web usage mining: discovery and applications of usage patterns from web data...
Post on 19-Dec-2015
222 views
TRANSCRIPT

Web Usage Mining: Discovery and Applications of UsagePatterns from Web Data
指導教授:黃三益老師 第二組:洪瑞麟 m964020015 蔡育洲 m964020034 陳怡綾 m964020041
SIGKDD Explorations. Copyrightc 2000 ACM SIGKDD, Jan 2000

Outline
Introduction Problem statement Detailed data mining Conclusions and critics

Introduction
Web mining: Data mining efforts associated with the Web content, usage, and structure
To discover usage patterns from Web data, in order to understand and better serve the needs of Web-based applications.

Classes
Web Content Mining: mining the data on the Web (text, image, audio, video, metadata and hyperlinks)
Web Structure Mining: mining the Web structure data
Web Usage Mining: mining the Web log data (preprocessing, pattern discovery, and pattern analysis )

Data type Content: The real data in the Web pages
(text and graphics) Structure: describes the organization of
the content. (as a tree structure) Usage: describes the pattern of usage of
Web pages (IP addresses, page references, and the date and time of accesses.)
User Profile: provides demographic information about users of the Web site. (registration data and customer profile information)

Data source (Web traffic )
Server Level Collection log files, Packet sniffing, Cookies, Query
data and CGI script Client Level Collection
Javascript, Java applet, and the modified browser
Proxy Level Collection Proxy caching

Data abstractions
user a single individual that is accessing file from one or
more Web servers through a browser page view
consists of every file that contributes to the display on a user's browser at one time
click-stream a sequential series of page view requests
user session the click-stream of page views for a singe user
across the entire Web server session (visit)
The set of page-views in a user session for a particular Web site
episode Any semantically meaningful subset of a user or
server session

Web usage mining phases

Preprocessing
Usage Preprocessing Content Preprocessing Structure Preprocessing

Preprocessing
Usage Preprocessing 資料處理最為複雜 可能會遭遇的問題
單一 IP 位置,多個 Server Session 使用者可能透過 Proxy 來進行連結。
多個 IP 位置,單一 Server Session 一些 ISP 會在不同的 Session 間,隨機指定 IP 位置。
多個 IP 位置,單一 User 使用者可能透過多台機器進行連結。
多個 Agent ,單一 User 使用者使用一個以上的瀏覽器來進行瀏覽。即使在同一
台機器上,其也會被視為不同的使用者。

Preprocessing
Content Preprocessing 將文字、圖像、 script 、或是多媒體形式的
檔案轉換為網頁使用探勘流程有用的格式 通常這個過程也執行分類( classification )
或分群( clustering )等類型的內容探勘

Preprocessing
Structure Preprocessing 網站的結構是由 page view 的超連結所建立 結構可由類似網站內容的處理方法來取得 動態的內容會造成比靜態 page view 更多的
問題

Pattern Discovery
Statistical Analysis Association Rules Clustering Classification Sequential Patterns Dependency Modeling

Statistical Analysis
最常使用到的方法 透過 session file 的分析,即可在
page view 、瀏覽的路徑長度或時間等特性上,進行頻率、平均值、中位數等不同的描述統計分析

Association Rules
可用來分析一個 server session 中,有哪些網頁是具有存取的關聯性
協助網頁設計者去重新架構網站,以增加相關網頁的連結

Clustering
將一群有相關特性的項目群組起來 usage cluster
將有類似瀏覽行為的使用者群組起來 運用人口統計上的特性,進行電子商務應用的
市場區隔 提供個人化的網頁
page cluster 找尋擁有相關內容的網頁群集 適合網際網路搜尋引擎的使用

Classification
將資料項目對應到一些已事先定義的類別 將使用者的使用紀錄歸類於一個或特定的
類別或分類 i.e. 在 /Procduct/Music 下單的客戶中,
有 30% 的人是屬於 18-25 歲的族群,且居住在西岸

Sequential Patterns
找尋 session 間的模型,某些項目出現後的一段時間之後,會有哪些的行動出現
預測客戶未來再度瀏覽的行為 針對特定的使用者族群作適當的廣告策略

Dependency Modeling
發展一模式,代表 Web domain 中各個變數之間的重要關係
如建立一個模式以代表在不同階段,一個瀏覽者所會執行的不同動作
可以提供分析使用者行為的理論架構 預測未來網站資源的消耗

Pattern Analysis
整體活動的最後一個階段 篩選在上述階段所產生的規則,將沒有意
義的規則過濾 SQL 、 OLAP 、視覺化工具

資料來源 國內某健康檢查中心 2002 年 9 月 ~10
月顧客上網資料 log 檔 IP 瀏覽的網頁代碼 瀏覽網頁的時間、進入與離開網站的時間
會員基本資料 編號、性別、地區 年齡、加入會員的日期

