fredrik, göran, henrik, håkan, jessica, johanna, jyrki...
TRANSCRIPT

TENTAFRÅGOR & SVARSFÖRSLAG – PSYKOLOGISK FORSKNINGSMETOD II
Frågorna är tagna ur tentorna den 17 oktober 20??, 21 december 2005, 7 juni 2006, 22 augusti 2006, 5 juni 2007, 5 juni 2008, 4 juni 2009, 21 augusti 2009. “(2 av 5)” anger att en fråga förekommer vid två av fem av tentorna. Kravet för G är 60% (16,2 resp 16,8 av 27 resp 28). Svarsförslag av Eleanor, Fredrik, Göran, Henrik, Håkan, Jessica, Johanna, Jyrki, Louise, Maja, Mimmi, Monica, Nahla, Per, Thomas m fl.
Parametiskt vs. icke-parametriskt 1. Icke-parametriska analysmetoder kallas med ett annat ord för fördelningsfria analyser. Hur förklarar du relevansen hos detta begrepp? Och vad står parametrisk och dess motsats icke-parametrisk för?
Parametrisk innebär att man uttalar sig om parametrar - medelvärde, standardavvikelse och samband - i en population utifrån estimat, uppskattningar, från ett stickprov. Icke-parametriska test baseras på rangordningar och median när man bearbetar data till skillnad från parametriska test som utgår ifrån jämna fördelningar av datavärden - där data fördelar sig jämt kring medelvärdet d v s är normalfördelat. Alltså för att kunna använda parametrisk statistik behöver data vara normalfördelat; de uppmätta värdena fördelar sig jämt (någorlunda i alla fall) kring sitt medelvärde. Data behöver dock inte
2. Vad tar du hänsyn till när du ska välja mellan att använda parametrisk eller icke-parametrisk statistik? Ge exempel på tre icke-parametriska alternativ till vanliga parametriska analyser eller sambandsmått. (Obs! Tydliga benämningar behövs) (2 tentor av 8)
vara normalfördelat om man ska använda icke-parametriska test.
• Är data normalfördelade? Ja – parametriskt test. Nej – icke parametriskt test.
Ev. överkurs: Om data är snedfördelat så är medelvärdet inte representativt för vad man i genomsnitt fått för värde i gruppen. Icke-parametriska test baserar sig på medianen som bättre motstår out-liers (avvikande värden) än medelvärdet.
• Vilken skalnivå ligger data på? Kvot, intervall (även ordinal med fler än 7 skalsteg) – parametriskt test. Nominal och ordinal – icke-parametriskt test.
• Är man intresserad av populationen? Om man utifrån stickprovet vill säga något om medelvärdet, standaravvikelsen eller sambandet i populationen – parametriskt test. Om inte – icke-parametriskt test.
Oberoende t-test – Mann Whitney´s U test Beroende t-test – Wilcoxon´s signed rank test Pearson´s r – Spearman´s rho
3. Du står inför några analysuppdrag och har konstaterat att dina data inte klarar av parametrisk statistik. Hur löser du följande uppgifter? Svaren kan vara korta (t ex namnet på ett sambandsmått) men de behöver vara exakta. Så tänk efter innan du svarar!
a) Uttrycka sambandsstyrkan mellan fasadfärgen på hus (röd/vit/blå) och ort (Uppsala/Falun) Annan tenta:
Data är på nominalnivå. För att räkna ut sambandet mellan variablerna kan man räkna ut sambandsmåttet phi.
Uttrycka sambandsstyrkan mellan variablerna bostadsområde (Gottsunda/Luthagen) och invånarnas sjukskrivningsstatus (sjukskriven/icke-sjukskriven).
b) Uttrycka den centrala tendensen för poäng från ett prov.
Medianen. Eftersom det är poäng från ett prov så ligger data på kvotnivå men outliers på nedsidan gör att data inte är normalfördelat (extremt dåliga resultat påverkar medelvärdet mer än extremt bra resultat).
c) Undersöka och uttrycka sambandet mellan för- och eftermätningsvärden i samband med depressionsbehandling.
Här är det sambandsmått som ska räknas ut. Om data är på ordinalnivå använder man sig av Spearmans ρ (rho) eller
Kendalls τ (tau).

d) Analysera skillnaden mellan för- och eftermätningsvärden i samband med depressionsbehandling. (så att du kan avgöra om en förändring var signifikant eller inte) (3 tentor av 8)
Här behöver vi ett icke-parametriskt test för en inomgruppsdesign med en OBV med två lägen. Det som står till buds är Wilcoxon signed-rank test
4. Som bekant så finns det icke-parametriska alternativ till vissa vanliga parametriska analyser och sambandsmått. Nedan ser du namnen på några analysmetoder och sambandsmått. Din uppgift är att fylla i den icke-parametriska eller parametriska motsvarigheten till analysmetoden/sambandsmåttet som redan finns i listan. (Namnen du använder ska vara entydiga så att ingen tveksamhet råder kring vilken analys/sambandsmått du avser)
om data är på ordinalnivå. Alternativt McNemars test of change om data är på nominalnivå.
Icke-parametriskt Parametriskt
? Pearsons r Mann-Whitneys U test ? ? Beroende (inomgrupps) t-test
Ickeparametriskt Parametriskt (typ av mått)
Spearmans ρ (rho) Pearsons r samband, korrelation Mann-Whitney U test Oberoende t-test test av skillnad mellan grupper Wilcoxon signed-rank test Beroende t-test test av skillnad inom grupp (Kruskall Wallis test Mellangrupps envägs-ANOVA envägs oberoende grupper/mätningar) (Friedmans test Inomgrupps envägs- ANOVA envägs beroende/upprepade grupper/mätningar)
5. Nedan ser du två fyrfältstabell A och B med observerade värden ifyllda. Gör en jämförelse mellan de två tabellerna betr den relativa storleken av förmodat chi2-värde, p-värde och phi. Ange om dessa är lika eller olika stora för tabellerna A och B. Du svarar enklast genom att notera något av tecknen >, =, < mellan A och B här nedan. OBS! Du behöver absolut inte beräkna någonting för att kunna svara på frågan. OBS OBS!! Tänk efter ordentligt, slarva inte!
chi2: A B A: B: p-värde: A B K M K M phi A B Ja 25 50 75 Ja 50 100 150 Nej 75 50 125 Nej 150 100 250 100 100 200 200 200 400 (2 tentor av 8)
Svar: χ2 (Chi2): A < B (ökat sample ökar homogenitet) p-värde: A > B (minskat sample ökar sannolikhet för nollhypotes) φ (Phi): A = B (korrelationen är densamma oavsett samplestorlek)
• Bonusfråga jag ej hittade tidigare:
Vad är det som gör icke-parametriska analysmetoder och sambandsmått mer tillförlitliga när data inte är normalfördelade eller når upp till föreskriven skalnivå?
Svar: Icke-parametriska test kan ”motstå” outliers (enstaka extrema värden) och sneda fördelningar bättre tack vare mediancentrering (istället för geomertiskt medelvärde) och behandling av data som rangordnade.
• Ytterligare fråga jag ej hittade tidigare:
Förklara principen bakom en chi2-analys. Vilka värden jämförs i analysen? Vad är nollhypotesen? Vilken uppfattning om sambandets styrka får du genom själva chi2-värdet? Vilka faktorer påverkar chi2-värdet? (max en A4)

Chi2 används för att signifikanstesta en hypotes, alltså en form av hypotesprövning. Man vill t.ex dra slutsatser om två grupper skiljer sig från varandra/har samband utifrån data insamlat från (representativa) stickprov.
Chi2-testet bygger på att de observerade frekvenserna (i tabellen) jämförs med de som skulle ha genererats, alltså de förväntade frekvenserna, om slumpen hade styrt, dvs. om nollhypotesen är sann (om statistiskt oberoende hade förelagat mellan variablerna) . Två händelser A och B kan sägas vara statistiskt oberoende om kunskap om den ena inte bidrar till att förutsäga utfallet av den andra. Sannolikheten för att A inträffar är i så fall densamma oavsett om B inträffar eller inte. Man jämför alltså den observerade fördelningen (i fyrfälts/korstabellen) med en förväntad fördelning med hjälp av en formel:
( )22
1
ni i
i i
O FF
χ=
−=∑ ,
( )2
2
1 1
n mij ij
i j ij
O FF
χ= =
−=∑∑
O = Observerat värde F = Förväntat värde
Nollhypotesen = det finns inga skillnader mellan populationerna. Den uppkomna stickprovsskillnaden beror på slumpen.
Chi2-värdet man får fram jämför man sedan med det kritiska chi2- värdet som man letar upp i en tabell efter att man bestämt vilken signifikansnivå man vill ha, (vanligen 5%). I tabellen går man in på det antal frihetsgrader som gäller dvs. (antal kolumner-1)multiplicerat med (antal rader-1) alltså (k-1)x(r-1) samt utgår i tabellen från signifikansnivån och finner då det kritiska chi2-värdet som anger gränsen för om mitt framräknade (från fyrfälts/korsfältstabellen uträknat) chi2-värde är signifikant eller inte. Alltså om skillnaderna/sambandet mellan grupperna uppkommit av slumpen eller ej. Om jag räknat ut ett chi2-värde på ex. 3.95 och får ett kritiskt chi2-värde (på 5% sign.nivå) på 3.84 så är chi2-värdet högre och därmed gäller inte nollhypotesen, H0 förkastas. Om det framräknade chi2-värdet hade varit mellan 0 och det kritiska chi2-värdet hade H1 gällt dvs. att det finns en signifikant skillnad mellan grupperna.
Chi2-värdet säger inget om styrkan i sambandet (ej heller om orsak och verkan). Ett signifikant mått på chi2 behöver inte betyda att sambandets styrka är kraftigt. För att få fram styrkan i sambandet måste man använda
sambandsmåttet Phi φ som har en egen formel. (Cramer's Nu ν för matris större än 2x2)
2
Nχφ =
,
2
( 1)N kχυ =−
Chi2-värdet påverkas av (är känsligt för) antal observationer. Om antalet fall/observationer hade varit 100 gånger större (i var och en av cellerna i fyrfälts/korstabellen) så skulle chi2-värdet likaså ha blivit 100 gånger större, utan att sambandet mellan variablerna hade förändrats.
De faktorer som påverkar det framräknade chi2-värdet är: de observerade (aktuella) värdena, de förväntade värdena, sampelstorlek (se ovan) samt antal kategorier som ju bestämmer antalet frihetsgrader (dvs antal kolumner och rader i tabellen, se ovan).
(Jag kommer inte på några fler faktorer som påverkar...)
• Och ytterligare en:
1b Vilket sambandsmått använder du som ett komplement till resultatet från din chi2-analys när ursprungsdata är uppställd som en 2x2-tabell?
Chi2-testet används för att avgöra om variabler överhuvudtaget är relaterade till varandra men svarar inte på hur starkt sambandet är. Ett signifikant värde på chi2 behöver inte betyda att sambandets styrka är kraftigt. Detta görs istället med sambandsmåttet phi för nominalskalor.
• Och ytterligare en:
Beskriv en situation där det finns anledning att överväga användningen av ett icke-parametriskt alternativ till en parametrisk analysmetod. Vilka egenskaper hos insamlad data påverkar ditt beslut?

OBV1
BV
OBV2
Icke-parametriska test är att rekommendera då:
Mätskalenivån är nominal eller ordinal med mindre än sju skalsteg
Om data inte är normalfördelat
Innehåller en del extrema värden
Detta eftersom icke-parametriska test räknar efter datas rangordning (blir då inte känsligt för outliers) och använder sig av median stället för medelvärde.
En situation kan vara att kunder i en affär får skatta hur stressig de tycker julen är och sedan ser om det finns någon könsskillnad. Vi vet inte om det är jämn fördelning av män och kvinnor i studien, vidare har vår skattning mindre än sjuskalsteg. (Hur intressant detta nu skulle vara att ta reda på, har inte fantasi att hitta på något bättre……)
Korrelation 6. Pearson’s korrelationskoefficient (r) har förmågan att uttrycka sambandets styrka och riktning. Redogör för logiken bakom detta sambandsmått. Vad bygger den på och vad är det man intresserar sig för vid beräkningen av korrelationskoefficienten? OBS! Ditt svar behöver inte innehålla någon formel. (2 tentor av 8) --- Korrelationskoefficienten r uttrycker hur två variabler samvarierar d v s när en variabel ökar så ökar den andra på motsvarande sätt och tvärtom – positivt samband. Alternativt så ökar den ena och den andra minskar – negativt samband. Variablernas samvariation kallas för kovarians; ett mått för hur variablerna gemensamt varierar kring sina medelvärden. Korrelationskoefficienten är den standardiserade kovariansen och kan anta värden mellan -1 och +1, perfekt negativt respektive positivt samband. Korrelationskoefficienten kan bara beskriva linjära samband, andra typer av samband, t ex kurvilinjära, missar den. Genom att kvadrera r får man fram effektstorleken, vilket är detsamma som andel förklarad varians –
d v s hur stor del av variansen i y som förklaras av x. Liten, medel, stor effekt = 1, 9, 25 procent. Man kan även se hur starkt sambandet är genom att bara titta på r; 0.1, 0.3, 0.5, liten medel och stor effekt.
7. Bivariat korrelation, partialkorrelation, multipel korrelation. Förklara vad dessa är för någonting, vad de uttrycker och i vilka sammanhang de kommer till användning. Illustrera begreppet förklarad varians i samband med alla tre.
Bivariat korrelation Handlar om korrelationen mellan två variabler. Man mäter hur stor del av BV som överlappas av OBV1.
Partial korrelation Mått på OBV1:s effekt på BV justerad för OBV2:s effekt på BV och OBV1. Används när man vill mäta den unika varians som förklaras av en av variablerna. I nedanstående exempel är det alltså det lila fältet man är intresserad av.
Multipel korrelation
8. Vilket sambandsmått skulle du välja att använda i följande fall? Motivera kort!
Den sammanlagda varians som alla de oberoende variablerna förklarar i den beroende variabeln, dvs. summan av OBV1:s korrelation med BV + det unika bidrag i förklarad varians varje ny OBV medför. I det här fallet är man alltså intresserade av alla överlappningar av oberoende variabler på BV, dvs. både det lila och det bruna fältet.
a) Du har tillgång till placeringarna från 15 barn som tävlat i höjdhopp och längdhopp och vill studera sambandet.

