5장. jsp와 servlet 프로그래밍을 위한 기본...
TRANSCRIPT

5. JSP와 Servlet 프로그래밍을 위한 기본 문법
JSP는 Java언어를 기반으로 하여 만들어졌기 때문에
Java언어의 기본적인 문법에 대한 숙지가 어느 정도
필요하다. 특히, 스크립트릿 블록안에는 Java 언어
코딩이 그대로 활용된다는 점 때문에 Java 언어를 능숙하게
작성하는 능력이 있다면 JSP 프로그래밍을 할 때 더 빠르고
더 많은 기능을 수행할 수 있게 된다. 본 절에서는 기본 적인
Java 문법을 살펴보도록 하겠다. 또한 클래스와 객체가
무엇을 의미하는 지에 대해서도 알아보고
간단한 객체지향 프로그래밍을 웹에서
어떻게 구현하는지에 대해서도 살펴본다.
하지만 본 절에서 다루는 내용 외에도
다른 Java 책을 통한 학습 내지 강의 수강을
통하여 더 심도 있는 Java 학습을 할 필요가 있다.
5.1 리터럴 (Literals)과 기본 데이터 타입
5.2 클래스와 객체
5.3 레퍼런스 데이터 타입과 배열
5.4 연산자
5.5 조건문과 반복문
5.6 문자열

5.1. 리터럴 (Literals)과 기본 데이터 타입
5.1.1 리터럴 (Literals)
리터럴은 JSP 소스 코드 내에 표기된 데이터 값 그대로인 상수(Constants)를 지칭한다. 다음
과 같은 상수들이 리터럴의 예이다.
1 01 .7 6 5'A ''/ u 4 4 2 2 '" JS P 프 로 그 래 밍 "
이러한 리터럴의 타입은 자바 컴파일러가 소스 코드를 컴파일할 때 자동으로 할당하는데 그
규칙은 다음과 같다.
- 소수점이 없는 수치 리터럴은 int 타입을 부여한다.
- 소수점이 있는 수치 리터럴은 double 타입을 부여한다.
- 큰따옴표(")로 묶여진 텍스트는 String 타입을 부여한다.
- 작은따옴표(')로 묶여진 문자에는 char 타입을 부여한다.
위의 4가지 규칙에서 주의할 점은 String 타입은 다음 절에 나오는 기본 데이터 타입이 아니
라는 점이다. Java는 Class를 사용하여 기본 데이터 타입이 아닌 레퍼런스 데이터 타입
(Reference Data Type)을 제공하는 데 String 타입과 배열 타입이 레퍼런스 데이터 타입의
대표적인 예이다.
5.1.2 예약어(Reserved Words)
예약어는 Java 언어의 문법을 구성하는 약속 단어라고 정의할 수 있으며 키워드 (Keyword)
라고도 한다. 아래는 Java 언어의 예약어 목록이다. 예약어 목록을 이곳에서 소개하는 이유는
JSP 및 Servlet 프로그래밍 시에 변수명과 같은 식별자로서 예약어를 사용하는 것이 금지되
어 있기 때문이다.

abstract do implements private throw
boolean double import protected throws
break else instanceof public transient
byte extends int return true
case false interface short try
catch final long static void
char finally native super volatile
class float new switch while
continue for null synchronized
default if package this
5.1.3 기본 데이터 타입 (Primitive Data Type)
Java 언어는 데이터 타입을 엄격하게 구분한다. 즉, 숫자 10과 문자열 “10”을 구분하고 숫자
중에서도 10과 10.0은 각각 int와 double로 취급한다. [표 5-1]은 Java 언어의 기본 데이터
타입을 정리하여 보여준다.
데이터 타입 값 기본값 크기 최소값과 최대값
boolean true 또는 false false 1 bit
char Unicode 문자 \u0000 16 bits \u0000 ~ \uffff
byte 부호있는 정수 0 8 bits -128 ~ 127
short 부호있는 정수 0 16 bits -32768 ~ 32767
int 부호있는 정수 0 32 bits-2147483648 ~
2147483647
long 부호있는 정수 0L 64 bits-9223372036854775808 ~
9223372036854775807
float 부동 실수 0.0F 32 bits1.40239846E-45F ~
3.40282347E+38F
double 부동 실수 0.0 64 bits4.94065645841246544E-324 ~
1.79769313486231570E+308
[표 5-1] JSP에서 활용가능한 기본 데이터 타입
위 표에서 기본값 예시 중에 long타입은 0이 아니라 0L이고 float타입은 0.0이 아니라 0.0F임
에 주목하자. 단순한 정수 리터럴인 0은 int타입으로 인식되기 때문에 0L로 표현해야 long타
입인 정수 리터럴이 된다. 같은 이유로서 0.0은 double타입의 실수 리터럴이기 때문에 0.0F로
표현해야 float타입의 실수 리터럴이 된다.

1) 문자타입과 문자 리터럴
문자타입인 char는 작은따옴표를 사용하여 리터럴을 표시한다.
‘A ', 'b ', '한 ', ’9 ‘, ’\ u d 6 5 4 '
위 예에서 마지막 ‘\ud654’가 Unicode 형태의 문자 리터럴이다. Java에서는 문자, 스트링과
변수, 메소드, 클래스 이름 등의 식별자(identifier)등은 모두 16 bit Unicode 문자로 표현된
다. 유니코드의 0x0000부터 0x00ff까지의 문자가 일반적으로 많이 쓰이는 ASCII 코드와 호
환되는 ISO8859-1 (Latin-1)문자 세트와 일치한다. 가령
ch a r a = 'A ';
라고 char타입의 변수 a를 만들면 실제로는 a에 ‘A’의 Unicode인 0x0041이 할당된다. 41은
ASCII 코드 값이기도 하다. 다음 예제를 실행해 보자.
0 10 20 30 40 50 60 70 80 91 01 11 21 31 41 51 61 71 81 9
< % @ p a g e co n te n tT yp e = " te x t/h tm l;c h a rse t= u tf-8 " % >< h tm l>< h e ad >< t it le > 유 니 코 드 예 제 < / t it le >< /h e ad >< b o d y>< % c h a r a = 'A '; o u t .p r in t ln ( ( in t )a + "< b r/> " ) ; o u t .p r in t ln ( (c h a r )6 5 + "< b r/> " ) ; o u t .p r in t ln ( (c h a r )0 x 0 0 4 1 + "< b r/> " ) ; o u t .p r in t ln ( '\ u 0 0 4 1 ' + "< b r/> " ); o u t .p r in t ln ("< h r/> " ) ; o u t .p r in t ln ( ( in t ) '가 ' + "< b r/> " ) ; o u t .p r in t ln ( (c h a r )0 xA C 0 0 + "< b r/> " ) ; o u t .p r in t ln ( '\ u A C 0 0 ' + "< b r/> " );% >< /b o d y>< /h tm l>
[예제 5.1] jspbook\ch05\unicode.jsp
[소스 코드 설명]
08: 변수 a는 자신의 값으로서 Unicode 값인 0x0041을 저장한다.
09: char 타입의 'A' 값을 지닌 변수 a를 10진수로 타입 변환하여 출력한다.

10~11: 10진수 65는 16진수 표기법으로 0x0041이므로 출력결과는 'A'이다.
12: 정확한 Unicode 값 표현으로 '\u0041'을 출력. 출력결과는 역시 'A'이다.
14~16: ‘가’의 Unicode 표현은 '\uAC00'이며 16진수 표현은 '0xAC00' 이다.
[그림 5-1] unicode.jsp의 수행 모습
몇 가지 특수한 문자는 별도의 방법을 사용하여 표현해야 한다. 예를 들어 탭(Tab)을 나타내
는 문자는 '\t'처럼 escape를 나타내는 '\'와 문자 't'를 결합하여 나타낸다. 다음은 각 특수
문자를 표시하는 방법을 정리한 것이다.
- \: \\
- 탭 (Tab): \t
- 새로운 줄 (New Line): \n
- 캐리지 리턴 (Carriage Return): \r
- 작은따옴표 ('): \'
- 큰따옴표 ("): \"
다음 예제는 이러한 특수문자의 사용 방법을 잘 알려준다.

0 10 20 30 40 50 60 70 80 91 01 11 21 31 41 5
< % @ p a g e co n te n tT yp e = " te x t/h tm l;c h a rse t= u tf-8 " % >< h tm l>< h e ad >< t it le > 특 수 문 자 예 제 < / t it le >< /h e ad >< b o d y>< % o u t .p r in t ln ("\ n 줄 바 꿈 \ n \ n 기 능 을 테 스 트 합 니 다 .< b r/> " ) ; o u t .p r in t ln ("\ t탭 기 능 을 \ t테 \ t스 트 합 니 다 < b r/> " ); o u t .p r in t ln ("캐 리 지 리 턴 을 \ r테 스 트 합 니 다 .< b r/> " ) ; o u t .p r in t ln ("\ '작 은 따 옴 표 를 테 스 트 합 니 다 .\ '< b r/> " ) ; o u t .p r in t ln ("\ " 큰 따 옴 표 를 테 스 트 합 니 다 .\ "" ) ;% >< /b o d y>< /h tm l>
[예제 5.2] jspbook\ch05\escape.jsp
[그림 5-2] escape.jsp의 수행 모습
위 escape.jsp의 브라우저 상의 수행 결과에서 '소스보기'를 하였을 때의 내용은 다음과 같다.

< h tm l>< h e ad >< t it le > 특 수 문 자 예 제 < /t it le >< /h e a d >< b o d y>
줄 바 꿈
기 능 을 테 스 트 합 니 다 .< b r/>탭 기 능 을 테 스 트 합 니 다 < b r/>
캐 리 지 리 턴 을 테 스 트 합 니 다 .< b r/>'작 은 따 옴 표 를 테 스 트 합 니 다 .'< b r/>"큰 따 옴 표 를 테 스 트 합 니 다 ."
< /b o d y>< /h tm l>
escape.jsp에서 08, 09, 10라인의 \n, \t, \r 은 각각 새로운 줄, 탭, 캐리지 리턴을 의미하는 데
실제 브라우저 출력에서는 어느 것도 반영이 안된 채 출력되어 있다는 점에 주목하자. 다만
브라우저에서 오른쪽 버튼을 눌러 '소스보기'을 하여 보게 되는 소스에는 반영이 잘 되어있다.
한편, 11, 12라인 작은따옴표와 큰따옴표는 실제 브라우저에서도 출력이 그대로 된다.
2) 정수타입과 정수 리터럴
정수타입에 속하는 것으로는 byte, short, int, long이 있다. 이 중 int 타입이 실제 웹 프로그
래밍에서 많이 활용되며 byte, short, long 타입 등은 잘 사용되지는 않는다. long타입의 리터
럴 값은 반드시 숫자 뒤에 L이나 l을 붙여야 하며 byte와 short타입은 캐스팅을 활용해야 한
다. 다음은 사용방법에 대한 예시이다.
in t a 1= 1 0 , b 1 = 10 0 0 , c 1 = -2 3 4 ;lo n g a 2 = 1 2 3 4 5 6 7 8 9 0 L , b 2 = 2 3 4 5 l;b y te a 3 = (b y te )1 0 ;sh o rt a 4 = (sh o rt )1 0 0 ;
3) 실수타입과 실수 리터럴
실수타입에는 double과 float이 있으며 소수점을 포함한 숫자를 나타낸다. 일반적인 실수 리

