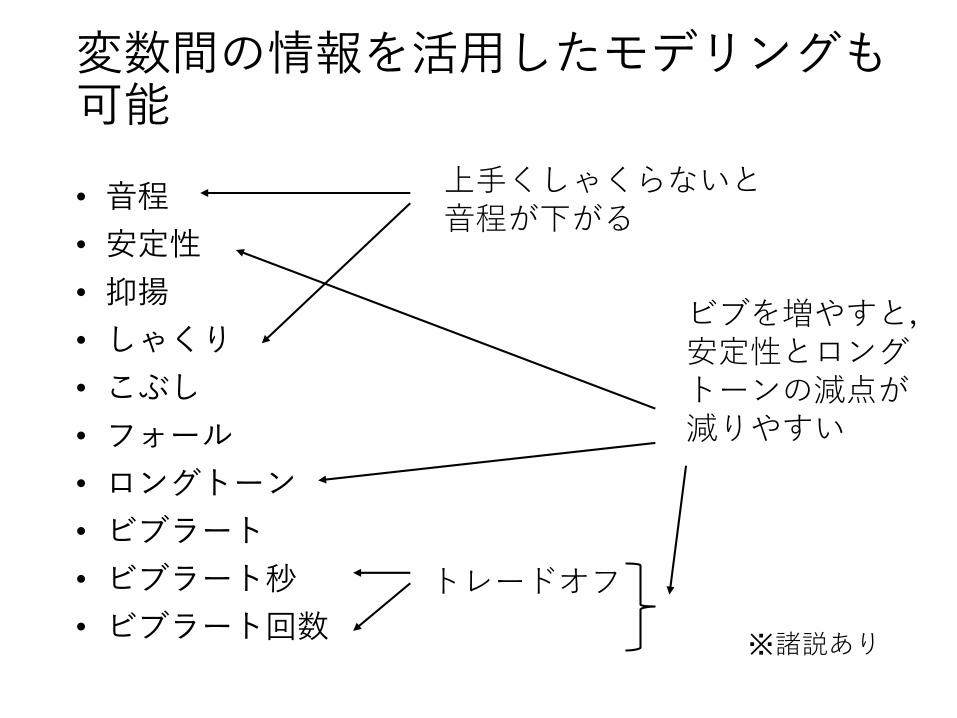
変数間の情報を活用したモデリングも可能
• 音程
• 安定性
• 抑揚
• しゃくり
• こぶし
• フォール
• ロングトーン
• ビブラート
• ビブラート秒
• ビブラート回数
トレードオフ
ビブを増やすと,安定性とロングトーンの減点が減りやすい
上手くしゃくらないと音程が下がる
※諸説あり
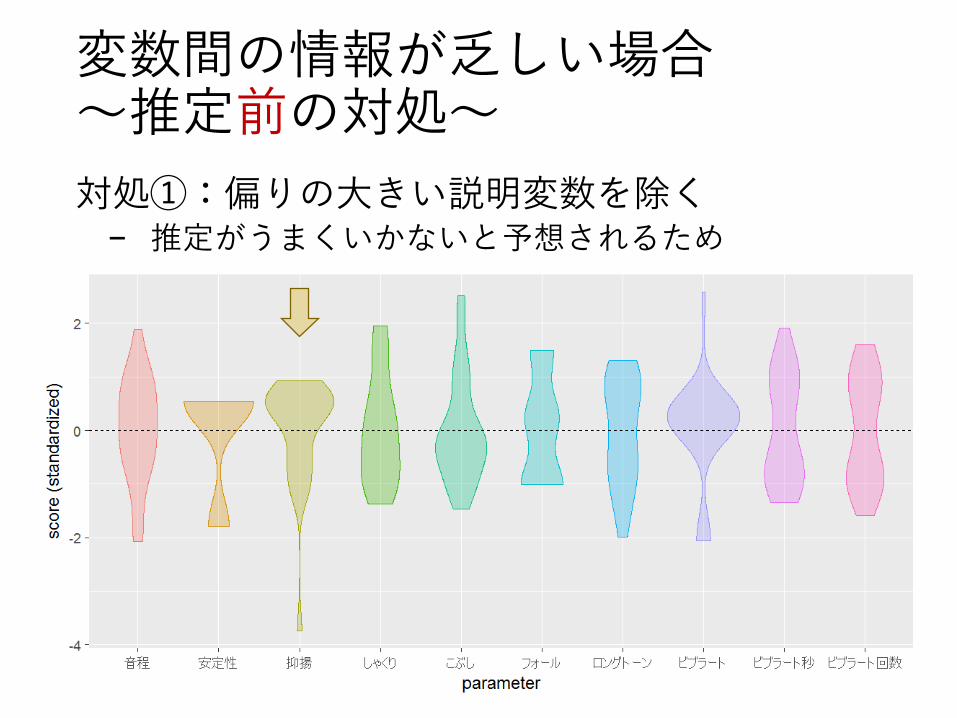
変数間の情報が乏しい場合~推定前の対処~
対処①:偏りの大きい説明変数を除く− 推定がうまくいかないと予想されるため
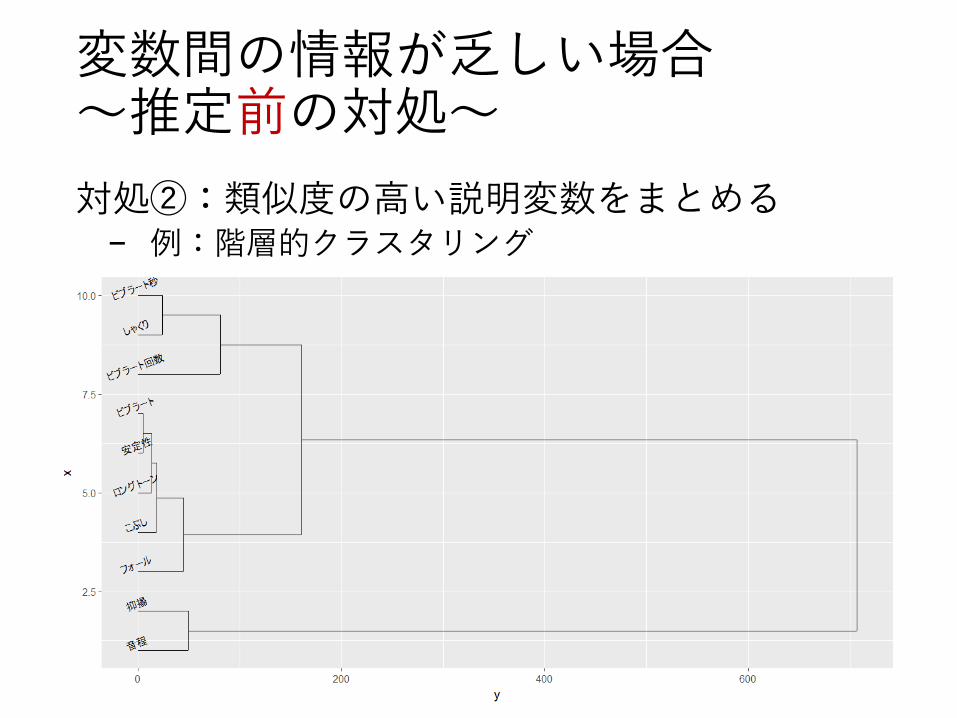
対処②:類似度の高い説明変数をまとめる− 例:階層的クラスタリング
変数間の情報が乏しい場合~推定前の対処~

