유한상태변환기를 이용한 한국어_형태소_분석_이상호
TRANSCRIPT

Rouzeta : 유한 상태 기반의한국어 형태소 분석기
이 상호

http://www.rouzeta.com https://www.youtube.com/watch?v=PjqUYvqK8v4

형태소 분석기란?
• 나는 나/대명사 + 는/조사 (나는 간다)
날/용언 + 는/어미 (높이 나는 새)
나/용언 + 는/어미 (피어 나는 곳)
• 고마워 고맙/용언 + 어/어미
• 해 해/명사 (해가 뜬다)
하/용언 + 어/어미 (해 주세요)
• 갈 갈/용언 + ㄹ/어미 (칼을 갈 사람)
가/용언 + ㄹ/어미 (거기 갈 사람)

품사 태깅 (Part-of-speech tagging)이란?
• 형태소 분석은 언제나 Ambiguity가 발생된다.• Ambiguity는 문맥을 보고 추정해야 한다.
• 형태소 분석기는 모든 가능한 형태소 분석 결과를 내어 주어야되는 모듈이고,
• 품사 태깅은 그 문장에서 해석되는 형태소 분석 결과를 선택하는 과정이다.

어디에 쓰이나?• 검색 시스템에서 색인어 추출
• 음성 인식기/합성기 개발에서 [단어:발음] 관계를 구해야 되는데품사를 알아야 정확한 발음을 알 수 있다.
• 단어 품사 발음
• 머리를 감기가 힘들다.• 감/용언 + 기/명사화접미사 [감끼가]
• 내가 감기가 걸렸다.• 감기/체언 [감기가]

형태소 분석기는
자연언어처리 시스템을 만드는데
있어서 기본 중에 기본 시스템이다.

뭐.. 오래된 기술 같은데
이걸 왜 또 만들었나요?

1993년~1995년 때를 되돌아 가보면..

그 당시 형태소 분석 방법
• Dictionary (사전)을 Trie로 만들어서 가지고 있는다.
• 주어진 어절에 대해서 CYK parsing 방법과 같은 것으로 가능한 모든 결과를 관리한다.
• 형태소 접점부분에서 발생되는 변이 현상을 추정, 혹은 그냥 ‘異형태’를 사전에 넣어버리고 만다.
• 고마워 고마 + 워 (‘고맙’의 이형태 ‘고마’도 사전에 넣어버린다)

CYK법에 기반한 한국어 형태소분석에서의 개선기법이은철, 포항공과대학교, 1993.

95년도에 형태소 분석기를 오픈 소스로 공개
• KTS (Korean Tagging System)
• 사전을 참조하고, 격자 (lattice)를 만들면서 형태소 분석을 함.
• 형태소 접점시 불규칙 현상/탈락되는 현상이 발생되는 음절 리스트를 가지고 있으며, ‘원형’을 복원한다.• 이형태 ‘고마‘ ‘워‘ 이런 것을 사전에 넣지 않는다.


미등록어를 고려한 한국어 품사 태깅 시스템 구현
이상호, KAIST, 1995.
𝑡1..𝑛∗ = arg𝑚𝑎𝑥𝑡..𝑛 𝑃 𝑤𝑖 𝑡𝑖 𝑃(𝑡𝑖|𝑡𝑖−1)

이 논문을 읽고 충격 받음.
Computational Linguistics, 1995.

영어에서의 품사 태깅을 보면..
•The flies like an arrow.
•Time flies like an arrow.

• Eric Brill의 ‘Transformational Rule-based Learner’를 Finite state transducer로 바꾸고 이를 순차적으로 적용하여 하나의Finite state transducer로 만들면, 품사 태깅 과정이deterministic하게 할 수 있다.
• 시간 복잡도가 O(n) (n은 단어 개수)로 변해 버린다.
• 그것보다도, 뭔가 처리하는 과정이 인간이 생각하는 과정(?)과비슷하다는 느낌을 받음.

