第六章 动态经济模型:自回归模型和分布滞后模型
DESCRIPTION
第六章 动态经济模型:自回归模型和分布滞后模型. 第一节 引言 很多经济过程的实现需要若干周期的时间,因此需要在我们的计量经济模型中引入一个时间维,通常的作法是将滞后经济变量引入模型中。让我们用两个简单的例子说明之。 例 1 . Y t = α+βX t-1 + u t , t = 1,2, … ,n 本例中 Y 的现期值与 X 的一期滞后值相联系,比较一般的情况是: Y t = α+β 0 X t +β 1 X t-1 + …… +β s X t-s + u t , - PowerPoint PPT PresentationTRANSCRIPT

1
第六章 动态经济模型:自回归模型和分布滞后模型

2
第一节 引言
很多经济过程的实现需要若干周期的时间,因此需要在我们的计量经济模型中引入一个时间维,通常的作法是将滞后经济变量引入模型中。让我们用两个简单的例子说明之。例 1 . Yt = α+βXt-1 + ut, t = 1,2,…,n 本例中 Y 的现期值与 X 的一期滞后值相联系,比较一般的情况是: Yt = α+β0Xt +β1Xt-1 +……+βsXt-s + ut, t = 1,2,…,n即 Y 的现期值不仅依赖于 X 的现期值,而且依赖于X 的若干期滞后值。这类模型称为分布滞后模型,因为 X 变量的影响分布于若干周期。

3
例 2 . Yt = α+βYt-1 + ut, t = 1,2,…,n
本例中 Y 的现期值与它自身的一期滞后值相联系,即依赖于它的过去值。一般情况可能是:
Yt = f (Yt-1, Yt-2, … , X2t, X3t, … )
即 Y 的现期值依赖于它自身若干期的滞后值,还依赖于其它解释变量。
在本例中,滞后的因变量(内生变量)作为解释变量出现在方程的右端。这种包含了内生变量滞后项的模型称为自回归模型。

4
动态经济模型
我们上面列举了模型中包含滞后经济变量的两种情况。第一种是仅包含滞后外生变量的模型,第二种是包含滞后内生变量的模型。在两种情况下,都通过一种滞后结构将时间维引入了模型,即实现了动态过程的构模。

5
第二节 分布滞后模型的估计
我们在上一节引入了分布滞后模型:
Yt =α+β0Xt +β1Xt-1 +……+βsXt-s + ut (1)
在这类模型中,由于在 X 和它的若干期滞后之间往往存在数据的高度相关,从而导致严重多重共线性问题。因此,分布滞后模型极少按( 1 )式这样的一般形式被估计。通常采用对模型各系数 βj 施加某种先验的约束条件的方法来减少待估计的独立参数的数目,从而避免多重共线性问题,或至少将其影响减至最小。这方面最著名的两种方法是科克方法和阿尔蒙方法。下面首先介绍科克方法。

6
一、科克分布滞后模型科克方法简单地假定解释变量的各滞后值的系数
(有时称为权数)按几何级数递减,即:
Yt =α+βXt+βλXt-1 +βλ2Xt-2 +…+ ut (2) 其中 0<λ<1
这实际上是假设无限滞后分布,由于 0<λ<1 , X的逐次滞后值对 Y 的影响是逐渐递减的。 ( 2 )式中仅有三个参数: α 、 β 和 λ 。但直接估计( 2 )式是不可能的。这是因为,首先,估计无限多个系数是不可行的。其次,从回归结果中很可能得不到 β 和 λ 的唯一估计值。幸运的是,我们有同时解决这两方面问题的方法。

7
二 . 非线性最小二乘法 非线性最小二乘法实际上是一种格点搜索法。首先定义 λ 的范围(如 0-1 ),指定一个步长(如 0.01 ),然后每次增加一个步长,依次考虑 0.01,0.02,……0.99 。步长越小,结果精确度越高,当然计算的时间也越长。由于目前计算机速度已不是个问题,你可以很容易达到你所要求的精度。

8
( 1 ) 对于 λ 的每个值,计算Zt=Xt+λXt-1+λ2Xt-2+…+λPXt-P (3)
P 的选择准则是, λP 充分小,使得 X 的 P阶以后滞后值对 Z 无显著影响。
( 2 )然后回归下面的方程: Yt =α+βZt + ut (4)
( 3 ) 对 λ 的所有取值重复执行上述步骤,选择回归
( 4 )式产生最高的 R2 的 λ 值。 α 和 β 的估计值即为该回归所得到的估计值。
非线性最小二乘法步骤

9
三、科克变换法 回到科克模型: Yt =α+βXt +βλXt-1 +βλ2Xt-2 +…+ ut (2)
( 2 ) - ( 5 ),得 Yt-λYt-1 =α(1-λ)+βXt + ut-λut-1 (6)
两端乘以 λ ,得:λYt-1 =λα+βλXt-1+βλ2Xt-2 +βλ3Xt-3 +…+λut-1 (5)
第二种方法是采用科克变换,( 2 )式两端取一期滞后,得: Yt-1 =α+βXt-1 +βλXt-2 +βλ2Xt-3 +…+ ut-1

10
所有的 X 滞后项都消掉了,因此 Yt =α(1-λ)+βXt + λYt-1 + ut-λut-1 (7)
( 7 )式称为自回归模型,因为因变量的滞后作为解释变量出现在方程右边。这一形式使得我们可以很容易分析该模型的短期(即期)和长期动态特性(短期乘数和长期乘数)。

