uber ベイズ推定・モデリングを用いたユーザーの目的地予測
TRANSCRIPT

"移動"にまつわるBIG DATAの応用事例と解析手法~ Bayesian Modeling を添えて ~

Agenda
1. Uberとは…
2. Bayesian Modelingに関する基礎中の基礎
3. Bayesian Modelingを用いたUserの目的地の予測
1. データの概要
2. モデル設計(事前分布、尤度の設計)
3. 事後確率の推定(MAP推定)
4. モデル結果
4. 本発表のまとめ

Profile
• 慶応義塾大学院 修士(2015)
• 交通データの解析(Probe-Car Data)
広告関連のデータやスポーツデータの分析やらその他諸々…
• Spatial Statistics, Bayesian Statistics をちょびっと
• Python/R/HDFS/Impala/Hive etc…その他も勉強中…
• GIS関連…
• “Ad Technology”界隈のエンジニアしてます。

内容を進めるにあたって
•本内容では、記述統計及びベイズ統計にふわっと触れますが、特に手法として最先端のものを扱ってはおりません。
•統計モデルに対して、深堀をするような内容ではありません。
•本発表に関する内容は、所属する団体および組織とは、全く関係はありませんので、ご了承ください。

本発表が向かうゴール
• “Uber”とその解析手法について
みんなに知ってもらいたい!!
• “Bayesian Modeling”に関して
みんなと勉強したい!!

一部省略

Bayesian Modelingを用いたユーザーの目的地の予測

Uberとは…
→ タクシー配車サービス→ アプリでサクッと呼び出すことが可能→ Online決済によりサラッと会計を済ますことが可能




Uberでは、どのようなことをやっているのか。
Bayesian Modelingを構築し、Userの目的地を予測

Bayesian Modeling

ベイズ推定を始める前に…
最尤推定法
• パラメータの値は未知であるが、人間の直観とは独立に存在する定数と捉える。 • 実際に観測データが得られた時、そのようなデータが得られる確率を最大にするパラメータの値を、最良の推定値とする。
ベイズ推定
• パラメータを、既知の事前分布をもつ確率変数として捉える。 • 観測結果を得ると、この事前分布は事後分布へと変化し、パラメータ値に対する確信度が修正される。
最尤推定法とベイズ推定の比較(簡易版)
ˆ
✓ = argmax
✓[P (x
(n); ✓) ]
ˆ
✓ = argmax
✓[P (✓|x(n)
) ]
[1]より
[1]より
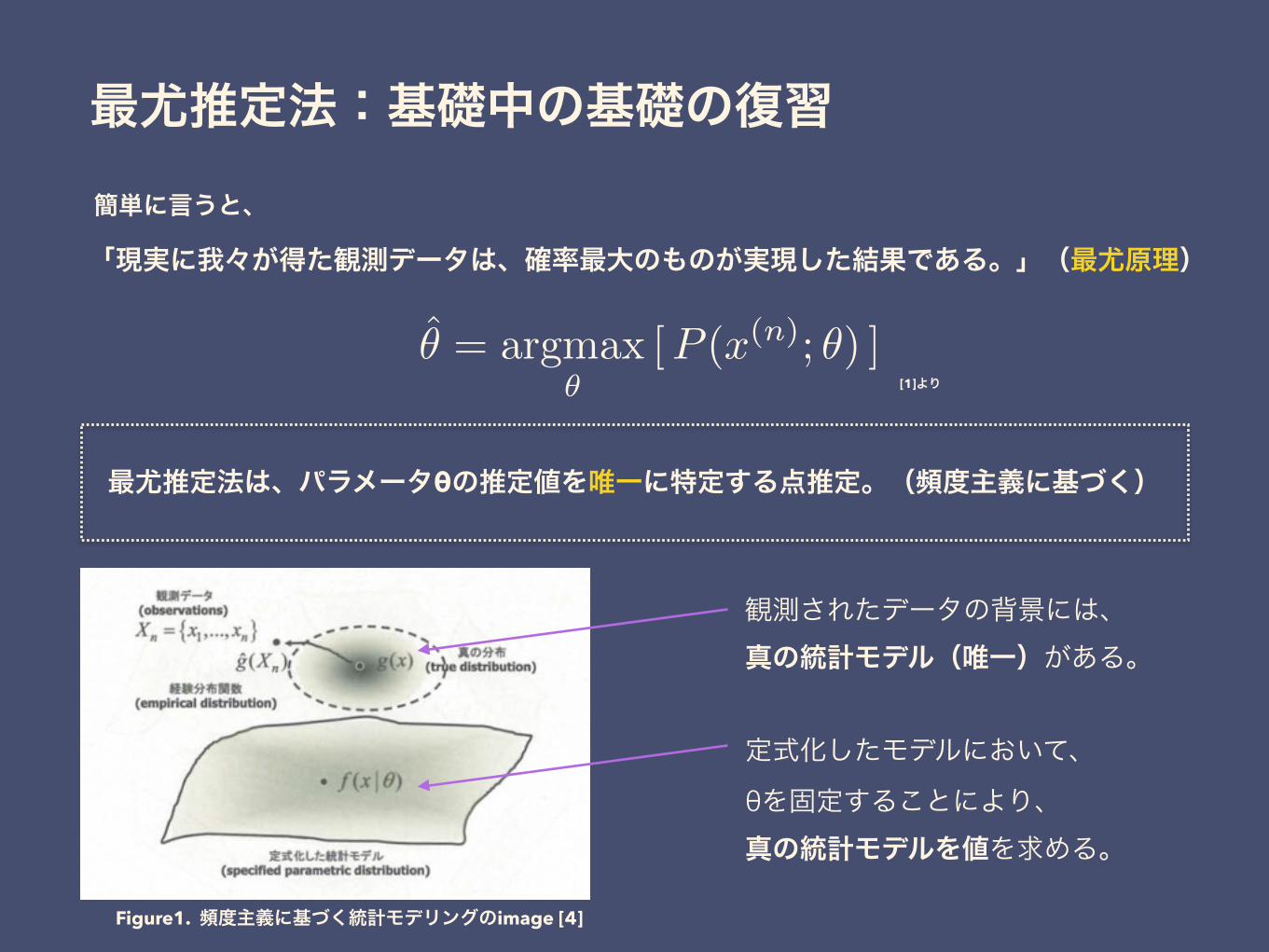
最尤推定法:基礎中の基礎の復習
「現実に我々が得た観測データは、確率最大のものが実現した結果である。」(最尤原理)
簡単に言うと、
ˆ
✓ = argmax
✓[P (x
(n); ✓) ]
最尤推定法は、パラメータθの推定値を唯一に特定する点推定。(頻度主義に基づく)
観測されたデータの背景には、真の統計モデル(唯一)がある。
定式化したモデルにおいて、 θを固定することにより、真の統計モデルを値を求める。
Figure1. 頻度主義に基づく統計モデリングのimage [4]
[1]より

