第 7 章 回归分析
DESCRIPTION
第 7 章 回归分析. 第一节、回归分析意义 第二节、回归分析的种类 第三节、相关分析与回归分析的关系 第四节、一元线性回归分析 第五节、估计标准误差. “回归”名称产生的背景. 回归分析的基本思想和方法以及“回归”名称的由来归功于英国统计学家 F.Galton 、 K.Pearson( 皮尔森 ) 等学者的工作。 他们在研究父母身高与其子女身高的关系时发现 ( 样本量 1078 对夫妇 ), 以 每对夫妇的身高为 x , 子女的身高为 y , 将结果绘制成散点图 , 发现趋于一条直线 , y=33.73+0.516x - PowerPoint PPT PresentationTRANSCRIPT

第 7 章 回归分析

第一节、回归分析意义
第二节、回归分析的种类
第三节、相关分析与回归分析的关系
第四节、一元线性回归分析
第五节、估计标准误差
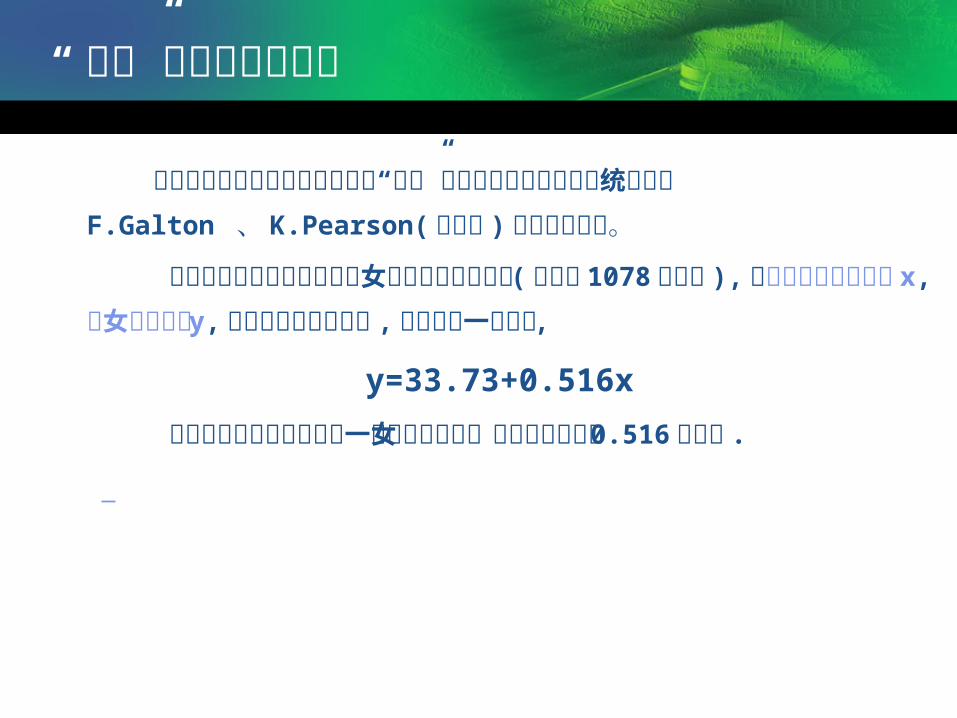
回归分析的基本思想和方法以及“回归”名称的由来归功于英国统计学家F.Galton 、 K.Pearson( 皮尔森 ) 等学者的工作。
他们在研究父母身高与其子女身高的关系时发现 ( 样本量 1078 对夫妇 ), 以每对夫妇的身高为 x, 子女的身高为 y, 将结果绘制成散点图 , 发现趋于一条直线 ,
y=33.73+0.516x
表明父母平均身高每增加一个单位与其子女身高也平均增加 0.516 个单位 .
“ 回归”名称产生的背景

结果表明虽然高个子父母生高个子儿子的趋势 , 但母辈增高 1 个单位 ,儿子身高仅增加半个单位 . 平均来说一群高个子的父母的儿子低于他们父辈的平均高度 . 他们儿子身高没有比他们更高 , 高个子的父母的平均身高一部分被他们的子代拉了回来 , 即子代的平均高度向中心回归了 .
低个了父母的儿子虽然为低个子 , 平均身高高于他们父辈 , 低个子的父母的平均身高一部分被他们的子代拉了回来一些 , 子代的身高没有比他们父辈更低 .
结果没有出现两极分化的现象 , 在一段相当长的时间内保持了生物学中物种的稳定 , 为了描述有趣的现象 , F.Galton 引用了”回归”的词

回归分析( regression analysis) 是确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法。 商品的消费量 (y) 与居民收入 (x) 之间的关系 商品的消费量 (y) 与物价 (x) 之间的关系 商品销售额 (y) 与广告费支出 (x) 之间的关系 粮食亩产量 (y) 与施肥量 (x1) 、降雨量 (x2) 、温度 (x3) 之间的关系 收入水平 (y) 与受教育程度 (x) 之间的关系 父亲身高 (y) 与子女身高 (x) 之间的关系
第一节、回归的意义

