ibm과 nvidia가 제안하는 딥러닝 플랫폼
TRANSCRIPT

IBM 과 NVIDIA 가 제안하는
딥러닝 플랫폼
기존 GPU기술의 한계를 혁신한 새로운 딥러닝 플랫폼
IBM Minsky
IBM
유부선 상무

IBM 과 NVIDIA 가 제안하는
딥러닝 플랫폼
GPU 컴퓨팅에서의 난제 - Host <-> GPU 간의 data copy
• Host 서버의 data를 CPU에서 GPU로, 또그반대로 copy해야함• GPU를써서얻는성능개선의상당부분이그 CPU-GPU간의 copy에서상쇄됨• Disk에서시스템memory로의 copy는 cache 될수도있으나, GPU 메모리는 16GB 또는 24GB 등으로
제한되므로용량에한계가있음
data
이론적16GB/sec실질적8GB/sec
PCIe Gen3
Source : http://www.tested.com/tech/457440-theoretical-vs-actual-bandwidth-pci-express-and-thunderbolt/

IBM 과 NVIDIA 가 제안하는
딥러닝 플랫폼
Vector computation time with CPU only = calcCpu: 1662 ms
calcCpufor (int k = 0; k < tot; k++) {c_B[k] = c_B[k] + c_A[k];}
calcGpucuMemcpyHtoD(d_A, Pointer.to(h_A), tot * Sizeof.DOUBLE);add(tot, d_B, d_B, d_A);cuMemcpyDtoH(Pointer.to(h_B), d_B, tot * Sizeof.DOUBLE);
copytoDevice: 1514copytoHost: 1875calcGpu: 174Vector computation time with GPU = copytoDevice+copytoHost+calcGpu = 3563 ms
Using GPU= calcCpu: 174 ms
(a, b, c, d, e, …. z) + (A, B, C, D, E, …. Z) = (a+A, b+B, c+C, d+D, e+E, …. z+Z)
CPU-GPU memcpy의 문제

IBM 과 NVIDIA 가 제안하는
딥러닝 플랫폼
Deep Learning을 위한 GPU 아키텍처의 고민
/usr/local/cuda-8.0/samples/0_Simple/simpleP2P# ./simpleP2P…Checking GPU(s) for support of peer to peer memory access...> Peer access from Tesla K80 (GPU0) -> Tesla K80 (GPU1) : Yes> Peer access from Tesla K80 (GPU1) -> Tesla K80 (GPU0) : Yes…Creating event handles...cudaMemcpyPeer / cudaMemcpy between GPU0 and GPU1: 7.40GB/s
Source : https://www.google.co.kr/url?sa=t&rct=j&q=&esrc=s&source=web&cd=1&cad=rja&uact=8&ved=0ahUKEwij-9jz48_QAhVJpJQKHezLBlkQFggnMAA&url=http%3A%2F%2Focean.kisti.re.kr%2Fdownfile%2Fvolume%2Fkips%2FJBCRJM%2F2013%2Fv2n2%2FJBCRJM_2013_v2n2_81.pdf&usg=AFQjCNHByHvoX_uKCDeAChs5OaYgstURXw&sig2=WNkcYVR8K6QZP_fEAKlIpQ&bvm=bv.139782543,d.dGo
“Design of MAHA Supercomputing System”
GPU 시스템 설계시 주요 고려 사항a) 메모리 대역폭 : CPU-메모리b) 매니코어 연산장치 대역폭 : CPU-매니코어장치c) 네트워크 장치 대역폭 : CPU-네트워크장치
“스위치의 up-link 연결의대역폭제한으로매니코어장치의유효대역폭이스위치에연결된장치수에반비례(1:n)하여줄어들게된다. MAHA 시스템에서는연산성능을최대한보장하기위하여CPU와매니코어연산장치의비율을 1:2 이하로제한하였다.”