対処③:データの次元を減らして説明変数とする− 例:主成分分析
変数間の情報が乏しい場合~推定前の対処~
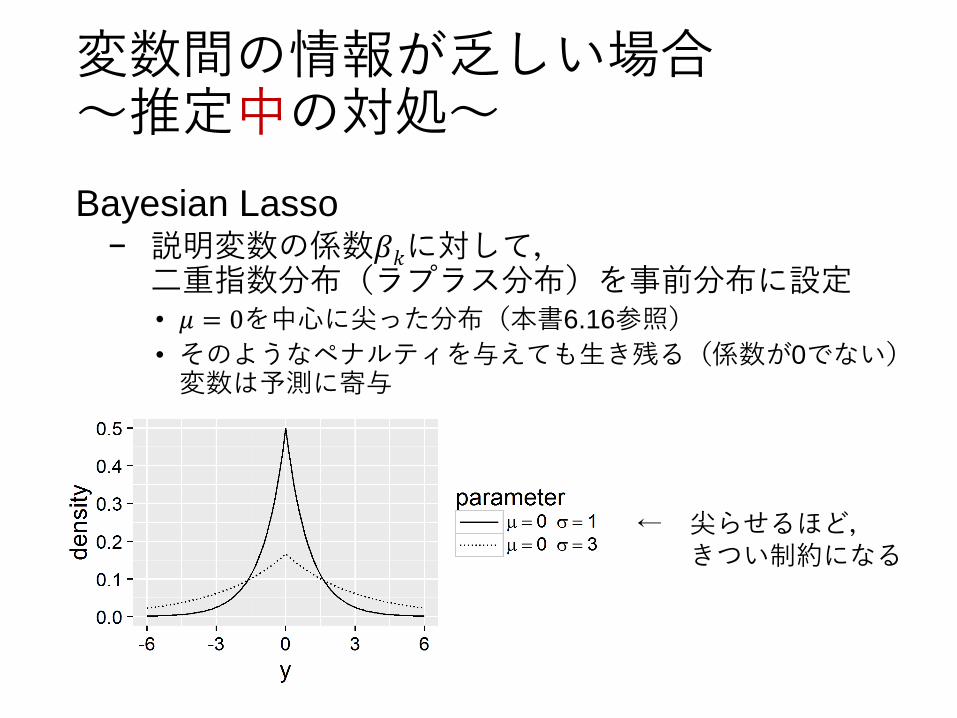
Bayesian Lasso− 説明変数の係数𝛽𝑘に対して,
二重指数分布(ラプラス分布)を事前分布に設定• 𝜇 = 0を中心に尖った分布(本書6.16参照)
• そのようなペナルティを与えても生き残る(係数が0でない)変数は予測に寄与
変数間の情報が乏しい場合~推定中の対処~
← 尖らせるほど,きつい制約になる

事前分布を加筆
説明変数は標準化しておく
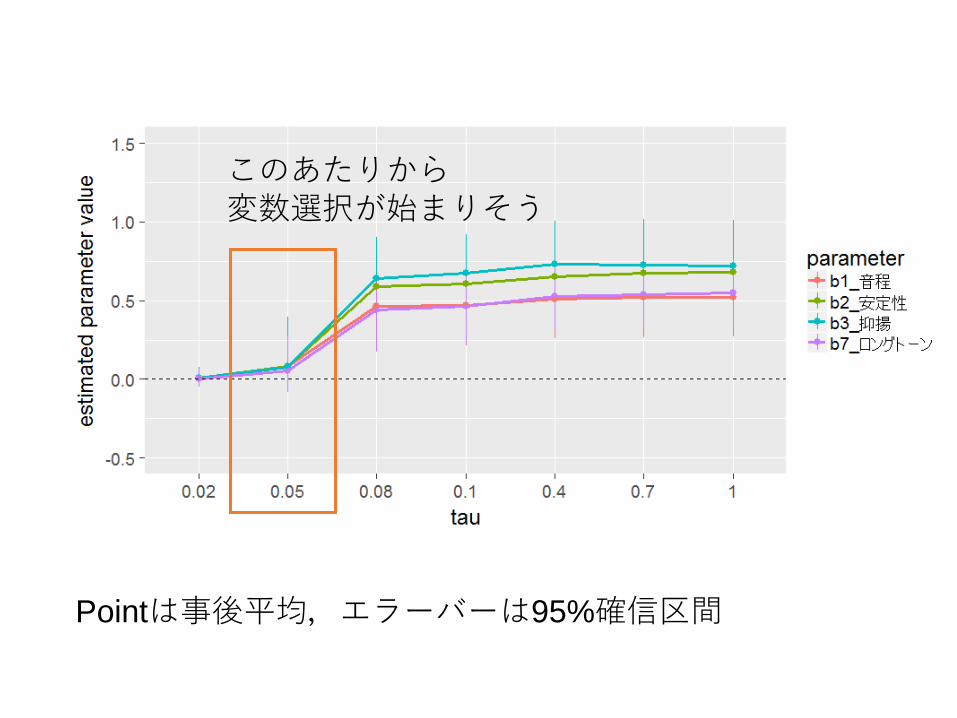
Pointは事後平均,エラーバーは95%確信区間
このあたりから変数選択が始まりそう

