prml上巻勉強会 at 東京大学 資料 第1章前半
TRANSCRIPT


ADGENDA
1
•はじめに
•1.1 多項式フィッティング
•1.2 確率論
•1.3 モデル選択

ADGENDA
2
•はじめに
•1.1 多項式フィッティング
•1.2 確率論
•1.3 モデル選択

はじめに
データに潜むパターンを見つけ出すと言う問題は根源的なものであり、その歴史は深い
• 天体観測を契機とする古典力学の誕生
• 原子スペクトルの規則性の発見を契機とする量子科学の誕生
パターン認識=計算機アルゴリズムを通して、データの規則性を発見すること
• 人間が規則性を決定する方法もある
• しかし、このアプローチはルール数の増大によってすぐに破綻する
3

• 機械学習のアプローチを採用すれば、はるかに良い結果が得られる
• N 個の手書き数字の大きな集合を使って、モデルのパラメータを適応的に調整
4

パターン認識の例
手書き文字認識
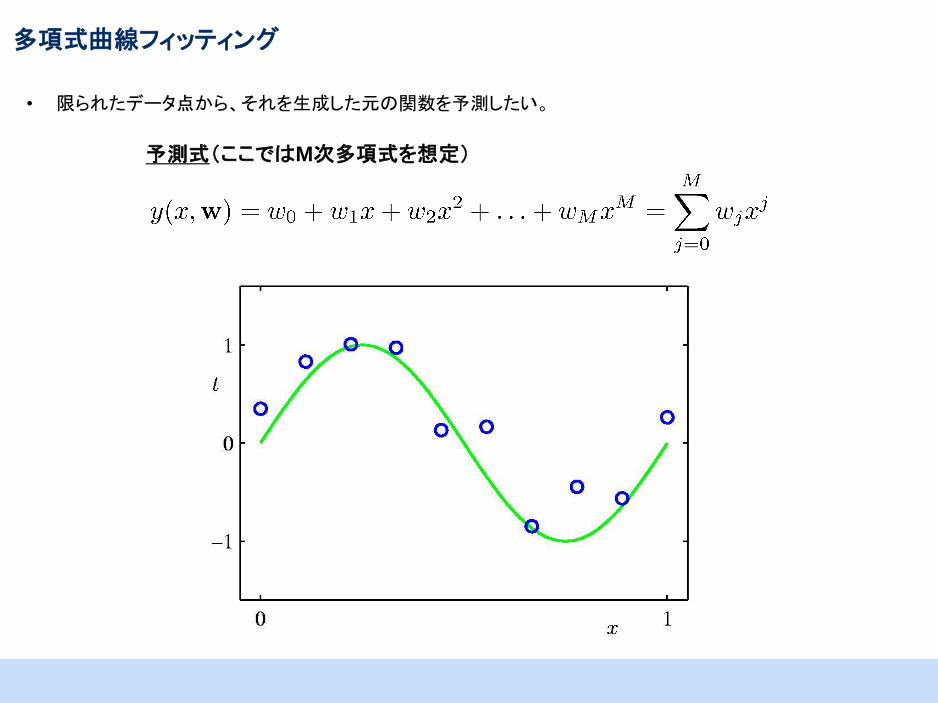
多項式曲線フィッティング
• 限られたデータ点から、それを生成した元の関数を予測したい。
予測式(ここではM次多項式を想定)