資料描述

系統架構

關聯法則 將路過 ( 太短 ) 及無
效 ( 太長 ) 的資料刪除
累加瀏覽時間 平均停留時間秒
54>37 秒(Nielsen/NetRatings)

關聯法則 -based on Apriori
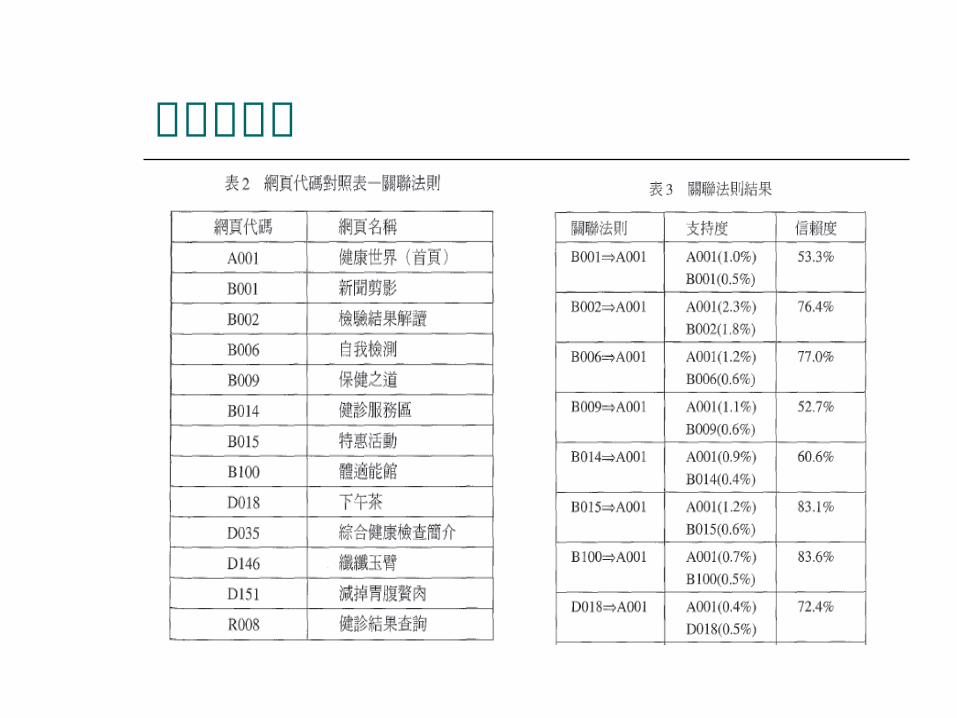
結果與分析

結果與分析 (A001,R008)B002 所代表的意義是在瀏覽首頁
(A001) 及登錄健檢結果查詢的網頁 (R008) 之狀況下也會瀏覽檢驗結果解讀的網頁 (B002) ,此結果與一般我們上網查詢健檢結果的狀況相符。可以將三個網頁擺在一起或是建立超連結,以改善網頁設計架構。
支持度可以看出網頁被瀏覽時受歡迎的程度,可提供醫療業者推出健檢項目搭配促銷的決策參考。
當醫療業者欲推出某網頁廣告的資訊時,可以參考信賴度。

決策樹
將一個網頁當成一個屬性,有瀏覽此網頁,則屬性值為 1 ,反之為 0
輸入參數 Maximum levels 與 Minimum support 以產生決策樹來將顧客分類

結果與分析 對會員基本資料及網站 log
檔進行探勘 年齡、性別、地區、網頁代
碼等屬性來建構決策樹,以進行顧客的分類
給予不同的廣告行銷策略及瀏覽之環境

結果與分析
性別為女、年齡大於 35 歲,瀏覽骨質疏鬆相關網頁的機率較高。當業者推出骨質疏鬆健檢活動時,顧客的屬性符合性別為女、年齡大於 35 歲之條件,可自動彈出該項健檢活動優惠專案

結果與分析 在關聯法則的實驗結
果,發現瀏覽網頁D018( 下午茶 ) 的狀況下也會瀏覽網頁D035( 綜合健康檢查簡介 )

結果與分析 結果發現,會瀏覽檢
驗結果解讀 (B002)網頁及血脂肪(D479) 網頁而不瀏覽肝臟保健 (D306)網頁之顧客,是屬於會瀏覽肝功能(D221) 網頁的族群

Conclusions
電子化交易的日漸普及,不僅是商業交易的資料,網站的日誌紀錄也是同樣的與日俱增
資料探勘領域也有大幅的成長 個人化網站的建立,以及適形化的服務也將成為未
來的趨勢 透過 Web Mining 技術的使用,則可以對現行的
資料進行深入的挖掘,從找出的規則中,去進行改變,以創造優勢