IBM 과 NVIDIA 가 제안하는
딥러닝 플랫폼
Deep Learning을 위한 half-precision 지원
$ vi cifar10.py...if FLAGS.use_fp16:
images = tf.cast(images, tf.float16)labels = tf.cast(labels, tf.float16)
return images, labels...(source : tensorflow CIFAR-10 example)
• Convolution layer로부터의 input은 noise 및 variation으로부터의 민감성을 줄이기 위해 해상도를 줄이는 등의 sub-sampling을 거침
• Backpropagation 알고리즘을 이용해서 trainin하는 deep neural network 아키텍처에서는half-precision(FP16)이면 충분
• 기존 Kepler/Maxwell에서도 FP16을 사용할 수는 있으나, 이는 GPU memory 사용량을 줄일수 있을 뿐 그만큼 GPU 성능을 증가시키지는 못함
Source : https://algobeans.com/2016/01/26/introduction-to-convolutional-neural-network/https://devblogs.nvidia.com/parallelforall/cuda-8-features-revealed/
IBM 과 NVIDIA 가 제안하는
딥러닝 플랫폼
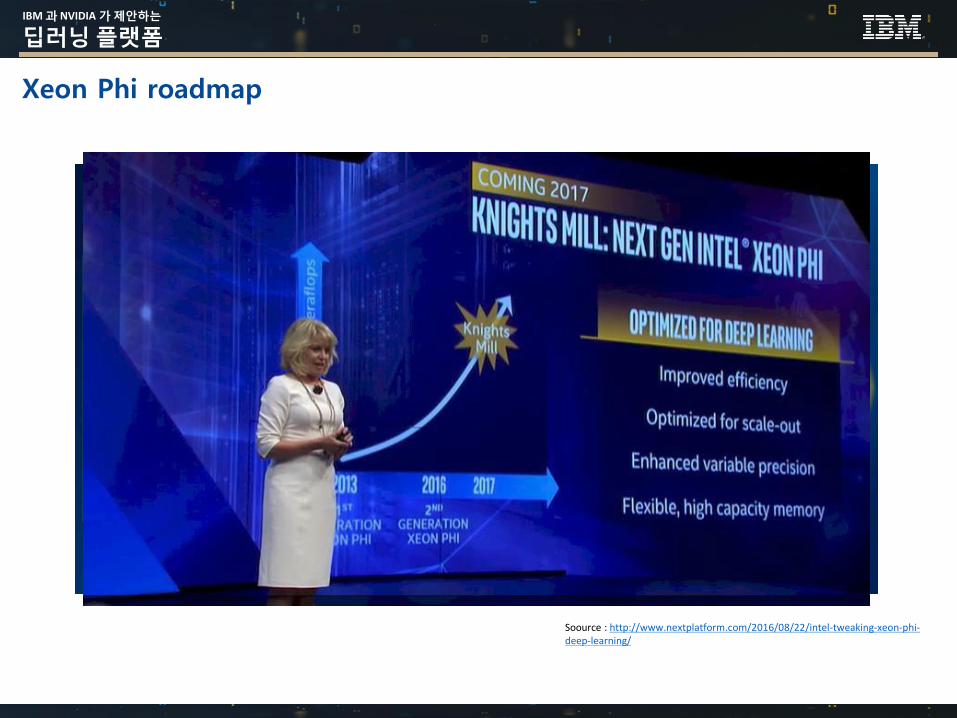
Xeon Phi roadmap
Soource : http://www.nextplatform.com/2016/08/22/intel-tweaking-xeon-phi-deep-learning/
IBM 과 NVIDIA 가 제안하는
딥러닝 플랫폼
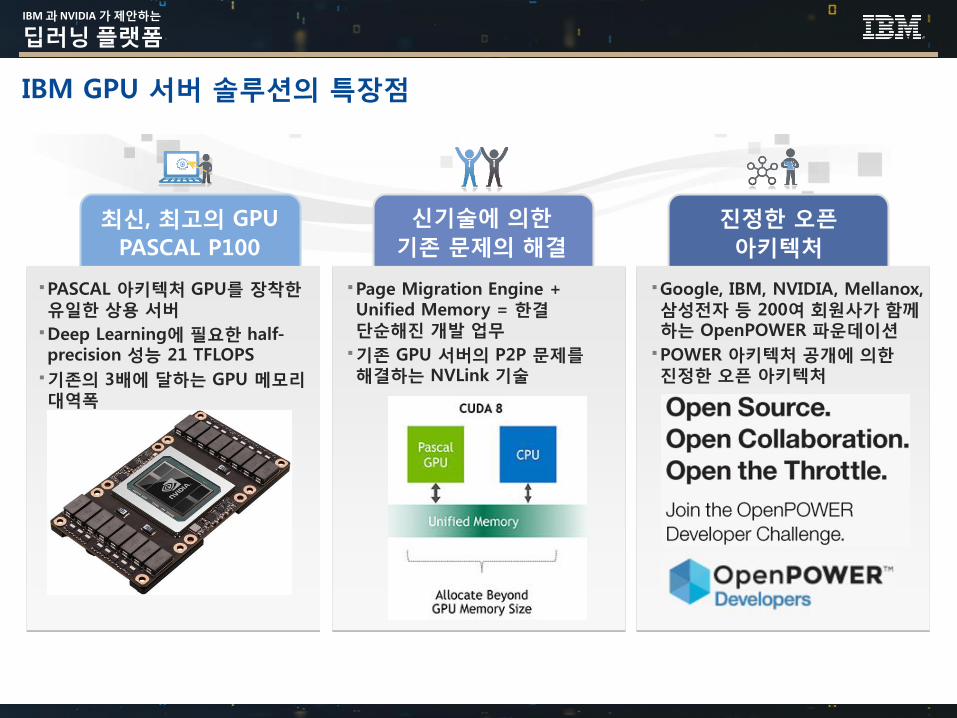
IBM GPU 서버 솔루션의 특장점
신기술에 의한
기존 문제의 해결
진정한 오픈
아키텍처
OpenPOWER
플랫폼
최신, 최고의 GPU
PASCAL P100
Page Migration Engine + Unified Memory = 한결단순해진 개발 업무
기존 GPU 서버의 P2P 문제를해결하는 NVLink 기술
Google, IBM, NVIDIA, Mellanox, 삼성전자 등 200여 회원사가 함께하는 OpenPOWER 파운데이션
POWER 아키텍처 공개에 의한진정한 오픈 아키텍처
PASCAL 아키텍처 GPU를 장착한유일한 상용 서버
Deep Learning에 필요한 half-precision 성능 21 TFLOPS
기존의 3배에 달하는 GPU 메모리대역폭

