xml 資料庫管理系統 之緩衝區管理策略
DESCRIPTION
XML 資料庫管理系統 之緩衝區管理策略. Buffer Management in XML DBMSs. 指導老師:陳世穎 老師 學生 : 翁瑜璘、廖育伶、李昱諭 日期 : 2006/05/10. 大 綱. 簡 介 研究動機 研究目的 問題分析 分析模擬結果 結論與未來方向. XML 簡 介. XML (eXtensible Markup Language) XML 擁有 擴充性 -- 讓使用者自行定義文件架構、標籤 允許使用者自定標籤屬性 XML 文件屬於 樹狀結構 的文件 XPath 為 XML 文件查詢語言之基礎. - PowerPoint PPT PresentationTRANSCRIPT

1
XML 資料庫管理系統之緩衝區管理策略
Buffer Management in XML DBMSs
指導老師:陳世穎 老師學生 : 翁瑜璘、廖育伶、李昱諭日期 : 2006/05/10

2
大 綱
• 簡 介• 研究動機• 研究目的• 問題分析• 分析模擬結果• 結論與未來方向

3
XML 簡 介
XML (eXtensible Markup Language)
XML 擁有擴充性 -- 讓使用者自行定義文件架構、標籤 允許使用者自定標籤屬性 XML 文件屬於樹狀結構的文件 XPath 為 XML 文件查詢語言之基礎
a
b1 b2
c4c3c1 c2
a/b1/c1
4
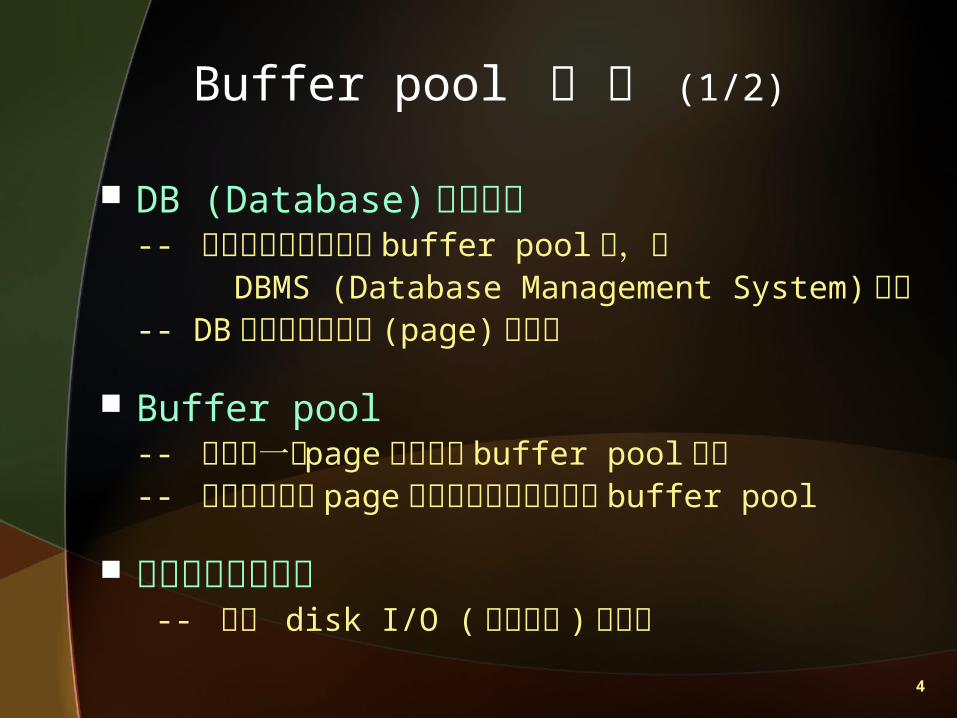
DB (Database) 存取方式-- 磁碟中取出資料放入 buffer pool 中,供
DBMS (Database Management System) 使用-- DB 的存取是以分頁 (page) 為單位
Buffer pool-- 尋找某一個 page 是否存在 buffer pool 之中-- 如果找不到此 page 則從磁碟中把它置換進 buffer pool
緩衝區管理的目的 -- 減少 disk I/O ( 磁碟存取 ) 的次數
Buffer pool 簡 介 (1/2)
5
Buffer pool 簡 介 (2/2)
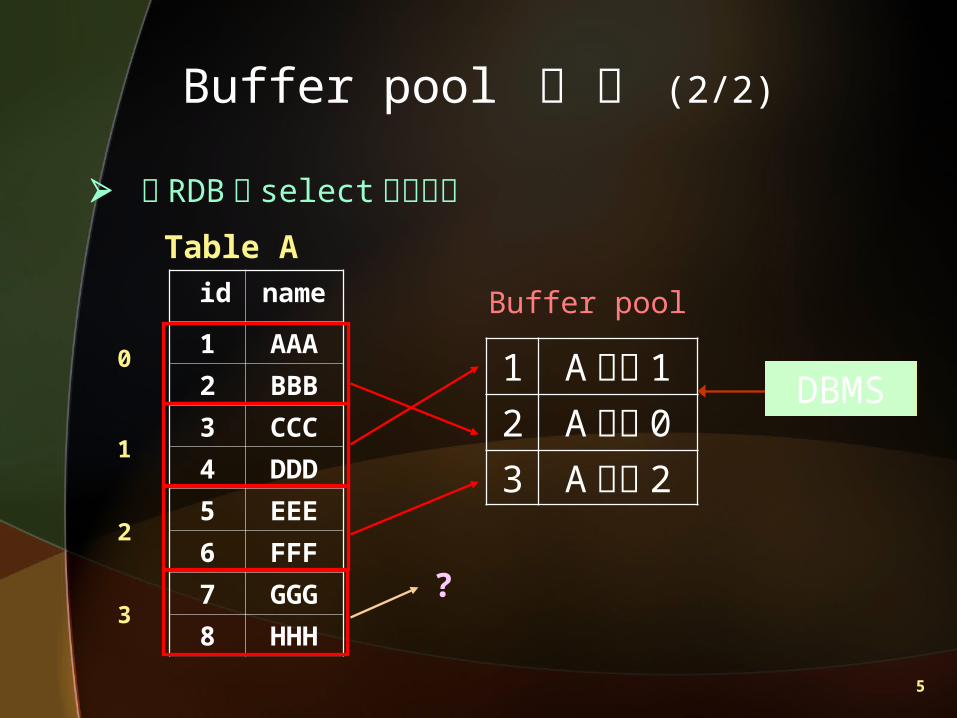
以 RDB 之 select 語法為例Table A
1 A 分頁 12 A 分頁 03 A 分頁 2
id name
1 AAA
2 BBB
3 CCC
4 DDD
5 EEE
6 FFF
7 GGG
8 HHH
0
1
2
Buffer pool
DBMS
3 ?
