機械学習(machine learning) - isem.co.jp · 1 機械学習(machine learning) 宮西洋太郎...
TRANSCRIPT

1
機械学習(Machine Learning)
宮西洋太郎
2015年4月23日
近未来研究会(第1回)
於 機械振興会館

2
機械学習(Machine Learning)とは http://ja.wikipedia.org/wiki/%E6%A9%9F%E6%A2%B0%E5%AD%A6
%E7%BF%92
• 人工知能(Artificial Intelligence)研究テーマの1つhttp://ja.wikipedia.org/wiki/%E4%BA%BA%E5%B7%A5%E7%9F%A5%E8%83%BD
• 人間のもつ学習能力と同様の機能をコンピュータで実現しようとする技術・手法
• 1959年、アーサー・サミュエル
「明示的にプログラムしなくても学習する能力をコンピュータに与える研究分野」
• トム・M・ミッチェル
「コンピュータプログラムがある種のタスクTと評価尺度P
において経験Eから学習するとは、タスクTにおけるその性能をPによって評価した際に、経験Eによってそれが改善されている場合である」

3
機械学習(Machine Learning)とは http://ja.wikipedia.org/wiki/%E6%A9%9F%E6%A2%B0%E5%AD%A6
%E7%BF%92
• トム・M・ミッチェル
「コンピュータプログラム(マシン)がある種のタスクTと評価尺度Pにおいて経験Eから学習するとは、タスクTにおけるその性能をPによって評価した際に、経験Eによってそれが改善されている場合である」
経験E マシン マシン
タスク付与
タスクT タスクT
タスク付与 タスク達成
評価尺度P1
タスク達成
評価尺度P2
評価尺度P2 評価尺度P1 <
学習過程
学習効果
時間軸
評価尺度が改善されている
4
