十一章 複因子試驗
DESCRIPTION
十一章 複因子試驗. Factorial Design : 研究因子超過一個,在設計上 安排因子 水準間之每一組合至少有一組觀察值,且實驗順序隨機。 特點: (1) 可同時試驗幾種因子自身的效應 (2) 可求因子間相互的影響 (3) 增加各因子重複次數,減少試驗誤差. Main Effect ( 主效應) : 對某一因子,因子水準的變換對觀察值 的影響。 Interaction ( 交互作用,交感效應) : 一因子對另一因子變化的影響力。 - PowerPoint PPT PresentationTRANSCRIPT
十一章 複因子試驗
• Factorial Design : 研究因子超過一個,在設計上安排因子 水準間之每一組合至少有一組觀察值,且實驗順序隨機。
特點:
(1) 可同時試驗幾種因子自身的效應 (2) 可求因子間相互的影響 (3) 增加各因子重複次數,減少試驗誤差
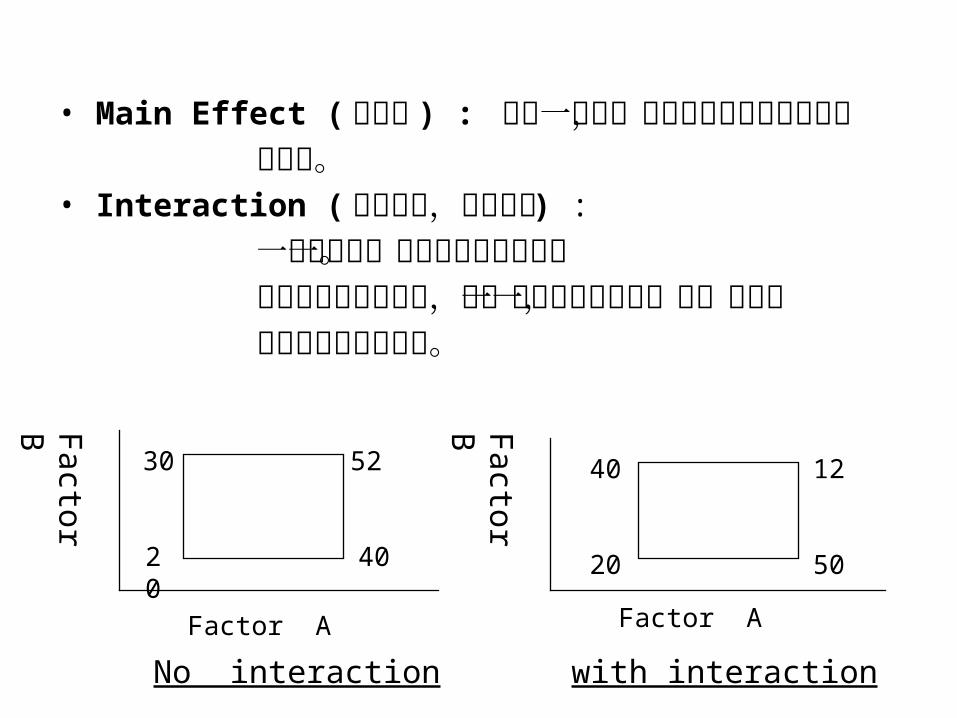
• Main Effect ( 主效應 ) : 對某一因子,因子水準的變換對觀察值 的影響。 • Interaction ( 交互作用,交感效應 ) :
一因子對另一因子變化的影響力。 某因子在不同水準下,另一因子之變化並不一致,此時稱 二因子間有交互作用。
No interaction with interaction
Factor
B
Factor A
20
1230
40
52
20
40
50
Factor A
Factor
B

研究問題
• Is any interaction between the two factors?
• Is there any main effect?
• If the effect is significant, what is the situation?
• Which treatment combination will has the most effort?
註 : 若二 factors 為 quantitative ,則可用迴歸分析尋求 觀察值對各 factor 之關係式;如:求 response surface, 進而得到最大或最小值。
2-factor factorial Design
設計
依實驗材質選擇 CRD, RCBD 或 LSD.

Model (2-factor Complete Randomized Factorial Design )
Yijk = μ + αi +βj+ (αβ)ij + εijk , i= 1,...,a, j= 1,…,b
μ 整體實驗的共同影響 αi 因子 A 第 i 項水準的影響力 βj 因子 B 第 j 項水準的影響力(αβ) 交互作用力
Source df SS MS F p-value
Factor A a-1 SSA MSA MSA /MSE pA
Factor B b-1 SSB MSB MSB /MSE pB
AB interaction(a-1)(b-1) SSAB MSAB MSAB /MSE pAB
Error ab(n-1) SSE MSE
Total abn-1 SST
ANOVA table for axb factorial design

若 pAB < 0.05 ,則 AB 交互作用顯著若 pA < 0.05 ,則因子 A 的影響顯著若 pB < 0.05 ,則因子 B 的影響顯著
Multiple Comparisons
A. No interaction
方法如 1-factor experiment.
B. Interaction is significant
1. 作圖,觀察交互作用。 2. 所有因子 A 與 因子 B 的組合間,互作比較。 3. 固定某一因子,對另一因子分析。

SPSS: 分析 → 一般線性模式 → 單變量 模式 :使用標準式,不需自訂 圖形 :某一因子為 X- 軸,另一因子為個別線Post Hoc 檢定:只有 2 levels 之因子不必作對對比較 比對 :針對數量型因子,選擇線性及二次關係之檢定。 儲存 :殘差標準化 選項 :同質性檢定 效果項大小估計值
常態性檢定:分析 → 統計值 → 預檢資料 統計圖 v 常態機率圖附檢定
一般 factorial design, SPSS 之初步執行指令
若交互作用顯著,則應進行資料分組之分析。