7.7説明変数にノイズを含む

背後では厳密な数値が得られているはずだが,ユーザには分からないので,見た目で点数を推測して,0~10点で入力→ ±1点程度の誤差があると仮定
点数真の
ビブラート得点見た目で推測した
ビブラート得点

まずはノイズを仮定せずにビブラート得点で点数を予測
データ数
見た目で推測したビブラート得点
点数
4章の単回帰と同じ
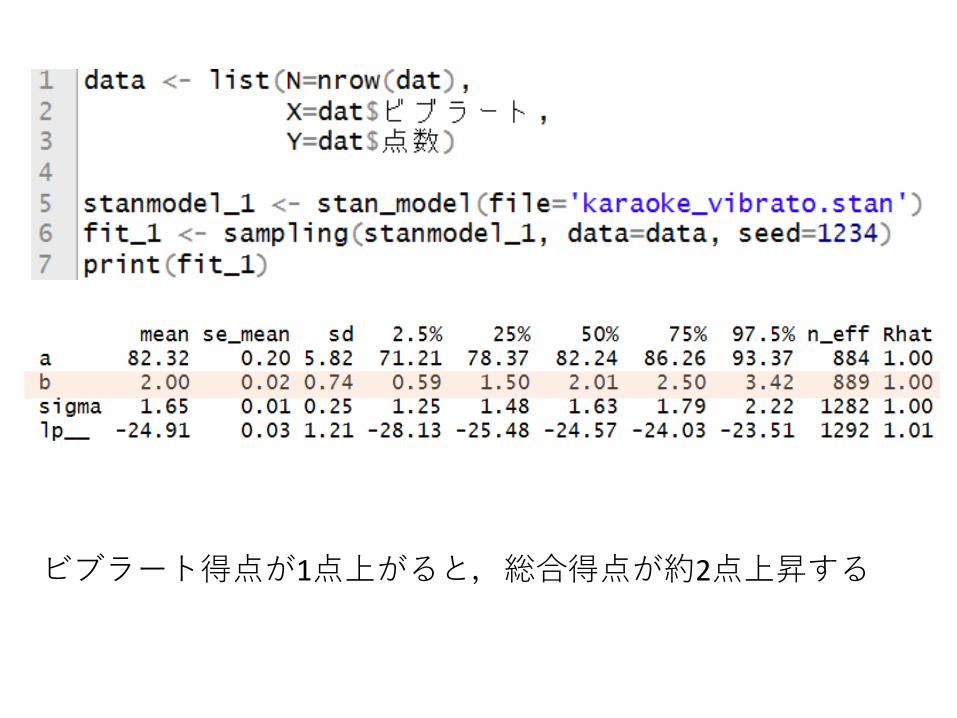
ビブラート得点が1点上がると,総合得点が約2点上昇する