문장을 읽을 때, 인간은 품사 ambiguity를 계속 쌓다가 어느 순간 확실한 clue를 만나면 그 동안 해결하지 못한 것을 한번에 해결하지 않나?
•하나의 단어에 가장 고빈도의 품사를 먼저 할당시킨다.
•이후 finite state transducer를 통과시킨다.

Vbn : 과거 분사Vbd : 과거Np : 명사
A movie recommended by you is ….
처음에는 과거형이라고 생각했다가뒤에 ‘by’를 보는 순간 과거 분사형이라는것을 추정하게 된다.‘by’를 보는 순간까지 사실 정확한 결정을 미룬다.
DET NP VBD by ….

더 이상 빠를 수가 없다.

Finite State Computing
Finite State Transducer


Weighted finite state transducer

From www.fsmbook.com
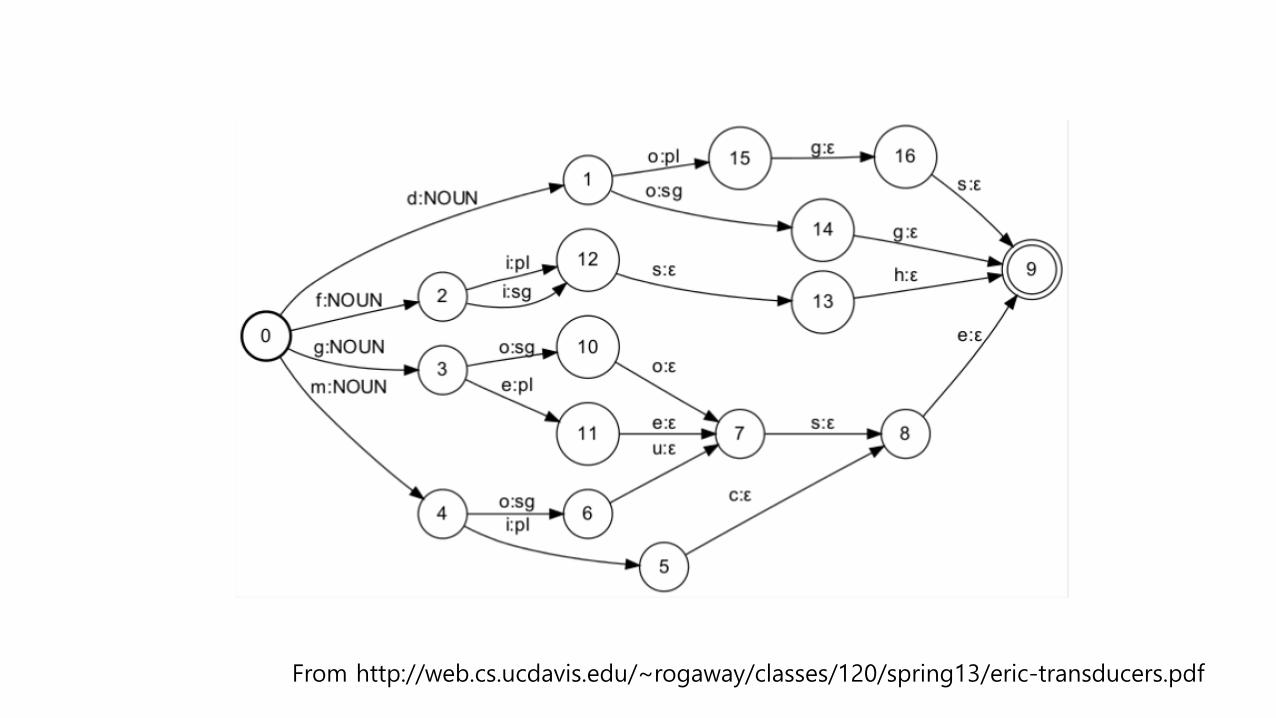
From http://web.cs.ucdavis.edu/~rogaway/classes/120/spring13/eric-transducers.pdf



하나의 언어에서 나오는 모든 가능한 문장에대해서 형태소 분석/생성 transducer 모델을만들 수 있나?
그것도, 형태소 접점에서 발생되는 변이를 모두 포함되어 있는 어휘형표층형 간 심벌매핑으로 된 거대한 transducer를 만든다?