Data ligger på ordinalskalenivå (de har en inbördes rangordning) och vi vill se sambandet mellan dessa rangordningar då är Spearman´s rho (Spearman´s rank-order correlation coefficient, som den också kallas) och Kendall´s tau (Kendall´s rank-order correlation coefficient) bäst att använda.
b) Från en annan tävling med lika många deltagare har du tillgång till deltagarnas kroppslängd och höjden de klarade av i tävlingen.
Pearson´s Product Moment korrelationskoefficient (r). Kan användas då data ligger på kvotskalenivå.
c) Du vill studera sambandet mellan kön och vilka som vunnit Melodifestivalen sedan tävlingarna startades.
Här skulle jag använda chi-2 (Phi) då vi studerar två grupper (män/kvinnor) som vi delar in i två kategorier, observerad vinst och förväntad vinst. Nollhypotesen är att lika många män som kvinnor har vunnit. Jag undersöker om det finns det en signifikant könsskillnad på Melodifestivalens vinnare. Varje cell kommer att ha minst 10 personer och i ett fyrfält rekommenderas ytterligare 10. (genom åren har ju minst 10 män och minst 10 kvinnor vunnit). Därmed har jag också tillräckligt många personer med i beräkningen.
Regression 9. På din PTP-arbetsplats kommer en AT-läkare (som saknar den gedigna metodutbildningen du har fått) fram till dig och undrar: ”Jag är lite förvirrad över det här med korrelation och regression, på något sätt verkar dom höra ihop men å andra sidan är dom ju inte samma sak heller. Kan du förklara för mig hur det ligger till med detta?” Kan du reda ut begreppen? Vad har korrelation och regression gemensamt och vad är det som är utmärkande för dem för sig? Vad får vi ut av respektive metoder? Försök att beskriva väsentligheterna för dessa metoder utan att fördjupa dig i alla detaljer (= max en A4-sida).
Båda är mått på samband som bygger på kovariansen mellan två variabler. Korrelationer beskriver om
---
det finns ett samband, dess styrka och riktning d v s om det är ett positivt (om x ökar så ökar y också) eller negativt samband (om x ökar så minskar y). Korrelationen uttrycks med korrelationskoefficienten som kan anta värden mellan -1 och +1 där +/-1 står för ett perfekt positivt respektive negativt samband och 0 = inget samband. Regressionen går ett steg längre och är mer exakt än korrelationen. Den bygger också på korrelationsberäkningar men utnyttjar beräkningen lite bättre. Genom att räkna ut regressionsekvationen kan man göra prediktioner, alltså utifrån värdet på x kan vi förutsäga värdet på y.
Korrelation: r = sambandet mellan två eller flera variabler Korrelationen varierar mellan -1 och 1, där 0 innebär att det inte finns något samband och -1 eller 1 att sambandet är totalt -mao ett uttryck för styrka och riktning hos ett linjärt samband. Korrelationen beror dessutom av antalet observationer varför man omvandlar det till en normalfördelad sannolikhet. Denna betecknas p och varierar mellan 0 och 1. För att ett samband ska anses vara säkert måste p vara mindre än 0.05. Det finns ytterligare en vanlig korrelation, Spearmans rangkorrelations koefficient (åtminstone ordinalnivå på datan). Ex: Ålder och motorisk förmåga. Skolbetyg och yrkesframgång. Att två variabler är korrelerade bevisar inte att det föreligger orsaksförhållande mellan dem. Ex: Det finns en positiv korrelation mellan längd och vikt; längd och vikt är positivt korrelerade. Samvariationen innebär att ju större längden är desto större är i allmänhet vikten och ju mindre längden är desto mindre är i allmänhet vikten. Ex: Det finns ett negativt samband mellan ålder och ögats förmåga att anpassa sig till seende på nära håll. Ju högre ålder i år desto sämre är i allmänhet denna förmåga. Korrelationskoefficient - mått på korrelationen mellan variabler. Två viktiga koefficienter är produktmomentkorrelationskoefficienten och Spearmans rangkorrelationskoefficient.
Regression är mer exakt än korrelation. Regression bygger på korrelationsberäkning men utnyttjar beräkningen lite bättre. Man kan därmed göra mer exakta prediktioner från x till y.

Y kan prediceras utifrån X mha regressionsekvationen Y = a + bX Y = kriterievariabel X = prediktorvariabel a = interceptet (värdet på Y då X = 0) b = regressionskoefficienten (hur mga enheter av Y får man per enheter av X; exempelvis nedan: försäljning i kg Y per grader X)
Regression
Regressionsanalysens syfte kan variera. Ibland kan man vilja beskriva hur sambandet ser ut, ofta för att kunna förutsäga värden i den beroende variabeln med hjälp av värden på OBVn. Eller så vill man öka förståelsen för hur samband ser ut. Eller så letar man efter en så bra modell som möjligt för att beskriva ett samband. I analysen kan det då vara så att man prövar olika kombinationer av OBV. Enkel linjär regression: Ordet enkel syftar på att endast en oberoende variabel finns och ordet linjär på att undersökningsmaterialet, åskådliggjort i ett punktdiagram, ansluter väl till en tänkt linje. Regressionsekvationen kan alltså avbildas som en regressionslinje (ibland kallad regressionskurva) i koordinatsystemet. Prediktion kan sedan göras med hjälp av denna linje. Linjen ska läggas så att den går så nära varje punkt som möjligt. Den går alltid genom interceptet och punkten för X respektive Ys medelvärden.
: Regression är starkt sammankopplat med korrelation och man får med regression ut hur en variabel beror av en eller flera (sambandet mellan en BV och flera OBV). Detta fås i form av en funktion som är en medellinje mellan de olika observationerna. Det finns flera typer av regressioner. Den vanligaste är linjär regression, man får en linjär funktion. Ofta använd är också polynomial regression. En tredje vanlig typ är multipel regression, vilken jämför fler variabler än två (mer än en OBV).
Least squares regression line = summan av de kvadrerade avstånden mellan alla Y predicerade från ekvationen och det verkligt observerade Y ska vara så liten som möjligt.
Residualer = våra prediktionsfel (Y-Y’)
Något som är av vikt är att uppmärksamma om regressionskoefficienten är standardiserad eller inte. Standardiserade regressionskoefficienten β (beta) uttrycker X effekt på Y i SD och varierar beroende på sambandet. Den ickestandardiserade är däremot skalberoende vilket innebär att om man använder en skala på 0-5 på X ( b=1, β =0,7) visar den större effekt än då skalan ligger på 0-10 (b=0,5, β =0,7), fastän sambandet är lika.
Summering från C-C Korrelation En korrelationskoefficient beskriver relationen mellan två variabler. Kan även användas för att hitta statistisk signifikans av en given relation. Man gör ett scattergram av data och beaktar det testade samplets egenskaper för att
• Inte missa en relation för att den är icke-linjär.
• Eller för att undvika att föreslå ett samband som är en artefakt av samplet. Man kan genom korrelationstest försäkra sig om
• Reliabilitet –grad av att samma test kommer att ge samma score från ett tillfälle till ett annat
• Interbedömar-reliabilitet –graden av samstämmighet i användning av ett scoringsystem. Man kan även kontrollera vissa former av validitet av mått genom att använda korrelation.

Summering från C-C Regression –alternativt, relaterat (till korrelation) sätt att undersöka relationer. Relationer mellan variabler kan undersökas genom regression. Enkel regression=en OBV. Multipel vid fler än en OBV. En sådan analys har två funktioner:
• Identifiera hur mycket av variansen i BV som kan förklaras genom variation i OBV
• Att bygga en modell av hur BV är relaterad till OBV och därigenom möjliggöra prediktion av BV för specifika värden på OBV.
Ibland ser man multipel regression som ett exempel på multivariat statistik.
10. Hur anpassas regressionslinjen (dvs hur ska den "dras") i förhållande till observationerna i samband med en regressionsanalys? Förklara principen bakom det hela och belys relevanta begrepp som felvarians, förklarad varians, residual, kvadratsumman. Illustrera med en figur.
Principen är att regressionsberäkningen ska ge oss en regressionslinje som går så nära varje uppmätt värde som möjligt d v s vi vill kunna förklara så mycket varians (variation kring medelvärdet) som möjligt. Det här beräknas genom att kvadrera avståndet mellan varje faktiskt Y (uppmätt värde) och dess från ekvationen predicerade Y och räkna ut summan för dessa, kvadratsumman, som då ska vara så liten som möjligt. Linjen går alltid genom interceptet (värdet på Y när X=0) och punkten för X:s och Y:s medelvärde. De faktiska Y varierar kring medelvärdet (total varians) och vi vill med regressionlinjen beskriva hur den här variationen ser ut. De avstånd som finns mellan Y och regressionslinjen är felvariansen d v s våra prediktionsfel som också kallas för residualer. Den variation i Y som vi kan förklara med X kallas för förklarad varians och erhålls om man tar den totala variansen – felvariansen.
Ekvationen för regressionen som ger oss regressionskurvan ser ut så här:
Y= a+bX
…där Y är det predicerade värdet, a = interceptet och b = regressionskoefficienten som uttrycker hur mycket Y förändras då X ökar en enhet.
Dubbelpil visar residualer, vanlig pil som utgår från medelvärdet (mittenlinjen) till regressionslinjen visar på förklarad varians och pil från medelvärdet till punkterna åskådliggör den totala variansen. Detta är källorna till de olika typerna av varians vid prediktion. Bilden här ovan är inte särskilt bra, vissa dubbelpilar och vanliga pilar ligger över varandra, men kunde inte göra en bättre bild på datorn, bristande datafärdigheter alltså ;) I Timos handout finns bra bilder som åskådliggör detta tydligare.
---- Regressionslinjen bestäms matematiskt med hjälp av en metod som kallas minsta-kvadrat-metoden som innebär att koefficienterna a och b i regressionsekvationen
Y = a + bX
bestämts på det sätt som gör att summan av avstånden till linjen, sedan de kvadrerats, blir så liten som möjligt. Kvadreringen av avstånden (residualerna) och minimeringen av summan är de två kärnorden i metoden. MK-metoden innebär alltså att man bestämmer regressionslinjen så att residualkvadratsumman blir så liten som möjligt. Denna kvadratsumma är ett mått på variationen kring linjen, dvs. hur väl regressionslinjen beskriver materialet. Men kvadratsummans storlek bestäms inte bara av variationen kring linjen utan också av antalet observationer i materialet. Regressionslinjen går alltid igenom medelvärdet av X och Y.

Regressionsekvationen: Y = a + bX
Y = kriterievariabel, det man vill predicera X = prediktorvariabel, det man predicerar med a = interceptet, värdet på Y när X är noll b = regressionskoefficienten bestämmer lutningen på linjen. Den anger med hur många enheter Y ändras när X ökar med en enhet (åt höger).
Alltså det lodräta avståndet från punkten till regressionslinjen finns så snart en punkt inte ligger på själva linjen, dessa avstånd kallas som sagt för residualer. De är desamma som prediktionsfelen (Y – Y’) dvs. avståndet mellan prediktion (det predicerade Y’) och det verkligt observerade värdet (Y). För varje punkt mäter man avståndet – parallellt med y-axeln till linjen. Man kvadrerar alla dessa avstånd och summerar kvadraterna. Slutligen bestämmer man linjens ekvation så att summan av de kvadrerade avstånden mellan alla Y’ predicerade från ekvationen och faktiska Y ska vara så liten som möjligt. (Svårt att förklara utan att kunna rita; lättare om ni ser axlarna m reg.linje. se Timos föreläsningshäfte om ”Korrelation och regression” s.5)
11. En “kursare” till dig hävdar att hon/han under sitt uppsatsarbete har hittat ett starkt samband mellan två intressanta variabler. Som bevis visar hon/han ett tydligt lutande regressionslinje mellan variablerna. “Köper” du detta? Har linjens lutning någonting med sambandets styrka att göra? Hur bestäms lutningen egentligen? Motivera din ståndpunkt!
12. Vi har genomfört en regressionsanalys med OBVn antal goda gärningar under året gentemot BVn antal julklappar
13. Vi har genomfört en regressionsanalys med OBVn
. Enligt resultatet är regressionskoefficienten b = 0,1. Den standardiserade regressionskoefficienten (ß-vikten) är 0,3. Utnyttja denna information och ge mig dina mest exakta förklaringar till vad som händer med BVn när värdet på OBVn ändras! (svaret kan ändå vara kort)
antal lästa timmar gentemot BVn tentaresultat (poäng)
Svar:
. Enligt resultatet är regressionskoefficienten b = 1. Den standardiserade regressionskoefficienten (ß-vikten) är 0,5. Utnyttja denna information och ge mig dina mest exakta förklaringar till vad som händer med BVn när värdet på OBVn ändras! (svaret kan ändå vara kort)
A: (icke.standardiserad regressionskoefficient)Regressionskoefficient b= 1 Denna är skalberoende, anges i faktiska poäng till skillnad från den standardiserade som angesr sd. B: (Standardiserad regressionskoefficient )β-vikten=0.5 uttrycker X:s effekt på Y i standardavvikelser (SD). DVS: om x ökar 1 standardavvikelse så ökar Y med 0.5 standardavvikelser.
X Tentaresultat
Y 0 1 2 3 4 5 6 OBV: Antal lästa timmar
X Tentaresultat Y
0 1 2 3 4 5 6 7 8 9 10 11 12 OBV: Antal lästa timmar
OBV: Antal lästa timmar (x)
BV: Tentaresultat (y)

Vad som händer med BVn när OBVn ändras är alltså att när BVn ökar med 1 sd så ökar OBVn med 0.5 sd. Ju mer du läser desto högre poäng får du.
14. Nedan ser du spridningsdiagrammen A, B och C som illustrerar olika typer av samvariation mellan variablerna X och Y. Mätskalorna skiljer sig inte åt mellan diagrammen. Svara på följande frågor. a) I vilket diagram finner du den högsta korrelationen? __________ b) I vilket diagram finner du den lägsta korrelationen? __________ c) Vilket diagram motsvarar den högsta icke-standardiserade regressionkoefficienten (b)? __________ d) Vilket diagram motsvarar den högsta standardiserade regressionkoefficienten (Beta, ß)? __________
a) A b) B c) B d) A
Multipel regression 15. Följande frågor handlar om multipel regressionsanalys. De kan besvaras relativt kort.
a) Vilka tre generella syften kan vi ha för att använda multipel regression?
1. Kontroll: Test av orsakssamband X och Y för att utesluta irrelevanta variabler, confounds – C1, C2, C3 etc – kontroll för att sambandet mellan X och Y påverkas av att bägge korrelerar med confounds.
2. Förklaringsmodell: Undersöka hur stort relativt inflytande X1, X2 och X3 har på Y. 3. Prediktion: Att ta fram en vägd kombination av X1, X2, X3 etc som ger optimal prediktion av Y.
X
Y
X
Y
X
YA B
C

b) Vilka huvudtyper av multipel regression finns det?
Standard, sekventiell och statistisk.
Standard: Samtliga OBV läggs in samtidigt där varje OBV värderas för sitt förklaringsvärde utöver andra OBV, dvs enligt den unika varians den bidrar med.
Sekventiell: OBV läggs in en eller flera i taget enligt en någon förutbestämd rationell eller teoretisk ordning. Varje OBV värderas enligt det förklaringsvärde den bidrar med när den läggs in.
Statistisk (stepwise och setwise): Forward selection: OBV läggs till en tom modell i ordningsföljd enligt förklaringsvärde där högst läggs till först. Backward deletion: OBV tas bort ifrån en fylld modell i ordningsföljd enligt förklaringsvärde där lägst tas bort först. Stepwise: OBV läggs till och tas bort ur en tom modell eller ifrån en fylld modell enligt förutbestämda regler och nivåer av förklaringsvärde för när en OBV skall läggas till respektive tas bort.
c) Hur väljer du mellan olika huvudtyper beroende på vilket generellt syfte du har för din analys?
Standard är förstahandsval då det inte finns speciella skäl att välja någon annan typ. Sekventiell ger bättre överblick för hur respektive OBV bidrar till förklaringsvärde och för att testa explicita hypoteser. Statistisk är bra för explorativa studier och för att ta fram en modell som har så högt förklaringsvärde som möjligt med få OBV som möjligt.
d) Utöver bivariat korrelation behövs två andra typer av korrelation för att kunna genomföra en multipel regressionsanalys. Vilka är dessa två och vad är deras roll i samband med multipel regressionsanalys? (2 av 8)
Svar: Rött indikerar de påståenden som jag tror kan negativt påverka en multiple regressionsanalys.
• BV är på nominalskalenivå: BV måste vara på intervall eller kvotskalenivå (obs- inte prediktorvariablerna).
• Hälften av OBV är på nominalskalenivå: som jag skrev ovan så går det bra med nominalskalenivå på obv:n, men den måste göras om till en dummyvariabel, dvs med två värden 0 och 1. Fler än två lägen går inte.
• Sampelstorlek= 20: kan orsaka problem då rekommendationer på minst 10-15 personer per prediktor (OBV) eller att antalet personer bör överstiga antalet prediktorer med 40 eller 50 personer. 20 pax låter lite väl lite då tycker jag! Ju fler deltagare, desto bättre.
• Du finner icke-linjära samband mellan OBV och BV:
• Avsaknaden av outliers: det är väl bara bra?
• Höga korrelationer mellan OBV: visar resultatet på höga korreltaioner mellan obv:s betyder det att de olika variablerna förklarar ungefär samma sak (=onödigt)
• --- Beroendevariabeln är på nominalskalenivå. Problem: BV måste vara på intervall eller kvotskalenivå
Hälften av OBV på nominalnivå. Bra: så länge man kan göra om variabeln till en dummyvariabel med två lägen, 0 och 1.
Sampelstorlek = 20. Problem eventuellt: tumregeln är minst 10-15 personer per OBV eller att man har 40-50 fler personer än antalet OBV:er. Ju fler deltagare, desto bättre. Så 20 personer är på håret!
Du hittar icke-linjära samband mellan OBV och BV. Problem: dessa kommer inte att synas eftersom korrelation, som regression bygger på, använder sig av räta linjens ekvation.
Avsaknad av outliers. Bra: kan ge intryck av korrelation fast den inte finns.
Höga korrelationer mellan OBV. Problem: leder till instabilitet i analysen, korrelationer över 0.7-0.8 är alarmerande.
Överkurs: OBV 1 sägs vara stabil då dess unika varians är oförändrad trots flera andra OBV i analysen. Dessa tar inte över OBV 1 samvarians hos Y. OBV 1 förklarade varians är konstant – stabil. Det här visar på statistikens funktion som enbart ett verktyg. Man kan i princip lägga in vilken variabel som helst i regressionsanalysen som skulle kunna ta