真のビブラート得点で点数を予測(ノイズの仮定有)
手元のビブラート得点が,標準偏差1の正規分布から得られたと仮定して真の得点を推定
その推定値を用いて,真のビブラート得点の影響を推定
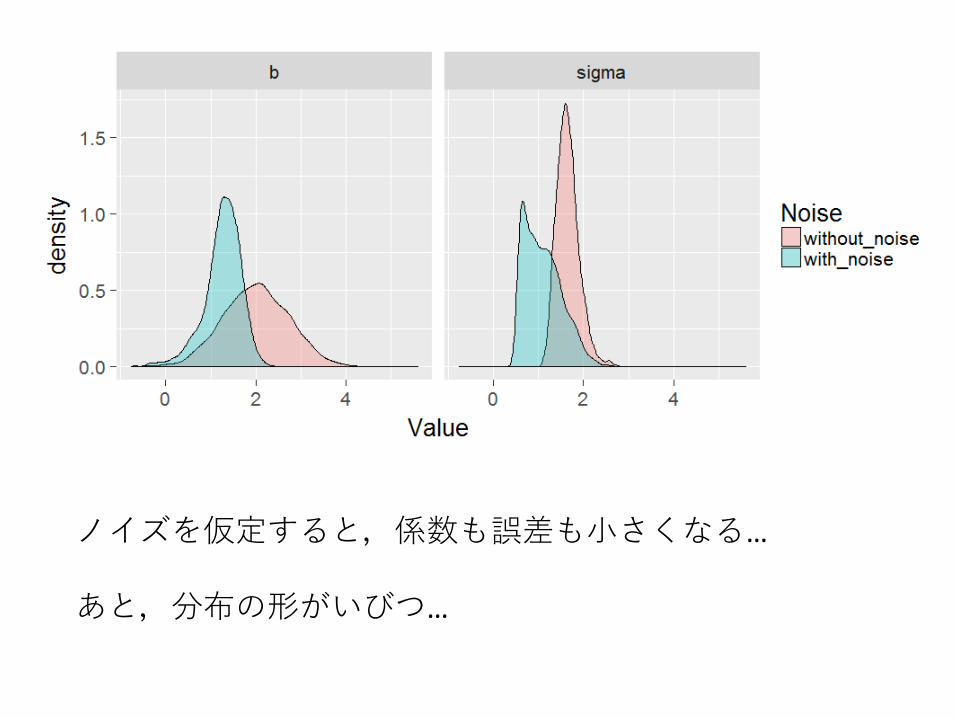
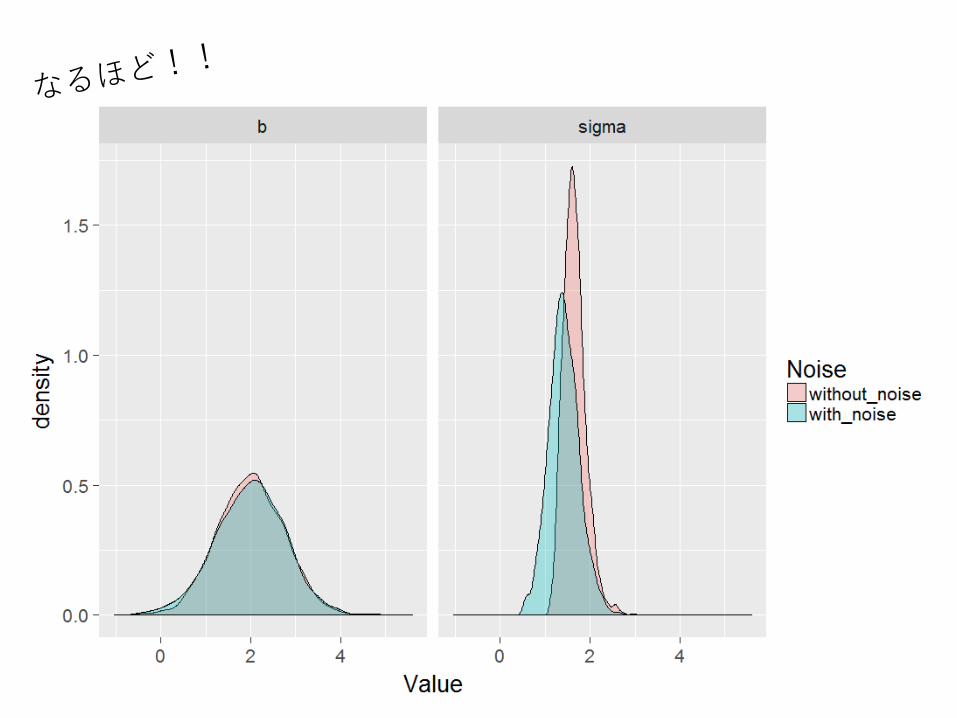
ノイズを仮定すると,係数も誤差も小さくなる…
あと,分布の形がいびつ…
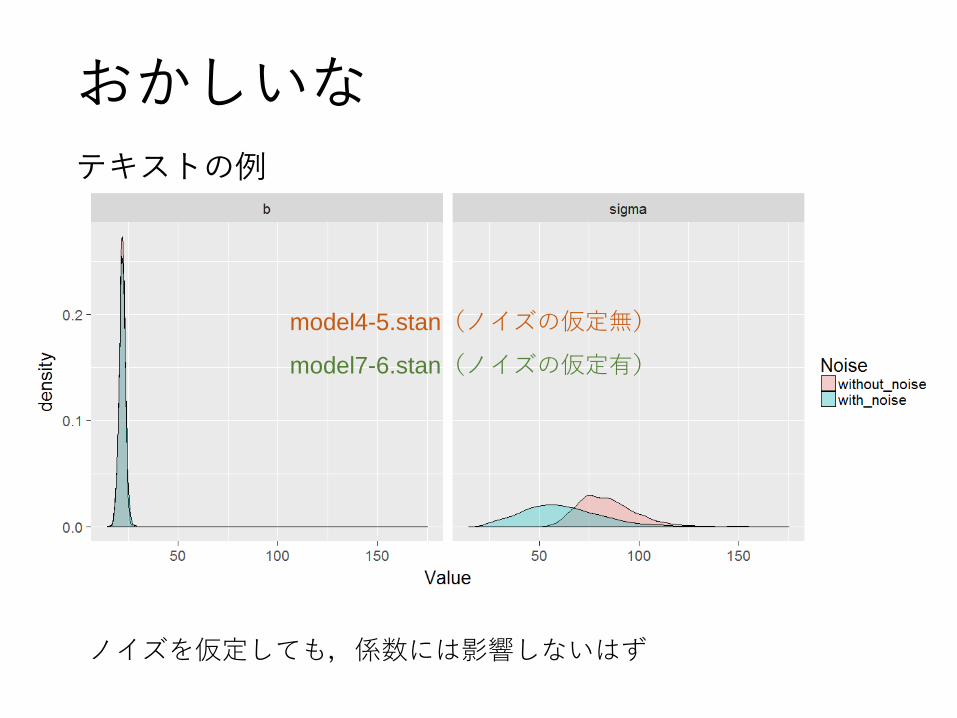
おかしいな
テキストの例
ノイズを仮定しても,係数には影響しないはず
model4-5.stan(ノイズの仮定無)
model7-6.stan(ノイズの仮定有)

