pattern: an open source project for migrating predictive models onto apache hadoop
TRANSCRIPT

Copyright @2013, Concurrent, Inc.
Paco NathanConcurrent, Inc.San Francisco, CA@pacoid
“Pattern – an open source project for migrating predictive models onto Apache Hadoop”
1Sunday, 17 March 13

Pattern: predictive models at scale
Scrubtoken
DocumentCollection
Tokenize
WordCount
GroupBytoken
Count
Stop WordList
Regextoken
HashJoinLeft
RHS
M
R
• Enterprise Data Workflows• Sample Code• A Little Theory…• Pattern• PMML• Roadmap• Customer Experiments
2Sunday, 17 March 13

Cascading – origins
API author Chris Wensel worked as a system architect at an Enterprise firm well-known for many popular data products.
Wensel was following the Nutch open source project – where Hadoop started.
Observation: would be difficult to find Java developers to write complex Enterprise apps in MapReduce – potential blocker for leveraging new open source technology.
3Sunday, 17 March 13

Cascading – functional programming
Key insight: MapReduce is based on functional programming – back to LISP in 1970s. Apache Hadoop use cases are mostly about data pipelines, which are functional in nature.
To ease staffing problems as “Main Street” Enterprise firms began to embrace Hadoop, Cascading was introduced in late 2007, as a new Java API to implement functional programming for large-scale data workflows:
• leverages JVM and Java-based tools without anyneed to create new languages
• allows programmers who have J2EE expertise to leverage the economics of Hadoop clusters
4Sunday, 17 March 13

functional programming… in production
• Twitter, eBay, LinkedIn, Nokia, YieldBot, uSwitch, etc., have invested in open source projects atop Cascading – used for their large-scale production deployments
• new case studies for Cascading apps are mostly based on domain-specific languages (DSLs) in JVM languages which emphasize functional programming:
Cascalog in Clojure (2010)Scalding in Scala (2012)
github.com/nathanmarz/cascalog/wiki
github.com/twitter/scalding/wiki
5Sunday, 17 March 13
Hadoop Cluster
sourcetap
sourcetap sink
taptraptap
customer profile DBsCustomer
Prefs
logslogs
Logs
DataWorkflow
Cache
Customers
Support
WebApp
Reporting
Analytics Cubes
sinktap
Modeling PMML
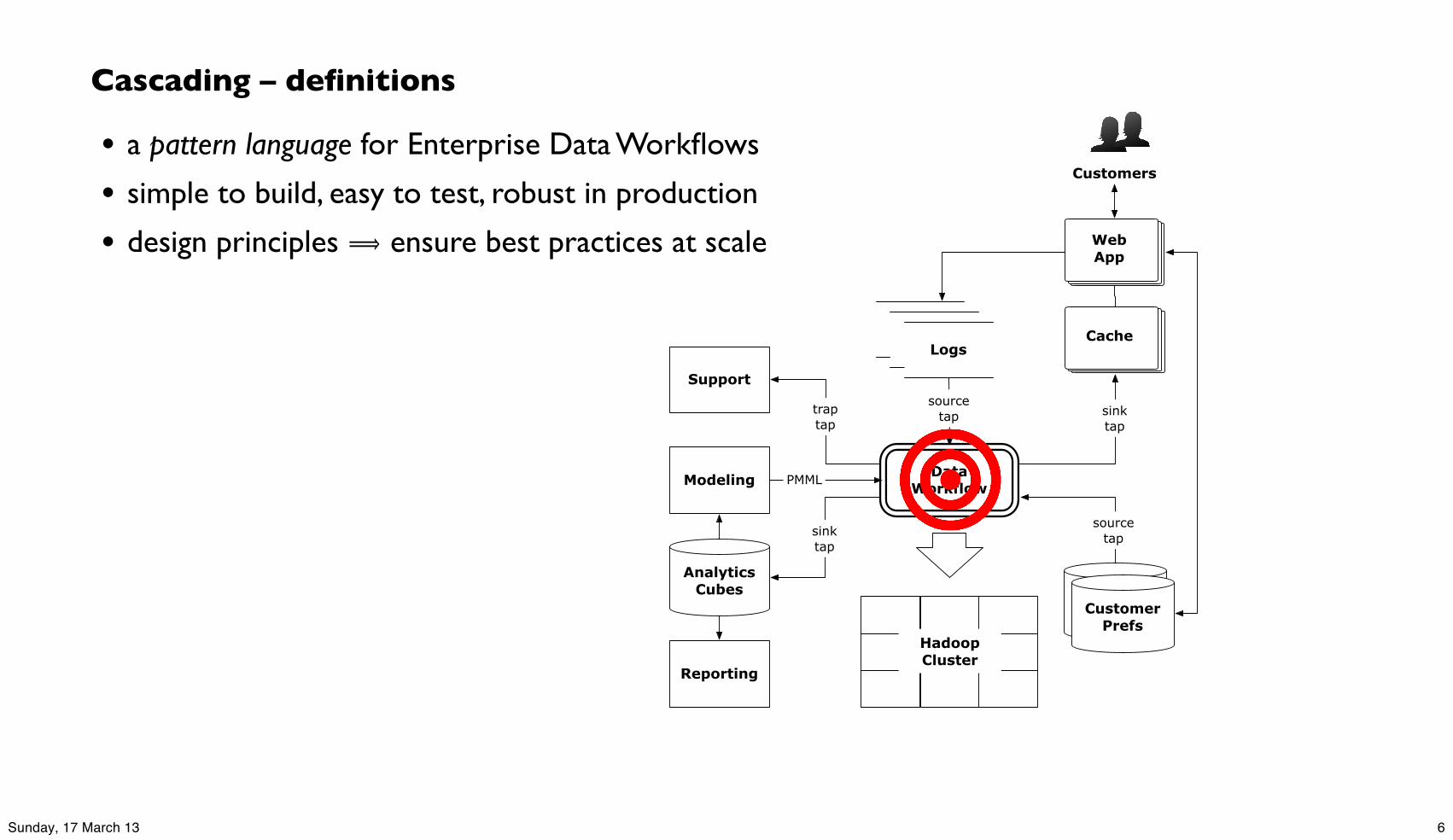
Cascading – definitions
• a pattern language for Enterprise Data Workflows
• simple to build, easy to test, robust in production
• design principles ⟹ ensure best practices at scale
6Sunday, 17 March 13
Hadoop Cluster
sourcetap
sourcetap sink
taptraptap
customer profile DBsCustomer
Prefs
logslogs
Logs
DataWorkflow
Cache
Customers
Support
WebApp
Reporting
Analytics Cubes
sinktap
Modeling PMML
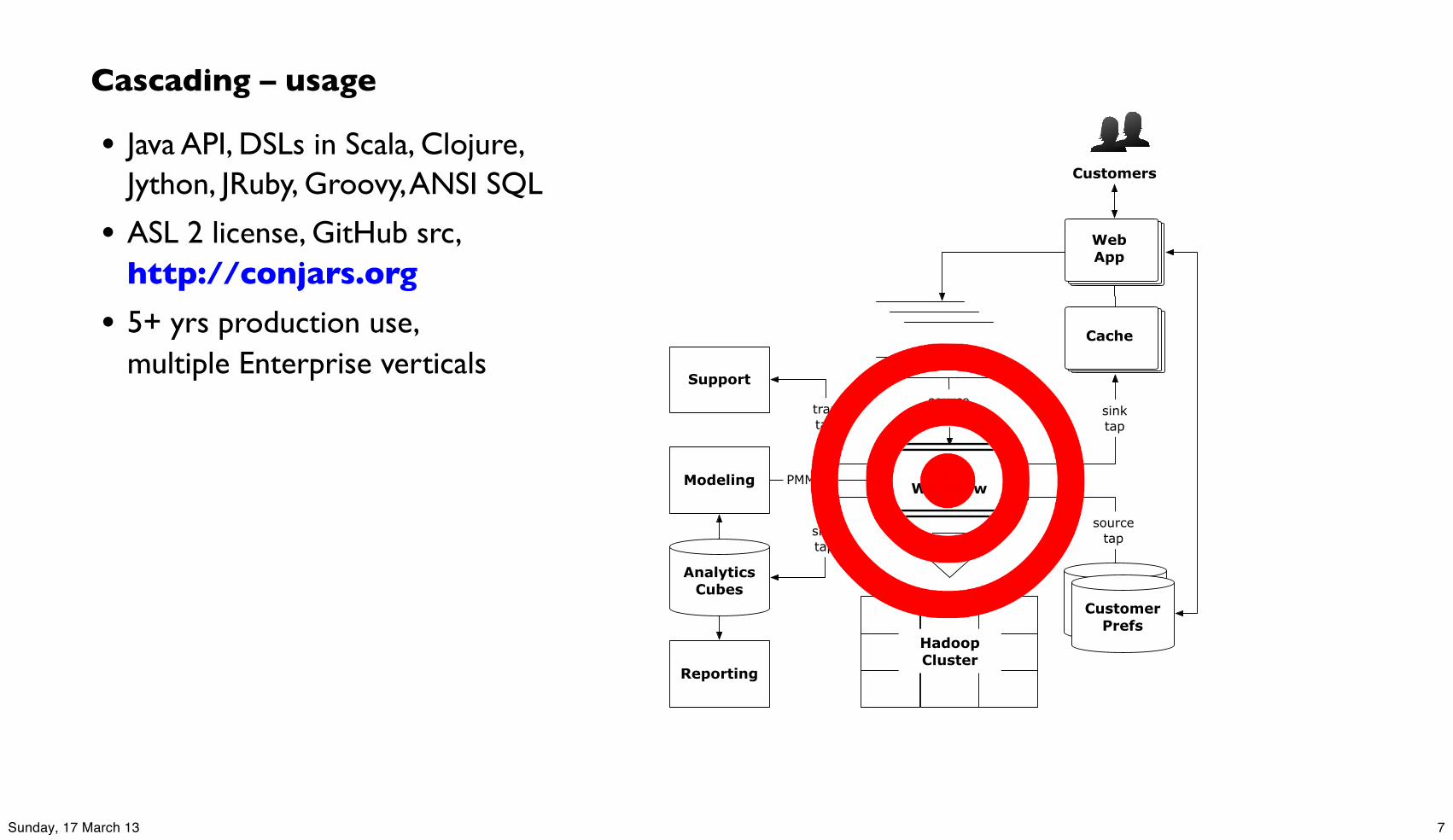
Cascading – usage
• Java API, DSLs in Scala, Clojure, Jython, JRuby, Groovy, ANSI SQL
• ASL 2 license, GitHub src, http://conjars.org
• 5+ yrs production use, multiple Enterprise verticals
7Sunday, 17 March 13
Hadoop Cluster
sourcetap
sourcetap sink
taptraptap
customer profile DBsCustomer
Prefs
logslogs
Logs
DataWorkflow
Cache
Customers
Support
WebApp
Reporting
Analytics Cubes
sinktap
Modeling PMML
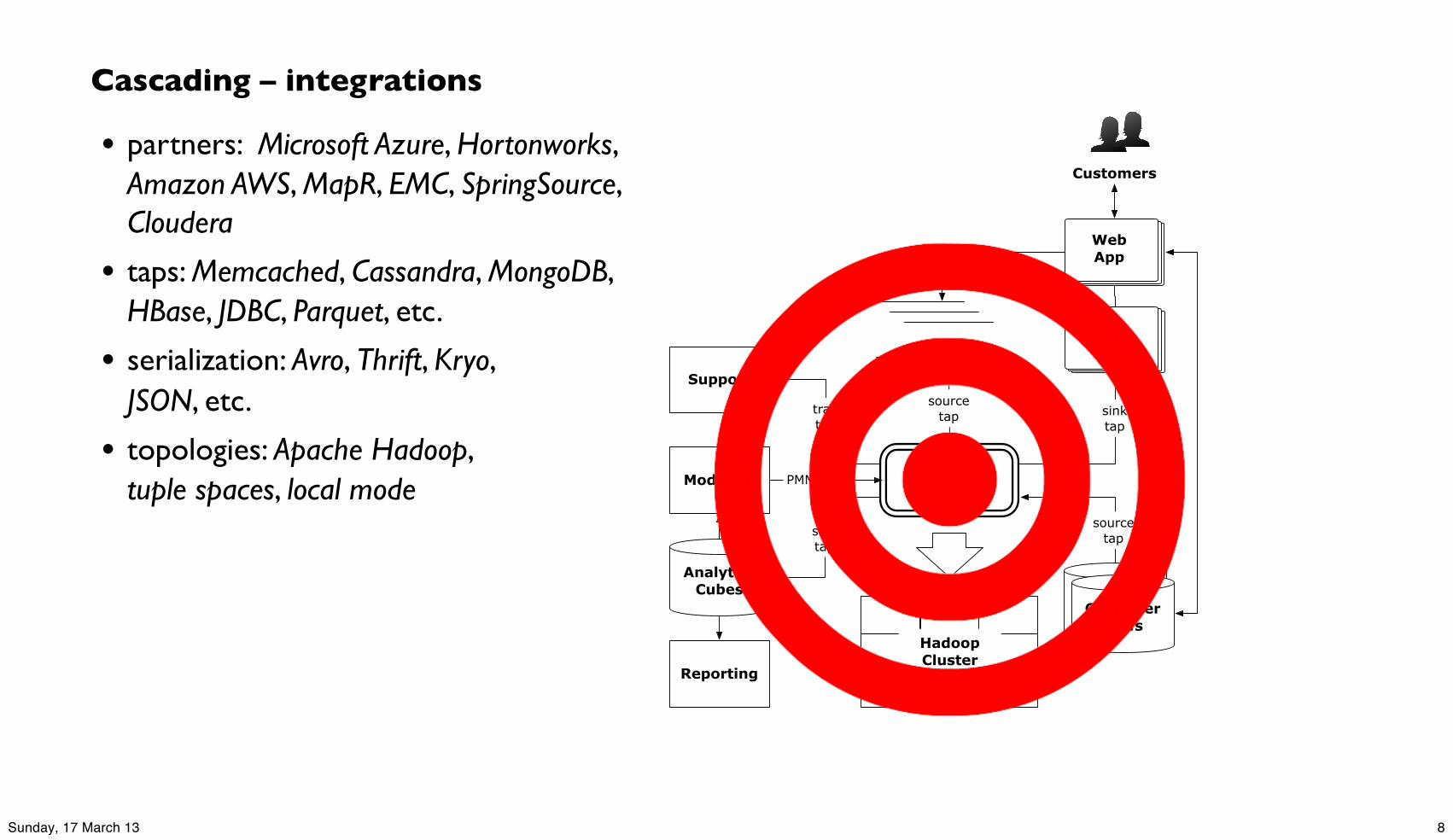
Cascading – integrations
• partners: Microsoft Azure, Hortonworks, Amazon AWS, MapR, EMC, SpringSource, Cloudera
• taps: Memcached, Cassandra, MongoDB, HBase, JDBC, Parquet, etc.
• serialization: Avro, Thrift, Kryo, JSON, etc.
• topologies: Apache Hadoop, tuple spaces, local mode
8Sunday, 17 March 13