一般化(Generalization) http://ja.wikipedia.org/wiki/%E6%A9%9F%E6%A2%B0%E5%AD%A6
%E7%BF%92
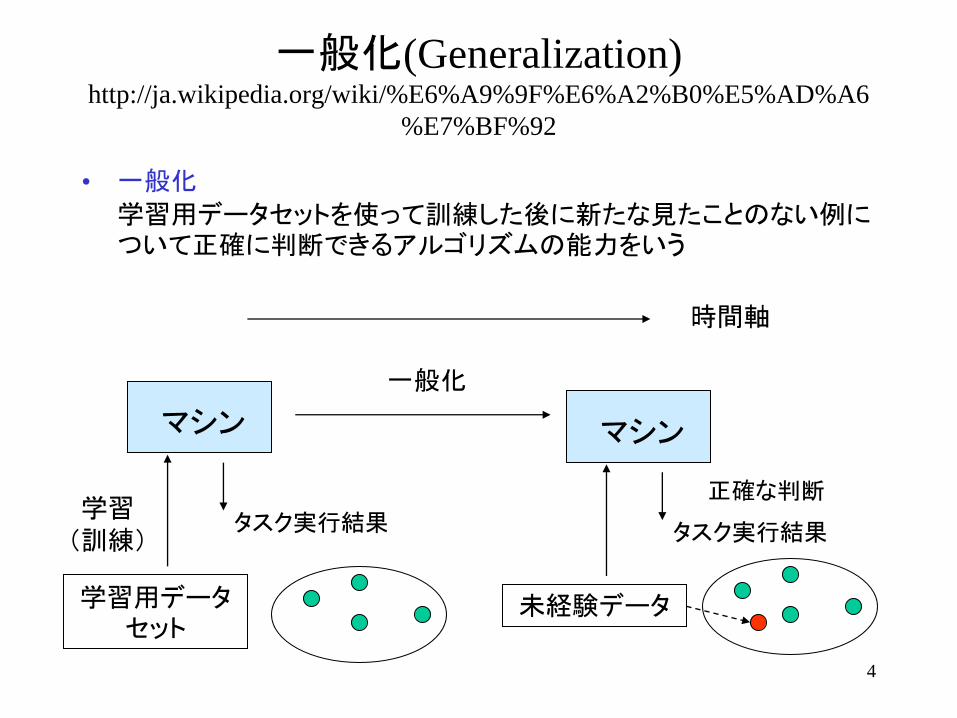
• 一般化
学習用データセットを使って訓練した後に新たな見たことのない例について正確に判断できるアルゴリズムの能力をいう
マシン
学習
(訓練)
学習用データセット
一般化
時間軸
タスク実行結果
マシン
未経験データ
タスク実行結果
正確な判断
5
データマイニング(Data Mining)との関係http://ja.wikipedia.org/wiki/%E6%A9%9F%E6%A2%B0%E5%AD%A6%E7%
BF%92
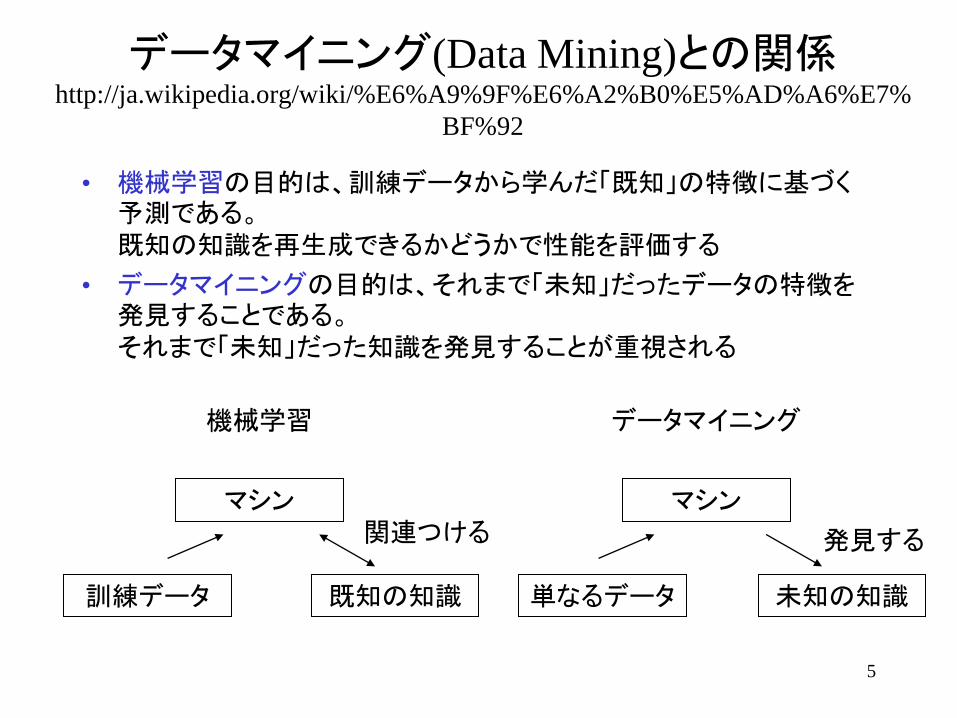
• 機械学習の目的は、訓練データから学んだ「既知」の特徴に基づく予測である。
既知の知識を再生成できるかどうかで性能を評価する
• データマイニングの目的は、それまで「未知」だったデータの特徴を発見することである。
それまで「未知」だった知識を発見することが重視される
機械学習
マシン
訓練データ 既知の知識
関連つける
データマイニング
マシン
単なるデータ 未知の知識
発見する

6
アルゴリズムの分類http://ja.wikipedia.org/wiki/%E6%A9%9F%E6%A2%B0%E5%AD%A6%E7%
BF%92
• 教師あり学習(昔は、教師つき学習ともいったが)
• 入力とそれに対応すべき出力(人間の専門家が訓練例にラベル付けすることで提供されることが多いのでラベルとも呼ばれる)を写像する関数を生成する。例えば、統計分類問題では入力ベクトルと出力に対応する分類で示される例を与えられ、それらを写像する関数を近似的に求める。
A(クラス)
B
Aですよ Aですよ
Bですよ Bですよ
教師あり学習の訓練
訓練終了
実践
A
B
さあ、自分でやってみなさい
これはBです
訓練の結果
分類(Classification)、分類器(Classifier)の例