터럴은 기본적으로는 double 타입으로 인식되며 float타입으로 인식시키기 위해서는 반드시
숫자 뒤에 F나 f를 명기해야 한다. 예를 들어 다음 예시는 컴파일이 안되는 예시이다.
f lo a t a = 1 2 3 .2 ; (X ) / /T y p e m ism a tch : c a n n o t co n ve r t f ro m d o u b le to f lo a t
위 예시의 올바른 표현은 다음과 같다.
f lo a t a = 1 2 3 .2 F ; (O )f lo a t a = 1 2 3 .2 f ; (O )d o u b le a = 1 2 3 .2 ; (O )
실수타입은 지수형태로도 명기할 수 있다. 예를 들어 129.9는 다음과 같은 지수표현을 가진다.
1 .2 9 9 e 2
실수타입을 브라우저로 출력하게 되면 매우 큰 숫자는 자동으로 지수형태 표기법으로 출력이
된다. 다음 예제를 수행해보자.
0 10 20 30 40 50 60 70 80 91 01 11 21 31 4
< % @ p a g e co n te n tT yp e = " te x t/h tm l;c h a rse t= u tf-8 " % >< h tm l>< h e ad >< t it le > 실 수 타 입 예 제 < / t it le >< /h e ad >< b o d y>< % d o u b le a = 9 .9 9 9 9 e 3 ; d o u b le b = 9 .9 9 9 9 e 3 0 0 ;% >변 수 a 출 력 : < % = a % > < b r/>변 수 b 출 력 : < % = b % > < /b o d y>< /h tm l>
[예제 5.3] jspbook\ch05\floating.jsp
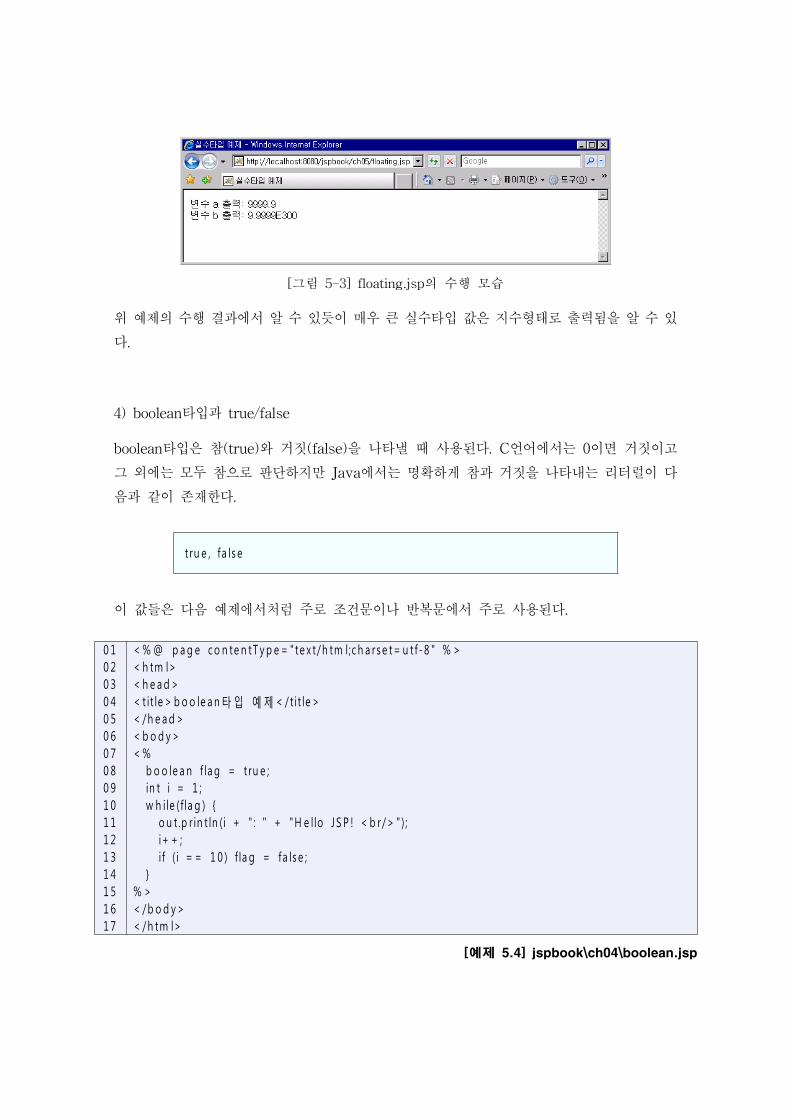
[그림 5-3] floating.jsp의 수행 모습
위 예제의 수행 결과에서 알 수 있듯이 매우 큰 실수타입 값은 지수형태로 출력됨을 알 수 있
다.
4) boolean타입과 true/false
boolean타입은 참(true)와 거짓(false)을 나타낼 때 사용된다. C언어에서는 0이면 거짓이고
그 외에는 모두 참으로 판단하지만 Java에서는 명확하게 참과 거짓을 나타내는 리터럴이 다
음과 같이 존재한다.
t ru e , fa ls e
이 값들은 다음 예제에서처럼 주로 조건문이나 반복문에서 주로 사용된다.
0 10 20 30 40 50 60 70 80 91 01 11 21 31 41 51 61 7
< % @ p a g e co n te n tT yp e = " te x t/h tm l;c h a rse t= u tf-8 " % >< h tm l>< h e ad >< t it le > b o o le a n 타 입 예 제 < /t it le >< /h e ad >< b o d y>< % b o o le a n f la g = t ru e ; in t i = 1 ; w h ile ( f la g ) { o u t .p r in t ln (i + " : " + "H e llo JS P ! < b r/> " ) ; i+ + ; if ( i = = 1 0 ) f la g = fa ls e ; }% >< /b o d y>< /h tm l>
[예제 5.4] jspbook\ch04\boolean.jsp

[그림 5-4] boolean.jsp의 수행 모습
5.1.4 타입 변환 (Type Casting)
타입 변환이란 어떤 타입의 값을 다른 타입으로 바꾸어 사용하는 것이다. Java에서는 서로 일
치하지 않는 타입의 값을 변수에 할당하게 되면 에러를 발생한다. 예를 들어 다음과 같은
Java 구문은 모두 "Type mismatch"에 관한 에러를 발생시킨다.
in t v a lu e 1 = 1 .2 9 ; (X ) / / in t타 입 v a lu e 1변 수 에 d o u b le타 입 값 할 당
flo a t v a lu e 2 = 3 .6 7 ; (X ) / / f lo a t타 입 v a lu e 2변 수 에 d o u b le타 입 값 할 당
sh o rt v a lu e 3 = 3 2 7 6 8 ; (X ) / / sh o r t타 입 v a lu e 3 변 수 에 는 -3 2 7 6 8 ~ 3 2 7 6 7인 정 수 값 만 할 당 가 능
b y te v a lu e 4 = 1 2 8 ; (X ) / / b y te 타 입 v a lu e 4 변 수 에 는 -1 2 8 ~ 12 7 인 정 수 값 만 할 당 가 능
위와 같이 타입을 올바로 사용하지 않으면 에러가 발생하게 되는 데 이러한 서로 다른 타입의
값을 변수에 할당해야 하는 경우가 때에 따라서 필요한 경우가 있다. 이런 경우에는 타입 변
환 (Type Casting)을 통해서 에러 없이 처리가 가능하다. 타입 변환에는 묵시적 타입 변환
(Implicit Type Casting)과 명시적 타입 변환 (Explicit Type Casting)이 있다.
1) 묵시적 타입 변환 (Implicit Type Casting)
각 타입별 범위의 순서는 아래와 같다.
b y te < sh o rt < in t < lo n g < f lo a t < d o u b le

묵시적 타입 변환은 자동 타입 변환 (Automatic Type Casting)이라고도 하며 범위가 작은
타입 값을 범위가 큰 타입 변수에 할당할 때 Java 언어 자체에서 자동으로 타입 변환을 해주
는 것을 의미한다. 다음 예를 보자.
lo n g v a lu e 1 = 1 0 0 ; / / in t 타 입 값 을 묵 시 적 으 로 lo n g 타 입 변 수 에 할 당 가 능
d o u b le v a lu e 2 = 1 0 0 ; / / in t 타 입 값 을 묵 시 적 으 로 d o u b le 타 입 변 수 에 할 당 가 능
d o u b le v a lu e 3 = 2 + 3 ; / / in t 타 입 연 산 결 과 를 d o u b le 타 입 변 수 로 할 당 가 능
위 예와 같이 int 타입의 값 100은 범위가 큰 long 타입 변수와 double 타입 변수에 별도의
절차 없이 간단하게 할당이 가능하다. 이러한 할당 과정에서 int 타입의 값인 100은 각각 long
타입과 double 타입으로 묵시적으로 타입 변환이 된다. 그래서 value2에는 100.0 이라는 실수
가 저장된다.
2) 명시적 타입 변환 (Implicit Type Casting)
명시적 타입 변환은 묵시적 타입 변환과 거꾸로 범위가 큰 타입의 값을 범위가 작은 타입의
변수로 할당할 때 반드시 필요하다. 명시적 타입 변환의 예는 다음과 같다.
lo n g v a lu e 1 = 1 0 0 L ; / / lo n g 타 입 값 을 lo n g 타 입 변 수 에 할 당 (타 입 변 환 없 음 )in t v a lu e 2 = ( in t )v a lu e 1 ; / / lo n g 타 입 값 을 명 시 적 으 로 in t 타 입 변 수 에 할 당
double타입 값을 int 타입 변수에 할당하는 다음 예도 주목하자.
in t v a lu e 3 = ( in t )5 0 0 .4 5 ;
d o u b le d = 9 .9 9 ;in t v a lu e 4 = ( in t )d ;
명시적 타입 변환에서 주의할 점은 값에 대한 손실이 있을 수 있다는 점이다. 위 예에서
value3에는 500이 저장되고 value4에는 9만이 할당된다. 즉, 실수타입을 정수타입으로 명시
적 타입 변환을 하게 되면 소수점 아래 값은 모두 버림에 주의해야 한다.

5.2 클래스와 객체
5.2.1 객체 지향 프로그래밍
1) 객체 지향 프로그래밍의 이점
JSP와 Servlet 프로그래밍은 기본적으로 Java를 활용한다. Java는 객체 지향 프로그래밍 언
어이다. 객체 지향(Object-oriented)을 사용하면 구체적으로 어떤 이익이 있을까? 객체 지향
개념은 실생활의 개념과 거의 동일하다는데 가장 큰 이점이 있다. 어떤 시스템을 구상을 하는
데 있어서 자주 통용되는 말과 생각들을 자연스럽게 컴퓨터에 적용하여 빠르게 그 결과를 볼
수 있는 특징이 있다. [그림 5-5]는 실세계에서 사람이 동전 및 지폐를 은행에 저금하는 상황
이 있다면 이것을 소프트웨어적인 객체로서 사람, 동전, 지폐, 은행으로 표현할 수 있음을 보
여준다.
[그림 5-5] 실세계와 객체 지향 개념
기존의 프로시저(Procedure) 방식과 객체 지향 방식의 차이점으로서 우선 프로그래머가 작성
해야 할 프로그램의 양이 줄어든다는 장점이 있다. 기존의 방식으로 몇 천줄, 몇 만줄 이상의
프로그램도 객체 지향 방식을 이용하면 훨씬 적은 양으로 코딩할 수 있다. 또한, 객체 지향 방
식은 각 객체들마다 완벽한 모듈화를 제공하기 때문에 코드 재사용을 극대화 할 수 있다. 일
례로 프로그램 시작 전에 전체적으로 디자인을 잘 해놓은 상태에서 프로그램 작성을 하고 있
었다고 생각해 보자. 그런데 갑자기 아주 좋은 생각이 떠올라서 기존의 디자인을 바꾸어야 할
필요가 있다고 생각된다면 예전의 방식으로는 지금까지 짜 놓은 프로그램의 상당량을 바꾸어
야 하지만 객체 지향 프로그램은 그렇지가 않다. 단 몇 줄만 바꾸거나 새로운 모듈을 추가하
기만 하면 된다. 이것은 곧 현대 사회에서 가장 중요한 시간을 절약할 수 있다는 의미이다.
프로그램은 만들어지고 패키지화되어 돈을 받고 팔면 그만이 아니다. 반드시 프로그램의 유지
보수가 필요하다. 이러한 프로그램의 유지보수에 상당한 인적, 물적, 시간 자원이 투여되어야
한다. 애초부터 객체 지향적으로 디자인하여 프로그래밍을 하면 좀 더 양질의 프로그램을 만
들 수 있으며 유지보수에도 상당히 편리하다는 것을 느낄 것이다.

객체 지향 프로그래밍의 장점
- 코드 량이 줄어든다.
- 코드 재사용을 원활하게 할 수 있다.
- 코드 수정이 용이하다.
- 유지보수에 편리하다.
2) 객체란 무엇인가?
객체란 그 객체의 속성 및 상태와 관련된 변수와 이러한 속성과 관계된 메소드들의 소프트웨
어 적인 모듈이다. 객체지향 기법을 알기 위해서 가장 기본이 되는 것이 객체이다. 우리 주변
에서 실세계에 존재하는 객체를 많이 볼 수 있다. 강아지, 책상, 텔레비전, 자전거 등이 좋은
예이다. 실세계의 객체는 두 가지 특성을 가지고 있는 것은 상태(state)와 행동(behaviour)이
라는 특성이다. 예를 들어서 강아지는 이름, 색, 품종, 배고픔.. 등 상태를 나타낼 수 있고 멍멍
짖고, 물고, 달리는 행동을 한다. 또한 자전거는 기어가 있고, 페달이 있고, 두개의 바퀴가 있
다는 상태와, 기어를 바꾸고, 속도를 높이고, 정지 하는 행동을 할 수 있다. 실세계의 객체와
마찬가지로 소프트웨어 객체도 상태와 행동이라는 특성을 가지며 이는 각각 변수(property)
와 메소드(method)로 표현 할 수 있다. 소프트웨어 객체는 실세계 객체를 모델링 한 후에 생
겨난 것이기 때문에 실세계의 모든 객체를 프로그래밍을 통해서 소프트웨어 객체로 표현 할
수 있다.
객체는 그 객체의 상태를 나타내는 변수와 행동을 구현하는 메소드
의 소프트웨적인 모듈이다.
객체 = 상태(State) + 행위(Behaviors)
= 속성(Property or Attributes) + 프로시저(Procedure)
= 변수(Variable) + 메소드(Methods)
[그림 5-6]은 일반적인 객체를 표현한 객체 다이어그램이다.
[그림 5-6] 객체 다이어그램
[그림 5-7]은 자동차를 예로 들어 여러 가지 속성들과 메소드를 표현한 객체 다이어그램이다.

