computational motor control: reinforcement learning (jaist summer course)
TRANSCRIPT

Computational Motor Control Summer School
06: Reinforcement Learning
Hiroyuki KambaraTokyo Institute of Technology

イントロダクション
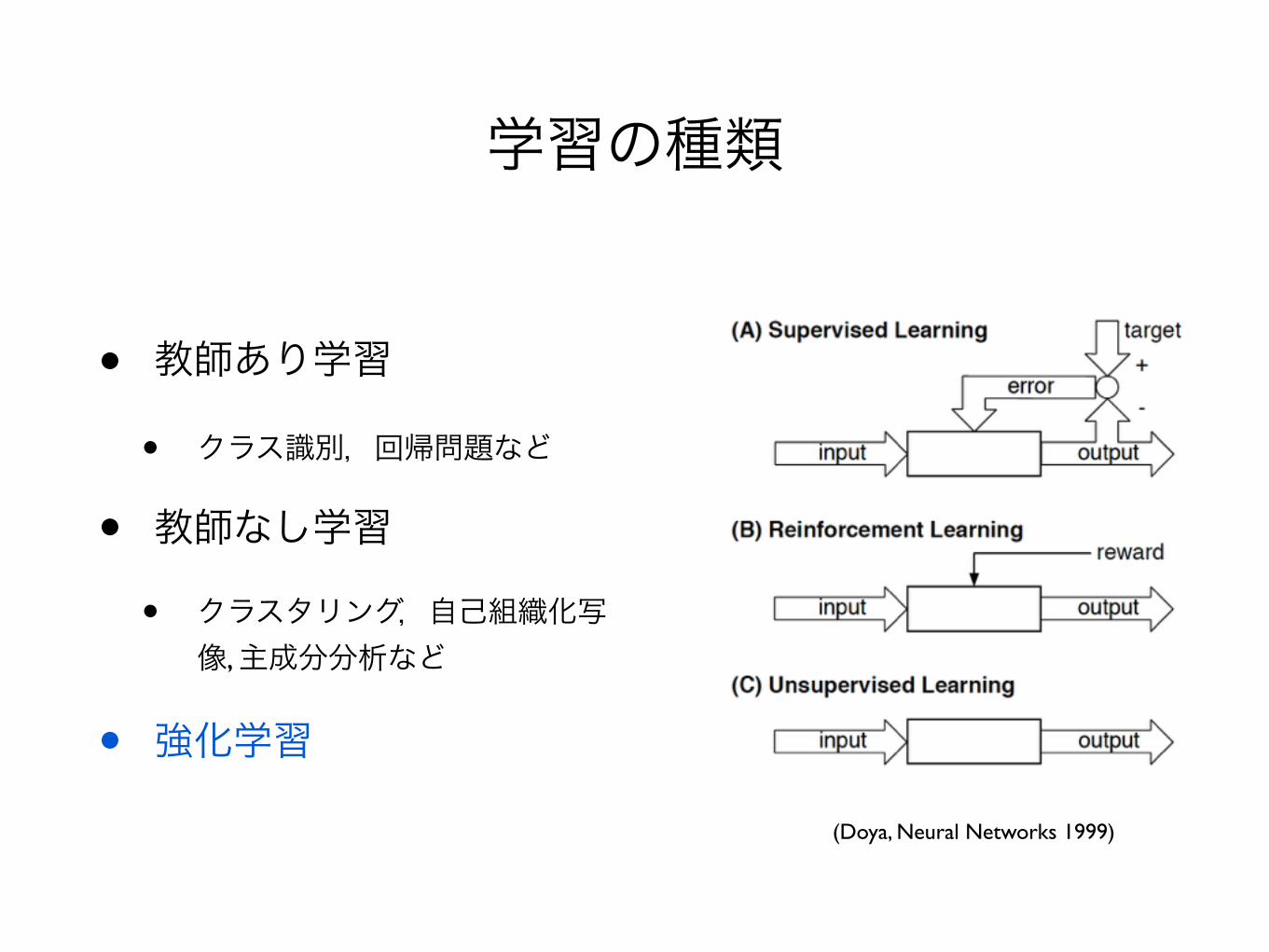
学習の種類
• 教師あり学習
• クラス識別,回帰問題など
• 教師なし学習
• クラスタリング,自己組織化写像, 主成分分析など
• 強化学習
(Doya, Neural Networks 1999)

概念
Reinforcement learning is learning what to do--how to map situations to actions--so as to maximize a numerical reward signal. The learner is not told which actions to take, as in most forms of machine learning, but instead must discover which actions yield the most reward by trying them.
Reinforcement Learning -An Introduction-(Sutton & Barto, 1999, MIT Press)
例えば...
強化学習の特徴
• 正しい行動ではなく、行動の善し悪しを示す報酬が与えられる
• 累積報酬を最大化する行動を学習
• 行動を通じて環境に変化をもたらすが、環境の変化の仕方は知らない
A B C D

アルゴリズム

問題設定
Agent
Environment
action
state reward
Agent : 学習主体(脳)Environment: 環境(身体、外界)
Policy : 政策
Reward: 報酬
Return: 利得
( : 割引率 )
利得を最大にする政策を獲得
State: 状態

状態と行動の価値関数
State Value Function : 状態価値関数
Action Value Function : 状態価値関数

最適な政策の獲得
政策の優劣
if and only if for all
他の全ての政策よりも同等か優れているものが最適な政策
政策反復法による最適政策の獲得• 全状態について を求める• 全状態について下記の式を満たすように政策改善

状態価値関数の学習
• 環境や報酬のモデルがない状況での学習方法
• Monte Carlo 法
• Temporal Difference 法

Monte Carlo 法
• 政策 に従った試行を行い、試行終了後に状態価値関数 を更新
• 環境や報酬についてのモデルが必要ない
• 正しい状態価値関数が学習可能
• ただし、すべての状態を無限回経験するとの仮定のもとで
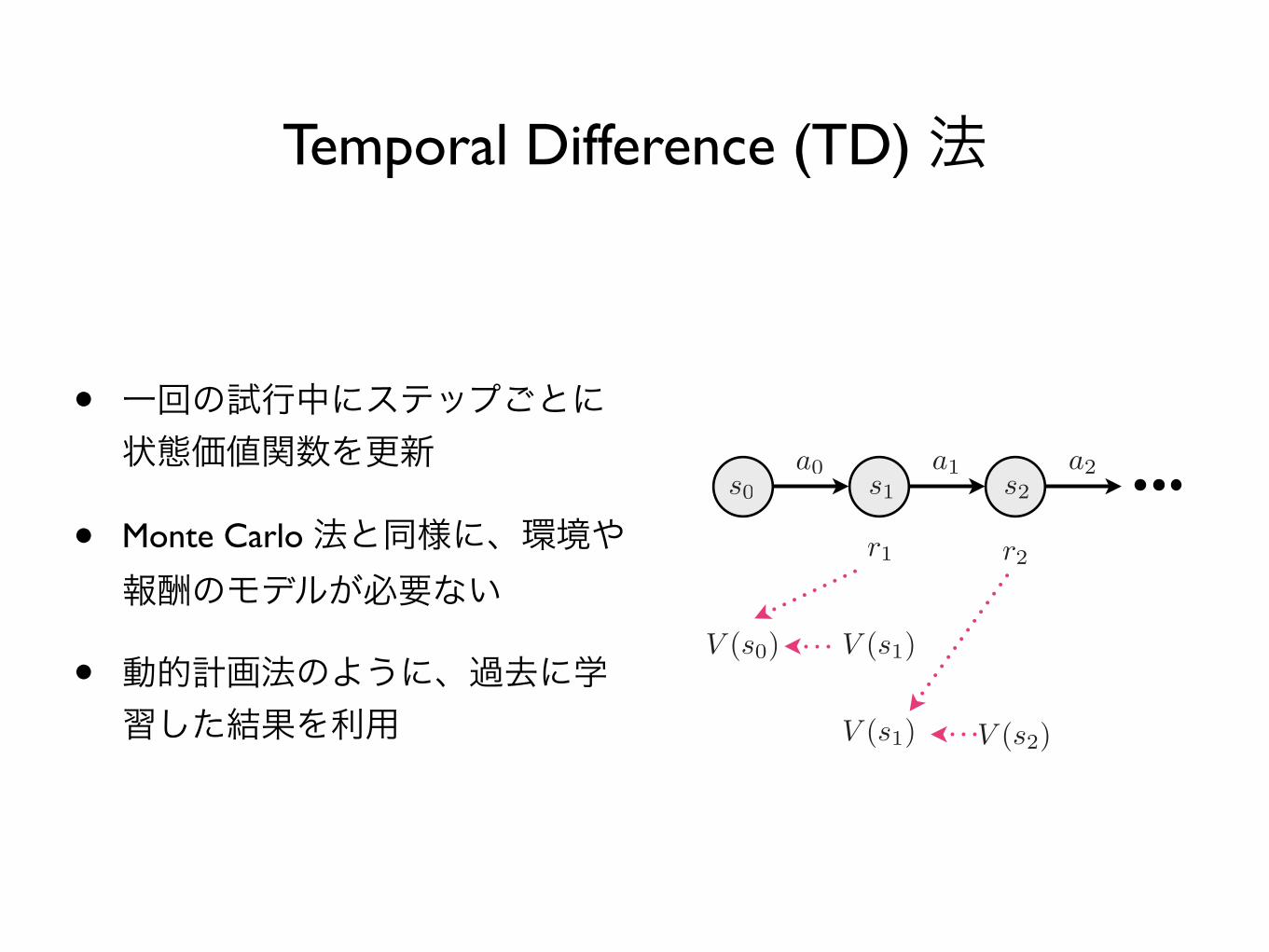
Temporal Difference (TD) 法
• 一回の試行中にステップごとに状態価値関数を更新
• Monte Carlo 法と同様に、環境や報酬のモデルが必要ない
• 動的計画法のように、過去に学習した結果を利用