Cascading – deployments
• case studies: Climate Corp, Twitter, Etsy, Williams-Sonoma, uSwitch, Airbnb, Nokia, YieldBot, Square, Harvard, etc.
• use cases: ETL, marketing funnel, anti-fraud, social media, retail pricing, search analytics, recommenders, eCRM, utility grids, telecom, genomics, climatology, agronomics, etc.
9Sunday, 17 March 13

Cascading – deployments
• case studies: Climate Corp, Twitter, Etsy, Williams-Sonoma, uSwitch, Airbnb, Nokia, YieldBot, Square, Harvard, etc.
• use cases: ETL, marketing funnel, anti-fraud, social media, retail pricing, search analytics, recommenders, eCRM, utility grids, telecom, genomics, climatology, agronomics, etc.
workflow abstraction addresses: • staffing bottleneck; • system integration; • operational complexity; • test-driven development
10Sunday, 17 March 13

Scrubtoken
DocumentCollection
Tokenize
WordCount
GroupBytoken
Count
Stop WordList
Regextoken
HashJoinLeft
RHS
M
R
Pattern: predictive models at scale
• Enterprise Data Workflows• Sample Code• A Little Theory…• Pattern• PMML• Roadmap• Customer Experiments
11Sunday, 17 March 13

void map (String doc_id, String text):
for each word w in segment(text):
emit(w, "1");
void reduce (String word, Iterator group):
int count = 0;
for each pc in group:
count += Int(pc);
emit(word, String(count));
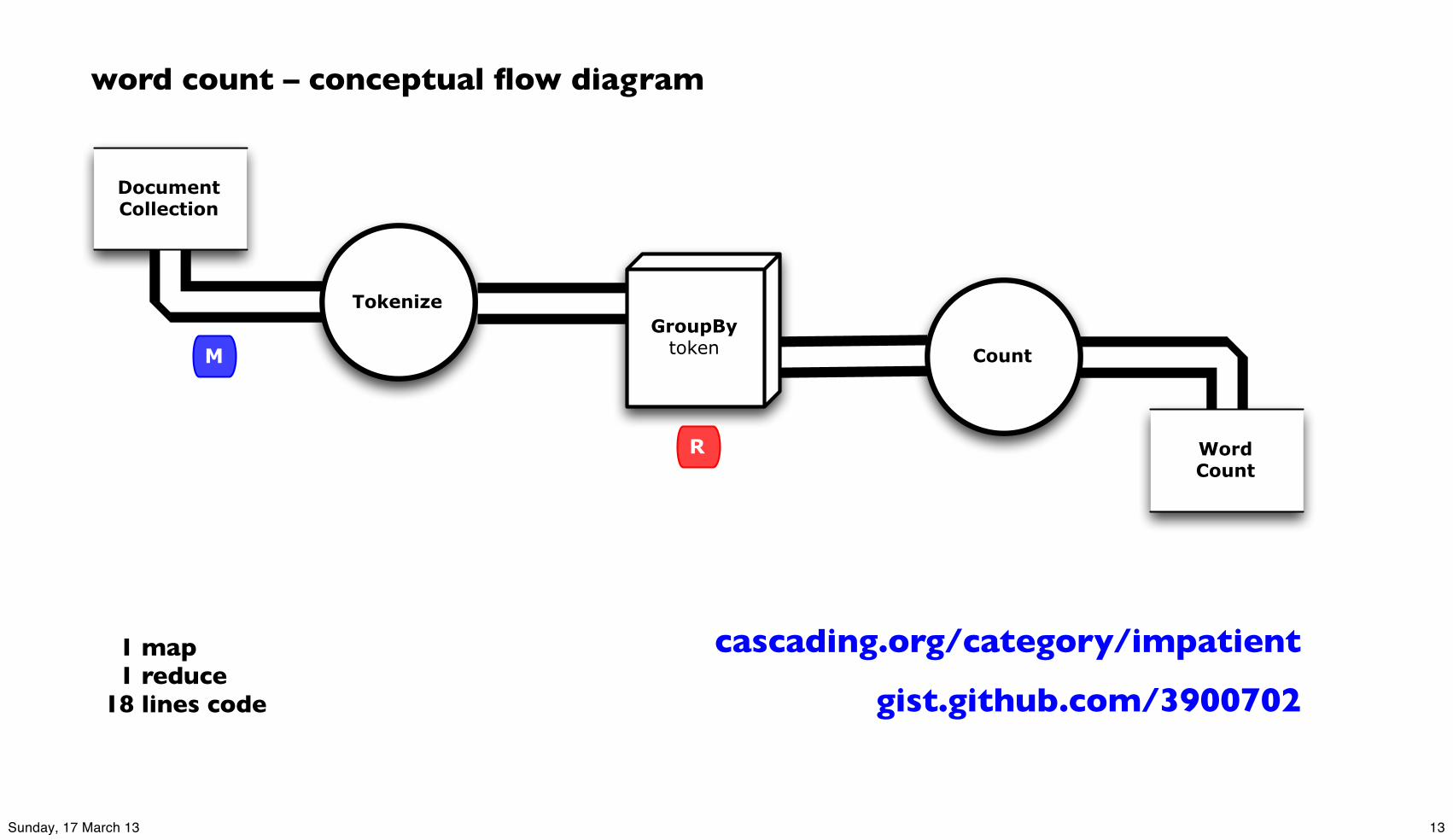
The Ubiquitous Word Count
Definition: count how often each word appears in a collection of text documents
This simple program provides an excellent test case for parallel processing, since it illustrates:
• requires a minimal amount of code
• demonstrates use of both symbolic and numeric values
• shows a dependency graph of tuples as an abstraction
• is not many steps away from useful search indexing
• serves as a “Hello World” for Hadoop apps
Any distributed computing framework which can run Word Count efficiently in parallel at scale can handle much larger and more interesting compute problems.
DocumentCollection
WordCount
TokenizeGroupBytoken Count
R
M
count how often each word appears in a collection of text documents
12Sunday, 17 March 13
DocumentCollection
WordCount
TokenizeGroupBytoken Count
R
M
1 map 1 reduce18 lines code gist.github.com/3900702
word count – conceptual flow diagram
cascading.org/category/impatient
13Sunday, 17 March 13

