第 9 讲 方差分析
DESCRIPTION
第 9 讲 方差分析. 第一节 引言. K 个样本. 样本数超过 2 个后,利用 t 检验的缺点 烦琐, k ( k – 1)/2 次 t 检验 每对检验的标准误不同, I 类错误增大 没有考虑平均数的秩次, I 类错误增大 如 3 个样本, P (Type I error)=1 – (1 – a ) k P(Type I error)=1 – (0.95) 3 = 1 – 0.86 =0.14 结论:不能利用 t 检验. 概念. 方差分析 (Analysis of variance) 把 k 个总体当作一个整体看待 - PowerPoint PPT PresentationTRANSCRIPT

1
第 9 讲方差分析

2
第一节 引言

3
K 个样本 样本数超过 2 个后,利用 t 检验的缺点
烦琐, k(k – 1)/2 次 t 检验 每对检验的标准误不同, I 类错误增大 没有考虑平均数的秩次, I 类错误增大 如 3 个样本,
P(Type I error)=1 – (1 – a)k
P(Type I error)=1 – (0.95)3= 1 – 0.86 =0.14
结论:不能利用 t 检验

4
概念 方差分析 (Analysis of variance)
把 k 个总体当作一个整体看待 把观察值的总变异的平方和及自由度分解为不同来源
的平方和及自由度 计算不同方差估计值的比值 检验各样本所属的平均数是否相等
实际上是观察值变异原因的数量分析

5
概念 试验指标 (Experimental index) :试验测定的
项目或者性状。 日增重、产仔数、瘦肉率
试验因素 (Experimental factor) :影响试验指标的因素。 温度、营养水平 单因素试验:只有一个因素的试验 多因素试验:有多个因素

6
概念 因素水平 (Level of factor) :试验因素所处的特
定状态或者数量等级。简称水平 如日粮中粗蛋白质含量
试验处理 (Treatment) :实施在试验单位上的具体项目。简称处理。 单因素:试验因素的一个水平 多因素:试验因素的一个水平组合

7
概念 试验单位 (Experimental unit) :试验载体
1 只家禽、 1 只鱼 几只家禽、几只鱼 观测数据的单位
重复 (Repetition) 一个处理实施在两个或者两个以上的试验单位上,称
为处理有重复。 试验单位数称为处理的重复数