広島大学・平川先生による,仮想データを用いた回帰
ノイズの仮定有
ノイズの仮定無
やはり係数にはあまり影響しない…

データをよく見てみる(今更)
元々の説明変数の標準偏差を超えるノイズを仮定していた
超えないように調整↓

7.8打ち切り

スコアラーあるある
見た瞬間に「あーーーもう! 次!」とか言って消す
→ 正確な点数が記憶されない(記録はされるけど)
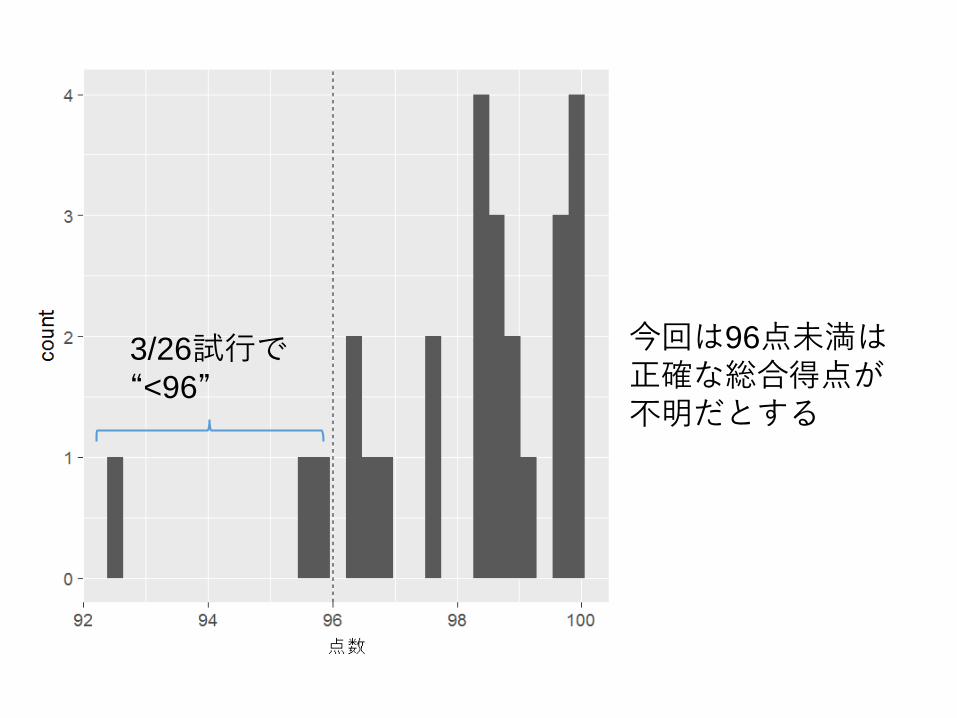
今回は96点未満は正確な総合得点が不明だとする
3/26試行で“<96”

打ち切りを含む点数の生成メカニズムを知りたい
対策①:<96 となっている値を,96で置換
ただし,平均値と標準偏差にバイアスがかかる(中略)

打ち切りを含む点数の生成メカニズムを知りたい
対策②:打ち切りしない/する場合で,異なるメカニズムを考える
– 真の平均値𝜇に,測定誤差などのノイズが加わって潜在的な測定値yが生成される
- 𝑦が検出可能な範囲内にあれば,𝑦が得られる
- 𝑦が検出可能な閾値を超えたら,打ち切られた値が得られる

下限打切の場合(left-censored)
Y n ~ 𝑁𝑜𝑟𝑚𝑎𝑙(𝜇, 𝜎𝑌)
y n ~ 𝑁𝑜𝑟𝑚𝑎𝑙 𝜇, 𝜎𝑌 ただし 𝑦 𝑛 < L
𝑛 = 1,… ,𝑁𝑜𝑏𝑠
𝑛 = 1,… ,𝑁𝑐𝑒𝑛𝑠実際には観測されず推定するので小文字
・打ち切りしない測定の場合
・打ち切りする測定の場合
例:96点以下は正確な点数を覚えていない
打ち切りの閾値

パラメータを推定するには尤度の計算が必要
– 打ち切りしない測定の尤度
– 打ち切りする場合の尤度(Lは打ち切りの閾値)
𝑁𝑜𝑟𝑚𝑎𝑙 𝑌 𝜇, 𝜎𝑌)
𝑦 < 𝐿の確率
𝑃𝑟𝑜𝑏 𝑦 < 𝐿 = ∞−𝐿𝑁𝑜𝑟𝑚𝑎𝑙 𝑦 𝜇, 𝜎𝛾)
= ∞−𝐿 1
2𝜋𝜎exp −
1
2
𝑦−𝜇
𝜎
2𝑑𝑦
= න−∞
𝐿−𝜇𝜎 1
2𝜋exp −
1
2𝑧2 𝑑𝑧 = න
−∞
𝐿−𝜇𝜎𝜑(𝑧)𝑑𝑧
= Φ𝐿 − 𝜇
𝜎
標準正規分布の確率密度関数

Stanマニュアルp475より
Stanにおける尤度の計算といえば,target+記法(4.3節参照)
ただしtarget+記法では,対数尤度を足し合わせている

まず,観測されたデータを用いて𝜇と𝜎が推定され,対数尤度を計算
↓
推定した𝜇と𝜎により推測される分布の形から,𝑃𝑟𝑜𝑏 𝑦 < 𝐿 を計算

真の点数を用いた場合
<96を96に置換した場合
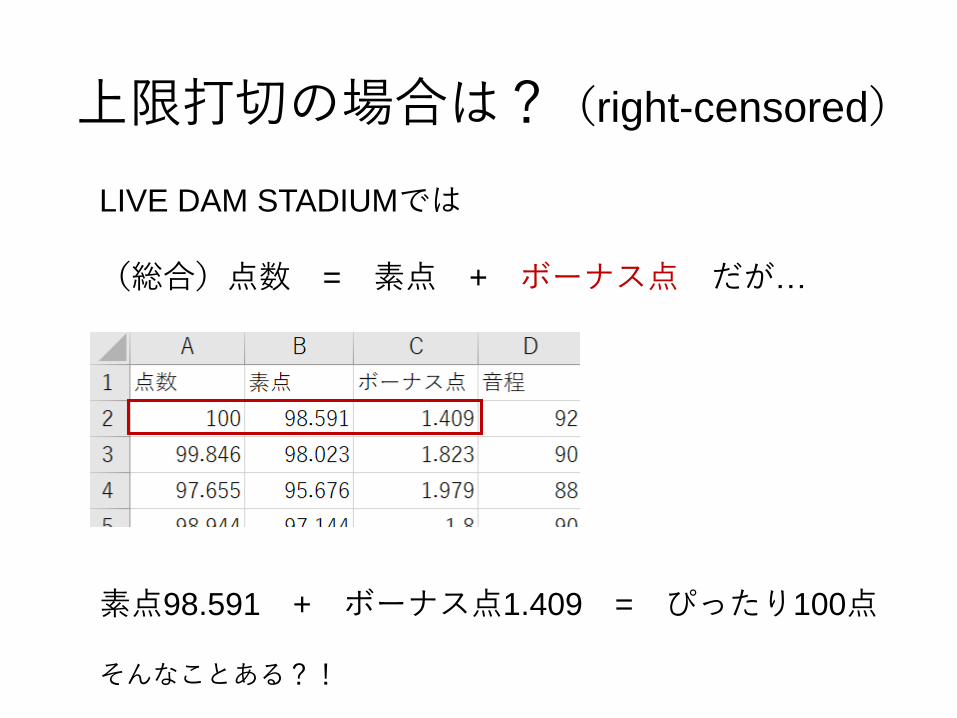
上限打切の場合は?(right-censored)
LIVE DAM STADIUMでは
(総合)点数 = 素点 + ボーナス点 だが…
素点98.591 + ボーナス点1.409 = ぴったり100点
そんなことある?!