word count – Cascading app in Java
String docPath = args[ 0 ];String wcPath = args[ 1 ];Properties properties = new Properties();AppProps.setApplicationJarClass( properties, Main.class );HadoopFlowConnector flowConnector = new HadoopFlowConnector( properties );
// create source and sink tapsTap docTap = new Hfs( new TextDelimited( true, "\t" ), docPath );Tap wcTap = new Hfs( new TextDelimited( true, "\t" ), wcPath );
// specify a regex to split "document" text lines into token streamFields token = new Fields( "token" );Fields text = new Fields( "text" );RegexSplitGenerator splitter = new RegexSplitGenerator( token, "[ \\[\\]\\(\\),.]" );// only returns "token"Pipe docPipe = new Each( "token", text, splitter, Fields.RESULTS );// determine the word countsPipe wcPipe = new Pipe( "wc", docPipe );wcPipe = new GroupBy( wcPipe, token );wcPipe = new Every( wcPipe, Fields.ALL, new Count(), Fields.ALL );
// connect the taps, pipes, etc., into a flowFlowDef flowDef = FlowDef.flowDef().setName( "wc" ) .addSource( docPipe, docTap ) .addTailSink( wcPipe, wcTap );// write a DOT file and run the flowFlow wcFlow = flowConnector.connect( flowDef );wcFlow.writeDOT( "dot/wc.dot" );wcFlow.complete();
DocumentCollection
WordCount
TokenizeGroupBytoken Count
R
M
14Sunday, 17 March 13

map
reduceEvery('wc')[Count[decl:'count']]
Hfs['TextDelimited[[UNKNOWN]->['token', 'count']]']['output/wc']']
GroupBy('wc')[by:['token']]
Each('token')[RegexSplitGenerator[decl:'token'][args:1]]
Hfs['TextDelimited[['doc_id', 'text']->[ALL]]']['data/rain.txt']']
[head]
[tail]
[{2}:'token', 'count'][{1}:'token']
[{2}:'doc_id', 'text'][{2}:'doc_id', 'text']
wc[{1}:'token'][{1}:'token']
[{2}:'token', 'count'][{2}:'token', 'count']
[{1}:'token'][{1}:'token']
word count – generated flow diagramDocumentCollection
WordCount
TokenizeGroupBytoken Count
R
M
15Sunday, 17 March 13
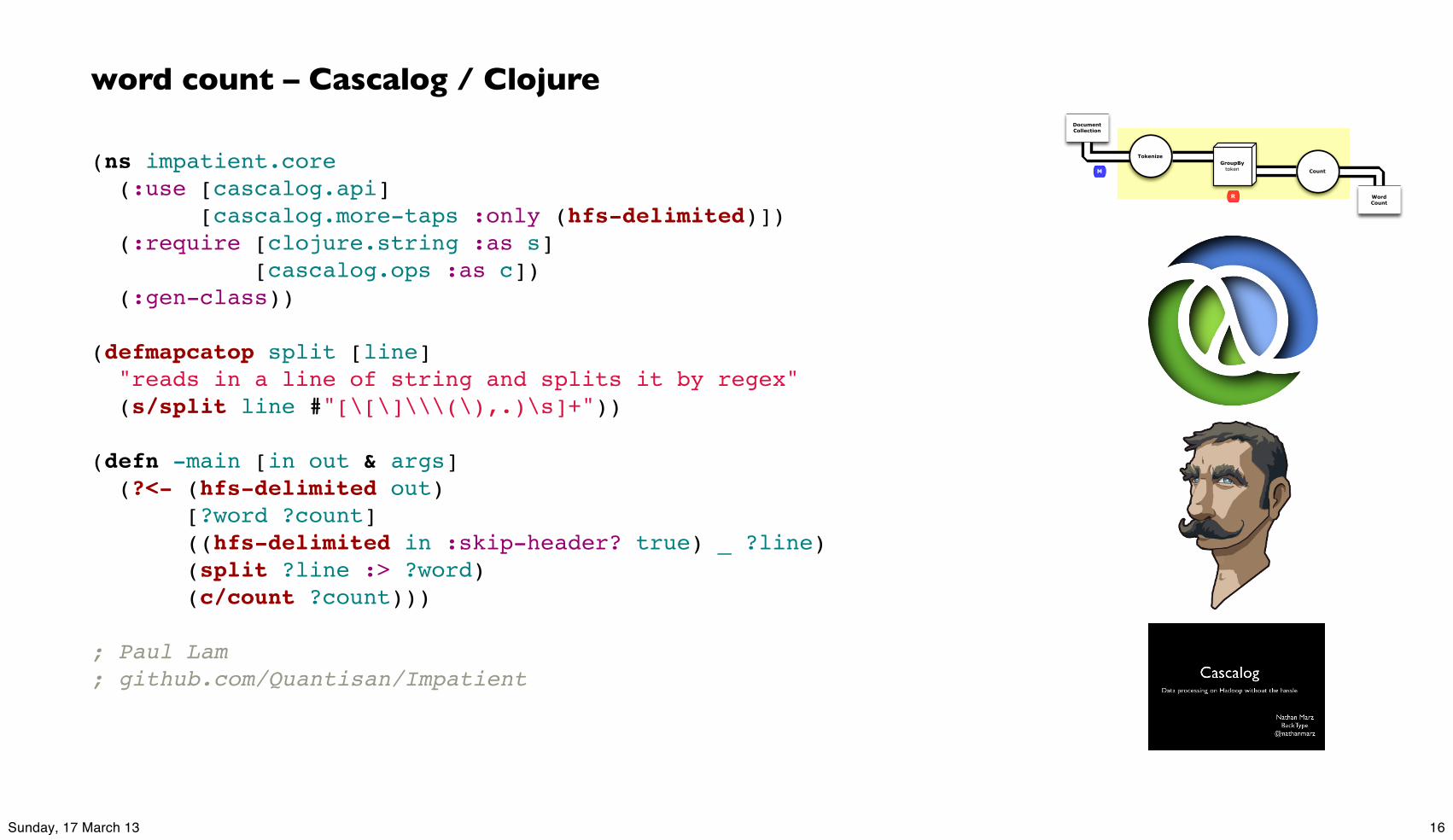
(ns impatient.core (:use [cascalog.api] [cascalog.more-taps :only (hfs-delimited)]) (:require [clojure.string :as s] [cascalog.ops :as c]) (:gen-class))
(defmapcatop split [line] "reads in a line of string and splits it by regex" (s/split line #"[\[\]\\\(\),.)\s]+"))
(defn -main [in out & args] (?<- (hfs-delimited out) [?word ?count] ((hfs-delimited in :skip-header? true) _ ?line) (split ?line :> ?word) (c/count ?count)))
; Paul Lam; github.com/Quantisan/Impatient
word count – Cascalog / ClojureDocumentCollection
WordCount
TokenizeGroupBytoken Count
R
M
16Sunday, 17 March 13

github.com/nathanmarz/cascalog/wiki
• implements Datalog in Clojure, with predicates backed by Cascading – for a highly declarative language
• run ad-hoc queries from the Clojure REPL –approx. 10:1 code reduction compared with SQL
• composable subqueries, used for test-driven development (TDD) practices at scale
• Leiningen build: simple, no surprises, in Clojure itself
• more new deployments than other Cascading DSLs – Climate Corp is largest use case: 90% Clojure/Cascalog
• has a learning curve, limited number of Clojure developers
• aggregators are the magic, and those take effort to learn
word count – Cascalog / ClojureDocumentCollection
WordCount
TokenizeGroupBytoken Count
R
M
17Sunday, 17 March 13

import com.twitter.scalding._ class WordCount(args : Args) extends Job(args) { Tsv(args("doc"), ('doc_id, 'text), skipHeader = true) .read .flatMap('text -> 'token) { text : String => text.split("[ \\[\\]\\(\\),.]") } .groupBy('token) { _.size('count) } .write(Tsv(args("wc"), writeHeader = true))}
word count – Scalding / ScalaDocumentCollection
WordCount
TokenizeGroupBytoken Count
R
M
18Sunday, 17 March 13

github.com/twitter/scalding/wiki
• extends the Scala collections API so that distributed lists become “pipes” backed by Cascading
• code is compact, easy to understand
• nearly 1:1 between elements of conceptual flow diagram and function calls
• extensive libraries are available for linear algebra, abstract algebra, machine learning – e.g., Matrix API, Algebird, etc.
• significant investments by Twitter, Etsy, eBay, etc.
• great for data services at scale
• less learning curve than Cascalog
word count – Scalding / ScalaDocumentCollection
WordCount
TokenizeGroupBytoken Count
R
M
19Sunday, 17 March 13

github.com/twitter/scalding/wiki
• extends the Scala collections API so that distributed lists become “pipes” backed by Cascading
• code is compact, easy to understand
• nearly 1:1 between elements of conceptual flow diagram and function calls
• extensive libraries are available for linear algebra, abstract algebra, machine learning – e.g., Matrix API, Algebird, etc.
• significant investments by Twitter, Etsy, eBay, etc.
• great for data services at scale
• less learning curve than Cascalog
word count – Scalding / ScalaDocumentCollection
WordCount
TokenizeGroupBytoken Count
R
M
Cascalog and Scalding DSLs leverage the functional aspects of MapReduce, helping limit complexity in process
20Sunday, 17 March 13
Two Avenues to the App Layer…
scale ➞co
mpl
exity
➞
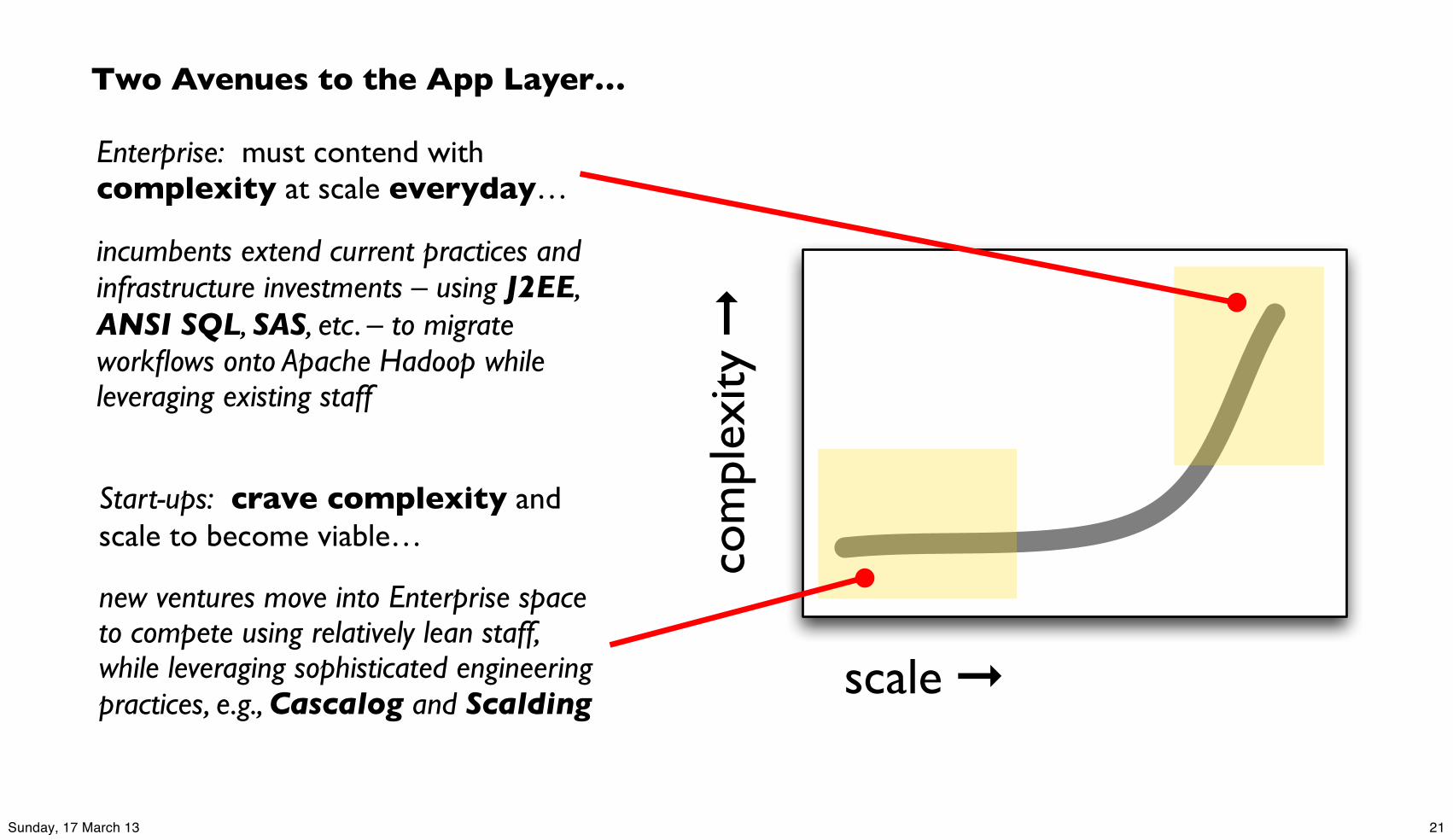
Enterprise: must contend with complexity at scale everyday…
incumbents extend current practices and infrastructure investments – using J2EE, ANSI SQL, SAS, etc. – to migrate workflows onto Apache Hadoop while leveraging existing staff
Start-ups: crave complexity and scale to become viable…
new ventures move into Enterprise space to compete using relatively lean staff, while leveraging sophisticated engineering practices, e.g., Cascalog and Scalding
21Sunday, 17 March 13