8
第二节 基本原理单因素分类资料的方差分析
9
一、各水平样本含量相等
10
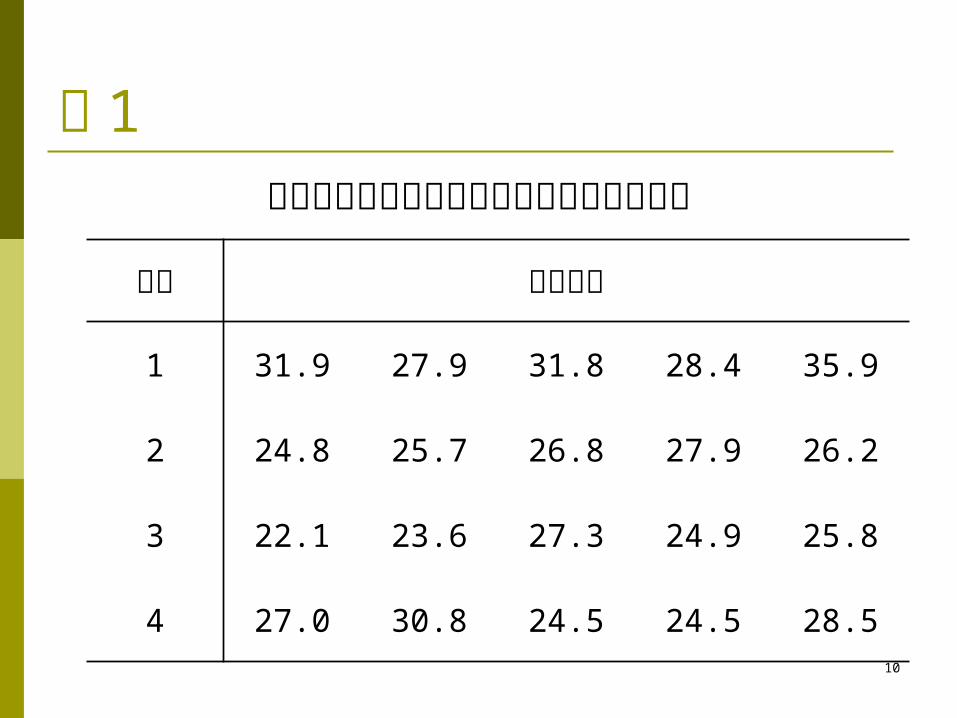
例 1某水产研究所比较四种饲料对鱼的饲喂效果
饲料 鱼的增重
1 31.9 27.9 31.8 28.4 35.9
2 24.8 25.7 26.8 27.9 26.2
3 22.1 23.6 27.3 24.9 25.8
4 27.0 30.8 24.5 24.5 28.5
11
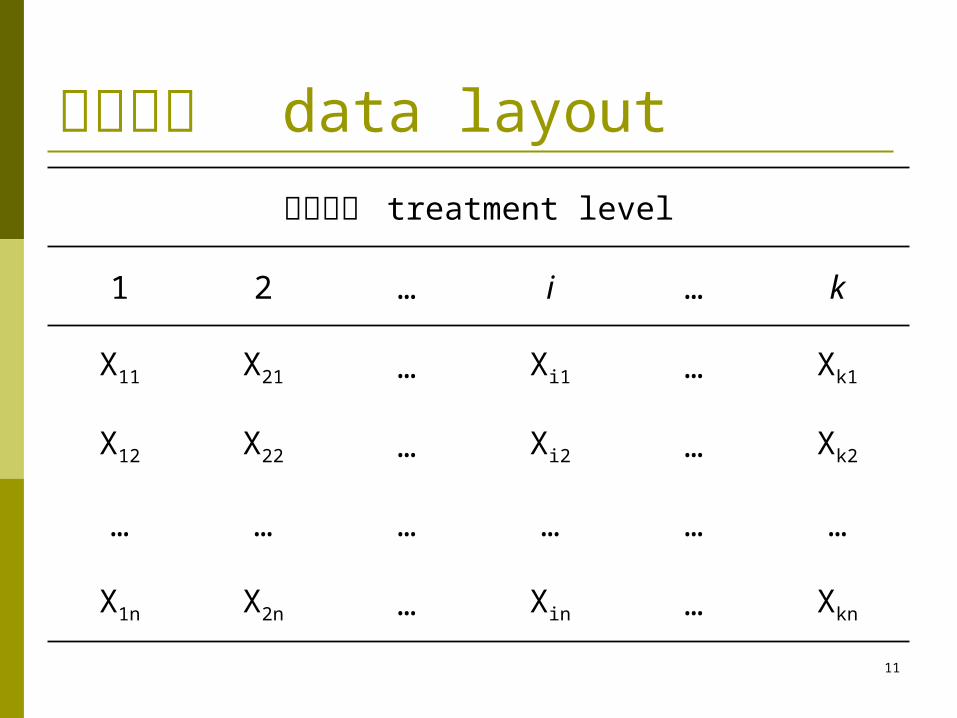
数据布局 data layout处理水平 treatment level
1 2 … i … k
X11 X21 … Xi1 … Xk1
X12 X22 … Xi2 … Xk2
… … … … … …
X1n X2n … Xin … Xkn

12
数学模型: ijiij eay
yij = 第 i 组第 j 个鱼的观察值; = 平均值;
i= 第 i 种日粮的效应值; eij = 误差效应 单因素试验 的 线 性 模 型( linear mode
l )亦称数学模型 模型假定:
e ~ N(0, 2) ,方差同质性 homogeneity数据正态分布 normality效应可加 additivity

13
假设H0 : 1 = 2 = … = n
HA: 至少有一对 不相等

14
平均数
in
jiji XT
1.
N
TX ..
..
总体平均数 grand mean
处理 和 平均
1 155.5 31.18
2 131.4 26.28
3 123.7 24.74
4 139.8 27.96
总 550.8 27.54
i
ii n
TX
..