他の100点を取った曲を見ても…
素点と本来のボーナス点の合計が100点を超える場合は,総合得点が100点になるようにボーナス点が調整される
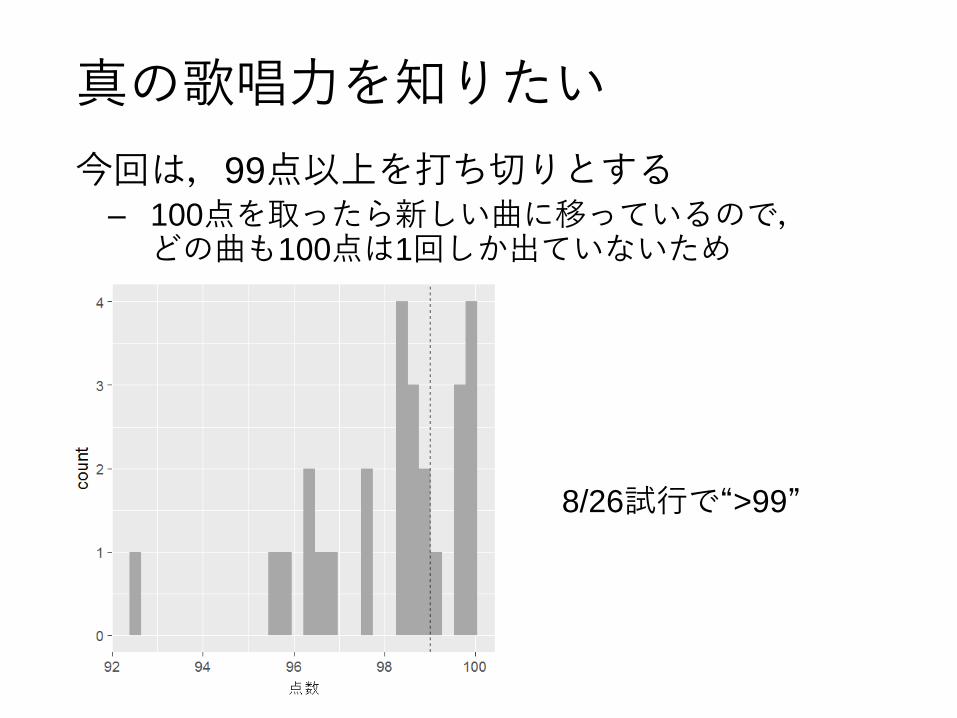
真の歌唱力を知りたい
今回は,99点以上を打ち切りとする– 100点を取ったら新しい曲に移っているので,
どの曲も100点は1回しか出ていないため
8/26試行で“>99”

Stanマニュアルp183より

Stanマニュアルp183より
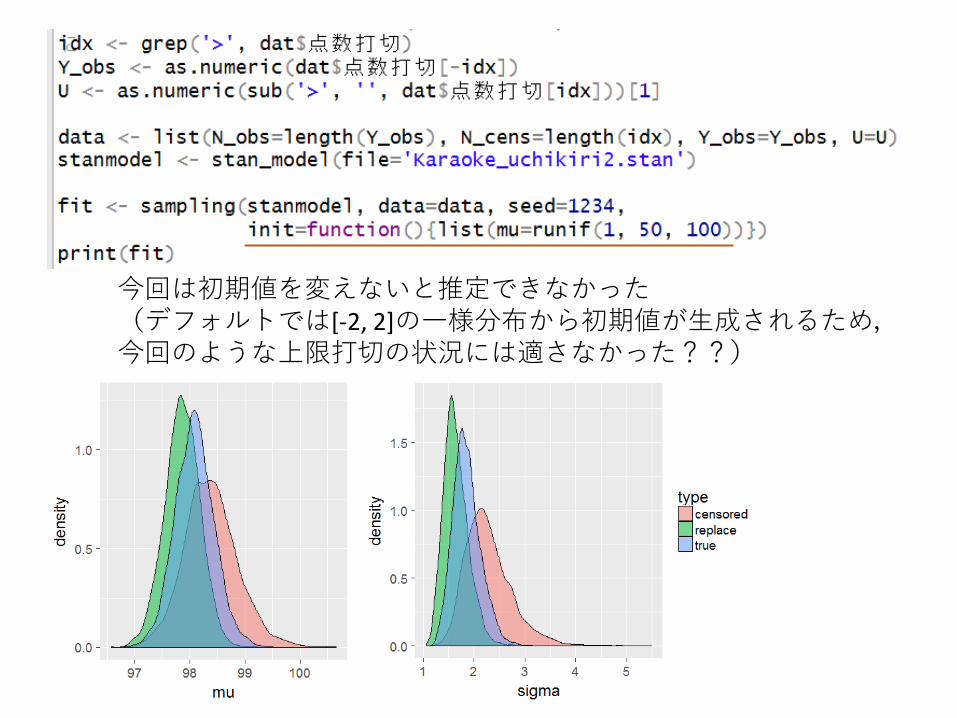
今回は初期値を変えないと推定できなかった(デフォルトでは[-2, 2]の一様分布から初期値が生成されるため,今回のような上限打切の状況には適さなかった??)