Scrubtoken
DocumentCollection
Tokenize
WordCount
GroupBytoken
Count
Stop WordList
Regextoken
HashJoinLeft
RHS
M
R
Pattern: predictive models at scale
• Enterprise Data Workflows• Sample Code• A Little Theory…• Pattern• PMML• Roadmap• Customer Experiments
22Sunday, 17 March 13
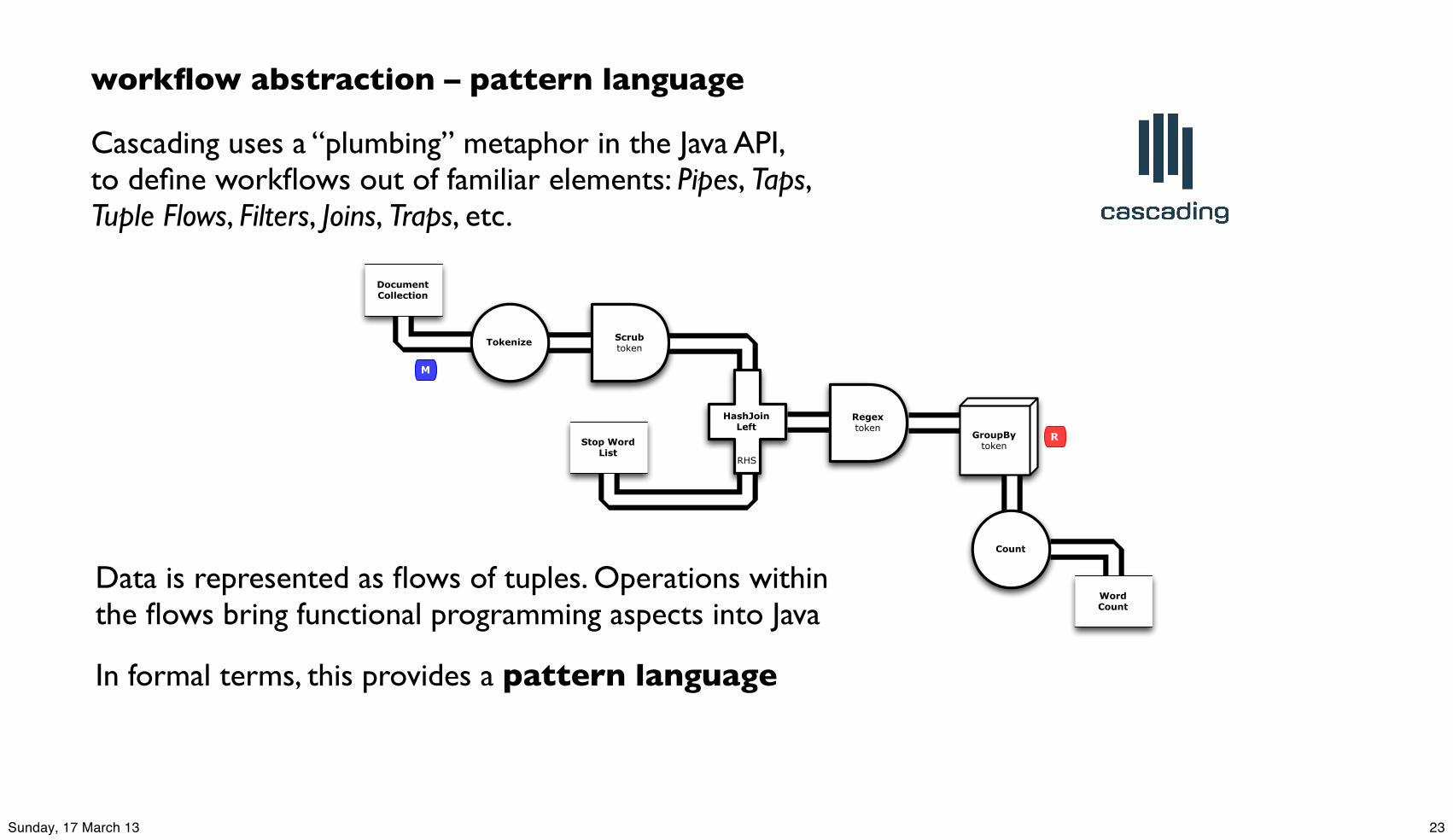
workflow abstraction – pattern language
Cascading uses a “plumbing” metaphor in the Java API, to define workflows out of familiar elements: Pipes, Taps, Tuple Flows, Filters, Joins, Traps, etc.
Scrubtoken
DocumentCollection
Tokenize
WordCount
GroupBytoken
Count
Stop WordList
Regextoken
HashJoinLeft
RHS
M
R
Data is represented as flows of tuples. Operations within the flows bring functional programming aspects into Java
In formal terms, this provides a pattern language
23Sunday, 17 March 13