第二节、回归分析的种类 按照自变量和因变量之间的关系类型,可分为线性回归分析和
非线性回归分析。
回归分析按照涉及的自变量的多少,可分为一元回归分析和多元回归分析;
如果在回归分析中,只包括一个自变量和一个因变量,且二者的关系可用一条直线近似表示,这种回归分析称为一元线性回归分析。
如果回归分析中包括两个或两个以上的自变量,且因变量和自变量之间是线性关系,则称为多元线性回归分析。
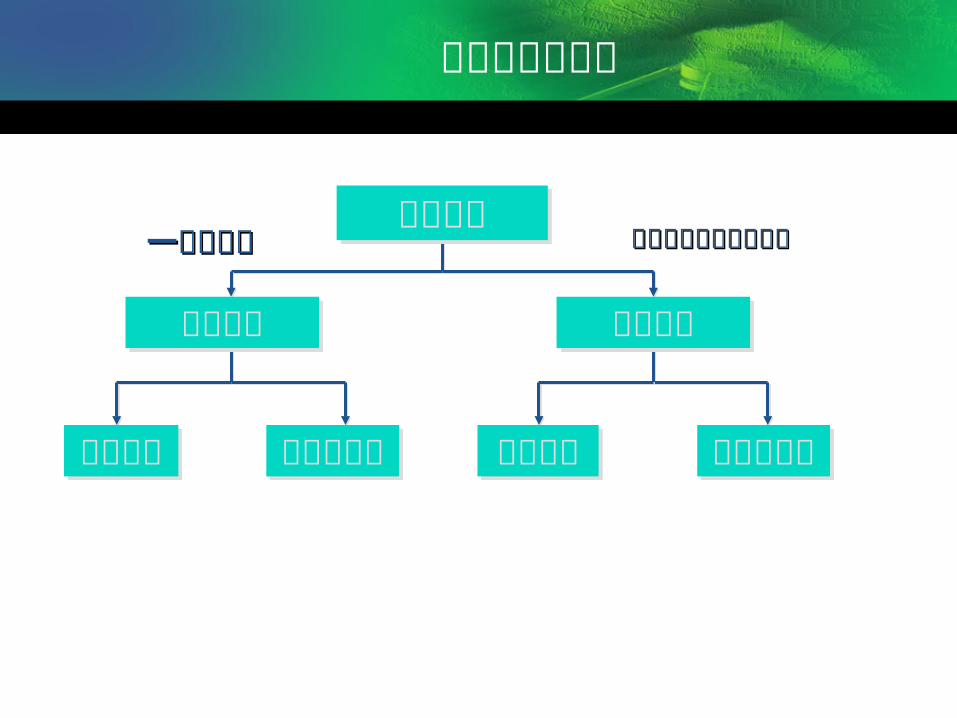
回归分析的类型
一个自变量一个自变量 两个及两个以上自变量两个及两个以上自变量回归分析回归分析
多元回归多元回归一元回归一元回归
线性回归线性回归
非线性回归
非线性回归
线性回归线性回归
非线性回归
非线性回归
回归的类型?
xx
yy

(函数关系)
( 1 )是一一对应的确定关系( 2 )设有两个变量 x 和 y ,变
量 y 随变量 x 一起变化,并完全依赖于 x ,当变量 x 取某个数值时, y 依确定的关系取相应的值,则称 y 是 x 的函数,记为 y = f (x) ,其中 x 称为自变量, y 称为因变量
( 3 )各观测点落在一条线上
xx
yy

变量间的关系
函数关系的例子 某种商品的销售额 (y) 与销售量 (x) 之间的
关系可表示为 y = p x (p 为单价 )
圆的面积 (S) 与半径之间的关系可表示为 S = r2
企业的原材料消耗额 (y) 与产量 (x1) 、单位产量消耗 (x2) 、原材料价格 (x3) 之间的关系可表示为 y = x1 x2 x3

相关分析与回归分析内容比较
1. 相关分析1. 相关分析就是用一个指标来表明现象间相互依存关系的密切程度。广义的相关分析包括相关关系的分析(狭义的相关分析)和回归分析。
2. 回归分析2. 回归分析是指对具有相关关系的现象,根据其相关关系的具体形态,选择一个合适的数学模型(称为回归方程式),用来近似地表达变量间的平均变化关系的一种统计分析方法。

第三节、相关分析与回归分析的关系
(一)区别 1 、相关分析的任务是确定两个变量之间相关的方向和密切程
度。回归分析的任务是寻找因变量对自变量依赖关系的数学表达式。
2 、相关分析不必确定两变量中哪个是自变量,哪个是因变量,而回归分析中必须区分因变量与自变量。
3 、相关分析中两变量是对等的改变两者的地位,并不影响相关系数的数值,只有一个相关系数。而在回归分析中,互为因果关系的两个变量可以编制两个独立的回归方程。
4 、相关分析中两变量可以都是随机的,而回归分析中因变量是随机的,自变量不是随机的。

(二)联系
1 、相关分析是回归分析的基础和前提。只有在相关分析确定了变量之间存在一定相关关系的基础上建立的回归方程才有意义。
2 、回归分析是相关分析的继续和深化。只有建立了回归方程才能表明变量之间的依赖关系,并进一步进行预测。