ベイズの定理
ベイズ推定:基礎中の基礎の復習
* 詳細なモデリングやMCMC関連の話はなし
θに関する確率分布
θが与えられた時のyの確率(密度)関数
yが与えられた時のθの確率(密度)関数 どんな仮説であってもデータの得られる確率
• 事前分布 P(θ)
• 尤度 P(y|θ)
• 事後分布 P(θ|y)
• 正規化定数 P(y)データ出現確率
P (✓|y) = P (y|✓)P (✓)
P (y)/ P (y|✓)P (✓)
➡ 事後分布は、尤度と事前分布をかけたものに比例する!
:
:
::
[1]をもとに

ベイズ推定を用いる利点
ベイズ推定
• 事前分布(主観確率)を自由に設定(推定値の分布に正規性を仮定しなくてよい)
• ベイズ更新によるモデルの強化(データを更新していけば、理論上は推定精度は上がっていく…)
• 求めたい事象の確率分布そのものを予測
• 点推定値を用いれば、頻度モデルと同様の結果を返すことも可能
• 真の値(結果)は一つである必要がない
• 観測回数nが小さい場合、事前分布が適切に設定されているならば、
「ベイズ推定 + 事後確率最大化」が有利
[1]と[7]より

ベイズ推定を用いる欠点
ベイズ推定
• 速くなったとは言えど、推定にかかる時間が長い…
• 複雑なモデルだと、収束しない場合が多々…
• 初期の教育課程において学ぶ頻度主義とは考え方が異なるので、
ちょっと習得コストが…
• 推定する上で、習得すべき理論や言語が多々…
(MCMCやそれらに関係するStan/Jags etc…)[1]と[7]より
最終推定で解くべきか、ベイズ推定で解くべきか、よく議題になるが、それぞれの目的やコストとの兼ね合いに応じて利用すればよい。

Bayesian Modelingを用いたユーザーの目的地の予測

Userの目的地予測モデル設計の詳細

少なくね!?
Base data
期間:半年分(2014年)
場所:San Francisco周辺
→タクシーで地域をまたぐ大移動は少ないため、
地域ごとのclosedなモデルを作成したらしい
データ量:3, 000以上の乗客利用データ(unique)
データの概要

確率的予測
ベイズの定理に当てはめる
目的地 特徴量
事前確率尤度
• 基本的なベイズの定理 • 事前分布と尤度を工夫し、モデル設計
P (D = i|X = x) =P (X = x|D = i)P (D = i)
PNj=1 P (X = x|D = j)P (D = j)
[9]より

3種類の事前分布を設定する → 混合正規分布の利用
1. 特定のUserはどこに行く傾向があるか。= Rider Prior
→「Userの履歴」
2. Uberを利用するUserは全体的にどこに行く傾向があるか。= Uber Prior
→「Uberにおける傾向」
3. このエリアではどの場所が一般的に人気が高いのか。= Popular Place Prior
→「人気のある場所に関するデータ」
事前分布の構築

1. 「Userの履歴」
• Userにとって馴染み深い場所はもちろん、そうでもない場所を考慮する
• 既に訪れたことのある場所には任意の確率を、
そうではない場所には全て「0」の確率を設定
• データのないUserには、全ての場所に対して「0」の確率を設定→いわば、「コールドスタート問題」対応
P (D = i|C = c)
Userを表す確率変数
PRider(D = i)事前分布の構築 →
[9]より