15
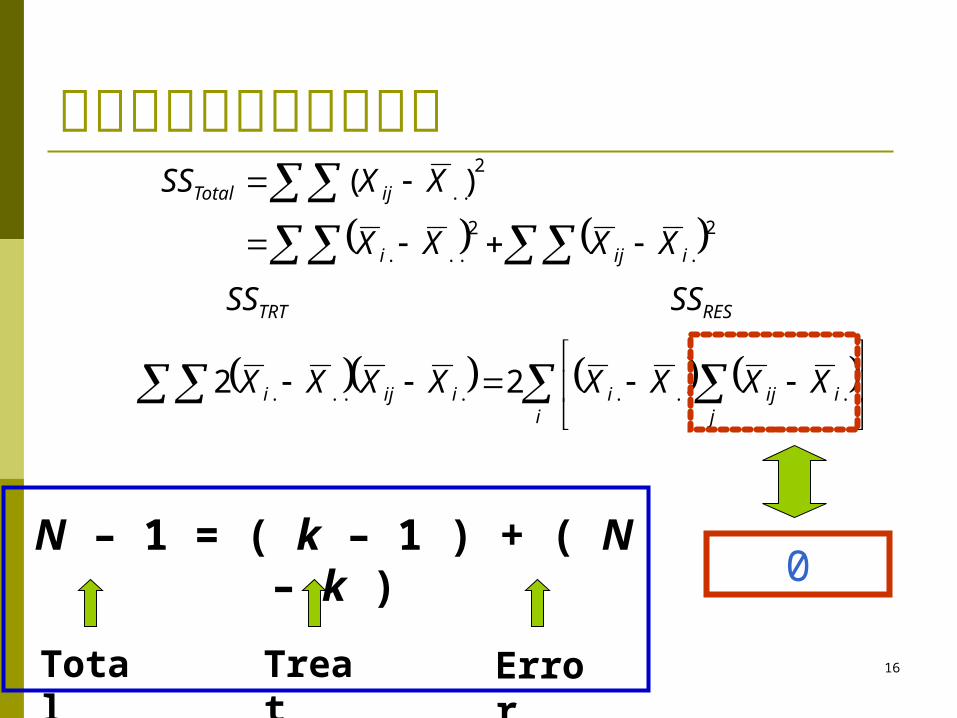
总平方和 sum of squares 总平方和
总平方和 (Total sum of squares, SSTotal) 观察值同总体平均数的离差可以剖分成与处理平
均与总体平均的差和观察值与处理平均的差
...... iijiij XXXXXX
2
..)( XXSS ijTotal
16
总平方和及自由度的剖分
2
.
2
...
2
..)(
iiji
ijTotal
XXXX
XXSS
i jiijiiiji XXXXXXXX ........ 22
0
SSTRT SSRES
Total Treat
Error
N – 1 = ( k – 1 ) + ( N – k )

17
F检验 SSTRT/2~2(k – 1) SSRES/2~2(n – k)
MSTRT = SSTRT/(k – 1) MSRES = SSRES/(n – k)
F = MSTRT/MSRES ~ F(k – 1, n – k)

18
期望均方
22
21
2222
211
21
21
2.
)1()1(
)(
估计e
k
kk
k
kiiij
e
ee
Sdfdfdf
SdfSdfSdf
dfdfdf
SSSSSS
nk
SS
nk
xx
df
SSMS
22
22
1
a
i
iiTreat
n
k
nMSE
请注意无效假设如果成立,则处理均方等于误差均方