7
アルゴリズムの分類http://ja.wikipedia.org/wiki/%E6%A9%9F%E6%A2%B0%E5%AD%A6%E7%
BF%92
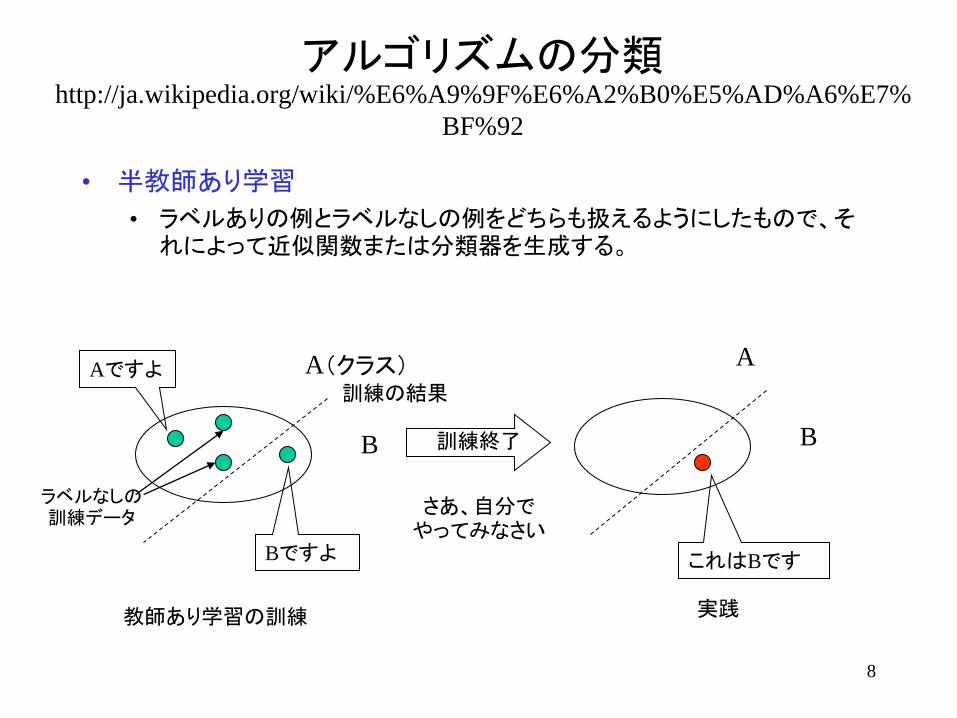
• 教師なし学習
• 入力のみ(ラベルなしの例)からモデルを構築する。データマイニングとも共通する。
A
B
教師なし学習の訓練
訓練終了もあいまい
実践
A
B
最初から、自分でやってみなさい
これはBです
日々、自分で訓練
訓練データにラベルなし(教師なし)
最初は、少し様子をみて、自分なりに分類方法を考える
8
アルゴリズムの分類http://ja.wikipedia.org/wiki/%E6%A9%9F%E6%A2%B0%E5%AD%A6%E7%
BF%92
• 半教師あり学習
• ラベルありの例とラベルなしの例をどちらも扱えるようにしたもので、それによって近似関数または分類器を生成する。
A(クラス)
B
Aですよ
Bですよ
教師あり学習の訓練
訓練終了
実践
A
B
さあ、自分でやってみなさい
これはBです
訓練の結果
ラベルなしの訓練データ
9
アルゴリズムの分類http://ja.wikipedia.org/wiki/%E6%A9%9F%E6%A2%B0%E5%AD%A6%E7%
BF%92
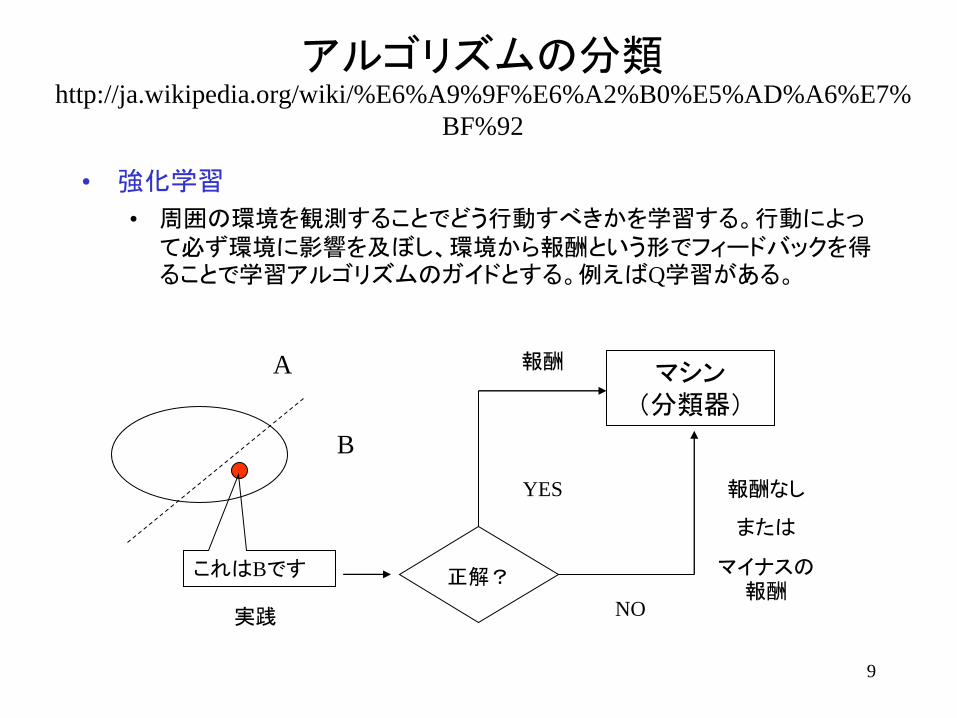
• 強化学習
• 周囲の環境を観測することでどう行動すべきかを学習する。行動によって必ず環境に影響を及ぼし、環境から報酬という形でフィードバックを得ることで学習アルゴリズムのガイドとする。例えばQ学習がある。
実践
A
B
これはBです
マシン
(分類器)
正解?
YES
NO
報酬
報酬なし
または
マイナスの報酬