[그림 5-7] 자동차 객체 a와 b의 객체 내부 모습
소프트웨어 객체로서의 자동차는 문을 열고, 시동을 걸고, 기어를 바꾸고, 브레이크를 밟는 행
동을 할 수 있다. 한편, 상태 또는 속성으로서 자동차의 색, 소유자, 연식, 번호 등을 지닐 수
있다. 속성은 객체의 특징적인 면들을 기술하며 보통 변수 이름과 그에 해당하는 값들의 쌍으
로 표현된다. 가령 자동차 객체의 ‘소유자’는 그 객체의 변수 이름이며, 그 ‘소유자’ 변수에는
'홍길동'이라는 값이 할당 될 수 있다. 다음 [표 5-2]는 [그림 5-7]에 표현된 자동차 객체 a와
b의 속성 정리표이다.
속성이름 자동차 객체 a 자동차 객체 b
색 흰색 검정색
번호 40너 4837 30겨 1287연식 2005 2008
브레이크 유압 x y
[표 5-2] 두 객체의 다른 속성
위의 다이어그램들은 원자의 핵처럼 안쪽은 속성들이 있고, 외부에 메소드들이 둘러싸고 있다.
이렇게 내부에 있는 속성은 외부로부터 보호되어 있는데 이것을 캡슐화(encapsulation)라고
한다. 일반적으로 캡슐화는 ‘외부로부터 자세한 내부의 정보 및 여러 가지 알고리즘을 숨긴다’
는 의미를 가진다. 예를 들어, 브레이크 유압이 얼마나 되는지는 외부에서 알 필요가 없다는
의미이다. 또한, 자동차의 기어를 변경할 때 기어가 어떻게 바뀌는지 그 원리를 알 필요가 없
다는 의미이다. 내부적인 기어의 메커니즘이 바뀌더라도 이 객체를 사용하는 쪽의 객체들은
그것을 알 필요가 전혀 없다는 의미이기도 하다. 단지 그 다른 쪽의 객체들은 기어를 바꾸는
행동을 예전처럼 행하면 된다. 이러한 캡슐화의 장점은 소프트웨어를 깔끔하고 복잡하지 않게
만들어 준다. 이와 같은 특징을 한마디로 ‘모듈화’ 와 ‘정보숨김’이라는 용어로 정리할 수 있다.

* 모듈화(Modularity)
: 하나의 객체에 대한 원시프로그램(source program)은 다른 객
체의 원시프로그램에 영향을 주지 않고 유지된다.
* 정보숨김(Information hiding)
: 객체는 다른 객체가 외부에서 접촉할 수 있는 공개된 인터페이
스(public interface)를 제공해줌과 동시에 외부에 아무 영향을
주지 않고 자신만의 정보를 처리할 수 있는 기능
3) 클래스와 객체
객체 지향 언어의 가장 중요한 두 가지 요소는 클래스(class)와 객체(object)이다. 보통 인스
턴스(instance)라는 용어가 객체를 대신하기도 하는데 이는 클래스에서 생성된 객체를 가리킬
때 자주 사용한다.
클래스와 객체의 관계는 '자동차 공장'과 '실제 자동차'의 관계와 같다. 자동차 공장은 구체적
으로 정의된 실제 자동차들을 만들어 낼 수 있는 설비시설을 가지고 있다. 즉, 클래스는 객체
가 따라야 하는 디자인 규칙을 지니고 있는 것이다. 다음 말을 명심하자.
임의의 클래스는 특정 객체를 생성하는 공장이다.
객체는 클래스로부터 생성된다. 따라서 객체는 클래스에서 정의한 모든 특성을 가지게 된다.
클래스는 한마디로 객체의 틀(frame)과 같은 역할을 한다. 자동차 공장인 자동차 클래스는 사
용자가 원하는 대로 자동차 객체를 생성할 수 있다. 이 때 사용자는 공장의 내용만 조금 바꾸
어 준다면 그 바뀐 내용이 담긴 새로운 객체를 다시 생성할 수 있는 것이다. 아래 코드는 자동
차 클래스로부터 자동차 객체를 생성해내는 Java 소스 코드이다.
C a r a = n e w C a r ("흰 색 " , "4 0너 4 8 3 7 " , 2 0 0 5 , x ) ;C a r b = n ew C a r ("검 정 색 ", "3 0 겨 1 2 8 7 " , 2 0 0 8 , y ) ;

위 소스에서 객체 변수 a와 b는 Car 타입으로 선언이 된다. 또한 선언과 동시에 new라는 키
워드를 사용하여 바로 객체를 생성하고 있으며 생성과 동시에 각 객체가 가져야 할 속성 값을
할당하고 있다. 변수 a와 b가 Car 타입이 된다는 것을 통해 알 수 있듯이 클래스를 이용하여
새로운 데이터 타입을 정의할 수 있다. 이와 관련된 사항은 5.2절에 자세히 다룬다.
같은 클래스에서 생성된 객체들은 그 나름대로 독립된 속성 값들을 가질 수 있다는 점이 중요
하다. 또한, 프로그래머가 한 객체의 속성 값들을 변경한다 할지라도 다른 객체의 속성 값들은
변경되지 않는다. [표 5-2]은 같은 자동차 클래스에서 생성해 낸 두 개의 객체 '자동차 객체
A'와 '자동차 객체 B'의 속성에 대한 것을 기술하고 있다. 각각의 속성 이름은 같지만 각 속
성 값은 모두 다르다.
Note: object과 instance 용어 정리
object : 보통 Object-Oriented 이론에서 말하는 객체를 지칭할 때나 일반적인 객체
를 통칭할 때 사용
instance : 클래스에서 생성된 객체(object)를 특별히 말함.
4) 메시지 (Message)와 메소드 호출
메소드는 해당 객체의 행동 방식을 정의하기 위해 만들어지며 객체들 사이에 서로 어떤 기능
을 수행하라고 명령할 때 쓰이게 된다. [그림 5-8]은 사람 객체 p가 자동차 객체 a에게 기어
를 바꾸어 달라고 하는 메소드를 호출하는 그림이다. 바로 이러한 메소드 호출을 객체 지향
개념을 설명할 때 메시지를 보내는 것으로 비유하기도 한다.
[그림 5-8] 메소드 호출
메소드는 다음과 같이 그 메소드 호출을 받을 객체의 이름과 그 메소드에서 필요로 하는 인자
로 구성된다.
a .ch a n g eG e a r (3 ) ;

위의 코드는 자동차 객체 a에게 메소드를 호출함을 명시하고 있으며 changeGear(3)과 같이
인자 3을 가진 메소드 이름을 적어 주고 있다. 객체 지향 프로그래밍에서 객체간의 상호접촉
은 이러한 메소드 호출을 통해서 한다.
미리 만들어진 클래스로부터 객체를 생성하고 그 객체들의 메소드를 사용한다고 할 때 그 메
소드는 해당 객체를 구현한 사람들로 인해 만들어진다. Java를 본인 컴퓨터에 설치하게 되면
Sun Microsystem 회사에서 이미 만들어 놓은 매우 많은 클래스가 설치된다. JSP와 Servlet
의 장점은 바로 그러한 풍부한 클래스들을 활용할 수 있다는 것이다. 이러한 클래스들이 지니
고 있는 여러 기능들을 메소드 호출을 통하여 이용할 수 있기 때문에 웹 사이트의 기능을 풍
부하고 다양하게 구현할 수 있다.
5) 상속 (Inheritance)
[그림 5-9] 상속과 클래스 계층도
객체지향 개념은 새로운 클래스를 정의할 때 이미 만들어 놓은 클래스를 이용할 수 있도록 한
다. 예를 들어, 자동차가 갖는 일반적인 상태와 행동들을 자동차 클래스로 정의해 놓고 이 자
동차 클래스를 확장하여 버스만이 갖는 상태와 행동을 추가하여 버스 클래스를 정의하고, 택
시가 갖는 상태와 행동을 추가하여 택시 클래스를 정의하고, 그리고 자가용이 갖는 상태와 행
동들을 추가하여 자가용 클래스를 정의 할 수 있다. 이 때, 자동차 클래스를 슈퍼 또는 상위클
래스(superclass)라 하고 버스 클래스, 택시 클래스, 자가용 클래스 등을 서브 또는 하위클래
스(subclass)라 하며, 이들 간의 관계에 대해 얘기할 때 “하위클래스는 상위클래스를 상속한
다(inherit)”라고 한다. 즉, 하위클래스는 상위클래스가 갖고 있는 모든 속성 및 행위들을 상속
하여 사용할 수 있다. 이러한 상속 관계를 트리로 나타낼 수 있고 이 상속관계 트리를 클래스
계층도(class hierarchy)라고 한다.
상속의 장점으로 상위클래스는 하위클래스들이 가질 수 있는 일반적인 상태와 행동을 정의하
고 있고, 하위클래스는 하위클래스 만이 갖는 특별한 상태와 행동을 정의하도록 함으로써 상
위클래스를 여러 하위클래스들이 재사용할 수 있고 소프트웨어 개발에 드는 비용을 절감할 수
있다.

5.2.2 클래스의 정의
1) 일반적인 클래스 정의 형식
Java에서 클래스를 정의하는 형식은 다음과 같다.
< m o d if ie r> p u b lic c la s s [C la s sn a m e ] < e x te n d s S u p e rc la s sn a m e > < im p le m e n ts In te rfa c e ( , In te rfa c e )> { / /멤 버 변 수 정 의 .. . / /생 성 자 정 의 .. . / /메 소 드 정 의 .. .}
[Classname] 위치에는 현재 정의하려고 하는 클래스 이름을 적는다. < > 안에 있는 것은 옵
션이기 때문에 필요한 경우에만 사용하면 된다. JSP나 Servlet과 프로그래밍에 활용할 새로
운 클래스를 정의하는 것은 주로 자바빈즈(JavaBeans)를 만들기 위해 활용된다. 자바빈즈를
구성할 때 Superclass나 Interface 등을 활용하면서까지 클래스를 정의하는 일은 드물다. 한
편, modifier는 클래스의 성격을 정의하는 것으로서 사용되는 키워드로서 JSP/Servlet 프로
그래밍과 연관된 클래스를 정의할 때에는 대부분 public을 할당한다.
아래는 위의 클래스 정의에 입각하여 코딩한 Point 클래스 정의 예이다.

p u b lic c la s s P o in t { / /멤 버 변 수 정 의 in t x , y ; / /생 성 자 정 의 p u b lic P o in t ( ) { x = 0 ; y = 0 ; } p u b lic P o in t ( in t x , in t y ) { th is .x = x ; th is .y = y ; } / /멤 버 메 소 드 정 의 p u b lic v o id s e tX ( in t xV a lu e ) { x = xV a lu e ; } p u b lic v o id s e tY ( in t y V a lu e ) { y = yV a lu e ; } p u b lic in t g e tX () { re tu rn x ; } p u b lic in t g e tY () { re tu rn y ; } p u b lic v o id m o ve ( in t xV a lu e , in t y V a lu e ) { x + = xV a lu e ; y + = yV a lu e ; }}
위 예에서 생성자 메소드와 일반 멤버 메소드는 모두 public으로 선언된 것에 유의하자. 이는
Point 클래스를 마치 라이브러리처럼 만들어서 이후 JSP 페이지나 Servlet 프로그램에서 관
련 메소드들을 활용하려는 취지이다. 하지만, 멤버 변수에는 public이 붙여있지 않으며 많은
경우 private이 붙어있는 경우도 있다. 이와 같이, 멤버 변수에 private 또는 아무것도 붙이지
않고 생성자 메소드와 멤버 메소드에 public을 붙이는 것은 5.2.1절에서 배운 객체 지향적 특
성을 반영한 것으로 생각하면 된다.
2) 생성자
생성자(Constructor)는 클래스로부터 객체를 생성할 때 호출되는 메소드이다. 위의 Point 클
래스에서는 public Point()로 시작하는 부분과 public Point(int x, int y)로 시작되는 부분이
생성자 정의 부분이다. 즉, 두 개의 생성자가 정의되었다. 생성자 메소드를 정의할 때에는 다
음의 규칙을 따라야 한다.
- 생성자 메소드의 정의는 public으로 시작되어야 한다. private 또는 protected로 시작되거
나 아무것도 안붙이기도 하지만 JSP와 Servlet 프로그래밍과 관련된 클래스를 정의할 때
에는 생성자 앞에 대부분 public을 붙인다.
- 생성자 메소드의 이름은 클래스 이름과 대소문자까지 정확하게 일치한다.

- 생성자 메소드 수행 후 리턴해주는 값이 없다. 그러므로, 생성자 메소드 정의 시작 부분에
리턴 타입에 대한 명시를 하지 않는다.
생성자 메소드를 호출하여 새로운 객체를 생성하는 코드 예는 다음과 같다.
P o in t p = n e w P o in t ( ) ;
P o in t q = n e w P o in t (1 ,2 ) ;
P o in t r ;r= n ew P o in t (1 0 ,2 0 ) ;
위 코드에서 p, q, r 모두 Point 객체 변수이며 각각의 변수에 new 키워드를 활용하면서 동시
에 생성자 메소드를 호출하여 실제 객체를 할당하고 있다.
3) this의 의미 및 역할
위 Point 클래스 정의에서 Point 생성자 메소드 내에 this.x 와 this.y라는 구문에서 this의
의미 및 역할을 알아보자. this는 자기 자신의 객체를 나타내는 것으로서 클래스로부터 새로운
객체를 만들게 되면 그 객체 자신을 가리키는 키워드이다. 그러므로 this.x와 this.y는 그 객체
의 멤버 변수인 x와 y를 가리키게 된다. 특히, 위 예에서 this.x와 this.y를 사용한 이유는 생
성자 메소드의 인자로 int x와 int y를 사용하기 때문이다. 이 때 인자로서의 x, y와 멤버 변
수로서의 x, y를 구분하기 위해서 특별히 멤버 변수 x, y에 대한 지칭을 this.x와 this.y를 사
용하고 있다. 이를 정리하면 다음 그림과 같다.
[그림 5-10] 생성자와 this의 역할

[그림 5-10]은 Point 클래스로부터 p1과 p2 객체를 생성하는 모습을 보여준다. p1 객체를 생
성할 때 호출하는 생성자 메소드에는 인자로서 1과 2를 할당하고 있으며 p2 객체는 3과 4를
할당하고 있다. 각 생성자 메소드는 인자로 받은 그러한 수를 각자의 멤버 변수 x, y에 할당한
다.
만약 생성자 메소드의 인자를 x와 y가 아닌 다른 이름을 사용한다면 내부에서 멤버 변수를
지칭하기 위해 this를 활용할 필요가 없다. 즉, 다음의 생성자 메소드 정의는 기존 정의와 완
전히 동일하다.
p u b lic P o in t ( in t xV a lu e , in t y V a lu e ) { x = xV a lu e ; y = yV a lu e ; }
4) 상속 (Inheritance)
위 Point 클래스의 멤버 변수와 멤버 메소드를 상속받으면서 새로운 클래스를 정의할 수 있
다. 다음 클래스 ColorPoint의 예를 보자.
p u b lic c la s s C o lo rP o in t e x te n d s P o in t { / /멤 버 변 수 정 의 S tr in g co lo r ; / /생 성 자 정 의 p u b lic C o lo rP o in t ( ) { co lo r = "b la c k " ; } p u b lic C o lo rP o in t (S t r in g c o lo r ) { th is .c o lo r = c o lo r ; } / /멤 버 메 소 드 정 의 p u b lic v o id s e tC o lo r (S t r in g c o lo rV a lu e ) { co lo r = co lo rV a lu e ; } p u b lic S t r in g g e tC o lo r( ) { re tu rn c o lo r ; }}
위 ColorPoint 클래스는 color 라는 멤버 변수 1개와 생성자 메소드 2개, 일반 멤버 메소드 2
개를 정의하였다. 하지만 ColorPoint는 Point를 상속하므로 Point 클래스에서 정의한 x, y 멤
버 변수 및 setX(int xValue) 등의 5개의 메소드를 모두 가지고 있다고 생각해도 무방하다.
즉, 위와 같은 ColorPoint가 정의된 이후에 아래와 같은 코딩이 가능하다.