二乗和誤差関数
• データと予測関数の間の誤差を最小にする。

過学習
しかし、実際はそんなに単純じゃない。変数が増えると、予測関数はデータに含まれるノイズに強く影響される。
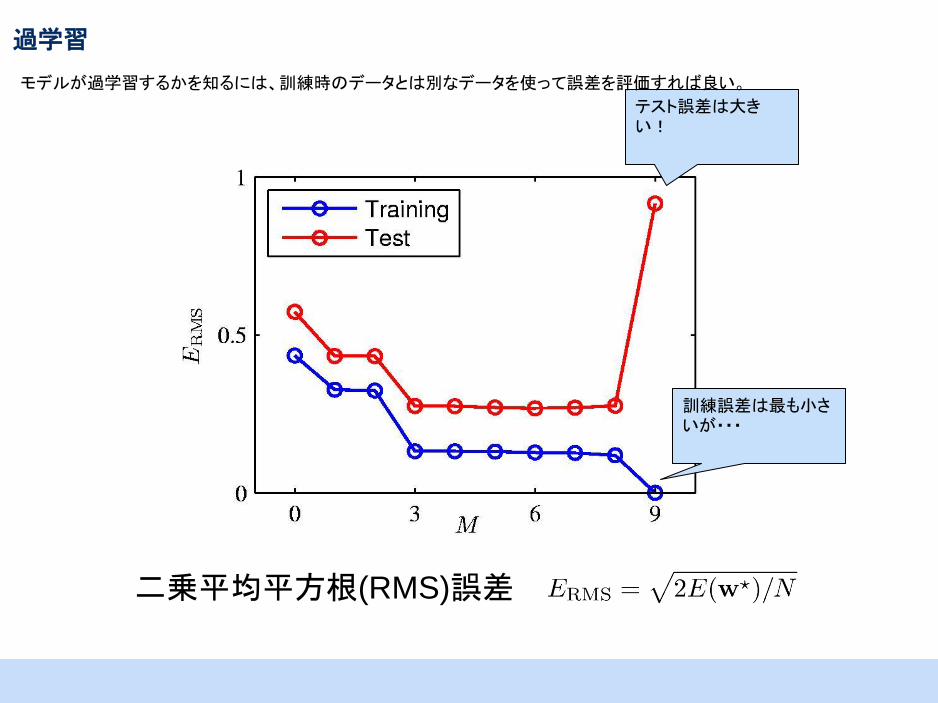
過学習
二乗平均平方根(RMS)誤差
テスト誤差は大きい!
訓練誤差は最も小さいが・・・
モデルが過学習するかを知るには、訓練時のデータとは別なデータを使って誤差を評価すれば良い。

過学習
予測関数の係数を見ると、過学習のケースでは値が大きくなっている。
過学習をすると係数は大きくなる。
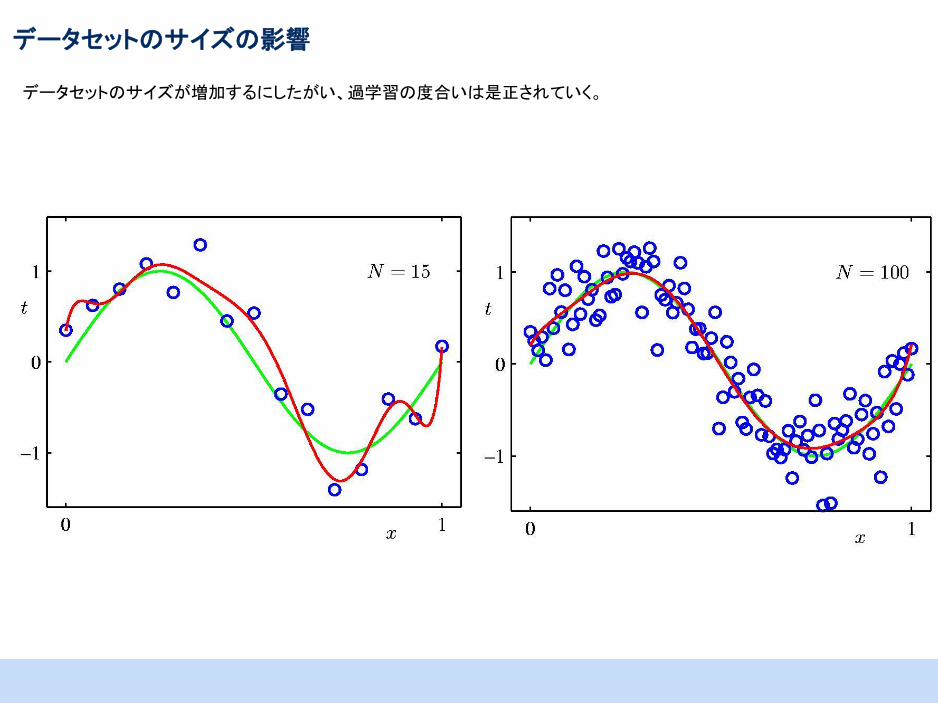
データセットのサイズの影響
データセットのサイズが増加するにしたがい、過学習の度合いは是正されていく。