6
目前無適當的 XML 資料庫系統之緩衝區管理機制 -- XML 資料庫 -- 以 Berkeley DB XML 為研究對象 -- 其取代策略是使用 LRU 的取代方式 -- 「結合運算 (join operations) 為一成本高之運算」 for $a in doc("items.xml")/item_tuple let $b:= doc("bids.xml")/bid_tuple[itemno = $a/itemno]
討論 XML 資料庫系統中緩衝區管理的問題
研究動機
7
以 XPath 語言為基礎,分析 XML 中 XQuery 查詢語言的特性,並依據特性作分類。
依據分類,提出有效率的 XML 資料庫系統中緩衝區管理所需的配置策略與取代策略。
針對影響查詢效能最鉅的結合運算 (join operations) ,來做討論與分析,以提高系統的效能。
研究目的

8
RDB (Relational Database)-- Hot set Algorithm-- DBMIN Algorithm
OODB (Object-Oriented Database)-- 巡弋查詢在物件導向資料庫系統的
緩衝區管理。
相關研究
9
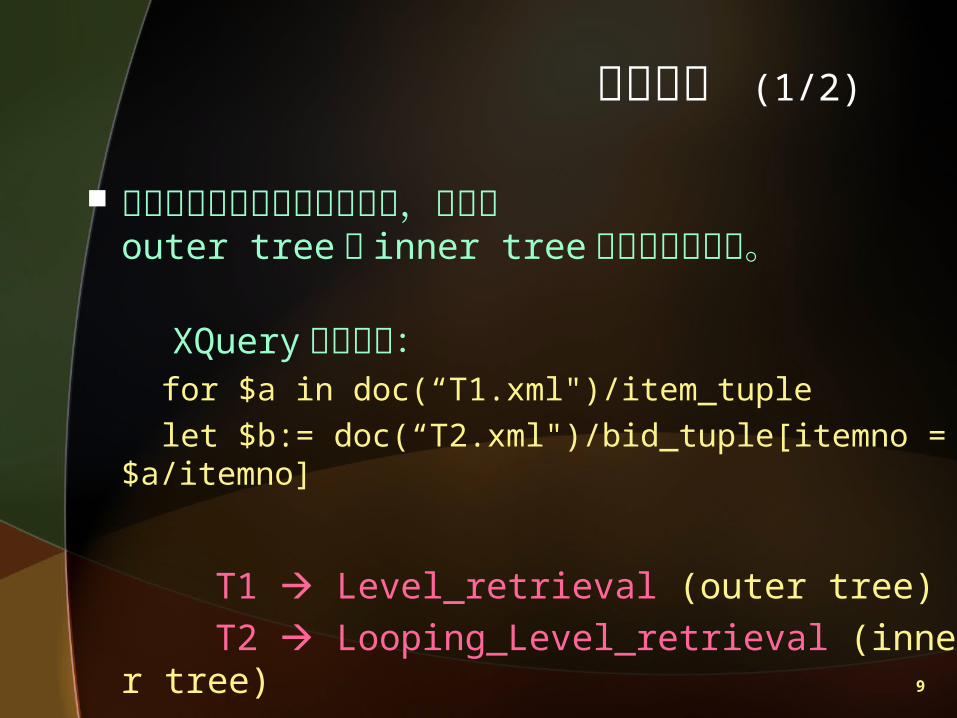