IBM 과 NVIDIA 가 제안하는
딥러닝 플랫폼
POWER8 with NVLink (2x)
• 190W
• Integrated NVLink 1.0
Memory DIMM’s Riser (8x)
• 4 DDR4 DIMMs per riser
• Single Centaur per riser
• 32 IS DIMM’s total
PCIe slot (3x)
• Gen3 PCIeNVidia GPU
• SXM2 form factor
• NVLink 1.0
• 300 W
• Max of 2 per socket
Power Supplies (2x)
• 1300W
• Common Form Factor Supply
Cooling Fans (4x)
• 80mm Counter- Rotating Fans
• Hot swap
Storage Option (2x)
• 0-2, SATA HDD.SSD
• Tray design for install/removal
• Hot Swap
Service Controller Card
• BMC Content
IBM S822LC for High Performance Computing : “Minsky” 서버
GPU-GPU는 물론 GPU-CPU도 NVLink로 연결된 유일한 서버

IBM 과 NVIDIA 가 제안하는
딥러닝 플랫폼
Source : http://www.nvidia.com/object/gpu-architecture.html#utm_source=shorturl&utm_medium=referrer&utm_campaign=pascalhttp://www.nvidia.com/object/tesla-p100.html
P100 Pascal 아키텍처의 5가지 신기술 적용
FinFET (Fin Field Effect Transistor)CoWoS (Chip-on Wafer-on-Substrate) HBM2 (High Bandwidth Memory 2)PME (Page Migration Engine)UM (Unified Memory)
16 nm
FinFET
기술에의해향상된
에너지효율
ML/DL을위한새로운
half-
precision
instruction
현재의 PCIe
대비 5배빠른 NVLink
기술로상호연결
CoWoS
HBM2로3배향상된메모리대역폭
PME와UM을통해사실상
해제된 GPU
메모리한계
IBM 과 NVIDIA 가 제안하는
딥러닝 플랫폼
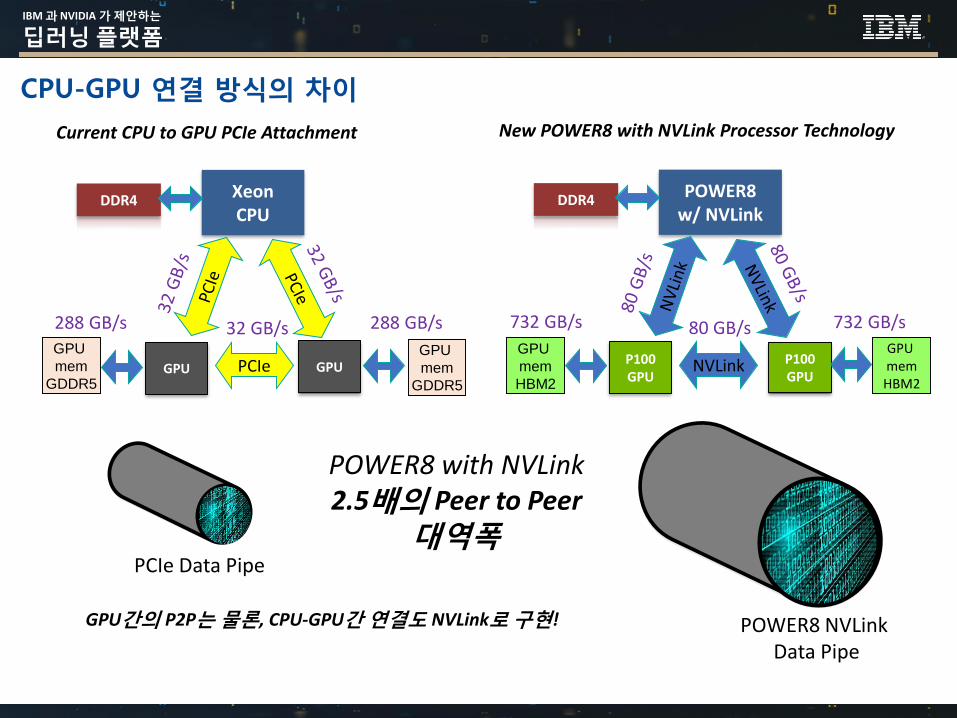
Current CPU to GPU PCIe Attachment
POWER8w/ NVLink
DDR4
P100GPU
NVLink
80 GB/s
New POWER8 with NVLink Processor Technology
GPU
mem
HBM2
GPU memHBM2
POWER8 with NVLink2.5배의 Peer to Peer
대역폭PCIe Data Pipe
POWER8 NVLinkData Pipe
GPU간의 P2P는 물론, CPU-GPU간 연결도 NVLink로 구현!
P100GPU
XeonCPU
DDR4
PCIe
32 GB/sGPU
mem
GDDR5
GPU
mem
GDDR5GPUGPU
288 GB/s 288 GB/s 732 GB/s 732 GB/s
CPU-GPU 연결 방식의 차이