11
短期乘数和长期乘数
在短期内(即期), Yt-1 可以认为是固定的, X 的变动对 Y 的影响为 β (短期乘数为 β )。从长期看,在忽略扰动项的情况下,如果 Xt 趋向于某一均衡水平 则Yt 和 Yt-1 也将趋向于某一均衡水平
(8)
这意味着 ( 9 ) 因此, X 对 Y 的长期影响(长期乘数)为 β/ ( 1-λ),若 λ 位于 0 和 1 之间,则 β/ ( 1-λ ) >β ,即长期影响大于短期影响。
,X
,Y
YXY )1(
XY
1

12
从实践的观点来看,科克变换模型很有吸引力,一个 OLS 回归就可得到 α 、 β 和 λ 的估计值( α的估计值是( 7 )式中的常数项除以 1 减 Yt-1 的系数估计值)。这显然比前面介绍的格点搜索法要省时很多,大大简化了计算。
可是,科克变换后模型的扰动项为 ut-λut-1 ,这带来了自相关问题(这种扰动项称为一阶移动平均扰动项)。并且,解释变量中包含了 Yt-1 ,它是一个随机变量,从而使得高斯—马尔柯夫定理的解释变量非随机的条件不成立。此问题的存在使得 OLS估计量是一个有偏和不一致估计量。这可以说是按下葫芦起了瓢。我们将在第四节中讨论科克模型的估计问题。

13
第三节 部分调整模型和适应预期模型
有两个著名的动态经济模型,它们最终可化成与上一节( 2 )式相同的几何分布滞后形式,因此都是科克类型的模型。它们是:
部分调整模型( Partial adjustment model ) 适应预期模型( Adaptive expectations model )

14
一、部分调整模型 在部分调整模型中,假设行为方程决定的是因变量的理想值( desired value )或目标值 Yt
* ,而不是其实际值 Yt :
Yt* =α+βXt+ut ( 1 )
由于 Yt* 不能直接观测,因而采用 “部分调整假
说” 确定之,即假定因变量的实际变动( Yt–Yt-1
) , 与其理想值和前期值之间的差异( Yt* –Yt-1 )
成正比:
Yt – Yt-1=δ ( Yt* - Yt-1 ) (2 )
0≤δ≤1, δ 称为调整系数。

15
从( 3 )式可看出, Yt 是现期理想值和前期实际值的加权平均。 δ 的值越高,调整过程越快。如果δ=1 ,则 Yt=Yt
*, 在一期内实现全调整。若 δ=0 ,则根本不作调整。
( 2 )式 Yt – Yt-1=δ ( Yt
* - Yt-1 ) (2 )可改写为:
Yt =δYt* +(1-δ) Yt-1 (3 )

16
(1 )式 Yt* =α+βXt+ut 代入( 3 )式
Yt =δYt* +(1-δ) Yt-1 ,得到
Yt=αδ+βδXt+(1-δ)Yt-1+δut ( 4 )
用此模型可估计出 α 、 β 和 δ 的值。
与科克模型类似,这里也存在解释变量为随机变量的问题( Yt-1 ) . 区别是科克模型中 ,Yt-1 与扰动项
( ut-λut-1 )同期相关,而部分调整模型不存在同期相关,因为 Vt 和 ut 都在 Yt-1 决定之后才产生。在这种情况下,用 OLS 法估计,得到的参数估计量是一个一致的估计量(渐近无偏和渐近有效)。

17
不难看出,( 4 )式 Yt=αδ+βδXt+(1-δ)Yt-1+δut ( 4 )与变换后的科克模型的形式相似,我们也不难通过对( 4 )式中 Yt-1 进行一系列的置换化为几何分布滞后的形式。( 4 )式两端取一期滞后,得 ( 5 )
将此式代入( 4 )式,得到(为简单起见,省略扰动项): ( 6 )
1211 )1( tttt uYXY
22
1 )1()1()]1(1[ tttt YXXY

18
我们可以用同样的方法置换 Yt-2 ,以及随后的 Yt-3,Yt-4,…, 直至无穷,结果是将 Yt 表示为 X 的当前值和滞后值的一个滞后结构,系数为科克形式的几何递减权数,具体形式为:
ttttt XXXY ......])1()1([ 22
1
......)1()1( 22
1 tttt uuu
) 7( ...] [22
1t t t t tX X X Y
与上节( 2 )式形式完全一样。
令 λ=1-δ , β’=βδ ,则得
其中

