大數據分析(big data analytics) - iot.cht.com.tw · 大數據分析快速上手操作手冊...
TRANSCRIPT

大數據分析快速上手操作手冊 2018
-1-
大數據分析(Big Data Analytics)
快速上手操作手冊
中華電信研究院巨量所
民國 107 年 2 月 12 日
大數據分析快速上手操作手冊 2018
-2-
1. 前言
IoT 大平台大數據分析服務 (Big Data Analytics) 建構於 Hadoop 雲端平台,
主要藉助 Apache Spark 提供大資料分析的演算法,後續更進一步將 Spark 演算法
加以包裝整合 Zeppelin 使用者介面,發展一個 Zeppelin Interpreter 稱為 runspark
(%run),提供方便的命令列式介面完成大數據資料分析任務。
此說明文件主要使用實際例子來說明如何在Zeppelin上使用 runspark快速的
分析資料,雖然在此文件中只用到某些 runspark 指令,但所有指令均提供詳細的
線上說明,如有指令使用上疑問,請使用 help 指令查詢。
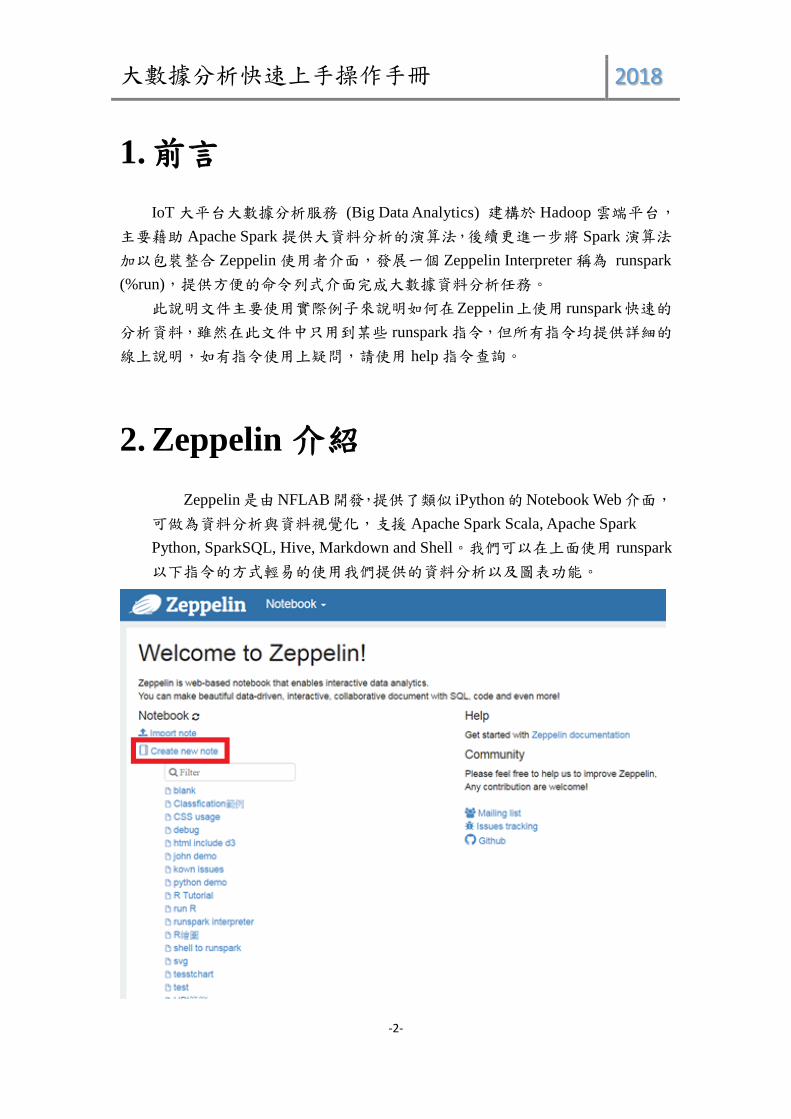
2. Zeppelin 介紹
Zeppelin是由NFLAB開發,提供了類似 iPython的Notebook Web介面,
可做為資料分析與資料視覺化,支援 Apache Spark Scala, Apache Spark
Python, SparkSQL, Hive, Markdown and Shell。我們可以在上面使用 runspark
以下指令的方式輕易的使用我們提供的資料分析以及圖表功能。

