はじパタ11章 後半
TRANSCRIPT

第14回「はじめてのパターン認識」読書会
第11章 識別器の組み合わせによる性能強化後編
@gepuro

●

11.3 バギング
● 複数の識別器を組み合わせる方法
– 学習データのブートストラップサンプル(復元抽出)を用いて複数の識別器を学習させ、多数決で決める
– それぞれの識別器は弱識別器
● ランダム識別器よりは高性能
● 並列処理可能
● 識別器間の相関が高くなり、性能強化出来ない可能性あり
– ブースティングやランダムフォレストで欠点を補う

11.4 アダブースト
● ブースティング
– 弱識別器の学習結果を参考にしながら、次の弱識別器を学習する

11.4.1 アダブースト学習アルゴリズム
● 2クラス問題の識別器
– 多クラス問題には一対他識別器
● 弱識別器の学習結果にしたがって学習データに重みが付く
– 誤った学習データ:重み大きく
– 正しく識別された学習データ:重み小さく

アダブーストのアルゴリズム
1) 重みを (i=1,...,N)に初期化する
2) m=1,...,Mについて以下を繰り返す
a) 識別器y_m(x)を重み付き誤差関数が最小になるように学習する
b) 識別器y_m(x)に対する重みα_mを計算する
c) 重み を更新する
3) 入力xに対する識別結果をY_M(x)に従って出力する

アダブーストのアルゴリズム
1) 重みを (i=1,...,N)に初期化する
2) m=1,...,Mについて以下を繰り返す
a) 識別器y_m(x)を重み付き誤差関数が最小になるように学習する
b) 識別器y_m(x)に対する重みα_mを計算する
c) 重み を更新する
3) 入力xに対する識別結果をY_M(x)に従って出力する
全ての学習データの重みを同じにする

アダブーストのアルゴリズム
1) 重みを (i=1,...,N)に初期化する
2) m=1,...,Mについて以下を繰り返す
a) 識別器y_m(x)を重み付き誤差関数が最小になるように学習する
b) 識別器y_m(x)に対する重みα_mを計算する
c) 重み を更新する
3) 入力xに対する識別結果をY_M(x)に従って出力する
弱識別ごとに計算する

1) 重みを (i=1,...,N)に初期化する
2) m=1,...,Mについて以下を繰り返す
a) 識別器y_m(x)を重み付き誤差関数が最小になるように学習する
b) 識別器y_m(x)に対する重みα_mを計算する
c) 重み を更新する
3) 入力xに対する識別結果をY_M(x)に従って出力する
は、識別関数の出力が教師と一致したら0、一致しないと1を返すE_mは弱識別器の定義より、E_m<1/2
アダブーストのアルゴリズム

アダブーストのアルゴリズム
1) 重みを (i=1,...,N)に初期化する
2) m=1,...,Mについて以下を繰り返す
a) 識別器y_m(x)を重み付き誤差関数が最小になるように学習する
b) 識別器y_m(x)に対する重みα_mを計算する
c) 重み を更新する
3) 入力xに対する識別結果をY_M(x)に従って出力する
誤差が小さい程、大きな値を取る。

アダブーストのアルゴリズム
1) 重みを (i=1,...,N)に初期化する
2) m=1,...,Mについて以下を繰り返す
a) 識別器y_m(x)を重み付き誤差関数が最小になるように学習する
b) 識別器y_m(x)に対する重みα_mを計算する
c) 重み を更新する
3) 入力xに対する識別結果をY_M(x)に従って出力する
正しく分類出来なかった学習データの重みをexp(α_m)倍する。

アダブーストのアルゴリズム
1) 重みを (i=1,...,N)に初期化する
2) m=1,...,Mについて以下を繰り返す
a) 識別器y_m(x)を重み付き誤差関数が最小になるように学習する
b) 識別器y_m(x)に対する重みα_mを計算する
c) 重み を更新する
3) 入力xに対する識別結果をY_M(x)に従って出力する
精度が高い識別器の重みを大きくし、精度が低い識別器の重みを小さくする。
sign(a)はa>0で+1、a=0で0、a<0で-1を出力する

11.5 ランダムフォレスト
バギングを改良し、決定木の各非終端ノードにおいて識別に用いる特量をあらかじめ決められた数だけランダムに選択する手法
● 森のサイズによる過学習が生じない