( 一 ) 相关表:将自变量 x 的数值按照从小到大的顺序,
并配合因变量 y 的数值一一对应而平行排列的表。
广告费(万元) 30 33 33 40 56 58 65 72 80 80 90
年销售收入(百万元) 12 12 12 13 14 14 20 22 26 26 30
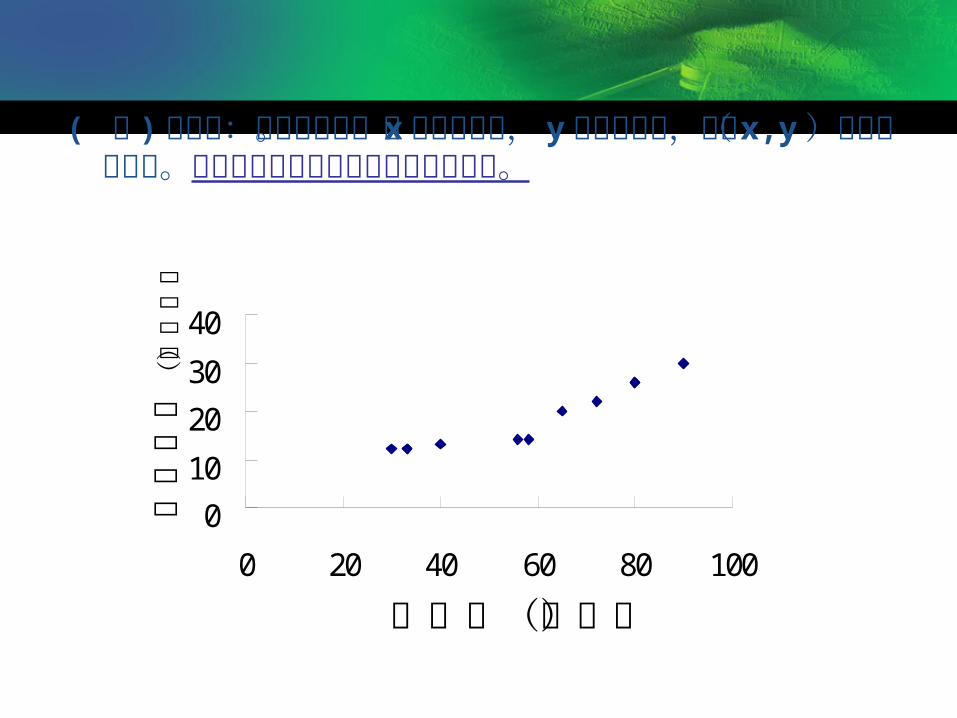
( 二 ) 相关图:又称散点图。将 x 置于横轴上, y 置于纵轴上,将( x,y )绘于坐标图上。用来反映两变量之间相关关系的图形。
0
10
20
30
40
0 20 40 60 80 100
广告费(万元)
销售收入(百万元)

第三节 一元线性回归分析
一、一元线性回归方程的建立
二、一元线性回归方程的分析
回答“变量之间是什么样的关系?” 方程中运用 -主要用于预测和估计

1. 从一组样本数据出发,确定变量之间的数学关系式
2. 对这些关系式的可信程度进行各种统计检验,并从影响某一特定变量的诸多变量中找出哪些变量的影响显著,哪些不显著
3. 利用所求的关系式,根据一个或几个变量的取值来预测或控制另一个特定变量的取值,并给出这种预测或控制的精确程度
一元线性回归分析

一元线性回归模型 (概念要点)
1. 当只涉及一个自变量时称为一元回归,若因变量 y 与自变量 x 之间为线性关系时称为一元线性回归。
2. 对于具有线性关系的两个变量,可以用一条线性方程来表示它们之间的关系。
3. 描述因变量 y 如何依赖于自变量 x 和误差项的方程称为回归模型。

标准的一元线性回归模型标准的一元线性回归模型
( 一 ) 总体回归函数 Y= a + b X+ ut
u t是随机误差项,又称随机干扰项,它是一个特殊的随机变量,反映未列入方程式的其他各种因素对Y的影响。
( 二 ) 样本回归函数 :
y= a+ bx+e t
e t称为残差,在概念上,e t与总体误差项 ut相互对应;n是样本的容量。