Temporal Difference Error
状態価値関数の更新
TD Error の導出
( : 学習率)
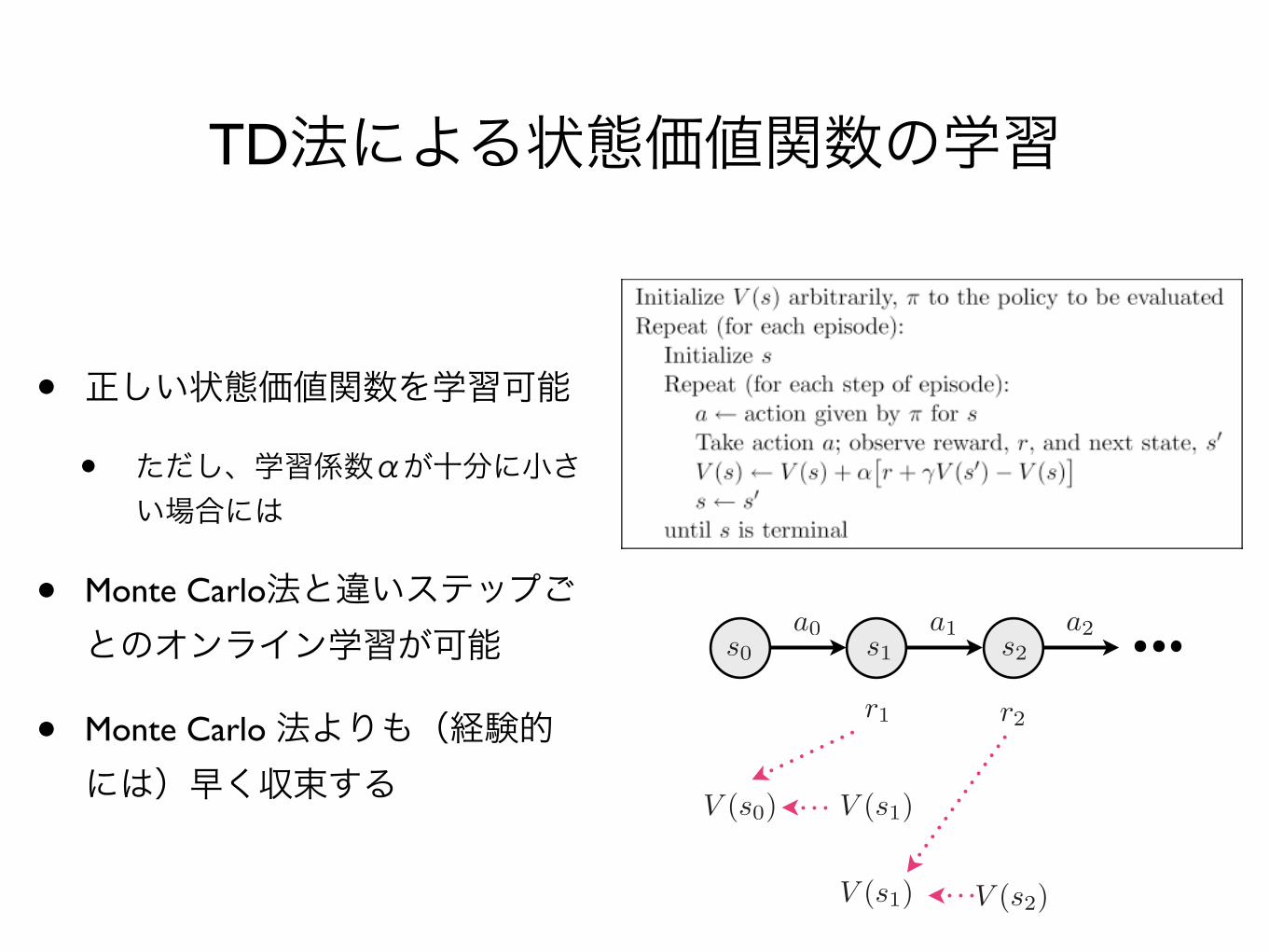
TD法による状態価値関数の学習
• 正しい状態価値関数を学習可能
• ただし、学習係数αが十分に小さい場合には
• Monte Carlo法と違いステップごとのオンライン学習が可能
• Monte Carlo 法よりも(経験的には)早く収束する
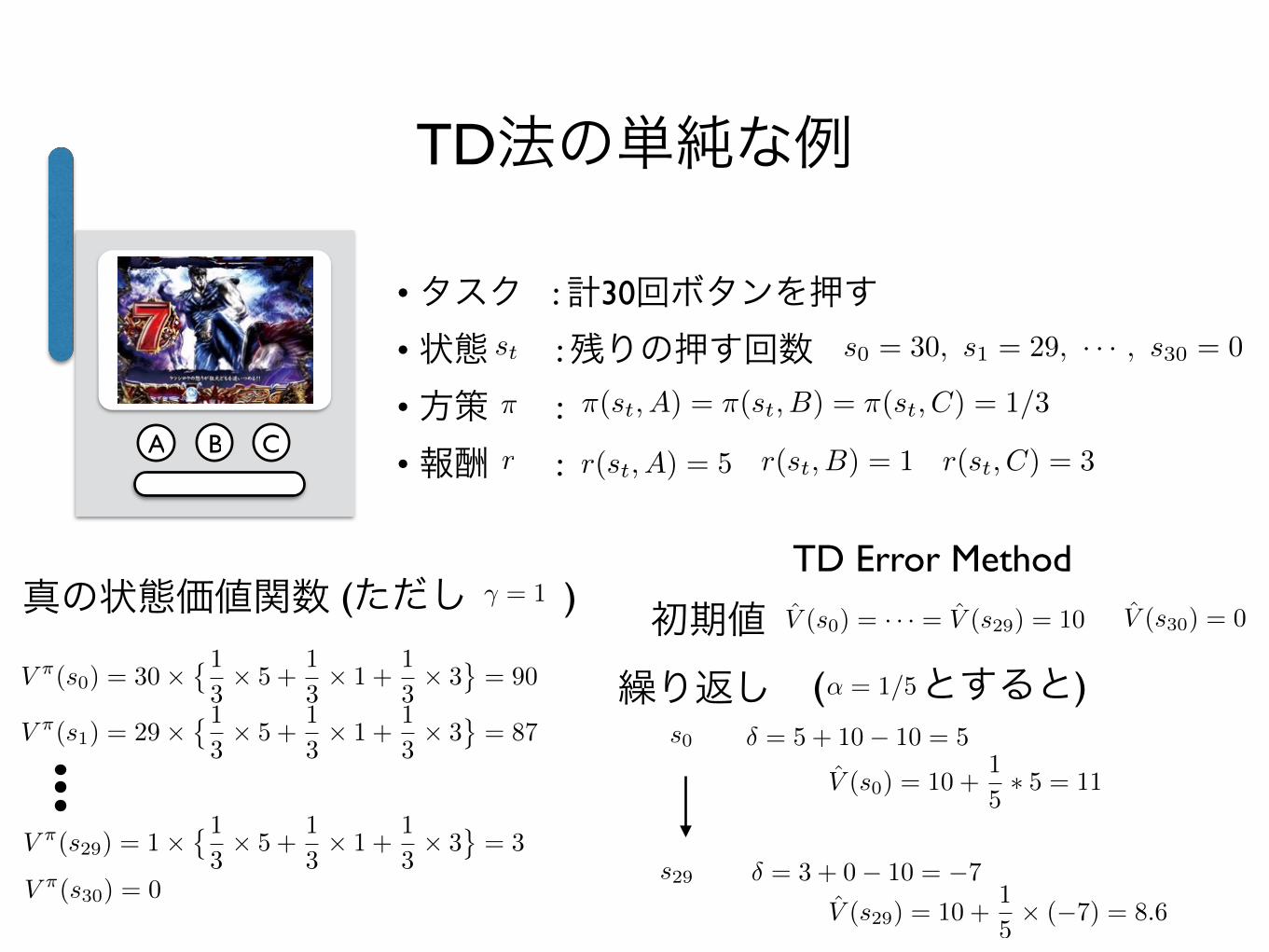
TD法の単純な例
A B C
•タスク : 計30回ボタンを押す•状態 : 残りの押す回数•方策 :
•報酬 :
⇡(st, A) = ⇡(st, B) = ⇡(st, C) = 1/3
r(st, A) = 5 r(st, B) = 1 r(st, C) = 3
st
⇡
r
s0 = 30, s1 = 29, · · · , s30 = 0
真の状態価値関数
V ⇡(s0) = 30⇥�13⇥ 5 +
1
3⇥ 1 +
1
3⇥ 3
= 90
V ⇡(s1) = 29⇥�13⇥ 5 +
1
3⇥ 1 +
1
3⇥ 3
= 87
V ⇡(s29) = 1⇥�13⇥ 5 +
1
3⇥ 1 +
1
3⇥ 3
= 3
V ⇡(s30) = 0
TD Error Method
V̂ (s0) = · · · = V̂ (s29) = 10初期値 V̂ (s30) = 0
繰り返しs0 � = 5 + 10� 10 = 5
V̂ (s0) = 10 +1
5⇤ 5 = 11
s29 � = 3 + 0� 10 = �7
V̂ (s29) = 10 +1
5⇥ (�7) = 8.6
� = 1(ただし )
↵ = 1/5( とすると)
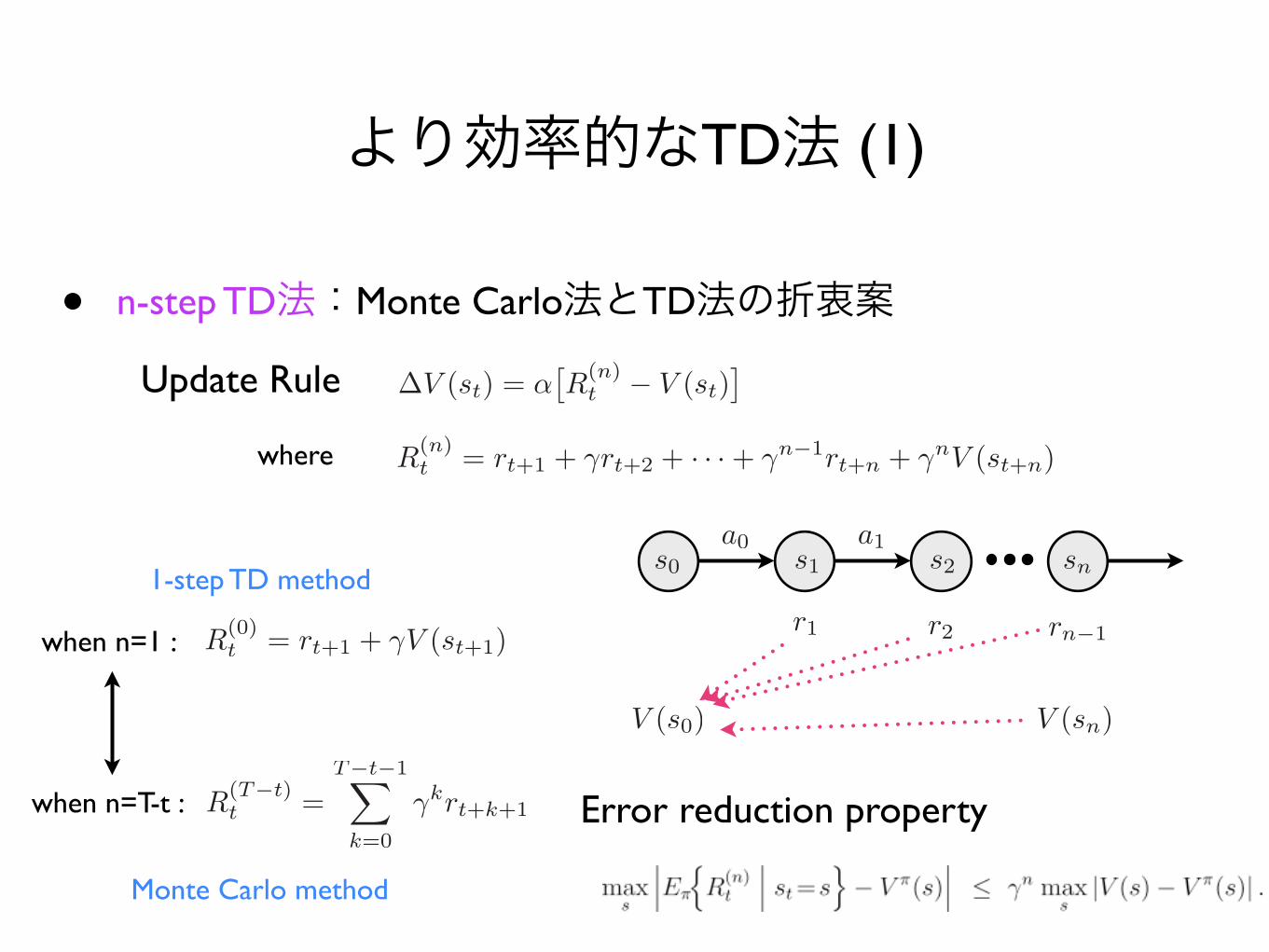
より効率的なTD法 (1)
• n-step TD法:Monte Carlo法とTD法の折衷案
where
Update Rule
when n=1 :
when n=T-t :
1-step TD method
Monte Carlo method
Error reduction property
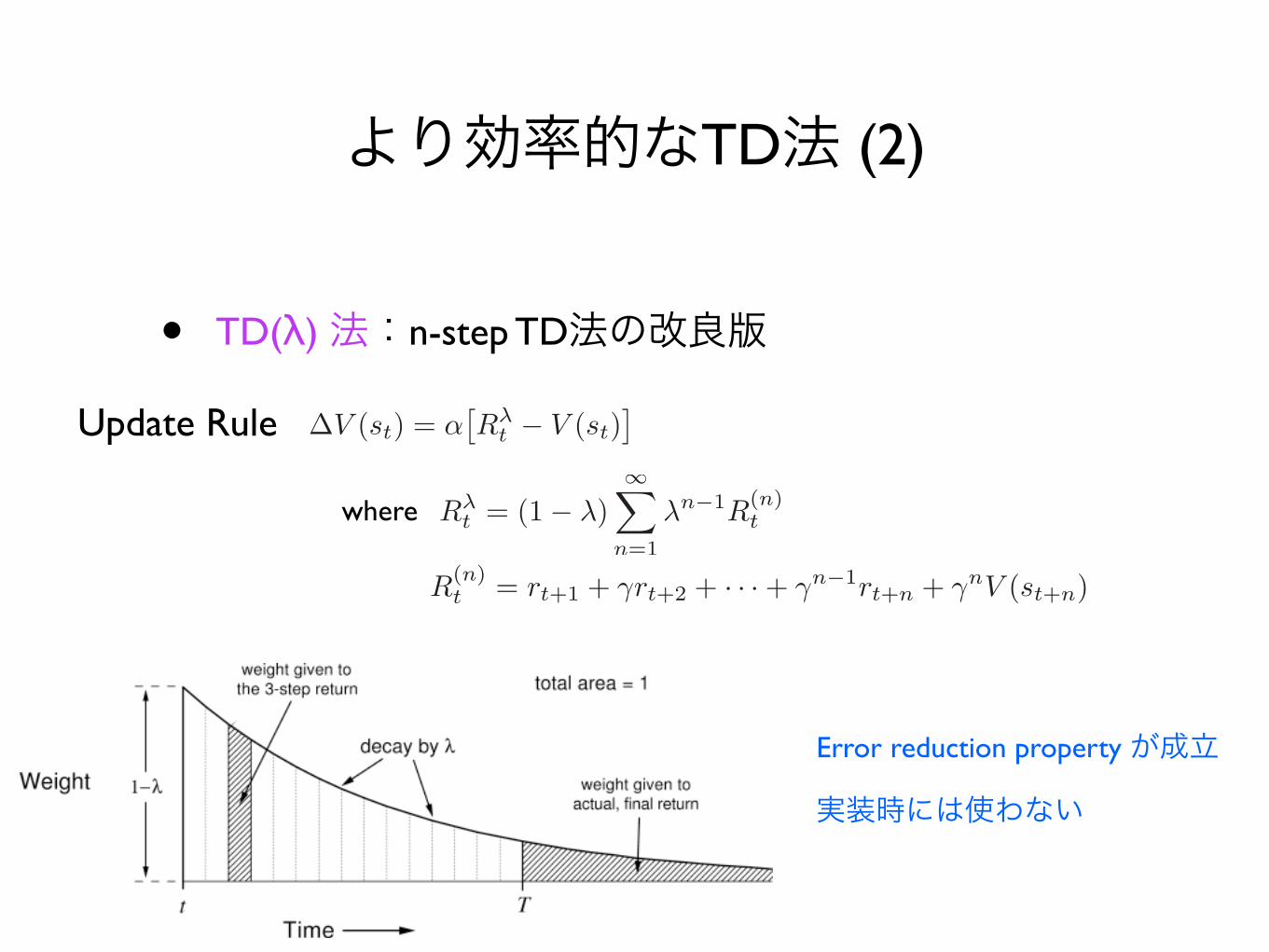
より効率的なTD法 (2)
• TD(λ) 法:n-step TD法の改良版
where
Update Rule
Error reduction property が成立
実装時には使わない
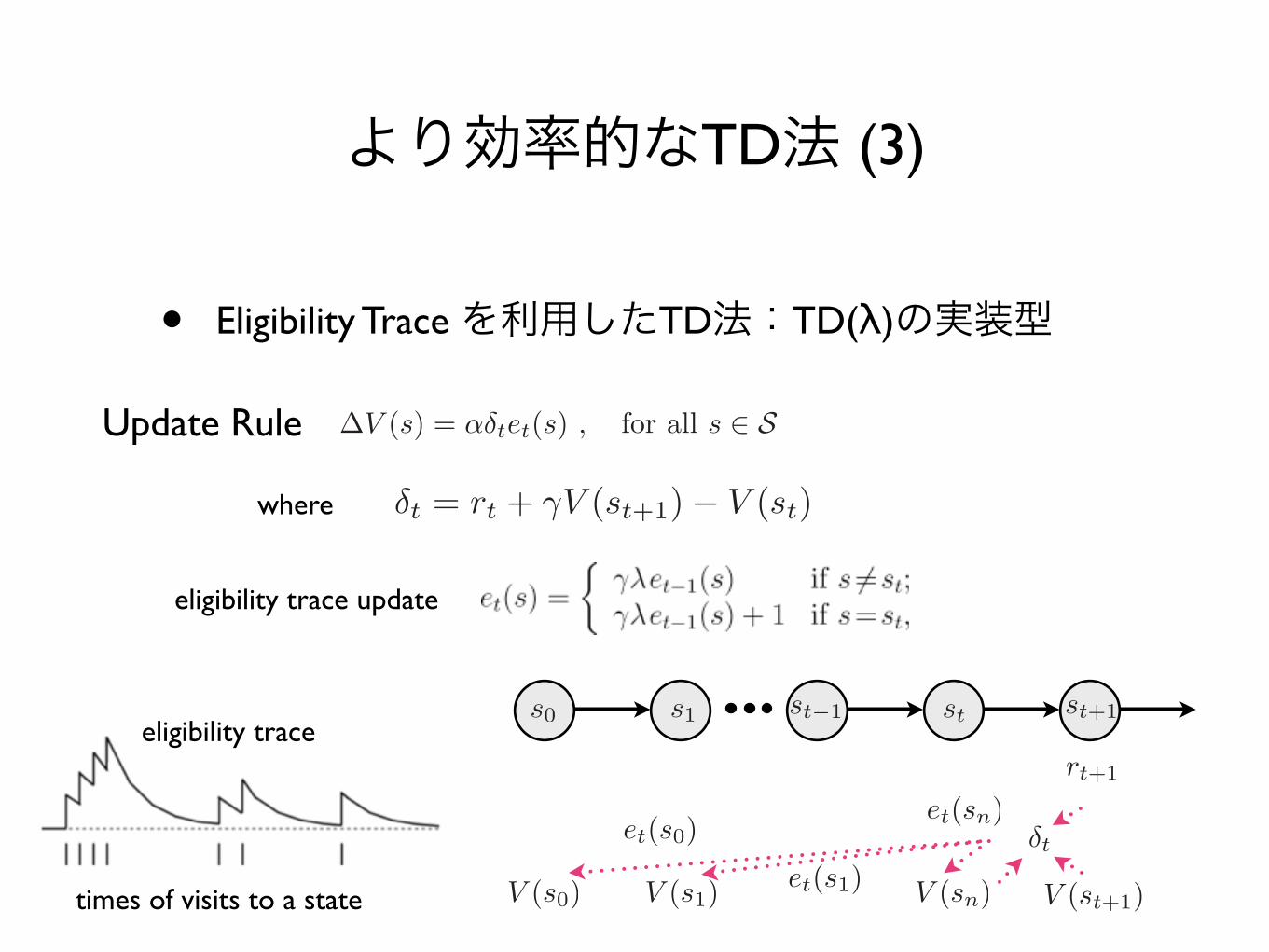
より効率的なTD法 (3)
• Eligibility Trace を利用したTD法:TD(λ)の実装型
where
Update Rule
eligibility trace update
eligibility trace
times of visits to a state