IBM 과 NVIDIA 가 제안하는
딥러닝 플랫폼
PCIe3 vs. NVLink (GPUdb의 query 테스트 결과)
전체 소요 시간 감축 수치 : 62 tick (1 tick = 0.01 sec)Data Transfer에서의 감축 : 48 ticks 전체 감소치의 77% GPU 계산에서의 감축 : 14 ticks 전체 감소치의 23%
전체 2.6x speedup
K80 w/ PCIe on Broadwell
P100 w/ NVLink on Minsky
Query time : 100 ticks
Query time : 38 ticks
NVLink로 data copy 속도 3배 향상 (73 tick 25 tick)
IBM 과 NVIDIA 가 제안하는
딥러닝 플랫폼
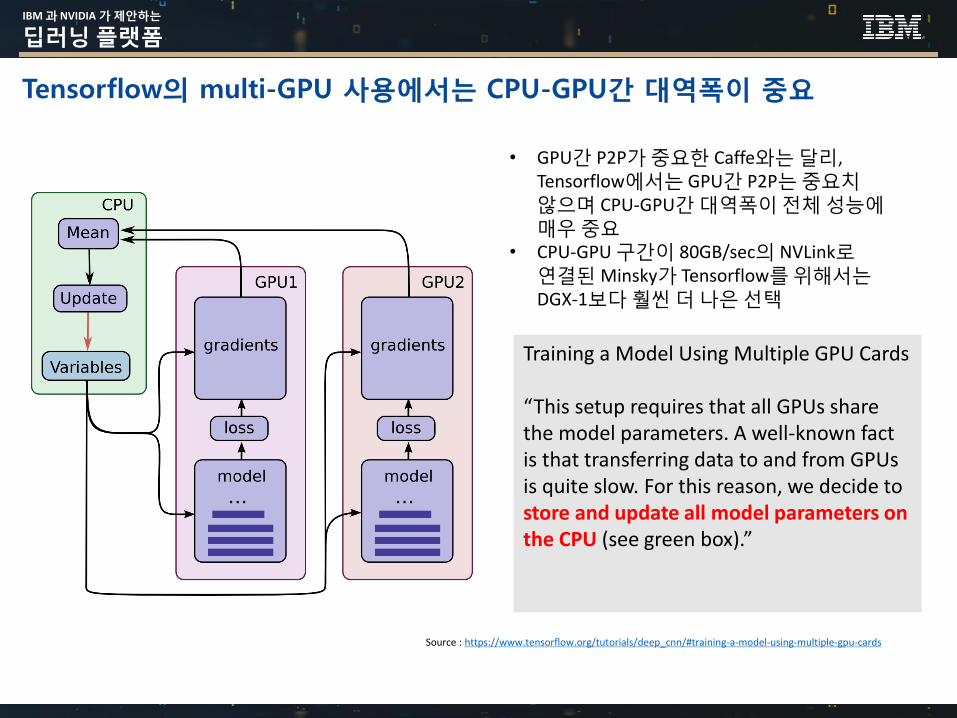
Tensorflow의 multi-GPU 사용에서는 CPU-GPU간 대역폭이 중요
Source : https://www.tensorflow.org/tutorials/deep_cnn/#training-a-model-using-multiple-gpu-cards
• GPU간 P2P가중요한 Caffe와는달리, Tensorflow에서는 GPU간 P2P는중요치않으며 CPU-GPU간대역폭이전체성능에매우중요
• CPU-GPU 구간이 80GB/sec의 NVLink로연결된Minsky가 Tensorflow를위해서는DGX-1보다훨씬더나은선택
Training a Model Using Multiple GPU Cards
“This setup requires that all GPUs share the model parameters. A well-known fact is that transferring data to and from GPUs is quite slow. For this reason, we decide to store and update all model parameters on the CPU (see green box).”