大數據分析快速上手操作手冊 2018
-3-

大數據分析快速上手操作手冊 2018
-4-
2.1 Interpreter 介紹
我們提供一個基本的 Interpreter:%run (runspark),利用這個 interpreter 來執
行所有經過包裝的大數據分析指令。例如,輸入
%run
help
用來查看目前提供哪些指令
文字處理 (text manipulation) (10項 API)
cntvec 計算字串出現的頻率作為特徵 (count vectorizer)
tf 計算文件內詞頻 (term frequency)
idf 計算文件詞頻倒數 (inverse document frequency)
idx 將字串欄位依字詞編碼
invidx 將字詞編碼反向轉換回原字串
ngram 將字串欄位轉換為其 n元語法模型 (n-grams)
rmstop 移除字串欄位中的停止詞 (stop words)
token 將字串欄位依空白切字成為字串陣列欄位
regtoken 將字串欄位依正規表示式切字成為字串陣列欄位
word2vec 將文字欄位依 word2vec 演算法轉換成向量
特徵抽取 (feature extraction) (16項 API)
onehot 將類別欄位轉換為其單顯編碼 (one hot encoding)
chisq 卡方特徵選擇
bin 以一閥值將連續值轉換為二元值
bucket 以多個閥值將連續值轉換為區段值
qd 將連續值欄位作離散化編碼 (quantile discretize)
dct 將 Vector 欄位作離散餘弦轉換 (discrete cosine transform)
scalar 將 Vector 欄位各維度各乘以指定的權重
interact 將兩個型態為 Vector 的欄位相乘得到新的 Vector 欄位
scale 將 Vector 欄位依給定的最小值、最大值正規化
stdscale 將 Vector 欄位的各維度依其平均值及標準差作正規化
normal 將 Vector 欄位正規化成為單位法向量 (unit normal vector)
pca 對 Vector 欄位進行主成份分析並轉換
polyexp 將 Vector 欄位做多項式計算展開成另一個 Vector 欄位
tovec 將多個欄位合併成一個 Vector 欄位
idxvec 將 Vector 欄位各維度依其值編碼成最多 maxCategories 個值
subvec 將 Vector 欄位挑選指定維度成為新的 Vector 欄位

大數據分析快速上手操作手冊 2018
-5-
資料探索 (data explorering) (5項 API)
Showdata 呈現原始資料
RegScatCSV 畫出兩指定欄位(x,y)散步圖分布
Count 列出資料指定欄位筆數
Rank 對特定欄位做排序
Stats 列出資料欄位平均值,變異數,數量,非零值數量,最大最小值
資料處理 (data manipulation) (5項 API)
split 依比例切分資料
cast 轉換資料格式
sql 以 SQL 敘述轉換資料
filter 下條件過濾資料
Merge 合併兩資料
分類 (classification) (7項 API)
logreg 羅吉斯迴歸分類器 (logistic regression classifier)
dectree 決策樹分類器 (decision tree classifier)
forest 隨機森林分類器 (random forest classifier)
gbtree 梯度增強決策樹分類器 (gradient-boosted tree classifier)
mlpc 多層感知器 (multilayer perceptron classifier)
vsrest 單顯分類法 (one-vs-rest classifier)
bayes 純樸貝氏分類器 (naive Bayes classifier)
迴歸 (regression) (6項 API)
aftreg 加速失效迴歸 (accelerated failure time regression)
decreg 決策樹迴歸 (decision tree regression)
gbtreg 梯度增強決策樹迴歸 (gradient-boosted tree regression)
isoreg 保序迴歸 (isotonic regression)
linreg 線性迴歸 (linear regression)
forreg 隨機森林迴歸 (random forest regression)