政策の改善方法
• Actor-Critic method
• Q-Learning method
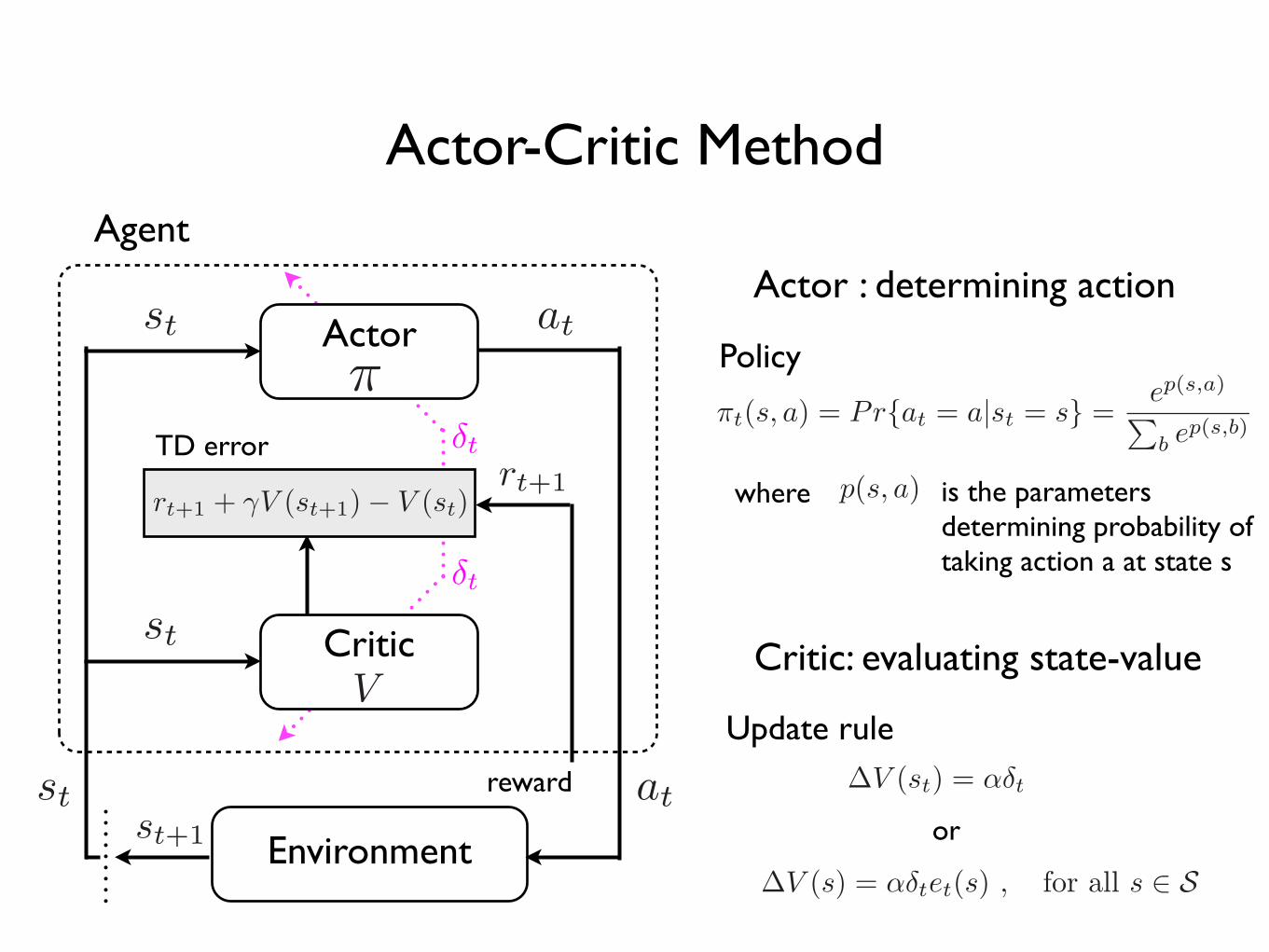
Actor-Critic MethodAgent
Environment
TD error
reward
Actor
Critic
Actor : determining action
Critic: evaluating state-value
where is the parameters determining probability of taking action a at state s
or
Update rule
Policy