19
F检验 F 检验:利用 F 值出现概率的大小推断两个总体方
差是否相等的方法 目的:推断处理间的差异是否存在,检验某项变异因素
的效应方差是否为零 在计算 F 值时总是以被检验因素的均方作分子,以误差
均方作分母 分子、分母的选择是由模型和各项变异原因的期望均方
决定的 ANOVA 分析中的 F 检验总是单尾检验 , 而且为右尾检验

20
如何理解 如果 H0 是正确的,那么 MSTRT 与 MSRES 都是总体
误差 2 的估计值,理论上讲 F 值等于 1 ;如果 H
0 是不正确的,那么 ,理论上讲 F 值就必大于 1 。但是由于抽样的原因,即使 H0 正确, F 值也会出现大于 1 的情况。 只有 F 值大于 1 达到一定程度时,才有理由否定 H0
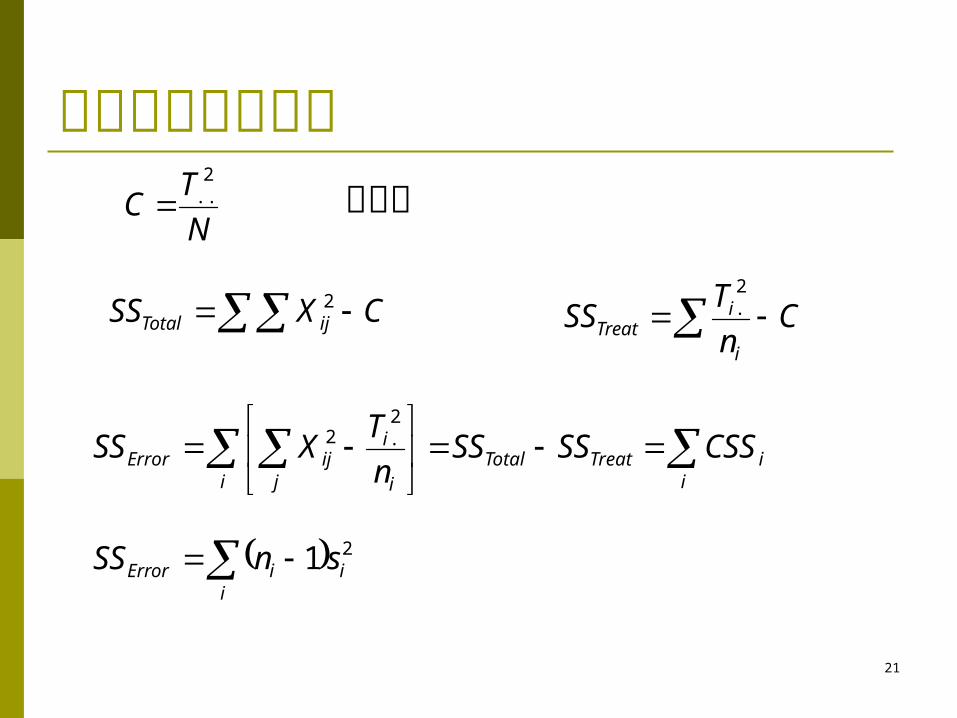