正規化: 過学習を防ぐ方法
大きな係数値にペナルティを与える

正規化係数
• 正規化係数を大きくしすぎると、真値へのフィット具合も抑制される

正規化係数 vs
• 全ページでの事例を、RMS誤差を使って定量的に議論
テスト誤差を最小化する正規化係数
正規化係数が小さすぎると、過学習

多項式の係数
• 正規化係数が大きすぎると、係数が小さくなりすぎる

ADGENDA
16
•はじめに
•1.1 多項式フィッティング
•1.2 確率論
•1.3 モデル選択

確率論
りんご
オレンジ
赤い箱
青い箱
40% 60%
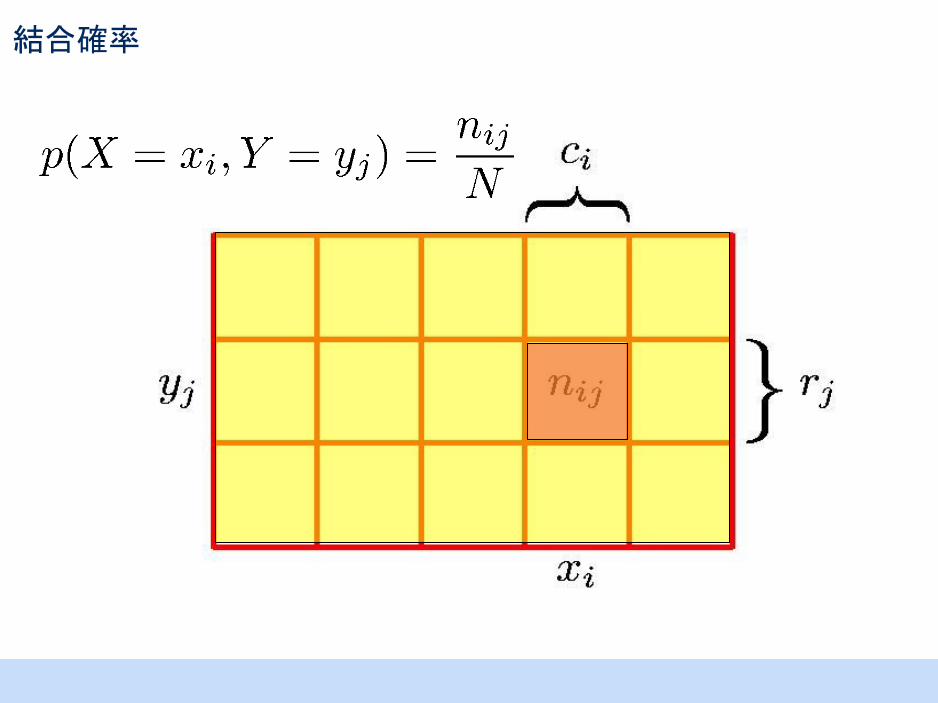
結合確率
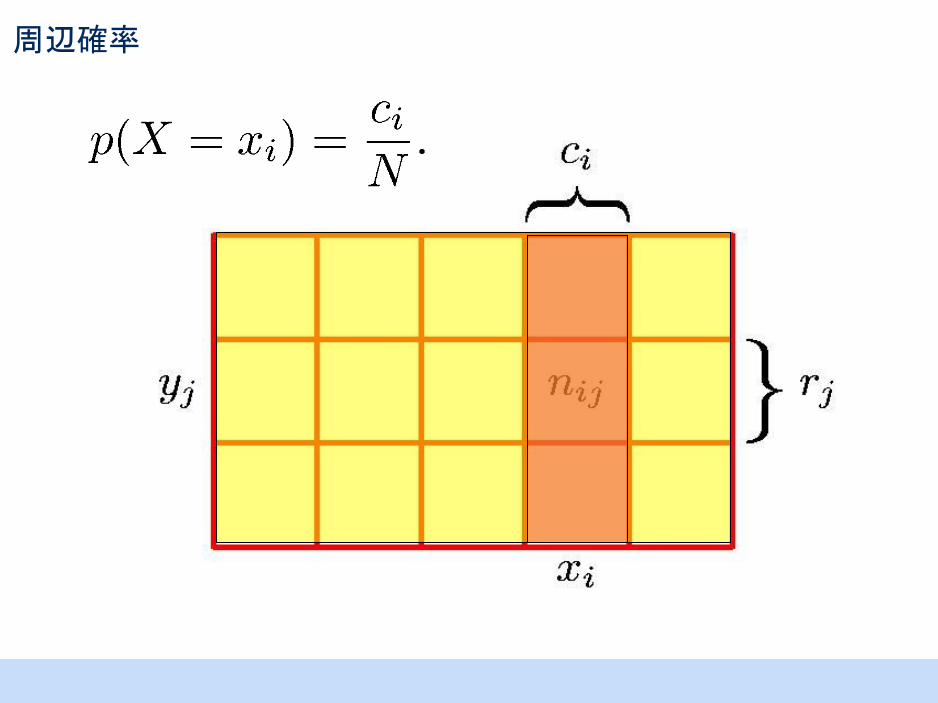
周辺確率
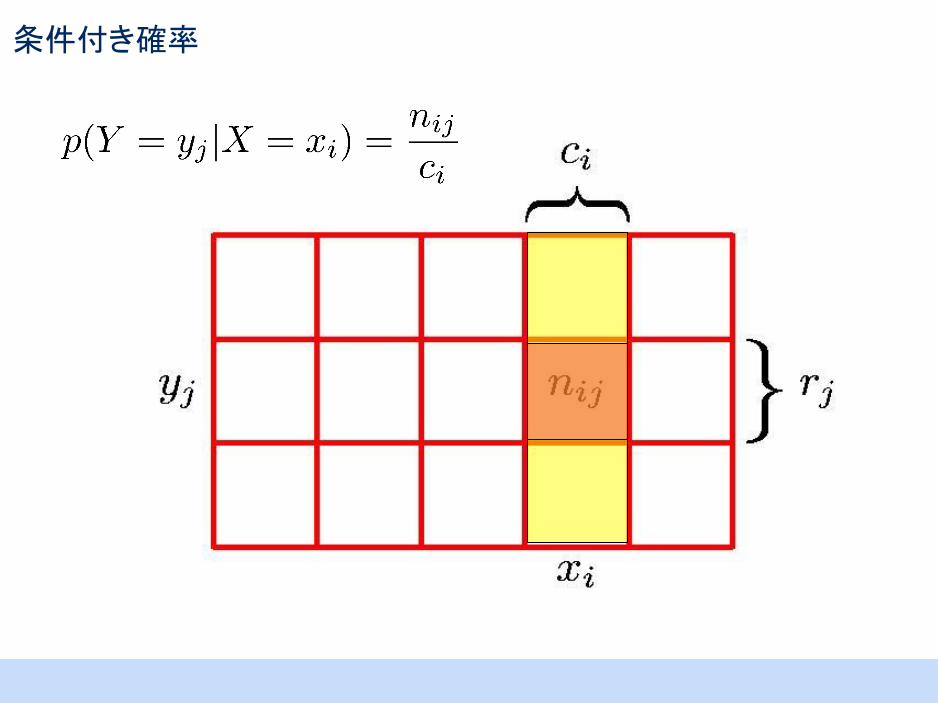