IBM 과 NVIDIA 가 제안하는
딥러닝 플랫폼
Tesla Products Tesla K40 Tesla K80 Tesla M40Tesla P100
(PCIe)Tesla P100 (NVLink)
GPU / Form FactorKepler
GK110 / PCIeKepler
GK210 / PCIeMaxwell
GM200 / PCIePascal
GP100 / PCIePascal
GP100 / SXM2
Stream Processors 2880 2 * 2496 3072 3584 3584
Base Clock 745 MHz 562 MHz 948 MHz 1126 MHz 1328 MHz
FP16 TFLOPs[1] 4.29 8.74 6.84 18.68 21.2
FP32 TFLOPs[1] 4.29 8.74 6.84 9.34 10.6
FP64 TFLOPs[1] 1.43 2.91 0.21 4.67 5.3
Memory Interface 384-bit GDDR5 384-bit GDDR5 384-bit GDDR5
3072-bit HBM2 (12GB)
4096-bit HBM2 (16GB)
4096-bit HBM2
Memory Bandwidth 288 GB/s 480 GB/s 288 GB/s549 GB/s (12GB)
732 GB/s (16GB)732 GB/s
Memory Size Up to 12 GB Up to 24 GB Up to 24 GB 12 GB or 16 GB 16 GB
L2 Cache Size 1536 KB 1536 KB 3072 KB 4096 KB 4096 KB
TDP 235 Watts 300 Watts 250 Watts 250 Watts 300 Watts
Manufacturing Process 28-nm 28-nm 28-nm 16-nm (FinFET) 16-nm (FinFET)
NVIDIA Tesla GPU 모델 비교
Source https://devblogs.nvidia.com/parallelforall/inside-pascal/http://www.anandtech.com/show/8729/nvidia-launches-tesla-k80-gk210-gpuhttp://www.anandtech.com/show/10222/nvidia-announces-tesla-p100-accelerator-pascal-power-for-hpc[1] The GFLOPS in this chart are based on GPU Boost Clocks.
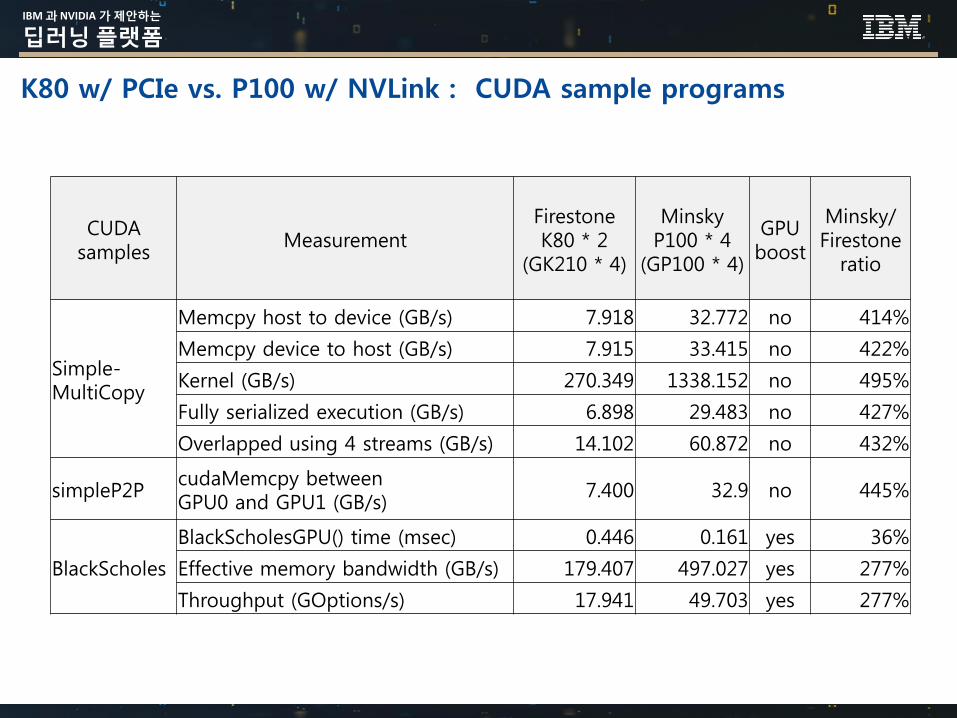
IBM 과 NVIDIA 가 제안하는
딥러닝 플랫폼
CUDA samples
MeasurementFirestoneK80 * 2
(GK210 * 4)
MinskyP100 * 4
(GP100 * 4)
GPU boost
Minsky/Firestone
ratio
Simple-MultiCopy
Memcpy host to device (GB/s) 7.918 32.772 no 414%
Memcpy device to host (GB/s) 7.915 33.415 no 422%
Kernel (GB/s) 270.349 1338.152 no 495%
Fully serialized execution (GB/s) 6.898 29.483 no 427%
Overlapped using 4 streams (GB/s) 14.102 60.872 no 432%
simpleP2PcudaMemcpy between GPU0 and GPU1 (GB/s)
7.400 32.9 no 445%
BlackScholes
BlackScholesGPU() time (msec) 0.446 0.161 yes 36%
Effective memory bandwidth (GB/s) 179.407 497.027 yes 277%
Throughput (GOptions/s) 17.941 49.703 yes 277%
K80 w/ PCIe vs. P100 w/ NVLink : CUDA sample programs

IBM 과 NVIDIA 가 제안하는
딥러닝 플랫폼
0
20
40
60
80
100
120
140
x86 with 4x M40 /PCIe
POWER8 with 4x TeslaP100 / NVLink
Training time (minutes): AlexNet and Caffe to top-1, 50% Accuracy
(Lower is better)
0:00
1:12
2:24
3:36
4:48
6:00
7:12
8:24
x86 with 8x M40 / PCIe POWER8 with 4x TeslaP100 / NVLink
BVLC Caffe vs IBM Caffe / VGGNetTime to Top-1 50% accuracy:
(Lower is better)
24% Faster2.2x Faster
IBM S822LC 20-cores 2.86GHz 512GB memory / 4 NVIDIA Tesla P100 GPUs / Ubuntu 16.04 / CUDA 8.0.44 / cuDNN 5.1 / IBM Caffe 1.0.0-rc3 / Imagenet Data
Intel Broadwell E5-2640v4 20-core 2.6 GHz 512GB memory / 8 NVIDIA TeslaM40 GPUs / Ubuntu 16.04 / CUDA 8.0.44 / cuDNN 5.1 / BVLC Caffe 1.0.0-rc3 / Imagenet Data
Deep Learning 성능 벤치마크 : Caffe Alexnet / VGGNet training

IBM 과 NVIDIA 가 제안하는
딥러닝 플랫폼
Source : https://developer.nvidia.com/cuda-release-candidate-download Source : http://openpowerfoundation.org/blogs/openpower-deep-learning-distribution/
POWER8의 주요 Deep Learning framework 지원 (PowerAI toolkit)
Caffe, Tensorflow, Theano, Torch 등 주요 프레임워크를 PPA repository로 제공
이들 framework은이미 ppc64le 지원을 github에 commit되어 source로부터의 build도지원

