ディープラーニングの2値化(binarized neural network)
TRANSCRIPT

Binarized Neural Networks:
Training Neural Networks with Weights and Activations Constrained to +1 or -1 −
2017.12.08


Abstract
● BNN(Binarized Neural Networks)
○ weight activation
○ Forward pass weight activation
(parameters gradient)
● BNN
○ (During forward pass)
○
○ → → NN
● BNN
○
■ MNIST CIFAR-10 SVHN state-of-the-art
○
■ GPU
■ GPU
3
Introduction
● DL Abstract
4

1.Binarized Neural Networks
5
BNN

1.1 Deterministic vs Stochastic Binarization
● BNN (weights) (activations)
+1 -1
●
→Section
● (real-valued variables)
○ (Deterministic)
○ (Stochastic)
6

Deterministic
xb: (weight/activation)
x:
7

Stochastic
xb:
x:
σ "hard sigmoid"
8

Hard Sigmoid
9
1/2
1
0 x
y=σ(x)
1-1

●
○
→
● ○ activation (Stochastic Binarization)
10
weight activation
deterministic stochastic
Run-time deterministic deterministic

1.2 Gradient Computation and Accumulation
● BNN
weight activation weight
→
● ○ weight SGD
○ SGD
weight
○ SGD
→
11

1.2
● weight activation
(regularization)
(generalization)
○ variational weight noise(Graves, 2011) Dropout(Srivastava,
2013) DropoutConnect(Wan et al., 2013)
● BNN Dropout
○ Dropout :
■ activation
○ BNN
■ activation weight
→
12

1.3. Propagating Gradients Through Discretization
● Sign
BP
○ Note:
● Bengio(2013)
○ (STE)
Hinton(2012)
● STE ○ BP
●
13

1.3.
●
● ○
○
○ Sign
○
■
■
14

1.3.
● (4)
○ #
●
● hard tanh
15

1.3.
16
● ○ activation sign
○ weight
■ weight -1 1
● weight wr [-1, 1] wr -1 1
weight
■ weight wr
○ (4)

17

18
Forward propagation)

19
(Backward propagation)
Backward Batch Normalization https://kratzert.github.io/2016/02/12/understanding-the-gradient-flow-through-the-batch-normalization-layer.html
←

1.4. Shift based Batch Normalization
● Batch Normalization(BN)(Ioffe & Szegedy, 2015)
weight
● Shift-based batch normalization(SBN)
→
● SBN BN
● SBN BN
20

21

22
BN
←β

1.5. Shift based AdaMax
● ADAM Kingma & Ba, 2014 weight
○ https://arxiv.org/pdf/1412.6980.pdf ● ADAM AdaMax
● AdaMax (vanilla) ADAM
● ADAM http://postd.cc/optimizing-gradient-descent/
23

24
AdaMax

25
ADAM

1.6. First Layer
● BNN 2 weight activation
●
2
● ○
■
512 R,G,B
■ ConvNet
○
■ m
■ :
●
26

1.6.
● 1,024
● MSB
● 1024
●
● (6) (7)
(7)
27

BNN
28

XNOR
●XNOR NOT XOR
29
INPUT OUTPUTA BL L LL H HH L HH H L
INPUT OUTPUTA BL L HL H LH L LH H H
XNORXOR
INPUT OUTPUTA B-1 -1 +1-1 +1 -1+1 -1 -1+1 +1 +1
L=-1, H=+1 OUTPUT A B

2.Benchmark Results
30

Benchmark results
● 2
○ Torch7
○ Theano
● state-of-the-art
○ MNIST, CIFAR-10, SVHN
● Activation
○ Torch7
○ Theano
● ― BN) ADAM
○ Torch7 BN ADAM
○ Theano BN ADAM
31
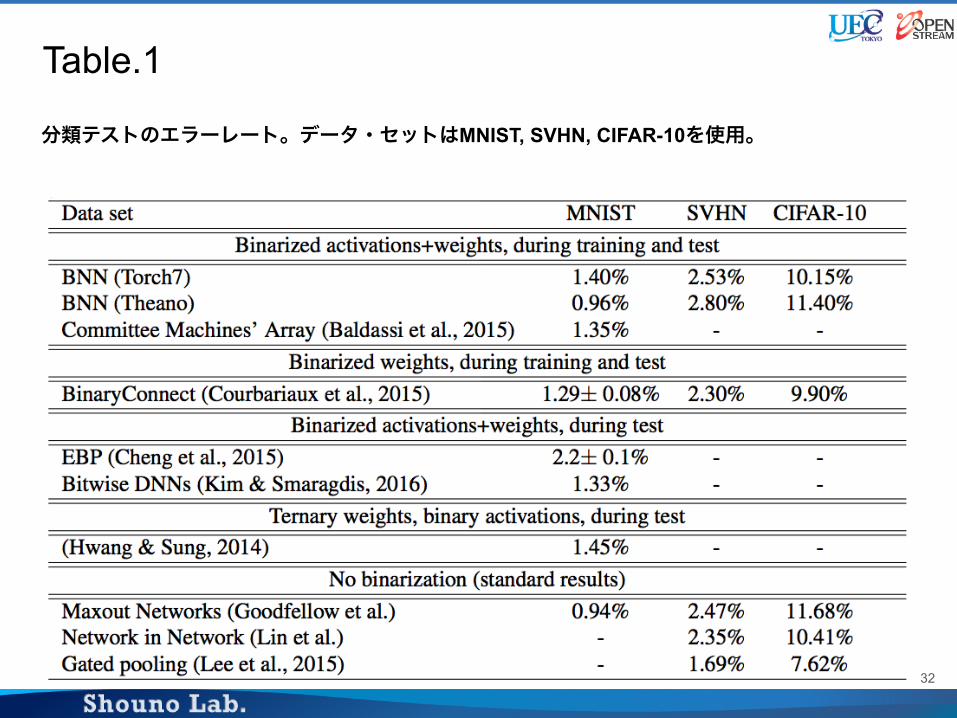
Table.1
32
MNIST, SVHN, CIFAR-10

Figure
33
CIFAR-10 ConvNet Square Hinge Loss:L2 loss
BNN

Figure 2
34
k 2^(k^2)
replication CIFAR-10 ConvNet 42%
58%

35
• • BNN Run-Time
•
•
• Figure BNN
• Shift-Based-X(BatchNormalization, AdaMax) • Run-time BN AdaMax
•

END
36