över OBV 1 varians och göra denne ostabil. Därför måste de variabler man har med i analysen vara vettiga och logiska. Då kan man dra slutsatsen att OBV 1 är stabil – den förklarar verkligen en del av variansen hos beroende variabeln.
19. En multipel regressionsanalys med standardmetoden har genomförts i syfte att avgöra hur olika faktorer bidrar till oro i klassrum i grundskolan.
OBV 1: antalet elever i klassen OBV 2: lärarens tjänsteår BV: stökindex (en kontinuerlig skala från 0-10, högre värde >> mer stök) Resultatet av en multipel regressionsanalys med standardmetoden visade följande.
b Beta (ß) Antalet elever i klassrummet 0,2 0.2 Lärarens tjänsteår - 0,4 - 0.1
a) Vad är den sannolika förklaringen till att standardmetoden har valts till denna analys? Vad heter de två andra huvudtyperna av multipel regression (namnen räcker)?
Vi lägger in alla variablerna i analysen på en gång, vi bryr oss inte om att minimera antalet variabler eller har någon tanke på att ta ut den eller de variabler som förklarar mer än någon annan. Det vi är intresserade är hur mycket respektive oberoende variabler påverkar beroende variabeln stök, därför är förstahandsvalet av regressionsmetod det lämpligaste valet. Här bedöms varje variabel utifrån hur mycket förklaringsvärde den lägger till utöver alla andra OBV, dvs den får ”credit” bara för den unika biten varians den förklarar.
• sekventiell multipel regression som ger mer kontroll över analysen och används då man vill testa specifika teorier
• statistisk multipel regression som kan ge den bästa kombinationen av OBV:er som förklarar mest varians hos beroende variabeln. Används explorativt för att bygga hypoteser.
b) Har lärarens tjänsteår eller antalet elever i klassen mest betydelse för att förklara varians i stökighet i klassrummet? Ge en fullständigt övertygande motivering för din ståndpunkt.
Beta värdet anger den standardiserade regressionskoefficienten (X:s effekt på Y) i termer av standardavvikelser och gör det då möjligt att jämföra regressionskoefficienter med varandra. Som vi ser i tabellen så har variabeln ”antal elever i klassrummet” ett högre beta värde, vilket innebär i det här fallet att när antalet elever (x) ökar med en standardavvikelse så ökar ”stöket” i klassrummet (y) med 0.2 standardavvikelser. Alltså förklarar den här OBV:n mer av variansen i BV än OBV:n ”lärarens tjänsteår”. Regressionskoefficienten visar att för varje ytterligare elev så ökar stökindex med 0.2 enheter och för varje ytterligare år en lärare har arbetat som lärare så minskar ”stöket” med 0.4 enheter.
20. Att handla julklappar kan vara stressigt. Resultatet från en studie som använde sig av regressionsanalys visade följande. (4 poäng) Oberoende variabel: antal timmar på stan Beroende variabel: antal poäng på stresskalan vid hemfärden (skala 0 – 20, hög poäng betyder hög stress) a = 2 b = 4 a) Hur tolkar du detta resultat i klartext?
När man har varit 0 timmar på stan så har man 2 poäng på stresskalan. För varje timme på stan kommer stresspoängen att öka med 4. a = interceptet; där linjen korsar Y axeln d v s värdet på Y när X = 0. b = regressionskoefficienten; visar hur mycket Y ökar när X ökar en enhet
Denna studie följdes upp med en ny studie där man lade till ytterligare en oberoende variabel, nämligen antalet personer som man behöver köpa julklappar till. Resultatet av en multipel regressionsanalys med standardmetoden visade bl a följande.

b Beta (ß) Antal timmar på stan 2 0.3 Antal personer som behöver en julklapp 3 0.3
b) Hur tolkar du resultatet?
Trots att OBV 2:s b-värde är högre än OBV 1 behöver detta inte betyda att OBV 2 effekt på Y är större. Deras relativa effekt på Y kan man avläsa genom Beta-värdet som i det här fallet säger oss att båda OBV har lika stor effekt på Y. Beta vikten beskriver sambandets styrka i proportion till de andra OBV. Stressen påverkas lika mycket av hur länge man är på stan som hur många personer man ska köpa julklapp åt.
c) Hur tolkar du det förhållandet att regressionskoefficienten för “antal timmar på stan” är lägre i den andra studien jämfört med den första?
Hur länge man är på stan är inte hela anledningen till stressen, utan naturligtvis är också hur många vi ska handla för av betydelse. I första analysen såg vi bara sambandet mellan antal timmar och stress. När vi så lägger in en till variabel, antal personer att handla för, märker vi att den också förklarar stressen. Därmed tillräknar sig den en del av förklaringsvärdet från första variabeln. Tekniskt sett samvarierar prediktorerna med varandra och OBV 1 unika varians minskar.
Eller lite annorlunda uttryckt: När vi lägger till ytterligare en variabel, OBV 2, i analysen förlorar OBV 1 en del av sitt förklaringsvärde hos Y till OBV 2. En del av Y:s varians förklarar de tillsammans; de korrelerar med varandra. Innan vi hade OBV 2 i analysen förklarade OBV 1 den varians som OBV 2 skulle komma att beskriva.
• Hittade en till fråga:
Som bekant kan du predicera individens värde på kriterievariabeln (y) utifrån värdet på prediktorvariabeln (x) m h a en känd regressionsekvation. Vad finns det för komponenter i en regressionsekvation och vad står de för?
y = a + bx är regressionslinjens matematiska/geometriska beskrivning. ”y” är prediktorvariabeln och ”x” är kriterievariabeln. ”b” är korrelationslinjens lutning, alltså hur brant eller flackt är sambandet, alltså hur mycket/litet förändras y beroende på x. ”a” är interceptet, alltså när x = noll, det värde y då har.
• Och en till:
Förklara kort följande begrepp och deras relevans i samband med en regressionsanalys (alltså inte i största allmänhet).
Multi-collinearity
…är när två OBV korrelerar högt med varandra och faktiskt därmed gör prediktorn mindre stabil. En av variablerna har då förklarat det mesta av variansen och ”lämnar” inte mycket att förklara till den andra variabeln som den interkorrelerar med. Ett sätt att komma tillrätta med detta är att helt enkelt plocka bort den ena OBV´n!
Residual och residualvarians
Residual är våra prediktonsfel, jag predicerar att när x =”si” blir y = ”så” men y blir i verkligheten något annat. Skillnaden mellan det verkliga värdet och det predicerade värdet kallas residual. Residualvariansen är den varians av mellan predicerade y och de faktiska y utifrån regressionslinjen.
Heterogen varians
…är när variansen skiljer sig mer än fyra gånger för två sampel, alltså det ena samplets varians är mer än fyra gånger större än det andra samplets varians, när samplen är lika stora. Om vi har olika stora sampel är variansen heterogen om den största variansen är mer än dubbelt så stor som den minsta variansen.
• Och fler:
4. Vad är ditt allmänna förstahandsval när det gäller vilken typ av multipel regressionsanalys som ska användas? (2p)

- Standard multipel regression. Om man inte har någon bra anledning att välja någon annan metod, väljer man denna, dsv den är förstahandsval. Den är som mest användbar när man vill förklara så mycket av variansen i OBV som möjligt, utan att ödsla tid på mätningar som bara ger lite extra information.
I vilken ordning läggs de oberoende variablerna in i analysen då? (2p)
- alla oberoende variabler läggs in samtidigt.
4. Vad har storleken på korrelationen mellan de olika oberoende variablerna för betydelse i samband med multipel regressionsanalys? (2p)
- om några av OBV korrelerar för mycket, .80 eller mer, kan det göra de predicerade variablerna mer instabila.
- för hög korrelation leder till instabilitet i betavärden vid jämförelse över flera sampel.
– Ett annat problem är att analysen kan ge intryck av att en given variabel inte är en bra prediktor av BV, helt enkelt för att det mesta av variansen den kan förklara redan har blivit ”accounted”” för av andra variabler i modellen.
3) Multipel regression
2 oberoende variabler X och V har ingått i en multipel regressionsanalys i syfte att förklara varians i beroendevariabeln Y. Enligt analysresultatet är felvariansen 50%. Den bivariata korrelationen mellan X och Y är: rxy = 0,60 och mellan X och V: rxy = 0,00 (Jag tror att man skrivit fel och i själva verket menar rxv = 0,00). Hur mycket varians i Y förklaras av V? (2 p, ord maj 02, ord maj 03)
De förklarar 50 % tillsammans – felvariansen är 50 % alltså måste resterande varians vara förklarad varians.
Hur mycket varians i Y förklaras av enbart V?
Om felvariansen är 0.50 (varians hos Y som beror på okända faktorer) d v s 50 % så är den förklarade variansen resten d v s 50 %. De båda OBV:erna X och V förklarar ingen gemensam varians i Y, vilket man ser på deras korrelation med varandra rxv = 0, vilket betyder att deras cirklar i Venn-diagrammet inte överlappar varandra utan överlappar på Y på olika ställen. Vi vet att X:s samvariation med Y är 0.70. För att få ut den förklarade variansen kvadrerar vi detta tal och får ut 0.49 vilket är 49 %. Alltså, X förklarar 49 % av Y:s varians. Då den totala förklarade variansen hos Y är 50 % måste resterande varians tillhöra X d v s 50-49 = 1. Alltså, V förklarar 1 % av Y:s varians.
Vi vet att 50% av den totala variansen i Y är felvarians. 50% av variansen i Y beror alltså på inverkan från okända faktorer. Då vet vi också att resten av variansen i Y (också det 50%) är förklarad varians, dvs. varians som kan förklaras av de aktuella variablerna X och V.
V
Y
X rxy
rvy
Det lila området är den del av Y som förklaras av V, enligt beräkningarna 14%.
Det bruna området är den de l av Y som förklaras av X, enligt beräkningarna 36%.
Det rosa området utgör felvariansen, dvs. den del av Y som inte förklaras av V eller X, enligt uppgift 50 %.

Den bivariata korrelationen mellan X och Y är rxy = 0,60. För att kunna ta reda på hur mycket av den totala variansen som motsvaras av X omvandlar vi korrelationskoefficienten r till determinationskoefficienten r2. (Den förklarade
variansen uttrycks alltid som r2 och det är r2 som kan omvandlas till procent). Beräkningen 0,60 × 0,60 = 0,36 ger att r 0,60 motsvaras av r2 0,36. Utifrån detta kan vi säga att 36% av variansen i Y kan förklaras av X.
Av den förklarade variansen r2 0,50 utgörs r2 0,36 av X. Eftersom det bara finns två variabler utgörs resten av den förklarade variansen av V. 0,50 – 0,36 = 0,14. Av detta kan vi således dra slutsatsen att 14 % av variansen i Y förklaras av V.
Har jag tänkt rätt här? Håller någon inte med så kontakta gärna mig!! Fråga: Om jag vill analysera hur mycket varians…..:
Hur mkt varians i ”ålder vid diagnosticerad alkoholism förklaras av 1. Det vi här plockar in först och som därmed får en reserverad plats är variansen förklarad av ”ärftlig
belastning avseende alkoholism”. 2. Därefter plockar vi in ”ålder för första fylla” som får förklara den varians som blir kvar.
Eftersom vi är intresserade av den förklarade variansen på en OBV utöver den förklarade variansen på en annan OBV så väljer vi sekventiell (hierarkisk) multipel regression: BV: Ålder vid alkoholismdiagnos OBV 1: ärftlig belastning’ OBV 2: Ålder vid första fylla
Som vi ser här så stjäl OBV 1 mer förklarad varians av BV och OBV 2 får nöja sig med den snutt som blir över!!
Varians / ANOVA 1. Vilka nollhypoteser testas i a) en envägs-ANOVA och b) en tvåvägs-ANOVA? (1p)
ho= OBV har ingen effekt på BV, dvs medelvärdena för BV under samtliga betingelser är lika ho=OBV1 har ingen effekt på BV, OBV2 har ingen effekt på BV, det finns ingen interaktionseffekt mellan OBV1 och OBV2.
2. I en oberoende envägs-ANOVA kan den totala variansen delas upp i mellangruppsvarians (systematisk varians) och inomgruppsvarians (felvarians). Vad menas med mellangruppsvarians och vad menas med inomgruppsvarians och hur används dessa för att beräkna F-kvoten?
Totalvarians: Summan av de kvadrerade skillnaderna mellan varje observation och det totala medelvärdet. (SStotal). Totalvarians = Mellangruppsvarians + Inomgruppsvarians
Mellangruppsvarians: Summan av de kvadrerade skillnaderna mellan varje grupps medelvärde och det totala medelvärdet gånger antalet försökspersoner. (OBV:s effekt: SSbetween). Mellangruppsvariansen består av två komponenter: Systematisk varians: Beror på skillnader i grupperna orsakad av ev. experimentell manipulation. Felvarians: Beror på olika slumpkällor.
BV
OBV2
OBV 1

Inomgruppsvarians: Summan av de kvadrerade skillnaderna mellan varje observation och respektive gruppmedelvärde. (felvarians: SSwithin) Inomgruppsvariansen är att betrakta som felvarians.
I en ANOVA beräknar vi kvoten av mellangruppsvarians och felvarians. F = Mellangruppsvarians / Inomgruppsvarians = (Systematisk varians + Felvarians) / Felvarians. Om en experimentell manipulation inte har någon effekt finns ingen systematisk varians och vi har att: F = (0 + Felvarians) / Felvarians = 1.
3. I en oberoende envägs-ANOVA kan den totala variansen delas upp i två delar, inomgruppsvarians (felvarians) och mellangruppsvarians (systematisk varians). Vad menas med inomgruppsvarians och vad menas med mellangruppsvarians? (2 tentor av 8)
Inomgruppsvarians = (varje observation – gruppens medelvärde) kvadrera och summera dessa. Mellangruppsvarians = (gruppens medelvärde – totalt medelvärde) kvadrera och summera.
4. Redogör för de fyra antaganden angående data som måste vara uppfyllda för att du skall kunna genomföra en oberoende envägs-ANOVA. (2 tentor av 8)
• Data på intervall och kvotskalenivå (ordinal med minst 7 skalsteg)
• Normalfördelade data.
• Homogen varians. Variansen i en grupp får inte vara mer än 4 gånger större än variansen i en annan grupp.
• Datapunkterna ska vara oberoende. Poäng i en betingelse påverkas inte av poäng i en annan betingelse (gäller bara oberoende ANOVA).
data skall vara relativt normalfördelat (någorlunda symmetrisk och kontinuerlig) oberoende data, dvs varje fp skall bara utsättas för en betingelse BV på minst 7 steg ordinal, helst kvot/intervall Relativt lika varaians i de olika betingelserna (högst faktor fyra)
5. Förklara begreppen (a) huvudeffekt (main effect) och (b) interaktionseffekt.
Huvudeffekt= en obvs påverkan på bv (jmfr simple effect) interaktionseffekt= en obs påverkan på hur en annan obv påverkar bv (jmfr moderation)
6. När är det viktigt att studera enkla effekter (simple effects)? då man ser en interaktionseffekt. Detta för att ta reda på hur de olika obvs påverkan på bv ser ut oberoende av den andre obvs påverkan på denna obv (haha). Exempelvis när huvudeffekten är mycket låg och OBV tar ut varandra, att studera simple effekts kan avslöja mycket hög påverkan av respektive OBV.
7. Du genomför en tvåvägs-ANOVA på data från studie X och en tvåvägs-ANOVA på data från studie Z. I studie X hittar du en signifikant huvudeffekt, en icke signifikant huvudeffekt och en icke signifikant interaktionseffekt. I studie Z hittar du ingen signifikant huvudeffekt men en signifikant interaktionseffekt. I en av dessa studier är det viktigt att studera enkla effekter (simple effects). Vilken? Varför?
studie z då du där inte hittat några huvudeffekter men däremot en interaktionseffekt. Du vill därför simple effekt där du konstanthåller en obv för att få den rena effekten (huvudeffekt) av en obv-bv relation. Det kan ju vara så att det finns huvudeffekter men att de tar ut varann pga interaktionseffekter.
8. Exemplifiera en mixed ANOVA med en av dig påhittad studie där du beskriver de ingående variablerna och anger (i) vilken eller vilka variabler som är oberoende variabler och (ii) vilken variabel som är den beroende variabeln. Ange även (iii) på vilken skalnivå din beroendevariabel ligger.
I mixed ANOVA (Split plot) har vi minst en beroende OBV och minst en oberoende OBV. Vi undersöker hur två skilda träningsmetoder (OBV) påverkar en violinists skicklighet (BV) över tid (OBV). Vi låter Grupp 1 använda Suzuki-metoden och Grupp 2 använda traditionell metod. Metoden är då oberoende OBV, olika metoder mellan grupperna. Vi testar personerna en gång i veckan i 10 veckors tid. Tidpunkt är då beroende OBV, lika mellan grupperna.