IBM 과 NVIDIA 가 제안하는
딥러닝 플랫폼
• IT업계 전반의 폭넓은 혁신 유도
• 현재의 데이타센타 기술의 문제점을 해결하는 보다 나은 대안을제시
• POWER 기술 관련 생태계 활성화
OpenPOWER Foundation 결성 목적
OpenPOWER Foundation 현황
• 2013년 IBM / Google / Mellanox / NVIDIA / TYAN 5개 회사로 시작
• 2016년 3월 현재 200개 이상으로 확대 및 강화
• 한국에서는 삼성전자 / SK Hynix 2개사가 메모리 분야에서 참여
OpenPOWER와의 협업으로 설계/생산된 새로운 POWER8
오픈 시스템을 위한 OpenPOWER Foundation
2016 4월, OpenPOWER플래티넘멤버인구글의 POWER 아키텍처서버개발과 SW 포팅에대한공개
POWER 아키텍처 자체의 공개를 통한, Google, IBM, Nvidia, Mellanox 등의 협업
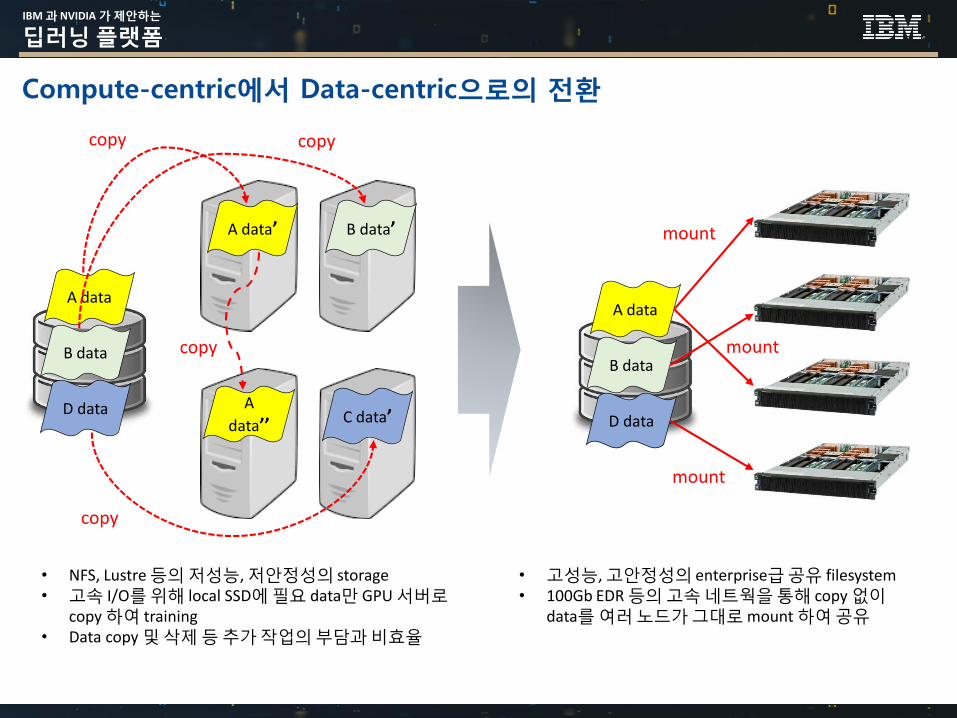
IBM 과 NVIDIA 가 제안하는
딥러닝 플랫폼
Compute-centric에서 Data-centric으로의 전환
A data
B data
D data
A data’ B data’
A
data’’ C data’
copy copy
copy
copy
A data
B data
D data
mount
mount
mount
• NFS, Lustre등의저성능, 저안정성의 storage• 고속 I/O를위해 local SSD에필요 data만 GPU 서버로
copy 하여 training• Data copy 및삭제등추가작업의부담과비효율
• 고성능, 고안정성의 enterprise급공유 filesystem • 100Gb EDR 등의고속네트웍을통해 copy 없이
data를여러노드가그대로mount 하여공유