21
平方和的计算公式
N
TC
2..
CXSS ijTotal2
Cn
TSS
i
iTreat
2.
iiTreatTotal
i j i
iijError CSSSSSS
n
TXSS
2.2
i
iiError snSS 21
校正数
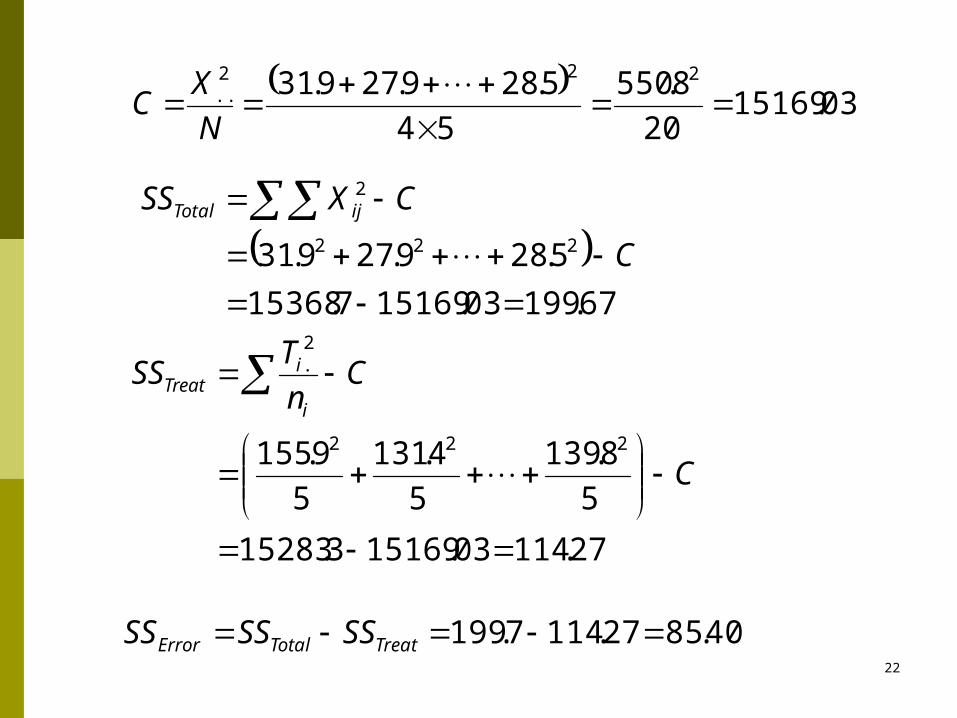
22
03.15169
20
8.550
54
5.289.279.31 222..
N
XC
67.19903.151697.15368
5.289.279.31 222
2
C
CXSS ijTotal
27.11403.151693.15283
5
8.139
5
4.131
5
9.155 222
2.
C
Cn
TSS
i
iTreat
40.8527.1147.199 TreatTotalError SSSSSS