e t 是因变量的实际值和估计值的离差:当给定 X 一数值时, y 的实际值可以看作由两部分组成:
一部分是 X 对 y 均值的线性影响而形成的系统部分,由回归量 Y=a+bX 来决定;
另一部分是内e t 所代表的各种偶然因素、观察误差以及被忽略的其他影响因素所带来的随机误差。
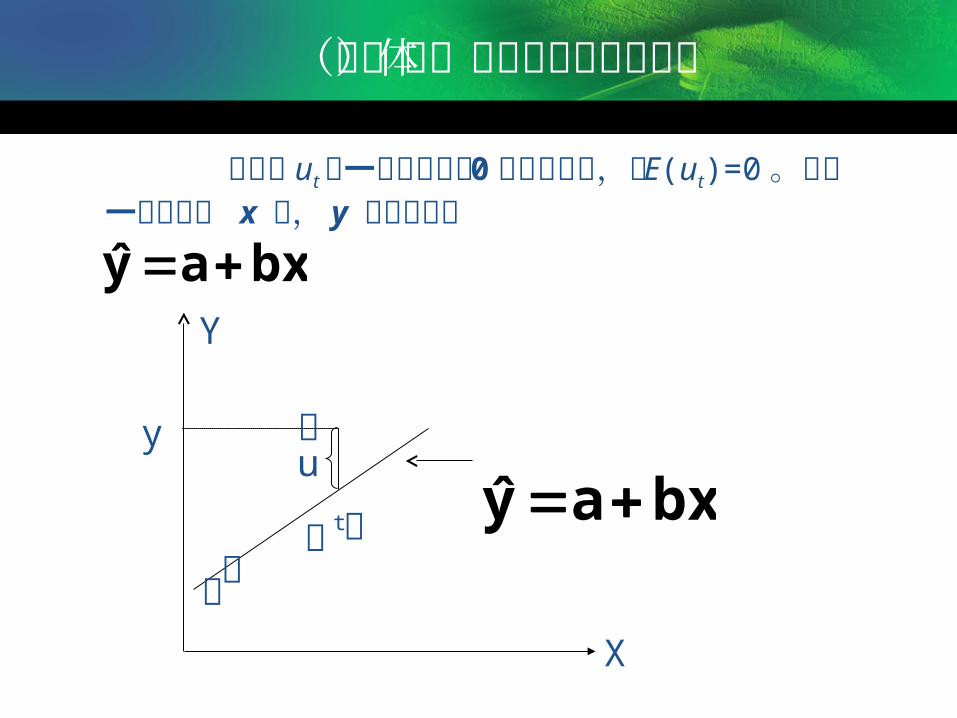
(三)总体回归线与随机误差项
误差项 ut 是一个期望值为 0 的随机变量,即 E(ut)=0 。对于一个给定的 x 值, y 的期望值为
bxay
X
y
Y
。 。 。
。
。ut
bxay

(四)回归方程 (概念要点)1. 描述 y 的平均值或期望值如何依赖于 x 的方程称为
回归方程。2. 简单线性回归方程的形式如下
方程的图示是一条直线,因此也称为直线回归方程
a 是回归直线在 y 轴上的截距,是当 x=0 时 y 的期望值
b 是直线的斜率,称为回归系数,表示当 x 每变动一个单位时, y 的平均变动值
bxay ˆ

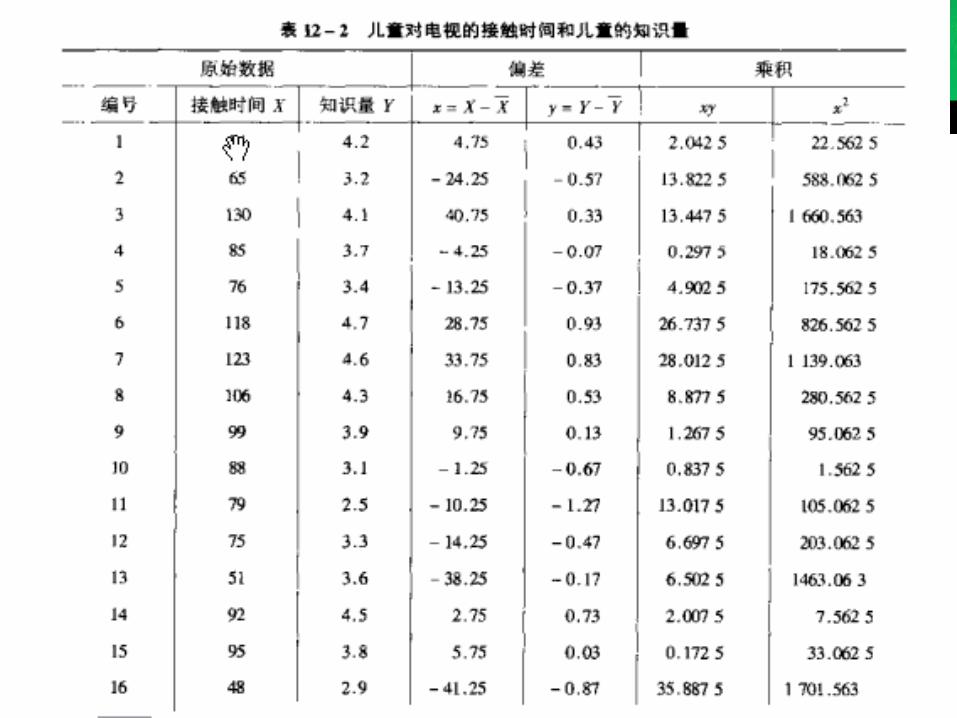
居民收入与商品零售额的统计数据如下:(亿元)
年份 居民收入 X 商品零售额 Y X2 xy
1 12 10 144 120
2 13 12 169 156
3 14 12 196 168
4 15 13 225 195
5 14 13 196 182
6 16 14 256 224
7 18 15 324 270
8 20 17 400 340合计 122 106 1910 1655

建立直线回归方程:(结果保留一位小数)
( 2 )试预测当居民收入增加 1 亿元时,商品零售额平均增加多少?
( 3 )试预测当居民收入增加到 30亿元时,商品零售额是多少?