references…
pattern language: a structured method for solving large, complex design problems, where the syntax of the language promotes the use of best practices
amazon.com/dp/0195019199
design patterns: the notion originated in consensus negotiation for architecture, later applied in OOP software engineering by “Gang of Four”
amazon.com/dp/0201633612
24Sunday, 17 March 13
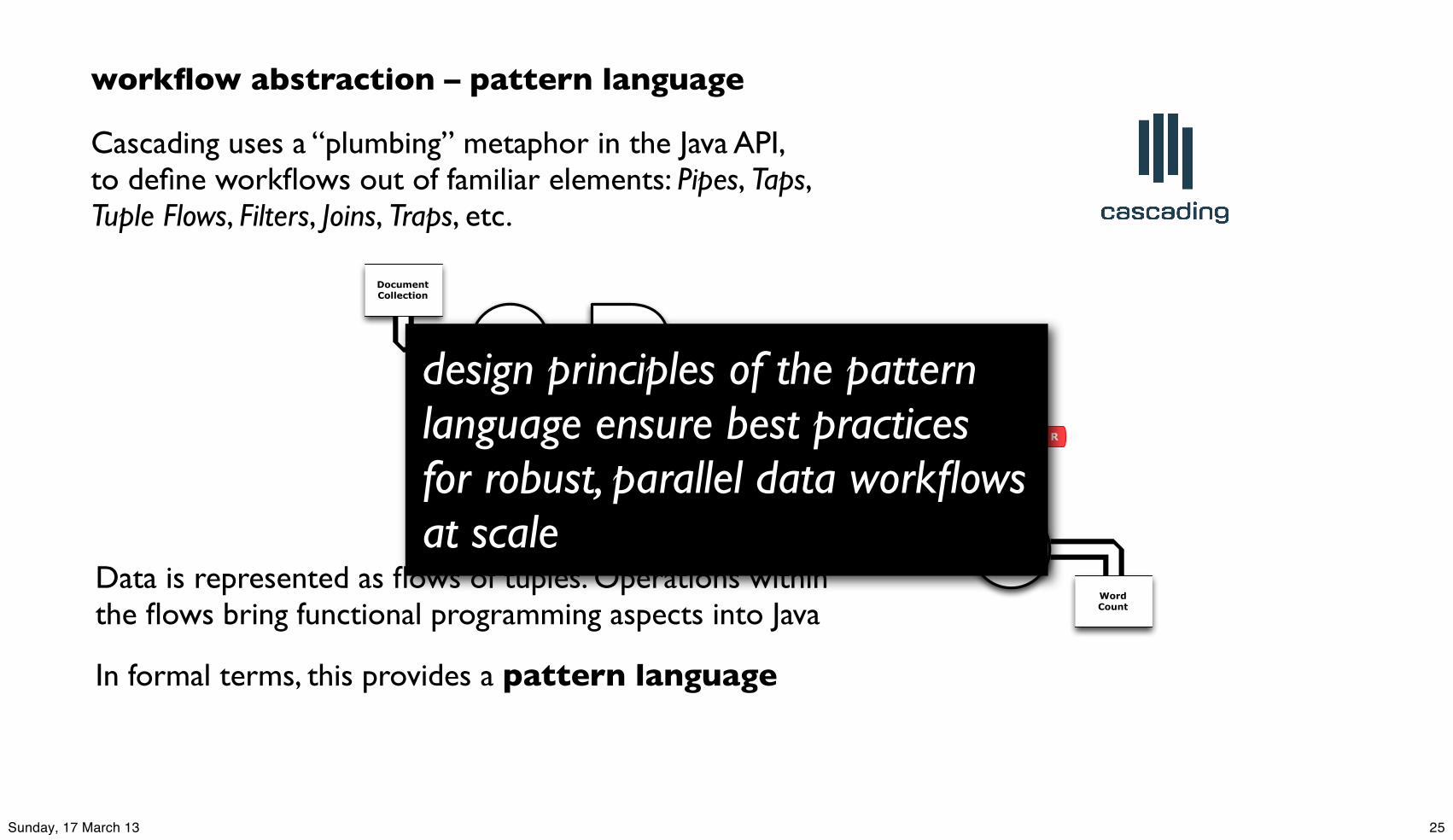
workflow abstraction – pattern language
Cascading uses a “plumbing” metaphor in the Java API, to define workflows out of familiar elements: Pipes, Taps, Tuple Flows, Filters, Joins, Traps, etc.
Scrubtoken
DocumentCollection
Tokenize
WordCount
GroupBytoken
Count
Stop WordList
Regextoken
HashJoinLeft
RHS
M
R
Data is represented as flows of tuples. Operations within the flows bring functional programming aspects into Java
In formal terms, this provides a pattern language
design principles of the pattern language ensure best practices for robust, parallel data workflows at scale
25Sunday, 17 March 13
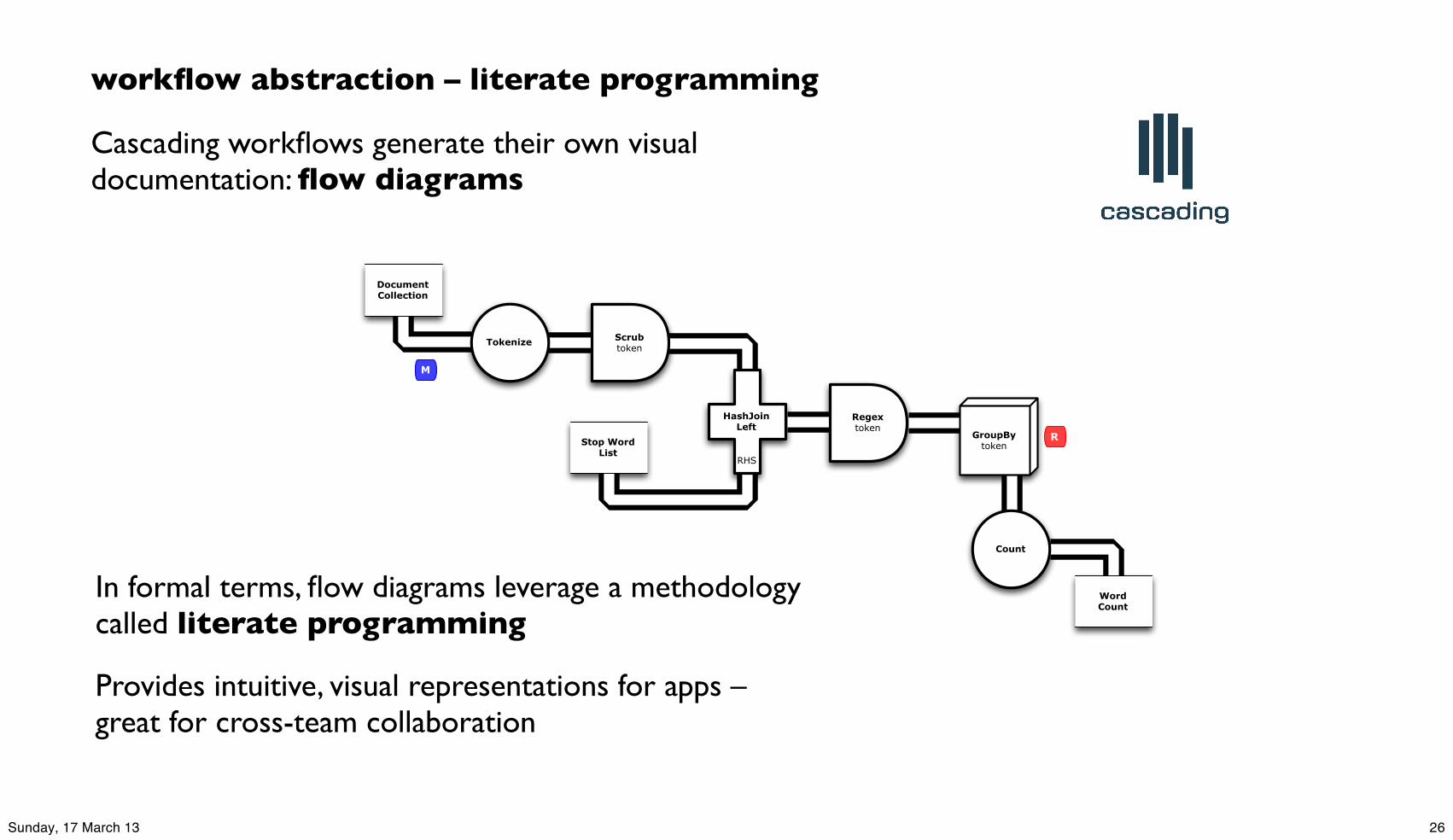
workflow abstraction – literate programming
Cascading workflows generate their own visual documentation: flow diagrams
In formal terms, flow diagrams leverage a methodology called literate programming
Provides intuitive, visual representations for apps –great for cross-team collaboration
Scrubtoken
DocumentCollection
Tokenize
WordCount
GroupBytoken
Count
Stop WordList
Regextoken
HashJoinLeft
RHS
M
R
26Sunday, 17 March 13

references…
by Don Knuth
Literate ProgrammingUniv of Chicago Press, 1992
literateprogramming.com/
“Instead of imagining that our main task is to instruct a computer what to do, let us concentrate rather on explaining to human beings what we want a computer to do.”
27Sunday, 17 March 13

Hadoop Cluster
sourcetap
sourcetap sink
taptraptap
customer profile DBsCustomer
Prefs
logslogs
Logs
DataWorkflow
Cache
Customers
Support
WebApp
Reporting
Analytics Cubes
sinktap
Modeling PMML
workflow abstraction – test-driven development
• assert patterns (regex) on the tuple streams
• adjust assert levels, like log4j levels
• trap edge cases as “data exceptions”
• TDD at scale:
1.start from raw inputs in the flow graph
2.define stream assertions for each stage of transforms
3.verify exceptions, code to remove them
4.when impl is complete, app has full test coverage
redirect traps in production to Ops, QA, Support, Audit, etc.
28Sunday, 17 March 13

workflow abstraction – business process
Following the essence of literate programming, Cascading workflows provide statements of business process
This recalls a sense of business process management for Enterprise apps (think BPM/BPEL for Big Data)
Cascading creates a separation of concerns between business process and implementation details (Hadoop, etc.)
This is especially apparent in large-scale Cascalog apps:
“Specify what you require, not how to achieve it.”
By virtue of the pattern language, the flow planner then determines how to translate business process into efficient, parallel jobs at scale
29Sunday, 17 March 13

references…
by Edgar Codd
“A relational model of data for large shared data banks”Communications of the ACM, 1970 dl.acm.org/citation.cfm?id=362685
Rather than arguing between SQL vs. NoSQL…structured vs. unstructured data frameworks… this approach focuses on what apps do:
the process of structuring data
Closely related to functional relational programming paradigm:
“Out of the Tar Pit”Moseley & Marks 2006http://goo.gl/SKspn
30Sunday, 17 March 13

workflow abstraction – API design principles
• specify what is required, not how it must be achieved
• plan far ahead, before consuming cluster resources – fail fast prior to submit
• fail the same way twice – deterministic flow planners help reduce engineering costs for debugging at scale
• same JAR, any scale – app does not require a recompile to change data taps or cluster topologies
31Sunday, 17 March 13

workflow abstraction – building apps in layers
test-driven development
businessprocess
patternlanguage
flow planner/ optimizer
topology
compiler/build
JVM cluster
separation of concerns: focus on specifying what is required, not how the computers must accomplish it – not unlike BPM/BPEL for BigData
assert expected patterns in tuple flows, adjust assertion levels, verify that tests fail, code until tests pass, repeat … route exceptional data to appropriate department
syntax of the pattern language conveys expertise – much like building a tower with Lego blocks: ensure best practices for robust, parallel data workflows at scale
enables the functional programming aspects: compiler within a compiler, mapping flows to topologies (e.g., create and sequence Hadoop job steps)
entire app is visible to the compiler: resolves issues of crossing boundaries for troubleshooting, exception handling, notifications, etc.; one app = one JAR
cluster scheduler, instrumentation, etc.
Apache Hadoop MR, IMDGs, etc., – upcoming MR2, etc.
32Sunday, 17 March 13

workflow abstraction – building apps in layers
test-driven development
businessprocess
patternlanguage
flow planner/ optimizer
topology
compiler/build
JVM cluster
separation of concerns: focus on specifying what is required, not how the computers must accomplish it – not unlike BPM/BPEL for BigData
assert expected patterns in tuple flows, adjust assertion levels, verify that tests fail, code until tests pass, repeat … route exceptional data to appropriate department
syntax of the pattern language conveys expertise – much like building a tower with Lego blocks: ensure best practices for robust, parallel data workflows at scale
enables the functional programming aspects: compiler within a compiler, mapping flows to topologies
entire app is visible to the compiler: resolves issues of crossing boundaries for troubleshooting, exception handling, notifications, etc.; one app = one JAR
cluster scheduler, instrumentation, etc.
Apache Hadoop MR, IMDGs, etc., – upcoming MR2, etc.
several theoretical aspects converge into software engineering practices which minimize the complexity of building and maintaining Enterprise data workflows
33Sunday, 17 March 13

Scrubtoken
DocumentCollection
Tokenize
WordCount
GroupBytoken
Count
Stop WordList
Regextoken
HashJoinLeft
RHS
M
R
Pattern: predictive models at scale
• Enterprise Data Workflows• Sample Code• A Little Theory…• Pattern• PMML• Roadmap• Customer Experiments
34Sunday, 17 March 13

Pattern – analytics workflows
• open source project – ASL 2, GitHub repo
• multiple companies contributing
• complementary to Apache Mahout – while leveraging workflow abstraction, multiple topologies, etc.
• model scoring: generates workflows from PMML models
• model creation: estimation at scale, captured as PMML
• use sample Hadoop app at scale – no coding required
• integrate with 2 lines of Java (1 line Clojure or Scala)
• excellent use cases for customer experiments at scale
cascading.org/pattern
35Sunday, 17 March 13