23
例: ANOVA表
变异来源 平方和 自由度 均方 F 值
处理 114.27 3 38.09 7.13**
误差 85.40 16 5.34
总变异 199.67 19
如果接受 H0 ,则分析结束。否则,进行下一步分析。

24
多重比较 多重比较
F 检验否定 H0, 不表明任意两个平均数间都存在显著差异 功能:发现哪两个平均数间存在显著差异 Mean separation technique or multiple comparison
s 常用方法
最小显著差数法 LSD(lest significant difference) 最小显著极差法 LSR(lest significant ranges) : q 法和DUNCAN

25
LSD法 LSD 法的基本原理:
..
)(
ji
e
xxdf S
LSDt
..)( jie xxdf StLSD
nMSS exx ji2
..

26
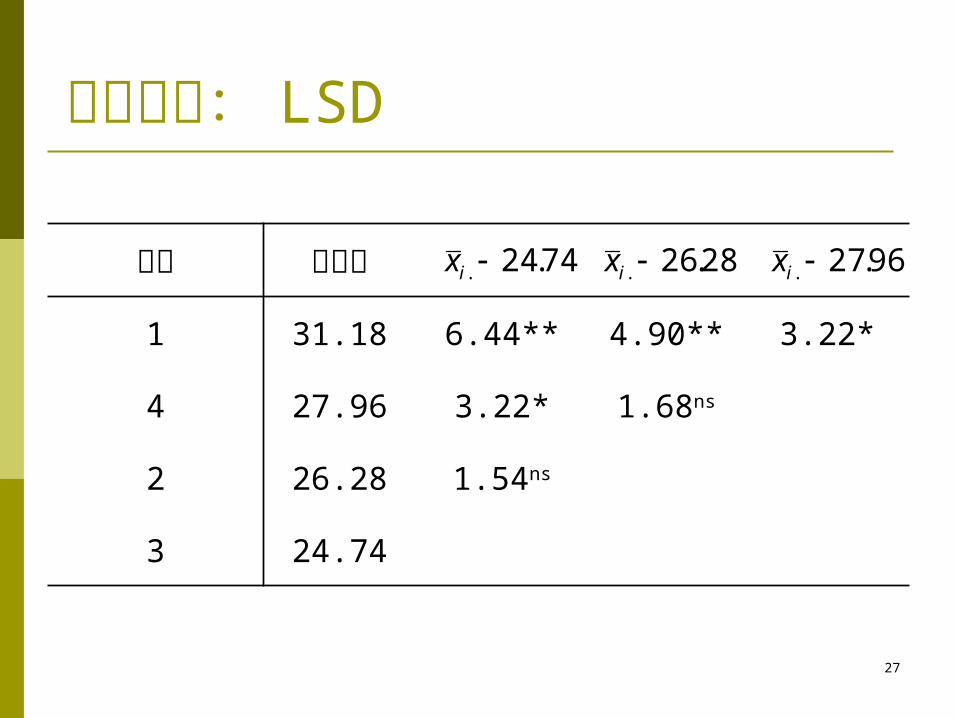
例
临界值: t0.05(16)=2.12, t0.01(16)= 2.921
LSD0.05(16)=2.120*1.462=3.099
LSD0.01(16)=2.921*1.462=4.271
462.15/34.522..
nMSS exx ji
27
多重比较: LSD
处理 平均数
1 31.18 6.44** 4.90** 3.22*
4 27.96 3.22* 1.68ns
2 26.28 1.54ns
3 24.74
74.24. ix 28.26. ix 96.27. ix

28
LSD 说明
实质上是 t 检验,但统一了标准误 简单、灵敏(降低了检验标准、夸大了差异的显著性)
I 类错误概率增大 , 控制单次比较的 I 类错误 (comparisonwise error rate) 时应用 无法控制所有比较的总体 I 类错误 (experimentwise
error rate)

29
LSR 把平均数的差异看成是平均数的极差 (range) 根据极差范围内所包括的处理数(称为秩次距) k
的不同,而采用不同的检验尺度叫做 最小显著极差 LSR
说明 I 类错误下降、工作量加大 把每个处理的样本数看成相同,如果不同,则需要校正

30
q检验法 此法是以统计量 q 的概率分布为基础的。 q 值由下式求得
xsdq xkdfk sqLSR ),(,
nMSS ex /
31
q检验步骤1. 列出平均数多重比较表;
2. 由自由度 dfRES 、秩次距 k 查临界 q 值,计算最小显著极差 LSR0.05,k , LSR0.01,k ;
3. 将平均数多重比较表中的各极差与相应的最小显著极差 LSR0.05,k, LSR0.01,k 比较,作出统计推断