結合運算之查詢牽涉到的文件,可分成outer tree 與 inner tree 兩個部份來分析。
XQuery 敘述如下: for $a in doc(“T1.xml")/item_tuple let $b:= doc(“T2.xml")/bid_tuple[itemno = $a/item
no]
T1 Level_retrieval (outer tree) T2 Looping_Level_retrieval (inner tree)
問題分析 (1/2)
10
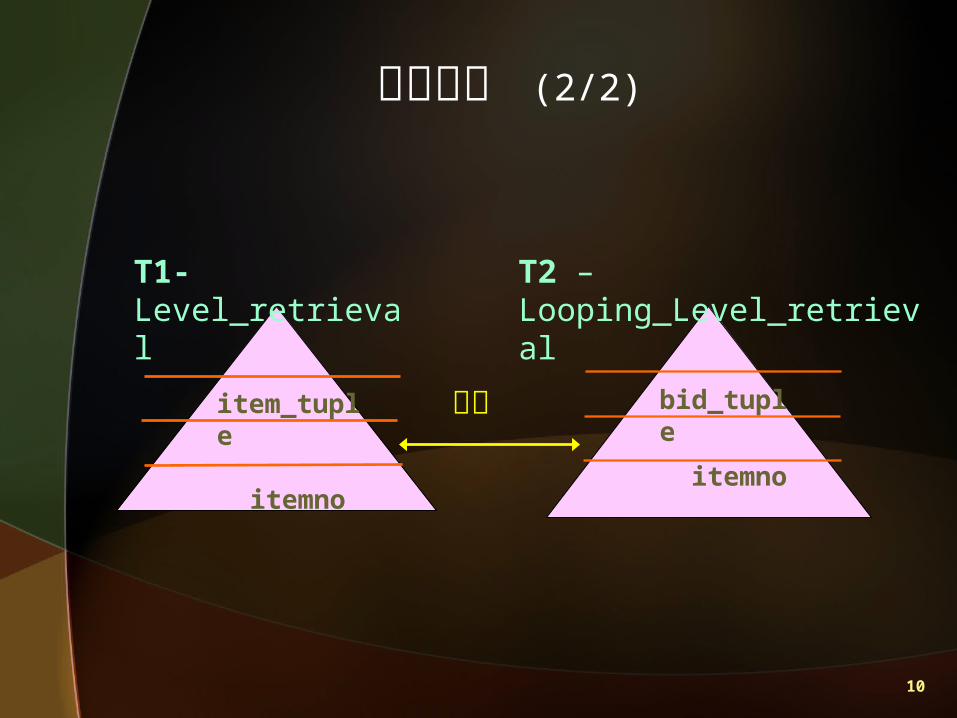
問題分析 (2/2)
item_tuple
itemno
比對 bid_tuple
itemno
T1- Level_retrieval T2 – Looping_Level_retrieval

11
Yao 公式
p
k
m
k
pmm
ppmkY
i
i
i
i
ii
iiiii
1),,('
iiii
iiii
pmmkif
pmmkif
/
/
1
0
h
i
輸入值: m -某一層資料數 p - m 筆資料分佈於 p 個 page k -欲存取資料筆數
輸出值: Y - 須要分配之 Buffer pool數

12
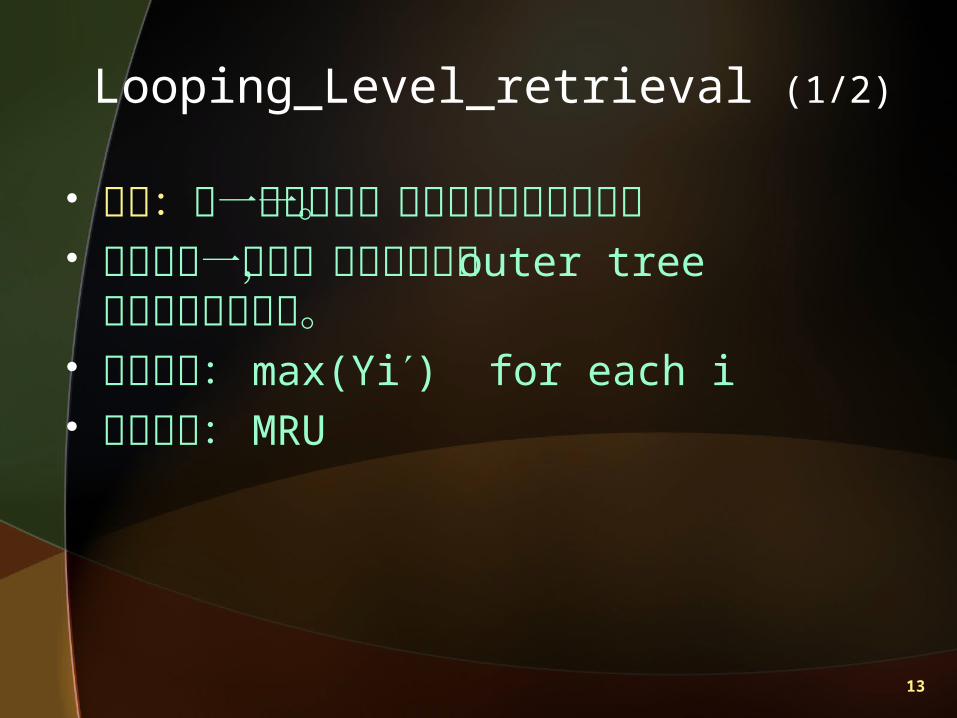