11.5.2 ランダムフォレストによるデータ解析
● 森のサイズによる誤り率の変化● 特徴の重要さに関する情報● 学習データ間の近さ

11.5.2 ランダムフォレストによるデータ解析
● 森のサイズによる誤り率の変化○ 個別クラスととOut-Of-Bag誤り率
■ Out-Of-Bag:ブートストラップサンプリングに使われなかった学習データが使われていないない部分森で、その学習データをテストデータにして誤りを評価する
● 特徴の重要さに関する情報● 学習データ間の近さ
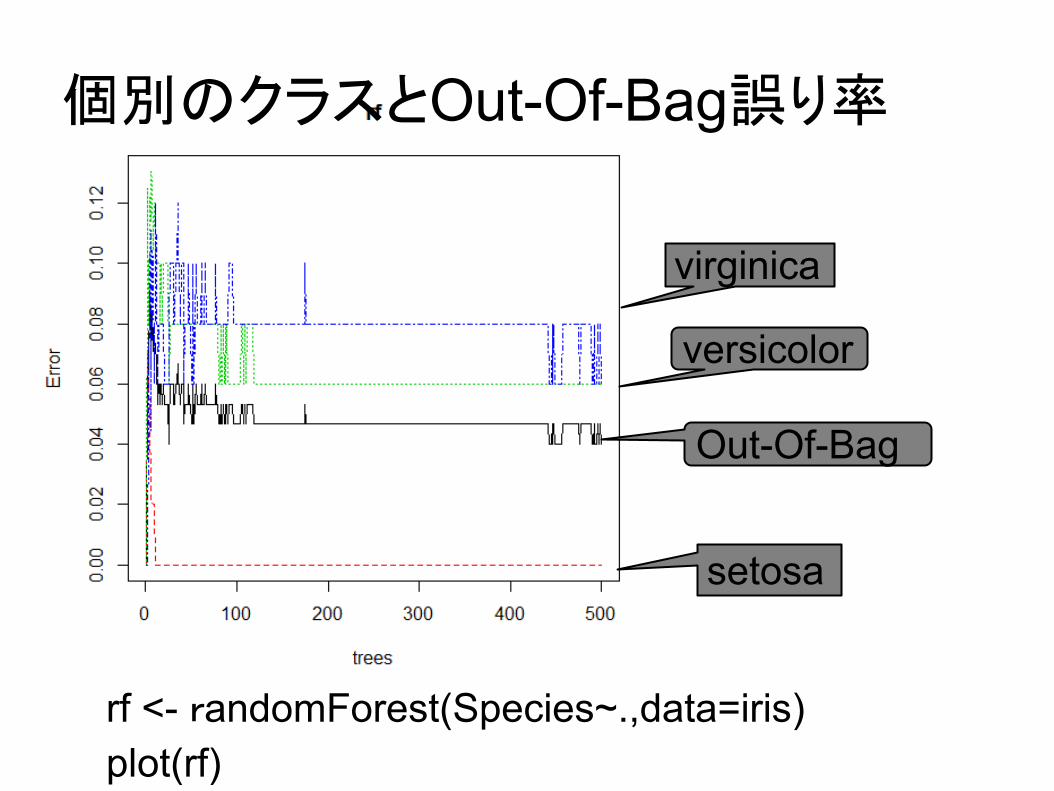
個別のクラスとOut-Of-Bag誤り率
rf <- randomForest(Species~.,data=iris)plot(rf)
Out-Of-Bag
setosa
virginica
versicolor

11.5.2 ランダムフォレストによるデータ解析
● 森のサイズによる誤り率の変化● 特徴の重要さに関する情報
○ 各特長がノード分割に使われたときの不純度(ジニ係数)の減少量を森全体で平均した量
○ 部分依存グラフ■ ある特徴の値がクラス識別にどのように寄与し
ているかを、他の特徴の寄与を加味したうえで見る指標
■ 分析対象の特徴のみをxで置換したベクトルを用いる
● 学習データ間の近さ