1. 輸入資料: Insert 每一因子佔一行,測值或觀察資料佔一行。
2. 分析: Analysis → ANOVA → Linear Models Columns :指定 Dependent variables Classification variables
Model Builder : Effects 含主效應及交互作用項 Model Options:ˇ TYPE III
Post-Hoc tests : → Least Squares → Add Effects
─ Effects 選欲比較的效應項─ Comparisons 選擇方法
SAS Enterprise Guide --- 複因子資料

Plots : Predictions: Data to predict ˇoriginal sample Additional Statistics ˇResiduals Save output data ˇPredictions
3. 檢查誤差的常態性: 選擇 prediction 資料 Analysis → Descriptive → Distribution Analysis Columns :選擇 student_ 為分析變數 Distribution : ˇ Normal Plots :ˇ Probability plot
Results : → Add New Table 加入 Test for normality 刪除其他
4. 若交互作用顯著時,可增加比較交互作用項。
Post-Hoc tests : → Least Squares→ Add Effects
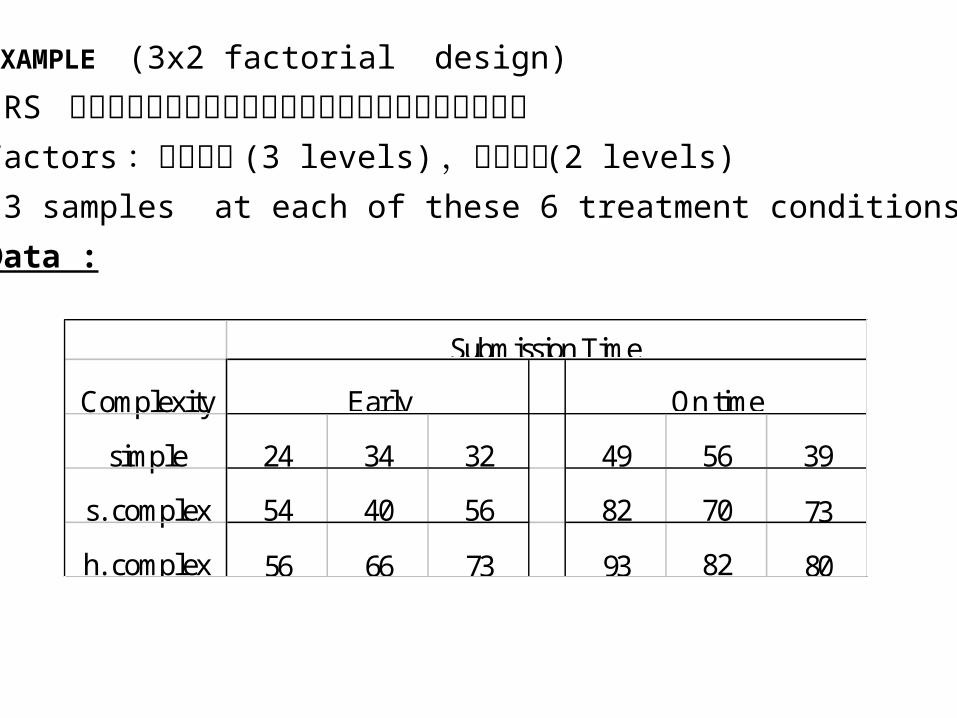
EXAMPLE (3x2 factorial design)
IRS 研究表格複雜程度與交表時間對所得稅作業時間的影響Factors :複雜程度 (3 levels) ,交表時間 (2 levels) 3 samples at each of these 6 treatment conditions
Data :
Complexity
simple 24 34 32 49 56 39
s. complex 54 40 56 82 70 73
h. complex 56 66 73 93 82 80
Early On time
Submission Time
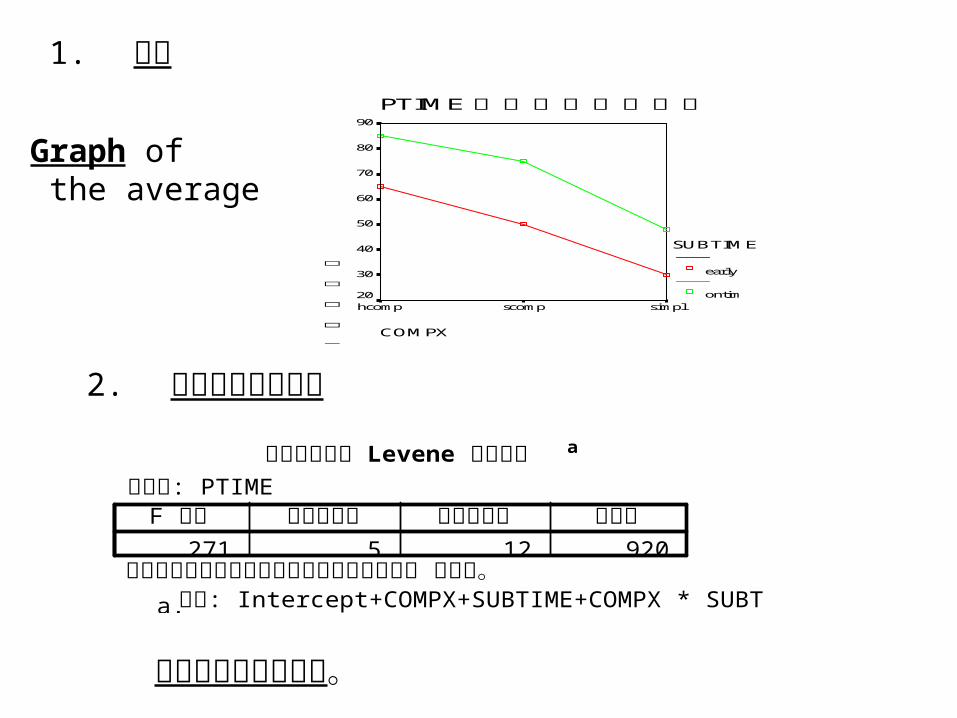
Graph of the average
Levene 誤差變異量的 檢定等式a
: PTIME依變數
.271 5 12 .920F 檢定 分子自由度 分母自由度 顯著性
檢定各組別中依變數誤差變異量的虛無假設是 相等的。: Intercept+COMPX+SUBTIME+COMPX * SUBTIME設計a.
2. 變異數同質性檢定
1. 圖形
各組資料變異數相同。
PTIME 的估計邊緣平均數
COMPX
simplscomphcomp
估計邊緣平均數
90
80
70
60
50
40
30
20
SUBTIME
early
ontim