이 모든게 가능하다.
• 그렇다면, 이것보다 모델이 더 아름다울 수 없다.
• 그냥 transducer를 실행시키는 프로그램 하나만 있으면 된다. 이거 동작시키는 프로그램은 구현하기도 쉽다.
• String string으로 mapping되는 문제는 모두 이 framework로 풀 수 있다.
• 그런데 어떻게 하나의 transducer를 만들지?

Composition Operator
• foma[0]: define A [하나:one] ;
• foma[0]: define B [one:いち] ;
• foma[0]: define C [いち:一] ;
• foma[1]: regex A .o. B .o. C ;
중간 심벌이 사라진다.
문제를 단계별로 나눈 후 해결한다.그 이후 모든 transducer를 composition하여 전체 문제를 해결한다.

From http://web.cs.ucdavis.edu/~rogaway/classes/120/spring13/eric-transducers.pdf

Replace Rule Operator
• Upper lower || leftcontext _ rightcontext
• foma[0]: define A a -> b || c _ d ;
aaccad aaccbd

Replace Rule Operator
define EDeletion e -> 0 || _ "^" [ i n g | e d ] ;define EInsertion [..] -> e || s | z | x | c h | s h _ "^" s ;define A %_ㄷ -> %_ㄹ || _ %/irrd %/vb ㅇ ;

한국어 규칙을composition한다.
define ARules NPFilter .o. ! 체언 + 조사 규칙 적용 : 사과는/사람은
VEFilter .o. ! 용언 + 어미 불가 필터 : 아름답+는/고마웠+아야지
VHarmony .o. ! 용언 모음 조화 : 막아/저어
RuleYI .o. ! '이' 축약 & '이' 생략 : 사과다/사과였다/가졌다
DropEU .o. ! '으' 탈락 현상 : 써도
InsertEU .o. ! '으' 삽입 현상 : 먹으면
IrrConjO .o. ! '오' 불규칙 현상 : 다오
DropL .o. ! 'ㄹ' 탈락 현상 : 아니까
DropS .o. ! 'ㅅ' 불규칙 현상 : 그어
ConjEAE .o. ! 'ㅐ'/'ㅔ'의 '어'탈락 : 메, 개, 갰다
IrrConjD .o. ! 'ㄷ' 불규칙 현상 : 깨달아
IrrConjB .o. ! 'ㅂ' 불규칙 현상 : 고와
IrrConjl .o. ! '르' 불규칙 현상 : 굴러
IrrConjL .o. ! '러' 불규칙 현상 : 푸르러
IrrConju .o. ! '우' 불규칙 현상 : 퍼
IrrConjYEO .o. ! '여' 불규칙 현상 : 하여, 해
IrrEola .o. ! '거라'/'너라' 불규칙 : 자거라, 오너라
IrrConjH .o. ! 'ㅎ' 불규칙 현상 : 하얘, 빨간
ConjDiph .o. ! 용언+어미 모음 축약 : 가(가+아), 됐다 (되+었+다)
ReducedWords .o. ! 줄임말들 처리 : 흔치 않다.
FilterOut .o. ! 기본적인 는/을/는다의 과분석 제거
ChangeNullCoda ;! Null 종성 삽입/삭제