Man undersöker två matematikträningsmetoder och hur de påverkar över tid. Man låter en grupp träna med metod 1 och en annan med metod 2 (OBV 1, oberoende: typ av träningsmetod). Man testar sedan personerna en gång i veckan under en 10 veckors period (OBV 2, beroende: tid). Beroende variabeln är antal rätt på ett matematiktest som man då låter de göra en gång i veckan under 10 veckor. Data är här på kvotnivå. Data behöver vara på intervall eller kvotnivå (ordinalnivå minst 7 skalsteg) för att ANOVA ska kunna användas som analys.
Män och kvinnor skall prova att hålla andan olika länge och sedan mäts hur länge de kan hålla uppmärksamheten på en prick. OBV1= kön (denna är oberoende, man är bara antingen man/kvinna) obv2= hållaandantid, 30 sek, 2 min, 1.5 min. (denna är beroende, man är med i alla tre betingelser). BV=tid man kan hålla uppmärksamheten på en prick. Denna är på kvotnivå.
A) Vilken betydelse har ordet mixed i en two-way mixed ANOVA?
Att minst en OBV är beroende och minst en OBV är oberoende.
I mixed ANOVA (Split plot) har vi minst en beroende OBV och minst en oberoende OBV. Det betyder att ANOVA designen innehåller (minst) en jämförelse mellan grupper samt (minst en) mellan individer i samma grupp. Det innebär att övergripande varians kan splittras mellan grupper och inom samma grupp. (Mellan grupp varians är skillnaden mellan grupperna (systematisk varians) och inom grupp varians är skillnaden mellan individer inom varje grupp (fel varians).)
Mixed innebär en blandning av inomgrupps och mellangrupps design d v s man har minst en beroende OBV (inomgruppsdesign) och minst en oberoende OBV (mellangruppsdesign). Ett exempel är en undersökning där man testar två oberoende grupper på en variabel (t ex OBV 1 = behandlingsgrupp vs kontrollgrupp) och mäter varje grupp flera gånger, upprepade mätningar (OBV 2 = tid).
B) När och varför använder man sig av ett kontrast test?
Vid två betingelser och en OBV kan man direkt se grafiskt var skillnaden ligger. När man vill se var skillnaden finns vid tre eller fler betingelser i en OBV så syns inte det. Man använder sig då av kontrasttest efter att man gjort en ANOVA för att identifiera mellan vilka grupper de eventuella signifikanta skillnaderna finns. ANOVA ger indikation om det finns signifikanta skillnader men inte var. Används för att studera mellan vilka medelvärden signifikant skillnad föreligger. Parvisa kontraster är oftast baserade på t-statistikan. Bonferronis t: signifikansnivå för en parvis kontrast = ursprunglig signifikansnivå (tex. .05) delat på totala antalet parvisa kontraster. A priori test: används när man på förhand bestämt vilka medelvärden man skall jämföra. Post hoc test: används när man inte på förhand bestämt vilka grupper/betingelser man skall jämföra. Post hoc test är aldrig ensvansade test eftersom de görs efter det att man studerat hur data ser ut. Det finns en lång rad post hoc test som varierar från liberala till konservativa. Vilket som bör användas varierar från situation till situation.
C) Vad är den huvudsakliga skillnaden mellan a priori test och post hoc test?
A priori - då man innan man gör testet tro sig veta vilken riktning skillnaden är i, ex att en viss behandling är bättre än en annan. Post hoc = då man inte vet innan (vilket oftast används).
Man gör kontrasttest efter ANOVA-analysen för att identifiera vart de signifikanta skillnaderna finns. Det finns två typer av kontrasttest: om man redan på förhand, innan ANOVA analysen, bestämt vilka medelvärden man ska jämföra så gör man ett a priori test. Om man inte planerat vilka grupper man vill jämföra så gör man ett post hoc test vilket är mer konservativt än a priori test d v s det är svårare att uppnå signifikans men minskar risken för typ 1 fel (falsk icke-signifikans, false negative).
9. När och varför använder man sig av a priori test och post hoc test, samt vilken är den huvudsakliga skillnaden mellan a priori och post hoc
Används för att studera mellan vilka medelvärden signifikant skillnad föreligger. Parvisa kontraster är oftast baserade på t-statistikan. Bonferronis t: signifikansnivå för en parvis kontrast = ursprunglig signifikansnivå (tex. .05) delat på totala antalet parvisa kontraster. A priori test: används när man på förhand bestämt vilka medelvärden man skall
test? När kan man använda sig av en ”ensvansad” signifikansprövning?

jämföra. Post hoc test: används när man inte på förhand bestämt vilka grupper/betingelser man skall jämföra. Post hoc test är aldrig ensvansade test eftersom de görs efter det att man studerat hur data ser ut. Det finns en lång rad post hoc test som varierar från liberala till konservativa. Vilket som bör användas varierar från situation till situation.
då man vill göra kontrasttest för att se var skillnaden mellan grupperna är. Då man har fler än två betingelser av en obv. A priori = då man innan vet vilken riktning skillnaden går i. post hoc= då man inte vet innan. Ensvansad= då man har en riktning och vill testa om skillnaden i den riktningen är signifikant ex att en viss behandling gav bättre resultat (typ a priori) --- Ensvansad signifikansprövning använder man sig av när man har en riktad hypotes d v s man säger i vilken riktning skillnaden kommer att gå, t ex grupp A kommer få högre poäng än grupp B.
Ev. överkurs: Alternativet är att ha en tvåsvansad signifikansprövning, vilket innebär att man säger att
10.
det blir en skillnad men inte till vilken grupps fördel. En tvåsvansad signifikansprövning är mer konservativ än sitt alternativ d v s det är svårare att få ett signifikant resultat när man har en oriktad hypotes jämfört med om man har en riktad hypotes.
När och varför använder man sig av a priori test och post hoc test? Vad är den huvudsakliga skillnaden mellan a priori test och post hoc test
När? post hoc test används när man inte på för hand bestämt vilka grupper, betingelser man skall jämföra.
? (2 tentor av 8)
A priori test används när man på förhand bestämt vilka medelvärde skall jämföras. Varför? Används för att studera mellan vilka medelvärden signifikant skillnad föreligger. post hoc test: miniskar risken för typ 1 fel.
11. Du vill undersöka effekten av tre olika träningsmetoder (A, B, C) för terränglöpare. Du delar slumpmässigt in 60 löpare i tre grupper om vardera 20 löpare. Under 6 månader får Grupp A träna enligt metod A, Grupp B enligt metod B och Grupp C enligt metod C. Innan träningsperiodens början (Tid 1) och efter träningsperiodens slut (Tid 2) mäter du hur snabbt löparna springer 10km terränglöpning. För att analysera resultatet genomför du en ANOVA med träningsmetod och tidpunkt som oberoende variabler (OBV) och löptidResultaten presenteras i tabellen nedan.
som beroende variabel (BV).
a. Vilken typ av ANOVA är genomförd (envägs/tvåvägs, oberoende/beroende/mixed etc.)? (1p) b. Hur tolkar du resultatet? (1p) c. Vilka ytterligare analyser av resultatet skulle du vilja göra? (1p)
EffectSS Degr. of
FreedomMS F p
InterceptGruppErrorTIDTID*GruppError
327033,0 1 327033,0 1752,874 0,00000033,2 2 16,6 0,089 0,915107
10634,5 57 186,6245,1 1 245,1 34,426 0,000000
3,7 2 1,9 0,260 0,771856405,8 57 7,1
Vilken typ av ANOVA är genomförd (envägs/tvåvägs, oberoende/beroende/mixed etc.)? (1p) tvåvägsanova split-plot
Hur tolkar du resultatet? (1p) det finns ingen huvudeffekt av OBV1 (grupp) men en huvudeffekt gällande tid (dvs grupperna sprang olika fort inna noch efter. det finns ingen sign interaktionseffekt
Vilka ytterligare analyser av resultatet skulle du vilja göra? (1p) Sätta in resultatet i ett diagram för att grafiskt avgöra huvudeffekten av OBV2. Om diagrammet tydligt visar att det gick fortare efter träningen så kan vi anta att resultatet är signifikant vilket bekröftas av resultatet, skillnaden är signifikant (p = 0,00). Eftersom det bara är två betingelser (före och efter) behöver vi inte göra kontrasttest (vilket man gör om det finns fler betingelser än två).

i. Eftersom det inte är ngt interaktionseffekt behöver jag inte göra simple effekt. ii. Jag antar att jag skulle vilja göra ngt form av effektstorlektest, eller? Hur stor skillnad var
det mellan före och efter. Jag tänker mig att Fvärdet är beroende av antalet fp??
12. Du undersöker effekterna av tre olika träningsmetoder (A, B och C). Du tar 30 hundrameterslöpare (15 män och 15 kvinnor) och delar slumpmässigt in dem i tre grupper (5 män och 5 kvinnor i varje grupp). Under en månad får Grupp A träna med metod A, Grupp B får träna med metod B och Grupp C får träna med metod C. Vid två tillfällen, dels dagen före träningsmånadens början (Tid 1) och dagen efter träningsmånadens slut (Tid 2), mäter du hur snabbt löparna springer 100 meter. Du genomför en ANOVA med träningsmetod och kön som oberoende variabler och förändringen mellan mätning 1 och mätning 2 (dvs. Tid 1 – Tid 2) som beroende variabel. Resultatet presenteras i tabellen nedan. Är ANOVA´n oberoende (between groups) eller beroende (within groups)? Är det en envägs ANOVA (one-way), tvåvägs ANOVA (two-way) eller trevägs ANOVA (three-way)? Hur tolkar du resultatet? (3p)
2 st OBV ger tvåvägs ANOVA. OBV 1 är träningsmetod med 3 betingelser, OBV 2 är kön. Oberoende ANOVA eftersom man jämför 3 grupper som var och en har fått olika slags träning. Signifikant huvudeffekt av kön men inte av träning. Ingen interaktionseffekt. (Eftersom det är två mätningar per betingelse så är detta, enligt vissa källor, en inomgruppsdesign i grund och botten, de menar att vid en mellangruppsdesign så sker det högst en mätning per betingelse. Då man jämför 3 grupper med olika deltagare i varje så finns det även en mellangruppsvariabel med i designen, vilket egentligen gör designen till mixed. Men mixed finns inte med som alternativ. Rätt svar på tentan är som sagt oberoende ANOVA, när jag frågade läraren varför så var fallet så sa han: ”eftersom BV är skillnaden mellan mätningarna kan inte mättillfälle vara OBV”. )
13. Du undersöker effekterna av tre olika träningsmetoder (A, B och C). Du tar 30 hundrameterslöpare (15 män och 15 kvinnor) och delar slumpmässigt in dem i tre grupper (15 män och 15 kvinnor i varje grupp). Under en månad får Grupp A träna med metod A, Grupp B får träna med metod B och Grupp C får träna med metod C. Vid två tillfällen, dels dagen före träningsmånadens början (Tid 1) och dagen efter träningsmånadens slut (Tid 2), mäter du hur snabbt löparna springer 100 meter. Du genomför en oberoende två-vägs ANOVA med träningsmetod och kön som oberoende variabler och förändringen mellan mätning 1 och mätning 2 (dvs. Tid 1 – Tid 2) som beroende variabel. Resultatet presenteras i tabellen nedan. Hur tolkar du resultatet?
Det finns en sign huvudeffekt av kön, det verkar alltså som att män/kvinnor fick olika bra resultatförändring. Då det bara är två betingelser räcker det med om vi visar det grafiskt och där ser vilken grupp som fick störst skillnad. Ingen sign huvudeffekt av träning. Dock, det finns nästan en sign interaktionseffekt så jag skulle ändå välja att testa simple effekts för att se den rena påvekan av en obv-bv. Kanske ser man då att det finns en huvudeffekt av träningstyp