2. 「Uberにおける傾向」
• UberのUserが特定の場所に行く特性を利用
• UberのUserが訪れたことのある場所毎の回数を利用(正規化)
PUber(D = i) = P (D = i|is Uber user)
PUber(D = i)
UberのUserが訪れる場所の正規化された回数
事前分布の構築 →
[9]より

PUber(D = i)
Figure2. UberのUserの事前分布[9]
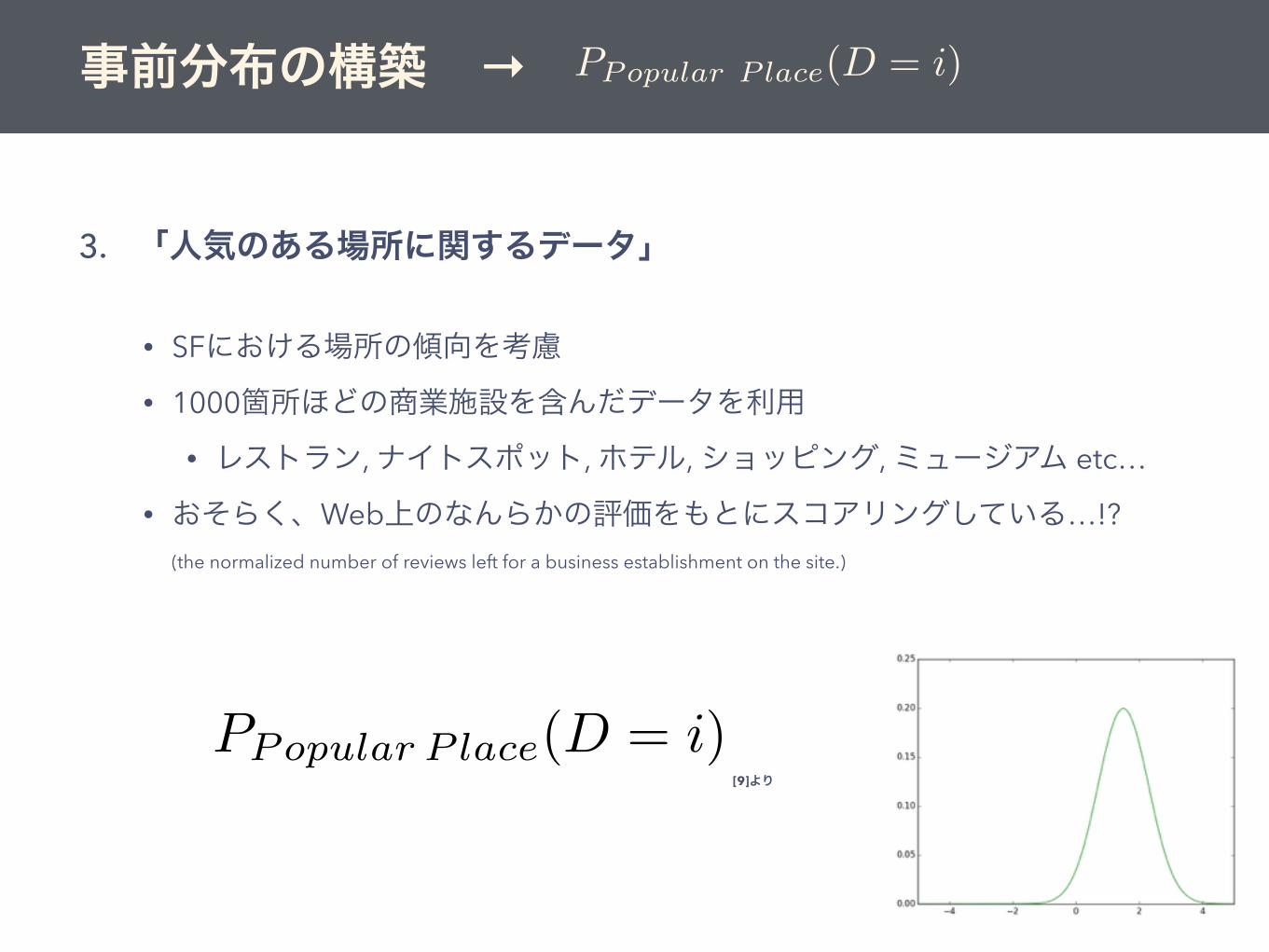
3. 「人気のある場所に関するデータ」
• SFにおける場所の傾向を考慮
• 1000箇所ほどの商業施設を含んだデータを利用
• レストラン, ナイトスポット, ホテル, ショッピング, ミュージアム etc…
• おそらく、Web上のなんらかの評価をもとにスコアリングしている…!?(the normalized number of reviews left for a business establishment on the site.)
PPopular P lace
(D = i)
PPopular P lace
(D = i)事前分布の構築 →
[9]より

P (D = i) = ↵PPopular P lace
(D = i) + �PUber
(D = i) + (1� ↵� �)PRider
(D = i)
Popular Place Prior Uber Prior Rider Prior
Destination Prior
.3 .3 .4
← これを事前分布として設定! (実際の値はわかりません…)
Hyper Parameter
事前分布の組み合わせ
[9]より