Level_retrieval
未作查詢部份
h 層
特性:節點經擷取過後即不須再取用。 配置策略: max(Yi) for each i 取代策略: Random
)'
C1(*)'(1'*
1
0 i
iiii
h
i YYkY
成本計算:成本計算:
C 為每一層之緩衝區配置大小
13
Looping_Level_retrieval (1/2)
特性:每一筆資料會一直不斷的做循環取出。 取出之每一資料,可以正確的與 outer tree中之資料比對完成。
配置策略: max(Yi) for each i 取代策略: MRU

14
Looping_Level_retrieval (2/2)
)))'_2
T2_C1(*)'_2_2(1'*_2(
)))'_2
T2_C1(*)'_2_2(1'*_2(*)_1(
))'_2
T2_C1(*)'_2_2(1'*_2(
1
0
j
ijwj
w
iwwww
i
iiii
h
i
YTYTkTYT
YTYTkTYTkT
YTYTkTYT
成本計算:成本計算:
做 h 層查詢所花費之成本
由 T1 而導致 T2 所須做 Looping 之花費成本
取出 T2 中比對成功之 J 元素
15
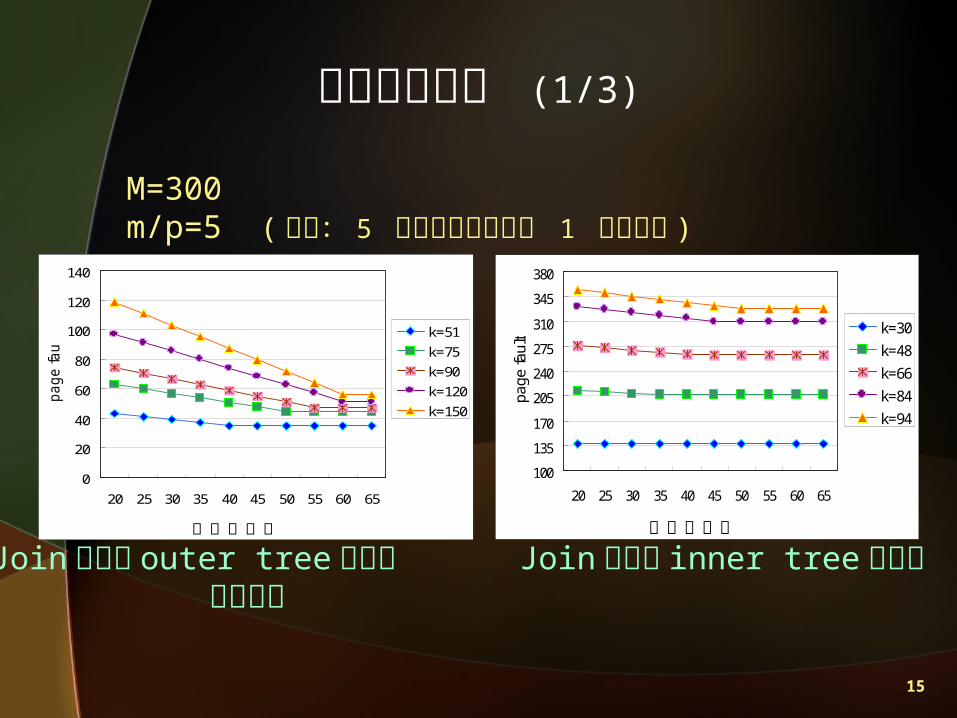