10
アルゴリズムの分類http://ja.wikipedia.org/wiki/%E6%A9%9F%E6%A2%B0%E5%AD%A6%E7%
BF%92
• トランスダクション(トランスダクティブ推論)
• 観測された具体的な(訓練)例から具体的かつ固定の(テスト)例の新たな出力を予測しようとする。
• マルチタスク学習
• 関連する複数の問題について同時に学習させ、主要な問題の予測精度を向上させる。
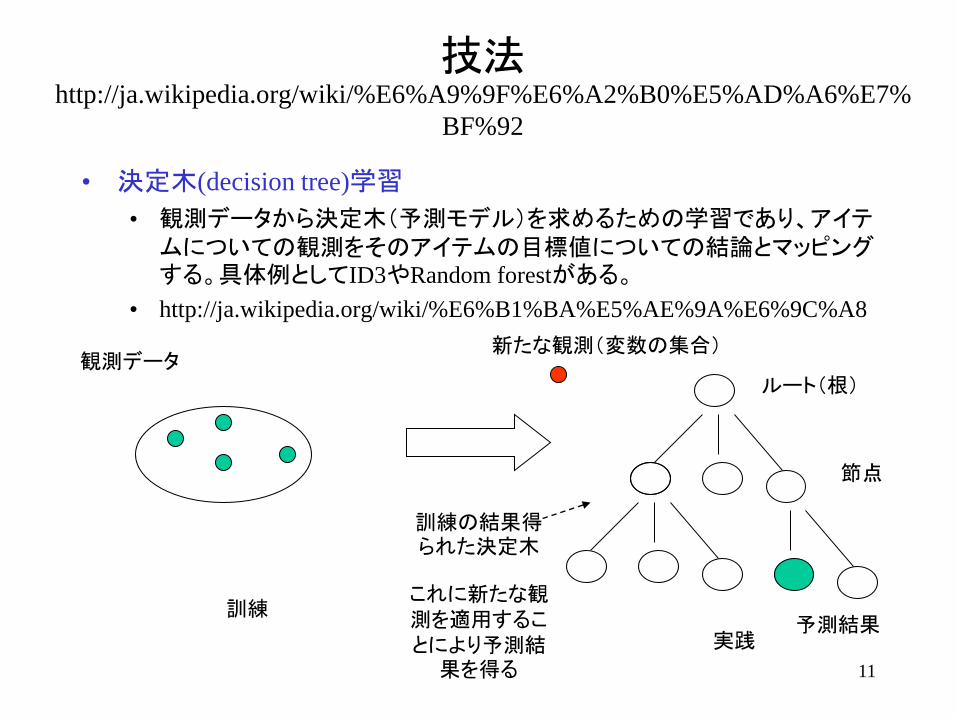
11
技法http://ja.wikipedia.org/wiki/%E6%A9%9F%E6%A2%B0%E5%AD%A6%E7%
BF%92
• 決定木(decision tree)学習
• 観測データから決定木(予測モデル)を求めるための学習であり、アイテムについての観測をそのアイテムの目標値についての結論とマッピングする。具体例としてID3やRandom forestがある。
• http://ja.wikipedia.org/wiki/%E6%B1%BA%E5%AE%9A%E6%9C%A8
実践
観測データ
訓練
新たな観測(変数の集合)
ルート(根)
訓練の結果得られた決定木
これに新たな観測を適用することにより予測結果を得る
節点
予測結果