条件付き確率
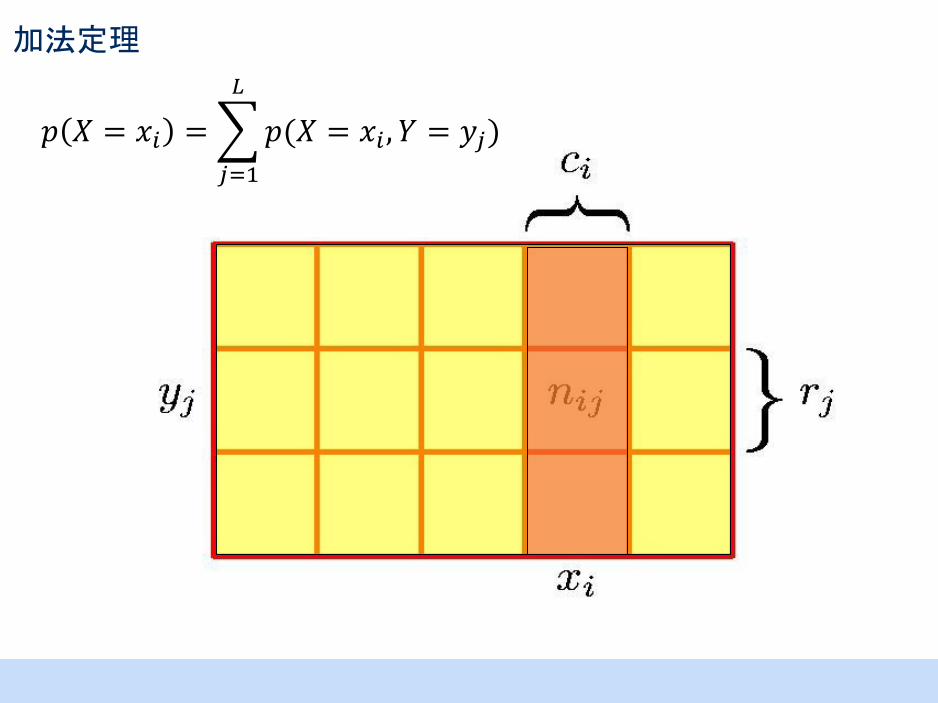
加法定理
𝑝 𝑋 = 𝑥𝑖 = 𝑝(𝑋 = 𝑥𝑖 , 𝑌 = 𝑦𝑗)
𝐿
𝑗=1
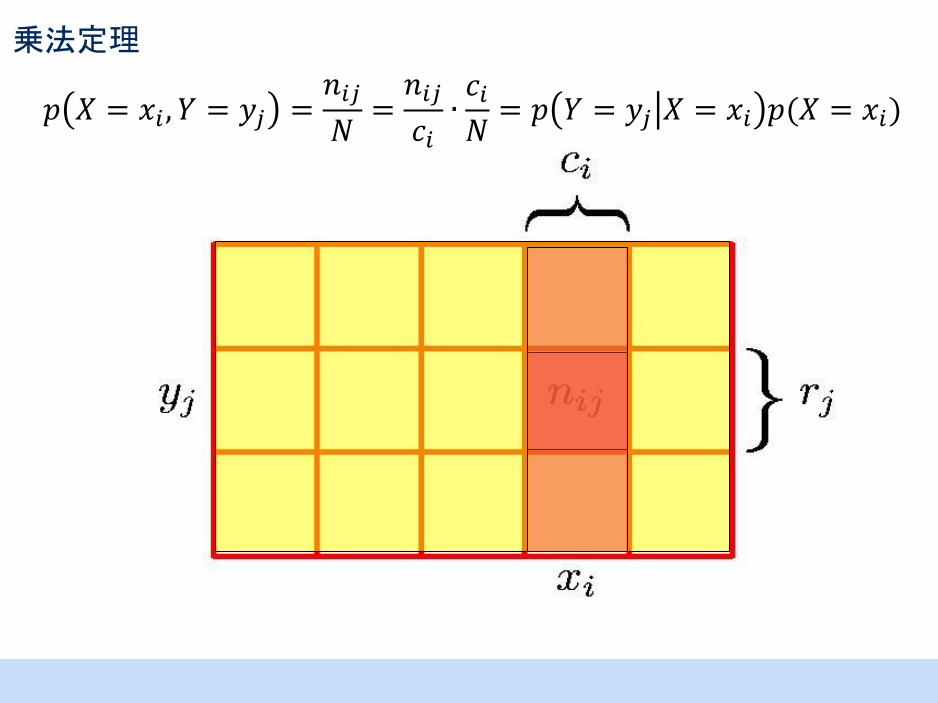
乗法定理
𝑝 𝑋 = 𝑥𝑖 , 𝑌 = 𝑦𝑗 =𝑛𝑖𝑗𝑁=𝑛𝑖𝑗𝑐𝑖∙𝑐𝑖𝑁= 𝑝 𝑌 = 𝑦𝑗 𝑋 = 𝑥𝑖 𝑝(𝑋 = 𝑥𝑖)