常態檢定
.126 18 .200* .918 18 .138PTIME Studentized 的 殘差統計量 自由度 顯著性 統計量 自由度 顯著性
Kolmogorov-Smirnov檢定a Shapiro-Wilk 常態性檢定
此為真顯著性的下限。*. Lilliefors 顯著性校正a.
PTIME Studentized Q-Q 的 殘差的常態 圖
觀察值
2.01.51.0.50.0-.5-1.0-1.5-2.0期望次數常態
2.0
1.5
1.0
.5
0.0
-.5
-1.0
-1.5
-2.0
3. Normality
資料未違背常態性假設

依據 ANOVA ,
1. 無証據顯示有交互作用存在。 2. 交表時間與表格複雜程度對平均作業時間有顯著影響。
受試者間效應項的檢定
: PTIME依變數
6032.500a 5 1206.500 21.417 .00062304.500 1 62304.500 1105.997 .0004009.000 2 2004.500 35.583 .0001984.500 1 1984.500 35.228 .000
39.000 2 19.500 .346 .714676.000 12 56.333
69013.000 186708.500 17
來源校正後的模式截距COMPXSUBTIMECOMPX * SUBTIME誤差總和校正後的總數
III 型 平方和 自由度 平均平方和 F 檢定 顯著性
R = .899 ( R = .857)平方 調過後的 平方a.
4. ANOVA
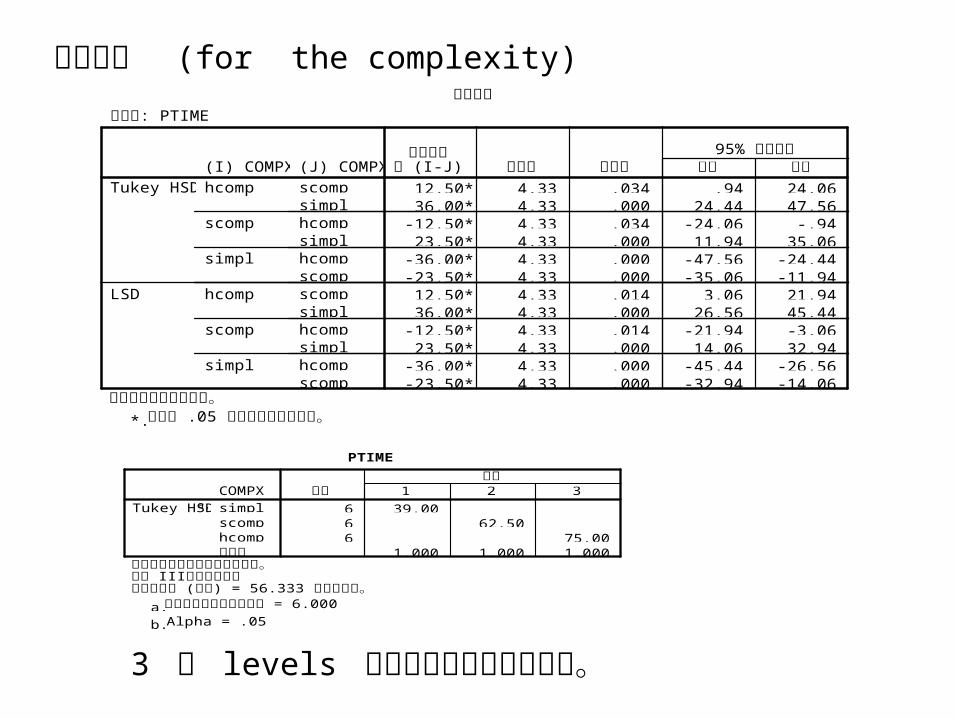
3 種 levels 中任二種間皆有顯著差異。
多重比較
: PTIME依變數
12.50* 4.33 .034 .94 24.0636.00* 4.33 .000 24.44 47.56
-12.50* 4.33 .034 -24.06 -.9423.50* 4.33 .000 11.94 35.06
-36.00* 4.33 .000 -47.56 -24.44-23.50* 4.33 .000 -35.06 -11.9412.50* 4.33 .014 3.06 21.9436.00* 4.33 .000 26.56 45.44
-12.50* 4.33 .014 -21.94 -3.0623.50* 4.33 .000 14.06 32.94
-36.00* 4.33 .000 -45.44 -26.56-23.50* 4.33 .000 -32.94 -14.06
(J) COMPXscompsimplhcompsimplhcompscompscompsimplhcompsimplhcompscomp
(I) COMPXhcomp
scomp
simpl
hcomp
scomp
simpl
Tukey HSD
LSD
平均數差 (I-J)異 標準誤 顯著性 下限 上限
95% 信賴區間
以觀察的平均數為基礎。 .05 在水準 上的平均數差異顯著。*.
PTIME
6 39.006 62.506 75.00
1.000 1.000 1.000
COMPXsimplscomphcomp顯著性
Tukey HSDa,b個數 1 2 3
子集
同質子集中組別的平均數已顯示。 III以型 平方和為基礎
( ) = 56.333 平均平方和 誤差 中的誤差項。 = 6.000使用調和平均數樣本大小a.
Alpha = .05b.
5. 對對比較 (for the complexity)
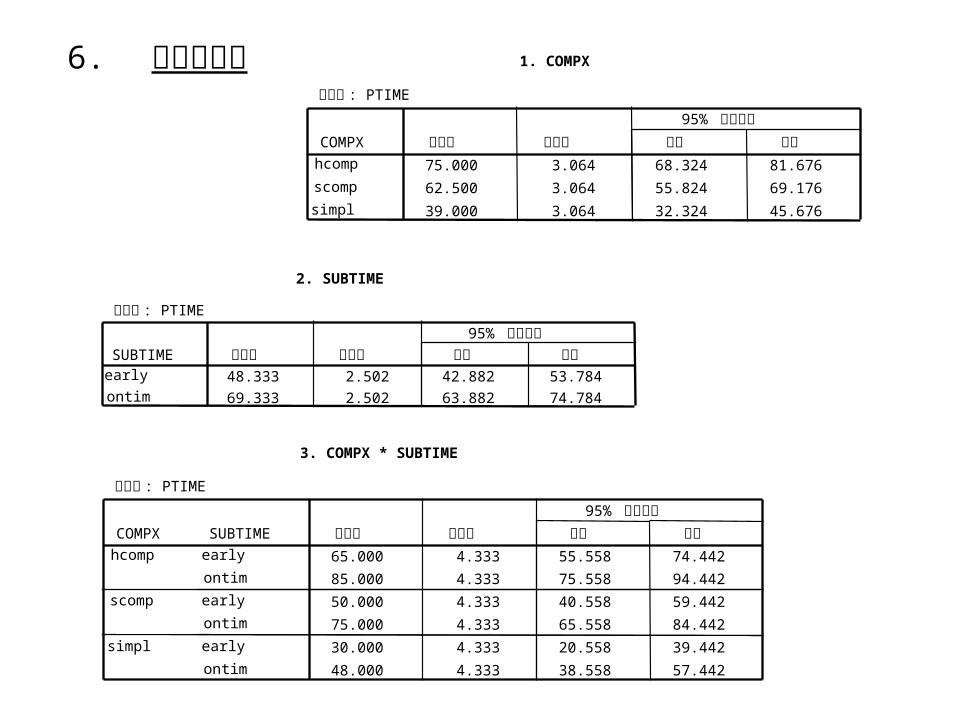
6. 平均質估計 1. COMPX
依變數 : PTIME
75.000 3.064 68.324 81.67662.500 3.064 55.824 69.17639.000 3.064 32.324 45.676
COMPX
hcomp
scomp
simpl
平均數 標準誤 下限 上限95% 信賴區間
2. SUBTIME
依變數 : PTIME
48.333 2.502 42.882 53.78469.333 2.502 63.882 74.784
SUBTIMEearly
ontim
平均數 標準誤 下限 上限95% 信賴區間
3. COMPX * SUBTIME
依變數 : PTIME
65.000 4.333 55.558 74.44285.000 4.333 75.558 94.44250.000 4.333 40.558 59.44275.000 4.333 65.558 84.44230.000 4.333 20.558 39.44248.000 4.333 38.558 57.442
SUBTIME
early
ontim
early
ontim
early
ontim
COMPX
hcomp
scomp
simpl
平均數 標準誤 下限 上限95% 信賴區間