分析模擬結果 (1/3)
0
20
40
60
80
100
120
140
20 25 30 35 40 45 50 55 60 65
緩衝區數目
pa
ge
fa
ult
k=51
k=75
k=90
k=120
k=150
100
135
170
205
240
275
310
345
380
20 25 30 35 40 45 50 55 60 65
緩衝區數目pa
ge fa
ult
k=30
k=48
k=66
k=84
k=94
Join 運算中 outer tree 產生之 Join 運算中 inner tree 產生之 頁失誤數 頁
失誤數
M=300 m/p=5 ( 比例: 5 個節點資料散佈於 1 個磁碟中 )
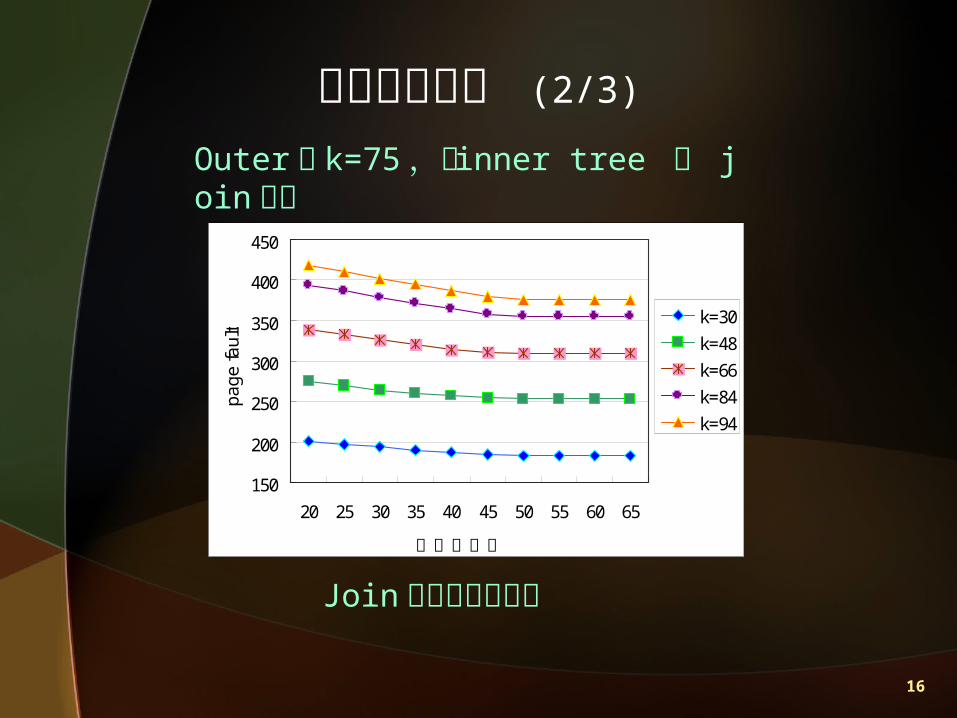
16
分析模擬結果 (2/3)
Join 運算之預估結果
Outer 之 k=75 ,與 inner tree 做 join運算
150
200
250
300
350
400
450
20 25 30 35 40 45 50 55 60 65
緩衝區數目
pa
ge
fau
lt
k=30
k=48
k=66
k=84
k=94
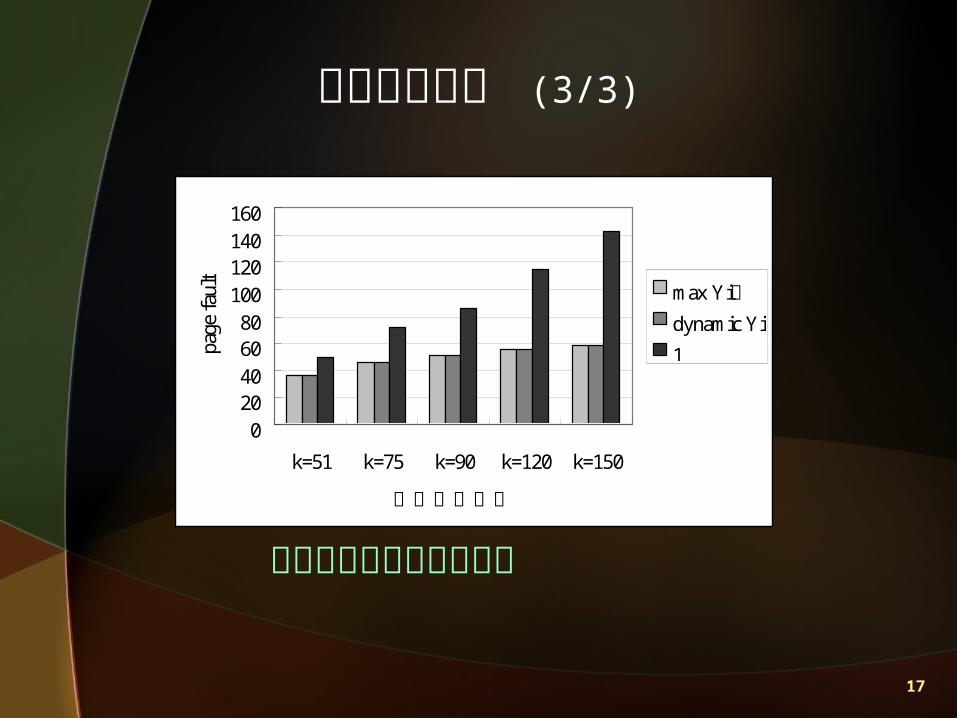