Actor-Critic Method
• Policy Improvement Rule
where
( : 学習率)
のとき : 予測通りの報酬 and 遷移した状態の価値
において を取る確率を増やす
何も変えない
のとき : 報酬 and/or 遷移した状態の価値が予測よりも良かった
のとき : 報酬 and/or 遷移した状態の価値が予測よりも悪かったにおいて を取る確率を減らす

Actor-Critic Method の政策改善• Actorの更新に Eligibility Trace を用いる場合 (木村ら, 人工知能学会, 1996)
REINFORCE Algorithm Theorem (Williams, Machine Learning 1992)
真の状態価値の勾配方向にwが更新

Q-Learning Method
行動価値関数を学習して、最適な行動を決定する方法
行動価値関数:
最適な行動価値関数
いろいろな行動を試しながら を直接学習
すべての状態・行動の組が十分多数回経験されれば収束
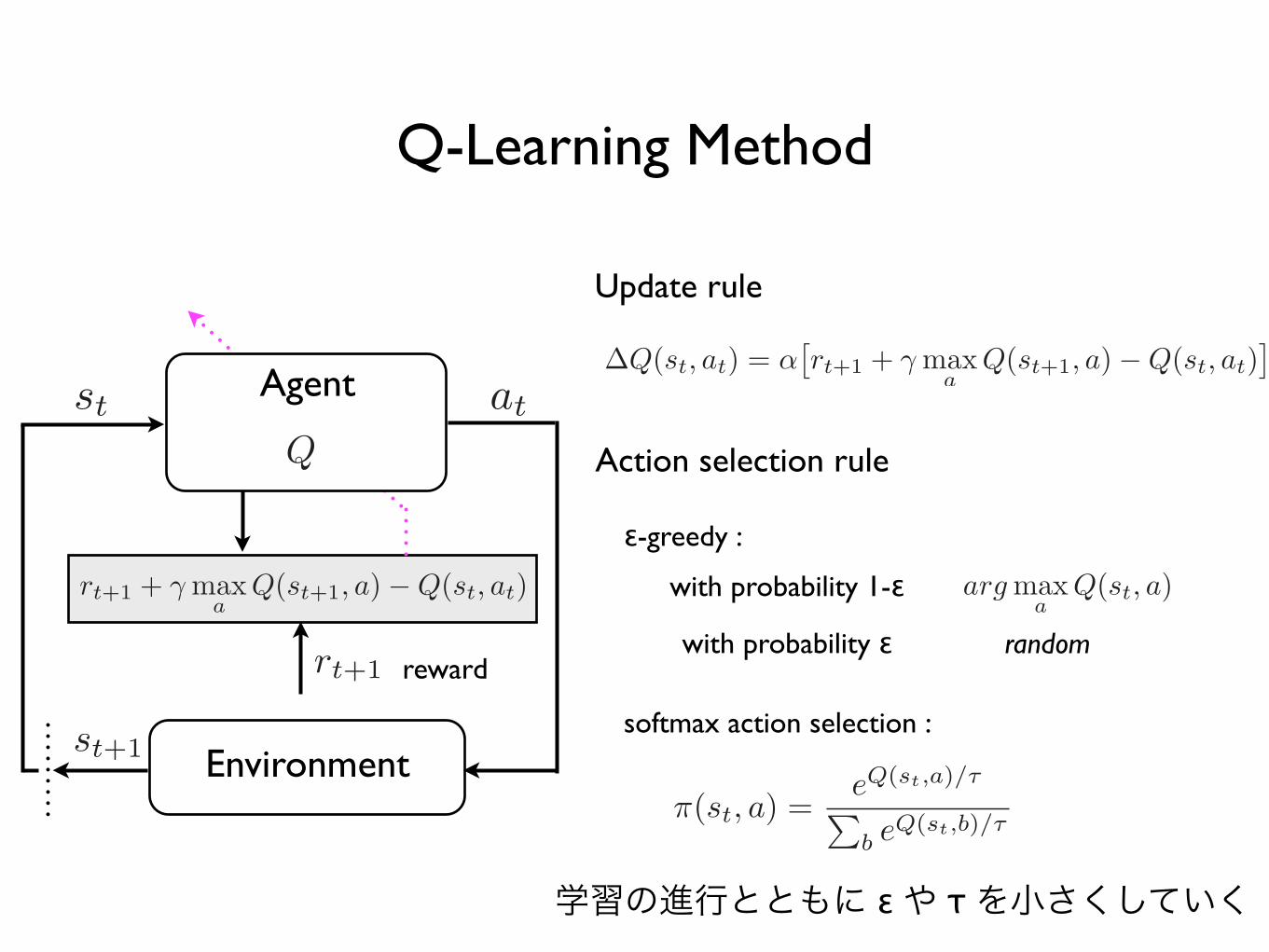
Q-Learning Method
Environment
Agent
reward
Update rule
Action selection rule
ε-greedy :
softmax action selection :
with probability 1-ε
with probability ε random
学習の進行とともに ε や τ を小さくしていく

強化学習に関する 生理学的知見
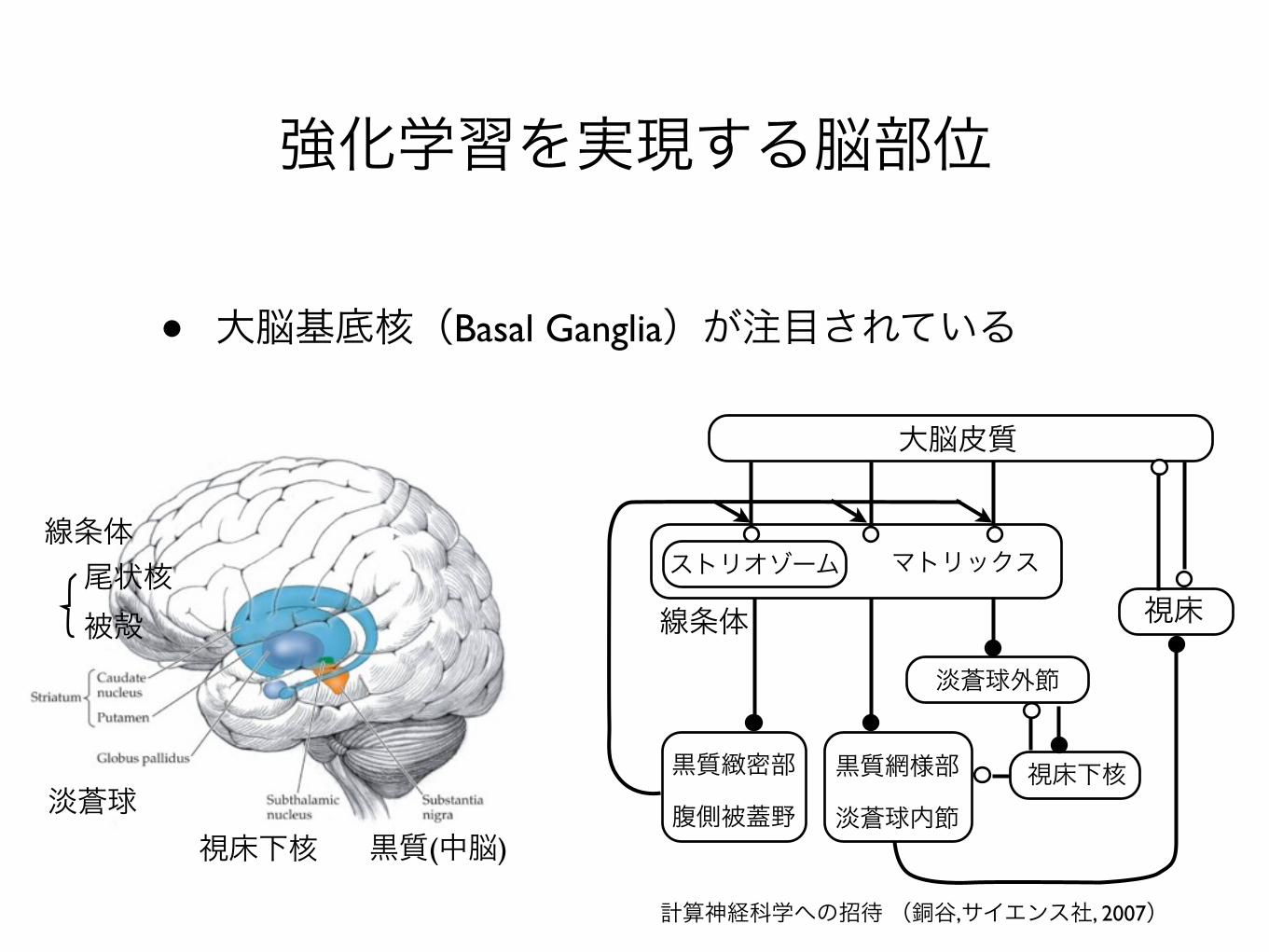
強化学習を実現する脳部位
• 大脳基底核(Basal Ganglia)が注目されている
淡蒼球視床下核 黒質(中脳)
線条体尾状核被殻
大脳皮質
ストリオゾーム マトリックス
線条体
黒質緻密部
腹側被蓋野
黒質網様部
淡蒼球内節視床下核
淡蒼球外節
視床
計算神経科学への招待 (銅谷,サイエンス社, 2007)
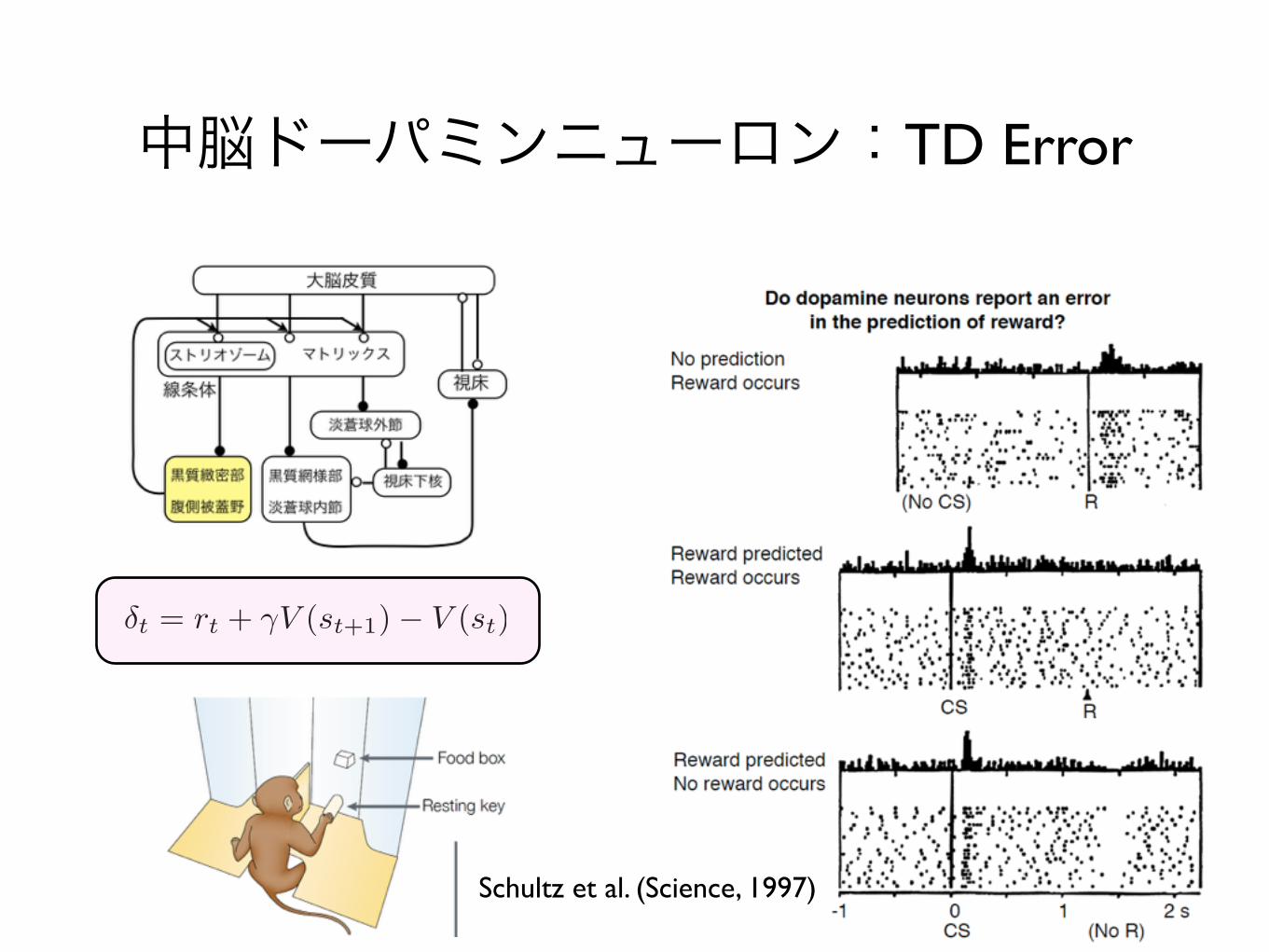
中脳ドーパミンニューロン:TD Error
Schultz et al. (Science, 1997)