7. 總結: (1) 繳表時間與表格之複雜度對其填表之費時無交互作用。 (2) 在不同時間繳交稅表,其填表之費時有顯著不同,提早繳表者 其填表之費時較短,均值分別為 48.3 及 67.3 。 (3) 三種表格之複雜度對其填表之費時皆有顯著不同,愈複雜費時 愈多,均值分別為 39, 62.5 及 75 。 (4) 提早繳表使用簡單格式者,費時最少,平均費時 30 及時繳表使用高度複雜格式者,費時最多,平均費時 85 各狀況之平均費時及標準差估計如下
Complexity Early On time
simple 30±4.33 48±4.33
s. complex 50±4.33 75±4.33
h. complex 65±4.33 85±4.33
Sub time

EXAMPLE (factorial design)
設下列資料為老鼠在不同時間及餵食維他命 B1 不同劑量所得之增重結果,問 (1) 老鼠在不同時間餵以 B1有否不同反應,(2)B1 劑量不同對其增加重量有無效果, (3) 不同時間餵以不同量之 B1,是否得到不同的效果, (4) 若時間與 B1劑量間有交互作用,以何時何量最為適當。
時間
上午 2. 5 2. 6 3. 8 4. 5 5.5 6.0
8am 2.4 2.7 4.2 4.0 4.8 5.0
下午 1. 9 2.2 2. 6 3. 0 3.6 3.95pm 2.2 2.0 3.5 2.8 3.5 4.2
B1 維他命劑量
10 ug 20ug 30ug
Factors : 維他命劑量 (3 levels) ,餵食時間 (2 levels)