C o lo rP o in t c p = n e w C o lo rP o in t ( ) ;c p .g e tX () ;c p .g e tY () ;c p .m o v e (1 0 0 ,2 0 0 ) ;
상속을 활용한 클래스를 정의한 이후 그 클래스로부터 객체를 생성할 때 호출하는 생성자 메
소드의 내부 동작방법을 [그림 5-11] 및 [그림 5-12]와 함께 이해해 보자.
[그림 5-11] 생성자 호출 순서
[그림 5-11]에서 보이듯이 ColorPoint 객체 cp1은 인자가 없는 생성자인 ColorPoint()를 호
출한다. 이것은 ColorPoint 클래스에 정의된 첫 번째 생성자 메소드를 호출한다. 이 때 중요한
것은 상속을 한 하위 클래스 ColorPoint에서 반드시 상위 클래스 Point로 적당한 생성자 호출
이 발생한다는 점이다. 하위 클래스 ColorPoint 의 생성자 내부에서 특별한 지정이 없었기 때
문에 상위 클래스 Point가 지닌 생성자 중 인자가 없는 기본 생성자가 호출된다. ColorPoint
의 두 번째 객체인 cp2는 String 인자를 받는 생성자를 호출하면서 생성된다. 이것은
ColorPoint 클래스에 정의된 두 번째 생성자 메소드를 호출한다. 역시 이 생성자 메소드에서
도 특별한 지정이 없었기 때문에 상위 클래스 Point가 지닌 생성자 중 인자가 없는 기본 생성
자가 호출된다는 점에 유의하자.
만약 하위 클래스 생성자에서 상위 클래스 생성자 중 특정 생성자를 지정하여 호출하려고 한
다면 [그림 5-12]처럼 super를 사용해야 한다.

[그림 5-12] super를 사용한 상위 클래스의 특정 생성자 호출하기
5) 오버라이딩(overriding)과 오버로딩(overloading)
오버라이딩은 상속과 관련된 것으로서 하위 클래스에서 상위 클래스와 똑같은 프로토타입을
가진 메소드를 다시 재정의하는 것을 의미한다. 아래 예에서 move 메소드는 오버라이딩 메소
드이다. 다시 한번 강조하면 상위 클래스 Point와 하위 클래스 ColorPoint에서 move 메소드
는 그 프로토타입이 정확히 일치한다.
p u b lic c la s s C o lo rP o in t e x te n d s P o in t { / /멤 버 변 수 정 의 S tr in g co lo r ; . . . v o id m o ve ( in t xV a lu e , in t y V a lu e ) { x + = xV a lu e ; y + = yV a lu e ; co lo r = "b la c k " }}
한편, 오버로딩은 상속과는 관련 없는 것으로서 메소드의 이름은 같지만 인자의 개수 또는 타
입이 다른 메소드를 중복정의하는 것을 의미한다. 즉, 하나의 클래스 정의 내에 같은 이름의
메소드가 여러 개 존재하는 것을 의미한다. 이미 Point 클래스와 ColorPoint 클래스 정의에서
중복정의의 예가 존재한다. 그것은 Point 생성자 메소드와 ColorPoint 생성자 메소드이다. 다
음은 move 메소드를 오버로딩한 예제이다.

p u b lic c la s s C o lo rP o in t e x te n d s P o in t { / /멤 버 변 수 정 의 S tr in g co lo r ; . . . p u b lic v o id m o ve ( in t xV a lu e , in t y V a lu e ) { x + = xV a lu e ; y + = yV a lu e ; co lo r = "b la c k " }
p u b lic v o id m o ve ( in t v a lu e ) { x + = va lu e ; y + = v a lu e ; }}
6) 정적 변수와 정적 메소드
정적 변수 (Static Variable)와 정적 메소드 (Static Method)는 객체의 선언 없이 바로 클래
스 이름 뒤에 붙여 활용할 수 있는 것들이다. 예를 들어 아래와 같이 Point 클래스에 num 변
수 선언 앞에 static을 붙여 정적 변수로 선언을 할 수 있다.
p u b lic c la s s P o in t { / /정 적 변 수 정 의 s ta t ic in t n u m = 0 ; .. . / /생 성 자 정 의 p u b lic P o in t ( ) { x = 0 ; y = 0 ; n u m + + ; } p u b lic P o in t ( in t x , in t y ) { th is .x = x ; th is .y = y ; n u m + + ; } / / 정 정 메 소 드 정 의 p u b lic s ta t ic in t g e t In s ta n ce N u m () { re tu rn n u m ; }}

위 예제에서는 생성자를 호출할 때 마다 num 정적 변수 값을 1씩 증가시키고 있다. 그래서,
아래와 같은 코드를 활용하여 Point 클래스에서 생성된 객체의 개수를 파악할 수 있다.
P o in t p 1 = n ew P o in t ( ) ;P o in t p 2 = n ew P o in t (1 0 0 ,2 0 0 ) ;o u t .p r in t ln (P o in t .g e t In s ta n ce N u m ()) ; / / 2 출 력
위와 같은 코드가 수행되면 메모리의 모습은 다음 [그림 5-13]과 같이 만들어진다는 점을 기
억하자. 중요한 것은 num 정적 변수와 getInstanceNum() 정적 메소드 모두 메모리에 적재
된 Point 클래스내부에 존재하며 절대 p1이나 p2의 객체에 존재하지 않는다는 점이다.
[그림 5-13] 정적 변수와 메소드의 메모리 상의 위치
JSP나 Servlet 프로그램을 작성할 때 이미 제공되고 있는 Java 클래스 라이브러리가 제공하
는 메소드를 활용할 때가 많다. 이때에는 반드시 그 메소드가 정적 메소드인지 객체의 멤버
메소드인지를 파악해야 한다. 예를 들어 오늘의 날짜 및 관련된 여러 가지 기능을 지닌
Calendar 클래스로부터 객체를 만들어 낼 때에는 new 키워드를 사용하지 않고 반드시
getInstance() 메소드를 이용해야 한다. 이 메소드가 정적 메소드인지 객체 멤버 메소드인지
알아내려면 일반적으로 Java SE API 문서1)를 활용한다.
1) Java SE 6 버전인 경우 http://java.sun.com/javase/6/docs/api/ 레퍼런스
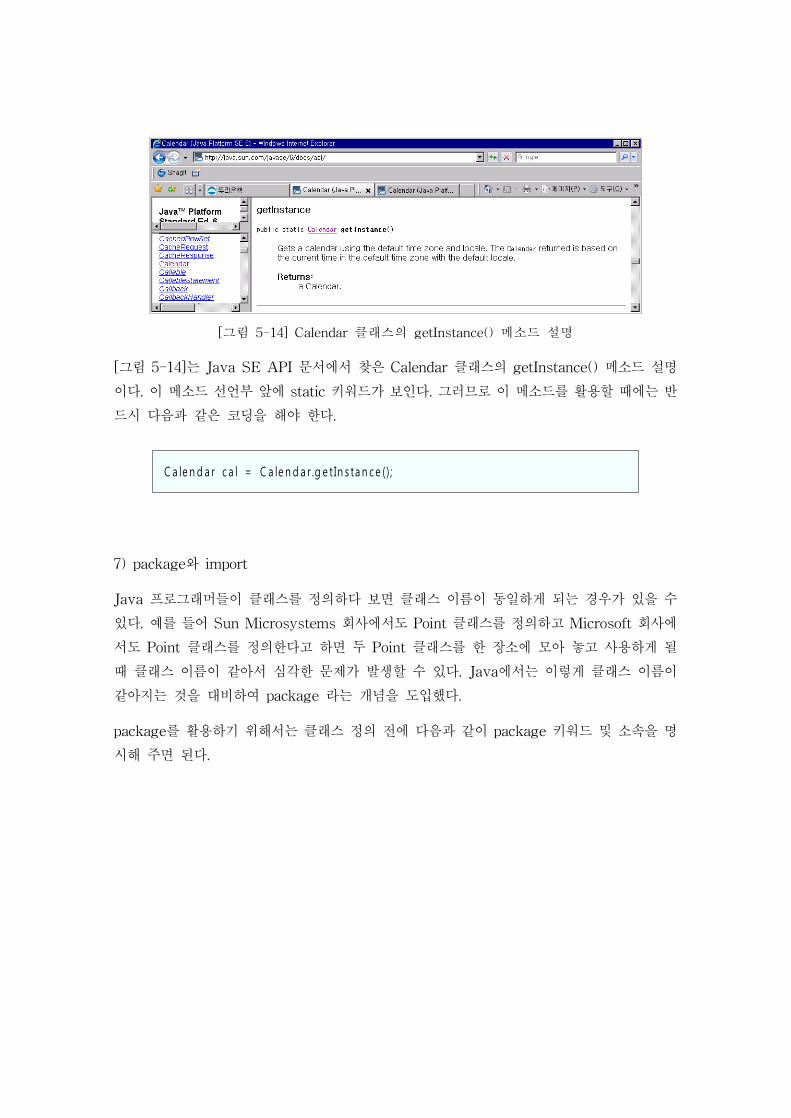
[그림 5-14] Calendar 클래스의 getInstance() 메소드 설명
[그림 5-14]는 Java SE API 문서에서 찾은 Calendar 클래스의 getInstance() 메소드 설명
이다. 이 메소드 선언부 앞에 static 키워드가 보인다. 그러므로 이 메소드를 활용할 때에는 반
드시 다음과 같은 코딩을 해야 한다.
C a le n d a r c a l = C a le n d a r .g e t In s ta n ce () ;
7) package와 import
Java 프로그래머들이 클래스를 정의하다 보면 클래스 이름이 동일하게 되는 경우가 있을 수
있다. 예를 들어 Sun Microsystems 회사에서도 Point 클래스를 정의하고 Microsoft 회사에
서도 Point 클래스를 정의한다고 하면 두 Point 클래스를 한 장소에 모아 놓고 사용하게 될
때 클래스 이름이 같아서 심각한 문제가 발생할 수 있다. Java에서는 이렇게 클래스 이름이
같아지는 것을 대비하여 package 라는 개념을 도입했다.
package를 활용하기 위해서는 클래스 정의 전에 다음과 같이 package 키워드 및 소속을 명
시해 주면 된다.

p a c k a g e th in ko n w e b .lib ;
p u b lic c la s s P o in t { / /멤 버 변 수 정 의 in t x , y ; / /생 성 자 정 의 p u b lic P o in t ( ) { x = 0 ; y = 0 ; } . . .}
위 예에서 Point 클래스의 소속은 thinkonweb.lib 라고 명시되었다. 이로써 위에서 정의한
Point 클래스의 정확한 이름은 thinkonweb.lib.Point 이며 이것을 특별하게 Point 클래스의
Fully-qualified Name (완전한 이름) 이라고도 일컫는다. 위 클래스를 컴파일하면 클래스가
위치하게 될 폴더에 thinkonweb이라는 폴더가 만들어지고 그 하위에 lib 폴더가 만들어지며
lib 폴더 안에 Point.class 가 위치하게 된다.
이후 위 Point 클래스를 이용하려면
th in k o n w eb .lib .P o in t p 1 = n e w th in k o n w e b .lib .P o in t ( ) ;th in k o n w eb .lib .P o in t p 2 = n e w th in k o n w e b .lib .P o in t (1 0 0 ,2 0 0 );
와 같이 Fully-qualified Name을 활용해야 한다. 하지만, Fully-qualified Name을 계속하여
사용하는 것은 다소 불편하기 때문에 아래와 같이 import 키워드를 활용하여 일반적인 클래
스 이름을 사용하는 것이 가능하다.
im p o rt th in k o n w e b .lib .P o in t ;
P o in t p 1 = n ew P o in t ( ) ;P o in t p 2 = n ew P o in t (1 0 0 ,2 0 0 ) ;
위 예에서 import 뒤에 thinkonweb.lib.Point처럼 Point 클래스 이름까지 정확하게 붙이면서
import 키워드를 활용할 수도 있고 다음처럼 *를 붙일 수도 있다. *를 붙이는 것은
thinkonweb.lib 밑에 있는 모든 클래스를 활용하겠다는 의도이다.

im p o rt th in k o n w e b .lib .* ;
P o in t p 1 = n ew P o in t ( ) ;P o in t p 2 = n ew P o in t (1 0 0 ,2 0 0 ) ;
이상 학습한 내용을 바탕으로 실제 클래스를 정의하여 컴파일하여 보자. 다음의 Point.java를
코딩하여 javabook\WEB-INF\java_sources 폴더에 저장한다. 3장 Servlet 예제와 마찬가
지로 모든 java 소스는 한 곳에 모아두는 곳이 좋으며 본 교재에서는 위 폴더에 저장하기로
약속한다.