大數據分析快速上手操作手冊 2018
-6-
使用 %run 這個 Interpreter 可以簡單快速完成分析,使用的方法跟終端機執
行差不多,只需要%run 加上想使用的指令就能執行,例如:
%run
logreg –i [input data path] –f [描述資料格式(schema=…)] –o [輸出名稱]
分群 (clustering) (3項 API)
kmeans 中心分群法 (k-means clustering)
gmm 高斯混合模型分群法 (Gaussian mixture model)
lda 隱含狄利克雷分群法 (latent Dirichlet allocation clustering)
推薦 (recommendation)
als 交替最小平方協同過濾推薦
內插 (interpolation)
interp 多元內插演算法 (multivariate interpolation)
分析流程 (analysis workflow) (7項 API)
testing 對模型進行測試
pipe 串接演算法
grid 建立參數組合
crvalid 交叉驗證模型選擇
stvalid 切分測試模型選擇
apply 應用模型或參數包
rformula 依照 R 語言的模型敘述公式 (model formula) 建立模型
圖表視覺化顯示 (visualization)(12項 API)
RegScat 利用點圖方式呈現實際值與預測值(適用 regression演算法)
RegBar 利用柱狀圖方式呈現實際值與預測值誤差占比
RegEval 將不同模型在不同參數下的結果呈現在同一圖表
CM 畫出 Confusion Matrix(適用 classification演算法)
ks_statistic 畫出 Kolmogorov-Smirnov 統計測試法
ClassEval 將不同模型在不同參數下的結果呈現在同一圖表
elbow 畫出在不同分群數時 squared errors(適用 clustering演算法)
silh silhouette analysis(適用 clustering演算法)
pca_2d 將 pca到 2維的結果利用點圖呈現(適用 PCA演算法)
pca_variance 畫出各個維度下資料可解釋的程度(適用 PCA演算法)
Correlation 呈現 pearson correlation結果
SQL 看特定欄位資料(可繪圖)

大數據分析快速上手操作手冊 2018
-7-
除此之外,Zeppelin 也提供了%python, %r 來讓熟悉 python 或 R 的人能夠在
上面直接寫程式,非常方便。
3. %run 操作範例
3.1 分析資料載入
(1) 讀取 IoT 大平台資料

大數據分析快速上手操作手冊 2018
-8-

大數據分析快速上手操作手冊 2018
-9-
3.2 使用指令分析資料

大數據分析快速上手操作手冊 2018
-10-
快速查詢資料指令
ls
使用 %run ls
查看目前 hdfs 目錄上已存放那些資料。
Showdata
印出資料檔案的內容,且可以簡單使用資料探索圖表功能
使用 %run Showdata [資料名稱]

大數據分析快速上手操作手冊 2018
-11-

大數據分析快速上手操作手冊 2018
-12-
快速查詢演算法及指令用法
help
使用 %run help
可以查看所有提供的分析指令
使用 %run help [指令名稱]
或 %run ? [指令名稱]
可以查看指令用法

大數據分析快速上手操作手冊 2018
-13-

大數據分析快速上手操作手冊 2018
-14-
3.3 廻歸演算法應用實例一(IoT 資料)
資料介紹
在這個範例中要分析的是發電量資料,主要想解決的問題是由於太陽能板會
受髒汙或被陰影遮蔽而影響發電量,但要在一大片太陽能板中找到並修復這個問
題非常耗人力與資源,所以在此範例中用預估太陽能的發電量來達到偵測的效果。
此範例中採用的資料是太陽能板的發電量與當時的溫度及照度。
用 Showdata 可以呈現資料內容

大數據分析快速上手操作手冊 2018
-15-
資料整備
目前資料整備功能可讓使用者利用 sql (hive sql)語法來整備資料,若是使用
者習慣自行寫程式處理也提供使用者可以用 python(prspark)處理。另外若是外部
資料也可以處理過後再上載到平台分析。
sql "語法" -i [input data] -o [output data]
分析建模
完整的分析流程會經過反覆的嘗試不同演算法與參數後,最後在選擇測試結
果最好的模型來運用,這個過程非常繁瑣與耗時。因在 %run Interpreter 中已
將演算法都包裝成指令式的方式,讓使用者能利用一兩個指令就完成訓練模型及
測試的動作:
利用 tovec 將欲分析的因子合併成一個新的欄位(feature)
tovec inputCols= [欄位ㄧ,欄位二,…] outputCol=[新的欄位名稱(一般是 feature)] -i
[input data] -o [output data]
利用 split 將資料分成訓練集與測試集兩個擋案