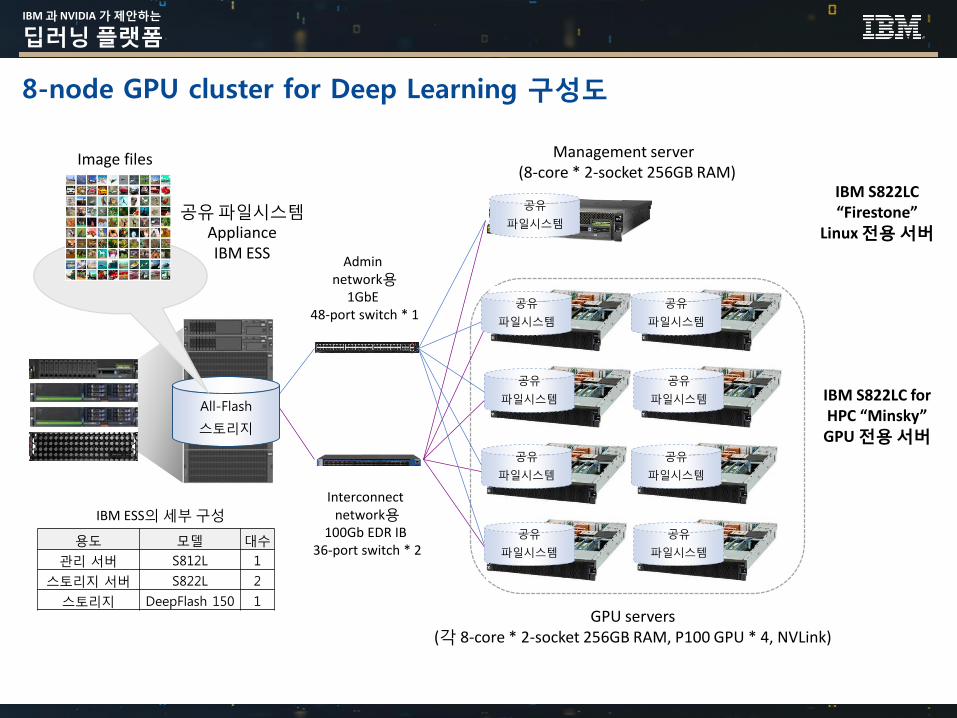
IBM 과 NVIDIA 가 제안하는
딥러닝 플랫폼
8-node GPU cluster for Deep Learning 구성도
Management server (8-core * 2-socket 256GB RAM)
GPU servers(각 8-core * 2-socket 256GB RAM, P100 GPU * 4, NVLink)
Admin network용
1GbE 48-port switch * 1
Interconnect network용
100Gb EDR IB 36-port switch * 2
공유파일시스템ApplianceIBM ESS
IBM S822LC “Firestone”
Linux 전용 서버
IBM S822LC for HPC “Minsky”GPU 전용 서버
용도 모델 대수
관리 서버 S812L 1
스토리지 서버 S822L 2
스토리지 DeepFlash 150 1
IBM ESS의세부구성
공유
파일시스템
공유
파일시스템
공유
파일시스템
공유
파일시스템
공유
파일시스템
공유
파일시스템
공유
파일시스템
공유
파일시스템
공유
파일시스템
Image files
All-Flash
스토리지
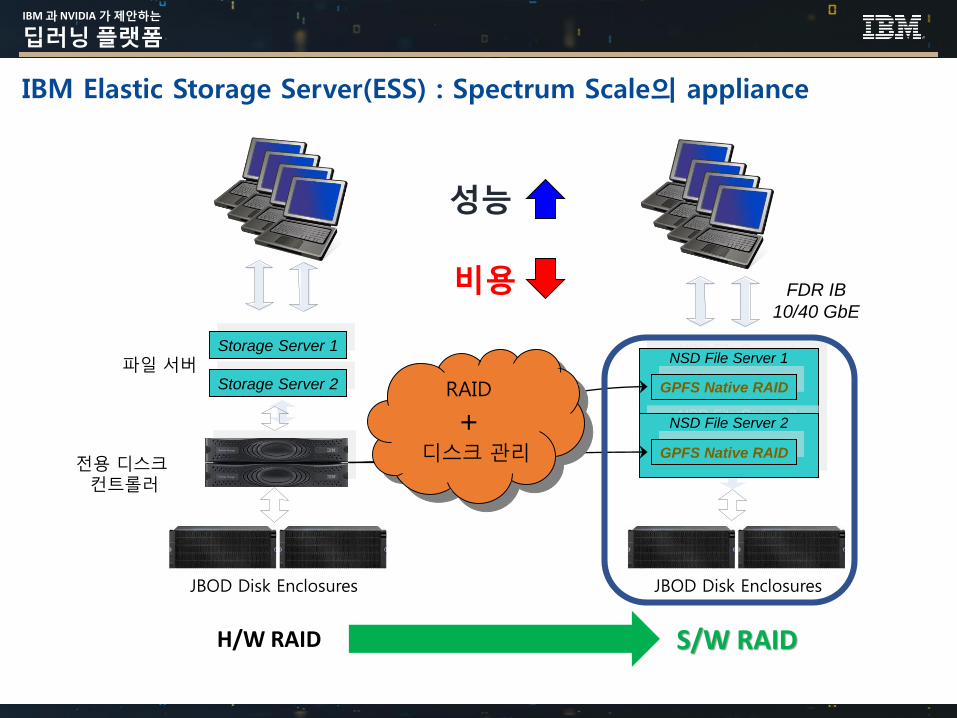
IBM 과 NVIDIA 가 제안하는
딥러닝 플랫폼
IBM Elastic Storage Server(ESS) : Spectrum Scale의 appliance
JBOD Disk Enclosures
NSD File Server 1
NSD File Server 2
FDR IB
10/40 GbE
전용 디스크컨트롤러
JBOD Disk Enclosures
Storage Server 1
Storage Server 2 GPFS Native RAID
GPFS Native RAID
파일 서버
RAID
+디스크 관리
성능
비용
H/W RAID S/W RAID