確率の基本法則
加法定理
乗法定理

ベイズの定理
事後確率 尤度 × 事前確率
事後確率
尤度 事前確率
正規化係数
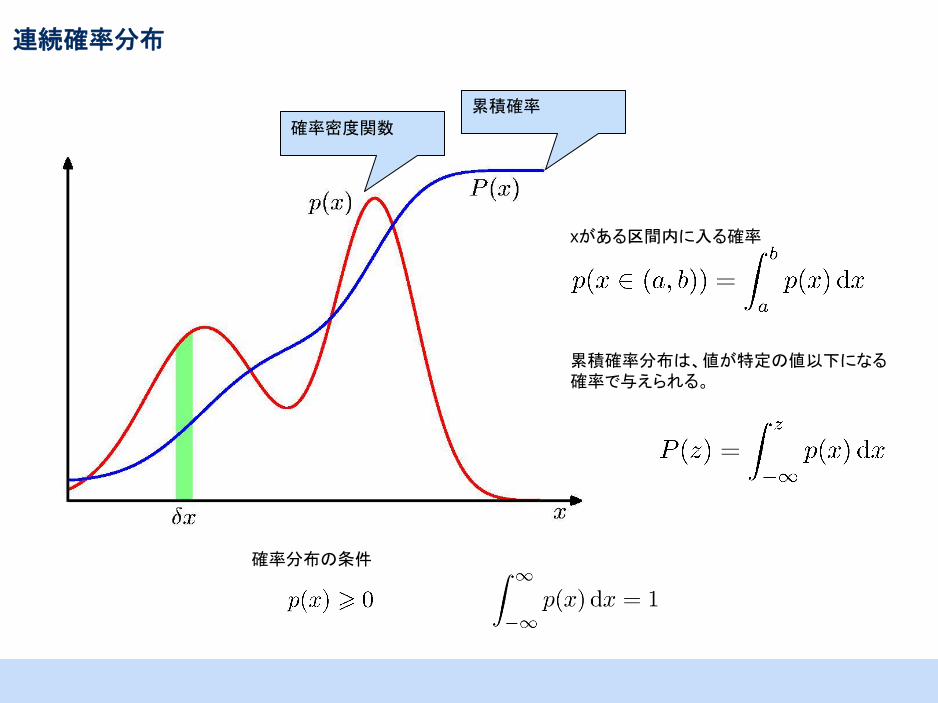
連続確率分布
確率密度関数
累積確率
確率分布の条件
累積確率分布は、値が特定の値以下になる
確率で与えられる。
xがある区間内に入る確率

分布の変換
変換関数
ヤコビアン

期待値
条件付き確率(離散)
近似期待値(離散、連続)
関数の期待値(離散) 関数の期待値(連続)

分散、共分散
分散(期待値からのずれの期待値)
共分散(一変量)
共分散(多変量)
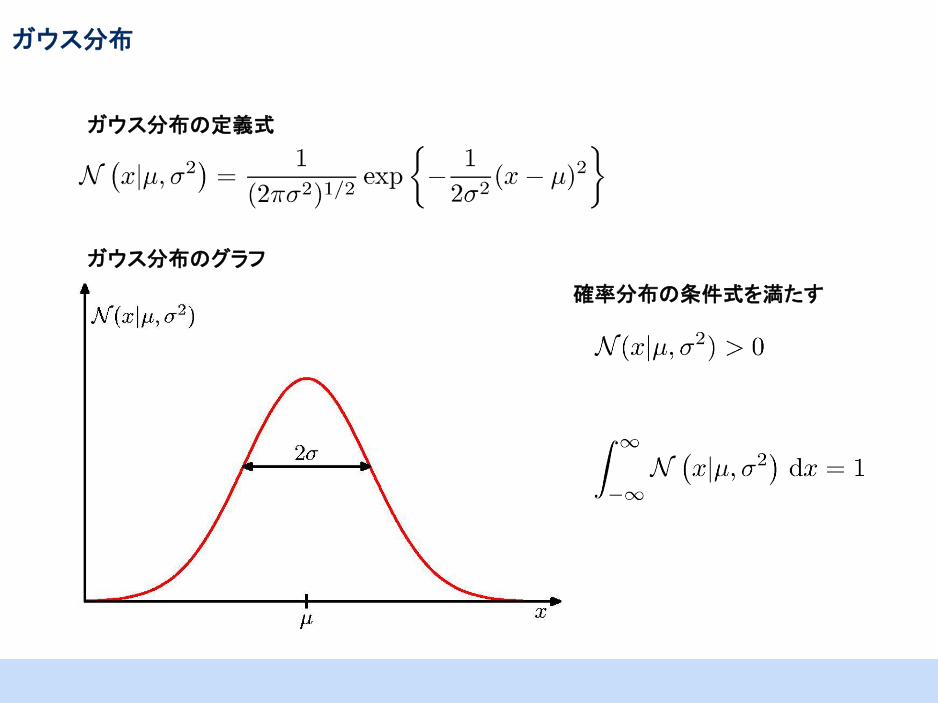
ガウス分布
ガウス分布の定義式
ガウス分布のグラフ
確率分布の条件式を満たす