också (det kanske är så att de olika träningsformerna fungerar olika bra om du är man resp kvinna och att skillanderna tar ut varann---ingen huvudeffekt av träning fast pga interaktionseffekten).
Det finns en huvudeffekt för kön, män och kvinnor skiljer sig signifikant på hur snabbt de springer. Ett kontrast test behövs göras för att se till vilken grupps fördel skillnaden är.
Effekten för träningsmetod är inte signifikant men ligger inte långt ifrån gränsvärdet. Jag skulle här beräkna effektstorleken för att se hur stor effekt respektive träningsmetod hade. Skulle det visa sig att det var en stor effekt skulle man kunna göra om studien med fler deltagare för att öka chansen att få signifikanta skillnader. En poweranalys kan göras för att uppskatta hur många deltagare som behövs för att få ett signifikant resultat vid en replikation (med 80 % sannolikhet).
Interaktionseffekten är på gränsen till signifikant. Enligt vissa bör man då undersöka den eftersom en eller flera av interaktionerna kan vara signifikanta trots att den totala interaktionseffekten inte är signifikant. Jag går alltså vidare och undersöker simple effects.
14. En forskare hade hypotesen att onlinerollspel av typen World of Warcraft i större utsträckning än andra aktiviteter på Internet var associerade med överdrivet spelande och beroendeliknande symptom (”Internetberoende”). Hon administrerade därför Youngs (1998) test för att mäta internetberoende till (1) en grupp ”World of warcraft”-spelare, (2) en annan grupp som primärt använde sig av email och chat när de var online och (3) en tredje grupp som primärt använde Internet till att surfa och läsa nyheter. Testpoängen ligger på en kvotskala och går från 0 till 20. Hon var dessutom intresserad av att studera om det fanns några relevanta könsskillnader, då tidigare forskning visat att män i större utsträckning än kvinnor får höga poäng på test som mäter internetberoende.
a.) Du överväger att använda t-test, envägs ANOVA eller faktoriell ANOVA. Resonera kring för- och nackdelar med dessa metoder i just detta sammanhang. Vilken metod väljer du? Två OBV (kön och internetberoende) BV på kvotnivå. Faktoriell ANOVA i o m att jag jämför fler än två grupper samt är intresserad av interaktionseffekter. T-test ökar typ 1 fel-risk (massignifikansproblem). ANOVA kontrollerar för massignifikansproblem. Envägs ANOVA för OBV 1 (3 grupper) och ett t-test för OBV 2 (kön) tillåter inte kontroll för interaktionseffekter.
b.) Om F-värdet är högt (signifikant) i den ANOVA du räknar ut, hur förhåller sig då mellangruppsvarians, inomgruppsvarians, felvarians och systematisk varians till varandra i just detta exempel? F = mellangruppsvarians / inomgsvarians = (systematisk varians + felvarians) / felvarians. Högt F-värde indikerar hög systematisk variation i relation till felvarians (dvs inomgruppsvarians).
Avvikelserna från medelvärdet inom varje grupp (inomgruppsvarians/felvarians) är mindre än skillnaden mellan gruppernas medelvärden (mellangruppsvarians/systematisk varians).
Ev. överkurs: Den totala variansen som ANOVA utgår ifrån består av varians inom grupperna (felvarians) och varians mellan grupperna (systematisk varians). ANOVA:n jämför skillnaden mellan dessa. Inomgruppsvariansen även kallad felvarians är ett mått på hur deltagarna inom en betingelse skiljer sig ifrån medelvärdet och beror på individuella skillnader i förmåga hos deltagarna och på bristande reliabilitet hos mätinstrumentet. Mellangruppsvariansen, s k systematisk varians, utgörs av skillnaden mellan betingelsernas medelvärden. Sista steget i ANOVA:n är att räkna ut hur stor del av variansen som är systematisk och benämns F värde.
F = systematisk varians / felvarians
Om skillnaden mellan grupperna är signifikant får man en hög F kvot, vilket alltså innebär att större delen av variansen beror på manipulationen av OBV.
15. Du är intresserad av att studera olika typer av musiks påverkan på intelligensen. Du rekryterar 30 studenter från Uppsala universitet och fördelar dem slumpmässigt i tre grupper. Alla skall under tre timmar varje dag i en månad lyssna på musik. De i Grupp A får lyssna på de gamla synthikonerna Depeche Mode, de i Grupp B får lyssna
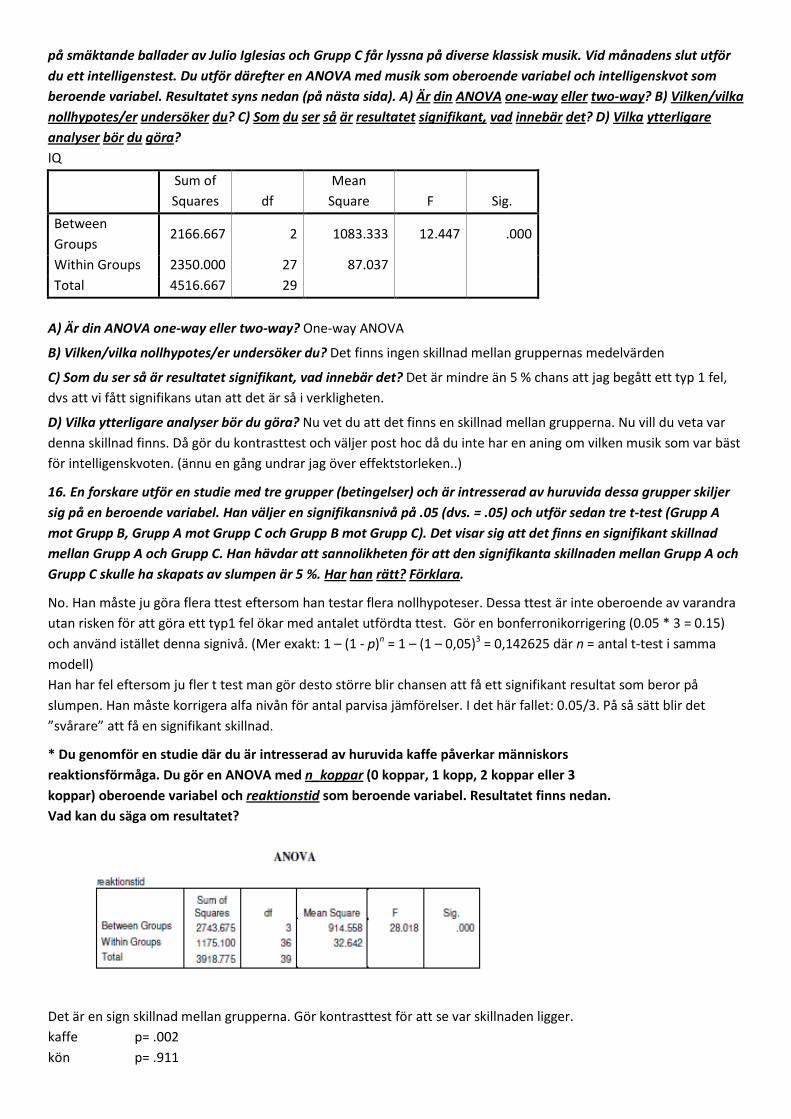
på smäktande ballader av Julio Iglesias och Grupp C får lyssna på diverse klassisk musik. Vid månadens slut utför du ett intelligenstest. Du utför därefter en ANOVA med musik som oberoende variabel och intelligenskvot som beroende variabel. Resultatet syns nedan (på nästa sida). A) Är din ANOVA one-way eller two-way? B) Vilken/vilka nollhypotes/er undersöker du? C) Som du ser så är resultatet signifikant, vad innebär det? D) Vilka ytterligare analyser bör du göra? IQ
Sum of Squares df
Mean Square F Sig.
Between Groups
2166.667 2 1083.333 12.447 .000
Within Groups 2350.000 27 87.037 Total 4516.667 29
A) Är din ANOVA one-way eller two-way? One-way ANOVA
B) Vilken/vilka nollhypotes/er undersöker du? Det finns ingen skillnad mellan gruppernas medelvärden
C) Som du ser så är resultatet signifikant, vad innebär det? Det är mindre än 5 % chans att jag begått ett typ 1 fel, dvs att vi fått signifikans utan att det är så i verkligheten.
D) Vilka ytterligare analyser bör du göra? Nu vet du att det finns en skillnad mellan grupperna. Nu vill du veta var denna skillnad finns. Då gör du kontrasttest och väljer post hoc då du inte har en aning om vilken musik som var bäst för intelligenskvoten. (ännu en gång undrar jag över effektstorleken..)
16. En forskare utför en studie med tre grupper (betingelser) och är intresserad av huruvida dessa grupper skiljer sig på en beroende variabel. Han väljer en signifikansnivå på .05 (dvs. = .05) och utför sedan tre t-test (Grupp A mot Grupp B, Grupp A mot Grupp C och Grupp B mot Grupp C). Det visar sig att det finns en signifikant skillnad mellan Grupp A och Grupp C. Han hävdar att sannolikheten för att den signifikanta skillnaden mellan Grupp A och Grupp C skulle ha skapats av slumpen är 5 %. Har han rätt? Förklara.
No. Han måste ju göra flera ttest eftersom han testar flera nollhypoteser. Dessa ttest är inte oberoende av varandra utan risken för att göra ett typ1 fel ökar med antalet utfördta ttest. Gör en bonferronikorrigering (0.05 * 3 = 0.15) och använd istället denna signivå. (Mer exakt: 1 – (1 - p)n = 1 – (1 – 0,05)3 = 0,142625 där n = antal t-test i samma modell) Han har fel eftersom ju fler t test man gör desto större blir chansen att få ett signifikant resultat som beror på slumpen. Han måste korrigera alfa nivån för antal parvisa jämförelser. I det här fallet: 0.05/3. På så sätt blir det ”svårare” att få en signifikant skillnad.
* Du genomför en studie där du är intresserad av huruvida kaffe påverkar människors reaktionsförmåga. Du gör en ANOVA med n_koppar (0 koppar, 1 kopp, 2 koppar eller 3 koppar) oberoende variabel och reaktionstid som beroende variabel. Resultatet finns nedan. Vad kan du säga om resultatet?
Det är en sign skillnad mellan grupperna. Gör kontrasttest för att se var skillnaden ligger. kaffe p= .002 kön p= .911

kaffe*kön p= .735
Det är en tvåvägs ANOVA i o m två OBV: kaffe och kön. En signifikant huvudeffekt för kaffe finns. Interaktionseffekten är inte signifikant, därför behöver jag inte undersöka simple effects. Jag går vidare med en kontrastanalys på den signifikanta OBV:n kaffe då jag inte vet mellan vilka betingelser de signifikanta skillnaderna finns. Jag skulle alltså få reda på vilken mängd kaffe som har en signifikant effekt på reaktionsförmågan.
17. Du genomför en studie där du är intresserad av huruvida kaffe påverkar människors reaktionsförmåga. Eftersom du är intresserad av eventuella könsskillnader rekryterar du försökspersoner så att 50 % är kvinnor och 50 % är män. Du gör en ANOVA med kaffeintag (0 koppar, 1 kopp, 2 koppar eller 3 koppar) och kön som oberoende variabler och reaktionstid som beroende variabel. Resultatet finns nedan. Är din ANOVA one-way eller two-way? Vilka signifikanta huvudeffekter och/eller interaktionseffekter finns? Förklara varför du måsta/inte måste undersöka simple effects? Du bestämmer dig för att göra en kontrast analys, på vilken/a variabel/variabler skall du utföra den på och vilka ytterligare svar skulle denna analys ge?
SVAR: ANOVA är two ways eftersom det finns två OBV, kaffeintag med tre betingelser och kön. Huvud effekter: Kaffeintag har en effekt signifikant, könInteraktion effekt: har inte något signifikant.
har ej signifikan.
Vi måste inte undersöka sampel effekt eftersom det inte finns interaktion mellan huvudeffekter(OBV: 1 och 2). Kontrast analys ska vara på kön variabel
Ytterligare svar som analys kan ange är mellan vilka medelvärde signifikant föreligger. I det fallet mellan vilka grupper medelvärde signifikant finns.
eftersom den enda variabel som har signifikant och påverkar BV,…..vad tycker ni?
--- Maja: det finns inte ngn sign interaktionseffekt, fattar inte varför man vill göra en simple effekt??? Det finns huvudeffekt av kaffeintag men inte av kön. Gör kontrasttest för att se vart skillnaderna mellan grupperna ligger. 18. En forskare har undersökt effekten av fyra olika metoder (A, B, C, D) på människors humör. Humörmåttet tillåter parametrisk analys. För att analysera resultatet har forskaren genomfört sex (6) oberoende t-test för att jämföra grupperna inbördes enligt: A-B, A-C, A-D, B-C, B-D, C-D.
a. Vad gör forskaren för fel och varför är det fel? b. Hur bör forskaren gått tillväga för att analysera resultatet? c. Vad gör forskaren för fel och varför är det fel? Att göra så många ttest innebär att risken för typ 1
fel är väldigt stor (1-alfa)^6. Man bör istället föra en oberoende envägsanova d. Hur bör forskaren gått tillväga för att analysera resultatet? Om man envisats med att göra ttest kan
man göra en kontrasttest som heter bonferronikorrigering o.o5/6 och använda denna siffra som signifikansnivå. Vet inte om man måste skriva mer här. Men det kan inte jag.
Faktoranalys 1. Vilka vetenskapliga frågeställningar kan vi besvara med faktoranalys?

Faktoranalys kan användas när man vill studera relationer mellan flera variabler samtidigt. Man kan se mönster i data och uttala sig om faktorer som man inte har frågat om (t.ex. g-faktorn) Det är ett sätt att pröva vetenskapliga teorier. Exempel på en frågeställning: Hänger vissa frågor i ett frågeformulär ihop så att de tillsammans tycks mäta en viss egenskap? Finns det några underliggande dimensioner som kan förklara en mängd data ex gällande personlighet. Underliggande dimensioner/komponenter/faktorer som kan förklara datan på ett (tillräckligt) bra sätt som gör datan enklare att förstås
Latenta dimensioner i data. När man vill undersöka underliggande mönster och förhållanden (inte direkt observerbara) för ett stort antal variabler. Detta kan användas på testresultat eller när man konstruerar frågeformulär. Vi har en teoretisk idé, testar den på en population och ser om våra subskalor (utifrån vår teoretiska idé) stämmer. Grupperas data utefter de dimensioner som vi tänkt att frågorna mäter?
Datareduktion för ytterligare analys. Om vi har mångdimensionella data eller stor multikolinearitet (hög korrelation mellan OBV:er) då kan vi reducera ner data till några latenta variabler och göra analyser som t ex regression eller ANOVA.
Särdragsextraktion. Om man använt många mätinstrument i sin studie och vill se vilka som är representativa för det vi vill mäta, så man slipper utvärdera varje. Vi väljer ut några med hjälp av faktoranalys och använder de som beroende mått.
2. Faktoranalys kan användas oberoende av om våra variabler är mätta på samma skala (har samma enhet) eller har samma medelvärde. Förklara kortfattat hur detta är möjligt!
Faktoranalys analyserar mönster i korrelationer mellan variabler och dessa är standardiserade oberoende av skala, skalenheter eller medelvärden. Standardisering innebär att två variabler får samma korrelation oavsett vilken skala, skalenhet eller medelvärde respektive variabel råkar ha vid mättilfället.
Man använder sig av p-värden och detta är ett standarliserat mått. Man har alltså tagit hänsyn till variablernas sd när man räknar ut korrelationer mellan de olika variablerna. Sedan använder man sig av dessa vid faktoranalysen. Man tittar alltså inte direkt på rådatan utan på hur olika variabler korrelerar.
3. Spelar det någon roll för resultatet av en faktoranalys om de ingående variablerna skiljer sig med avseende på medelvärde och varians? Varför/varför inte?
Faktoranalys analyserar mönster i korrelationer mellan variabler och dessa är standardiserade oberoende av skala, skalenheter eller medelvärden. Standardisering innebär att två variabler får samma korrelation oavsett vilken skala, skalenhet eller medelvärde respektive variabel råkar ha vid mättilfället.
Nej det spelar ingen roll. När man gör faktoranalys jobbar man med korrelationer och inte med rådata direkt vilket innebär att man använder ett standardiserat mått som redan tagit hänsyn till medelvärde och varians.
4. Hair diskuterar Q-faktoranalys och R-faktoranalys. Beskriv de två typerna av faktoranalys och vad som skiljer dem åt. När använder man vilken typ av analys?
R-faktoranalys är analys av latenta strukturer i datamängden. Det man så gott som alltid gör i en vanlig korrelations/faktoranalys. Q-faktoranalys är analys av latenta strukturer bland deltagarna. Q-analys kan man göra om man får svaga resultat i en R-analys på grund av något man misstänker har med systematiska mönster i urvalet och deltagare att göra (oupptäckta "subpopulationer"). (Kan vara så att i det SCB kallar klusteranalys så använder man sig av givna subpopulationer som om de inte är totalt var självklara från början så är de resultat av Q-faktoranalyser.)
R-faktoranalys används då man i sin faktoranalys tittar efter samband mellan variabler, Q-faktoranalys analyserar samband mellan respondenter.
Om målet är att gruppera egenskaper/variabler så använder man faktoranalys på en korrelationsmatris där man korrelerat variablerna, R-faktoranalys. Man analyserar en hop med variabler för att hitta latenta dimensioner i data (sådana som inte är enkelt observerbara). Variablerna kan t e x vara frågor i ett frågeformulär. Man sammanställer