32
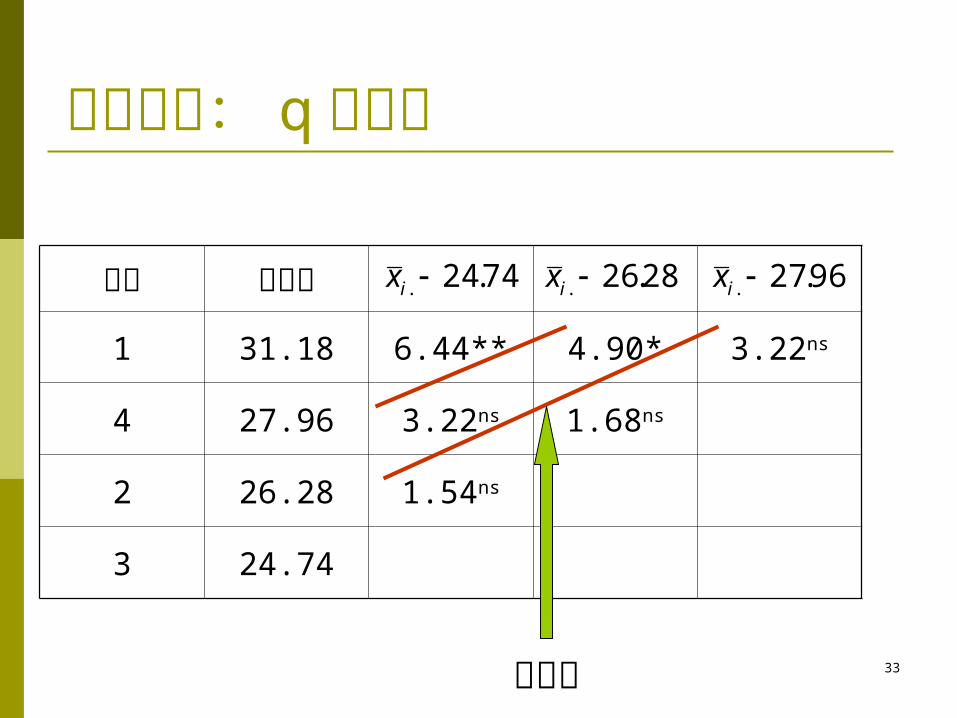
q检验法
dfe k q0.05 q0.01 LSR0.05 LSR0.01
16
2 3.00 4.13 3.099 4.266
3 3.65 4.79 3.770 4.948
4 4.05 5.19 4.184 5.361
q 值及 LSR
033.15/34.5/ nMSS ex
33
多重比较: q 检验法
处理 平均数
1 31.18 6.44** 4.90* 3.22ns
4 27.96 3.22ns 1.68ns
2 26.28 1.54ns
3 24.74
74.24. ix 28.26. ix 96.27. ix
秩次距

34
结果表示
处理 平均数 a=0.05 a=0.01
1 31.18a A A
4 27.96b B AB
2 26.28c B B
3 24.74c B B

35
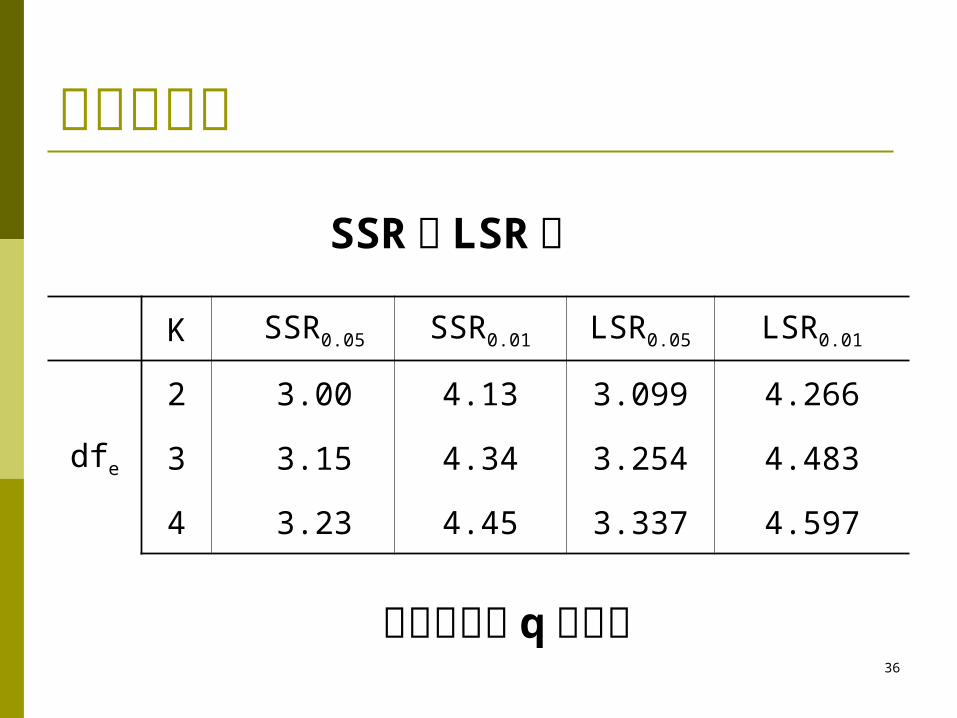
新复极差法 英语名称
New multiple range method Shortest significant ranges, SSR Duncan’s multiple range test, DMRT
新复极差法与 q 检验法的检验步骤相同,唯一不同的是计算最小显著极差时需查SSR 表 ( 附表 6)而不是查q 值表
公式
xkdfk sSSRLSR ),(,
36
新复极差法
K SSR0.05 SSR0.01 LSR0.05 LSR0.01
dfe
2 3.00 4.13 3.099 4.266
3 3.15 4.34 3.254 4.483
4 3.23 4.45 3.337 4.597
SSR 与 LSR 值
以后步骤与 q 法相同