17
分析模擬結果 (3/3)
三種配置策略之結果比較
020406080
100120140160
k=51 k=75 k=90 k=120 k=150
存取之資料量
page
faul
t
max Yi
dynamic Yi
1
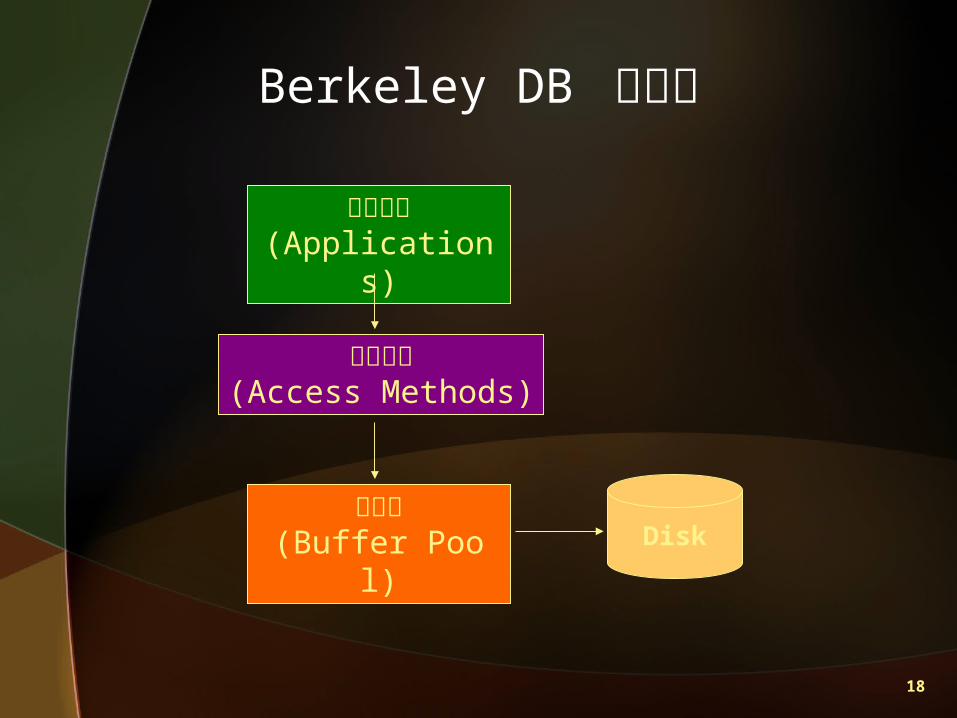
18
Berkeley DB 架構圖
應用程式(Applications)
存取函式(Access Methods)
暫存區(Buffer Pool) Disk
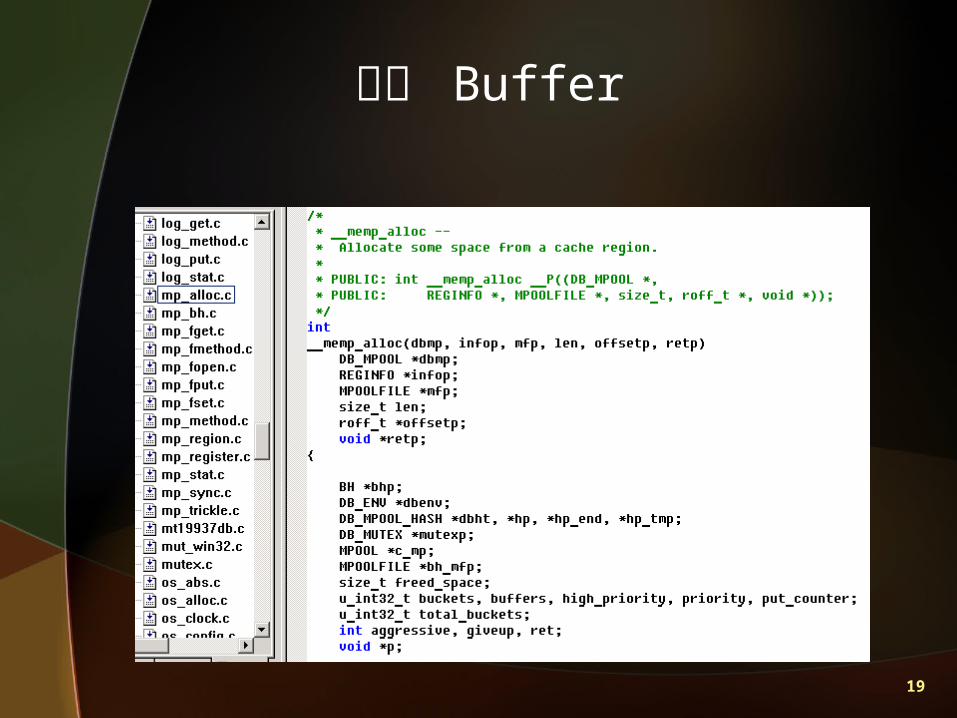
19
配置 Buffer
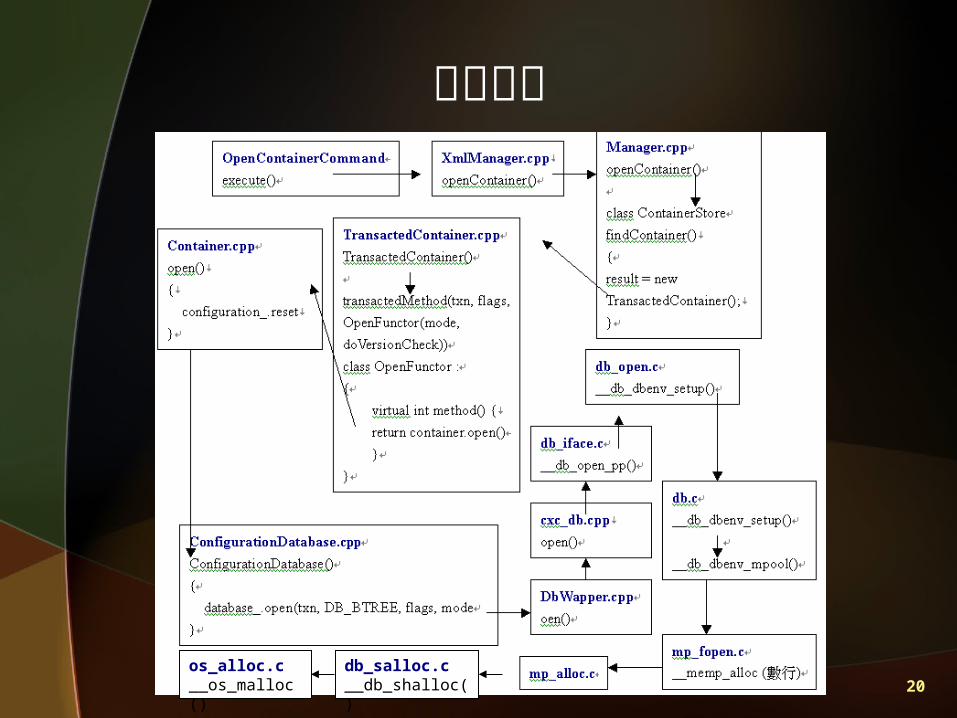
20
查詢流程
os_alloc.c__os_malloc()
db_salloc.c__db_shalloc()

21
結 論
分析了 XML 資料庫在做查詢時,最主要的兩種查詢方式。
使用 Yao 公式算出須要建立多大的緩衝區提供暫存並建立成本分析數學模式。

22
未來方向
分析與設計其他 XQuery 中所需的緩衝區管理機制。
利用本研究之成本分析結果設計查詢最佳化之決策。

23
報告完畢謝謝

24
Hot Set Algorithm