hur folk har svarat på frågorna och korrelerat data för att hitta underliggande dimensioner som sammanfattar data till ett fåtal variabler d v s faktorer. I det här exemplet skulle frågorna kunna handla om människors hälsa i allmänhet och analysen skulle kunna dela upp frågorna i psykisk och fysisk hälsa. Vilket namn man väljer på den extraherade faktorn får forskaren själv bestämma utefter teori och logik.
Faktoranalys kan användas när analysenheten är respondenter, Q-faktoranalys. Man använder sig här också av en korrelationsmatris där man sätter in respondenterna utefter deras egenskaper. Analysen placerar folk i grupper utefter hur lika de är med avseende på vissa egenskaper.
Ev överkurs: Q-faktoranalys baserar sig på interkorrelationer mellan respondenter medan klusteranalys formar grupper utefter avståndsbaserad likhet mellan respondenternas poäng på variabeln. Q-faktoranalys grupperar utefter hur svarsmönstret för varje respondent ser ut d v s personer vars svarsmönster liknar varandra, oavsett hur mycket de poängmässigt skiljer sig från varandra, hamnar i samma grupp. Klusteranalys formar grupper utefter vilka poäng respondenterna har på en variabel d v s personer med ungefär samma poäng hamnar i samma grupp. Jag är inte säker, men just att Q-faktoranalys grupperar respondenter utefter deras svarsmönster skulle kunna vara en utmärkande egenskap hos metoden, utöver att den behandlar respondenter istället för variabler. Dock vet jag inte om klusteranalys är utmärkande för R-faktoranalys; så att man kan säga att R-faktoranalys grupperar utefter poäng och Q-faktoranalys grupperar utefter svarsmönster. Återigen, fråga en expert!
5. Chefen tar in dig på sitt rum och ber dig förklara en sak. Chefen har läst en testmanual där orden faktoranalys och egenvärde förekom. Nu undrar chefen vad egenvärdena egentligen står för i en faktoranalys. Du ser det här som en chans att öka respekten för psykologkåren och förklarar.
Egenvärde är måttet på hur stor del av den totala variansen som en faktor förklarar. Totala variansen= addera ihop alla variablernas varians. I detta fall blir det lika med antalet variabler, ex har vi 15 variabler blir den tot variansen 15. Om en faktors egenvärde är 3 betyder det att den förklarar 33 % av totala variansen. Man adderar hur stora communalities (hur stor del av variansen i en variabel som en faktor kan förklara) och får på så sätt den totala variansen.
Eigenvalue är förklaringsvärdet för en enskild faktor jämfört med det genomsnittliga förklaringsvärdet för en variabel. Om en faktor förklarar lika mycket varians som en genomsnittlig variabel får den eigenvalue 1.
6. Eftersom du verkade ha så bra koll på egenvärden så har chefen bett dig att konstruera ett mätinstrument som ska screena för somatiska och psykologiska stressymtom. Instrumentet skall innehålla 10 items i var och en av de två sub-skalorna. Beskriv hur du går till väga! Följande termer skall finnas med i ditt svar: förklarad varians, communality, dubbelladdning, oblik och/eller ortogonal rotation.
Jag har mina 20 frågor och bjuder testet till en massa folk. Sedan gör jag en korranalys av svaren och plottrar en korrmatris. Jag vill se vilka variabler som korr med vilka för att undersöka huruvida det är några underliggande dimensioner som kan förklara data på ett bra och enkelt sätt. Jag besätmmer att jag vill använda mig av faktorer som har egenvärde större än ett och hittar fyra stycken. Dessa döper jag till smärta, oro, sömnproblem och stress efter att ha tittat på de variabler som laddar på varje faktor. Några variabler dubbelladdade och då valde jag att ta bort två av dem. Två ville jag ha kvar så jag var tvungen att rotera lite. Jag valde ortogonal då jag kanske vill göra lite statistik på skiten längre fram (vill ju inte att faktorerna skall korr inombördes för guds skull). Jag tittade på hur mkt varje faktor kunde förklara en variabels varians (communalities) och även på den totala förklarade variansen. Det var ju den som fick avgöra om en faktor fick blir en faktor eller inte ( egenvärde över 1)
Jag ska konstruera ett frågeformulär som screenar för somatiska och psykiska stressymtom. Först gör jag frågorna så att jag har 10 frågor per subskala. Här använder jag mig av teori och min kliniska erfarenhet för att komma på frågor som jag anser fångar dimensionerna.
• Uppskatta antal deltagare som krävs för analysen; 5-10 pers per variabel. Det blir i det här fallet 100 deltagare (20x5). FA kräver minst 50 deltagare, helst över 100.
• Samla in data. Låt lämplig population fylla i formuläret.
• Kontrollera att data är lämplig, att det finns spridning och gemensam varians.

• Sätta in data i en korrelationsmatris. Se hur frågorna korrelerar med varandra. Verkar subskalorna utkristallisera sig?
• Bestämma antalet faktorer som ska extraheras. Antingen a prioi eller utifrån data. I så fall kan vi ta bort de faktorer som har lägre egenvärde än 1 eller bestämma oss utifrån armbågen i scree-plot. I det här fallet har vi redan en idé om att det ska finnas två subskalor, faktorer.
• Tittar på faktorladdningarna. Dubbelladdningar? Varje fråga ska bara ladda högt på en faktor. Bestäm cut off, högt = 0.3-0.5.
• För att få en tydligare lösning kan vi göra en rotation; ortogonalt och/eller oblikt.
• Ta bort frågor som laddar högt på båda. Laddar de lågt på alla faktorer kan man räkna communality d v s hur stor varians hos en fråga som förklaras av båda faktorer. Är värdet lågt tar man bort frågan. Se så att varje faktors egenvärde inte är mindre än 1, d v s den varians i data som förklaras av faktorn. Är värdet under 1 har faktorn inte tillräckligt förklaringsvärde för att få vara kvar i lösningen. Den korrelerar alltså för lite med frågorna och kan då inte sägas utgöra en underliggande dimension i data.
• Namnge faktorerna, i vårt fall är det redan gjort; somatiska och psykiska stressymtom.
Första steget i analysen blir att specificera syfte och att definiera variabler som skall undersökas. En principalkompontentanalys som utgår från all varians (felvarians, unik varians och gemensam varians) är mer stabil än en faktoranalys och är bättre att använda vid datareduktion. Därefter undersöks om data är lämplig, dvs. se om det finns spridning och gemensam varians. Ett statistiskt mått på lämplighet är Bartlett´s test of sphericity. Man tar reda på om det finns tillräckligt många signifikanta korrelationer mellan variablerna att utgå ifrån. Sedan kan man i en korrelationsmatris se hur varje item korrelerar med varje annat item och hur varje item korrelerar med alla andra item. Som ett mått på förklarad varians får man fram eigenvalues för de olika faktorerna. Om en faktor förklarar lika mycket varians som en genomsnittlig variabel får den eigenvalue 1. Det finns olika sätt att avgöra hur många faktorer man ska ha i sin lösning. En variant är att utgå från eigenvalue, ett annat sätt är att använda scree-test. När en oroterad lösning sedan skall tolkas finns ofta en risk att flera variabler laddar högt på mer än en faktor (=dubbelladdning). För att få en så tydlig lösning som möjligt kan man utföra en rotation. Det innebär att faktorladdningarna stuvas om så att varians från tidigare faktorer läggs på senare faktorer, utan att den inbördes relationen mellan variablerna ändras. En ortogonal, vinkelrät, rotation är stabil och ger faktorer som är enklast att tolka. En oblique rotation skapar tydligare faktorer av materialet men är svårare att tolka. Beträffande datareduktion kan man a) välja den mest typiska variabeln, b) räkna ut faktorpoäng eller c) använda en summerad skala.
7. Vad behöver man ta hänsyn till när man ska välja hur många faktorer man vill ha med i sin slutgiltiga faktorlösning? Nämn minst fyra kriterier som man kan använda samt kommentera hur ”statistiskt hårt” eller ”objektivt” varje kriterium kan anses vara. Räkna ut communalities och egenvärden från följande matris av faktorladdningar för två faktorer (OBS! Faktorladdningarna är hypotetiska och valda för att det ska gå att lösa med hjälp av huvudräkning).
Faktor 1 Faktor 2 Variabel 1 0.7 0.2 Variabel 2 0.7 0.2 Variabel 3 0.1 0.6 Variabel 4 0.1 0.6
man kan ta hänsyn till vad man har för tankar om faktorerna, tror man att det finns fyra underliggande faktorer kan man ju anta detta och se om det kan vara så.Detta är ju ganska så subjektivt då man kan rotera och ta bort in i förbannelse. Man kan använda egenvärde över 1 som gräns. Detta är ju det mest objektiva måttet. Är det mindre än det kan man ju lika gärna ha kvar den ursprungliga variabeln. Man kan titta på armbågen i screenplotten. Denna är mittemellan, lite objektiv och lite subjektiv. den fjärde vet jag ej. väldigt osäker på om det är detta svar han syftar till...
Communality (kvadrera alla laddningar för varje variabel och summera) Variabel 1, 2: 0.72 + 0.22 = 0.49 + 0.04 = 0.53 Variabel 3, 4: 0.12 + 0.62 = 0.01 + 0.36 = 0.37

Egenvärde (kvadrera alla laddningar för varje faktor och summera) Faktor 1: 0.72 + 0.72 + 0.12 + 0.12 = 2(0.49 + 0.01) = 1.0 Faktor 2: 0.12 + 0.22 + 0.62 + 0.62 = 2(0.04 + 0.36) = 0.80
Faktor 1 Faktor 2 Communality Variabel 1 0.7 0.2 0.53 Variabel 2 0.7 0.2 0.53 Variabel 3 0.1 0.6 0.37 Variabel 4 0.1 0.6 0.37
Egenvärde 1.0 0.80
Det finns fyra metoder att bestämma antalet faktorer man extraherar ur analysen. Antingen bestäms antalet faktorer a priori d v s på förhand utifrån ens teoretiska/konceptuella förförståelse ELLER med hänsyn till egenvärdena genom att man sätter ett tröskelvärde på 1 eller letar rätt på armbågen i den s k scree plot:en. Ytterligare ett kriterium är att man sätter en tröskel för hur mycket varians i data faktorerna minst ska förklara, t ex 60 %.
Ev. överkurs: Scree test används för att identifiera de faktorer som förklarar så mycket av den gemensamma variansen och så lite av den unika variansen som möjligt. Varje variabels varians kan delas upp i gemensam/förklarad varians och oförklarad varians; unik varians och felvarians. Scree test plottar upp egenvärdena mot faktorerna i ett diagram. Så länge kurvan sjunker (den indikerar egenvärdet för varje faktor) kan man ta med ytterligare faktorer i lösningen, man stoppar där kurvan planar ut, ”armbågen”. Ytterligare ett kriterium angående hur många faktorer man ska ta med i sin lösning kallas ”kriteriet för procentuell varians” och handlar om att antalet faktorer man tar med tillsammans ska förklara en viss andel av den totala variansen i data, inom psykologisk forskning brukar tröskeln ligga på 60 %.
Faktor två når inte upp till ett egenvärde av 1, därför bör den avlägsnas.
Ev. överkurs: För att en faktor ska få vara med i vår lösning ska den ha ett egenvärde på minst 1, med andra ord, faktorn ska åtminstone kunna förklara lika mycket varians som en variabel i genomsnitt kan förklara i vårt dataset. Vi ser att första faktorn når upp till tröskeln på 1 i egenvärde vilket den andre faktorn inte lyckas med. Därför bör vi ta bort faktor två ur vår lösning.
Besvara följande:
a) Hur bestäms hur många faktorer man får ut ur en faktoranalys och borde faktor 2 vara med i faktorlösningen i den förra uppgiften?
Man kan göra på olika sätt. Antingen bestämmer man det innan man börjar analysen ex att man tror att det finns fyra underliggande dimensioner. Eller så tar man med de faktorer som har egenvärde större än ett eller ”armbågen” i screenploten (där lutningen minskar kraftigt)
b) Vad beskriver egenvärdet?
Det beskriver hur stor del av den totala variansen en faktor förklarar. Man adderar alla variablernas communalities (hur mkt en faktor kan förklara av en variabels totala varians). Man vill ju ha ett egenvärde som minst är över ett, annars kan man ju lika gärna ha kvar den variabel man hade. Totala variansen; man adderar alla variablers varians för sig och dessa får man tag i på diagonalen i en korrmatris. I en korrmatris blir detta antalet variabler. Om en faktor ex har egnvärde 5 och total varians är 20 täcker den in 5/20=25% av variansen.
c) Vad är dubbelladdningar?
det är när en variabel korr med flera olika faktorer. Detta vill man inte då man vill hitta faktorer som förklarar datan. Vi vill att varje variabel laddar på en faktor så mkt som möjligt.
d) Varför roterar man oftast sin faktorlösning?

Det har att göra med att man vill försöka få det så att varje variabel laddar på en faktor så mkt som möjligt. Det är då det blir teoretiskt mer meningsfullt. Det kan leda till att vissa faktorladdningar minskar men att fler variabler laddar på endast en faktor.
b) Vad beskriver egenvärdet?
Egenvärdet säger oss hur mycket varians i våra data som förklaras av en faktor (faktor kallas även för komponent).
Ev. överkurs: Den ska helst ha ett egenvärde på minst 1 annars bör man överväga att ta bort faktorn. Egenvärdet 1 innebär att faktorn förklarar lika mycket varians som en variabel i våra data i genomsnitt förklarar.
c) Vad är dubbelladdningar?
Dubbelladdning innebär att en variabel korrelerar högt på två eller flera faktorer, vilket gör att den inte har en tydlig tillhörighet till en specifik faktor.
Ev. överkurs: I vår analys strävar vi efter att varje variabel endast ska ladda högt på en av faktorerna, så att vi får tydliga faktorer. Om man kvadrerar faktorladdningen (d v s dess korrelationskoefficient; r) får man ut hur mycket av variabelns varians som förklaras av en faktor.
d) Varför roterar man oftast sin faktorlösning?
För att få bort eventuella dubbelladdningar och få tydliga faktorer, alltså variablerna i analysen laddar bara högt på en faktor.
Ev. överkurs: Rotering förenklar tolkningen av faktorstrukturen genom att fördela variansen från tidigare faktorer (den faktor som extraheras först i analysen förklarar den mesta variansen, nästa faktor förklara näst mest varians osv) till senare faktorer och på så sätt uppnå ett enklare och teoretiskt sett mer meningsfullt faktormönster. Det finns två typer av roteringar man kan göra – ortogonal och oblik. Den mest använda är ortogonal, den är enklare än oblik. Här roterar man axlarna (faktorladdningarna plottas upp på ett x/y diagram, där x och y axlarna representerar respektive faktor) så att punkterna hamnar närmare axlarna, vilket innebär att variablerna laddar mer på bara en av faktorerna. Axlarna behåller hela tiden sin vinkel på 90 grader. Vid oblik rotering förändras även vinkeln på axlarna. Här är dessutom faktorerna korrelerade med varandra.
8. Vid konstruktion av frågeformulär är faktoranalys ett viktigt verktyg. Besvara följande frågor. Motivera ditt svar!
a) Vad är det minimala antalet frågor (items) som bör ladda högt på en faktor? för att det skall bli meningsfullt antar jag att det är minst två. Annars kan man ju lika gärna ha kvar the original itemet. Hmm.
b) Vilket är det minimala egenvärdet som en faktor bör ha för att anses relevant? 1. Se fråga a.
c) Vilket antagande gör man angående sina faktorer då man använder oblik rotation? faktorerna börjar korr med varann. Ej bra om man skall statistika vidare.
d) Vad är en dubbelladdning och vad kan man göra åt den? en variabel laddar på flera faktorer. Man kan antingen ta bort itemet och vill man inte det kan man rotera för att försöka hitta en vinkel där varje variabel bara laddar på en faktor,
9. Anta att du ska konstruera ett nytt frågeformulär som ska gå att dela upp i olika delskalor. Du väljer strategin att inledningsvis inkludera fler frågor än vad du tänkt ha med i slutändan, i syfte att kunna välja ut de frågor som har de bästa psykometriska egenskaperna. Du har från början med 35 frågor.
Hur många personer bör fylla i formuläret för att du ska kunna göra en faktoranalys som håller för samtliga 35 frågor?
Det ska vara 5-10 gånger fler observationer än antalet variabler. I det här fallet blir det 5 x 35= 175. Minst 175 personer bör fylla i frågeformuläret. Minst 50 observationer, helst över 100.