大數據分析快速上手操作手冊 2018
-16-
split parts=0.2,0.8 -i [input data] -o [輸出的測試集名稱,輸出的訓練集名稱]
利用?linreg 查看方法如何使用
利用 testing 及測試集評估模型結果
linreg labelCol=[欲預測的欄位名稱] featuresCol=[因子名稱] [方法參數] -i [訓練
資料] -o [輸出的模型名稱]
testing [模型名稱] labelCol=[欲預測的欄位名稱] task=[方法類型(reg)] -i [測試資
料] -o [output data]
模型佈署
訓練完成模型可以透過指令佈署再利用 api 呼叫模型執行預測
利用 deploy 佈署模型
deploy -i [想要佈署的模型名稱] -a [deploy or delete] (–d [modelID,此參數在刪除
模型時才需要])

大數據分析快速上手操作手冊 2018
-17-
3.4 廻歸演算法應用實例ㄧ(外部資料)
資料介紹
在這個範例中要分析的是駕駛行為,資料假設可以蒐集到:已行駛的里
程數、平均速度…等資料,我們想要利用這些資料來做為駕駛車子是否安全
的參考,目前蒐集到的資料已由專家判斷給定一個分數,分數越高代表車主
的駕駛行為越安全,分析的目標是想要預測其他車主的駕駛行為是否安全
(分數高低)。
因為建模型的部分是數學運算,所以資料中有遺漏空白的部分和中文須補”0”
或經過編碼成數字,而在這範例中我們是不使用那些欄位。
資料整備
較為複雜的資料整備功能主要是透過 SQL 資料處理完成,也是透過幾個
runspark 的指令執行即可,這部分功能還在測試中。所以範例中先自行整理好資
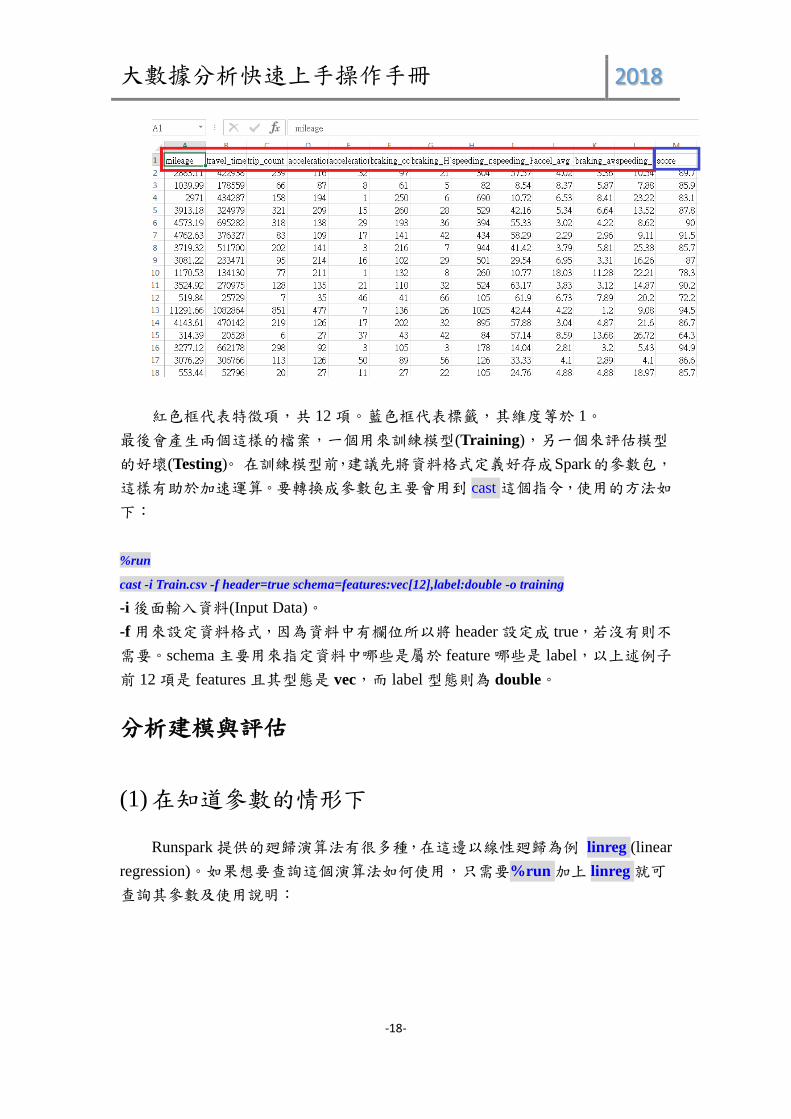
料再上傳到 HDFS 上。因為廻歸模型需要定義特徵值(features,也就是平均速度…
等因子),還有標籤(label,在此例子中是分數),所以會將資料整備成特徵欄位在
前,標籤欄位接在特徵後面的結果。
大數據分析快速上手操作手冊 2018
-18-
紅色框代表特徵項,共 12 項。藍色框代表標籤,其維度等於 1。
最後會產生兩個這樣的檔案,一個用來訓練模型(Training),另一個來評估模型
的好壞(Testing)。 在訓練模型前,建議先將資料格式定義好存成Spark的參數包,
這樣有助於加速運算。要轉換成參數包主要會用到 cast 這個指令,使用的方法如
下:
%run
cast -i Train.csv -f header=true schema=features:vec[12],label:double -o training
-i 後面輸入資料(Input Data)。
-f 用來設定資料格式,因為資料中有欄位所以將 header 設定成 true,若沒有則不
需要。schema 主要用來指定資料中哪些是屬於 feature 哪些是 label,以上述例子
前 12 項是 features 且其型態是 vec,而 label 型態則為 double。
分析建模與評估
(1) 在知道參數的情形下
Runspark 提供的廻歸演算法有很多種,在這邊以線性廻歸為例 linreg (linear
regression)。如果想要查詢這個演算法如何使用,只需要%run 加上 linreg 就可
查詢其參數及使用說明:

大數據分析快速上手操作手冊 2018
-19-
在這個例子中,要訓練模型會使用的指令為:
linreg regParam=0.01 -i training -o models
regParam 的部分是模型參數,可以自行設定或者使用預設又或者調整其他參數,
並沒有什麼最好的做法,需實驗驗證。
-i 後面輸入訓練資料(Training Data)
-o 是最後訓練完輸出的模型名稱
模型訓練完後需要評估這次訓練的結果好不好,所以利用先前經過 cast 轉
換後得到的 Testing Data 來評估。
apply models -i testing -o Prediction
testing models task=reg -i testing -o report
apply 的功能是輸出模型預測的分數為何(例如 80 分)
testing 則是輸出一些預設的評估方法結果(例如 R-squared)
在兩個指令的後面同樣加上先前訓練的模型名稱(models)並且以-i –o 的方式輸入

大數據分析快速上手操作手冊 2018
-20-
資料和輸出結果。不同的地方在於使用 testing 指令時須設定目前模型種類為
reg。
在 Zeppelin 的 Notebook 中可以先寫好上述所有指令再一次執行。
%run
cast -i Train.csv -f header=true schema=features:vec[12],label:double -o training
linreg regParam=0.01 -i training -o models
cast -i Test.csv -f header=true schema=features:vec[12],label:double -o testing
apply models -i testing -o Prediction
testing models task=reg -i testing -o report
(2) 在不知道參數的情形下
當然也是可以用上一節的方法一個參數一個參數慢慢設定,但這樣有點麻煩。
所以在 runspark 中提供了 grid 指令幫助我們一次可以對參數設定多個值,只要
在演算法前面加入 grid 指令,在後面參數的部分就能設定多個值,並且可以輸
出多個模型,當然在後面評估時也會自動帶入這些模型一起做,以上述的例子可
以改寫成:
%run
cast -i Train.csv -f header=true schema=features:vec[12],label:double -o training
grid linreg regParam=0.01,0.02,0.03,0.04,0.05 -i training -o models

大數據分析快速上手操作手冊 2018
-21-
cast -i Test.csv -f header=true schema=features:vec[12],label:double -o testing
testing models task=reg -i testing -o report
在確定哪個模型較好後再使用 apply 指令以及評估結果較好的那一組參數。
(3) 目前已支援的圖表功能
RegScatCSV
這個功能主要是以點圖的方式來顯示欄位 1 跟欄位 2 的分布情況。
%run
RegScatCSV -i [資料路徑] -f1 [欄位 1] -f2 [欄位 2]