1. 「Userの履歴」
➡ あなたがよく行く場所…
2. 「Uberにおける傾向」
➡ あなたの友達がよく行く場所…
3. 「人気のある場所に関するデータ」
➡ 一般的によく行かれる場所…
3種類の事前分布を設定することにより…
事前分布の組み合わせ
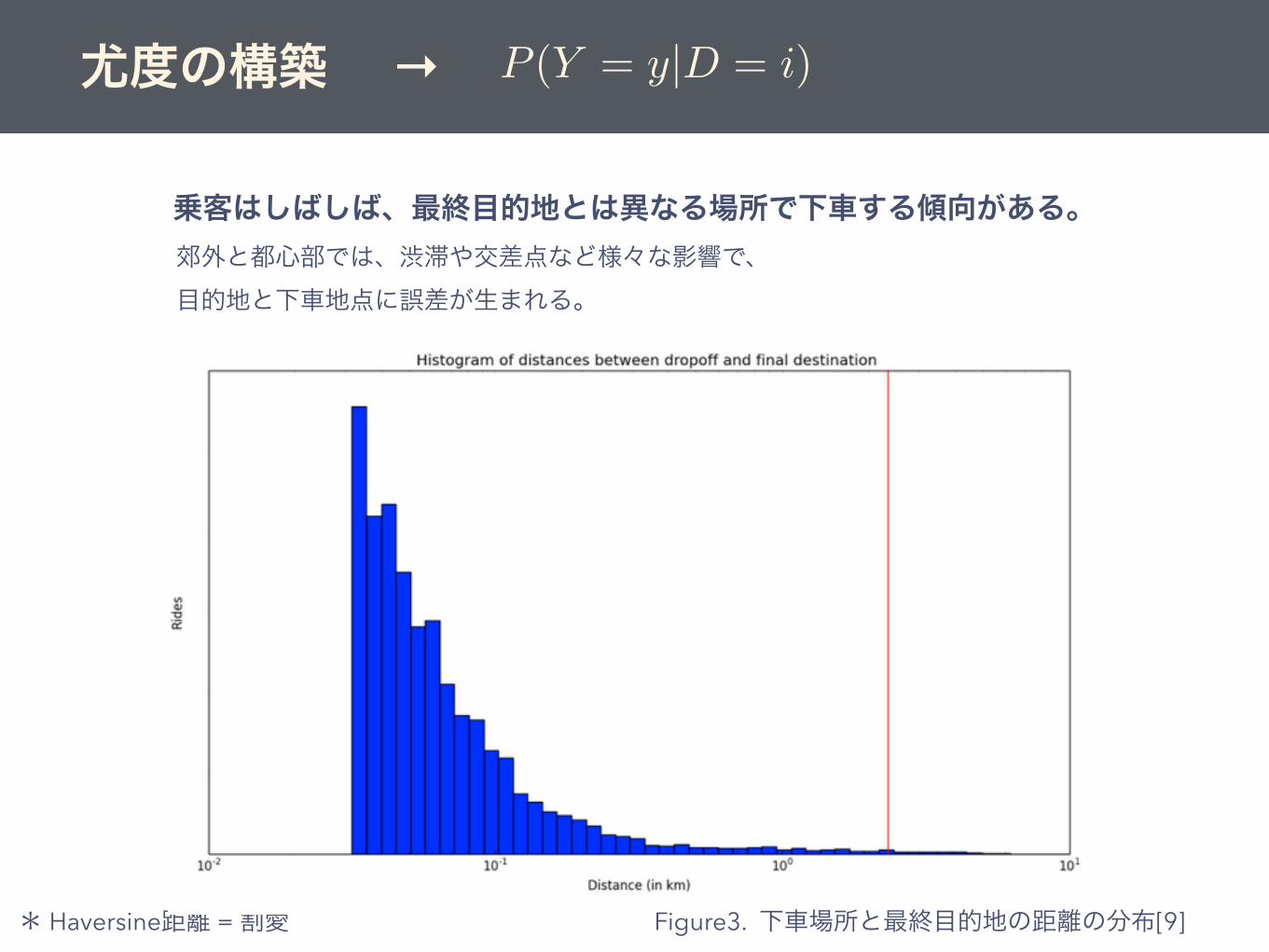
乗客はしばしば、最終目的地とは異なる場所で下車する傾向がある。
P (Y = y|D = i)
* Haversine距離 = 割愛
尤度の構築 →
Figure3. 下車場所と最終目的地の距離の分布[9]
郊外と都心部では、渋滞や交差点など様々な影響で、目的地と下車地点に誤差が生まれる。

ガウス分布に従うと仮定し、最尤推定値 と を利用。µ̂MLE �̂2MLE
P (Y = y|D = i) = N(Y = y|µ,�2)
• 目的地と下車地点の距離の確率分布の算出
目的地と下車地点の距離の確率分布ガウス分布に従う
P (Y = y|D = i)尤度の構築 →
[9]より