eftersom vi är konservativt lagda vill vi ha minst 350 pers.
Vad bör du ta hänsyn till när du bedömer vilka frågor som inte ska vara med i den slutgiltiga lösningen? Nämn åtminstone två riktlinjer!
• Frågor som har dubbelladdningar eller laddar lågt på alla faktorer, de visar ingen tydlig tillhörighet till en specifik faktor.
• Frågor som har låg communality d v s de förklaras dåligt av faktorerna tillsammans. Värdet bör vara minst 0.5 för att frågan ska få vara kvar.
• Frågor som korrelerar högt med varandra bör tas bort då de säger samma sak.
• --- dubbelladdningar är inte bra. Antingen ta bort eller rotera. Det är heller inte bra med variabler som inte korr mot någon av faktorerna, då kan du välja mellan att ta bort eller att göra något annat som jag inte kommer igår vad det var. Titta på communalities för att se om de existerande faktorerna kan förklara variansen i denna variabel. Titta också på själva frågan för att se om det känns ok att ta bort den. Titta också på hur stort egenvärde de olika faktorerna har, hur stor varians är du beredd att gå miste om?
10. Föreställ dig att du har ett test med tio frågor som du tror mäter två faktorer. Din roterade faktorlösning ger två faktorer, men hur vill du att faktorladdningarna ska se ut i respektive faktor för att du ska vara övertygad om att testet mäter just två faktorer? Skriv ned en tabell med faktorladdningar (dvs hitta på laddningarna). Nämn andra statistiska mått som har betydelse för din uttolkning (t.ex procent förklarad …..)
Variabel faktor 1 faktor 2
1 .75 .08 2 .021 .64 3 .82 .20 4 -.001 .78 5 .19 .67 6 .65 -.10 7 .12 .75 8 .77 .00 9 -.05 .65 10 .79 .15
Förutom tabellen med faktorladdningar är det betydelsefullt att känna till kommunalitet, eigenvalue (förklarad varians) och MSA/KMO.
Jag vill att de båda faktorerna skall förklara olika variablers variation. Jag vill att faktorladdningen skall vara minst .3-.5 (dvs en förklarad varians= dessa nummer kvadrerade). Jag vill att det inte ska vara en massa dubbelladdningar. Jag vill att egenvärdena adderade skall vara ganska nära totala variansen. ---
F1 F2 0.90 0.10 0.80 0.20 0.70 0.10 0.80 0.05 0.85 0.15 0.10 0.90 0.20 0.80 0.10 0.70 0.05 0.80 0.15 0.85
Viktigt att varje variabel (fråga) endast laddar högt på en av faktorerna.
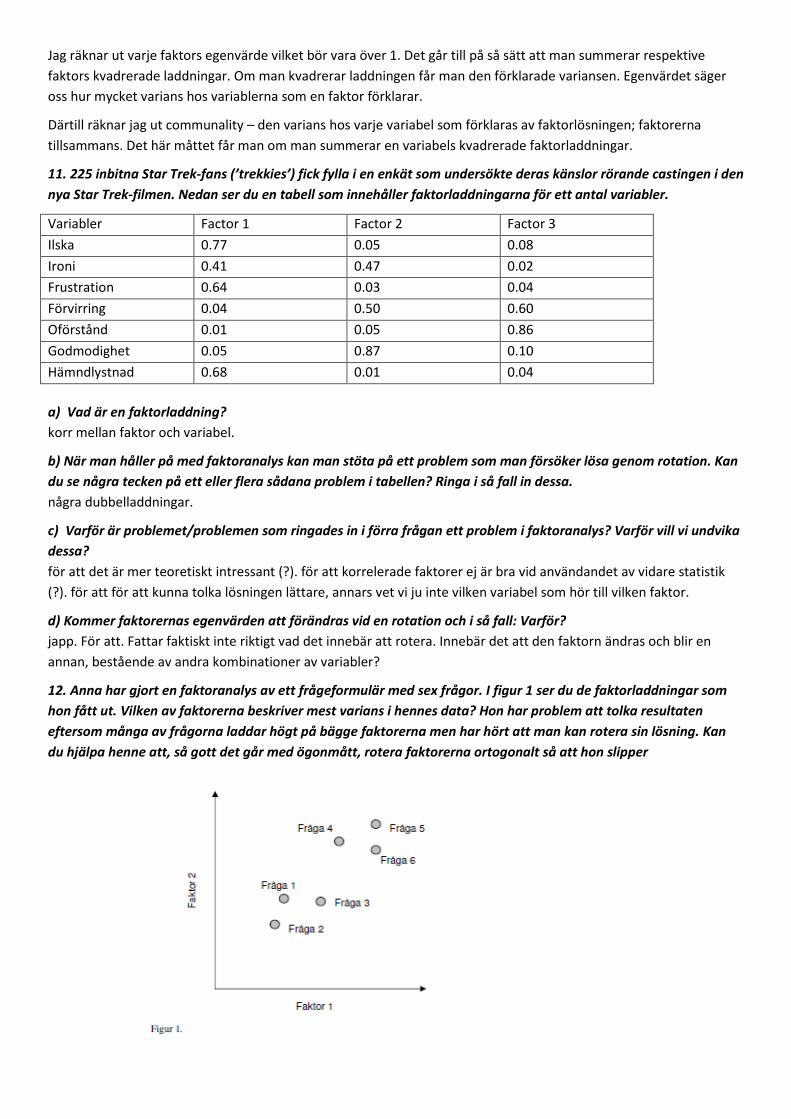
Jag räknar ut varje faktors egenvärde vilket bör vara över 1. Det går till på så sätt att man summerar respektive faktors kvadrerade laddningar. Om man kvadrerar laddningen får man den förklarade variansen. Egenvärdet säger oss hur mycket varians hos variablerna som en faktor förklarar.
Därtill räknar jag ut communality – den varians hos varje variabel som förklaras av faktorlösningen; faktorerna tillsammans. Det här måttet får man om man summerar en variabels kvadrerade faktorladdningar.
11. 225 inbitna Star Trek-fans (’trekkies’) fick fylla i en enkät som undersökte deras känslor rörande castingen i den nya Star Trek-filmen. Nedan ser du en tabell som innehåller faktorladdningarna för ett antal variabler.
Variabler Factor 1 Factor 2 Factor 3
Ilska 0.77 0.05 0.08
Ironi 0.41 0.47 0.02
Frustration 0.64 0.03 0.04
Förvirring 0.04 0.50 0.60
Oförstånd 0.01 0.05 0.86
Godmodighet 0.05 0.87 0.10
Hämndlystnad 0.68 0.01 0.04
a) Vad är en faktorladdning? korr mellan faktor och variabel.
b) När man håller på med faktoranalys kan man stöta på ett problem som man försöker lösa genom rotation. Kan du se några tecken på ett eller flera sådana problem i tabellen? Ringa i så fall in dessa. några dubbelladdningar.
c) Varför är problemet/problemen som ringades in i förra frågan ett problem i faktoranalys? Varför vill vi undvika dessa? för att det är mer teoretiskt intressant (?). för att korrelerade faktorer ej är bra vid användandet av vidare statistik (?). för att för att kunna tolka lösningen lättare, annars vet vi ju inte vilken variabel som hör till vilken faktor.
d) Kommer faktorernas egenvärden att förändras vid en rotation och i så fall: Varför? japp. För att. Fattar faktiskt inte riktigt vad det innebär att rotera. Innebär det att den faktorn ändras och blir en annan, bestående av andra kombinationer av variabler?
12. Anna har gjort en faktoranalys av ett frågeformulär med sex frågor. I figur 1 ser du de faktorladdningar som hon fått ut. Vilken av faktorerna beskriver mest varians i hennes data? Hon har problem att tolka resultaten eftersom många av frågorna laddar högt på bägge faktorerna men har hört att man kan rotera sin lösning. Kan du hjälpa henne att, så gott det går med ögonmått, rotera faktorerna ortogonalt så att hon slipper

dubbelladdningar (rita figuren i ditt svar)?
Utifrån diagrammet i det här icke roterade läget - punkterna samlas kring en tänkt rak linje som går snett uppåt genom diagrammet - så ser det ut som att båda faktorerna beskriver ungefär lika mycket varians i data. För att få en tydligare faktorlösning där variablerna laddar endast på en av faktorerna behöver vi göra roteringar.
En ortogonal rotering kan se ut så här:
Nu laddar hälften av variablerna (fråga 4, 5, 6) högt på enbart faktor 2. Andra hälften (fråga 1, 2, 3) laddar lågt på båda faktorerna. Faktor 1 förklarar här ingen större varians i data och kan inte sägas fånga den underliggande dimensionen hos någon av frågorna.
Hittade en ytterligare fråga:
Vad kan man använda faktoranalys till? Vilka krav bör man ställa på data?
Faktoranalys kan användas för att hitta underliggande konstrukt, för att reducera data inför fortsatt analys eller för att testa tidigare indelningar i faktorer. Det är även användbart när man vill konstruera frågeformulär. Faktoranalys har varit viktigt inom personlighets- och intelligensforskning. De krav man kan ställa på data är att det skall finnas spidning och homogen varians. Man bör se upp för outliers. Beträffande normalitet är kraven inte så hårda.
FAKTOR 1
F A K T O R 2
Fråga 2 Fråga 1
Fråga 3
Fråga 6
Fråga 5 Fråga 4

Och en till:
På japanska heter social fobi taijin kyofusho
a) Skulle författarna kunnat hitta en lösning med färre komponenter där alla variabler hade minst en laddning över 0.499 på minst en komponent?
. I en japansk studie ville man hitta en struktur i ett frågeformulär. För ändamålet utfördes en faktoranalys av resultaten från de 135 personer som fyllt i frågeformuläret. Faktorladdningar på komponenter med ett egenvärde över 1 i den ortogonalt roterade faktorlösningen analyserades. De olika variablernas laddningar och komponenternas namn ser du i tabell 1. Endast laddningar större eller lika med 0.499 redovisas. Utifrån den information du fått i texten ovan och i tabell 1 ska du svara på frågorna nedan och motivera ditt svar. Tycker du att du skulle behöva ytterligare information för att besvara en fråga, beskriv då vilken statistik du saknar! (4 poäng):
b) Vad skulle det betyda ifall lösningen var oblik istället för ortogonal? c) Hur mycket varians i varje variabel förklaras av lösningen? d) Hur mycket varians i data förklaras av lösningen?
SVAR: a) Den varians som förklaras i en variabel av de faktorer/komponenter man fått ur sin lösning
brukar kallas ”communality”. Den räknas ut som summan av varje faktorladdning för respektive variabel upphöjt i 2 (eftersom faktorladdningarna är variabelns korrelation med faktorn/komponenten och förklarad varians brukar skrivas som korrelationskoefficienten upphöjt i 2, r2). För att säkert veta att en lösning med 3 komponenter inte kan ge en lösning där alla variabler hade minst en laddning över 0.499 på minst en komponent skulle vi behöva veta vilken ”communality” varje variabel har i en sådan lösning. Det skulle vi kunna få reda på om vi hade den oroterade matrisen med faktorladdningar. Då skulle vi summera alla variablers laddningar för de 3 första faktorerna. När vi har vår ”communality” kan vi säga att om någon variabel har en communality som är mindre än 0.499 upphöjt i två, vilket ungefär är lika med 0.25, så kan den heller aldrig ha en laddning som är 0.499 eller över, hur vi än roterar.
b) Att faktorerna/komponenterna är korrelerade med varann. c) Proportionen förklarad varians beskrivs av ”communality” som vi inte har. Vi kan även komma åt
den om vi hade haft tillgång till alla laddningar (OBS! här spelar det inte någon roll om faktorerna/komponenterna är roterade eller inte eftersom summan av de kvadrerade laddningarna för alla 4 komponenter sammantagna blir densamma oavsett så länge vi endast roterar ortogonalt. Matematiskt kan man säga att den roterade lösningen ligger i ett underrum till den oroterade lösningen.) och inte endast dem över 0.499 (se svar på fråga a).
d) För att lättast kunna svara på den här frågan skulle vi behöva tillgång till egenvärdena. Proportionen förklarad varians är lika med summan av egenvärdena tillhörande faktorerna/komponenterna i vår lösning delat med summan av alla egenvärden.
SVAR: T.ex vid konstruktion av frågeformulär för att se att frågorna hänger ihop och det inte finns någon fråga som laddar högt på flera faktorer eller ensam på en. Ett annat exempel är då vi vill använda oss av faktoranalys för att komprimera data. Vi kan sedan använda det vi får ut i en regression mot andra variabler.
Tabell 1. Principal component analysis
Socially
inadequate Performance Offensive
feelings anxiety Fear Tenacity
Giving an impression that I am a bore
0.807
Being thought of as 0.804

an odd fellow
Being thought of as difficult to get along with
0.798
Being very shy 0.774
Feeling that only I am out of keeping with company
0.763
Being seized with stage fright
0.835
Behaving awkwardly if aware of being scrutinized by others
0.761
Being afraid of getting flurried in public
0.745
Fear of being humiliated by tensing up in a crowd
0.723
Not being able to manage well in the presence of others
0.623
Feeling that I displease others
0.803
Avoiding a crowd because of fear of giving them gloomy feelings
0.773
Disgusting others 0.499 0.67
Feeling that my face and eyes influence others
0.625
Able to display my potential ability if I can be myself with other people
0.768
Having struggled to overcome my timidity in public
0.737
Not having to avoid social interactions if I can behave naturally
0.674
Having tried hard to get rid of social anxiety
0.555
Extraction method: principal component analysis; rotation method: Varimax with Kaiser normalization.

Från: Iwase, Madoka, Nakao, Kazuhisa, Takaishi, Jyo, Yorifuji, Kazuhiro, Ikezawa, Koji & Takeda, Masatoshi (2000). An empirical classification of social anxiety: Performance, interpersonal and offensive. Psychiatry and Clinical Neurosciences 54(1),67-75.
Metaanalys 1. Metaanalys går ut på att systematisera resultatet från flera studier. Men hur går man till väga? (3 poäng)
Allra först: Definiera en intressant frågeställning. Ett exempel kan vara; vilken kognitiv intervention fungerar bäst när man behandlar tvångstankar? Tillvägagångssätt. Bestämma sig för om man antingen ska analysera sambandsstudier eller interventionsstudier. I sambandsstudier används korrelationskoefficienten för att räkna effektstorlek och vid interventionsstudier så används Cohens d.
Litteratursökning. Mycket viktigt steg, krävande arbete. För att få fram studier kring frågeställningen så försöker man få fram allt som är publicerat i ämnet. Man ska vara tydlig med hur och varför man valt ut de aktuella studierna: redogöra för sina inklusionskriterier. Kodning av studier. Nu är det dags att ta fram den information som man vill få ut av studien, som sedan används för att genomföra metaanalysen. Saker som kan vara bra att koda för: demografiska fakta, kön, publikationsår, fullständig referens, teoretisk preferens hos forskaren osv. Studierna är metaanalysens deltagare och de bör beskrivas så ingående som möjligt. Ofta kodar man för mer än vad som kommer med i analysen. Uträkning av effektmått. Man jämför inte studiernas p värden utan istället deras effektstorlek – skillnaden mellan två gruppers medelvärden uttryckt i standardavvikelser. Alla studiers sammanlagda effektstorlek räknas ut eller kategorier av effektstorlek (t ex effektstorlek för symtom, negativ effekt, sömn). Man strävar att använda sig av så jämförbara mått som möjligt. Diskussion och kontroll av resultaten. Kontroll av homogenitet med hjälp av chi2-test. Man räknar ut om det är homogenitet i effektstorlekarna som ska slås ihop. Går studierna att lägga ihop eller spretar de för mycket? Om de är heterogena så undersöker man om man kan hitta orsaken till det genom s k underanalyser.
2. Metaanalys från A till Ö? Jag vill att du kortfattat beskriver hur man går tillväga. (3p)
3. Du har tillgång till 45 studier inom ett område (t.ex behandling av paniksyndrom). Hur gör du en meta-analys?
4. Meta-analys förutsätter tillgång till studier. Hur bör dessa se ut? Hur kan man avgränsa? Hur gör sen beräkningarna?
Studierna ska vara väl genomförda och bör inkludera randomised controlled trials. Det ska helst finnas omfattande information i studien om deltagarna, design och metod, och gärna om forskarens teoretiska preferenser.
Vid en metaanalys ska man söka efter samtliga studier inom området man är intresserad av. Detta är en omöjlighet, av flera orsaker: inte alla studier som publiceras, studier på främmande språk etc. Det viktigaste är dock att man noggrant redogör för hur man har sökt, vilka databaser etc och att man redovisar sina inklusionskriterier. En avgränsning är mellan att antingen analysera interventionsstudier eller sambandsstudier.
I metaanalys använder man sig av effektstorlek och inte p-värden när man jämför studier. För interventionsstudier räknar man Cohens d och för sambandsstudier r. Det är inte lätt att välja ut en effektstorlek som är representativ för hela studien. Här får man också redogöra för hur och varför man gjort som man gjort. En bra idé kan vara att ha kategorier av effekter t ex symtom, negativ affekt och sömn. Därefter räknar man ut den sammanlagda effektstorleken för samtliga studier i metaanalysen. Även här kan man använda sig av kategorier. Viktigt i sammanhangen är att beräkna effektstorlekarnas homogenitet; studiernas resultat får inte spreta för mycket. Då blir det svårt att slå ihop dom. Om de varierar mycket görs underanalyser för att reda ut varför de skiljer sig åt.
5. För att kunna göra en metaanalys behöver de studier man inkluderar innehålla tillräcklig information. Problematisera kring detta! Kan man exempelvis klumpa ihop studier hur som helst?
I Metaanalys är studier lika med försökspersoner (fp) och bör beskrivas lika noga som fp i enskilda studier. Olika faktorer som t e x design och metod i studierna påverkar resultatet och måste kodas enligt de kriterier som forskaren väljer och kontrolleras för. Det är frågeställningen som avgör metod och vilken information man väljer att ta fram. Det går därför inte att klumpa ihop studier eller rättare sagt effektstorlekar som är det mått som används för att