線条体のニューロン:価値関数(報酬予測)
Kawagoe et al. (Nature Neuroscience, 1998)
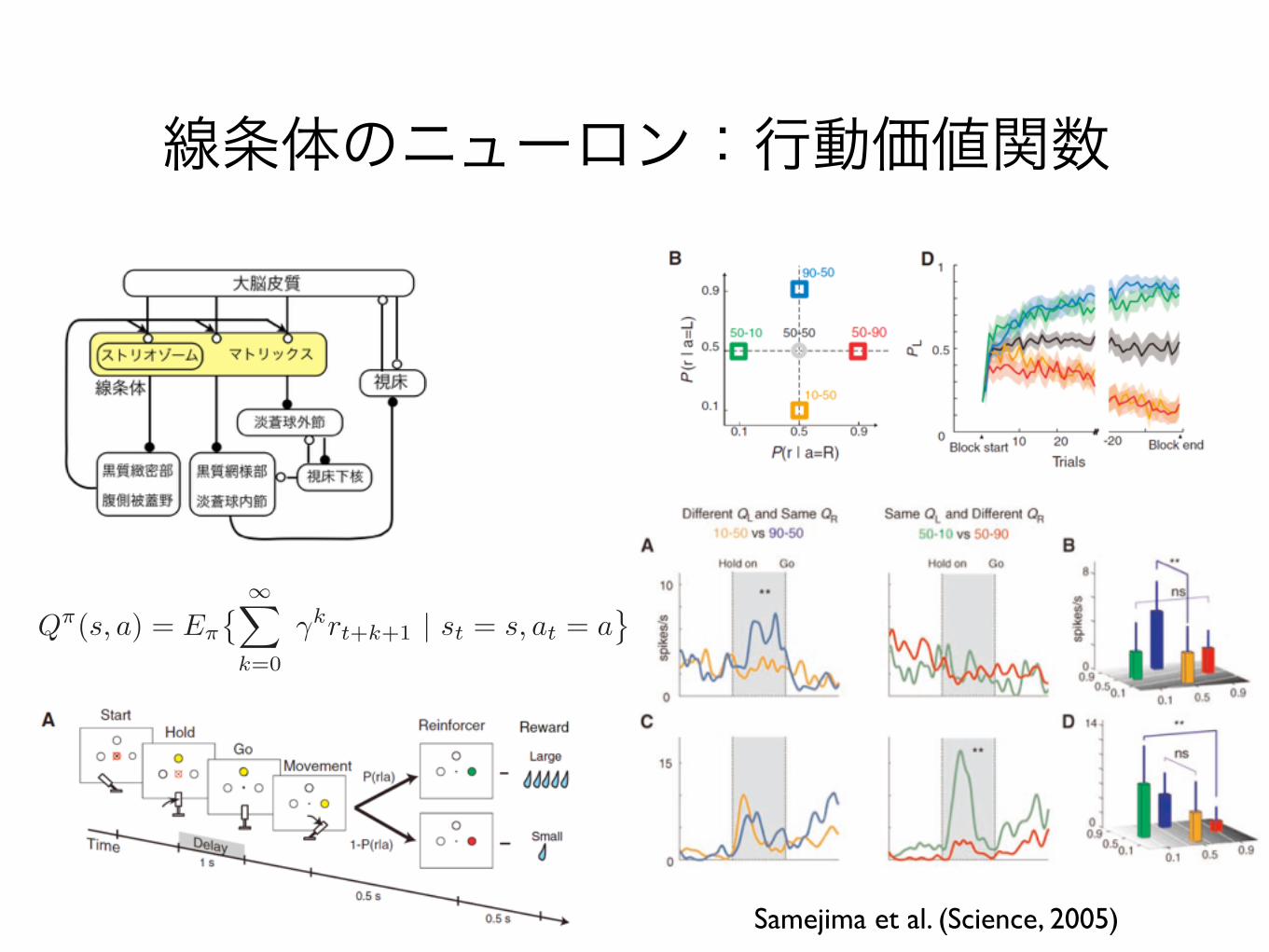
線条体のニューロン:行動価値関数
Samejima et al. (Science, 2005)
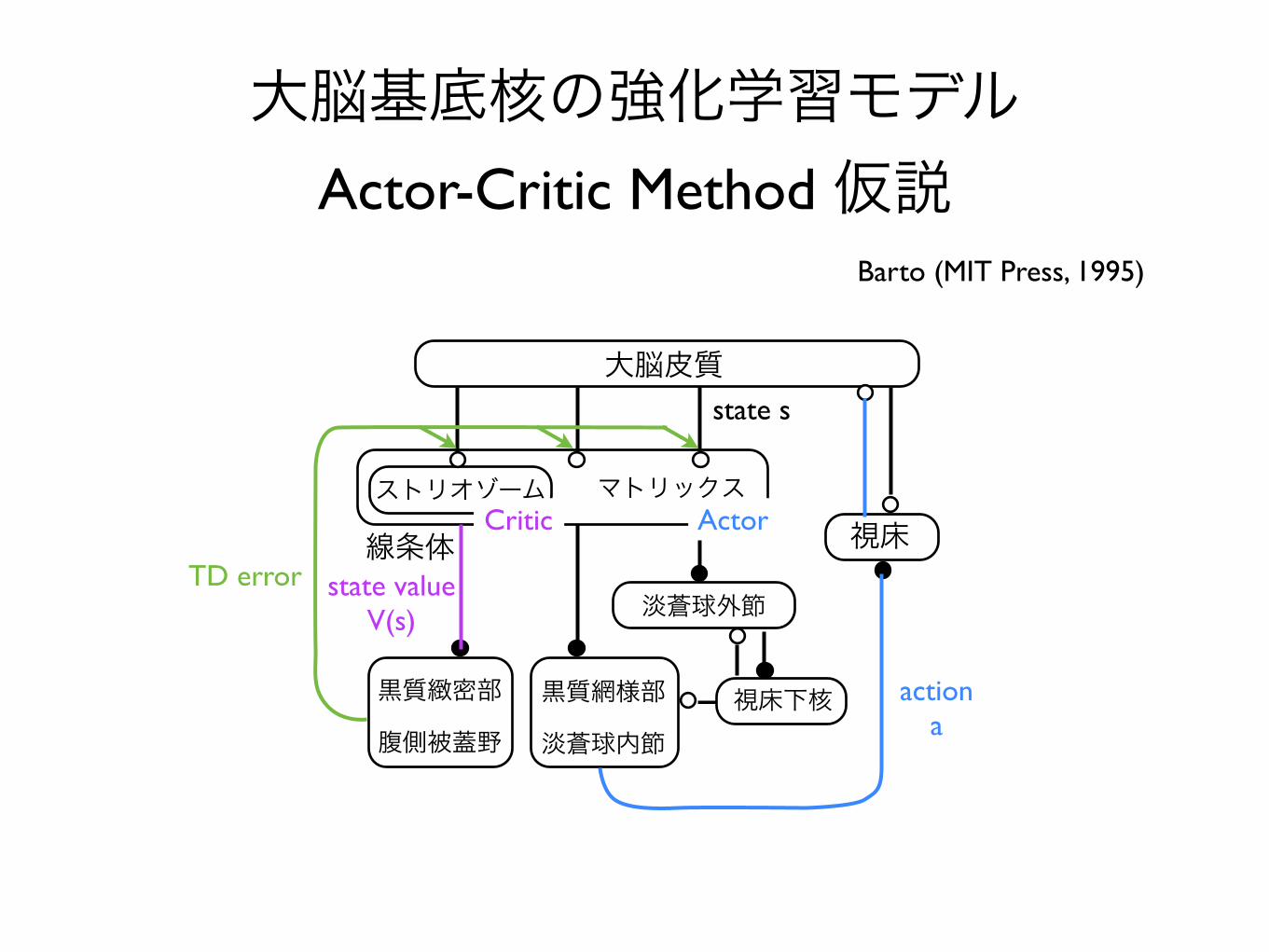
大脳基底核の強化学習モデル Actor-Critic Method 仮説
大脳皮質
ストリオゾーム マトリックス
線条体
黒質緻密部
腹側被蓋野
黒質網様部
淡蒼球内節視床下核
淡蒼球外節
視床Critic Actor
actiona
state valueV(s)
TD error
Barto (MIT Press, 1995)
state s
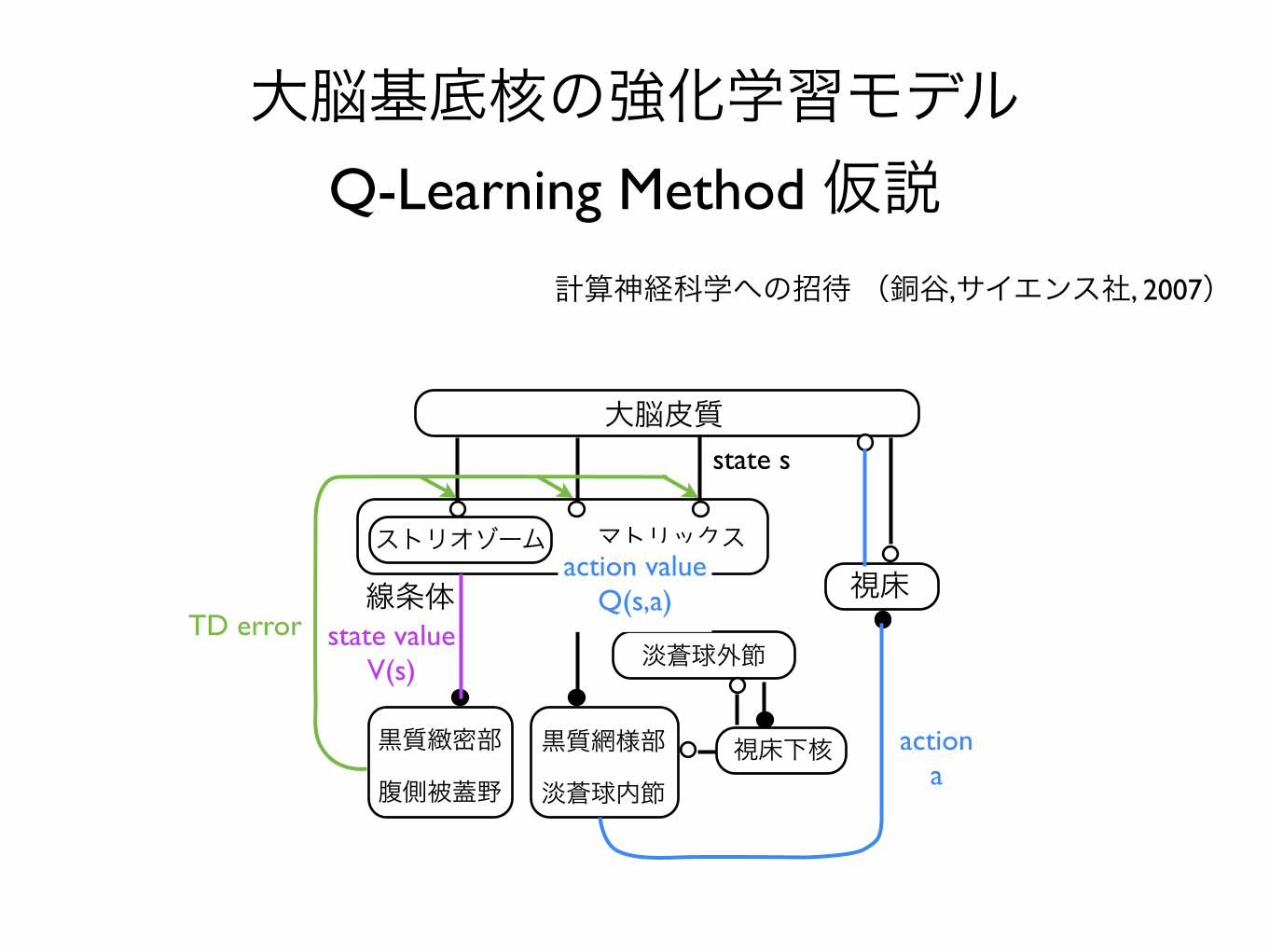
大脳基底核の強化学習モデル Q-Learning Method 仮説
大脳皮質
ストリオゾーム マトリックス
線条体
黒質緻密部
腹側被蓋野
黒質網様部
淡蒼球内節視床下核
淡蒼球外節
視床action valueQ(s,a)
actiona
state valueV(s)
TD error
state s
計算神経科学への招待 (銅谷,サイエンス社, 2007)