• 平均値と分散の推定値の算出
平均値
分散
ガウス分布のあれ
目的地と下車地点の距離の確率分布
uniform distribution
ˆ�
2Z=z =
1Pnk=1 1(Z = z)
nX
k=1
(xk � ˆµZ=z)2
ˆµZ=z =1Pn
k=1 1(Z = z)
nX
k=1
xk 1(Z = z)
P (Y = y|D = i) =
1p2⇡�
exp[� (xk � ˆµZ=z)2
ˆ
2�
2Z=z
]
P (Y = y|D = i)尤度の構築 →
[9]より
[9]をもとに
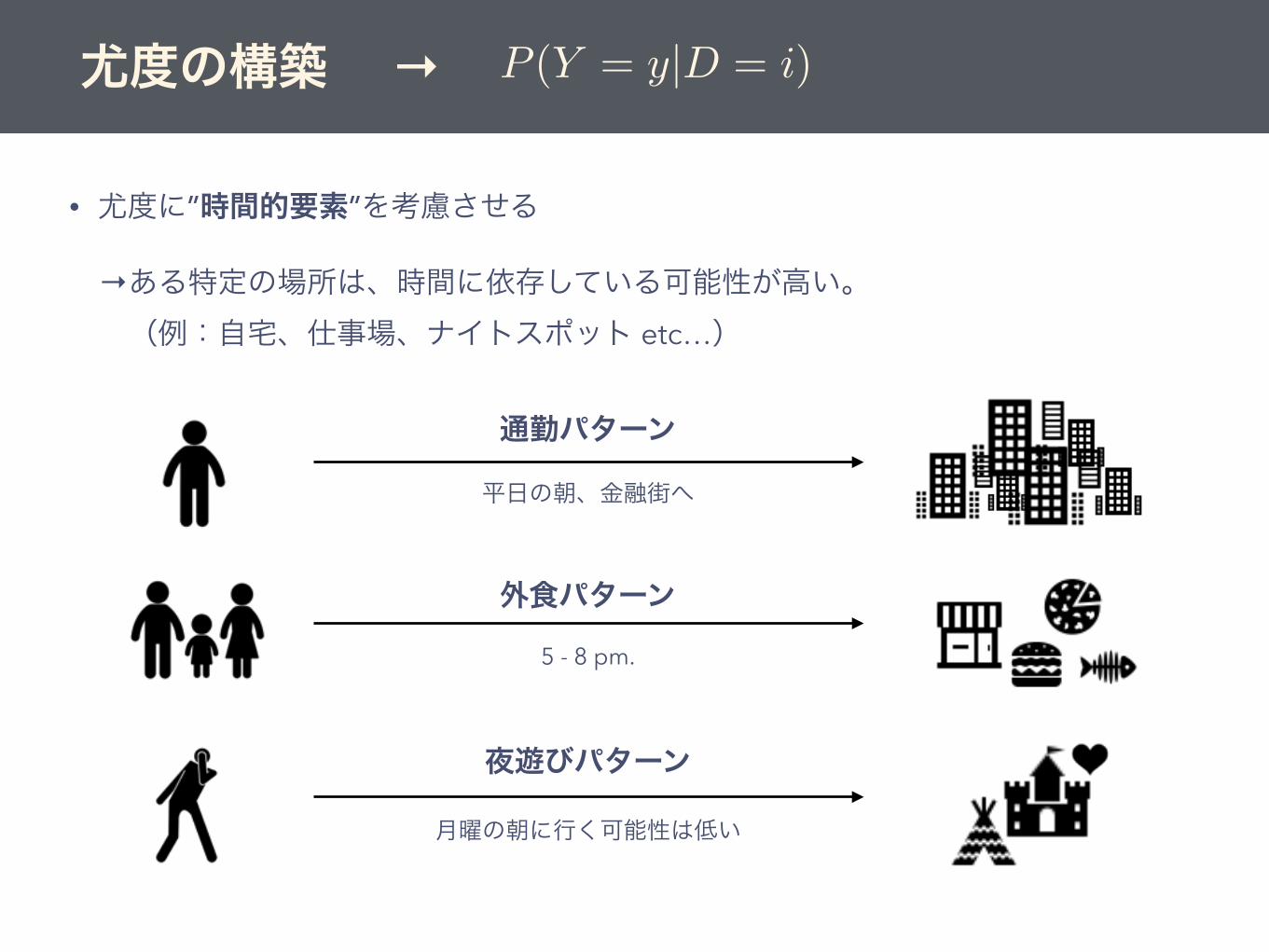
→ある特定の場所は、時間に依存している可能性が高い。 (例:自宅、仕事場、ナイトスポット etc…)
• 尤度に”時間的要素”を考慮させる
通勤パターン
外食パターン
夜遊びパターン
平日の朝、金融街へ
5 - 8 pm.
月曜の朝に行く可能性は低い
P (Y = y|D = i)尤度の構築 →

• “時間的要素”を考慮するための確率分布
P (T = t|D = i)
各乗車の時間帯を表す確率変数
→ イベント確率を各時間帯 における場所 への乗車カウント数(正規化)を カテゴリー分布として表現(時間は1時間区切り)
t i
P (T = t|D = i)
P (Y = y|D = i)尤度の構築 → ×
[9]より