12
技法http://ja.wikipedia.org/wiki/%E6%A9%9F%E6%A2%B0%E5%AD%A6%E7%
BF%92
• 相関ルール (association rule)学習
• 大規模データベースにおける変数間の興味深い関係を発見するための技法。
• マーケットバスケット分析とも呼ばれる。
データマイニングに活用される例が多い。
有名な例は、スーパーマーケットのバスケット分析(おむつとビール)
因果関係を追求するのに向いていそう。
例:農作物の生育や病気と肥料の関係など。
私見

13
技法http://ja.wikipedia.org/wiki/%E6%A9%9F%E6%A2%B0%E5%AD%A6%E7%
BF%92
• ニューラルネットワーク (NN)
• 人工ニューラルネットワーク (ANN) とも呼ばれ、生物の神経ネットワー
クの構造と機能を模倣するという観点から生まれた学習アルゴリズムである。人工神経を相互接続したもので計算を構造化し、コネクショニズム的計算技法で情報を処理する。現代的ニューラルネットワークは非線形な統計的データモデリングツールである。入力と出力の間の複雑な関係をモデル化するのに使われ、データのパターン認識や観測された変数間の未知の同時分布における統計的構造を捉えるなどの用途がある。
1958年 Rosenblattのパーセプトロンが起源。ながらく≒30年沈没。
ディープラーニング(深層学習)はニューラルネットワークを使っている。ディープラーニングは、最近目立った成果をあげている。
(例:Googleの猫画像の認識)
人間の脳の構造に他の方法より、近い。
以上から今後、有望な技法であろう。
私見

14
技法http://ja.wikipedia.org/wiki/%E6%A9%9F%E6%A2%B0%E5%AD%A6%E7%
BF%92
• 遺伝的プログラミング (GP:Genetic Programming)
• 生物の進化を模倣した進化的アルゴリズムに基づく技法であり、ユーザーが定義したタスクを実行するプログラムを探索する。遺伝的アルゴリズムを拡張・特化させたものである。所定のタスクを実行する能力によって適応度地形を決定し、それによってコンピュータプログラムを最適化させていく機械学習技法である。
若干異質なアプローチ。
ニューロが人間の一時期の学習(現実の人間の学習)を模擬したものに比べ、GPは、人類の進化過程を模擬したもの。
短時間では、なかなか把握できなかった。(奥が深い?)
私見