Pattern – analytics workflows
• open source project – ASL 2, GitHub repo
• multiple companies contributing
• complementary to Apache Mahout – while leveraging workflow abstraction, multiple topologies, etc.
• model scoring: generates workflows from PMML models
• model creation: estimation at scale, captured at PMML
• use sample Hadoop app at scale – no coding required
• integrate with 2 lines of Java (1 line Clojure or Scala)
• excellent use cases for customer experiments at scale
cascading.org/pattern
greatly reduced development costs, less licensing issues at scale – leveraging the economics of Apache Hadoop clusters, plus the core competencies of analytics staff, plus existing IP in predictive models
36Sunday, 17 March 13
Hadoop Cluster
sourcetap
sourcetap sink
taptraptap
customer profile DBsCustomer
Prefs
logslogs
Logs
DataWorkflow
Cache
Customers
Support
WebApp
Reporting
Analytics Cubes
sinktap
Modeling PMML
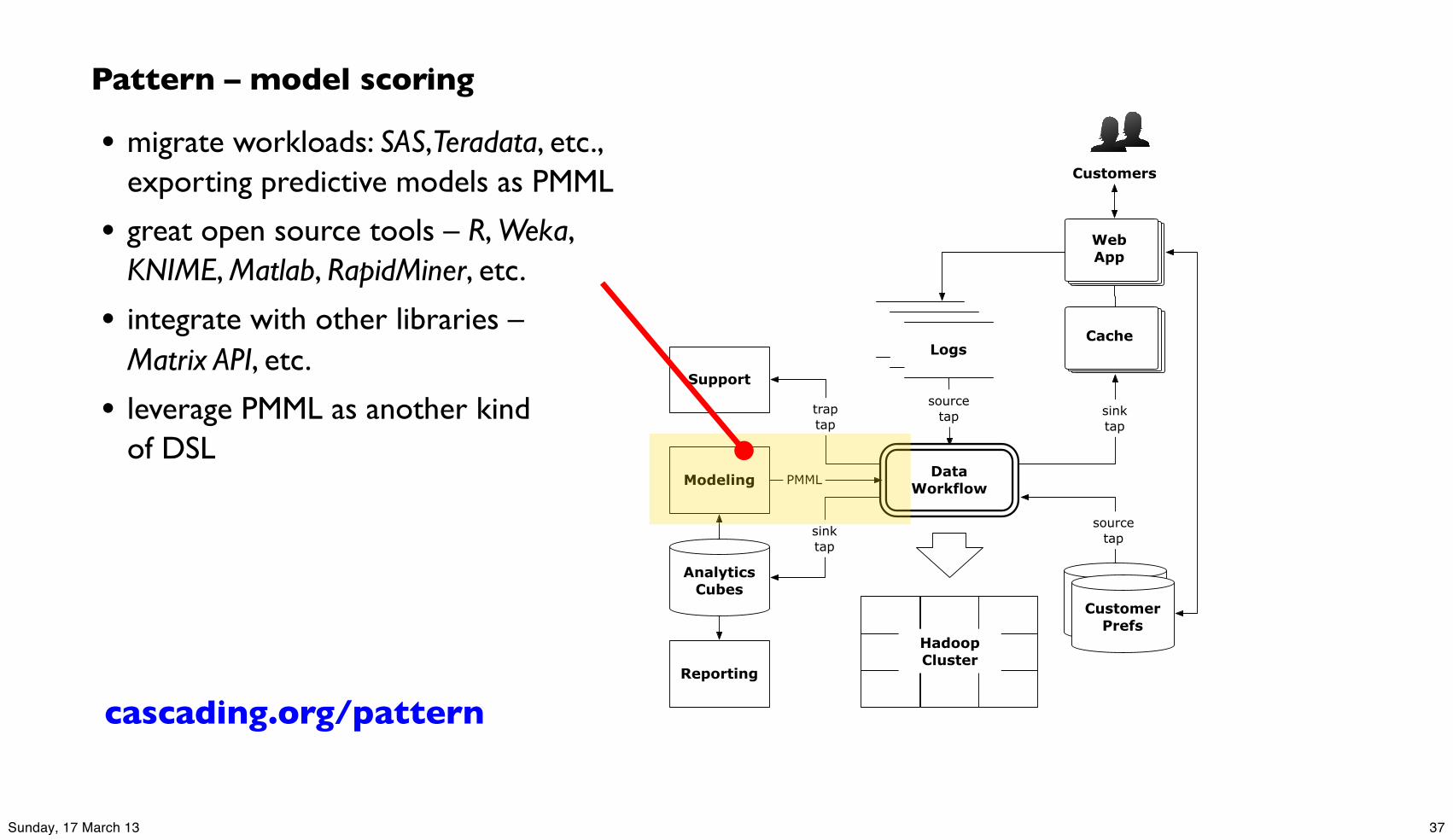
Pattern – model scoring
• migrate workloads: SAS,Teradata, etc., exporting predictive models as PMML
• great open source tools – R, Weka, KNIME, Matlab, RapidMiner, etc.
• integrate with other libraries –Matrix API, etc.
• leverage PMML as another kind of DSL
cascading.org/pattern
37Sunday, 17 March 13
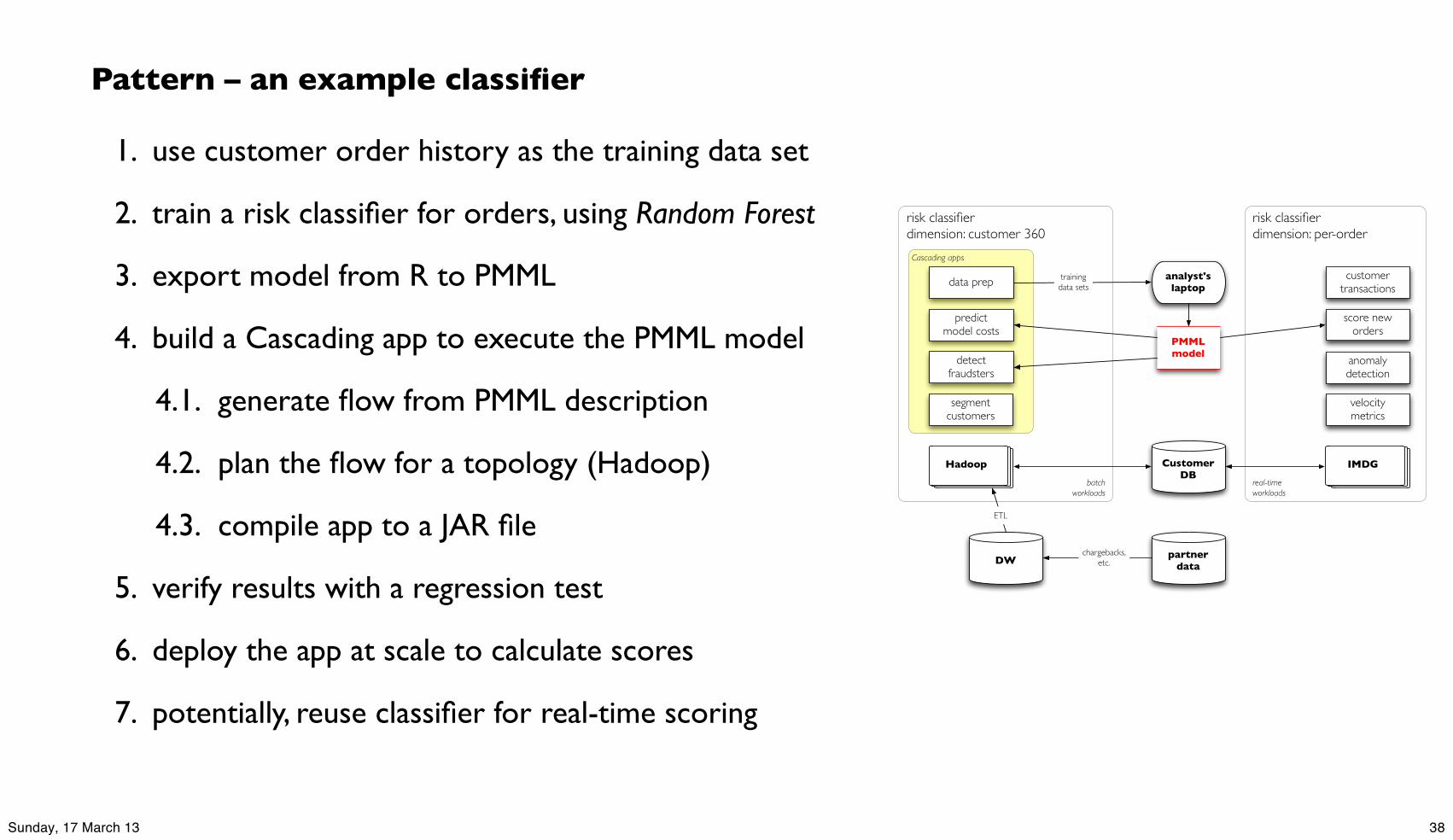
1. use customer order history as the training data set
2. train a risk classifier for orders, using Random Forest
3. export model from R to PMML
4. build a Cascading app to execute the PMML model
4.1. generate flow from PMML description
4.2. plan the flow for a topology (Hadoop)
4.3. compile app to a JAR file
5. verify results with a regression test
6. deploy the app at scale to calculate scores
7. potentially, reuse classifier for real-time scoring
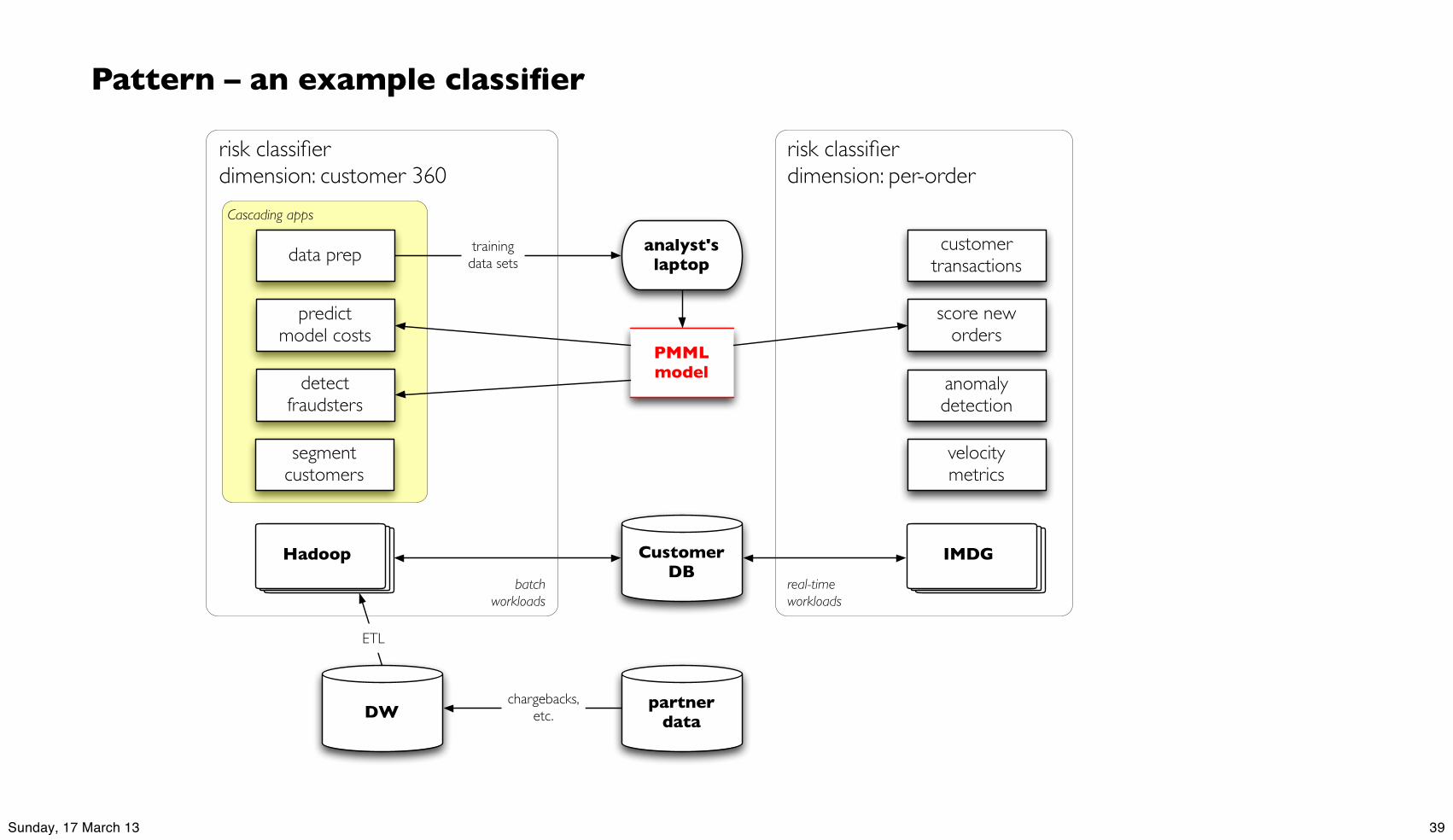
Pattern – an example classifier
Cascading apps
risk classifierdimension: per-order
risk classifierdimension: customer 360
PMML model
analyst'slaptopdata prep
detectfraudsters
predictmodel costs
customertransactions
score new orders
trainingdata sets
batchworkloads
real-timeworkloads
anomalydetection
segmentcustomers
IMDGHadoop
partner dataDW
ETL
chargebacks,etc.
CustomerDB
velocitymetrics
38Sunday, 17 March 13
Cascading apps
risk classifierdimension: per-order
risk classifierdimension: customer 360
PMML model
analyst'slaptopdata prep
detectfraudsters
predictmodel costs
customertransactions
score new orders
trainingdata sets
batchworkloads
real-timeworkloads
anomalydetection
segmentcustomers
IMDGHadoop
partner dataDW
ETL
chargebacks,etc.
CustomerDB
velocitymetrics
Pattern – an example classifier
39Sunday, 17 March 13