資料圖形
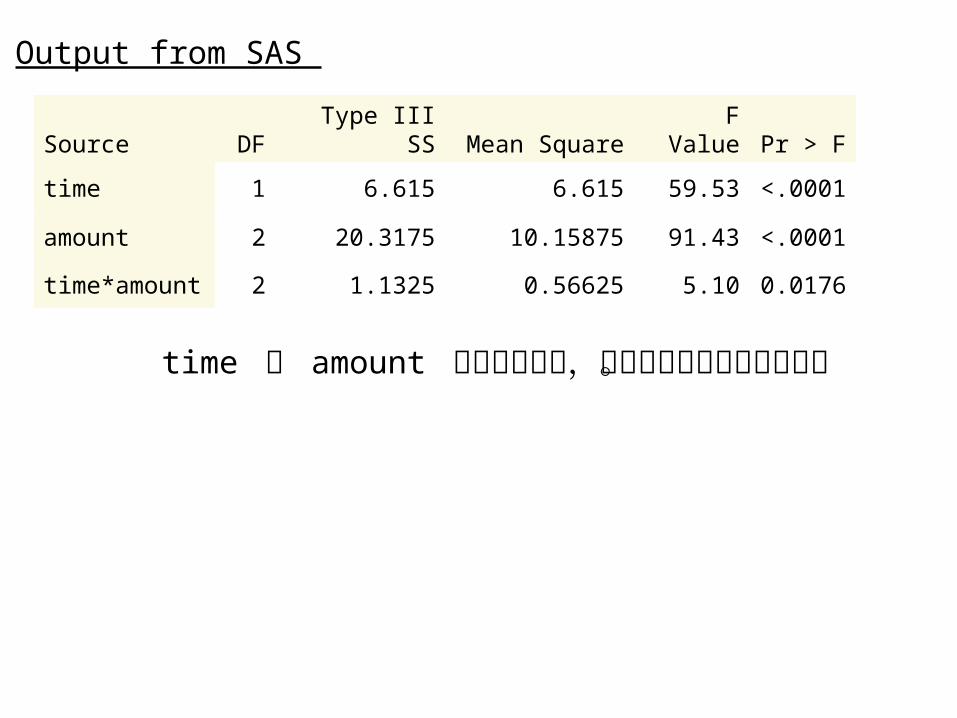
Source DFType III
SS Mean SquareF
Value Pr > F
time 1 6.615 6.615 59.53 <.0001
amount 2 20.3175 10.15875 91.43 <.0001
time*amount 2 1.1325 0.56625 5.10 0.0176
Output from SAS
time 及 amount 的主效應顯著,二因子的交互作用也顯著。
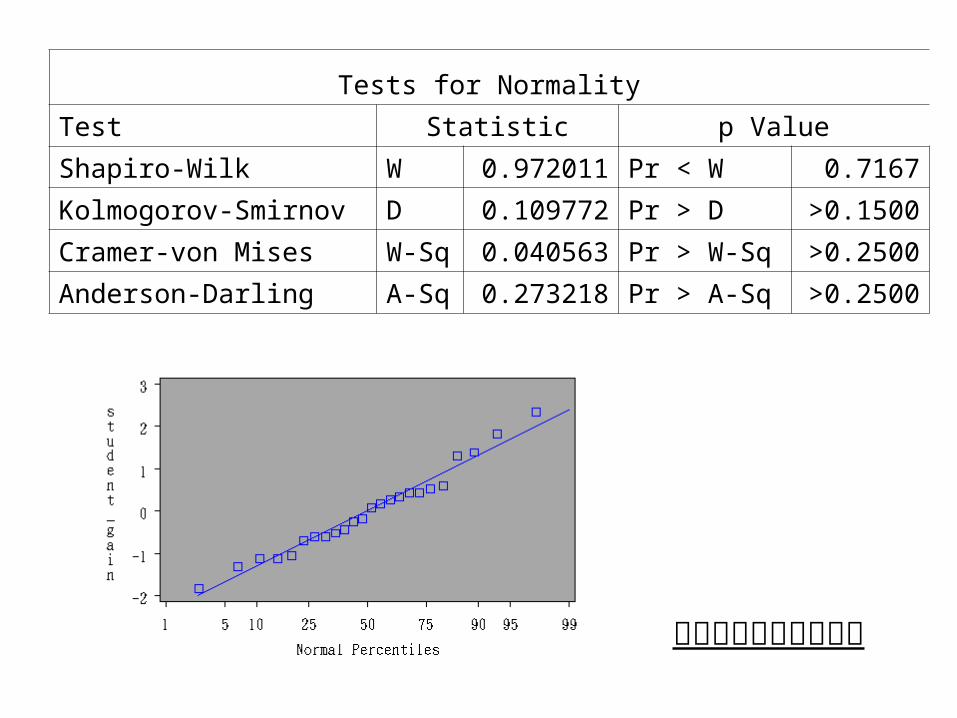
Tests for Normality
Test Statistic p Value
Shapiro-Wilk W 0.972011 Pr < W 0.7167
Kolmogorov-Smirnov D 0.109772 Pr > D >0.1500
Cramer-von Mises W-Sq 0.040563 Pr > W-Sq >0.2500
Anderson-Darling A-Sq 0.273218 Pr > A-Sq >0.2500
資料未違背常態性假設

The GLM Procedure
Least Squares Means
Adjustment for Multiple Comparisons: Tukey
time amount gain LSMEAN LSMEAN Number
a 10 2.55000000 1
a 20 4.12500000 2
a 30 5.32500000 3
b 10 2.07500000 4
b 20 2.97500000 5
b 30 3.80000000 6
因交互作用力顯著,可選擇:( 一 ) 針對六組合處理做對對比較