運動学習における 強化学習
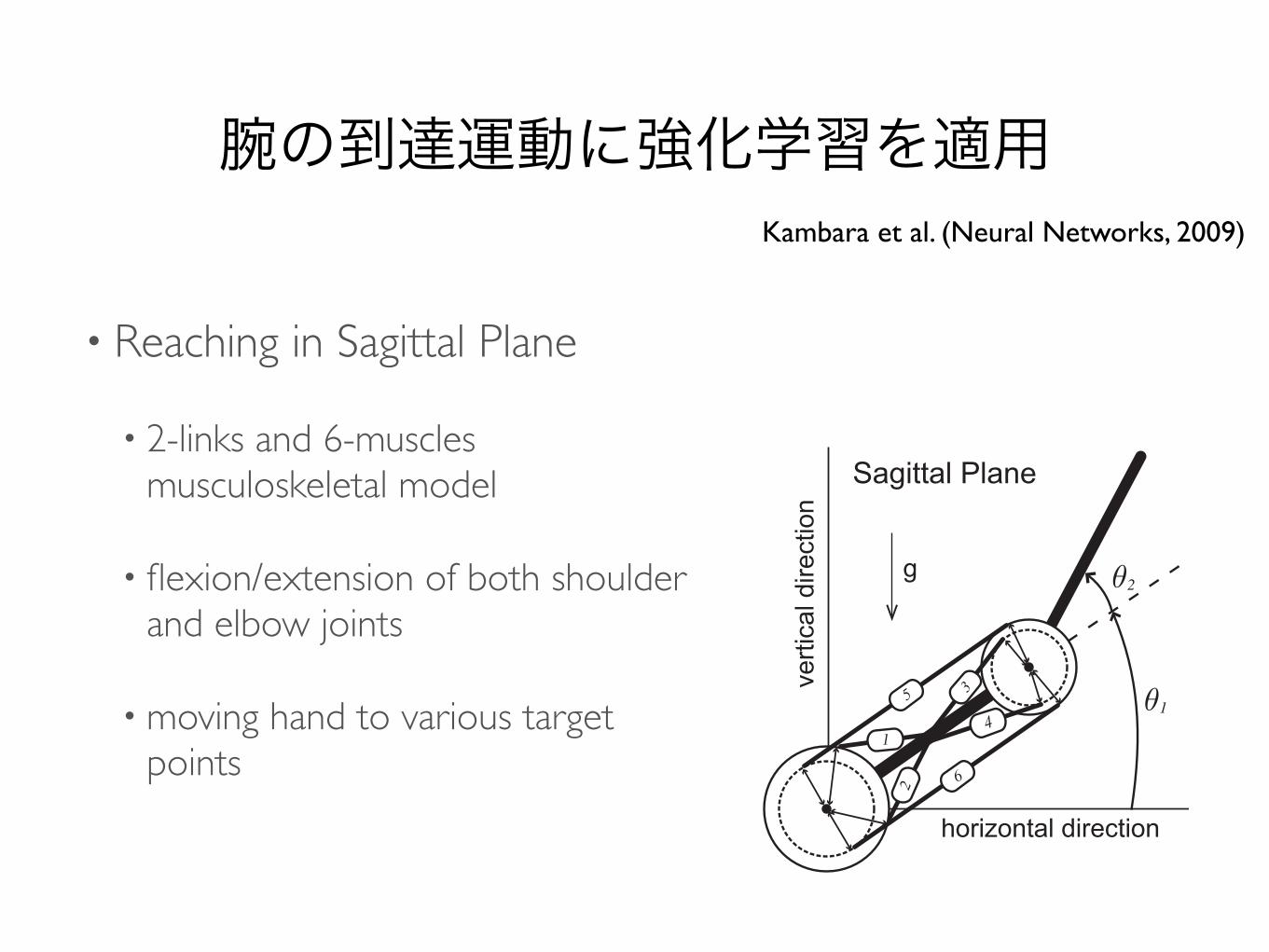
腕の到達運動に強化学習を適用
• Reaching in Sagittal Plane
• 2-links and 6-muscles musculoskeletal model
• flexion/extension of both shoulder and elbow joints
• moving hand to various target points
1
2
1
5
4
3
2 6
horizontal directionve
rtica
l dire
ctio
n
Sagittal Plane
g
Kambara et al. (Neural Networks, 2009)
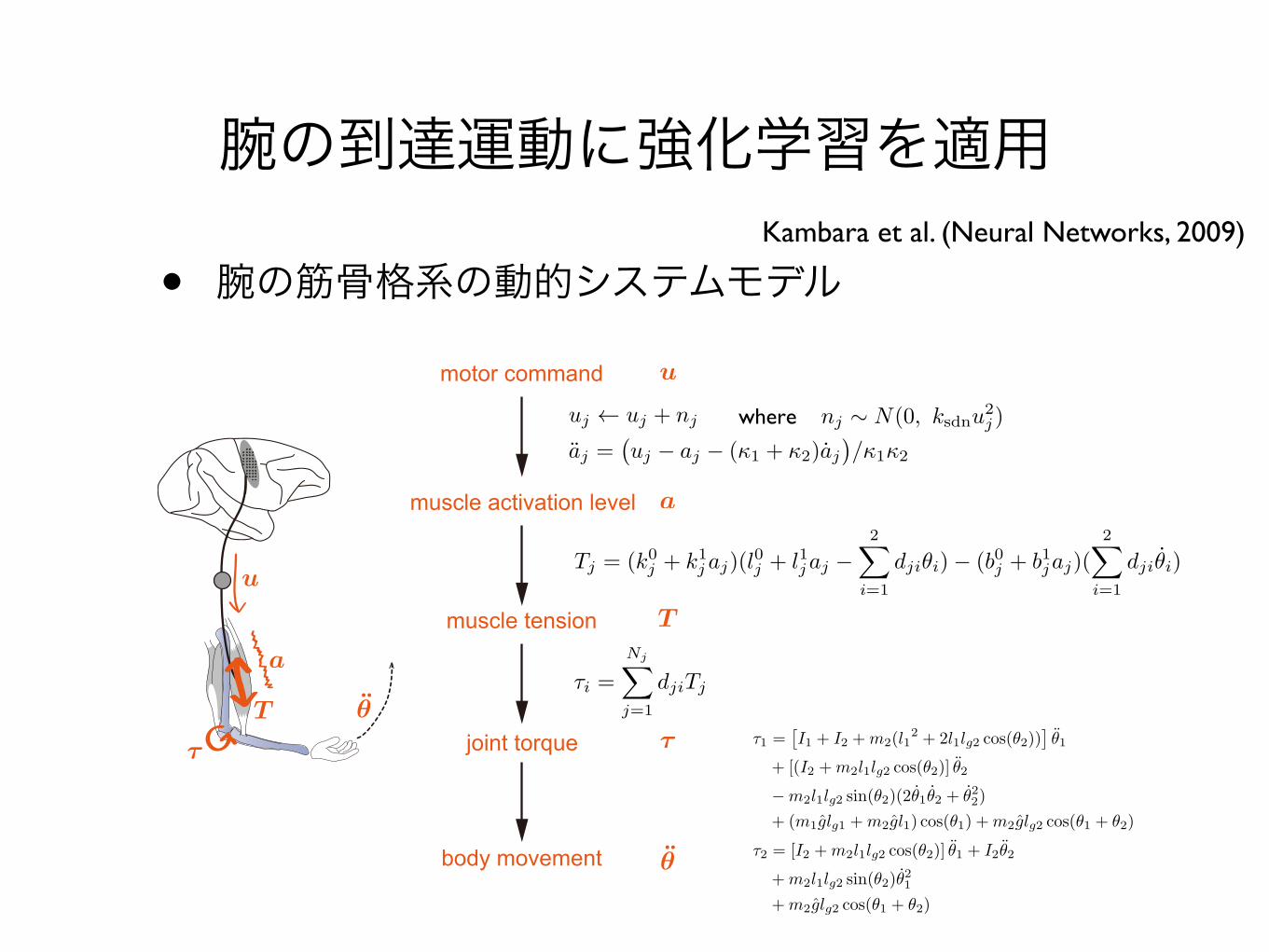
腕の到達運動に強化学習を適用
• 腕の筋骨格系の動的システムモデル
motor command
muscle activation level
muscle tension
joint torque
body movement
where
Kambara et al. (Neural Networks, 2009)
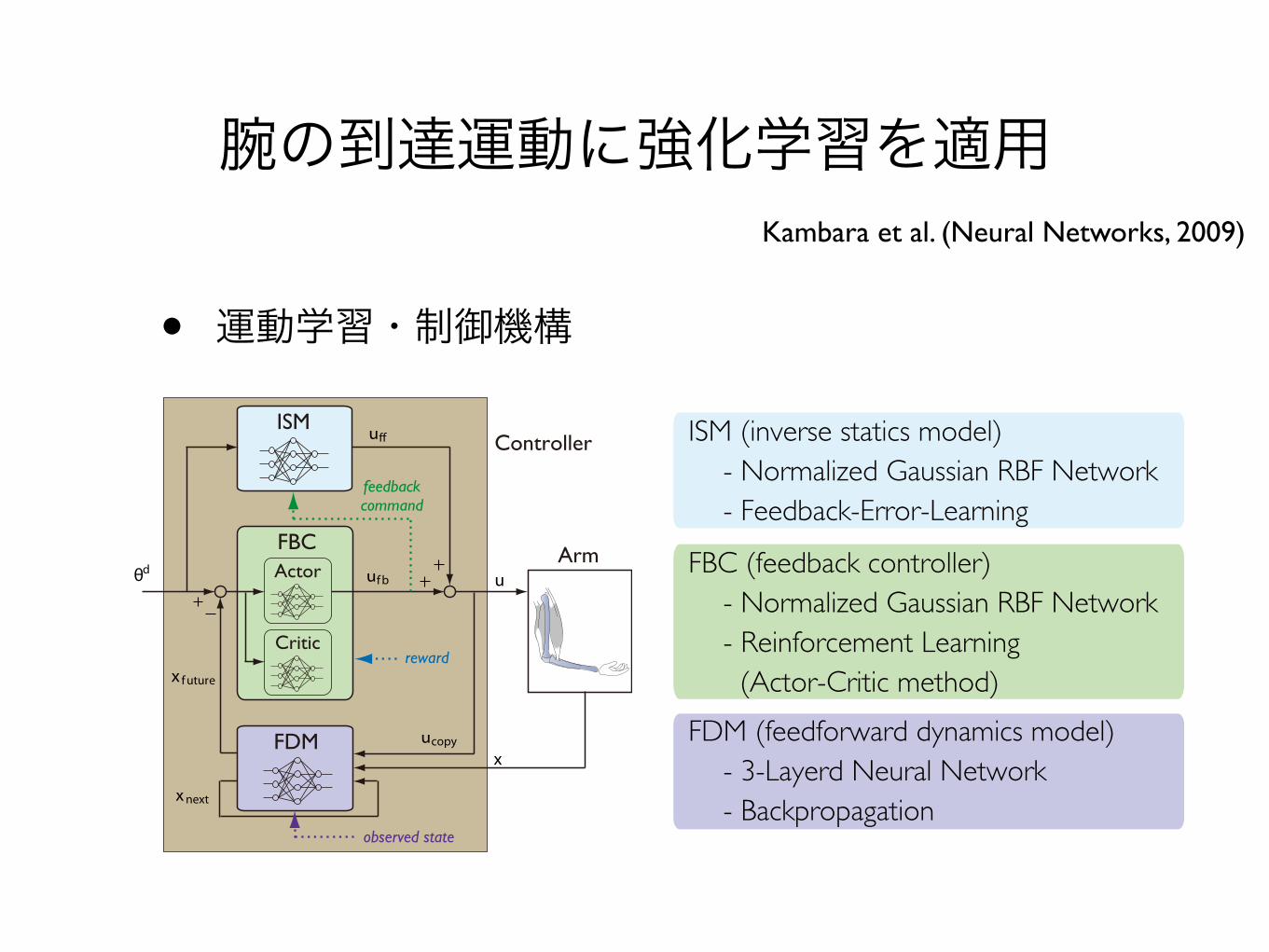
腕の到達運動に強化学習を適用
• 運動学習・制御機構
FDM (feedforward dynamics model)- 3-Layerd Neural Network- Backpropagation
ISM (inverse statics model)- Normalized Gaussian RBF Network- Feedback-Error-Learning
FBC (feedback controller)- Normalized Gaussian RBF Network- Reinforcement Learning (Actor-Critic method)
ISM
FBCActor
Critic
FDM
observed state
reward
feedbackcommand
θd ufb
uff
u
x
x future
xnext
ucopy
Arm
Controller
Kambara et al. (Neural Networks, 2009)