大數據分析快速上手操作手冊 2018
-22-
RegBar
這個功能是提供模型評估時,實際值跟預測值之間誤差比例分析圖。
%run
RegBar -i [經由 apply 指令 output 的 data 路徑] -n [柱的數量] -s [誤差區間]
-n 代表柱狀圖要顯示的柱子數量
-s 代表每個柱子間的數值間距,在此例子上就是誤差值間距
RegScat
這個功能主要以點圖的方式來呈現實際跟預測數值。
%run
RegScat -i [經由 apply 指令 output 的 data 路徑] -n[點數量(預設為 50)]
-n 代表要顯示的資料筆數

大數據分析快速上手操作手冊 2018
-23-
RegEval
這個功能主要是用圖表來呈現各種參數評估的結果,以 regression 問題來說,評
估的方法為 R-squared,mse,rmse 和 mae,通常這個圖表會跟 grid 指令搭配使用。
%run
RegEval -i [經由 test 指令 output 的結果路徑] -d [參數數列]
-d 代表參數值數列,例如 0.1,0.2,0.3,0.4,0.5

大數據分析快速上手操作手冊 2018
-24-

大數據分析快速上手操作手冊 2018
-25-
3.5 廻歸模型應用實例二(外部資料)
資料介紹
在這個範例中採用的是高公局開放出來的高速公路開放資料(freeway.csv),
此資料含有路段 ID、日期(幾月、星期幾…)、旅行時間,我們的目標就是預測某
一路段駕駛所需花的時間(旅行時間)。
資料整備
首先挑選出想分析的路段,在這個範例中選擇 RouteID = 1 的資料,資料整備時
會先執行以下幾個步驟:
(1) 將資料轉成 Dataframe

大數據分析快速上手操作手冊 2018
-26-
cast -i freeway.csv -f csv header=true
schema=RouteID:int,DateTime:string,TripTime:double,timeSlot:double,month:double,weekday:
double,unknown:double -o freeway
在這個資料中,因為資料格式的關係,需自行設定 schema 以確保讀取格式的
正確。
(2) 挑選欲使用的路段資料在存成另一檔案,並選定 feature
filter -i freeway -f RouteID=10 -o freeway_10
利用 filter 設定條件(-f)再另存成另一檔案(-o)。
tovec inputCols=timeSlot,month,weekday,unknown outputCol=features -i freeway_10 -o
freewaydata
利用 tovec來選擇 feature,設定要用的欄位(timeSlot,month,weekday,unknown),
將這些欄位設定成 features 的欄位,最後再輸出檔案(freewaydata)
split parts=0.2,0.8 -i freewaydata -o freeway_10_testing,freeway_10_training
最後利用 split 將整備好的資料按照 2:8 的方式分成測試集和訓練集
分析建模與評估
若不清楚要使用何種模型或指令,可以輸入 help 查看所有指令名稱,再利
用 help + [指令名稱]來查看指令詳細用法
(1) 利用線性廻歸模型,featuresCol 為先前產生的 features 欄位,labelCol 預設
是 label,因此在此範例中需自行設定成 TripTime
linreg labelCol=TripTime featuresCol=features -i freeway_10_training -o freeway_10_model
(2) 利用 testing,labelCol 為 TripTime,可得到一些預設的評估方法結果
testing freeway_10_model labelCol=TripTime task=reg -i freeway_10_testing -o
freewayreport_10

大數據分析快速上手操作手冊 2018
-27-
(3) 利用 apply 指令得到預測結果
apply freeway_10_model -i freeway_10_testing -o freewayPrediction_10

大數據分析快速上手操作手冊 2018
-28-
(4) 利用散布圖檢視預測值誤差(RegScat)
RegScat -i freewayPrediction -l TripTime

大數據分析快速上手操作手冊 2018
-29-
(5) 利用直方圖檢視預測值誤差比率(RegBar)
RegBar -i freewayPrediction -n 15 -s 500 -l TripTime

大數據分析快速上手操作手冊 2018
-30-
4.佈署模型及 API 呼叫
模型佈署
在訓練好滿意的模型後就可以透過佈署模型的指令將模型佈署到 API 能夠
呼叫執行的位置:
使用 %run deploy –i [model_name] –a deploy
佈署已完成訓練模型
可以得到一組 modelID

大數據分析快速上手操作手冊 2018
-31-
使用 API 做預測
成功佈署模型後,我們可以透過北向 API 使用此模型預測結果來開發服務
API: http://iottl_dev.cht.com.tw/api/bssa/v1/prediction/{model_ID}
POST : {“feature”:”[10,2]”}