• hot set: 一組有循環行為的 page
• hot set in memory (efficient vs. page faults) buffer pool 的大小足夠持有 hot set buffer pool 的大小不足以持有 hot set
• hot points :在 efficient 和 page faults 間取得平衡
• Buffer pool 配置大小 (hot points)
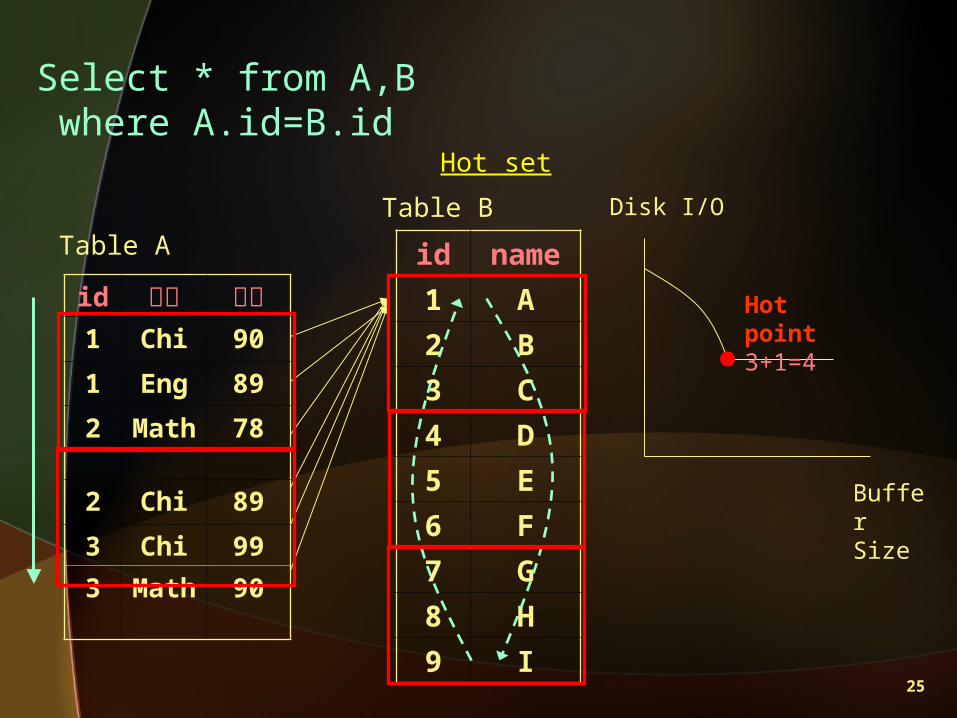
25
Select * from A,Bwhere A.id=B.id
id 科目 成績1 Chi 90
1 Eng 89
2 Math
78
2 Chi 89
3 Chi 99
3 Math
90
id name
1 A
2 B
3 C
4 D
5 E
6 F
7 G
8 H
9 I
Hot set
Table ATable B Disk I/O
Buffer Size
Hot point3+1=4
26
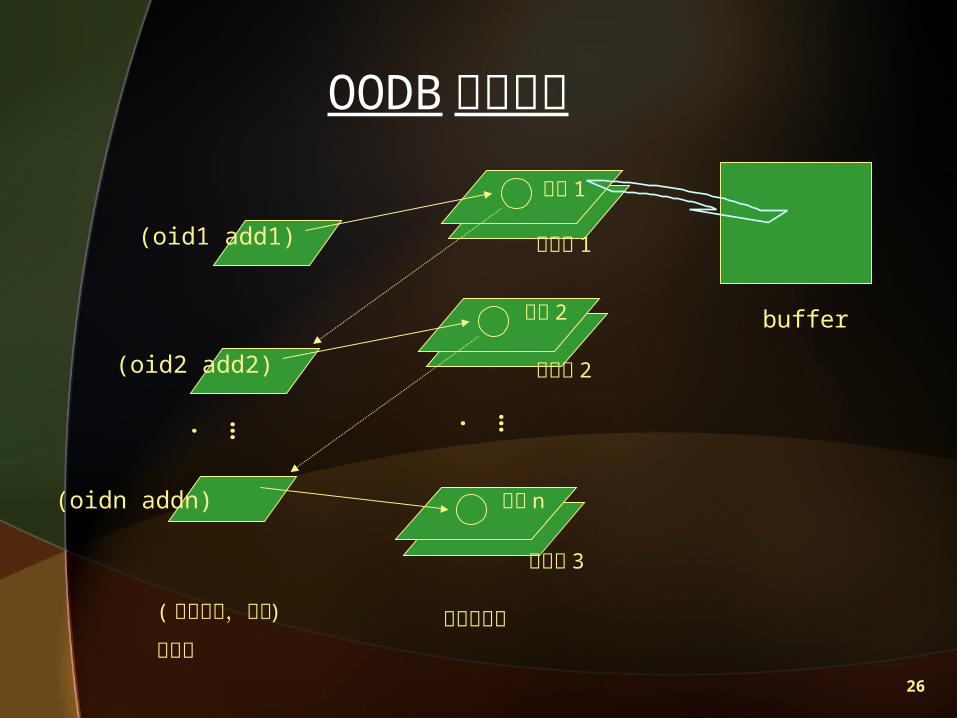
(oid1 add1)
(oid2 add2)
(oidn addn)
物件 2
物件 n
buffer
磁碟頁 3
磁碟頁 1
磁碟頁 2
物件 1
…. ….