IBM 과 NVIDIA 가 제안하는
딥러닝 플랫폼
Docker를 통해 가능한 다양한 환경 제공
# Host 서버에서 NVCC v7.5를사용
root@minsky:/data# nvcc --versionnvcc: NVIDIA (R) Cuda compiler driverCopyright (c) 2005-2015 NVIDIA CorporationBuilt on Tue_Aug_11_14:31:50_CDT_2015Cuda compilation tools, release 7.5, V7.5.17
# 연구원 A가 CUDA 8.0의 over-subscription 사용을위해 nvcc v8.0을요구# 그러나다른연구원들은여전히 v7.5를필요해결책은 ?
root@minsky:/data# docker run --rm bsyu/nvcc:ppc64le-xenial nvcc --versionnvcc: NVIDIA (R) Cuda compiler driverCopyright (c) 2005-2016 NVIDIA CorporationBuilt on Sat_Sep__3_19:09:38_CDT_2016Cuda compilation tools, release 8.0, V8.0.44

IBM 과 NVIDIA 가 제안하는
딥러닝 플랫폼
Why nvidia-docker ?
root@minsky:/data/mydocker# docker run --rm bsyu/p2p:ppc64le-xenial[./simpleP2P] - Starting...Checking for multiple GPUs...CUDA error at simpleP2P.cu:63 code=30(cudaErrorUnknown) "cudaGetDeviceCount(&gpu_n)“…
root@minsky:/data/mydocker# nvidia-docker run --rm bsyu/p2p:ppc64le-xenial[./simpleP2P] - Starting...Checking for multiple GPUs...CUDA-capable device count: 4> GPU0 = "Tesla P100-SXM2-16GB" IS capable of Peer-to-Peer (P2P)> GPU1 = "Tesla P100-SXM2-16GB" IS capable of Peer-to-Peer (P2P)> GPU2 = "Tesla P100-SXM2-16GB" IS capable of Peer-to-Peer (P2P)> GPU3 = "Tesla P100-SXM2-16GB" IS capable of Peer-to-Peer (P2P)…cudaMemcpyPeer / cudaMemcpy between GPU0 and GPU1: 32.91GB/s
“nvidia-docker is essentially a wrapper around the docker command that
transparently provisions a container with the necessary components to execute code
on the GPU.”

IBM 과 NVIDIA 가 제안하는
딥러닝 플랫폼
POWER8 상에서의 nvidia-docker 지원
root@minsky:~# NV_GPU=0,1 nvidia-docker run --rm -v /nvme:/nvme bsyu/caffe:ppc64le-xenial ./caffe train -gpu all --solver=/nvme/solver.prototxt
Fri Feb 3 15:56:37 2017
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 361.107 Driver Version: 361.107 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|=============================================================================|
| 0 Tesla P100-SXM2... On | 0002:01:00.0 Off | 0 |
| N/A 51C P0 47W / 300W | 15927MiB / 16280MiB | 65% Default |
+-------------------------------+----------------------+----------------------+
| 1 Tesla P100-SXM2... On | 0003:01:00.0 Off | 0 |
| N/A 40C P0 46W / 300W | 15443MiB / 16280MiB | 44% Default |
+-------------------------------+----------------------+----------------------+
| 2 Tesla P100-SXM2... On | 0006:01:00.0 Off | 0 |
| N/A 39C P0 32W / 300W | 0MiB / 16280MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 3 Tesla P100-SXM2... On | 0007:01:00.0 Off | 0 |
| N/A 35C P0 30W / 300W | 0MiB / 16280MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| 0 129098 C ./caffe 15909MiB |
| 1 129098 C ./caffe 15425MiB |
+-----------------------------------------------------------------------------+
IBM 과 NVIDIA 가 제안하는
딥러닝 플랫폼
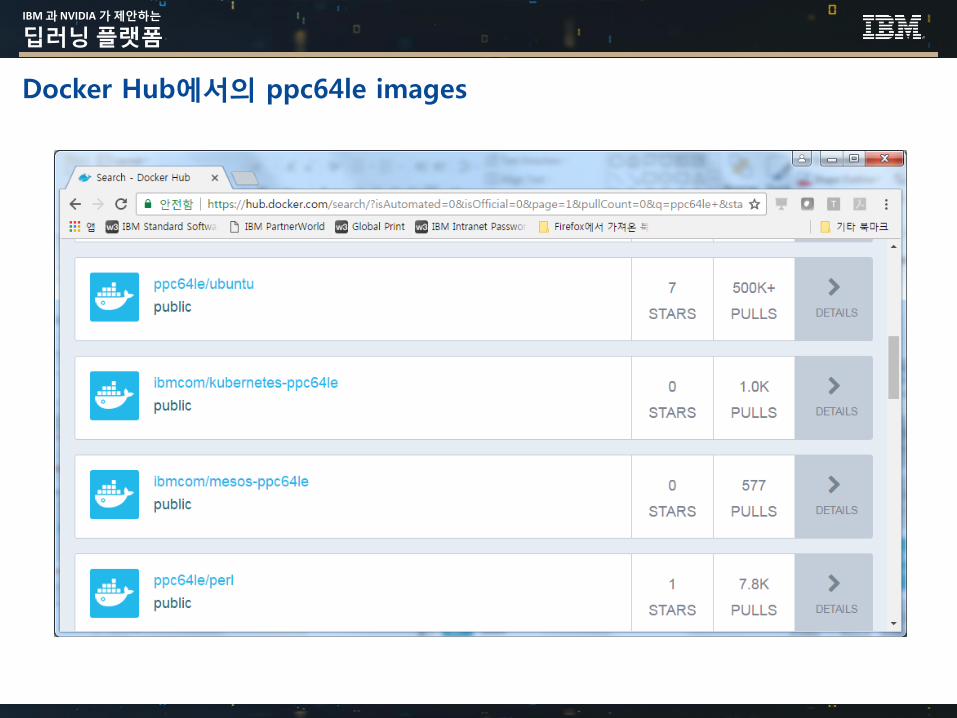
Docker Hub에서의 ppc64le images

Thank You감사합니다