公式 1

Y = 1.3385+ 0.7778x
当居民收入增加量每增加 1 亿元时,社会商品的零售额平均增加 0.7778亿元。

a=∑y/n-b∑x/n
求 a 和 b 公式二
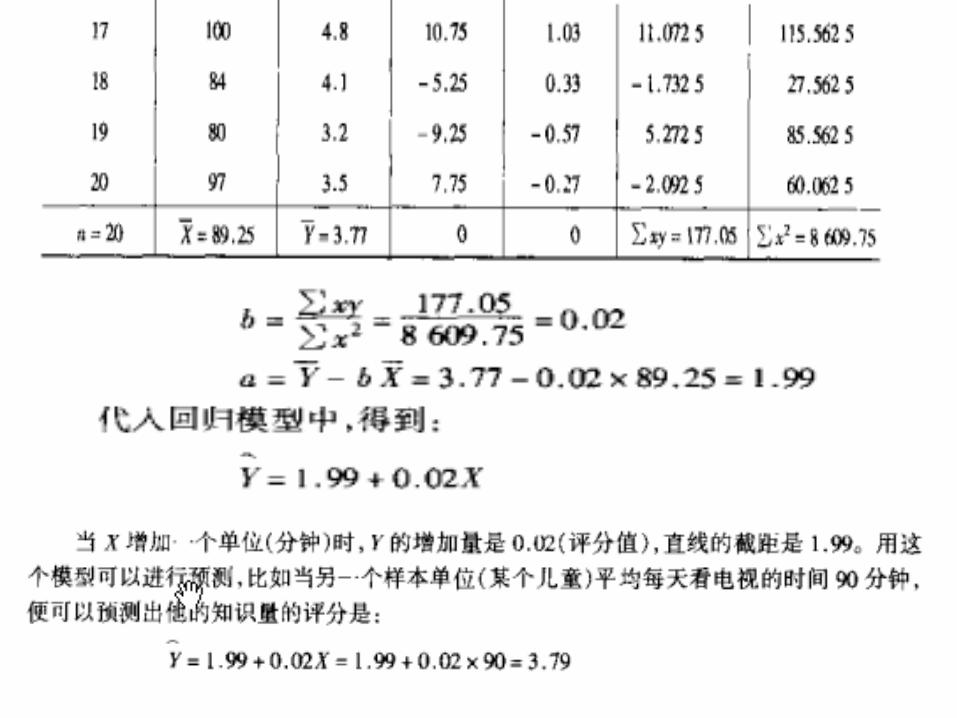

例:建立回归方程,并说明其意义?
编 号
人口增长量(千人)x
年 需 求 量(十吨)
y 1 274 162 2 180 120 3 375 223 4 205 131 5 86 67 6 265 169 7 98 81 8 330 192 9 195 116 10 53 55 11 430 252 12 372 234 13 236 144 14 157 103 15 370 212 合计 3626 2261

编 号
人口增长量(千人)
x
年 需 求 量(十吨)
y
2x 2y xy
合计 3626 2261 1067614 395039 647851
15n
Y= 22.59+0.5301x
上式表示人口增加量每增加(或减少) 1 千人,该种食品的年需求量平均来说增加(或减少) 0.5301十吨即 5.301吨。

练习:下面的数据是产品广告费与销售额的关系
广告费(万元) 30 33 33 40 56 58 65 72 80 80 90
年销售收入(百万元) 12 12 12 13 14 14 20 22 26 26 30
1 、建立回归方程。
2 、试预测当广告费增加 1 万元时,年销售额平均增加多少?3 、试预测当广告费增加到 50 万元时,年销售 额是多少?
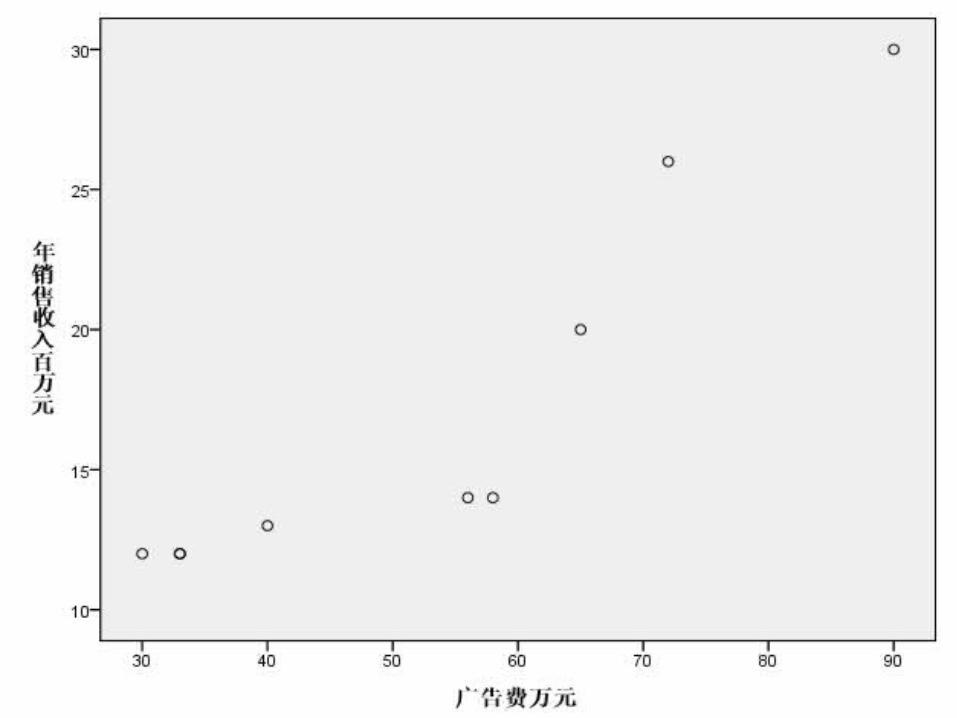