0 10 20 30 40 50 60 70 80 91 01 11 21 31 41 51 61 71 81 92 02 12 22 32 42 52 62 72 82 93 03 1
p a c k ag e th in k o n w e b .lib ;
p u b lic c la s s P o in t { s ta t ic in t n u m ;
in t x , y ;
p u b lic P o in t ( ) { x = 0 ; y = 0 ; n u m + + ; } p u b lic P o in t ( in t x , in t y ) { th is .x = x ; th is .y = y ; n u m + + ; }
p u b lic v o id s e tX ( in t xV a lu e ) { x = xV a lu e ; } p u b lic v o id s e tY ( in t y V a lu e ) { y = yV a lu e ; } p u b lic in t g e tX () { re tu rn x ; } p u b lic in t g e tY () { re tu rn y ; } p u b lic v o id m o ve ( in t xV a lu e , in t y V a lu e ) { x + = xV a lu e ; y + = yV a lu e ; }
p u b lic s ta t ic in t g e t In s ta n ce N u m () { re tu rn n u m ; }}
[예제 5.5] jspbook\WEB-INF\java_sources\Point.java
04: 정적변수 정의
06: 멤버변수 정의
08~17: 생성자 정의
19~26: 멤버메소드 정의
28~30: 정적메소드 정의
위 클래스 정의를 컴파일하기 위하여 다음과 같이 cmd창에서 우선 해당 폴더로 이동한다.
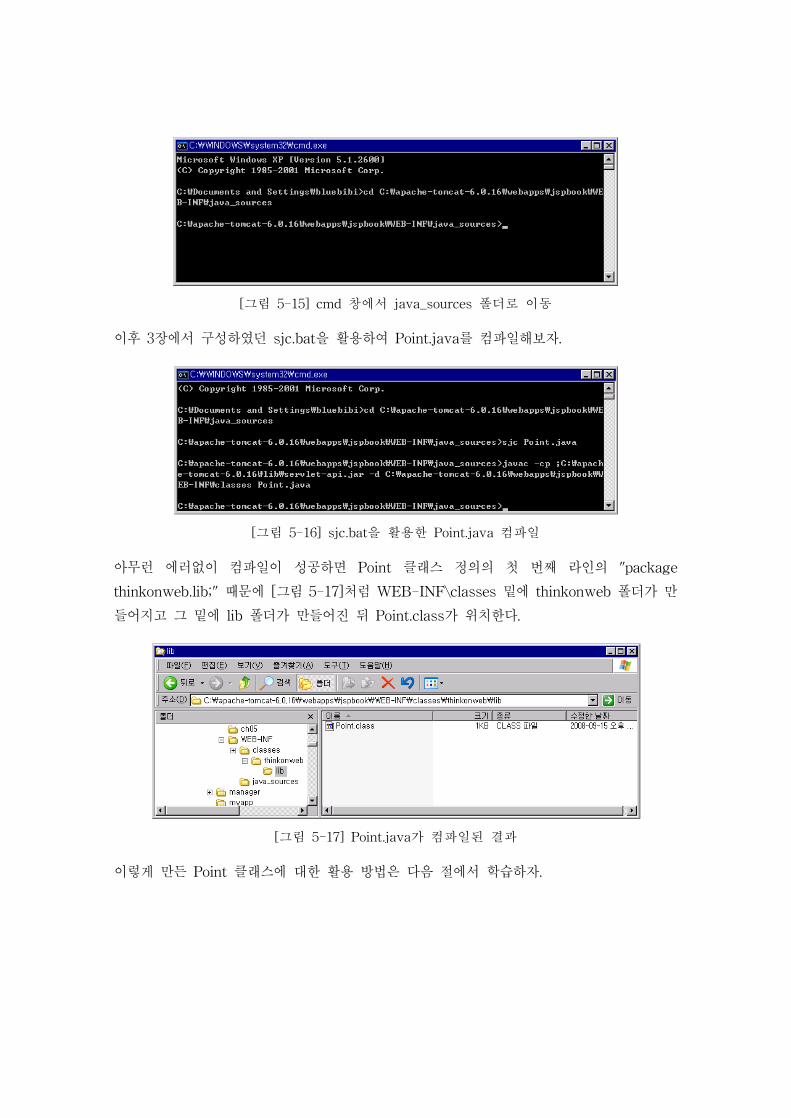
[그림 5-15] cmd 창에서 java_sources 폴더로 이동
이후 3장에서 구성하였던 sjc.bat을 활용하여 Point.java를 컴파일해보자.
[그림 5-16] sjc.bat을 활용한 Point.java 컴파일
아무런 에러없이 컴파일이 성공하면 Point 클래스 정의의 첫 번째 라인의 "package
thinkonweb.lib;" 때문에 [그림 5-17]처럼 WEB-INF\classes 밑에 thinkonweb 폴더가 만
들어지고 그 밑에 lib 폴더가 만들어진 뒤 Point.class가 위치한다.
[그림 5-17] Point.java가 컴파일된 결과
이렇게 만든 Point 클래스에 대한 활용 방법은 다음 절에서 학습하자.

5.3 레퍼런스 데이터 타입과 배열
5.3.1 레퍼런스 데이터 타입 (Reference Data Type)
Java에는 C언어와 같은 포인터가 없기 때문에 JSP 프로그래밍 작성 시에도 포인터에 대해
신경 쓸 필요가 없다. 하지만, 객체를 생성해서 객체의 레퍼런스를 변수에 저장하여 그 객체에
접근하는 방법이 사용된다. 레퍼런스 (Reference)라는 단어는 이와 같이 객체를 참조한다는
것을 의미하는 것으로서 다음 예에서 변수 a, b, c, d, e는 레퍼런스 데이터 타입 변수이다.
S tr in g a ;
S t r in g b = n u ll ;
S t r in g c = "H e llo " ;
D a te d = n e w D a te () ;
C a le n d a r e = C a le n d a r .g e t In s ta n ce () ;
모든 레퍼런스 데이터 타입의 변수의 기본 값은 null이다. 위의 예에서 a에는 묵시적으로 null
이 할당된다. 하지만, b처럼 레퍼런스 데이터 타입 변수에 아무런 데이터 값을 할당하지 않을
때에는 명시적으로 null을 할당하는 것이 일반적인 관례이다.
레퍼런스 데이터 타입을 직접 개발자가 만들고 JSP에서 활용이 가능하다. 레퍼런스 데이터
타입을 개발자가 직접 만든다는 것은 5.2.2절에서 배운 새로운 클래스를 정의하는 것과 매우
관련이 깊다. 즉, 이미 [예제 5.5]에서 만든 Point 클래스에 대한 컴파일이 성공적으로 끝나게
되면 Tomcat 시스템 내에서는 Point 레퍼런스 데이터 타입이 구성되어 있는 것이다.
이번 절에서는 Point 레퍼런스 데이터 타입을 활용하는 예제를 jsp 페이지로 구현해 보자.

0 10 20 30 40 50 60 70 80 91 01 11 21 31 41 51 61 71 81 92 02 12 2
< % @ p a g e co n te n tT yp e = " te x t/h tm l;c h a rse t= u tf-8 " % >< % @ p a g e im p o rt= " th in k o n w eb .lib .* " % >< h tm l>< h e ad > < t it le > 레 퍼 런 스 데 이 터 타 입 테 스 트 < /t it le > < /h e ad >< b o d y>< % P o in t p 1 = n e w P o in t ( ) ; P o in t p 2 = n e w P o in t (1 0 , 2 0 ) ;% >Th e n u m b e r o f P o in t in s ta n ce s : < % = P o in t .g e t In s ta n ce N u m ()% > < b r/>
p 1 's x : < % = p 1 .g e tX () % > < b r/>p 1 's y : < % = p 1 .g e tY () % > < b r/>p 2 's x : < % = p 2 .g e tX () % > < b r/>p 2 's y : < % = p 2 .g e tY () % > < b r/>< % p 1 .m o v e (1 0 0 ,2 0 0 );% >p 1 's x : < % = p 1 .g e tX () % > < b r/>p 1 's y : < % = p 1 .g e tY () % > < b r/>< /b o d y>< /h tm l>
[예제 5.6] jspbook\ch05\usepoint.jsp
02: Point 클래스 활용위한 import 지시문 추가
07~08: Point 객체 p1과 p2 생성
10: Point 클래스로부터 정적 메소드 활용
12~20: p1과 p2 객체의 멤버 메소드 활용
[그림 5-18] usepoint.jsp 수행 모습
5.3.2 배열 (Array)
배열은 같은 타입의 자료를 여러 개 연속적으로 나열하여 저장하는 자료구조를 말한다. Java

에서의 배열은 역시 레퍼런스 데이터 타입으로서 일종의 객체임에 주목해야 한다. 배열의 선
언 규칙은 다음과 같다.
- 배열로 선언되는 변수를 정할 때는 비어있는 대괄호 [ ]를 활용한다.
- new 연산자를 통해 메모리를 할당받는다.
- 대괄호 [ ] 내에 정수를 지정함으로써 배열에 할당할 수 있는 요소개수를 지정한다.
[그림 5-19] 배열 선언
선언된 배열을 이용할 때에는 인덱스가 0부터 시작하며 배열의 길이를 알아보려면 배열명 뒤
에 '.length'라는 붙여서 알아볼 수 있다. 'length'는 모든 배열 객체가 가지고 있는 멤버변수
이다. 다음은 배열을 활용하는 예제이다.
[그림 5-20] 배열 선언 예제 실행 모습

0 10 20 30 40 50 60 70 80 91 01 11 21 31 41 51 61 71 81 92 02 12 2
< % @ p a g e co n te n tT yp e = " te x t/h tm l;c h a rse t= u tf-8 " % >< h tm l>< h e ad > < t it le > 배 열 테 스 트 < / t it le > < /h e a d >< b o d y>< % in t [ ] f ib o n a c c i = n e w in t [5 ]; in t le n g th A rra y ; f ib o n a c c i[0 ] = 0 ; f ib o n a c c i[1 ] = 1 ; f ib o n a c c i[2 ] = f ib o n a c c i[0 ] + fib o n a c c i[1 ] ; f ib o n a c c i[3 ] = f ib o n a c c i[1 ] + fib o n a c c i[2 ] ; f ib o n a c c i[4 ] = f ib o n a c c i[2 ] + fib o n a c c i[3 ] ; le n g th A rra y = fib o n a c c i.le n g th ;% >fib o n a c c i 배 열 의 내 용 : < % fo r ( in t i = 0 ; i < 5 ; i+ + ) { % >< % = fib o n a c c i[ i] % >< % } % >< b r/>f ib o n a c c i 배 열 의 길 이 : < % = le n g th A rra y % > < b r/>< /b o d y>< /h tm l>
[예제 5.7] jspbook\ch05\arraytest.jsp
06: 배열 선언
07: 추후 배열 길이를 할당받을 변수 선언
08~12: 배열에 값 할당
13: 배열의 길이를 lengthArray에 할당

5.4 연산자
Java는 다른 프로그래밍 언어와 마찬가지로 수치 연산, 비교 연산자, 비트 연산자 등을 풍부
하게 제공한다. 그러므로 JSP 및 Servlet 코딩 시에도 그러한 풍부한 연산자를 활용할 수 있
다.
5.4.1 수치 연산자
수치 연산자는 int나 double과 같은 숫자 타입에 적용되는 연산자로서 사칙 연산자 및 나머지
를 구해 주는 연산자가 있다. 이들 연산자는 [표 5-3]에 정리되어 있다.
연산자 설명
+ 두 값을 더한다.
- 한 값에서 다른 값을 뺀다.
* 두 값을 곱한다.
/ 한 값을 다른 값으로 나눈다.
% 한 값을 다른 값으로 나눈 나머지를 구한다.
[표 5-3] Java의 수치 연산자
다음 예제는 수치연산자의 기본적인 사용방법을 알려준다.
0 10 20 30 40 50 60 70 80 91 01 11 21 31 41 51 6
< % @ p a g e co n te n tT yp e = " te x t/h tm l;c h a rse t= u tf-8 " % >< h tm l>< h e ad > < t it le > 수 치 연 산 자 예 < /t it le > < /h e ad >< b o d y>< % in t o p e ra n d 1 = 8 ; in t o p e ra n d 2 = 3 ; o u t .p r in t ln (o p e ra n d 1 + " + "+ o p e ra n d 2 + " = " + (o p e ra n d 1 + o p e ra n d 2 ) + "< b r/> " ) ; o u t .p r in t ln (o p e ra n d 1 + " - "+ o p e ra n d 2 + " = " + (o p e ra n d 1 - o p e ra n d 2 ) + "< b r/> " ) ; o u t .p r in t ln (o p e ra n d 1 + " * "+ o p e ra n d 2 + " = " + (o p e ra n d 1 * o p e ra n d 2 ) + "< b r/> " ); o u t .p r in t ln (o p e ra n d 1 + " / "+ o p e ra n d 2 + " = " + (o p e ra n d 1 / o p e ra n d 2 ) + "< b r/> " ) ; o u t .p r in t ln (o p e ra n d 1 + " % "+ o p e ra n d 2 + " = " + (o p e ra n d 1 % o p e ra n d 2 ) + "< b r/> " ) ;% >< /b o d y>< /h tm l>
[예제 5.8] jspbook\ch05\mathoperator.jsp