19
例 林特纳( lintner )的股息调整模型 J . Lintner 建立的股息调整模型是应用部分调整模型的一个著名实例。 在对公司股息行为的研究中, Lintner 发现,所有股份公司都将其税后利润的一部分以股息的形式分配给股东,其余部分则用作投资。 当利润增加时,股息一般也增加,但通常不会将增加的利润都用作股息分配,这是因为:( 1 )利润的增加可能是暂时的;( 2 )可能有很好的投资机会。 为了建立一个描述这种行为的模型, Lintner 假设各公司有一个长期的目标派息率 γ ,理想的股息Dt
*
与现期利润Πt 有关,其关系为
Dt*=γΠt
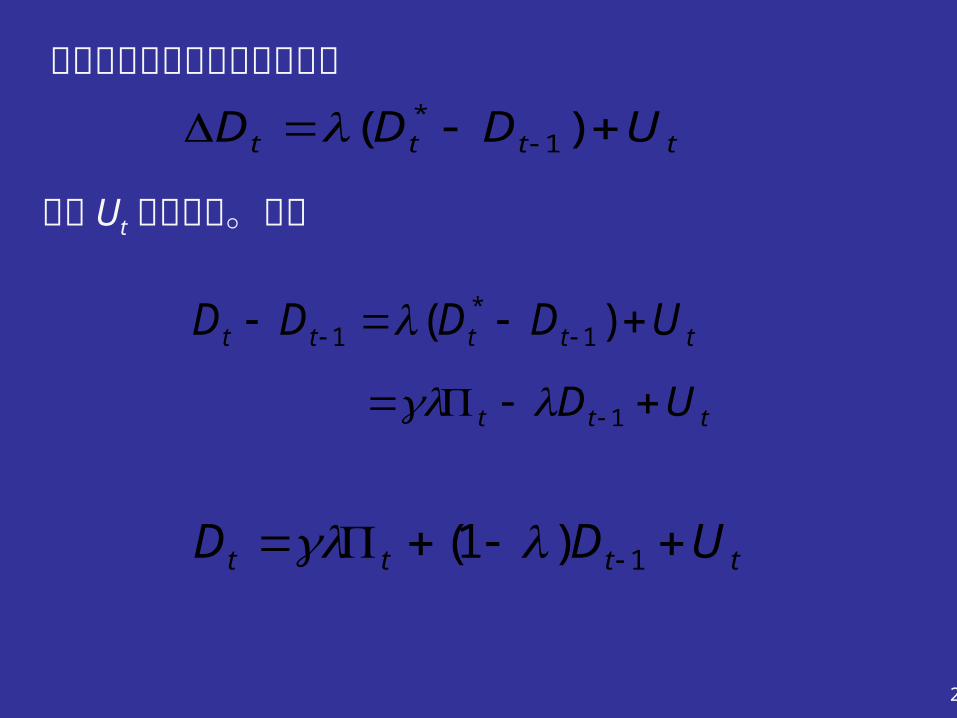
20
而实际股息服从部分调整机制
tttt UDDD )( 1*
ttttt UDDDD )( 1*
1
ttt UD 1
tttt UDD 1)1(
其中 Ut 为扰动项。因此

21
使用美国公司部门 1918—1941 年数据,得到如下回归结果:
170.015.03.352ˆ ttt DD
各系数在 1%显著水平下都显著异于 0 。
从回归结果可知,( 1-λ )的估计值为 0.70 ,因而调整系数 λ 的估计值为 0.30 ,即调整速度为 0.30 。由于 Πt 的系数是 γλ 的估计值,除以 0.30 ,则得到长期派息率( γ )的估计值为 0.50 。
22
. 二、适应预期模型 1 、在模型中考虑预期的重要性 预期( expectation )的构模往往是应用经济学家最重要和最困难的任务,在宏观经济学中更是如此。投资,储蓄等都是对有关未来的预期很敏感的。如果政府实施一项扩张政策,这将影响工商界人士有关未来经济总状况的预期,特别是关于盈利能力的预期,因而影响他们的计划,不管利率如何变化。
例如,如果存在很可观的失业,则政府支出增加被认为是有益的,并将刺激投资。另一方面,如果经济正接近充分就业,则政府的扩张政策被认为将导致通货膨胀,结果是工商界的信心受挫,投资下降。

23
2 、适应预期模型 由上所述,可知在模型中考虑预期的重要性。不幸的是,在宏观经济领域,不存在令人满意的直接计量预期的方法。作为一种权宜之计,某些模型使用一种称为适应预期过程的间接方法。
)( 11ett
et
et XXXX (0≤γ≤1) ( 8 )
适应预期过程是一种简单的学习过程,其机制是,在每一时期中,将所涉及变量的当前观测值与以前所预期的值相比较,如果实际观测值大,则将预期值向上调整,如果实际发生值小,则预期值向下调整。调整的幅度是其预测误差的一个分数,即:

24
( 8 )式可写成 (0≤γ≤1) ( 9 ) 上式表明, X 的预期值是其当前实际值和先前预期值的加权平均。 γ 的值越大,预期值向 X 的实际发生值调整的速度越快。
ett
et XXX 1)1(
适应预期和部分调整之间当然有很多明显的类似之处,可是从适应预期模型的最初形式导出仅包含可观测变量的模型(可操作模型)不象在部分调整模型的情况那么简单。

25
假设你认为因变量 Yt 与某个解释变量 X 的预期值 Xte 有关,则可写出模型 )10(t
ett uXY
)11()1( 211ett
et XXX
这里,我们无法直接用( 8 )或( 9 )代入( 10)来解决这个问题,因为 Xt
e 无法表示成仅由可观测变量组成的表达式。可是,如果( 9 )式成立,则对于 t-1 期,它也成立,即:
若假定 Xte 用适应预期机制确定,这就是一个适应
预期模型,其中解释变量 Xte 是不可观测的,必须用
可观测变量取代之。

26
将( 11 )式
代入( 9 )式 ,得
)12()1()1( 22
1ettt
et XXXX
,2etX
)13(...])1()1([ 22
1 tttet XXXX
我们可以用类似的方法,消掉( 12 )式中的 这一过程可无限重复下去,最后得到:
ett
et XXX 211 )1(
ett
et XXX 1)1(