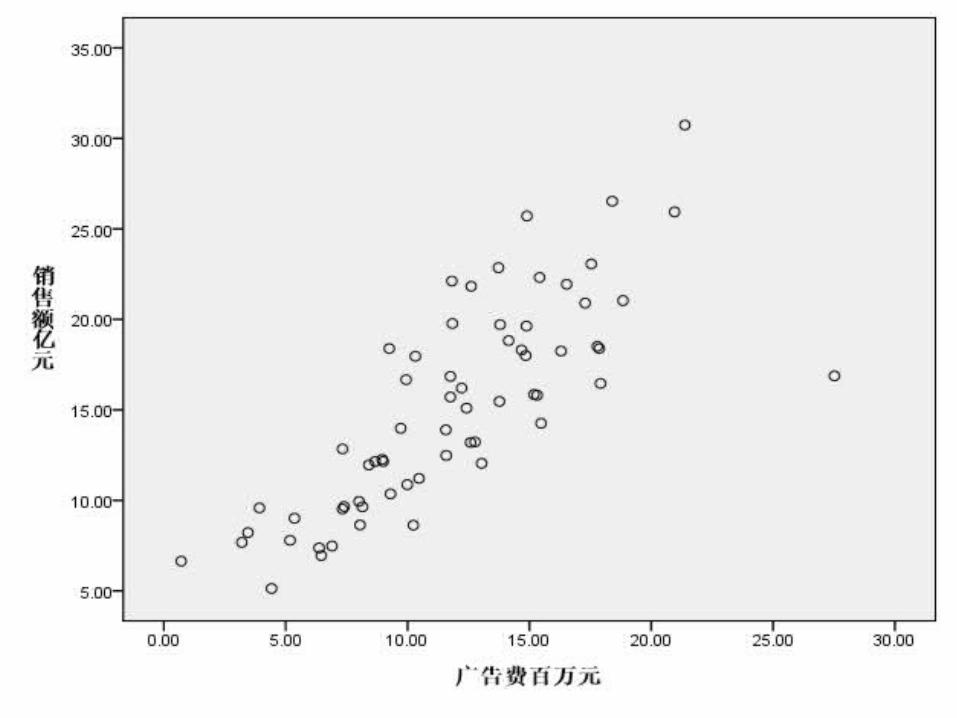
某大型电器公司广告费与销售额数据

一元回归:自变量 - 广告费
xy 908.042.4ˆ

332211ˆ xbxbxbay
321 024.0114.0434.0057.5ˆ xxxy

第五节、估计平均误差第五节、估计平均误差
回归方程的一个重要作用在于根据自变量的已知值估计因变量的可能值。这个估计值和真正的实际值可能一致,也可能不一致。
例如,当居民收入增加量每增加 1亿元时,社会商品的零售额平均增加 0.7778 亿元。人口增加量每增加(或减少) 1 千人,该种食品的年需求量平均来说增加(或减少) 0.5301十吨即 5.301吨。
回归方程的可靠性问题如何?也就是说,根据回归方程计算的估计值,其代表性如何?
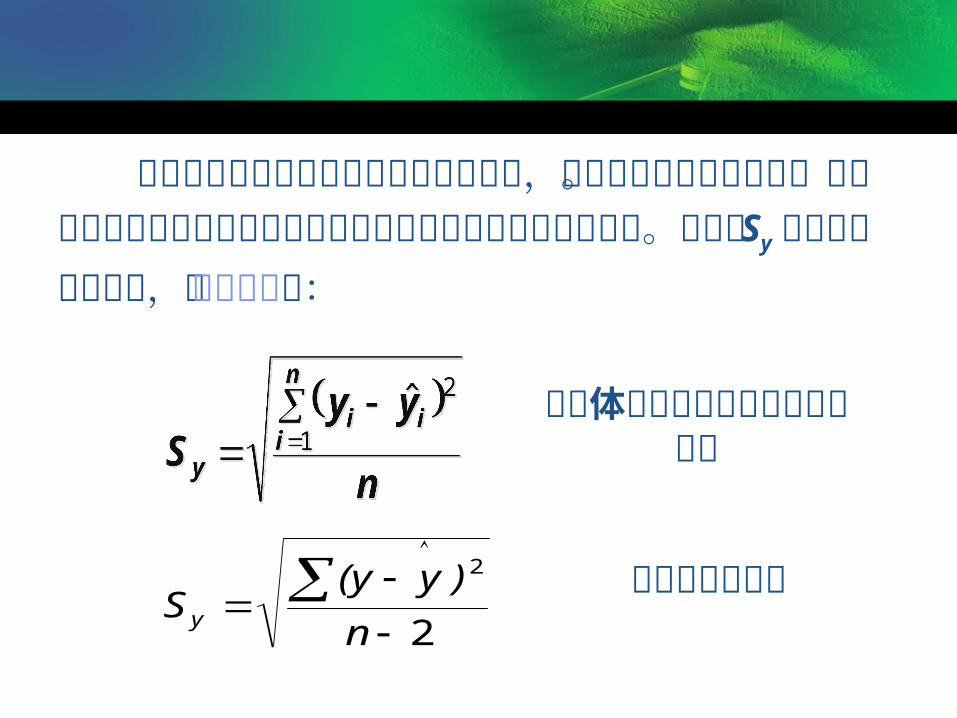
为了度量估计公式即回归方程的可靠性,通常计算估计平均误差。估计平均误差度量观察值回绕着回归直线的变化程度或分散程度。通常用Sy 代表估计平均误差,其计算公式为:
2
2
n
)y(yS y
由样本资料计算
由总体资料计算或在大样本情况下