7.9外れ値
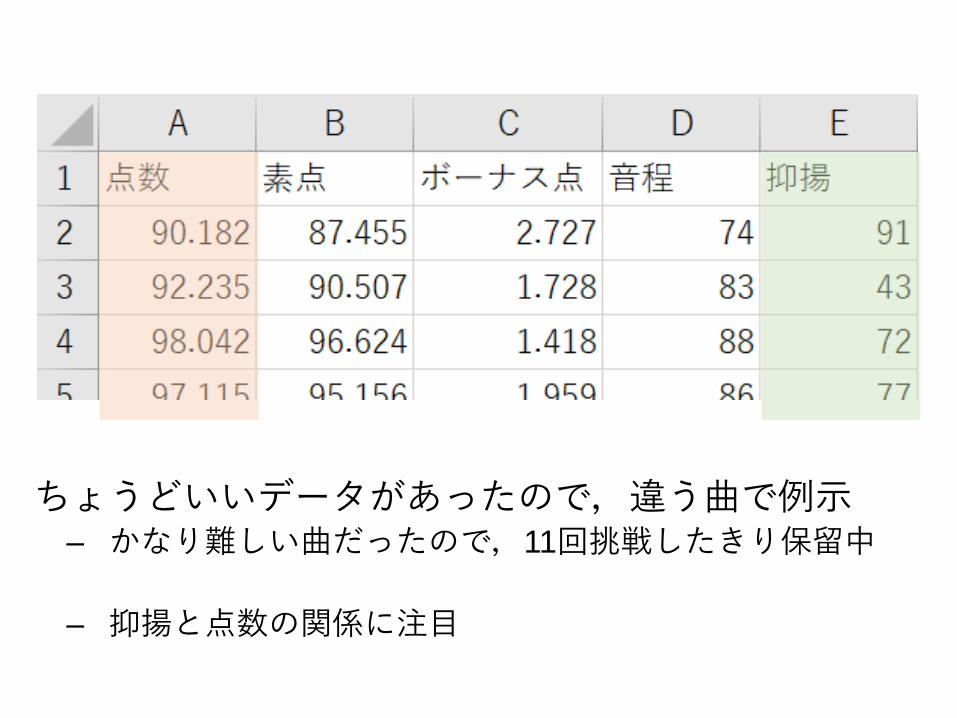
ちょうどいいデータがあったので,違う曲で例示‒ かなり難しい曲だったので,11回挑戦したきり保留中
‒ 抑揚と点数の関係に注目
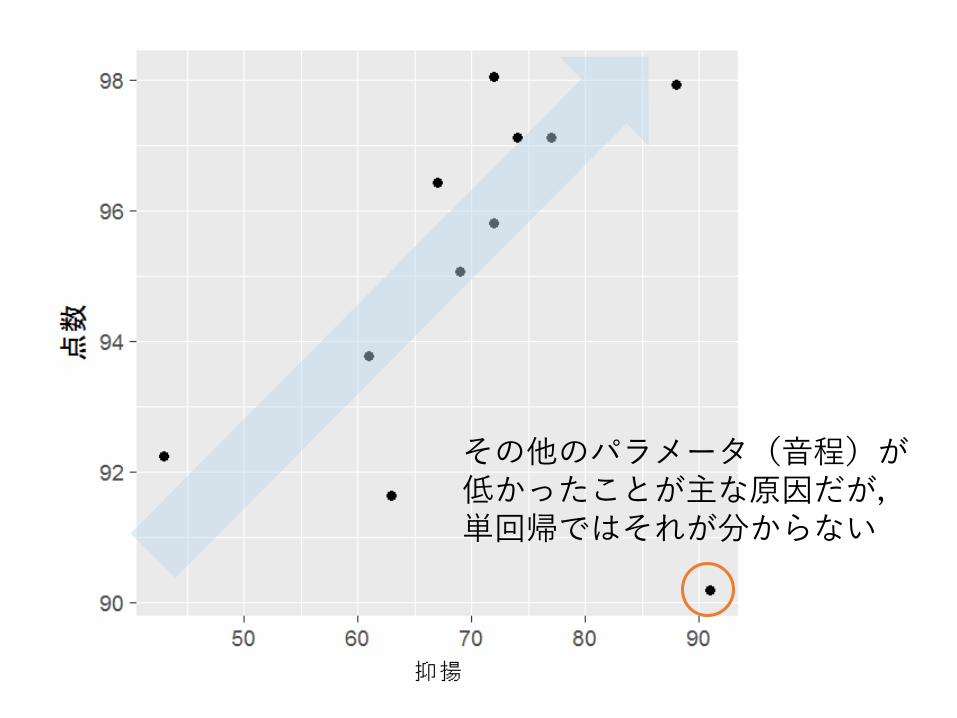
その他のパラメータ(音程)が低かったことが主な原因だが,単回帰ではそれが分からない

外れ値への対処
• 原因が明確で分析に不適な場合(例:歌唱中に中断)
‒ 当該データの修正や削除
• 経験的にあり得る場合(例:スランプによる低得点)
1. 本当の力はこんなもんじゃない,と,除外
2. 稀に外れ値が出ることが分かっているので,そのようなメカニズムを仮定し,外れ値を含めて解析
- 裾の長いコーシー分布
- Studentのt分布

ノイズに正規分布を仮定したモデル式(単回帰)– 𝑌 𝑛 ~ 𝑁𝑜𝑟𝑚𝑎𝑙 𝑎 + 𝑏𝑋 𝑛 , 𝜎 𝑛 = 1, 2,… ,𝑁
点数
model7-8.stan
予測分布を描くために正規分布に従う乱数を生成
抑揚

点数
コーシー分布を仮定したモデル式– 𝑌 𝑛 ~ 𝐶𝑎𝑢𝑐ℎ𝑦 𝑎 + 𝑏𝑋 𝑛 , 𝜎 𝑛 = 1, 2,… ,𝑁
予測分布を描くためにコーシー分布に従う乱数を生成
model7-9.stan
抑揚