✦ 尤度の完成
P (X = x|D = i) = P (Y = y, T = t|D = i)
= P (Y = y|D = i)P (T = t|D = i)
• 「個人の履歴」「UberのUserの傾向」「SFの傾向」の3つの確率分布を混合 • 各時間帯毎のカウント数をもとにカテゴリー分布を生成
事前分布を設定
時間帯毎の各乗車回数目的地と下車地点の距離の確率分布
尤度
尤度の構築 → P (X = x|D = i)
[9]より

事後分布の推定
• 事後分布を求める
• Userの真の目的地を求める。
• “事後分布”は、先に求めた”事前分布”と”尤度”の乗算で求めることが可能
事前確率尤度
P (D = i|X = x) =P (X = x|D = i)P (D = i)
PNj=1 P (X = x|D = j)P (D = j)
事後分布
[9]より
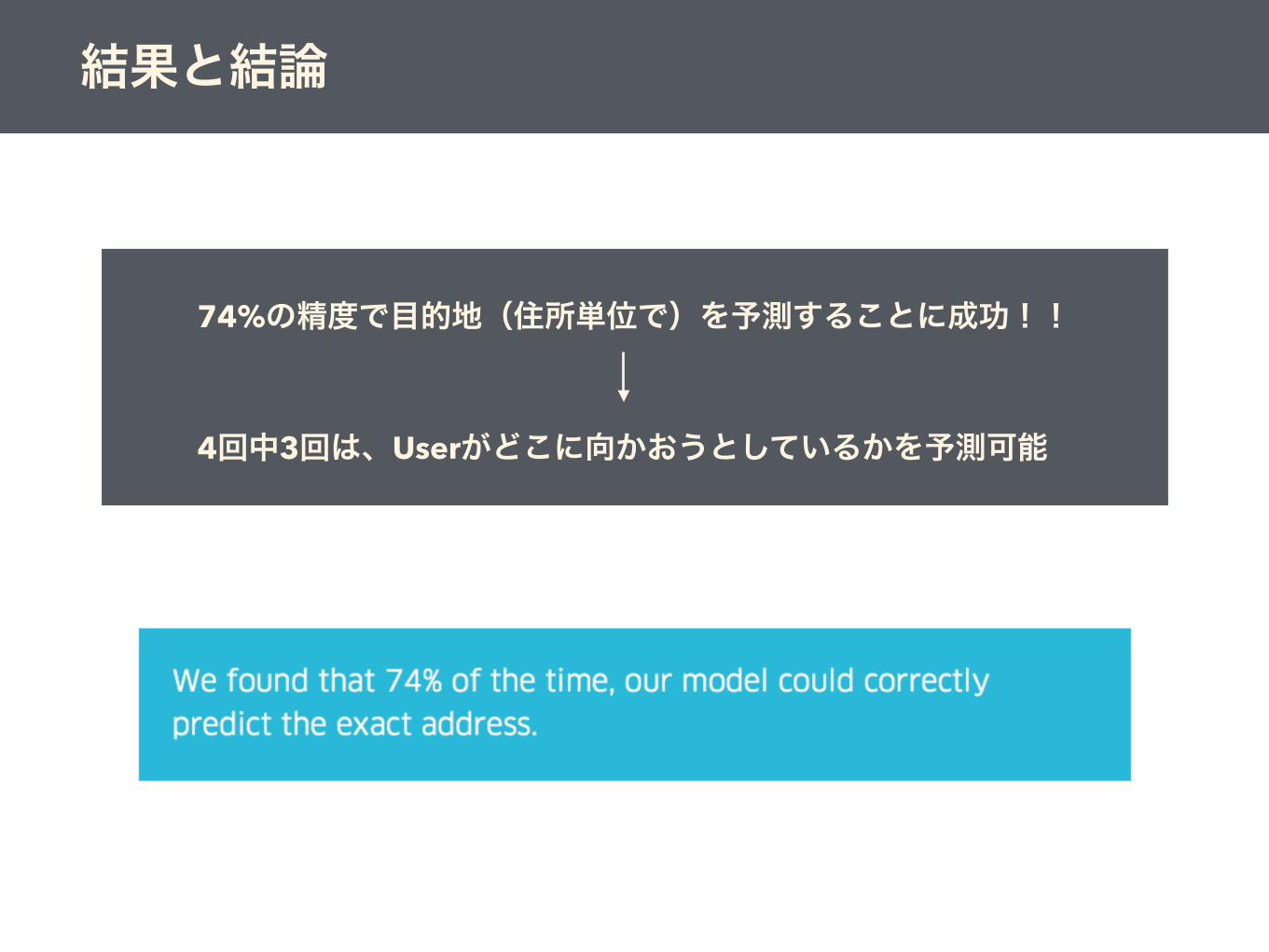
結果と結論
74%の精度で目的地(住所単位で)を予測することに成功!!
4回中3回は、Userがどこに向かおうとしているかを予測可能