估计标准误差 Sy 意义
1. 实际观察值与回归估计值离差平方和的均方根。2. 反映实际观察值在回归直线周围的分散状况。3. 从另一个角度说明了回归直线的拟合程度4. 估计标准误差是说明回归方程代表性大小的统计分析指标。
其值小,表明方程代表性大;反之亦然。

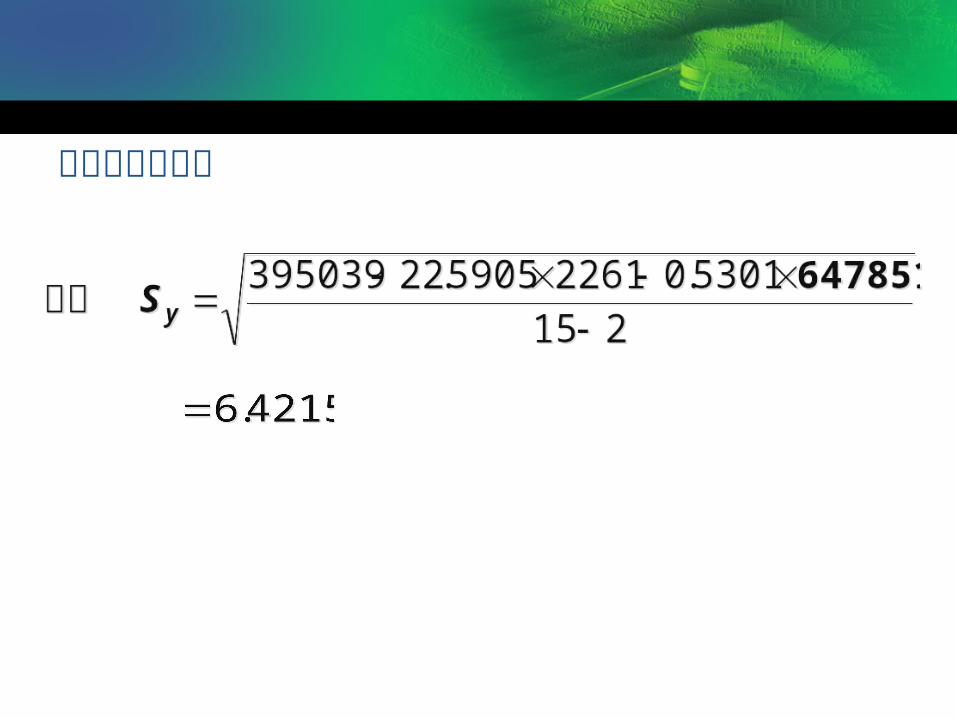
编号 x y y 22.5905+0.5301x 2)ˆ( yy 1 274 162 167.8379 33.9272 2 180 120 118.0085 3.8122 3 375 223 221.3780 2.4849 4 205 131 131.2610 0.0681 5 86 67 68.1791 1.2364 6 265 169 163.0670 35.0466 7 98 81 74.5403 41.4969 8 330 192 197.5235 30.3551 9 195 116 125.9600 98.9707 10 53 55 50.6858 18.4584 11 430 252 250.5335 1.9967 12 372 234 219.7877 201.8362 13 236 144 147.6947 13.4925 14 157 103 105.8162 7.7771 15 370 212 218.7275 45.1054 合计 3626 2261 — 536.0644
)(4215.6215
0644.5362
2)ˆ( 十吨
n
yyQ
S
计算例子