Least Squares Means for effect time*amountPr > |t| for H0: LSMean(i)=LSMean(j)
Dependent Variable: gain
i/j 1 2 3 4 5 6
1 <.0001 <.0001 0.3720 0.4880 0.0006
2 <.0001 0.0009 <.0001 0.0014 0.7385
3 <.0001 0.0009 <.0001 <.0001 <.0001
4 0.3720 <.0001 <.0001 0.0135 <.0001
5 0.4880 0.0014 <.0001 0.0135 0.0261
6 0.0006 0.7385 <.0001 <.0001 0.0261
六組合處理對對比較的 p- 值
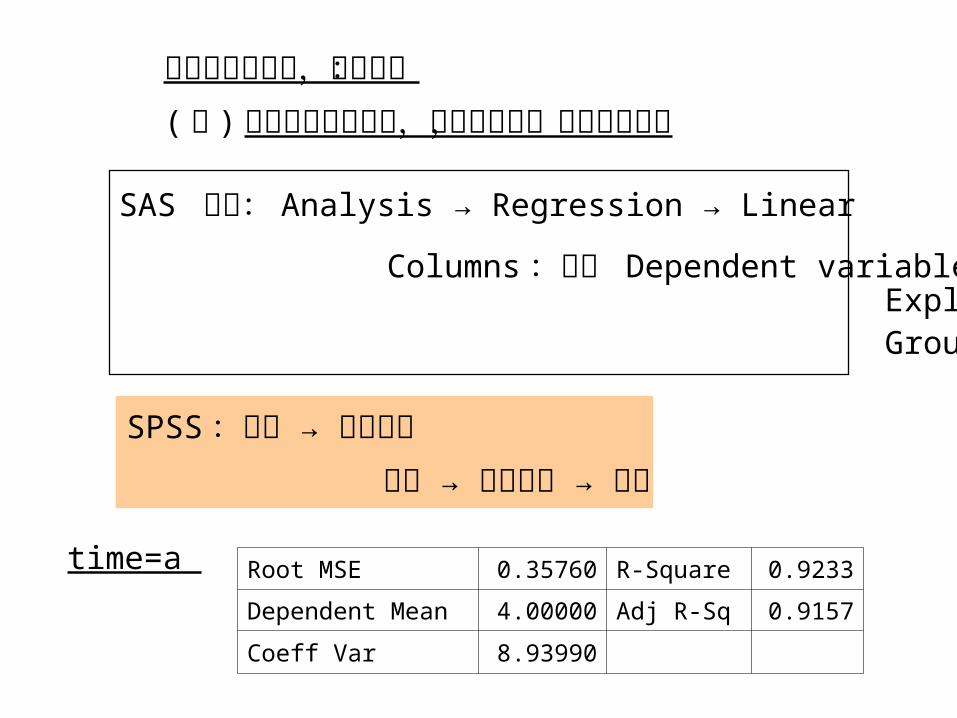
因交互作用顯著,可選擇:( 二 ) 尋求上午及下午時,劑量的影響,使用迴歸分析
SAS 步驟: Analysis → Regression → Linear
Columns :指定 Dependent variables Explainatory variables Group
time=a Root MSE 0.35760 R-Square 0.9233
Dependent Mean 4.00000 Adj R-Sq 0.9157
Coeff Var 8.93990
SPSS :資料 → 分割檔案 分析 → 迴歸方法 → 線性

Parameter Estimates
Variable DFParameterEstimate
StandardError t Value
Pr > |t|
Intercept 1 1.22500 0.27312 4.49 0.0012
amount 1 0.13875 0.01264 10.97 <.0001
Root MSE 0.28614 R-Square 0.8791
Dependent Mean 2.95000 Adj R-Sq 0.8670
Coeff Var 9.69960
Parameter Estimates
Variable DFParameterEstimate
StandardError t Value
Pr > |t|
Intercept 1 1.22500 0.21854 5.61 0.0002
amount 1 0.08625 0.01012 8.53 <.0001
time=b gain = 1.23 + 0.139 (amount)
gain = 1.23 + 0.0863 (amount)

觀察平均數的圖形 1. 增重與 B1 攝取量有直線關係。 2. 早上與下午得到的直線趨勢並不平行,故在 ANOVA 上, 顯示 interacting effect
3. 如果接受交互作用存在,可找出二條關係直線,得到 B1 攝取量影響程度的差異。
依據 ANOVA
1. The interacting effect is significant at α=0.05.
2. The effects of the vitamin B1 and the feeding time are both significant.

總結:
(1) 餵食時間對增重有顯著影響。早上餵食效果較佳。
(2)B1 劑量對增重有顯著影響。多量比少量的效果佳。
(3) 在 α=0.05 ,交互作用存在,不同時間餵以不同量之 B1,效果不同。
(4) 時間與 B1 劑量間有交互作用,上午餵食 30μg 效果最佳。
(5) 在認定交互作用存在之情況, 對早上 8am 餵食, 增重 = 1.23 + 0.139( 劑量 ), R2 = 0.923 對下午 5pm 餵食, 增重 = 1.23 + 0.0863( 劑量 ), R2 = 0.879 早上每一 μg B1 的效果估計為 0.139 ,下午則為 0.0863 。
(6) 六組合比較結果:早上餵 10μg 與下午餵 10μg 的效果無差異, 早上餵 10μg 與下午餵 20μg 的效果無差異, 早上餵 20μg 與下午餵 30μg 的效果無差異, 其餘各組間有顯著差異。

Model (2-factor Randomize Complete Block Factorial Design )
Yijk = μ + αi +βj+ (αβ)ij +γk + εijk , i= 1,...,a, j= 1,…,b
k = 1,…,c
μ 整體實驗的共同影響 αi 因子 A 第 i 項水準的效應力 βj 因子 B 第 j 項水準的效應力(αβ) 交感效應力 γ 區集效應力
隨機完全區集複因子試驗

若 pAB < 0.05 ,則 AB 交感效應力顯著若 pA < 0.05 ,則因子 A 的影響顯著若 pB < 0.05 ,則因子 B 的影響顯著
Source df SS MS F p-valueBlock c-1
Factor A a-1 SSA MSA MSA /MSE pA
Factor B b-1 SSB MSB MSB /MSE pB
AB interaction (a-1)(b-1) SSAB MSAB MSAB /MSE pAB
Error (c-1)(ab-1) SSE MSE
ANOVA table