ガウス分布の平均、分散
ガウス分布の期待値
ガウス分布の二次モーメント(二乗の期待値)
ガウス分布の分散

多変量ガウス分布
多変量ガウス分布の定義式
多変量ガウス分布の等高線

ガウス分布のパラメータ推定
尤度関数
• ある点列から、ガウス分布がどの分布から生成されたものなのかを推定する

最尤推定
• 対数尤度を最小化するようなパラメータμ、σを求める→最尤推定(ML)
平均の最尤推定値 分散の最尤推定値
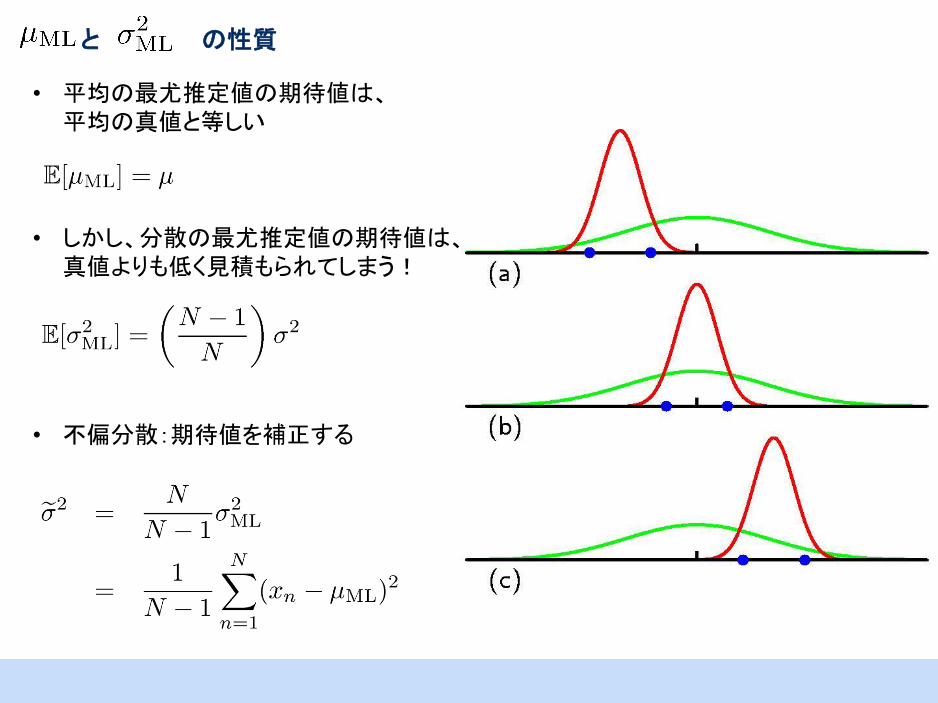
と の性質
• 平均の最尤推定値の期待値は、
平均の真値と等しい
• しかし、分散の最尤推定値の期待値は、
真値よりも低く見積もられてしまう!
• 不偏分散:期待値を補正する
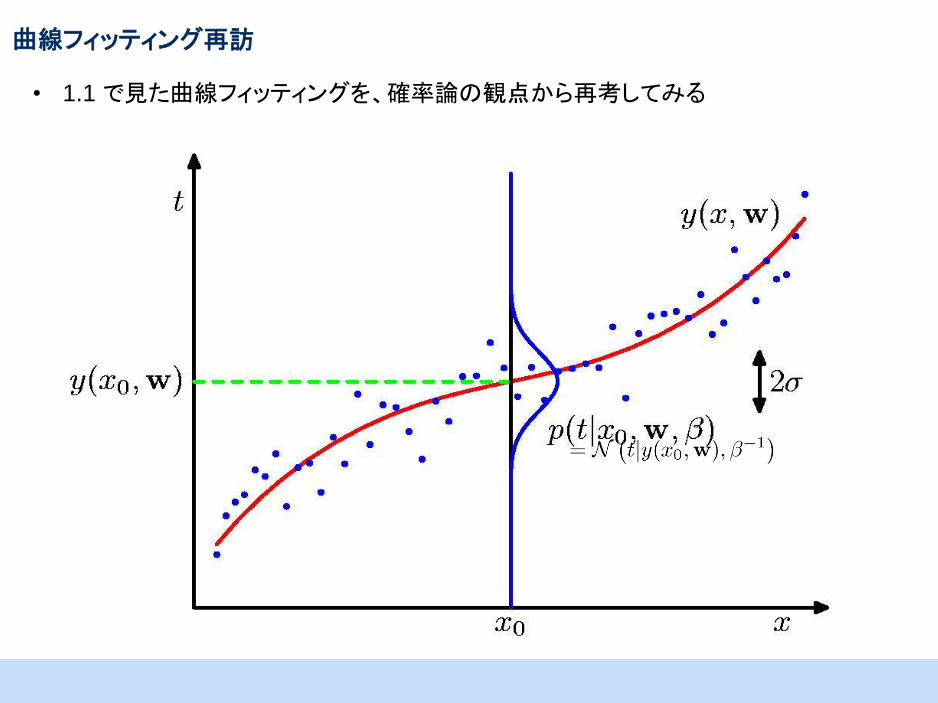
曲線フィッティング再訪
• 1.1 で見た曲線フィッティングを、確率論の観点から再考してみる