!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!
! '하다' + '어' => '하여' '하다' + '어' => '해'
! '하다' + '어서' => '하여서' '하다' + '어서' => '해서'
! '하다' + '었다' => '하였다' '하다' + '었다' => '했다'
!
! 하여 => * ㅎ ㅏ %_ /vb + ㅇ ㅓ * /e*
! (1) => * ㅎ ㅏ %_ /vb + ㅇ ㅕ * /e*
! (2) => * ㅎ /vb + ㅐ * /e*
! => (1) | (2)
!
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
define IrrConjYEO1 ㅓ -> ㅕ || ㅎ ㅏ FILLC [%/vb|%/vi|%/vj|%/vx|%/xj|%/xv] ㅇ _ ;
define IrrConjYEO2 ㅏ FILLC %/vb ㅇ ㅕ (->) %/vb ㅐ || ㅎ _ .o.
ㅏ FILLC %/vi ㅇ ㅕ (->) %/vi ㅐ || ㅎ _ .o.
ㅏ FILLC %/vj ㅇ ㅕ (->) %/vj ㅐ || ㅎ _ .o.
ㅏ FILLC %/vx ㅇ ㅕ (->) %/vx ㅐ || ㅎ _ .o.
ㅏ FILLC %/xj ㅇ ㅕ (->) %/xj ㅐ || ㅎ _ .o.
ㅏ FILLC %/xv ㅇ ㅕ (->) %/xv ㅐ || ㅎ _ ;
define IrrConjYEO IrrConjYEO1 .o. IrrConjYEO2 ;

foma[1]: upapply up> 고마웠다
고맙/irrb/vj었/ep다/ef
고맙/irrb/vj었/ep다/ex
apply up> 빨개서
빨갛/irrh/vj아서/ef
빨갛/irrh/vj아서/ex
빨갛/irrh/vj아/ec서/pa
빨/vb_ㄹ/ed개서/nc
apply up> 사괄 먹는다사과/nc_ㄹ/po 먹/vb는다/ef
사과/nc_ㄹ/po 먹/vb는다/ex
사과/nc_ㄹ/po 먹/vx는다/ef

반대로, ‘고맙’ ‘어’를 넣으면 ‘고마워'가나온다.
통상 분석기를 만드는 사람들은 ‘분석'만 되게 만들지만,FST는 분석의 input/output symbol pair를 바꾸기만 하면, ‘생성 모델'이 된다.

Rouzeta
약 29만 어휘127,416개의 State 수2,806,708개의 Arc 수
세종 코퍼스 기반으로만듦.

국내에서 FST 기반 한국어 형태소 분석기오픈 소스는 처음임.• 더 이상 실행 속도가 빨라지는 것은 쉽지 않다.
• 수학적으로 sound함. 더 이상 아름다울 수가 없음.
• High level information을 넣는 것이 수월함• Composition operator를 이용해서
• 단점 (?)• 절대 시간 이상의 공부가 필요함.
• ‘Replace Operator’ 같은 것을 공부하고 싶다면, 머리에서 쥐난다.
• 모델에 대한 근원적 제약 조건이데, 풀어야 되는 문제가 Context-free grammar 같은 것을 사용해야 하는 string-to-string 문제라면approximiate 접근법을 취해야 한다. – 하지만 parsing을 FST로 푸는논문이 많음.

품사 태깅 – composition으로 만든다
𝑡1..𝑛∗ = arg𝑚𝑎𝑥𝑡..𝑛 𝑃(𝑤𝑖 , 𝑡𝑖)

품사 태깅 예• 나 는 <space> 학 교 에 서 <space> 공 부 합 니 다 .
• 나 /np 는 /pt <space> 학 교 /nc 에 서 /pa <space> 공 부 /na 하 /xv _ㅂ 니 다 /ef . /sf
• 선 을 <space> 그 어 <space> 버 렸 다 . • 선 /nc 을 /po <space> 긋 /irrs /vb 어 /ex <space> 버 리 /vx 었 /ep
다 /ef . /sf
• 고 마 웠 다 . • 고 맙 /irrb /vj 었 /ep 다 /ef . /sf
• 이 것 은 <space> 사 과 다 .• 이 것 /nm 은 /pt <space> 사 과 /nc 이 /pp 다 /ef . /sf

앞으로 방향성
• 이것 가지고 하고 싶은 것은 정말 많으나…
• 회사 일을 해야 되어서 지금은 시간이 없음..
• 완전 오픈하고, 관심 있는 사람이 고쳐서 사용해서, 우리나라 언어처리 기술 발전에 도움이 되었으면 함.. 그게 전부임.