## train a RandomForest model f <- as.formula("as.factor(label) ~ .")fit <- randomForest(f, data_train, ntree=50) ## test the model on the holdout test set print(fit$importance)print(fit) predicted <- predict(fit, data)data$predicted <- predictedconfuse <- table(pred = predicted, true = data[,1])print(confuse) ## export predicted labels to TSV write.table(data, file=paste(dat_folder, "sample.tsv", sep="/"), quote=FALSE, sep="\t", row.names=FALSE) ## export RF model to PMML saveXML(pmml(fit), file=paste(dat_folder, "sample.rf.xml", sep="/"))
Pattern – create a model in R
40Sunday, 17 March 13

<?xml version="1.0"?><PMML version="4.0" xmlns="http://www.dmg.org/PMML-4_0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.dmg.org/PMML-4_0 http://www.dmg.org/v4-0/pmml-4-0.xsd"> <Header copyright="Copyright (c)2012 Concurrent, Inc." description="Random Forest Tree Model"> <Extension name="user" value="ceteri" extender="Rattle/PMML"/> <Application name="Rattle/PMML" version="1.2.30"/> <Timestamp>2012-10-22 19:39:28</Timestamp> </Header> <DataDictionary numberOfFields="4"> <DataField name="label" optype="categorical" dataType="string"> <Value value="0"/> <Value value="1"/> </DataField> <DataField name="var0" optype="continuous" dataType="double"/> <DataField name="var1" optype="continuous" dataType="double"/> <DataField name="var2" optype="continuous" dataType="double"/> </DataDictionary> <MiningModel modelName="randomForest_Model" functionName="classification"> <MiningSchema> <MiningField name="label" usageType="predicted"/> <MiningField name="var0" usageType="active"/> <MiningField name="var1" usageType="active"/> <MiningField name="var2" usageType="active"/> </MiningSchema> <Segmentation multipleModelMethod="majorityVote"> <Segment id="1"> <True/> <TreeModel modelName="randomForest_Model" functionName="classification" algorithmName="randomForest" splitCharacteristic="binarySplit"> <MiningSchema> <MiningField name="label" usageType="predicted"/> <MiningField name="var0" usageType="active"/> <MiningField name="var1" usageType="active"/> <MiningField name="var2" usageType="active"/> </MiningSchema>...
Pattern – capture model parameters as PMML
41Sunday, 17 March 13

public class Main { public static void main( String[] args ) { String pmmlPath = args[ 0 ]; String ordersPath = args[ 1 ]; String classifyPath = args[ 2 ]; String trapPath = args[ 3 ];
Properties properties = new Properties(); AppProps.setApplicationJarClass( properties, Main.class ); HadoopFlowConnector flowConnector = new HadoopFlowConnector( properties );
// create source and sink taps Tap ordersTap = new Hfs( new TextDelimited( true, "\t" ), ordersPath ); Tap classifyTap = new Hfs( new TextDelimited( true, "\t" ), classifyPath ); Tap trapTap = new Hfs( new TextDelimited( true, "\t" ), trapPath );
// define a "Classifier" model from PMML to evaluate the orders ClassifierFunction classFunc = new ClassifierFunction( new Fields( "score" ), pmmlPath ); Pipe classifyPipe = new Each( new Pipe( "classify" ), classFunc.getInputFields(), classFunc, Fields.ALL );
// connect the taps, pipes, etc., into a flow FlowDef flowDef = FlowDef.flowDef().setName( "classify" ) .addSource( classifyPipe, ordersTap ) .addTrap( classifyPipe, trapTap ) .addSink( classifyPipe, classifyTap );
// write a DOT file and run the flow Flow classifyFlow = flowConnector.connect( flowDef ); classifyFlow.writeDOT( "dot/classify.dot" ); classifyFlow.complete(); }}
Pattern – score a model, within an app
42Sunday, 17 March 13

CustomerOrders
Classify ScoredOrders
GroupBytoken
Count
PMMLModel
M R
FailureTraps
Assert
ConfusionMatrix
Pattern – score a model, using pre-defined Cascading app
43Sunday, 17 March 13

## run an RF classifier at scale hadoop jar build/libs/pattern.jar data/sample.tsv out/classify out/trap \ --pmml data/sample.rf.xml
## run an RF classifier at scale, assert regression test, measure confusion matrix hadoop jar build/libs/pattern.jar data/sample.tsv out/classify out/trap \ --pmml data/sample.rf.xml --assert --measure out/measure
## run a predictive model at scale, measure RMSE hadoop jar build/libs/pattern.jar data/iris.lm_p.tsv out/classify out/trap \ --pmml data/iris.lm_p.xml --rmse out/measure
Pattern – score a model, using pre-defined Cascading app
44Sunday, 17 March 13

bash-3.2$ head out/classify/part-00000 label"var0" var1" var2" order_id" predicted"score1" 0" 1" 0" 6f8e1014" 1" 10" 0" 0" 1" 6f8ea22e" 0" 01" 0" 1" 0" 6f8ea435" 1" 10" 0" 0" 1" 6f8ea5e1" 0" 01" 0" 1" 0" 6f8ea785" 1" 11" 0" 1" 0" 6f8ea91e" 1" 10" 1" 0" 0" 6f8eaaba" 0" 01" 0" 1" 0" 6f8eac54" 1" 10" 1" 1" 0" 6f8eade3" 1" 1
Pattern – evaluating results
45Sunday, 17 March 13

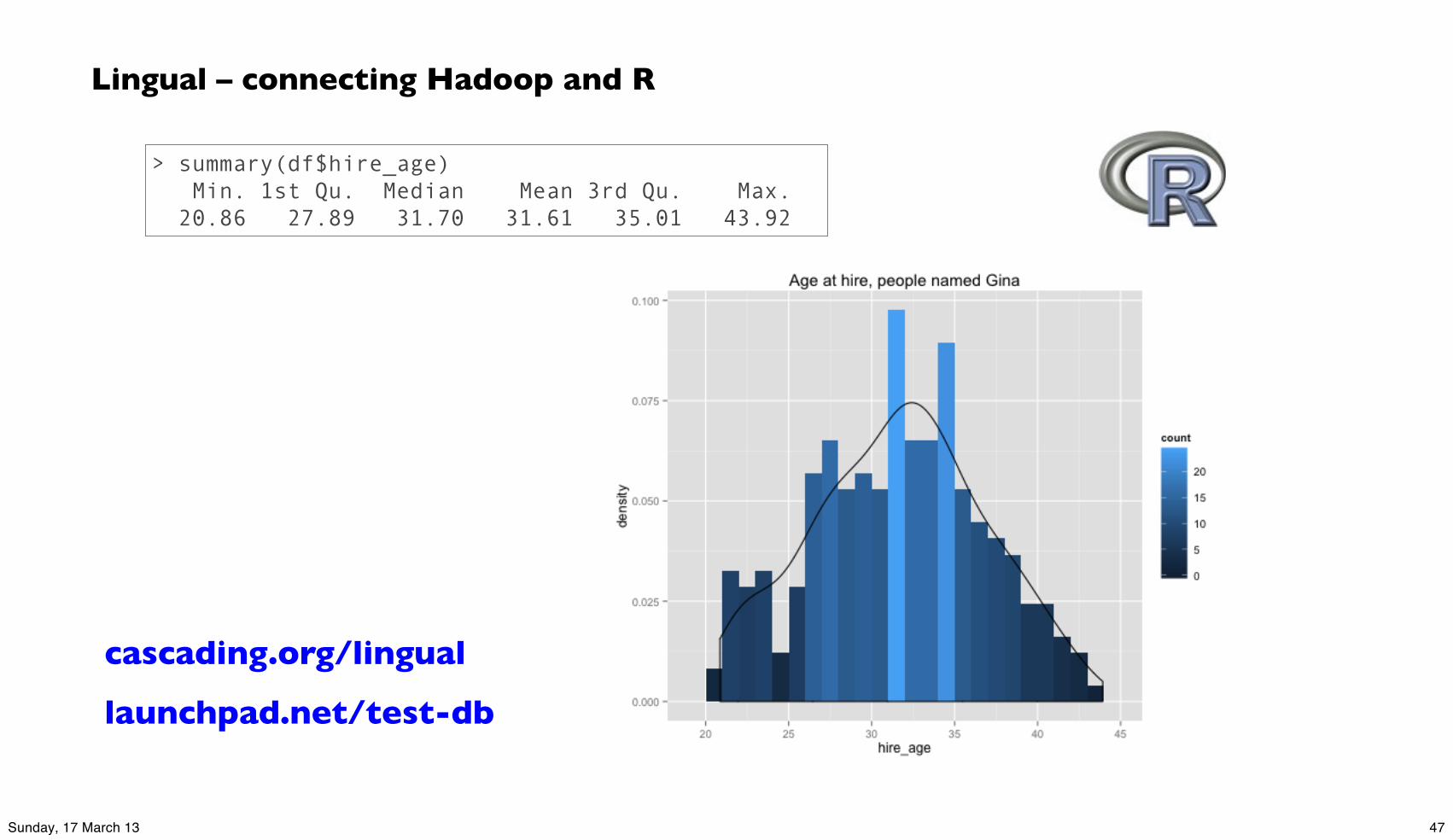
# load the JDBC packagelibrary(RJDBC) # set up the driverdrv <- JDBC("cascading.lingual.jdbc.Driver", "~/src/concur/lingual/lingual-local/build/libs/lingual-local-1.0.0-wip-dev-jdbc.jar") # set up a database connection to a local repositoryconnection <- dbConnect(drv, "jdbc:lingual:local;catalog=~/src/concur/lingual/lingual-examples/tables;schema=EMPLOYEES") # query the repository: in this case the MySQL sample database (CSV files)df <- dbGetQuery(connection, "SELECT * FROM EMPLOYEES.EMPLOYEES WHERE FIRST_NAME = 'Gina'")head(df) # use R functions to summarize and visualize part of the datadf$hire_age <- as.integer(as.Date(df$HIRE_DATE) - as.Date(df$BIRTH_DATE)) / 365.25summary(df$hire_age)
library(ggplot2)m <- ggplot(df, aes(x=hire_age))m <- m + ggtitle("Age at hire, people named Gina")m + geom_histogram(binwidth=1, aes(y=..density.., fill=..count..)) + geom_density()
Lingual – connecting Hadoop and R
46Sunday, 17 March 13
> summary(df$hire_age) Min. 1st Qu. Median Mean 3rd Qu. Max. 20.86 27.89 31.70 31.61 35.01 43.92
Lingual – connecting Hadoop and R
launchpad.net/test-db
cascading.org/lingual
47Sunday, 17 March 13