27
将( 13 )式
代入( 10 )式 ,得
))1(()1( 11 ttttt uuYXY
) 14 ( ...] ) 1( ) 1( [22
1t t t t tu X X X Y
...])1()1([ 22
1 tttet XXXX
tett uXY
不难看出,此式与上节中科克分布( 2 )的形式相同。该模型的参数可用上一节介绍的非线性方法估计。对( 14 )式施加科克变换,将简化模型的数学形式,但由于与科克模型同样的理由,不宜直接用 OLS 法估计。施加科克变换的适应预期模型为:

28
3 、例子: Friedman 的持久收入假说 1957 年,弗里德曼对传统消费函数提出批评,提出了自己的消费模型。在他的模型中,第 i 个消费者在第 t 期的消费与持久性收入( permanent income ) Yit
P 有关,而不是与当期的收入 Yit 有关。持久性收入是一种长期收入概念,它表示在考虑了各种可能的波动的情况下,某人大体上可以依靠的收入。
持久收入是根据最近的经验和有关未来的预期而主观决定的,由于是主观的,因而无法直接计量。任何一年中的实际收入可能高于或低于持久收入,取决于该年中的特别因素。实际收入和持久收入之差称为暂时性收入 (transitory income) ,记为 Yit
T ,我们有:

29
他以同样方式区分了持久性消费,实际消费和暂时性消费的概念。持久性消费是与持久性收入的水平相对应的消费水平。实际消费可能与持久消费有差异,原因是出现了某些特殊的未预料到的情况(如未预料到的医疗费用),或者是冲动性购买的结果。二者之差称为暂时性消费,记为 Cit
T:
)16(Tit
pitit CCC
)15(Tit
pitit YYY
YitT 和 Cit
T 被假定为具有 0 均值和常数方差的随机变量,它们相互独立,且与 Yit
P 和 CitP 无关。弗里
德曼进一步假定持久消费与持久收入成正比:

30
上式中持久收入 YitP 不可观测,为解决这一问题,
弗里德曼假设持久收入遵从适应预期过程,也就是说,如果某人的现期收入高于(或低于)其先前的持久收入概念,则他将增加(或减少)后者,增加(或减少)的幅度是二者之差乘以 λ :
)17(Pit
Pit YC
)18()( 1Pitit
Pit YYY
λ 一般位于 0 和 1 之间。因此人们在实际收入增加时将调整他们的持久收入概念,但不会做全额调整,这是因为认识到实际收入的变动或许有一部分是由于收入的暂时分量变动的结果。

31
( 18 )式可改写为:
即 此式表明,在第 t 年,消费者将持久收入估计为实际收入和以前的持久性收入概念的加权平均。如果 λ 接近于 1 ,则该消费者将绝大部分权重给了实际收入, YP 迅速向 Y 调整,若 λ 接近 0,则很小部分权重给了实际收入,调整过程将很缓慢。
)19()( 11Pitit
Pit
Pit YYYY
)20()1( 1Pitit
Pit YYY

32
至此,我们得到了实际消费和持久收入之间的关系式,即消费函数的弗里德曼模型。式中 Cit
T 起着扰动项的作用。
)21(Tit
Pitit CYC
将( 17 )式
代入( 16 )式
我们有:
)17(Pit
Pit YC
)16(Tit
pitit CCC

33
为了估计这个模型,弗里德曼用( 20 )式(适应预期机制)将持久收入表示成实际收入的现期值和各期滞后值:
Pitit
Pit YYY 1)1(
Pititit YYY 2
21 )1()1(
)22()1()1()1( 3
32
21 itititit YYYY
若 0<λ<1 ,这就是一个合理的假设,现期收入的权数最大,上一年次之,随着时间往回推,影响逐年衰减。最后,权数变得非常之小,使得无需考虑该年之前那些过去值。

34
弗里德曼采用的估计方法是我们前面介绍过的非线性方法,即首先试位于 0 和 1 区间内的大量 λ 值,为每个 λ 值计算相应的持久收入时间序列,然后用消费对每个持久收入数据集回归,根据 R2 选出最佳 λ 值。
为了与传统消费函数相比较,弗里德曼用美国 1905—1951 (战争期间除外)的人均实际消费和人均可支配收入数据进行了回归。在格点搜索计算中,他将持久收入计算为现期收入和 16 个滞后收入项的加权平均值, λ 的最优值为 0.37 ,得到消费函数中 β 的估计值为 0.88 。

35
第四节 自回归模型的估计
上两节中,我们讨论了下列三个模型:
科克模型
部分调整模型
适应预期模型
)1()()1( 11 ttttt uuYXY
)2()1( 1 tttt uYXY
)3())1(()1( 11 ttttt uuYXY

36
这种解释变量中包括因变量的滞后值的模型称为自回归模型。仅包含因变量一期滞后值的自回归模型是动态经济模型的一种比较简单的形式。由于在解释变量中包含了因变量的滞后值 , 我们就可以动态地考察该变量在若干周期中的变动 , 因此称为动态模型。 在自回归模型( 4 )中,由于随机解释变量的存在和序列相关的可能性这双重原因, OLS 法不能直接应用,因此我们必须研究这类模型的估计问题。
)4(1210 tttt VYXY
这三个模型具有一种共同的形式,即:

37
一、自回归模型的估计问题 OLS 法的应用,要求解释变量 Xt 为非随机的。在自回归模型中,由于 Yt-1 作为解释变量,这一条件已无法满足,这是因为,由于
因此:
这表明, Yt-1 是随着随机扰动项 Vt-1 的变动而变动的,即 Yt-1 部分地由 Vt-1 决定,因而 Yt-1 是随机变量。
tttt VYXY 1210
1221101 tttt VYXY

38
1. 解释变量为随机变量时 OLS 估计量的统计性质
可以证明,当 X 为非随机变量这一条不满足时
( 1 )若每一个 Xt 都独立于所有的扰动项 ut ,即 cov(Xs,ut)=0, s=1,2,…,n t=1,2,…n 则OLS 估计量仍为无偏估计量。
( 2 )若解释变量 Xt 独立于相应的扰动因素 ut ,即随机解释 变量与扰动项同期无关 : Cov(Xt,ut)=0, t=1,2,…,n 则OLS 估计量为一致估计量。
( 3 )若上述两条均不满足,则 OLS 估计量既是有偏的,又 是不一致的。

39
2 、自回归模型的估计问题
在自回归模型的情况下,第( 1 )条已无法满足,因为 Yt-1 显然可以表示为 Vt-1,Vt-2,…,V1 等的函数,因而依赖于 Vt-1 和所有早期的扰动因子。
现在让我们来看是否有可能满足解释变量与扰动项同期无关的条件,从而得到一个一致的估计量。在自回归模型( 4 )的情况下,也就是要求 Yt-1 独立于 Vt, 或 Cov(Yt-1,Vt)=0
不难看出,只要扰动项 Vt 是序列独立的(即自回归模型( 4)的各期扰动项相互独立),我们就可以假定 Yt-1 独立于所有未来的扰动因子(包括 Vt ),在这种假定下, Yt-1 与 Vt 无关,我们对( 4 )式应用 OLS 得到的参数估计量是一致估计量。
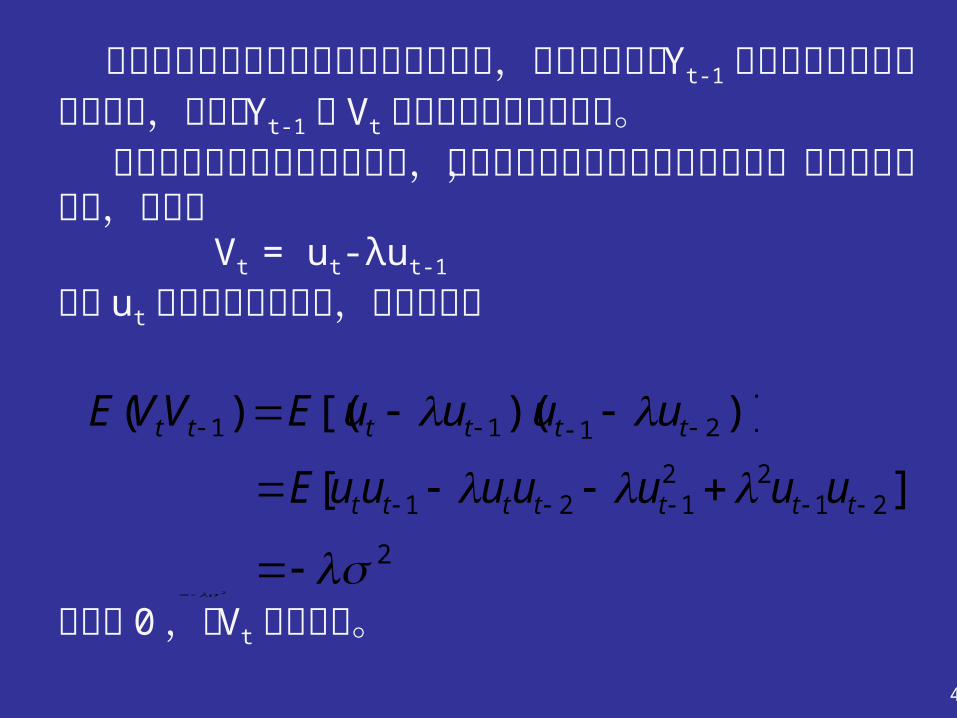
40
让我们回到本节开始时列出的三个模型,看看我们关于 Yt-1 独立于所有未来的扰动因子,特别是 Yt-1 与Vt 无关的假定是否能成立。 在科克模型和适应预期模型中,扰动因子序列独立的条件不成立,以科克模型为例,扰动项 Vt = ut-λut-1
假定 ut 满足标准假设条件,则容易证明
该式非 0 ,即 Vt 序列相关。
][ 2122
121 ttttttt uuuuuuuE 2
2
)])([()( 2111 tttttt uuuuEVVE

41
我们还不难证明
即 Yt-1 与 Vt 相关。适应预期模型的情况与此类似。
)](,[),( 111 ttttt uuYCovVYCov 2
因此,对于科克模型和适应预期模型,应用 OLS法不仅得不到无偏估计量,而且也得不到一致估计量。也就是说,即使样本容量无限增大,参数估计量也不趋向于其总体值。因此,不宜采用 OLS 法估计上述两种模型。

