doing data science_ch2
TRANSCRIPT

Doing Data Science통계적 추론, 탐색적 데이터분석과 데이터 과학 과정

통계적 추론● 데이터 과학 학습의 적절한 출발점이지 않을까?● 모수(parameter)에 대한 어떤 판단을 내리기 위하여, 모집단(population)에서 표본(sample)을 추출하여 데이터를 얻고 이 데이터를 기초로 하여 통계이론에 의한 결론을 내리는 과정
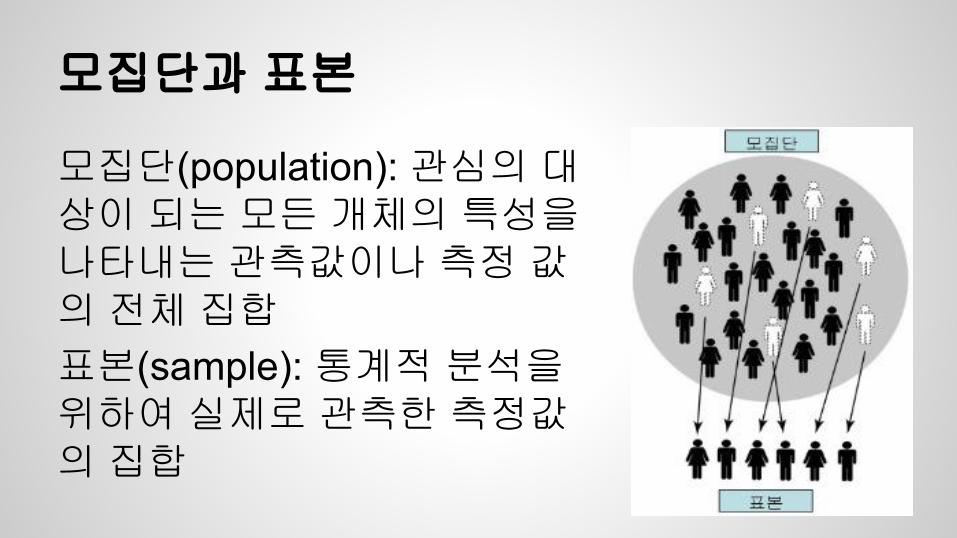
모집단과 표본
모집단(population): 관심의 대상이 되는 모든 개체의 특성을 나타내는 관측값이나 측정 값의 전체 집합표본(sample): 통계적 분석을 위하여 실제로 관측한 측정값의 집합

빅데이터의 모집단과 표본
● 빅데이터인데 모집단과 표본이 필요한가?○ 응. 데이터와 머신들이 무한하진 않잖아?
● ex) 허리케인 샌디 전후의 트윗 분석에 대한 오판, 47p
● 사실 모집단이 표본이였고 더큰 모집단이 있었어. One more thing. 더큰 모집단이 또있지롱. 그래서 표본을 잘 만들어야....
● 쌓이는 데이터 포맷은 다양

빅데이터는 커다란 가정?
● 보통 아닌데?● 데이터는 단지 사건들의 정량적이며 수동적인 반향일 뿐이다.

모형화(Model)
● 건축가는 청사진과 3차원 축소 모형, 분자생물학자는 아미노산연결을 3차원화, 데이터 과학자는 데이터의 형태와 구조를 표현하는 수학적 함수로 데이터 생성과정의 불확실성과 무작위성을 포착

● 우선 탐색적 데이터분석(EDA) 부터 시도하면서 그래프를 그리고 선형함수도 적어보고 이것저것 주관적으로 끼워맞춘다.
● 경험이 쌓이면 모형을 만드는 자신만의 툴킷이 생기고 그중 하나로 확률분포를 써라.
● 만들고나면 적합, 과적합이 된다. 적합한 모형을 만들기 위해 R, Python을 이용하자.
모형은 어떻게 만들어요?

확률분포

탐색적 데이터 분석
● 가설이나 검증에 치우치지 않고 도표, 그래프, 요약 통계 같은 방법으로 데이터 자체를 분석

데이터과학 과정

리얼다이렉트 사례
아.... 읽고 한번 이야기 해봐요....

끝