Scrubtoken
DocumentCollection
Tokenize
WordCount
GroupBytoken
Count
Stop WordList
Regextoken
HashJoinLeft
RHS
M
R
Pattern: predictive models at scale
• Enterprise Data Workflows• Sample Code• A Little Theory…• Pattern• PMML• Roadmap• Customer Experiments
48Sunday, 17 March 13

• established XML standard for predictive model markup
• organized by Data Mining Group (DMG), since 1997 http://dmg.org/
• members: IBM, SAS, Visa, NASA, Equifax, Microstrategy, Microsoft, etc.
• PMML concepts for metadata, ensembles, etc., translate directly into Cascading tuple flows
“PMML is the leading standard for statistical and data mining models and supported by over 20 vendors and organizations. With PMML, it is easy to develop a model on one system using one application and deploy the model on another system using another application.”
PMML – standard
wikipedia.org/wiki/Predictive_Model_Markup_Language
49Sunday, 17 March 13

• Association Rules: AssociationModel element
• Cluster Models: ClusteringModel element
• Decision Trees: TreeModel element
• Naïve Bayes Classifiers: NaiveBayesModel element
• Neural Networks: NeuralNetwork element
• Regression: RegressionModel and GeneralRegressionModel elements
• Rulesets: RuleSetModel element
• Sequences: SequenceModel element
• Support Vector Machines: SupportVectorMachineModel element
• Text Models: TextModel element
• Time Series: TimeSeriesModel element
PMML – models
ibm.com/developerworks/industry/library/ind-PMML2/
50Sunday, 17 March 13

PMML – vendor coverage
51Sunday, 17 March 13

Scrubtoken
DocumentCollection
Tokenize
WordCount
GroupBytoken
Count
Stop WordList
Regextoken
HashJoinLeft
RHS
M
R
Pattern: predictive models at scale
• Enterprise Data Workflows• Sample Code• A Little Theory…• Pattern• PMML• Roadmap• Customer Experiments
52Sunday, 17 March 13

roadmap – existing algorithms for scoring
• Random Forest
• Decision Trees
• Linear Regression
• GLM
• Logistic Regression
• K-Means Clustering
• Hierarchical Clustering
• Support Vector Machines
cascading.org/pattern
53Sunday, 17 March 13

roadmap – top priorities for creating models at scale
• Random Forest
• Logistic Regression
• K-Means Clustering
a wealth of recent research indicates many opportunities to parallelize popular algorithms for training models at scale on Apache Hadoop…
cascading.org/pattern
54Sunday, 17 March 13

roadmap – next priorities for scoring
• Time Series (ARIMA forecast)
• Association Rules (basket analysis)
• Naïve Bayes
• Neural Networks
algorithms extended based on customer use cases – contact @pacoid
cascading.org/pattern
55Sunday, 17 March 13

Scrubtoken
DocumentCollection
Tokenize
WordCount
GroupBytoken
Count
Stop WordList
Regextoken
HashJoinLeft
RHS
M
R
Pattern: predictive models at scale
• Enterprise Data Workflows• Sample Code• A Little Theory…• Pattern• PMML• Roadmap• Customer Experiments
56Sunday, 17 March 13

experiments – comparing models
• much customer interest in leveraging Cascading and Apache Hadoop to run customer experiments at scale
• run multiple variants, then measure relative “lift”
• Concurrent runtime – tag and track models
the following example compares two models trained with different machine learning algorithms
this is exaggerated, one has an important variable intentionally omitted to help illustrate the experiment
57Sunday, 17 March 13

## train a Random Forest model## example: http://mkseo.pe.kr/stats/?p=220 f <- as.formula("as.factor(label) ~ var0 + var1 + var2")fit <- randomForest(f, data=data, proximity=TRUE, ntree=25)print(fit)saveXML(pmml(fit), file=paste(out_folder, "sample.rf.xml", sep="/"))
experiments – Random Forest model
OOB estimate of error rate: 14%Confusion matrix: 0 1 class.error0 69 16 0.18823531 12 103 0.1043478
58Sunday, 17 March 13
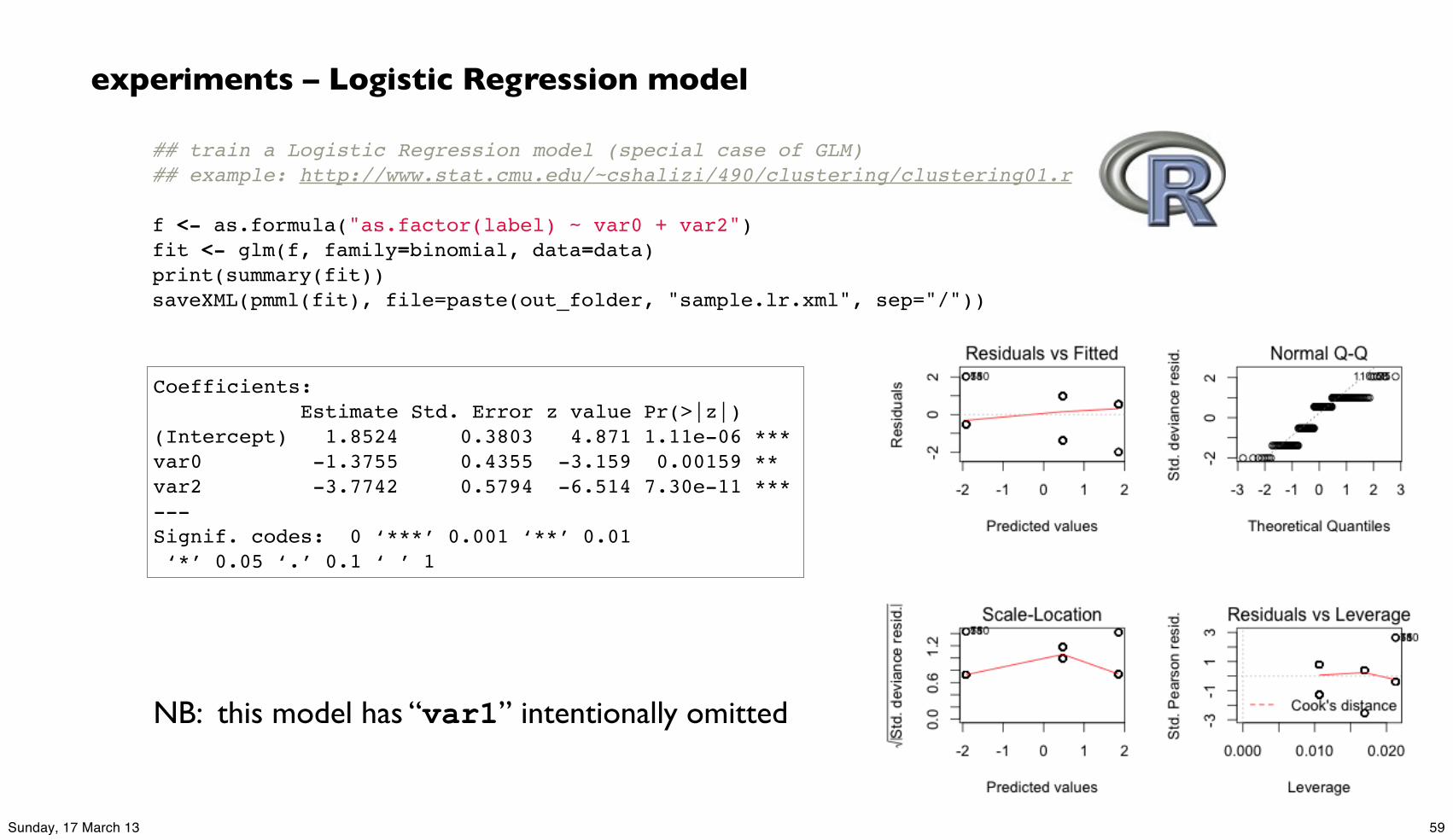
## train a Logistic Regression model (special case of GLM)## example: http://www.stat.cmu.edu/~cshalizi/490/clustering/clustering01.r f <- as.formula("as.factor(label) ~ var0 + var2")fit <- glm(f, family=binomial, data=data)print(summary(fit))saveXML(pmml(fit), file=paste(out_folder, "sample.lr.xml", sep="/"))
experiments – Logistic Regression model
Coefficients: Estimate Std. Error z value Pr(>|z|) (Intercept) 1.8524 0.3803 4.871 1.11e-06 ***var0 -1.3755 0.4355 -3.159 0.00159 ** var2 -3.7742 0.5794 -6.514 7.30e-11 ***---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
NB: this model has “var1” intentionally omitted
59Sunday, 17 March 13

experiments – comparing results
• use a confusion matrix to compare results for the classifiers
• Logistic Regression has a lower “false negative” rate (5% vs. 11%)however it has a much higher “false positive” rate (52% vs. 14%)
• assign a cost model to select a winner –for example, in an ecommerce anti-fraud classifier:
FN ∼ chargeback risk FP ∼ customer support costs
60Sunday, 17 March 13

Enterprise Data Workflowswith Cascading
O’Reilly, 2013amazon.com/dp/1449358721
references…
61Sunday, 17 March 13

blog, dev community, code/wiki/gists, maven repo, commercial products, career opportunities:
cascading.org
zest.to/group11
github.com/Cascading
conjars.org
goo.gl/KQtUL
concurrentinc.com
drill-down…
Copyright @2013, Concurrent, Inc.
62Sunday, 17 March 13