[그림 5-21] mathoperator.jsp의 수행 모습
mathoperator.jsp 예제에서 8 / 3 의 계산 결과는 원래 2.666... 이지만 8과 3이 int 형이기 때
문에 그 결과도 int형로서 2만 출력되는 점을 주의하자. 즉, 2.666... 결과의 소수점 부분을 모
두 버리는 형태로 int형으로 변환된다.
5.4.2 증가/감소 연산자
증감 연산자는 정수 값을 1 증가시키거나 1 감소시킬 때 사용되며 [표 5-4]와 같이 네 가지
형태가 있다.
연산자 설명
++operand operand의 값을 1만큼 증가시킨 후 operand를 처리한다.
--operand operand의 값을 1만큼 감소시킨 후 operand를 처리한다.
operand++ operand를 처리한 후 operand의 값을 1 증가시킨다.
operand-- operand를 처리한 후 operand의 값을 1 감소시킨다.
[표 5-4] Java의 증가/감소 연산자
operand가 연산자 앞에 붙는지 뒤에 붙는지에 따라서 그 사용 방법이 달라진다. "++operand"
형태는 먼저 1 증가된 이후에 전체 문장이 수행되며 "operand++"형태는 전체 문장이 수행된
이후에 1 증가된다. 다음 예제를 잘 이해해 보자.

0 10 20 30 40 50 60 70 80 91 01 11 21 31 41 51 61 71 81 9
< % @ p a g e co n te n tT yp e = " te x t/h tm l;c h a rse t= u tf-8 " % >< h tm l>< h e ad > < t it le > + + 및 -- 연 산 자 사 용 < /t it le > < /h e ad >< b o d y>< % in t i = 0 ; in t j = 0 ;% >첫 번 째 i 값 = < % = i+ + % > < b r/>두 번 째 i 값 = < % = i % > < b r/>세 번 째 i 값 = < % = + + i % > < b r/>네 번 째 i 값 = < % = i % >< h r/>첫 번 째 j 값 = < % = j- - % > < b r/>두 번 째 j 값 = < % = j % > < b r/>세 번 째 j 값 = < % = -- j % > < b r/>네 번 째 j 값 = < % = j % >< /b o d y>< /h tm l>
[예제 5.9] jspbook\ch05\incdec.jsp
[그림 5-22] incdec.jsp의 수행 모습
5.4.3 비교 연산자
두 숫자 중에서 어느 값이 큰 지 또는 두 숫자가 같은 지와 같이 두 값을 비교해야 하는 경우
가 있는데 이럴 때 사용되는 것이 비교 연산자이다. 비교 연산자의 결과 값은 boolean타입이
다. 피연산자1과 피연산자2를 비교하고 결과 값으로 참(true) 또는 거짓(false)을 리턴한다.
Java에서 제공하는 비교 연산자는 [표 5-5]와 같다.

연산자 설명
a == b a와 b가 같을 경우 참(true), 다를 경우 거짓(false)
a != b a와 b가 다를 경우 참(true), 같을 경우 거짓(false)
a > b a가 b보다 클 경우 참(true), 그렇지 않을 경우 거짓(false)
a >= b a가 b보다 크거나 같을 경우 참(true), 그렇지 않을 경우 거짓(false)
a < b a가 b보다 작을 경우 참(true), 그렇지 않을 경우 거짓(false)
a <= b a가 b보다 작거나 같을 경우 참(true), 그렇지 않을 경우 거짓(false)
[표 5-5] Java의 비교 연산자
5.4.4 논리 연산자
논리 연산자는 참(true)과 거짓(false)를 논리적으로 비교하는 연산자로서 [표 5-6]과 같다.
A B A && B의 결과 A || B의 결과
참(true) 참(true) 참(true) 참(true)
참(true) 거짓(false) 거짓(false) 참(true)
거짓(false) 참(true) 거짓(false) 참(true)
거짓(false) 거짓(false) 거짓(false) 거짓(false)
[표 5-6] Java의 논리 연산자
&&연산자는 피연산자인 A와 B가 모두 참(true)일 때만 참(true)이 되며 그렇지 않은 경우는
모두 거짓(false)이 된다. || 연산자는 피연산자인 A와 B중에 하나만 참(true)이 되어도 참
(true)을 결과로 주며 둘 다 거짓(false)일 경우만 거짓(false)을 결과로 리턴한다.
&&와 ||연산자는 여러 조건을 동시에 검사하고자 할 때 사용된다. 예를 들어, 변수 A의 값이
1이상이고 100미만인지의 여부를 판단할 때에는 다음과 같이 && 논리연산자를 사용하면 된
다. 다음 비교식은 A값이 1이상 100미만이면 참(true)을, 그렇지 않으면 거짓(false)을 리턴한
다.
A > = 1 & & A < 10 0
|| 연산자는 피연산자 중에 하나만 참이 되면 결과가 참이 되기 때문에 피연산자 1과 피연산자
2가 있을 경우에 피연산자 1이 참이면 피연산자 2가 참, 거짓 여부를 판단하지 않고 바로 참
을 리턴한다. 다음 예제를 통해 &&연산자와 ||연산자에 대해 배워보자.

0 10 20 30 40 50 60 70 80 91 01 11 21 31 41 51 61 71 8
< % @ p a g e co n te n tT yp e = " te x t/h tm l;c h a rse t= u tf-8 " % >< h tm l>< h e ad > < t it le > 논 리 연 산 자 < / t it le > < /h e a d >< b o d y>< % in t i = 0 ; in t j = 1 ; if (+ + i= = j & & + + i= = + + j) o u t .p r in t ln (" t ru e < b r/> " );% >i 값 = < % = i % > < b r>j 값 = < % = j % > < b r>< % if (+ + i= = + + j | | + + i= = j) o u t .p r in t ln (" t ru e < b r/> " ) ;% >i 값 = < % = i % > < b r>j 값 = < % = j % >< /b o d y>< /h tm l>
[예제 5.10] jspbook\ch05\logic.jsp
[그림 5-23] logic.jsp의 수행 모습
logic.jsp에서 && 연산자는 피연산자 1과 피연산자 2를 모두 비교하기 때문에 &&연산자에
서 i와 j의 값은 증감연산자에 의하여 값이 2가 되어 "true"가 출력된다. 그러나 || 연산자에서
는 ++i와 ++j의 값이 참(true)이기 때문에 || 논리 연산자 이후의 식인 "++i==j"는 실행되지
않고 바로 "true"가 출력되며 i와 j의 값은 3이 된다.
5.4.5 할당 연산자
할당 연산자는 지금까지 별다른 언급 없이 계속해서 사용해 온 연산자로서 = 연산자가 바로
할당 연산자이다. 할당 연산자는 기본 데이터 타입 변수에 새로운 값을 저장하거나 레퍼런스
데이터 타입 변수에 새로운 클래스 인스턴스를 할당한다. 예를 들어, 아래 코드는 a라는 변수
에 10이라는 값을 저장한다.

a=10;
할당 연산자에는 단순히 변수에 값을 할당해 주는 = 연산자뿐만 아니라 다른 연산자와 함께
사용되는 것이 존재한다. 다른 연산자와 함께 사용되는 할당 연산자는 [표 5-7]과 같다.
연산자 설명 동일한 표현 방법
op1 += op2 op1에 op2를 더한 후 그 결과를 op1에 저장한다. op1 = op1 + op2
op1 -= op2 op1에 op2를 뺀 후 그 결과를 op1에 저장한다. op1 = op1 - op2
op1 *= op2 op1과 op2를 곱한 결과를 op1에 저장한다. op1 = op1 * op2
op1 /= op2 op1에 op2로 나눈 결과를 op1에 저장한다. op1 = op1 / op2
op1 %= op2 op1을 op2로 나눈 나머지를 op1에 저장한다. op1 = op1 % op2
[표 5-7] Java의 할당 연산자
5.4.6 연산자의 우선순위
연산자 우선순위는 어떤 연산을 먼저 처리하고 어떤 연산을 나중에 처리할 것인가에 대한 기
준을 의미한다. [표 5-8]은 Java에서의 연산자 우선순위를 정리하여 보여준다.
우선순위 명칭 연산자 연산방향
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
1차 연산자
선위형 증감 및 단항 연산자
수치(승법) 연산자
수치(가법) 연산자
Shift 연산자
비교(관계) 연산자
비교(등가) 연산자
bit(곱) 연산자
bit(차) 연산자
bit(합) 연산자
논리(곱) 연산자
논리(합) 연산자
조건 연산자
할당 연산자
후위형 증감 연산자
순차 연산자
. [] ()
++ -- ! ~
* / %
+ -
<< >>
< > <= >=
== !=
&
^
|
&&
||
? :
= += -= *= /= %= &= ^= |= >>= <<=
++ --
,
←
→
→
→
→
→
→
→
→
→
→
←
←
→
→
[표 5-8] Java의 연산자 우선순위
위에서 소개된 연산자 중에 별도로 소개하지 않은 연산자들은 JSP 및 Servlet 코딩을 할 때

사용빈도가 극히 낮다. 예를 들어 bit 연산자 및 Shift 연산자들은 웹 프로그래밍에서는 활용
할 일이 거의 없다. 하지만, 웹 프로그래밍의 수준이 높아지고 web 2.0 지향의 추천시스템 및
분석 시스템이 들어 있는 웹 사이트는 고차원적인 프로그래밍 기술이 요구되기 때문에 다른
전문적인 Java 학습서와 함께 프로그래밍 실력을 쌓을 필요가 있다.

5.5 조건문과 반복문
5.5.1 조건문
임의의 주어진 조건을 만족해야지만 어떠한 작업을 수행토록 하는 경우에는 조건문을 사용한
다.
1) if 문
<형태 1>
if (조 건 ) { 코 드 ; / / 조 건 비 교 의 결 과 값 이 참 (tru e )인 경 우 에 코 드 를 수 행}
가장 기본적인 조건문의 형태로서 조건에는 비교 연산자 및 논리 연산자를 사용한 코드가 위
치한다. 조건의 결과 값이 true일 경우 블록 안의 코드를 실행한다.
<형태 2>
if (조 건 ) { 코 드 1 ; / / 조 건 이 참 (tru e )인 경 우 에 수 행} e lse { 코 드 2 ; / / 조 건 이 거 짓 (fa ls e )일 경 우 에 수 행}
조건의 평가 결과 값이 참인 경우와 거짓인 경우에 따로따로 수행하는 코드를 "코드 1"과 "코
드 2"로서 만들 수 있다.
<형태 3>
if (조 건 1 ) { 코 드 1 ; / / 조 건 1 이 참 (tru e )인 경 우 에 수 행} e ls e if (조 건 2 ) { 코 드 2 ; / / 조 건 1 이 거 짓 (fa lse )이 고 조 건 2 가 참 (tru e )인 경 우 에 수 행} e ls e { 코 드 3 ; / / 조 건 1 과 조 건 2가 모 두 거 짓 (fa ls e )인 경 우 에 수 행}
여러 개의 조건을 검사할 수 있는 형태로서 else if에 따라오는 "조건 2"는 위 블록의 "조건

1"이 만족하지 않은 경우에만 평가가 된다. 역시 모든 if 조건이 거짓(false)일 경우에는 else
블록 안에 코드가 실행된다. 다음 예제를 통해서 if 문을 학습해 보자.
0 10 20 30 40 50 60 70 80 91 01 11 21 31 41 51 61 7
< % @ p a g e co n te n tT yp e = " te x t/h tm l;c h a rse t= u tf-8 " % >< h tm l>< h e ad > < t it le > if 문 < /t it le > < /h e ad >< b o d y>< % in t n u m = 5 ; o u t .p r in t ("n u m = " ) ;
if (n u m = = 2 ) { o u t .p r in t ln ("2 " ) ; }e ls e if (n u m = = 5 ) o u t .p r in t ln ("5 " ) ; e ls e { o u t .p r in t ln ("n u ll" ) ; }% >< /h tm l>
[예제 5.11] jspbook\ch05\if.jsp
[그림 5-24] if.jsp의 수행 모습
2) switch~case문
주어진 조건에 대한 각각의 경우에 따라서 별개의 문장을 수행한다. switch문의 기본 형태는
다음과 같다.

sw itch (조 건 식 ) { c a se 상 수 1 : 문 장 1 ; b re a k ; c a se 상 수 2 : 문 장 2 ; b re a k ; c a se 상 수 n : 문 장 n ; b re a k ; d e fa u lt : 문 장 ;}
switch문은 조건식의 결과 값에 해당하는 경우(case)를 찾아서 수행하고 break를 통하여 종
료된다. 해당하는 경우가 없을 경우에는 default의 문장이 수행된다. switch문에서 break는
생략이 가능하지만 break를 쓰지 않을 경우에 해당하는 경우(case)의 다음 경우들도 모두 수
행이 되어 버린다. switch문의 조건식에 올 수 있는 변수의 데이터 타입은 byte, short, char
와 int 타입이다. 한편, 기본 데이터 타입의 "Wrap" 형태의 레퍼런스 데이터 타입인 Byte,
Short, Character, Integer 타입의 변수도 올 수 있다.
다음 예제는 간단한 switch~case문 예제이다.