結果と結論
1. 乗車するUserに対して、予測目的地の候補リスト(100m以内)を算出
2. 最大事後確率(MAP推定)の候補地を選択 3. その候補地の住所が真の目的地と一致したか
テスト方法
1. native baselineとsmart baselineの比較
1. native baseline候補地の中からランダムに選択し、40%の精度を達成
2. smart baseline候補地の中から最も近い候補地を選択し、44%の精度を達成
モデルの比較
精度の基準がいまいちわからない…
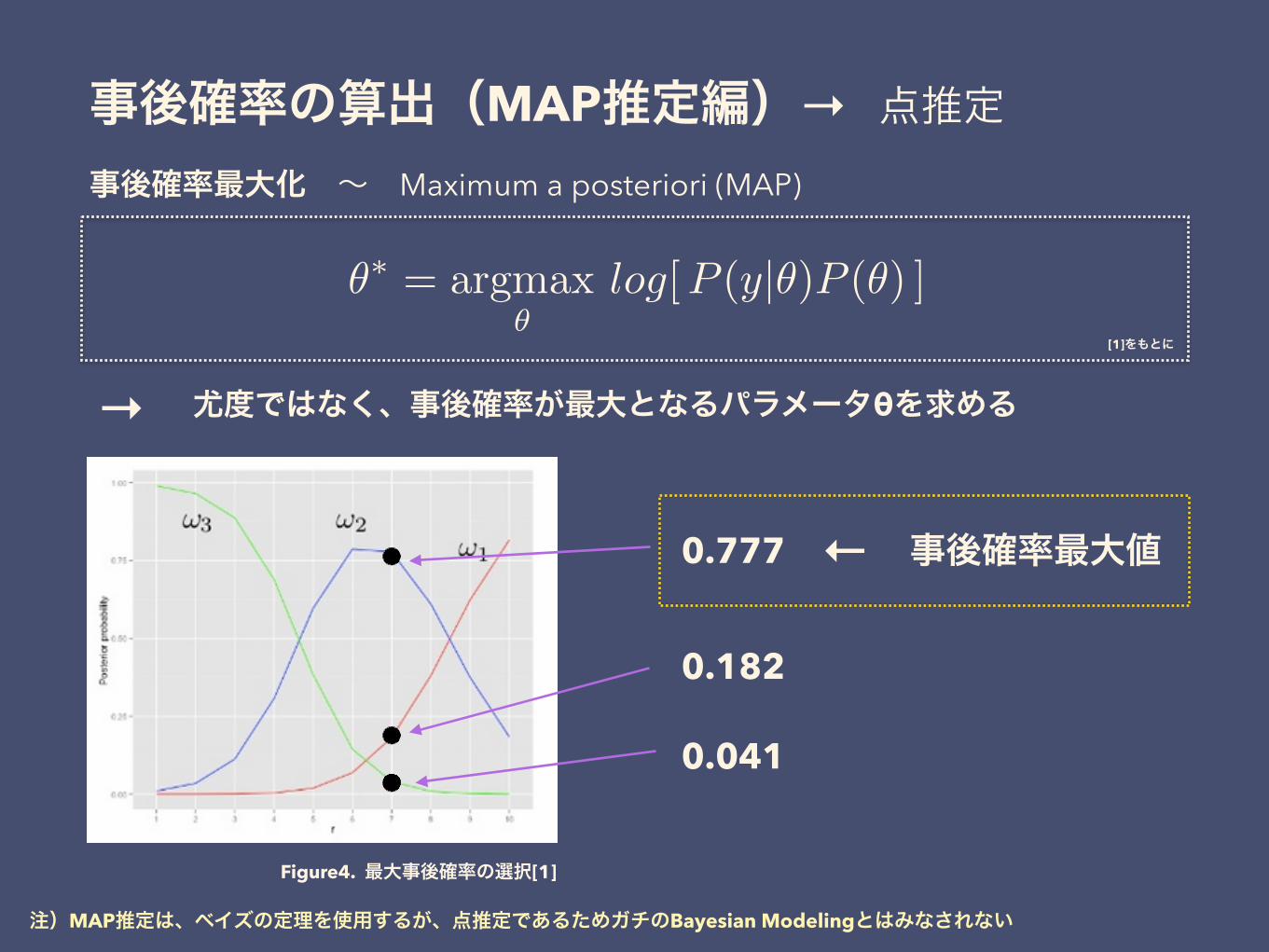
事後確率最大化 ~ Maximum a posteriori (MAP)
事後確率の算出(MAP推定編)
✓
⇤= argmax
✓log[P (y|✓)P (✓) ]
→
尤度ではなく、事後確率が最大となるパラメータθを求める
注)MAP推定は、ベイズの定理を使用するが、点推定であるためガチのBayesian Modelingとはみなされない
→
0.777
0.182
0.041
事後確率最大値←
点推定→
Figure4. 最大事後確率の選択[1]
[1]をもとに
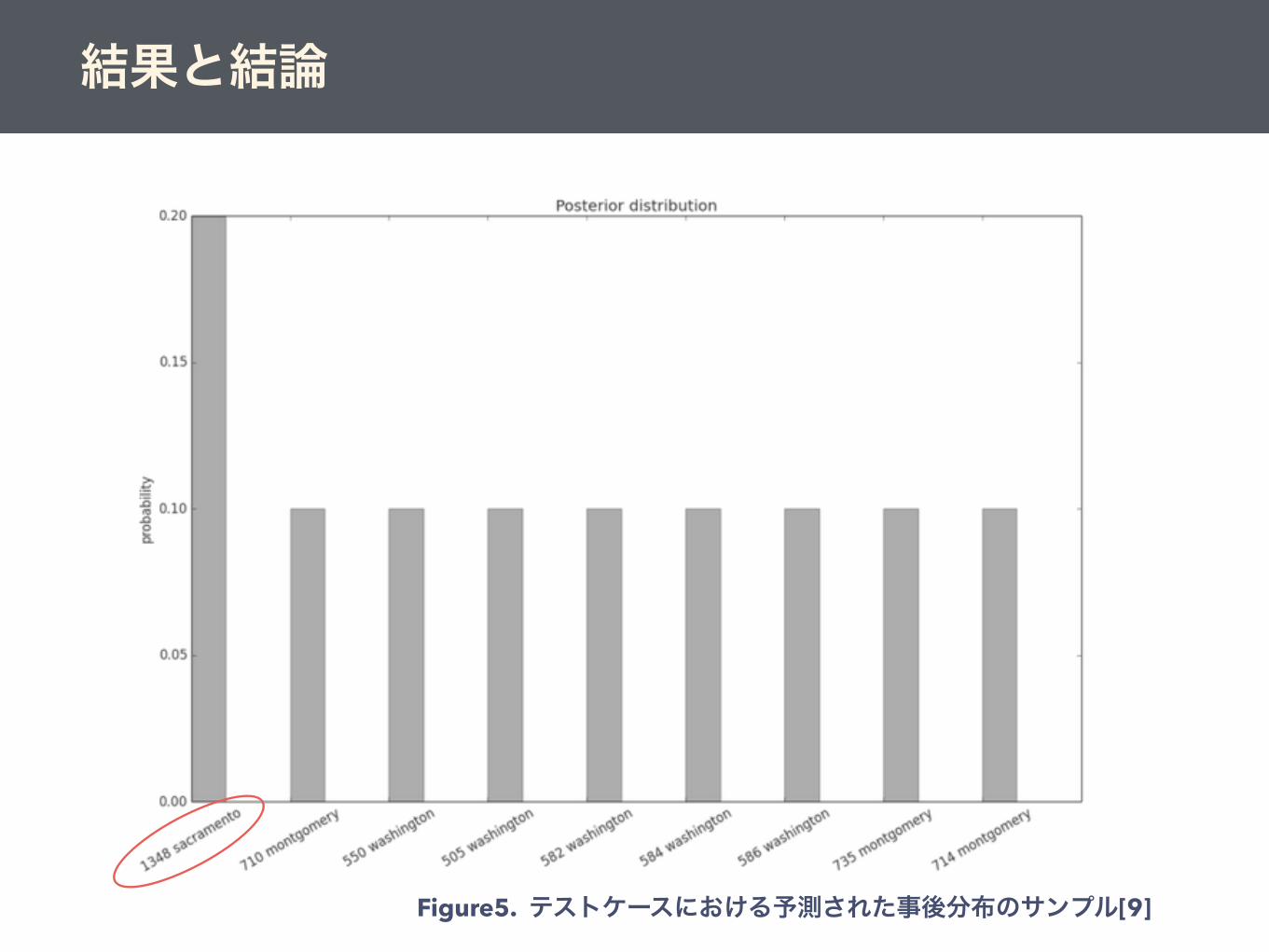
結果と結論
Figure5. テストケースにおける予測された事後分布のサンプル[9]