ジニ係数の減少量と特徴の重要度
varImpPlot(rf)
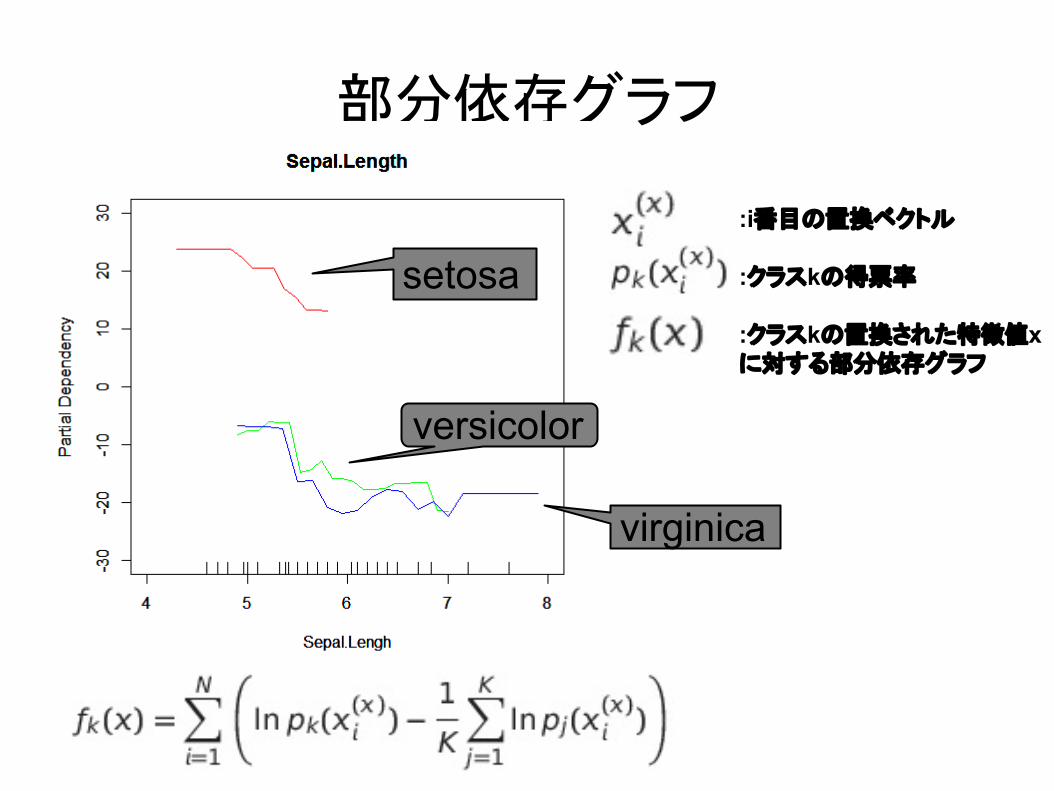
部分依存グラフ
setosa
virginica
versicolor
:i番目の置換ベクトル
:クラスkの得票率
:クラスkの置換された特徴値xに対する部分依存グラフ
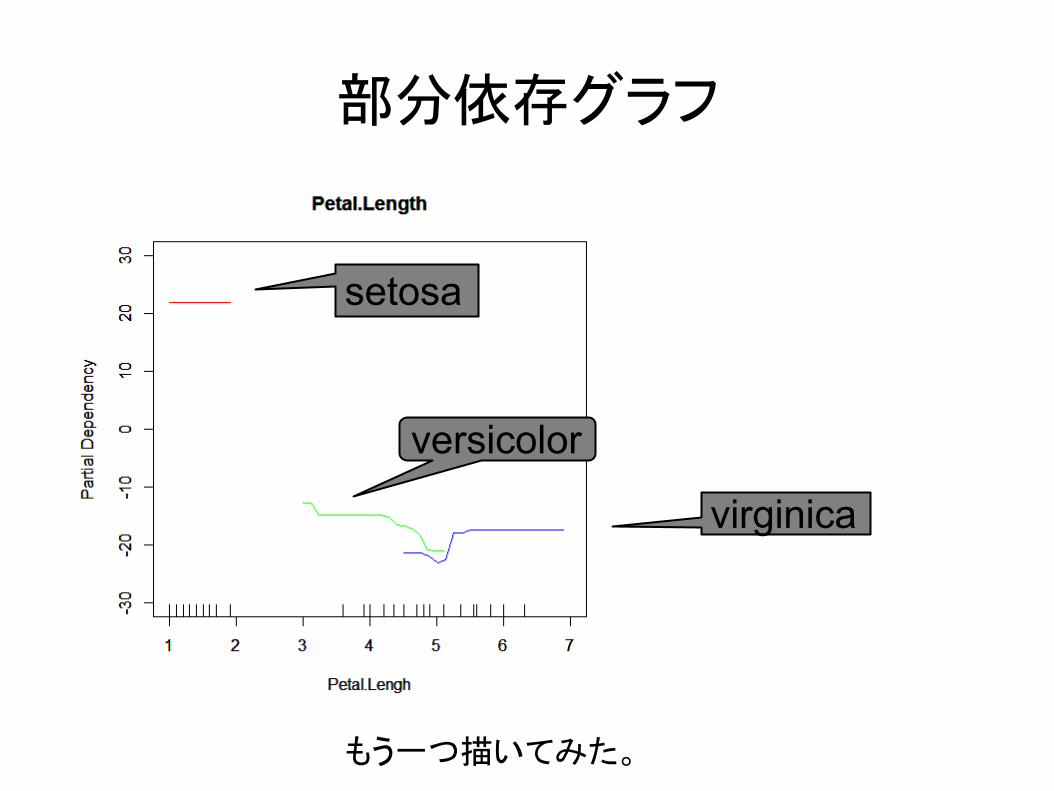
部分依存グラフ
setosa
virginica
versicolor
もう一つ描いてみた。