0 10 20 30 40 50 60 70 80 91 01 11 21 31 41 51 61 71 81 92 02 12 22 32 4
< % @ p a g e co n te n tT yp e = " te x t/h tm l;c h a rse t= u tf-8 " % >< h tm l>< h e ad > < t it le > sw itch 문 < /t it le > < /h e ad >< b o d y>< % in t n u m = 1 2 /3 ; o u t .p r in t ("n u m = " ) ;
sw itch (n u m ){ c a s e 1 : o u t .p r in t ln ("1 " ) ; b re a k ; c a s e 2 : o u t .p r in t ln ("2 " ) ; b re a k ; c a s e 4 : o u t .p r in t ln ("4 " ) ; b re a k ; d e fa u lt : o u t .p r in t ln ("d e fa u lt" ) ; b re a k ; }% >< /h tm l>
[예제 5.12] jspbook\ch05\switch.jsp
12, 15, 18: break문은 반드시 삽입
19~21: 가급적 default에 대한 수행문을 삽입
[그림 5-25] switch.jsp의 수행 모습
다음은 switch ~ case문을 사용하여 주어진 연도와 달에 대하여 그 달의 총 일수를 알려주
는 프로그램이다.

0 10 20 30 40 50 60 70 80 91 01 11 21 31 41 51 61 71 81 92 02 12 22 32 42 52 62 72 82 93 03 13 23 33 43 53 63 7
< % @ p a g e co n te n tT yp e = " te x t/h tm l;c h a rse t= u tf-8 " % >< h tm l>< h e ad > < t it le > sw itch 문 활 용 예 제 < / t it le > < /h e a d >< b o d y>< % in t m o n th = 2 ; in t y e a r = 2 0 0 9 ; in t n u m D a y s = 0 ;
sw itch (m o n th ) { c a s e 1 : c a s e 3 : c a s e 5 : c a s e 7 : c a s e 8 : c a s e 1 0 : c a s e 1 2 : n u m D a y s = 3 1 ; b re a k ; c a s e 4 : c a s e 6 : c a s e 9 : c a s e 1 1 : n u m D a y s = 3 0 ; b re a k ; c a s e 2 : if ( ((y e a r % 4 = = 0 ) & & !(y e a r % 1 0 0 = = 0 )) || (y e a r % 4 0 0 = = 0 ) )
n u m D a y s = 2 9 ; e ls e
n u m D a y s = 2 8 ; b re a k ; d e fa u lt : b re a k ; }% >< % = y e a r % > 년 < % = m o n th % > 의 총 일 수 는 < % = n u m D a y s % > 일 입 니 다 .< /h tm l>
[예제 5.13] jspbook\ch05\numdays.jsp
11~19: month값이 1,3,5,7,8,10,12 일 경우 numDays는 31로 할당
20~25: month값이 4,6,9,11 일 경우 numDays는 30로 할당
27~31: month값이 2인 경우 윤년에 대한 판단 및 numDays 설정

[그림 5-26] numdays.jsp의 수행 모습
5.5.2 반복문
반복적인 작업을 처리할 때에는 for 문과 while 문, 그리고 do~while 문을 사용한다. 이 세
가지 중에서 어떤 것을 사용해서 반복처리를 하더라도 같은 기능을 수행할 수 있도록 구현할
수 있다. 일반적으로 세 가지 반복문의 주된 사용 용도는 다음 [표 5-9]와 같다.
반복문 사용법
for반복할 횟수가 정해진 경우에 주로 사용된다. 예를 들어, 배열의 각 요소를
반복해서 처리한다거나 지정한 횟수만큼 처리가 필요한 경우에 사용된다.
while반복할 횟수가 정해져 있지 않은 경우에 주로 사용된다. 경우에 따라서 한번
도 실행되지 않을 수가 있다.
do~while반복할 횟수가 정해져 있지 않은 경우에 주로 사용된다. 최소한 한번은 실행
된다.
[표 5-9] 각 반복문의 사용법
1) for 문
일반적으로 많이 쓰이는 반복문으로서 기본 형태는 다음과 같다.
fo r (초 기 값 ; 조 건 식 ; 증 감 식 ){ 반 복 할 문 장 ; / / 조 건 식 이 참 인 경 우 에 수 행}
위 for 문 형태에서 초기값, 반복 조건, 증감식의 역할은 다음과 같다.
▪ 초기값: 루프 제어변수를 초기화 한다. (단 1회만 수행)
▪ 반복 조건: 루프 제어변수의 범위를 검사하여 조건식이 참일 동안 반복한다. 초기값을

할당한 직후에도 반복 조건 검사를 수행하여 조건이 거짓이면 루프 내 문장
을 수행하지 않는다.
▪ 증감식: 루프 제어변수를 증가 또는 감소시킨다. 루프 제어변수 초기화 이후 루프 내 문
장을 수행한 이후부터 증감식이 수행된다.
다음은 for 문을 이용하여 구구단 2단을 출력해주는 예제이다.
0 10 20 30 40 50 60 70 80 91 01 1
< % @ p a g e co n te n tT yp e = " te x t/h tm l;c h a rse t= u tf-8 " % >< h tm l>< h e ad > < t it le > fo r문 을 이 용 한 구 구 단 2단 < / t it le > < /h e a d >< b o d y>< % in t i = 2 ; fo r( in t j= 1 ; j< 1 0 ; j+ + ){ o u t .p r in t ln (i + " * " + j + " = " + ( i* j) + "< b r/> " ) ; } % >< /h tm l>
[예제 5.14] jspbook\ch05\for.jsp
[그림 5-27] for.jsp의 수행 모습
위 프로그램에서는 j값이 1부터 9까지 증가하며 반복하는 동안 i값과 j값을 곱하여 구구단 2단
의 결과를 출력한다.
2) while 문
while 문은 조건식이 참(true)인 동안 반복하여 내부코드를 실행한다. while문의 기본 형태는
다음과 같다.

w h ile (조 건 식 ) { 반 복 할 문 장 ; / / 조 건 식 이 참 인 경 우 에 수 행}
while 문은 반복되는 실행 코드 안에서 반복 조건을 탈출할 수 있도록 처리해 주어야 한다.
조건식만을 통해서 반복문을 탈출할 수 없을 경우에는 while문 안에 break를 주어서 반복문
을 탈출할 수 있다. 다음 예제는 while문을 이용하여 구구단 5단을 출력해주는 예제이다.
0 10 20 30 40 50 60 70 80 91 01 11 21 3
< % @ p a g e co n te n tT yp e = " te x t/h tm l;c h a rse t= u tf-8 " % >< h tm l>< h e ad > < t it le > w h ile문 을 이 용 한 구 구 단 5 단 < /t it le > < /h e ad >< b o d y>< % in t i = 5 ; in t j = 1 ; w h ile (j< 1 0 ) { o u t .p r in t ln (i + " * " + j + " = " + ( i* j) + "< b r/> " ) ; j+ + ; }% >< /h tm l>
[예제 5.15] jspbook\ch05\while.jsp
[그림 5-28] while.jsp의 수행 모습
3) do~while 문
while 문과 마찬가지로 조건식이 참인 동안에 반복된다. while문과의 차이점은 조건식의 참,
거짓과 상관없이 처음 한번은 무조건 수행이 된다는 점이다. do ~ while문의 기본 형태는 다
음과 같다.

d o { 반 복 할 문 장 ; / / 한 번 수 행 후 조 건 식 이 참 인 경 우 에 수 행} w h ile (조 건 식 );
다음은 do~while문을 이용하여 구구단 9단을 출력해주는 예제이다.
0 10 20 30 40 50 60 70 80 91 01 11 21 3
< % @ p a g e co n te n tT yp e = " te x t/h tm l;c h a rse t= u tf-8 " % >< h tm l>< h e ad > < t it le > d o ~ w h ile문 을 이 용 한 구 구 단 9 단 < /t it le > < /h e ad >< b o d y>< % in t i = 9 ; in t j = 1 ; d o { o u t .p r in t ln (i + " * " + j + " = " + ( i* j) + "< b r/> " ) ; j+ + ; } w h ile ( j< 1 0 ) ;% >< /h tm l>
[예제 5.16] jspbook\ch05\dowhile.jsp
[그림 5-29] dowhile.jsp의 수행 모습
4) 반복문에서 break문과 continue문의 사용
반복문을 사용하다 보면 어떤 조건이 만족되는 상황인 경우에 해당 반복문을 그만 수행되길
원할 때가 있다. 이런 경우에 사용할 수 있는 것이 바로 break이다. break는 반복문 블록 안

에서 사용되며 break를 만나는 순간 곧바로 반복문이 종료된다. 일반적으로 break는 다음과
같이 사용된다.
w h ile (조 건 식 1 ) { .. . if (조 건 식 2 ) b re a k ; .. .}
즉, "조건식 1"이 계속해서 참(true)이 되어 반복문이 계속해서 수행되지만 어느 순간 "조건식
2"가 참(true)로 만족되어서 결국 반복문을 빠져나올 수 있다. 예를 들어, 1부터 10 사이의 임
의의 숫자를 10회 뽑는데 만약 뽑은 숫자가 5가 나오면 반복을 끝내는 JSP 프로그램을 생각
해 보자. 이 경우 뽑은 숫자가 5인지의 여부를 판단해서 break를 사용하면 된다.
0 10 20 30 40 50 60 70 80 91 01 11 21 31 41 5
< % @ p a g e co n te n tT yp e = " te x t/h tm l;c h a rse t= u tf-8 " % >< % @ p a g e im p o rt = " ja v a .u t il .R a n d o m " % >< h tm l>< h e ad > < t it le > b re a k 예 < /t it le > < /h e ad >< b o d y>< % R a n d o m ra n d o m = n e w R an d o m () ; fo r ( in t i = 1 ; i < = 1 0 ; i+ + ) { in t n u m b e r = ra n d o m .n e x t In t (1 0 ) + 1 ; o u t .p r in t ln (i + "번 째 값 : " + n u m b e r + "< b r/> " ) ; if (n u m b e r = = 5 ) b re a k ; }% >< /b o d y>< /h tm l>
[예제 5.17] jspbook\ch05\break.jsp
[그림 5-30] break.jsp의 수행 모습
break.jsp의 수행모습과 같이 원래 10번째 값까지 출력이 되어야 하지만 임의로 뽑은 값이 5

가 나왔을 때는 반복문이 종료되어 7번째 값에서 더 이상 출력되지 않은 것을 확인할 수 있다.
break가 반복문 전체를 멈추는 것과 달리 continue는 현재 실행되는 반복을 멈추고 다음 반
복으로 넘어간다. break와 마찬가지로 반복문 블록 안에서 사용된다. 일반적으로 continue는
다음과 같이 사용된다.
w h ile (조 건 식 1 ) { .. . if (조 건 식 2 ) c o n t in u e ; .. .}
d o { .. . if (조 건 식 2 ) c o n t in u e ; .. .} w h ile (조 건 식 1 );
fo r (초 기 값 ; 조 건 식 1 ; 증 감 식 ){ .. . if (조 건 식 2 ) c o n t in u e ; .. .}
위와 같은 형태에서 조건식 2가 만족되면 continue가 수행되며 곧바로 프로그램의 흐름은
while 문에서는 조건식 1로 가며, for문에서는 증감식으로 이동된다. 즉, 조건식 2를 지니고
있는 if 문장의 아래 부분은 수행되지 않는다.
1부터 10 사이의 임의의 숫자를 10회 뽑는데 만약 뽑은 숫자가 5가 나오면 결과를 출력하지
않는 JSP 프로그램을 생각해 보자. 이 경우 뽑은 숫자가 5인지의 여부를 판단해서 continue
를 사용한다.

0 10 20 30 40 50 60 70 80 91 01 11 21 31 41 5
< % @ p a g e co n te n tT yp e = " te x t/h tm l;c h a rse t= u tf-8 " % >< % @ p a g e im p o rt = " ja v a .u t il .R a n d o m " % >< h tm l>< h e ad > < t it le > co n t in u e 예 < /t it le > < /h e ad >< b o d y>< % R a n d o m ra n d o m = n e w R an d o m () ; fo r ( in t i = 1 ; i < = 1 0 ; i+ + ) { in t n u m b e r = ra n d o m .n e x t In t (1 0 ) + 1 ; if (n u m b e r = = 5 ) co n t in u e ; o u t .p r in t ln (i + "번 째 값 : " + n u m b e r + "< b r/> " ) ; }% >< /b o d y>< /h tm l>
[예제 5.18] jspbook\ch05\continue.jsp
[그림 5-31] continue.jsp의 수행 모습
comtinue.jsp의 수행 모습을 보면 1부터 10사이의 값 중에서 1번째 값, 5번째 값, 7번째 값이
출력되지 않은 것을 확인할 수 있다. 그러한 값들이 출력되지 않은 이유는 임의의 숫자가 5가
나온 경우에 continue를 통하여 예제의 11라인을 수행하지 않았기 때문이다.