腕の到達運動に強化学習を適用
shoulder
elbow
hand
0 0.5 10
1
2
Velo
city
[m/s
]
Time [s]0 0.5 1
0
1
2
Velo
city
[m/s
]
Time [s]0 0.5 1
0
1
2
Velo
city
[m/s
]
Time [s]0 0.5 1
0
1
2Ve
loci
ty [m
/s]
Time [s]
(A) 1,000th trial (B) 5,000th trial (C) 10,000th trial (D) 100,000th trial
0.3 0.4 0.5 0.6
−0.4
−0.2
0
0 0.5
0
1
2
0 0.5
0
1
2
0 0.5
0
1
2
0 0.5
0
1
2
0 0.5
0
1
2
0 0.5
0
1
2
0 0.5
0
1
2
Horizontal (X) position [m]
Ve
rtic
al (Y
) p
ositio
n [m
]
a
b
e
c
d
f
g
Time [s]
Ve
locity [
m/s
]
a b
e
c
d f g
subject A
proposed model
min-variance model
(A)
学習中の到達運動軌道の変化
学習後の運動軌道を被験者のデータと比較
Kambara et al. (Neural Networks, 2009)
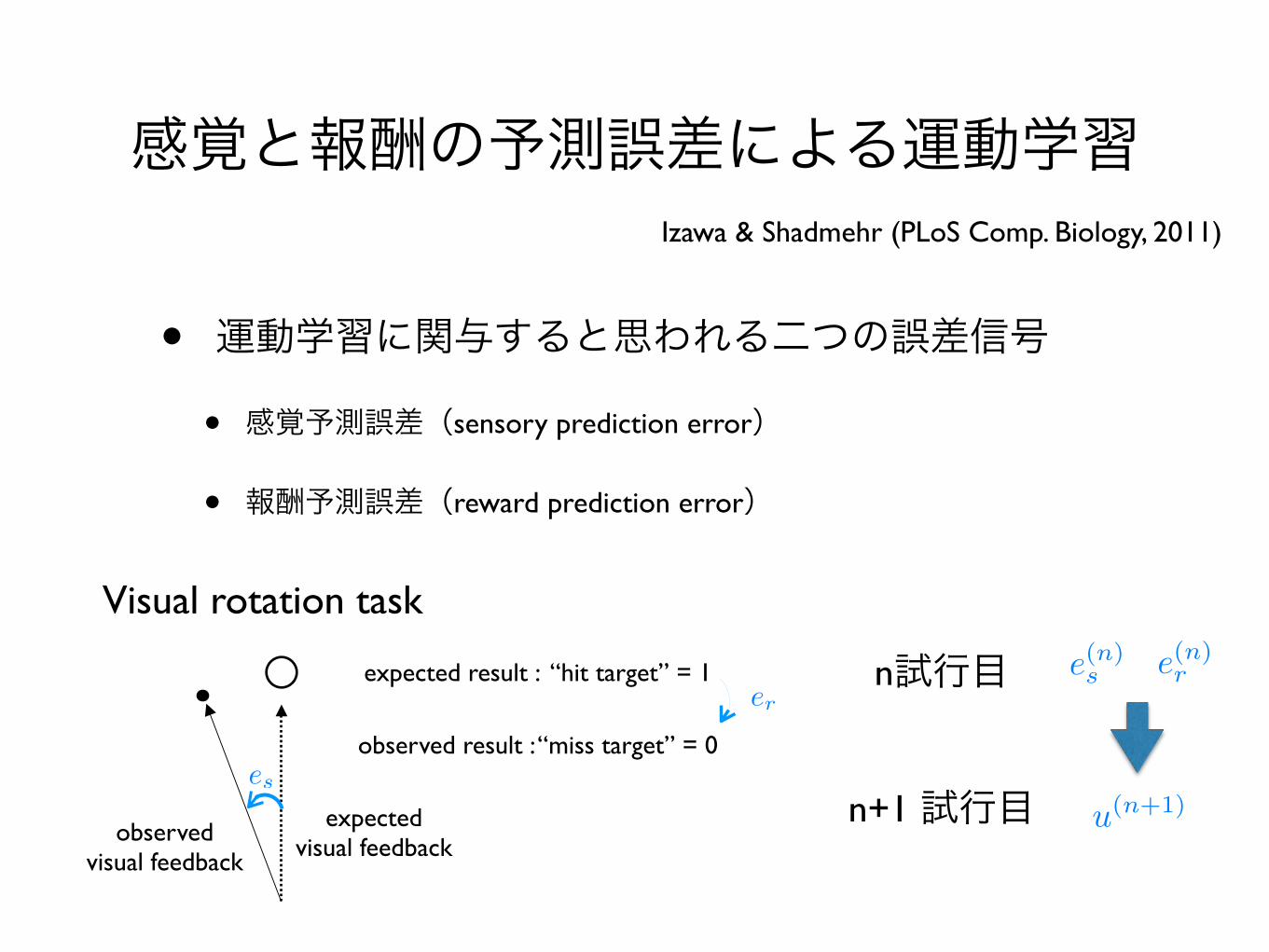
感覚と報酬の予測誤差による運動学習
• 運動学習に関与すると思われる二つの誤差信号
• 感覚予測誤差(sensory prediction error)
• 報酬予測誤差(reward prediction error)
Izawa & Shadmehr (PLoS Comp. Biology, 2011)
Visual rotation task
expectedvisual feedback
observedvisual feedback
expected result : “hit target” = 1
observed result : “miss target” = 0es
ern試行目
n+1 試行目
e(n)re(n)s
u(n+1)