EXAMPLE 11.2 (randomized complete block 3x2 factorial design)
研究水稻品種與氮肥對產量的影響,選擇水稻二品種,氮肥三種份量,分四區集試驗,每一區集以隨機方式安排此 6個處方。Factors :水稻品種 (2 levels) ,氮肥 (3 levels) 4 blocks
Data :
N1 N2 N3 N1 N2 N3
Block 1 6 14 11 9 13 6
Block 2 8 13 9 10 15 8
Block 3 7 14 12 11 16 5
Block 4 9 12 9 7 14 6
品種 1 品種 2
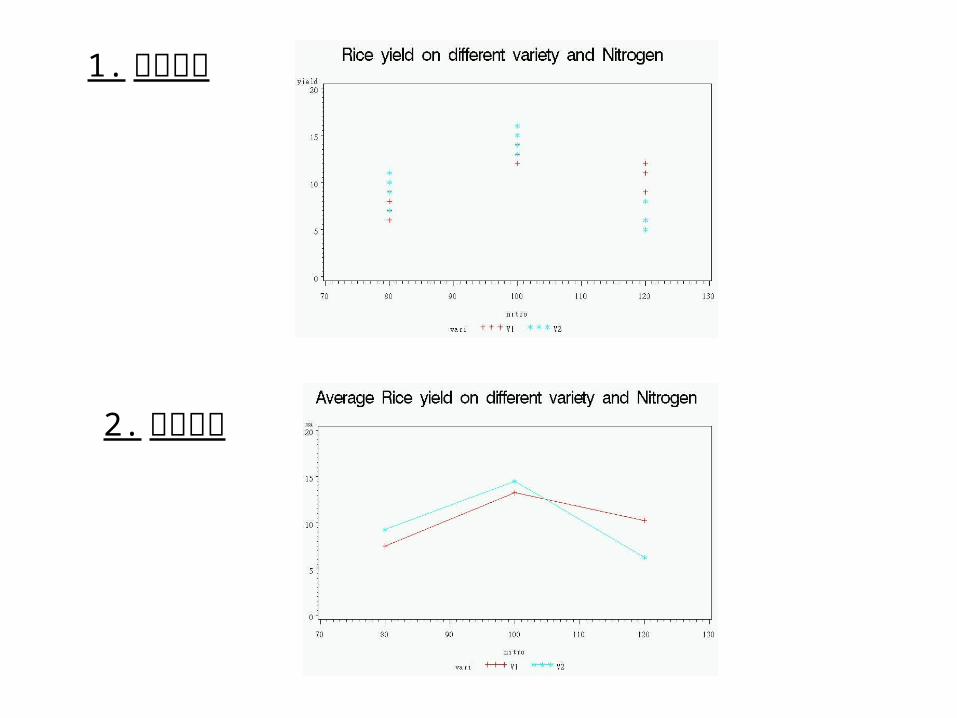
1. 資料分布
2. 均值分布