部分依存グラフのプロット(Sepal.Length)
partialPlot(rf, subset(iris,iris$Species=="setosa"), Sepal.Length, main = "Sepal.Length", xlab = "Sepal.Lengh", ylab = "Partial Dependency", col = "red",xlim=c(4,8),ylim=c(-30,30))par(new=T)partialPlot(rf, subset(iris,iris$Species=="versicolor"), Sepal.Length, main = "Sepal.Length", xlab = "Sepal.Lengh", ylab = "Partial Dependency", col = "green",xlim=c(4,8),ylim=c(-30,30))par(new=T)partialPlot(rf, subset(iris,iris$Species=="virginica"), Sepal.Length, main = "Sepal.Length", xlab = "Sepal.Lengh", ylab = "Partial Dependency", col = "blue",xlim=c(4,8),ylim=c(-30,30))

11.5.2 ランダムフォレストによるデータ解析
● 森のサイズによる誤り率の変化● 特徴の重要さに関する情報● 学習データ間の近さ
○ 近接グラフ■ 多次元尺度構成法により2次元空間に写像
● N×N近接行列○ i番目の学習データとj番目の学習データ
がOOBで同じ終端ノードに分類される木があれば、行列のi行j列とj行i列に1を加える
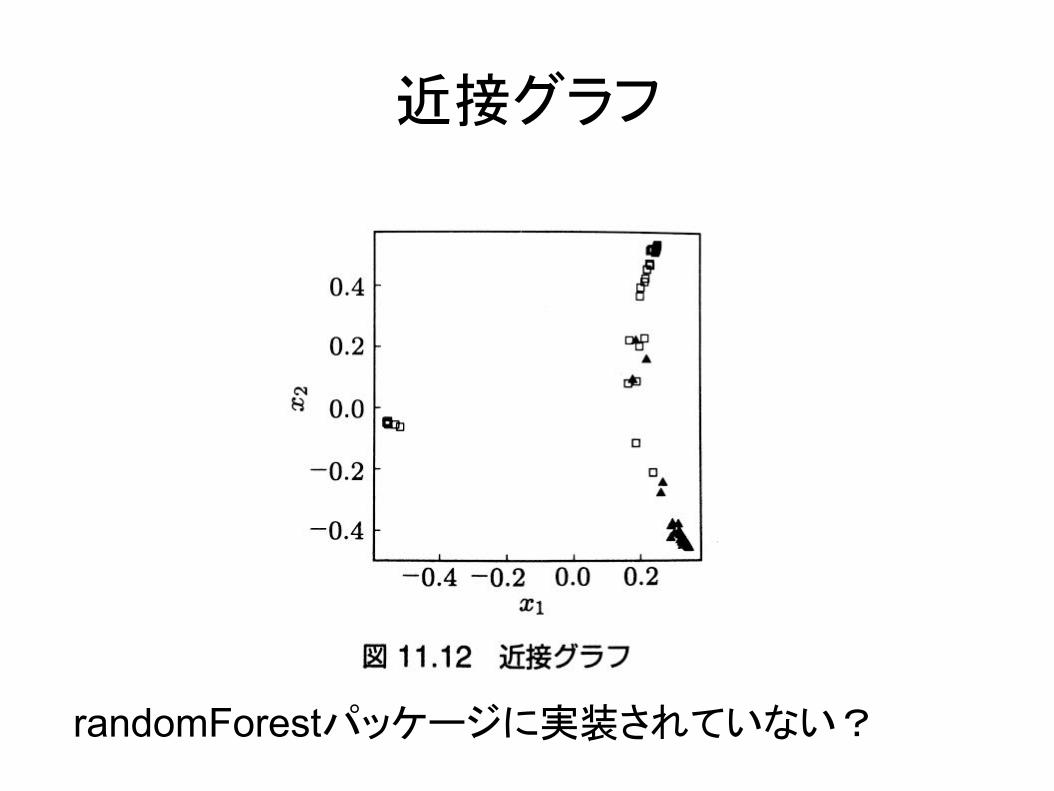
近接グラフ
randomForestパッケージに実装されていない?

性能比較
決定木 バギング アダブースト ランダムフォレスト
誤り率 0.16 0.053 0.04 0.04
教科書の表11.4 アヤメで0他を用いた性能比較

参考
● 平井有三、森北出版、はじめてのパターン認識● Rと集団学習,http://mjin.doshisha.ac.jp/R/32/32.html● ランダムフォレストの部分従属プロット (R Advent Calendar 2013),http://d.
hatena.ne.jp/langstat/touch/20131228● 多次元尺度構成法イントロダクション, http://d.hatena.ne.
jp/koh_ta/20110514/1305348816