15
技法http://ja.wikipedia.org/wiki/%E6%A9%9F%E6%A2%B0%E5%AD%A6%E7%
BF%92
• 帰納論理プログラミング (ILP:Inductive Logic Programming)
• 例、背景知識、仮説を一様な表現とし、論理プログラミングを使って学習を規則化する技法である。既知の背景知識と例の集合をコード化して事実の論理データベースとし、全てのポジティブな例を含み、ネガティブな例を全く含まない仮説的論理プログラムを生成する。
• https://www.jstage.jst.go.jp/article/jssst/23/2/23_2_2_29/_pdf 京大山本
• 帰納論理プログラミングとは、論理プログラムを用いた機械学習法であり、構造化データからのデータ分析と知識獲得への応用が進められている。
• https://www.math.kyoto-u.ac.jp/~susumu/ppl_ss05/yamamoto-online.ppt 京大山本
• 帰納論理プログラミングとは、具体的な観測事例から、それを一般的に説明する規則性を論理プログラムの形で構成する手法を対象とする研究分野である。
ともかくむつかしい。せめて、オープンソフトがあれば、利用もできるが。(電気工学ではなく、やはり計算機科学、数理論理学の知識が必要) むつかしさに見合う効用がありや否や。
私見

16
技法http://ja.wikipedia.org/wiki/%E6%A9%9F%E6%A2%B0%E5%AD%A6%E7%
BF%92
• サポートベクターマシン (SVM)
• 統計分類や回帰分析に使われる一連の教師あり学習技法である。訓練例のラベルは2値(2つに分類される)であり、訓練アルゴリズムによってモデルを構築し、新たな例がどちらに分類されるかを予測する。
• http://home.hiroshima-u.ac.jp/tkurita/lecture/svm.pdf
• カーネルトリックにより非線形の識別関数を構成できるように拡張したサポートベクターマシンは、現在知られている多くの手法の中でも最も認識性能の優れた学習モデルの一つである。サポートベクターマシンが優れた認識性能を発揮できるのは、未学習データに対して高い識別性能を得るための工夫があるためである。

17
技法http://ja.wikipedia.org/wiki/%E6%A9%9F%E6%A2%B0%E5%AD%A6%E7%
BF%92
• クラスタリング
• クラスタリングは、観測された例をクラスタと呼ばれる部分集合に振り分けるもので、振り分けは事前に指示された基準に従って行う。クラスタリングはデータの構造についての仮説(基準)の立て方によって結果が異なる。仮説は「類似尺度」で定義され、「内部コンパクト性」(同一クラスタ内のメンバー間の類似性)や異なるクラスタ間の距離によって評価される。「推定密度」や「グラフ接続性」に基づく技法もある。クラスタリングは教師なし学習技法であり、統計的データ解析でよく使われる。

18
技法http://ja.wikipedia.org/wiki/%E6%A9%9F%E6%A2%B0%E5%AD%A6%E7%
BF%92
• ベイジアンネットワーク
• 確率変数群とそれらの条件付き独立性を有向非巡回グラフ (DAG) で
表した確率論的グラフィカルモデルである。例えば、病気と症状の関係を確率的に表すことができる。そのネットワークに症状を入力すれば、考えられる病気の一覧を確率付きで出力できる。これを使って推論と学習を行う効率的アルゴリズムが存在する。

19
技法http://ja.wikipedia.org/wiki/%E6%A9%9F%E6%A2%B0%E5%AD%A6%E7%
BF%92
• 強化学習
• 「エージェント」が「環境」の中でどのような「行動」をとるべきかを、何らかの長期的「報酬」を最大化するよう決定する。環境の「状態」からエージェントの行動への写像を行う「方針」を求めるのが強化学習アルゴリズムである。正しい入出力例は与えられないし、最適でない行動が明示的に訂正されることもないので、教師あり学習とは異なる。