5.6 문자열
5.6.1 문자열 리터럴과 문자열 객체
java.lang.String 클래스는 Java에서 문자열을 나타내는 클래스이다. 기본 데이터 타입인
char는 하나의 글자만을 표현하는 반면에 String 클래스는 한 개 이상의 문자가 합쳐져 있는
문자열을 나타낼 때 사용하는 레퍼런스 데이터 타입이다. 문자열 리터럴을 표현할 때에는 다
음과 같이 문자열을 큰따옴표로 둘러싼다. 또한, 문자열은 java.lang.String 클래스의 인스턴
스로서 다음과 같이 String 레퍼런스 데이터 타입 변수에 할당할 수 있다.
S tr in g s t r = " js p b o o k 웹 어 플 리 케 이 션 "; / / 문 자 열 리 터 럴 할 당
한편, 일반적인 객체 생성 방법으로 new 키워드를 활용하여 String 레퍼런스 데이터 타입 변
수에 문자열 객체를 할당할 수 있다.
S tr in g s t r = n e w S tr in g (" js p b o o k 웹 어 플 리 케 이 션 "); / / 문 자 열 객 체 할 당
바로 이점에서 Java는 문자열을 다소 독특하게 다룬다. 다음 예제를 실행해보자.
0 10 20 30 40 50 60 70 80 91 01 11 21 31 41 51 61 71 81 9
< % @ p a g e co n te n tT yp e = " te x t/h tm l;c h a rse t= u tf-8 " % >< h tm l>< h e ad >< t it le > S tr in g 동 일 성 판 단 예 제 < /t it le >< /h e ad >< b o d y>< % S tr in g s t r1 = " jsp b o o k 웹 어 플 리 케 이 션 "; S t r in g s t r2 = " jsp b o o k 웹 어 플 리 케 이 션 "; S t r in g s t r3 = n e w S tr in g (" jsp b o o k 웹 어 플 리 케 이 션 ");% >s tr1 = = s t r2 : < % = s tr1 = = s t r2 % > < b r/>s tr1 = = s t r3 : < % = s tr1 = = s t r3 % > < b r/>s tr2 = = s t r3 : < % = s tr2 = = s t r3 % > < b r/>s tr1 .e q u a ls (s t r2 ) : < % = s tr1 .e q u a ls (s t r2 ) % > < b r/>s tr1 .e q u a ls (s t r3 ) : < % = s tr1 .e q u a ls (s t r3 ) % > < b r/>s tr2 .e q u a ls (s t r3 ) : < % = s tr2 .e q u a ls (s t r3 ) % > < b r/>< /b o d y>< /h tm l>
[예제 5.19] jspbook\ch05\stringTest.jsp

[그림 5-32]는 stringTest.jsp를 수행한 모습이다.
[그림 5-32] stringTest.jsp의 수행 모습
stringTest.jsp 수행 모습의 첫 번째 줄에서 알 수 있듯이 같은 문자열 리터럴은 서로 다른
변수에 할당되더라도 그 변수는 같은 리터럴을 가리킨다. 즉, == 테스트에 의하여 true가 나
온다. 하지만, 두 번째 줄과 세 번째 줄에서 알 수 있듯이 new 키워드를 사용해서 객체화하여
할당한 변수에는 아무리 그 내용이 같다고 할지라도 다른 것이 할당된다. 결론적으로 문자열
리터럴과 문자열 객체는 그 내용이 같다고 할지라도 근본적으로 다르다.
한편, 문자열 객체가 가지고 있는 equals()라는 메소드는 객체가 지니고 있는 내용이 같은지
를 검사하는 메소드이다. 그래서, 위 수행 모습의 네 번째부터 여섯 번째까지의 출력내용에서
알 수 있듯이 equals() 테스트는 모두 true로 결과가 나온다.
5.6.2 여러 메소드를 통하여 문자열 다루기
문자열은 자신이 지닌 각 글자의 위치를 나타내기 위하여 인덱스(index)를 사용하는데 인덱스
는 0부터 시작한다. 예를 들어 "Hello, World"라는 문자열에서 각 문자의 인덱스는 다음과 같
다.
각 문 자 H e l l o , W o r l d
인 덱 스 0 1 2 3 4 5 6 7 8 9 1 0 1 1
한글이 섞여 있는 문자열인 "안녕 JSP!"에서의 인덱스는 다음과 같다.
각 문 자 안 녕 J S P !
인 덱 스 0 1 2 3 4 5 6

한글도 역시 한문자에 하나의 인덱스가 할당됨을 유의하자. 그리고 혹시 C언어에 익숙해져 있
는 개발자라면 문자열 맨 뒤에 '/0'이 있다고 생각하면 안 된다.
String 클래스는 자시이 지니고 있는 문자열에 대해서 여러 가지 작업을 할 수 있는 다양한
메소드를 제공하고 있으며 각 메소드에 대한 설명은 [표 5-10]에 정리되어 있다.
메소드 리턴타입 설명
length() int문자열의 길이를 리턴한다. 맨 마지막 인덱스에 대
해 1이 더해진 값이 리턴된다.
charAt(int index) char 지정한 인덱스에 위치한 문자를 리턴한다.
indexOf(String str) int
자신이 지닌 문자열에서 주어진 문자열 str과 정확
히 일치하는 곳이 있는지 확인한 후 일치하는 첫
번째 문자의 인덱스를 리턴한다. str이 일치되지
않을 경우 -1을 리턴한다.
indexOf(String str, int index) int
자신이 지닌 문자열에서 index에 해당하는 문자
이후에 주어진 문자열 str과 정확히 일치하는 곳이
있는지 확인한 후 일치하는 첫 번째 문자의 인덱
스를 리턴한다. str이 일치되지 않을 경우 -1을 리
턴한다.
indexOf(char ch) int
자신이 지닌 문자열에서 문자 ch의 첫 번째 인덱
스를 리턴한다. 문자 ch가 존재하지 않을 경우 -1
을 리턴한다.
indexOf(char ch, int index) int
자신이 지닌 문자열에서 index에 해당하는 문자
이후에 문자 ch의 첫 번째 인덱스를 리턴한다. 문
자 ch가 존재하지 않을 경우 -1을 리턴한다.
substring(int i) String자신이 지닌 문자열에서 인덱스 i부터 끝까지의 부
분 문자열을 리턴한다.
substring(int i, int j) String자신이 지닌 문자열에서 인덱스 i 부터 j-1 까지의
부분 문자열을 리턴한다.
equals(String str) boolean자신이 지닌 문자열과 주어진 문자열 str이 같은
내용을 지니고 있을 경우 true를 리턴한다.
compareTo(String str) int
자신이 지닌 문자열과 주어진 문자열 str이 같은
내용을 지닌 경우 0을 리턴한다. 유니코드 상으로
자신이 지닌 문자열이 앞에 위치한 경우에는 음수
를 리턴하고 주어진 문자열 str이 앞에 위치한 경
우에는 양수를 리턴한다.
[표 5-10] String 클래스가 제공하는 메소드
[표 5-10]에 있는 각 메소드를 사용하여 자신이 지니고 있는 문자열에 여러 가지 작업을 하는
다음 예제를 살펴보자.

0 10 20 30 40 50 60 70 80 91 01 11 21 31 41 51 61 71 81 92 02 12 22 32 42 52 62 72 82 93 03 13 23 33 4
< % @ p a g e co n te n tT yp e = " te x t/h tm l;c h a rse t= u tf-8 " % >< h tm l>< h e ad >< t it le > S tr in g 메 소 드 예 제 < /t it le >< /h e ad >< b o d y>< % S tr in g s t r1 = " f r is t s t r in g " ; S t r in g s t r2 = "se co n d s t r in g " ; S t r in g s t r3 = " JS P 프 로 그 래 밍 !" ;% >s tr1 : < % = s tr1 % > < b r/>s tr2 : < % = s tr2 % > < b r/>s tr3 : < % = s tr3 % > < b r/>< h r/>s tr1 .le n g th () : < % = s tr1 .le n g th () % > < b r/>s tr2 .le n g th () : < % = s tr2 .le n g th () % > < b r/>s tr3 .le n g th () : < % = s tr3 .le n g th () % > < b r/>< h r/>s tr1 .c h a rA t (4 ): < % = s tr1 .c h a rA t (4 ) % > < b r/>s tr1 .in d e xO f(" in g " ) : < % = s tr1 .in d e xO f(" in g " ) % > < b r/>s tr1 .in d e xO f(" s t" , 4 ) : < % = s tr1 .in d e xO f(" s t" , 4 ) % > < b r/>s tr2 .in d e xO f( 's ') : < % = s tr2 .in d e xO f('s ') % > < b r/>s tr2 .in d e xO f( 's ' , 4 ) : < % = s tr2 .in d e xO f('s ' , 4 ) % > < b r/>s tr3 .in d e xO f("프 로 그 래 밍 "): < % = s tr3 .in d e xO f("프 로 그 래 밍 ") % > < b r/>< h r/>s tr1 .s u b s tr in g (6 ) : < % = s tr1 .su b s tr in g (6 ) % > < b r/>s tr2 .s u b s tr in g (4 , 9 ) : < % = s tr2 .su b s tr in g (4 , 9 ) % > < b r/>s tr3 .s u b s tr in g (4 ) : < % = s tr3 .su b s tr in g (4 ) % > < b r/>< h r>s tr1 .e q u a ls (s t r2 ) : < % = s tr1 .e q u a ls (s t r2 ) % > < b r/>s tr1 .c o m p a re T o (s t r2 ) : < % = s tr1 .co m p a re T o (s t r2 ) % > < b r/>< /b o d y>< /h tm l>
[예제 5.19] jspbook\ch05\stringTest2.jsp
stringTest2.jsp의 08〜10 라인에서 str1, str2, str3가 내부적으로 관리하는 각 문자와 인덱
스는 다음과 같다.
각 문 자 f i r s t s t r i n g
인 덱 스 0 1 2 3 4 5 6 7 8 9 1 0 1 1

각 문 자 s e c o n d s t r i n g
인 덱 스 0 1 2 3 4 5 6 7 8 9 1 0 1 1 1 2
각 문 자 J S P 프 로 그 래 밍 !
인 덱 스 0 1 2 3 4 5 6 7 8 9
실행 결과는 아래 그림과 같다. 각 메소드와 위에 표시한 각 문자열의 인덱스를 비교해가면서
실행 결과를 살펴보기 바란다.
[그림 5-33] usestring.jsp의 수행 모습
5.6.2 StringTokenizer 클래스와 문자열
StringTokenizer 클래스는 문자열을 분할할 수 있는 개체를 생성할 수 있는 클래스이다. 문
자열을 여러 개의 문자열로 분할하는 작업을 파싱(parsing)이라고 한다. 이 때 나누는 단위가
되는 문자열이 토큰(Token)이다. 토큰을 나누는 문자를 구분 문자라 하며 보통 클래스로부터
객체를 생성할 때 구분 문자를 지정할 수 있다. 구분문자의 기본 값은 공백문자 하나를 포함
한 문자열 (" ") 이다. 다음은 StringTokenizer 객체를 생성하는 구문 예이다.

S tr in g T o k e n iz e r s t = n e w S tr in g T o k e n iz e r("2 0 0 8 -9 -6 /토 요 일 ", " - / " ) ;
위 생성자의 두 번째 인자는 토큰 구분문자를 여러 개 지닌 문자열이다. 즉, 빼기부호('-')와
나누가 부호('/') 모두를 토큰 구분자로 지정한다. 그러므로 “2008-9-6/토요일” 문자열을 토
큰화하면 위 st 객체는 “2008”, “9”, “6”, “토요일”을 토큰으로 지니게 된다.
StringTokenizer 타입을 지닌 객체에서 문자열을 파싱하는데 사용하는 메소드는 [표 5.11]과
같다.
메소드 리턴타입 설명
countTokens() intStringTokenizer 객체에 대하여 nextToken() 메소드를 호
출할 수 있는 회수를 리턴한다.
hasMoreTokens() booleanStringTokenizer 객체 내의 문자열로부터 이용할 수 있는
토큰이 존재하는 경우 true를 리턴한다.
nextToken() StringStringTokenizer 객체 내의 문자열로부터 다음의 토큰을
리턴한다.
[표 5-11] StringTokenizer 클래스가 제공하는 메소드
[표 5-11]에 있는 각 메소드를 사용하는 예제는 다음과 같다.

0 10 20 30 40 50 60 70 80 91 01 11 21 31 41 51 61 71 81 92 02 1
< % @ p a g e co n te n tT yp e = " te x t/h tm l;c h a rse t= u tf-8 " % >< % @ p a g e im p o rt= " ja v a .u t il .S t r in g T o k e n iz e r" % >< h tm l>< h e ad >< t it le > S tr in g T o k e n iz e r 메 소 드 예 제 < /t it le >< /h e ad >< b o d y>< % S tr in g s t r = "2 0 0 8 /0 9 /0 6 " ; S t r in g T o k e n iz e r s t = n e w S tr in g T o k e n iz e r(s t r , " / " ) ;% >s t .co u n tT o k e n s () = < % = s t .c o u n tT o k e n s () % > < b r/>< % w h ile (s t .h a sM o re T o k e n s ()) {% > s t .n e x tT o k e n s () = < % = s t .n e x tT o k e n () % > < b r/>< % }% > < /b o d y>< /h tm l>
[예제 5.20] jspbook\ch05\tokenizer.jsp
10: 구분자로 “/”를 사용하는 StringTokenizer 객체 st 생성
12: 구분자인 “/” 기준에 토큰의 개수는 3 개
14: 토큰이 더 남아 있는지 테스트
16: 각각의 토큰을 출력
[그림 5-34] tokenizer.jsp의 수행 모습