最尤推定
二乗和誤差 を最小化することで、 を決定する
• 尤度関数
• 対数尤度
• 分散の推定

予測分布

MAP推定:ベイズへの道
Determine by minimizing regularized sum-of-squares error, .
• 事前分布
• 正規化最小二乗誤差
• 予測誤差

ベイズ曲線フィッティング
• 新たな点xに関する目標値tを、p(t|x,w)をwに対して周辺化することによって求める。
• 予測平均 • 予測分散
• 分散行列 • 基底
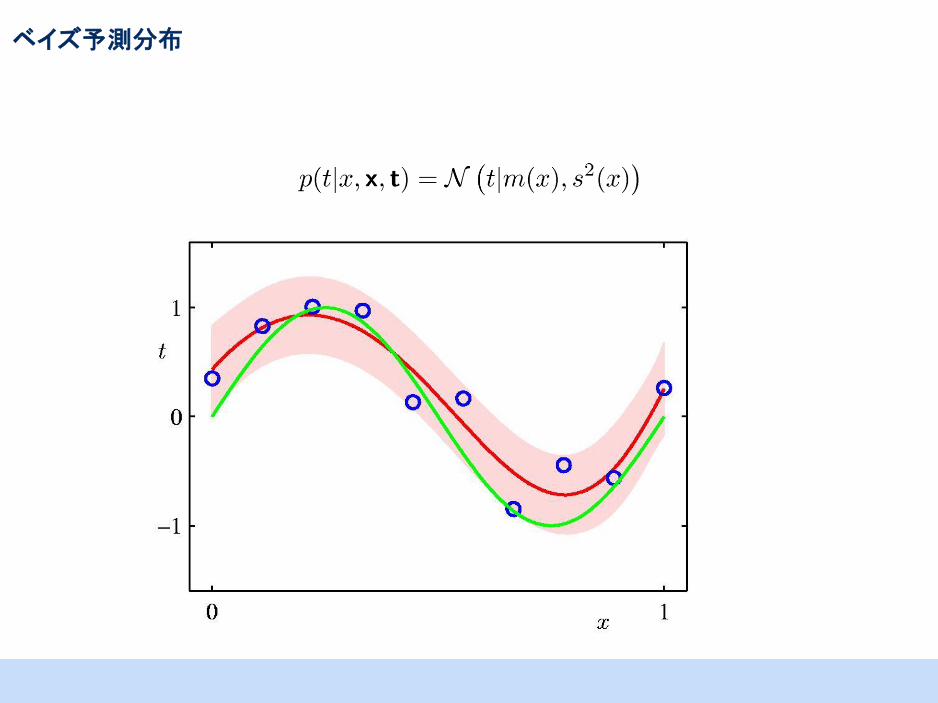
ベイズ予測分布

ADGENDA
41
•はじめに
•1.1 多項式フィッティング
•1.2 確率論
•1.3 モデル選択

モデル選択
• これまで、正規化係数や次元数など、モデルの超パラメータを調整する方法については説明してこなかった
• 実際には、下図に示す交差検定をすることで求める
訓練データ
検定データ