OODB 存取模式
( 物件指標,位址 )
對應區物件存放區

27
OODBMS巡弋查詢在物件導向資料庫系統的緩衝區管理
•直接法 -- 直接查詢
•區塊法 --先查詢 Buffer 裡有無要查詢的資料
•索引法 --透過標籤或屬性值做索引查詢

28
Berkeley DB 之應用
• Amazon.com uses Berkeley DB as a fast cache for several critical parts of its customer-facing e-commerce website.
• Google uses Berkeley DB High Availability for Google Accounts.
• Motorola uses Berkeley DB to track mobile units in its wireless radio network products.
29
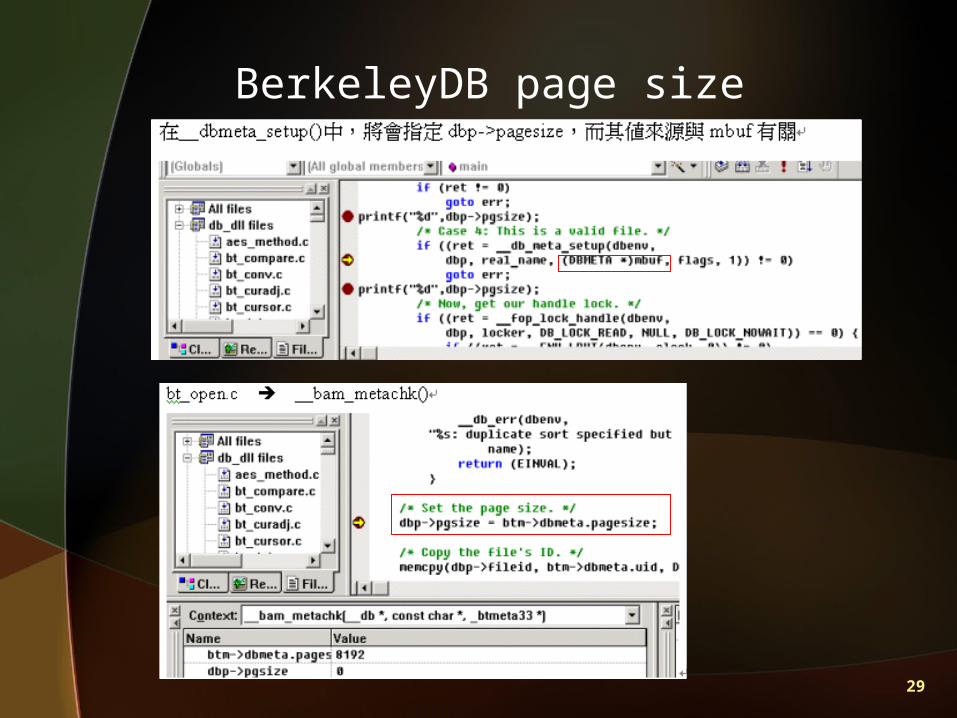
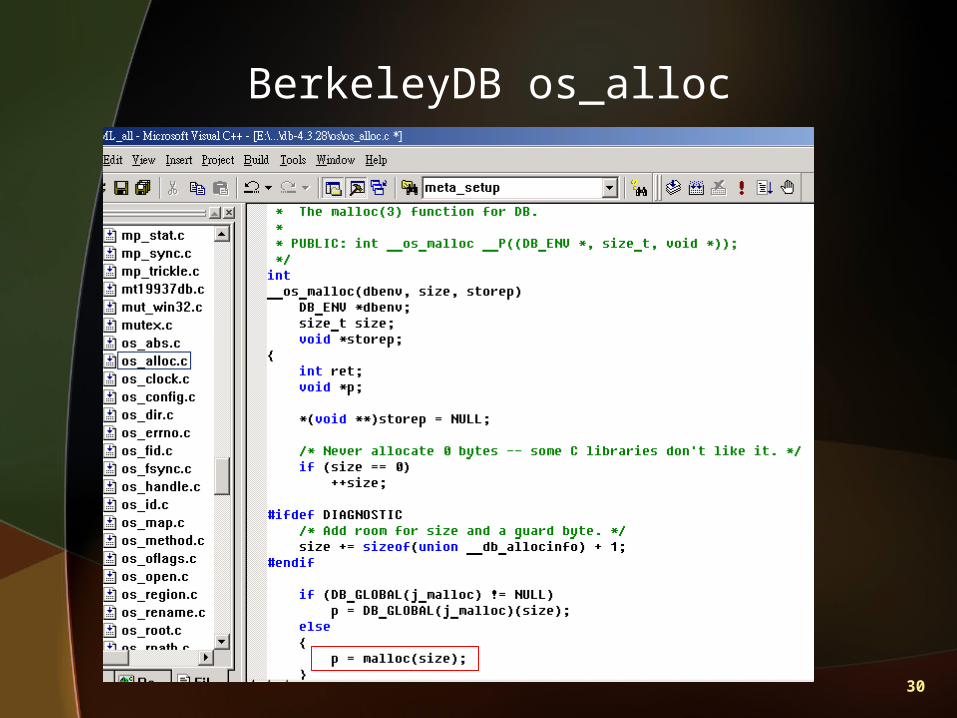
BerkeleyDB page size
30
BerkeleyDB os_alloc