42
但是,部分调整模型不同,在该模型中, Vt=δut
,若 ut 满足标准假设条件,则 Vt 也满足。因此,可用 OLS 法直接估计部分调整模型,将产生一致估计值,虽然估计值通常是有偏的(在小样本情况下)。
综上所述, OLS 法可用于部分调整模型的估计,并提供一致的估计值。而科克模型和适应预期模型,则由于其扰动项存在序列相关,用 OLS 进行估计得到的估计量既是有偏的,也是不一致的。

43
二、工具变量法( IV 法, Instrumental Variable )
OLS 法不能应用于科克模型和适应预期模型的原因是解释变量 Yt-1 与扰动项 Vt 相关,如果这种相关能够被消除的话,我们就可以用 OLS 得到一致估计值。如何实现这一点呢?利维顿( Liviatan )提出的工具变量法是一种解决方法。
工具变量法的基本思路是当扰动项 u 与解释变量 X 高度相关时,设法找到另一个变量 Z , Z 与 X 高度相关,而与扰动项 u 不相关,在模型中,用 Z替换 X ,然后用 OLS 法估计,变量 Z 称为工具变量。
只要工具变量的选取能够保证 Z 与 X 高度相关,而与 u 不相关,则我们得到的将是一致估计量。 Z 与 X 的相关程度越高,这种替代的效果就越好。我们下面回到科克模型和适应预期模型,研究工具变量的选取。

44
我们的模型为
这里 X 是唯一的外生变量,而 Y 的行为部分地依赖于 X 的行为, Yt-1 的取值部分地取决于 Xt-1 的数值。因此,这里 Xt-1
就是一个比较理想的工具变量,即用滞后外生变量作为滞后内生变量的工具:
Zt=Xt-1, t=1,2,…,n
来估计
为了使用该模型所含的全部观测值,需要 X 的一个附加观测值 X0 。
tttt VYXY 1210
ntVZXY tttt ,...,2,1210

45
应该指出,找到一个好的工具变量绝非易事,并且还可能带来新的问题(如多重共线性),因此 IV法实用性不大。
在实践中,自回归模型还可以用极大似然法估计,得到的估计量是一致估计量。
当然,对于本节所涉及的三种模型,由于它们都是几何滞后模型,因而都可以用前面介绍的非线性方法进行估计,该方法尽管费时,但没有估计问题。

46
第五节 阿尔蒙多项式分布滞后 ( Almon Polynomial Distributed Lags ) 科克分布假定滞后解释变量的系数按几何级数递减。对于很多应用问题来说,这是一种令人满意的近似,但对于另一些应用问题,这种假设就未必符合现实情况。例如,在某些情况下较现实的假设是,因变量对解释变量变动的响应是,开始小,然后随时间变大,尔后再次衰减,如下图所示
t
滞后
的权
数
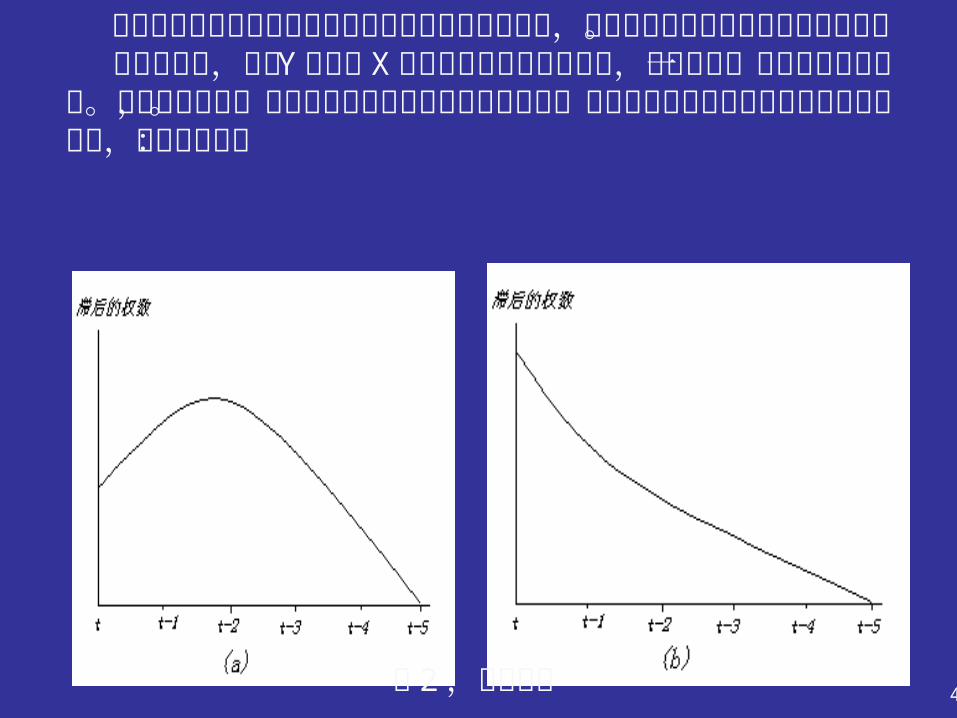
47
阿尔蒙滞后分布为这类行为的构模提供了灵活的选择,同时使待估计的参数数目大大减少。 基本假设是,如果 Y 依赖于 X 的现期值和若干期滞后值,则权数由一个多项式分布给出。由于这个原因,阿尔蒙滞后也称为多项式分布滞后。最简单的例子是二次和三次多项式的情况,如下图所示:
图 2 ,二次函数