感覚と報酬の予測誤差による運動学習Izawa & Shadmehr (PLoS Comp. Biology, 2011)
• Sensory and Reward prediction errors engage learning in distinct neural structures.
• sensory prediction error drives a sensory remapping and broad generalization.
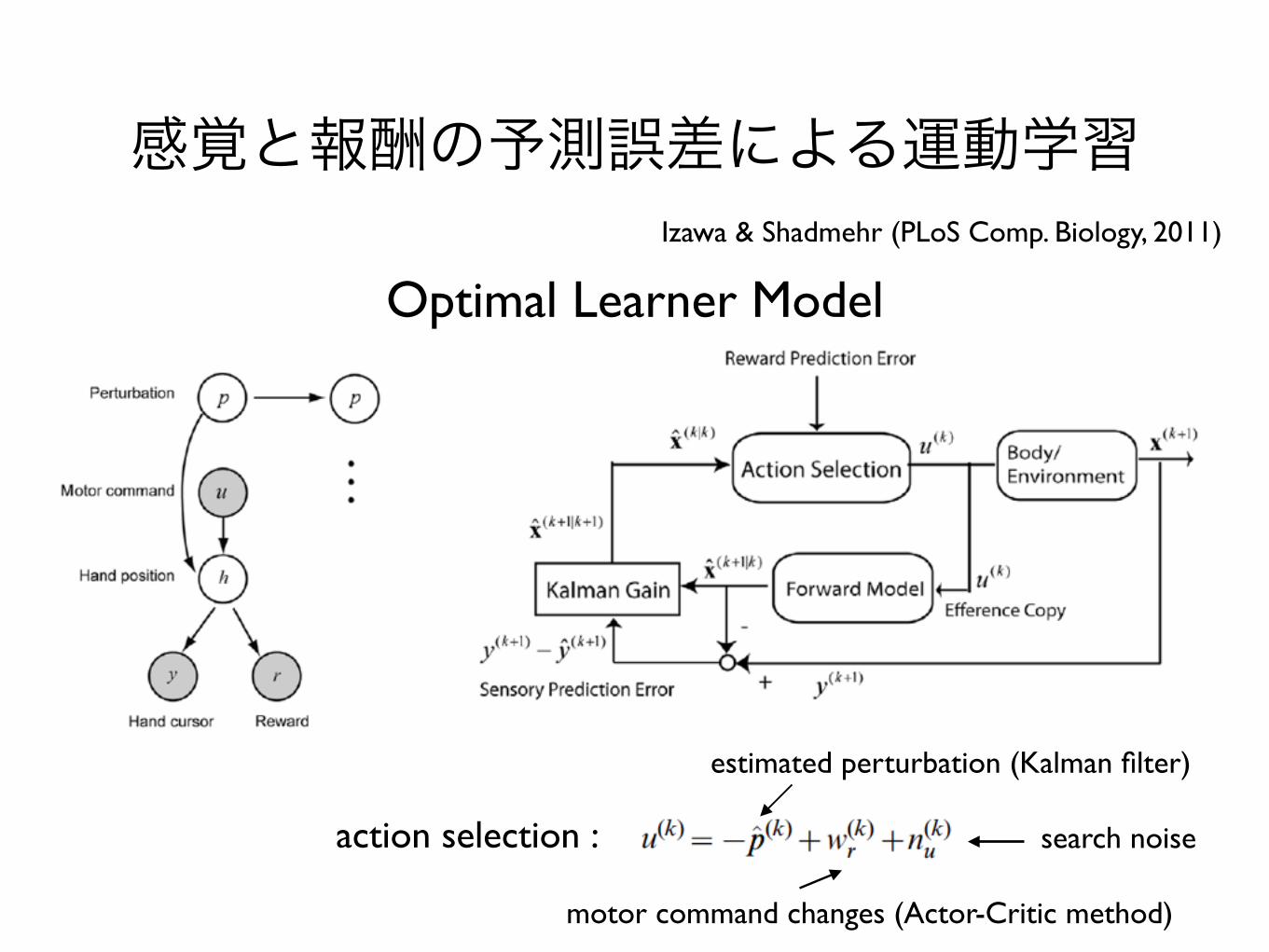
感覚と報酬の予測誤差による運動学習Izawa & Shadmehr (PLoS Comp. Biology, 2011)
Optimal Learner Model
action selection :
estimated perturbation (Kalman filter)
motor command changes (Actor-Critic method)
search noise
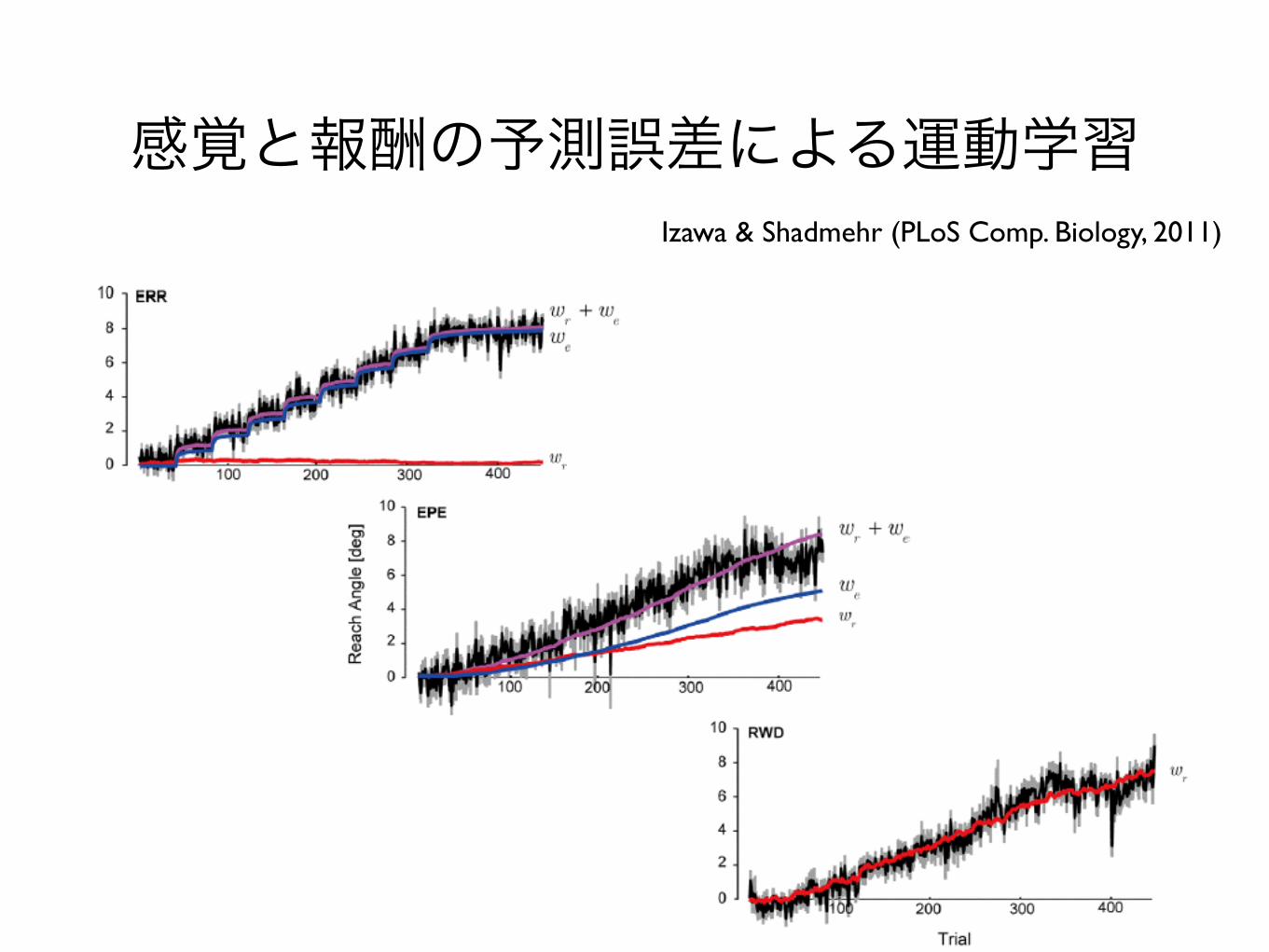
感覚と報酬の予測誤差による運動学習Izawa & Shadmehr (PLoS Comp. Biology, 2011)

Summary
• 強化学習では環境や報酬(コスト)のモデルがなくても試行錯誤を通じて最適な行動(方策)を学習可能
• 強化学習の枠組みに従った学習が大脳基底核を含めた神経回路機構で実現されている可能性
• 意思決定だけでなく運動学習や運動適応も強化学習で行われている可能性

Reference
• Dora, K. What are the computations of the cerebellum, the basal ganglia and the cerebral cortex? Neural Networks, 12, 961-974, (1999)
• Reinforcement Learning -An Introduction-, Sutton & Barto, 1999, MIT Press.
• ︎︎︎︎︎木村元, 小林重信, Actorに適性度の履歴を用いたActor-Criticアルゴリズム: 不完全なValue-
Functionのもとでの強化学習, 人工知能学会誌, 11, (1996).
• Williams, R. J., Simple Statistical Gradient ︎Following Algorithms for Connectionist Reinforcement Learning, Machine Learning, 8, 229-256, 1992. ︎ ︎ ︎︎
• 計算論的神経科学への招待, 銅谷賢治, 2007, サイエンス社.
• Schultz, W., Dayan, P., Montague, P.R., A Neural Substrate of Prediction and Reward, Science, 275, 1593-1599, (1997).
• Kawagoe, R., Takikawa, Y., Hikosaka, O., Expectation of reward modulates cognitive signals in the basal ganglia, Nature Neuroscience, 1, 411-416, (1998).
• Samejima, K., Ueda, Y., Doya, K., Kimura, M., Representation of Action-Specific Reward Values in the Striatum, Science, 310, 1337-1340, (2005).
• Kambara, H., Kim, K., Shin, D., Sato, M., Koike, Y., Learning and generation of goal-directed arm reaching from scratch, 22, 348-361, (2009)
• Izawa, J., Shadmehr, R., Learning from Sensory and Reward Prediction Errors during Motor Adaptation, PLoS Computational Biology, 7, e1002012, (2011).

Exercise
• Izawa & Shadmehr 2011 にある Optimal Learner Model
を用いてVisual Rotation Task をシミュレーションしてみよう