定义公式
计算公式2n
)yy(s
2
yx
2nxybyay
y2
yx
xybyay
xybyaxyb2ya2y
)xbxa(b)xbna(axyb2ya2y
xbxab2naxyb2ya2y
)bxa(y)yy(
2
2
22
2222
22
上式的推导证明
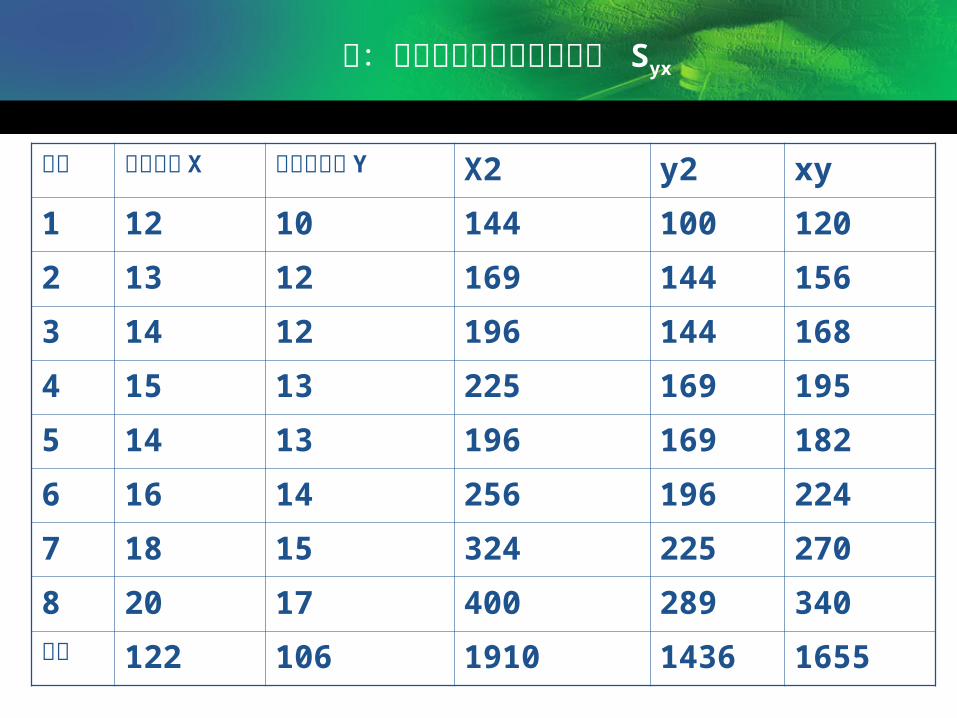
例:现以前例的资料配合计算 Syx
年份 居民收入 X 商品零售额 Y X2 y2 xy
1 12 10 144 100 120
2 13 12 169 144 156
3 14 12 196 144 168
4 15 13 225 169 195
5 14 13 196 169 182
6 16 14 256 196 224
7 18 15 324 225 270
8 20 17 400 289 340合计 122 106 1910 1436 1655

xx
yy(xn , yn)
(x1 , y1)
(x2 , y2)
(xi , yi)
}}ei = yi-yi^^
xy 10ˆˆˆ xy 10ˆˆˆ
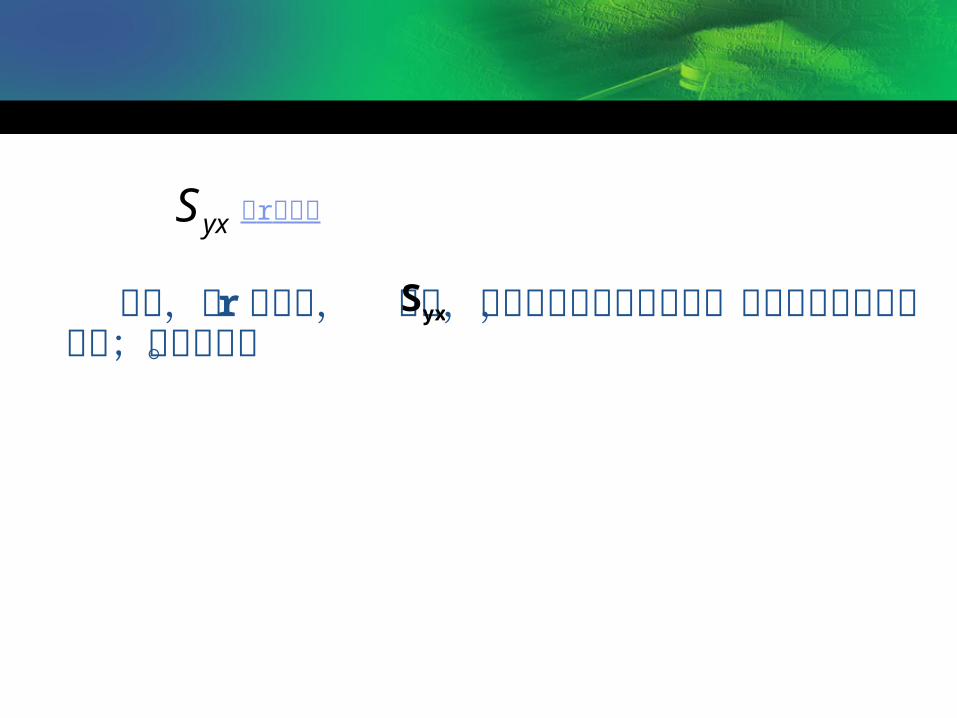
与r的关系yxS
可见,当 r 越大时, 越小,这时相关密切程度较高,回归直线的代表性就大;反之亦然。
yxS

消费行为调查分析报告 :
http://www.dina.com.cn/Report.asp
2008年家用电脑消费行为调查分析报告http://www.dina.com.cn/ShowReportContent1.asp?ID=450
2008年汽车消费幸福指数测评报告 :
http://www.dina.com.cn/ShowReportContent4.asp?ID=479
2008年手机消费行为调查分析报告http://www.dina.com.cn/ShowReportContent1.asp?ID=447
消费行为调查分析报告