48
图 3 三次函数
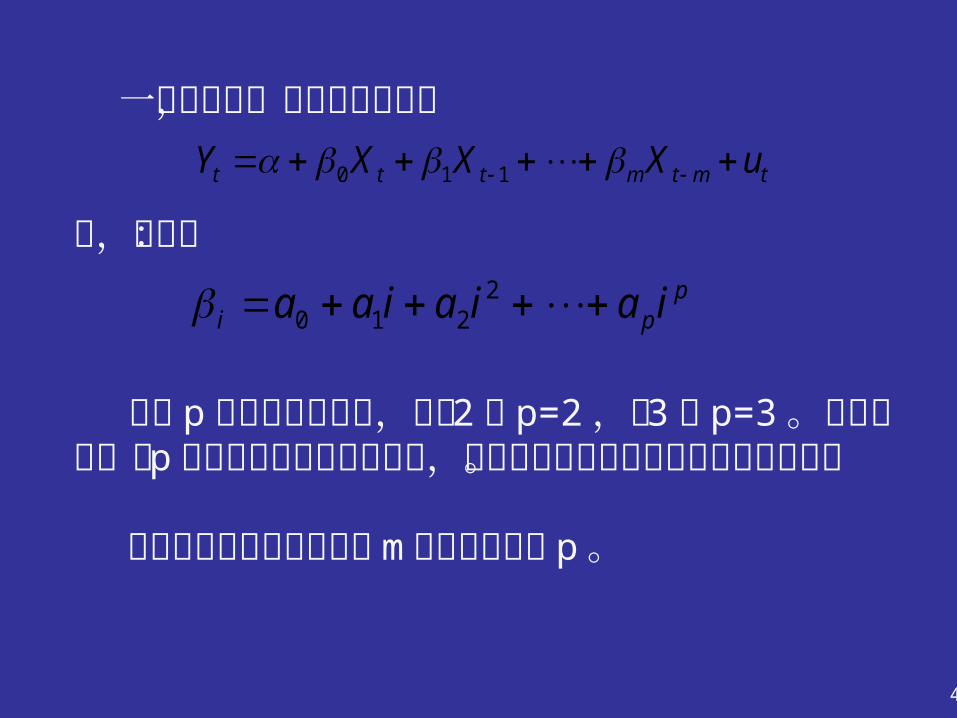
49
一般情况下,在分布滞后模型
中,假定:
其中 p 为多项式的阶数,如图 2 中 p=2 ,图 3中 p=3 。也就是用一个 p 阶多项式来拟合分布滞后,该多项式曲线通过滞后分布的所有点。
由用户选择最大滞后周期 m 和多项式阶数 p 。
ppi iaiaiaa 2
210
tmtmttt uXXXY 110

50
例:若你根据一实际问题设定下面的模型:
这表明,你所选择的最大滞后周期 m=4 ,模型中共有 6 个参数。 若决定用二次式进行拟合,即 p=2 ,则
我们有:
2210 iaiaai
00 a
2101 aaa
2102 42 aaa
2103 93 aaa
2104 164 aaa
)1(443322110 ttttttt uXXXXXY
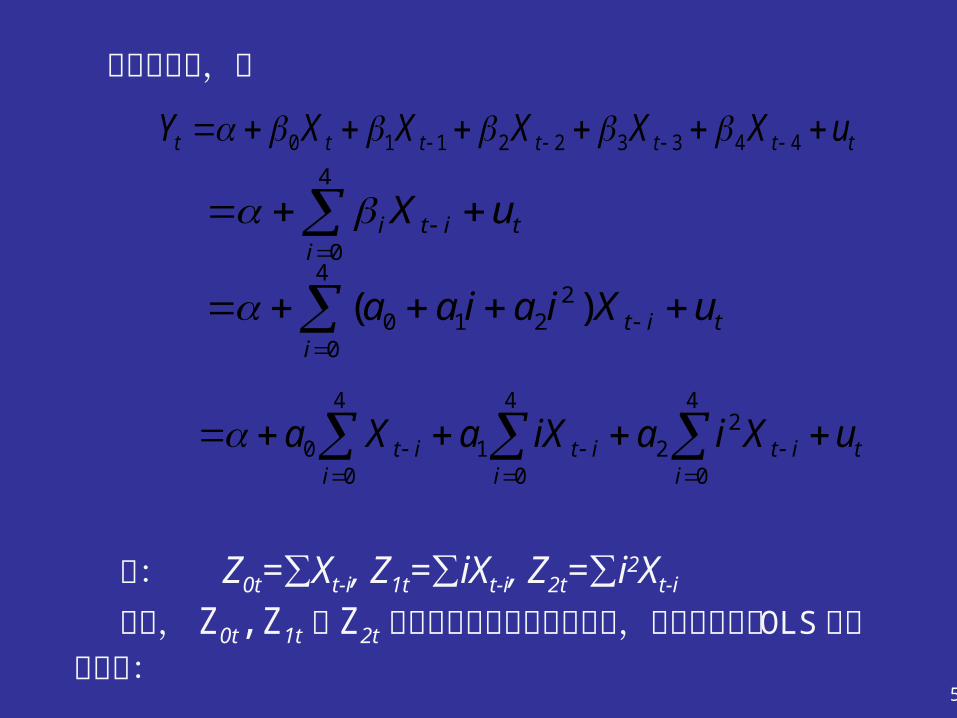
51
代入原模型,得
ti
iti uX
4
0
4
0
2210 )(
itit uXiaiaa
ti
iti
iti
it uXiaiXaXa
4
0
22
4
01
4
00
令: Z0t=∑Xt-i, Z1t=∑iXt-i, Z2t=∑i2Xt-i 显然, Z0t,Z1t 和 Z2t 可以从现有观测数据中得出,使得我们可用 OLS 法估计下式:
ttttttt uXXXXXY 443322110