3. Normality
資料未違背常態性假設
Tests for Normality
Test --Statistic--- -----p Value------
Shapiro-Wilk W 0.962919 Pr < W 0.4998 Kolmogorov-Smirnov D 0.156039 Pr > D 0.1330 Cramer-von Mises W-Sq 0.067884 Pr > W-Sq >0.2500 Anderson-Darling A-Sq 0.399561 Pr > A-Sq >0.2500
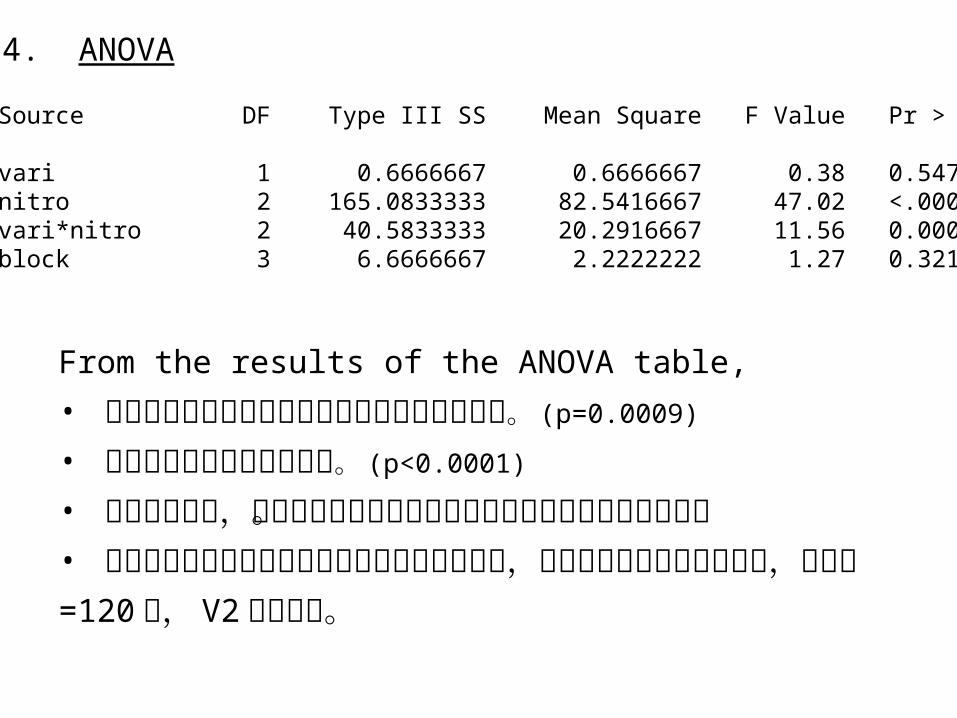
From the results of the ANOVA table,
• 水稻品種與氮肥對產量的影響有顯著的交感效應。 (p=0.0009)• 氮肥對產量的影響是顯著的。 (p<0.0001) • 由於交感效應,在變方分析中無法檢定出品種對產量的影響的顯著性。• 由均值圖看出氮肥對產量的影響是先上升再下降,不同品種對氮肥的反應不同,氮肥量 =120時, V2下降較快。
4. ANOVA
Source DF Type III SS Mean Square F Value Pr > F
vari 1 0.6666667 0.6666667 0.38 0.5470 nitro 2 165.0833333 82.5416667 47.02 <.0001 vari*nitro 2 40.5833333 20.2916667 11.56 0.0009 block 3 6.6666667 2.2222222 1.27 0.3217
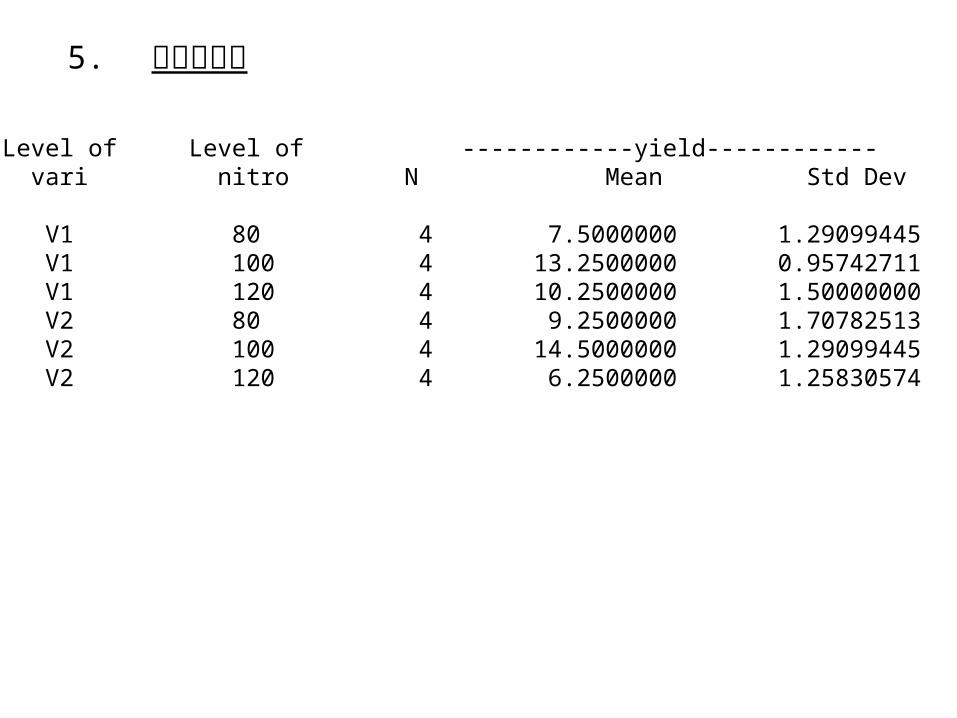
5. 平均值估計
Level of Level of ------------yield------------ vari nitro N Mean Std Dev
V1 80 4 7.5000000 1.29099445 V1 100 4 13.2500000 0.95742711 V1 120 4 10.2500000 1.50000000 V2 80 4 9.2500000 1.70782513 V2 100 4 14.5000000 1.29099445 V2 120 4 6.2500000 1.25830574
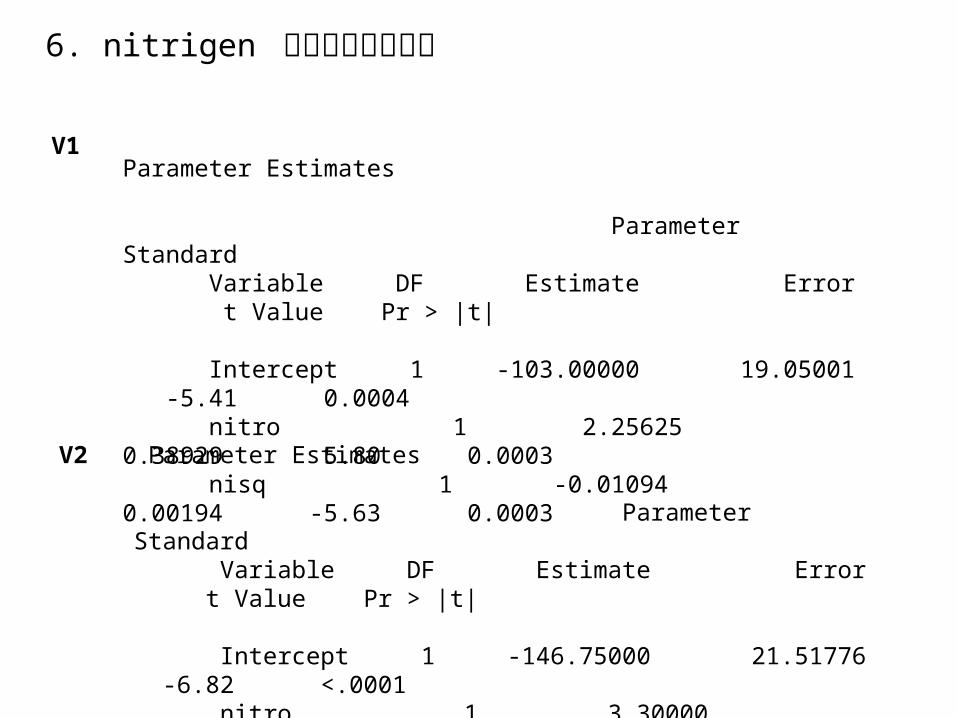
Parameter Estimates
Parameter Standard Variable DF Estimate Error t Value Pr > |t|
Intercept 1 -103.00000 19.05001 -5.41 0.0004 nitro 1 2.25625 0.38929 5.80 0.0003 nisq 1 -0.01094 0.00194 -5.63 0.0003
Parameter Estimates Parameter Standard Variable DF Estimate Error t Value Pr > |t|
Intercept 1 -146.75000 21.51776 -6.82 <.0001 nitro 1 3.30000 0.43972 7.50 <.0001 nisq 1 -0.01688 0.00219 -7.69 <.000
V1
V2
6. nitrigen 對產量的二次關係

7. 總結: (1) 氮肥用量對水稻收成量的影響是一曲線關係。 (2) V1 與 V2 二品種對氮肥的反應不同, V1 為較耐肥品種, V2 則為不耐肥品種。 (3) 若以二次曲線估計水稻收成量,得到 V1 : 收成量 = -103 + 2.26( 氮肥量 )-0.011( 氮肥量 )2 , R2=0.82
估計在氮肥量 =102.7 時,收成量最佳。 V2 : 收成量 = -147 + 3.30( 氮肥量 )-0.017( 氮肥量 )2 , R2=0.88
估計在氮肥量 =97.0 時,收成量最佳。