20
技法http://ja.wikipedia.org/wiki/%E6%A9%9F%E6%A2%B0%E5%AD%A6%E7%
BF%92
• 表現学習
• 教師なし学習アルゴリズムの一部は、訓練中に提供された入力のよりよい表現を発見しようとする。古典的な例として主成分分析やクラスタ分析がある。入力の持つ情報は保持したまま、分類や予測の前に入力をより便利な表現に変換するアルゴリズムもある。その際に入力データが従っている未知の確率分布から入力を再建できるようにするが、その確率分布においては信じがたい例も忠実に再現する必要はない。例えば多様体学習アルゴリズムは、何らかの制約下で入力の次元を低く変換して表現する。スパースコーディングアルゴリズムでは、入力が疎ら(ゼロが多い)という制約下で同様の表現の変換を行う。ニューラルネットワークの深層学習は複数レベルの表現または特徴の階層を発見するもので、低いレベルで抽出した特徴から高いレベルの抽象化した特徴までを求める。知的機械は、観測されたデータを説明する偏差の潜在的要因を解きほぐす表現を学習するものだという主張もある。

21
その他の参考 https://ja.wikipedia.org/wiki/EM%E3%82%A2%E3%83%AB%E3%82%B4%E
3%83%AA%E3%82%BA%E3%83%A0
• EMアルゴリズム expectation-maximization algorithm 期待値最大化法
• 観測データを x、パラメータを θ、潜在データあるいは欠損値を z 、尤度関数 L(θ;x,z)とするとき、パラメータの最尤推定値は、観測データに対する周辺尤度(英語版)を最大化することで求められる。しかしその最適化問題は解析的に解けず[5]、計算量はintractableであり、繰り返しにより解を求めることになる。
• EMアルゴリズムでは、下記の二つのステップを反復することにより、最尤推定値を見つけようとする。
• E ステップ: 現在推定されているパラメータの分布θ(t)のもとで、尤度関数の、条件付き確率 P(z|x) に関する期待値を計算する:
• M ステップ: 下記の量Qを最大化するパラメータを求める。
• EMアルゴリズムは観測データの対数尤度を、E ステップとM ステップの繰り返しにより最大化するアルゴリズムであるので、正確にはlog-EMアルゴリズムというべきものである。log関数にはα-logとよばれる一般化された対数があるので、それを用いるとlog-EMを特例として含むアルゴリズムを作り上げることができる。ただし、この場合は尤度ではなくてα-log尤度比とαダイバージェンスを用いて基本等式を導くことになる。このようにして得られたものがα-EMアルゴリズム [6] であり、log-EMアルゴリズムをサブクラスとして含んでいる。α-EMアルゴリズムは適切なαを選ぶことにより、log-EMアルゴリズムよりも高速になる。また、log-EMが隠れマルコフモデル推定アルゴリズム(Baum-Welchアルゴリズム)を含んでいるように、α-EMアルゴリズムから高速なα-HMMアルゴリズムを得ることができる。

22
その他の参考 https://ja.wikipedia.org/wiki/%E3%83%90%E3%82%A6%E3%83%A0%EF%B
C%9D%E3%82%A6%E3%82%A7%E3%83%AB%E3%83%81%E3%82%A2
%E3%83%AB%E3%82%B4%E3%83%AA%E3%82%BA%E3%83%A0
• バウム・ウエルチアルゴリズム
• バウム=ウェルチアルゴリズムは、一般化期待値最大化法 (GEM) である。HMMのパラメータ群(遷移確率と出力確率)について、訓練例の出力のみから最尤値と事後確率および最頻値の予測値を計算できる。
• このアルゴリズムは以下の2段階から成る。
1. HMMの各状態について、前向き確率と後向き確率を計算する。
2. それに基づき、遷移-出力対の値の頻度を決定し、文字列全体の確率でそれを割る。これは特定の遷移-出力対の回数の期待値を計算することに相当
する。特定の遷移が見つかる度に文字列全体の確率で割った遷移の商の値が上がっていき、それが遷移の新たな値となる。

23
その他の参考 https://ja.wikipedia.org/wiki/%E3%83%93%E3%82%BF%E3%83%93%E3%82
%A2%E3%83%AB%E3%82%B4%E3%83%AA%E3%82%BA%E3%83%A0
• ビタビアルゴリズム