sammanfatta resultatet från enskilda studier hur som helst. Utan man särskiljer mellan samband och skillnader. Exempelvis: att klumpa ihop olika effektstorlekar är inte att rekommendera. Det är dock svårt att välja en effekt som är representativ för en studie. Forskarens beslutgrunder påverkar i hög grad resultatet, även lika beslutsgrunder kan leda till olika resultat och beslutsgrunder måste därför noga redovisas. Det bästa sättet är att hantera flera effektstorlekar i samma studie är att dela in dem i kategorier och sedan analysera separat. Man bör exempelvis inte klumpa ihop mellangrupp och inomgrupps effekter då den först nämnda tenderar att ”dra iväg”, vilket ger en skev bild. Komplicerade metoder för beräkning av kombination finns men förutsätter information som ofta inte finns i originalstudierna t e x korrelationen mellan för- o eftermätning. Effektstorlekarna bör vara oberoende d v s inte komma från samma studie eftersom annars kan ju en studie bidra med tio effektstorlekar och en lika väl gjord studie endast bidra med en. Dessutom ges en skev bild av urvalet om samma studie kan bidra med fler effektstorlekar. Dock kan olika typer av effekt analyseras parallellt. Resultatet blir då olika genomsnittliga effektstorlekar (t ex en för sjukskrivningstid och en annan för upplevd smärta). Effektstorlekar kan bete sig olika beroende på samplets karaktär. Det gäller då att beräkna den vägda effektstorleken (för sampelstorlek). Exempelvis om vi har stora skillnader i sampelstorlek kan beräkningsmetoden ge upphov till stora skillnader. Det är därför viktigt att både rapporter den ovägda och den vägda sammanlagda t e x korrelationtionskoefficenten eller annan effektstorlek. --- Antingen analysera interventionsstudier eller sambandsstudier. Studien ska vara väl genomförd och bör inkludera randomised controlled trials. Typ av försökspersoner, kön, ålder och andra viktiga fakta för metaanalysen; hur länge fp haft sitt problem, om flera grupper av fp har deltagit i studien etc. Studiens design, metoder för att samla in data. Beroendemått som använts, dess reliabilitet. Allra helst samma mått i alla studier. Forskarens teoretiska preferenser, kontrollera för bias. Effektstorlekarna för de ingående studierna får inte spreta för mycket. Om de varierar för mycket ska de inte slås ihop. Gör underanalyser för att ta reda på varför. Inte klumpa ihop mellan och inomgrupps effekter då det ger en skev bild. Byrålådeproblemet. Metaanalysen kan ge ett falskt intryck av signifikans då det finns icke signifikant forskning som inte publicerats. Man kan uppskatta hur resistent metaanalysen är mot byrålådeproblemet.
6. I boken om metaanalys beskrivs en del problem man måste vara vaksam inför när man gör en metaanalys. Nämn minst tre potentiella svårigheter när en metaanalys ska sammanställas. (3 p)
7. En forskare kommer till slutsatsen "Denna metaanalys visar ett den genomsnittliga effektstorleken för parterapi är d=.70". Hur kan hon ha kommit fram till detta?
8. Nämn två problem med signifikanstestning.
Varför kan man inte okritiskt acceptera signifikansprövning? Därför att statisktisk signifikans ofta missförstås, p- värdet uppfattas ofta inte korrekt. P-värdet (p<.05) står för sannolikheten att få ett liknande (eller större/bättre) resultat givet att nollhypotesen är sann. Nollhypotesen säger att urvalet, givet dess skillnad, kommer från samma population (det finns ingen skillnad), och att den alternativa hypotesen säger att de kommer från skilda populationer (det finns en skillnad). Kritik har riktats mot att endast använda p-värdet för att fastställa forskningsresultats relevans: Nollhypotestestning och vetenskaplig härledning gäller olika frågeställningar. Vetenskaplig härledning handlar om sannolikheten att nollhypotesen är sann! Forskare utgår ofta felaktigt från att ett lågt p-värde automatiskt ger en falsk nollhypotes. Nollhypotestesning har egentligen två steg: ett statistiskt (p-värdet) och ett om logisk interferens. En kontroll för endast Typ I fel gör att man missar sannolikhet för att göra Typ II fel. P <.05 för tankarna till ett dikotomt förfarande. Om p<.05 antar vi att vi har ett resultat som osannolikt kan förklaras av slumpen = nollhypotes förkastas. Det vi egentligen vill veta är om vår data ger stöd för vår hypotes. Ofta antas det (felaktigt) att p-värdet anger sannolikheten att nollhypotesen är sann. Ofta antas det (felaktigt) att p-värdet anger sannolikheten att ett signifikant resultat uppstår vid replikering. Ofta antas det (felaktigt) att nollhypotesen kan vara sann, men nollhypotesen är alltid falsk. Proof by contradiction= i nollhypotes testning försöker forskaren att förkasta negationen av den teoretiska förväntningen.
Ge mig 2 argument varför det är på tiden att se över vårt sätt att se på statistisk signifikans. Problematisera användandet av traditionell signifikanstestning. Nämn minst 2 nackdelar.

Svar:
Pettersons studie t(78) = 2.21, p<0.05, d = 0.50 Lundströms studie t(18) = 1.06, p<0.30, d = 0.50
(Se även tidigare fråga!). Det traditionella användandet av signifikanstest är en återvändsgränd (Hunter och Schmidt). En aspekt av problemet med signifikanstestning är att två studier vid en jämförelse kan leda till helt skilda slutsatser, trots att de har exakt samma effektstorlek! Ett exempel: Petterson har gjort en studie med 78 personer och funnit en signifikant effekt av behandlingen. Kollegan Lundström har gjort om studien med 18 personer och inte kunnat replikera effekten med t-test. Problemet är att effektstorleken i dessa två studier kan vara identisk, då signifikansvärdet påverkas av att Lundström har färre försökspersoner:
Effektstorlekarna d (=den standardiserad skillnaden mellan grupper, d v s skillnaden mellan medelvärden delat med standardavvikelsen) är identiska. Pettersons studie har replikerats, men problemet är att Lundström haft för få försökspersoner. Detta brukar anges som power vilket definieras som möjligheten att finna en effekt utifrån ett visst antal försökspersoner, givet att det finns en effekt. Genom att inte ta hänsyn till studiens power riskerar forskaren att göra allvarliga misstag vid signifikanstestning. Cohen har beskrivit 0.80 som en önskvärd power. Forskaren ska med andra ord ha 80% sannolikhet att finna en effekt, om den finns där. Tre typiska faktorer som påverkar power brukar omnämnas: effektstorleken i populationen, signifikansnivån och antalet observationer. Till detta kan läggas reliabilitet i måtten samt möjligheten att via experimentell design kontrollera för ovidkommande variabler. Om forskaren vet ungefär hur stark effekt hon har att förvänta och dessutom vet vilken signifikansnivå som hon önskar, kan hon på det sättet ta reda på hur många försökspersoner som behövs för att uppnå ett signifikant resultat.
Power är relaterat till risken för Typ 2-fel. Power är en bättre och mer korrekt uppskattning av vår möjlighet att replikera resultat än vad p-värdet är. Invändningar mot detta resonemang finns dock, och rent empiriskt finns det skäl att anta att p-värdet trots allt är en ganska bra indikator på om effekter kommer att replikeras.
9. P-värden är ett sätt för oss att veta om vi ska bry oss om ett resultat. Hur då? Finns det problem med p-värden? (2 poäng)
P-värdet står för sannolikheten att få ett liknande resultat (som man fått i sin studie) givet att nollhypotesen är sann. Med andra ord: chansen att mitt resultat beror på slumpen. P-värdet säger alltså inte hur säkert eller starkt mitt resultat är. Inte heller om en replikation skulle ge samma resultat. Det är t o m så att ett p-värde blir signifikant om man har tillräckligt många deltagare i sin studie. Detta betyder att i fråga om p-värdet så kan alla resultat bli signifikanta om man har tillräckligt många deltagare. P-värdet säger oss inget direkt om hur stor skillnaden mellan grupperna är eller sambandets styrka. Det säger t ex inget om hur stark effekt behandlingen har - bara om sannolikheten att få ett liknande eller bättre resultat p g a slumpen. Två olika studier kan ha exakt samma effektstorlek där den ena blir signifikant och den andra icke signifikant, bara för att den andra har för få deltagare. Som man kan förstå här så finns det en risk att man ignorerar viktiga resultat om man bara går på studiers p-värden. Ytterligare en sak som komplicerar det hela är att man har satt en godtycklig gräns för p-värdet, 0.05, allt under är signifikant och allt över är icke-signifikant. Vad är det som säger att 0.06 är så mycket sämre resultat? Det blir lite märkligt att ha en sådan dikotom beslutsprocess. Ett sätt att gardera sig mot den här problematiken är att räkna ut studiers effektstorlek, Cohens d, och power. Power är ett uttryck för sannolikheten att hitta en signifikant skillnad om det verkligen finns en sådan. Beräkningen talar då även om hur många deltagare som det krävs för att hitta en signifikant skillnad, med en viss sannolikhet, t e x 80 %. P-värdet kan dock vara bra för att sortera bort knasiga resultat. Dessutom kan teorier testas med detta mått i o m att effektens storlek här inte är så viktig. En huvudanledning till att p-värdet fått sådan status i forskningen är förmodligen forskares behov av att ha något att utgå ifrån – rött eller grönt ljus.
10. Nämn två risker med att förlita sig alltför mkt på p-värden när man ska värdera forskningsresultat.
11. Nu vet ni att statistisk signifikans inte självklart innebär "kliniskt relevant". Ge några förslag till oss forskare hur vi ska göra för att forskningen ska ge "meningsfulla" resultat?
presentera effektstorlek vid sidan om p-värde genomföra power-analys för att undersöka om en studie överhuvudtaget haft en chans att få ett signifikant resultat och/eller hur många fp som behövs för att uppnå ev. signifikans redovisa resultat i andel förbättrade (%) eller i antal standardavvikelser fp har förbättrats där 2 SD = klinisk signifikans använda konfidensintervall, man får ett tydligare och överskådligare resultat metaanalys för att sammanfatta resultat från studier

Statistisk signifikans innebär inte nödvändigtvis klinisk relevans. Detta kan förklaras utifrån att p-värden oftast inte uppfattas korrekt. P-värdet påverkas av hur stark effekten är (kan indikera om man bör göra om studien eller inte) och sampelstorlek. Effektstorlek som Cohens d är ett mått på hur många standardavvikelser ifrån varandra de båda medelvärdena är. Forskare behöver beslutskriterier att utgå ifrån och teorier kan testas utan att effektens storlek har någon större betydelse. Men när det kommer till klinisk forskning kan skillnaden i endast ett poäng vara förödande t e x en poängs skillnad i grad av depression är viktig om det gäller liv eller död. Sålunda vid ”människoräddande” studier kan även en liten effektstorlek vara en viktig effekt.
Förslag till förbättringar i syfte till att forskningen ska ge meningsfulla resultat:
12. Vilket är mest sant p<.05 eller p<.001? Vill du veta mer innan du svarar? Vad i så fall? (2 p)
-Genomföra poweranalys Power är förmåga att kunna påvisa att en sann skillnad mellan grupperna verkligen är statistiskt signifikant d v s sannolikhet att få ett signifikant resultat i de fall det finns effekt. .80 är önskvärd power .50 är dock vanlig inom psykologin. Power är relaterad till Typ II fel d v s sanolikheten att begå ett typ II fel (finns en skillnad men jag säger att det beror på slumpen). Vet man om ungefärlig förväntad effekt samt önskvärd signifikansnivå, går det att räkna ut hur många fpp som behövs för att nå ett signifikant resultat. -Öka statistisk kraft genom: 1. kontrollerade experiment 2. Mäta flera gånger. Power påverkas av effektstorlek, signifikansnivån, sampelstorlek (större sampel =högre power), reliabilitet & kontroll för sammanblandning av variabler. -presentera effektstorlekar vid sidan av p-värde Förtydligande samt är ett alternativ till signifikanstestning (p-värde). -Använda konfidensintervall Enligt vissa ger ett konfidensintervall all information ett signifikanstest ger samt ett spann inom vilket den sanna skillnaden sannolikt ligger. Dessutom får man ett mer synligt, tydligare och överskådligare resultat. -Använda klinisk signifikans Dikotomisering av utfall. Klinisk signifikans innebär att man undersöker hur stor del av patienter i en undersökning som faktiskt erhåller en ordentlig förbättring (inte endast statistisk signifikans som beskrivs som det meningslösa p-värdet). - Att man generellt enas som samma mått och definition gällande klinisk signifikans. Det råder dock fortfarande problem kring hur klinisk signifikans ska räknas ut, om det ens redovisas. Ett sätt som klinisk signifikans kan definieras är exempelvis: för att räknas som kliniskt förbättrad måste personen förflytta sig två standardavvikelser i rätt riktning/komma in i ”normalpopulationen”. - Använda Metaanalys Två syften med Metaanalys: Syntetisk metaanalys innebär att man slår ihop studier. Analystisk metaanalys innebär analys om vad som är bakomliggande effekter.
13. Varför är p<0.05 bättre än p<0.06? Eller är det inte så?
14. En doktor säger ”Detta resultat är ju p<0.001 och måste därför vara mer sant än p<0.05”. Oturligt nog sitter du i publiken och ställer dig upp för att rätta till missförståndet. Vad säger du?
Svar:
Falk och Greenbaum gick igenom logiken bakom signifikanstestning och enligt dem är det ”proof by contradiction” och involverar två negationer: ”In null hypothesis testing the experimenter tries to reject the negation of the theoretical expectation”. De kritiserar också Typ 1-fel som även det missförstås. Typ 1-fel brukar beskrivas som risken att finna en signifikant effekt som inte är sann. Gränsen p<0.05 är dock inte det samma som sannolikheten för Typ 1-fel. Ett vanligt felslut (enligt Kirk) är att tro att a) p-värdet anger sannolikheten för att nollhypotesen är korrekt, b) p-värdet anger sannolikheten att ett signifikant resultat skulle komma upp vid en replikation.
(Se även svar på frågorna nedan!) En påverkande faktor för metaanalysens framgång är att flera forskare har uppmärksammat problemet med traditionell signifikanstestning. Vid hypotesprövning anses det nämligen ibland felaktigt att ”ju fler decimaler desto bättre” (eller ett lägre värde). Således ses t ex en studie med utfallet p<0.001 som bättre än en med p<0.05. Så enkelt är det däremot inte och signifikanstestning missförstås ofta och har således kraftigt ifrågasatts. Jag vill klargöra vad p-värdet egentligen står för: p-värdet står för sannolikheten att få ett liknande (eller bättre/större) resultat givet att nollhypotesen är sann. Detta skulle enkelt kunna förstås som ”risken att begå ett slumpfel”, men den sannolikhet som ges (t ex p<0.01) gäller förhållandet att det inte är någon skillnad mellan grupperna (alt. inget samband mellan variablerna). Alltså prövas data mot nollhypotesen och p-värdet ger således inte direkt ett värde på datas säkerhet eller om resultaten skulle komma att reproduceras.
Att endast kontrollera för Typ 1-fel gör att forskare ignorerar sannolikheten för Typ 2-fel, vilken ibland kan vara mycket hög. Fel av typ två är risken att missa en skillnad eller effekt som är sann. En annan kritik från Kirk är att den fixerade nivån (p<0.05) gör en kontinuerlig beslutsprocess till ett dikotomt förfarande. Varför just 5% risk att göra

fel? ”Surely, God loves the .06 nearly as much as the .05” (Rosnow och Rosenthal). Om vårt p-värde är lika med eller mindre än p<0.05 drar vi slutsatsen att vi har ett resultat, som osannolikt kan förklaras av slumpen eller samplingvariation, och vi förkastar nollhypotesen. Vad vi egentligen vill veta är om data ger stöd för vår vetenskapliga hypotes.