結果と結論1348 Sacramento Street, San Francisco
なんか、家!?

まとめ
1.目的地予測において、74%はなかなかの精度では…
2.一応ベイズモデリングではあるが、MAP推定である
3.多くのフィードバックを得た結果、少し情報が少ないため、
胡散臭さも否めない… 4.最終目的地が正であるかの判定はどのようにやってるのか疑問が残る 5.ビジネスインパクトがまだまだ小さい
位置情報関連のデータを使って、お金を生み出すって難しいね…

参考文献 & 参考URL
1. 石井健一 他,「続わかりやすいパターン認識 教師なし学習入門」, 旺文社, 2014/10/30
2. 鹿島久嗣, 「数理情報工学特論第一【機械学習とデータマイニング】回帰②」,
URL: (www.geocities.co.jp/Technopolis/5893/2-2.pdf) 3. 古谷知之,「ベイズ統計データ分析 -R&WinBUGS -」, 朝倉書店, 2008/09/15
4. 安道知寛,「ベイズ統計モデリング」, 朝倉書店, 2010/02/25
5. Allen B Downey,「Think Bayes - プログラマのためのベイズ統計入門」, O`Reilly,
2014/9 6. aidiary, “人口知能に関する断片録”, ‘最尤推定、MAP推定、ベイズ推定’,
URL: (http://aidiary.hatenablog.com/entry/20100404/1270359720), posted on 2010/04/04
7. noriume, “Sunny side up”, ‘従来の推定法とベイズ推定法の違い’,
URL: (http://norimune.net/708), posted on 2013/02/26 8. Masayuki Isobe, “数式をなるべく使わないベイズ推定入門”,
URL: (https://speakerdeck.com/chiral/shu-shi-wonarubekushi-wanaibeizutui-ding-ru-men), posted on 2013/2
9. Uber, “Making a Bayesian Model to Infer Uber Rider Destinations,”, URL: (http://blog.uber.com/passenger-destinations)