ノイズに正規分布を仮定した場合
→ 外れ値に引っ張られて予測分布が広く,95%予測区間内に外れ値が入っている
ノイズにコーシー分布を仮定した場合
→ 外れ値以外のデータに沿った傾き外れ値が95%予測区間の外にある
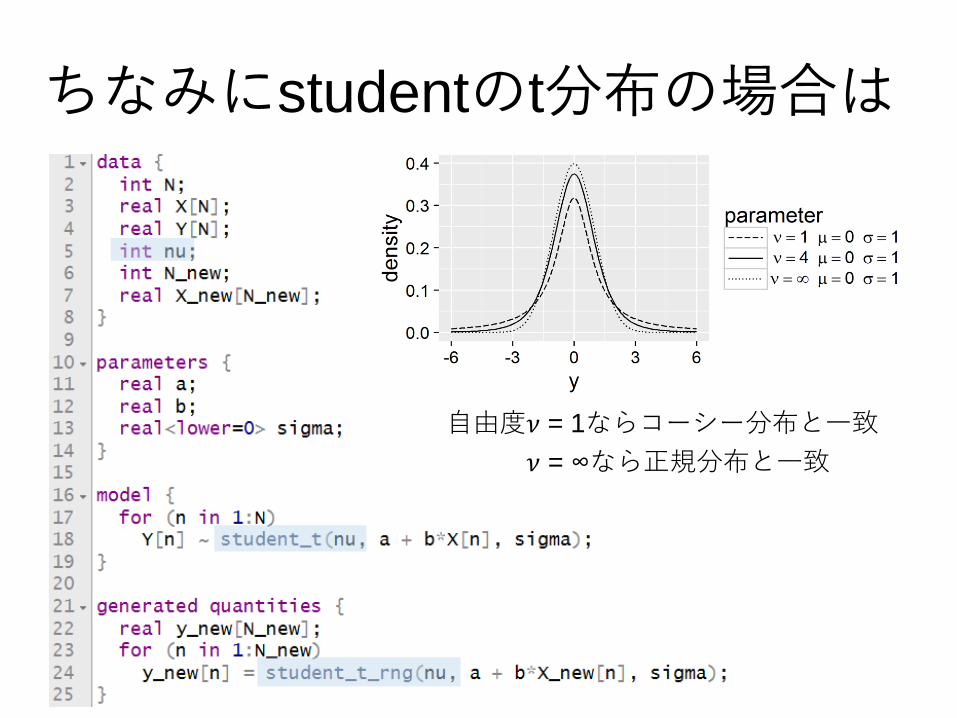
ちなみにstudentのt分布の場合は
自由度𝜈 = 1ならコーシー分布と一致
𝜈 = ∞なら正規分布と一致
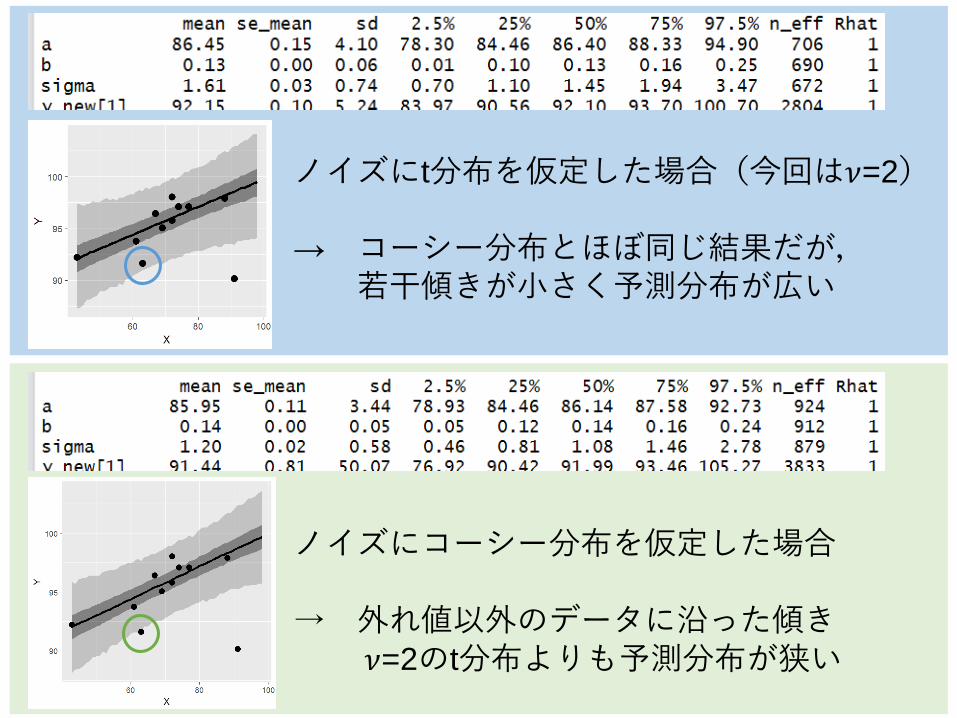
ノイズにt分布を仮定した場合(今回は𝜈=2)
→ コーシー分布とほぼ同じ結果だが,若干傾きが小さく予測分布が広い
ノイズにコーシー分布を仮定した場合
→ 外れ値以外のデータに沿った傾き𝜈=2のt分布よりも予測分布が狭い

自由度は非負(実質1以上)と考えられるので下限を指定
自由度の事前分布
自由度𝒗も推定してみる
外れ値の数が多い場合(例:全体の5%)
Stanコードの書き方 中級編よりhttps://www.slideshare.net/simizu706/stan-64926504
11章へ続く…
最後に
カラオケのモデリングは奥が深い…
(80点,90点を境に,関数形が変わるらしい…)
http://www.hnagata.net/archives/836
一緒にカラオケに行ってくれるデータを取ってくれる方,募集中