52
( 2 )式中有 4 个参数,比( 1 )式的 6 个少了两个,估计出, a0,a1,a2 的值之后,我们可以转换为βi 的估计值 , 公式为:
应用阿尔蒙滞后的关键在于如何选择最大滞后周期m 和多项式的阶数 P 。在应用阿尔蒙法之前必须确定 m 和 P ,是该方法的一个弱点,其优点是避免了科克方法带来的估计问题。
2210 ˆˆˆˆ iaiaai
)2(221100 ttttt uZaZaZaY

53
在实践中,人们期望m尽量小一些,如果有 10 年的数据,通常滞后取二至三期。对于 P ,我们可直接由( 2 )式用 t 检验法检验 H0: aP = 0, 如果接受原假设,我们就可以去掉 aP ,然后用( P-1 )阶来估计( 2 )式,如果 H0: aP = 0 被拒绝,我们可以试(p+1 )阶,并检验 H0: aP+1= 0 ,等等。 一般说来,采用高阶多项式,拟合效果要好一些,但出现多重共线性问题的可能性要比二阶、三阶多项式大。一般情况下,三次多项式是一个不错的选择。

54
第六章 小结 现实的经济模型往往包括经济变量的滞后。有两种类型的滞后变量:滞后的解释变量和滞后的因变量。包含非随机的X 变量的现期值和滞后值的回归模型称为分布滞后模型。而解释变量中包含因变量的滞后值的模型称为自回归模型。
如果分布滞后模型包含若干期的滞后,则采用 OLS 法进行估计,尽管理论上可行,但实践上困难很大。这是由于它将消耗过多的自由度,并且一般存在严重的多重共线性问题。解决的方法是对滞后系数施加先验约束条件。广泛使用的一种方法是科克几何分布滞后模型,它假定诸滞后系数按几何级数递减。根据这一假设,包含不确定数目滞后项的模型可简化为仅包含非随机 X 变量的现期值和因变量的一期滞后值作为解释变量的模型: Yt = α(1-λ) + βXt + λYt-1 + (ut – λut-1)

55
科克模型大大简化了分布滞后模型,代价是带来了严重的估计问题,主要是包含了一个随机的解释变量 Yt-1 ,它与扰动项相关,这使得 OLS 估计量不仅有偏,而且不一致。因此,需采用适当的估计技术,本章中介绍了其中的一种,即工具变量法,其思路是用另一个变量来代替滞后的随机解释变量 Yt-1 ,该变量与 Yt-1 高度相关,而与扰动项不相关。
科克模型尽管在计量经济学中很著名,但它缺乏坚实的理论基础。这一缺陷可由适应预期模型和部分调整模型来弥补。这两个模型研究的是,参与经济的各方如何形成它们关于不确定经济事件的预期,以及当他们的预期与现实不符时如何调整预期。这两个模型的最终形式与科克模型相似,分别为

56
适应预期模型 Yt = αγ + βγXt + (1-γ)Yt-1 + (ut - ( 1-γ)ut-1 )
部分调整模型 Yt = αδ + βδXt + ( 1-δ ) Yt-1 + δut
其中 γ 和 δ 为调整系数( 0≤γ 、 δ≤1 ), ut 为原模型扰动因子。 相应的调整机制为: 适应预期机制: Xt
e – Xt-1e = γ(Xt – Xt-1
e)
部分调整机制: Yt – Yt-1 = δ(Yt* - Yt-1 )
其中 Xe 和 Y* 分别为解释变量和因变量的“预期值”或“理想值”。

57
处理分布滞后模型的另一个方法是阿尔蒙多项式分布滞后模型,它假定诸滞后系数可用滞后长度 i 的一个适当阶数的多项式来近似。阿尔蒙法的优点是避免了科克方法带来的估计问题,缺点是多项式阶数 p 和最大滞后长度 m都必须由使用者事先确定,这往往带有主观的色彩。
尽管存在着估计问题,分布滞后模型和自回归模型在实证经济学中非常有用,这是因为它们使得静态经济理论动态化。这些模型有助于区分解释变量值的单位变动对因变量的短期和长期影响,可用于短期和长期的价格弹性、收入弹性、替代弹性等的估计。

58
第六章 习题
1 、考虑下面的模型: Yt = α+β(W0Xt+ W1Xt-1 + W2Xt-2 + W3Xt-3)+ut
请说明如何用阿尔蒙滞后方法来估计上述模型(设用二次多项式来近似)。
2 、下面的模型是一个将部分调整和适应预期假说结合在一起的模型: Yt
* = βXt+1e
Yt-Yt-1 = δ(Yt* - Yt-1) + ut
Xt+1e - Xt
e = (1-λ)( Xt - Xte) ; t=1 , 2 ,…, n
式中 Yt* 是理想值, Xt+1
e 和 Xte 是预期值。试推导出一个
只包含可观测变量的方程,并说明该方程参数估计方面的问题。