37
总结 方差分析假定不同处理的方差相等
若不相等,则结果的可靠性下降 数据不是正态分布要经过转换;或者利用非参数方法
38
总结 多重比较有多种方法,不同方法用途不同、比较
的结果不同 尺度大小: LSD法≤新复极差法≤检验法
当秩次距 k=2 时,取等号; 秩次距 k ≥3 时,取小于号。 对试验要求严格时,用 q 检验法较为妥当 生物试验中,由于试验误差较大,常采用新复极差法
应该注明利用的是何种多重比较方法 LSR 的目的是控制单次多重比较的 I 类错误

39
二、各处理重复数不等的方差分析

40
例子

41
41.848225/5.460/ 22.. NxC
20424
4151
241251
84.3850.4634.85
50.4641.848291.8528
41.8482
)4/5.664/8.785/5.916/0.1036/0.121(
/
34.8541.848275.8567
41.8482)0.160.175.195.21(
22222
2.
22222
tTRES
TRT
Total
tTRES
iiTRT
ijTotal
dfdfdf
kdf
Ndf
SSSSSS
CnxSS
CxSS

42
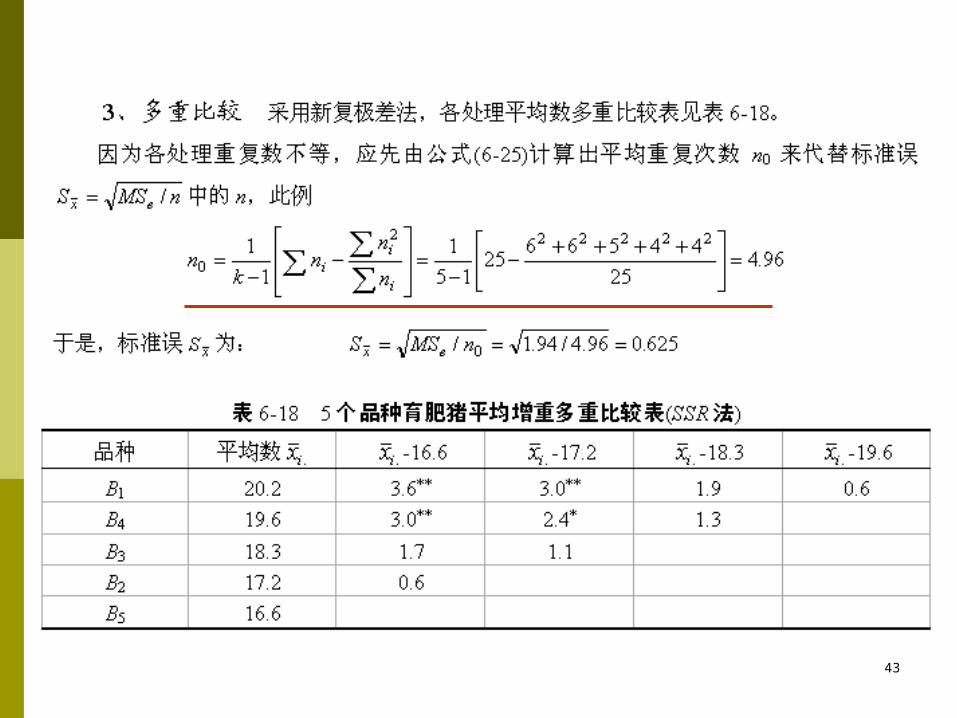
方差分析表
43
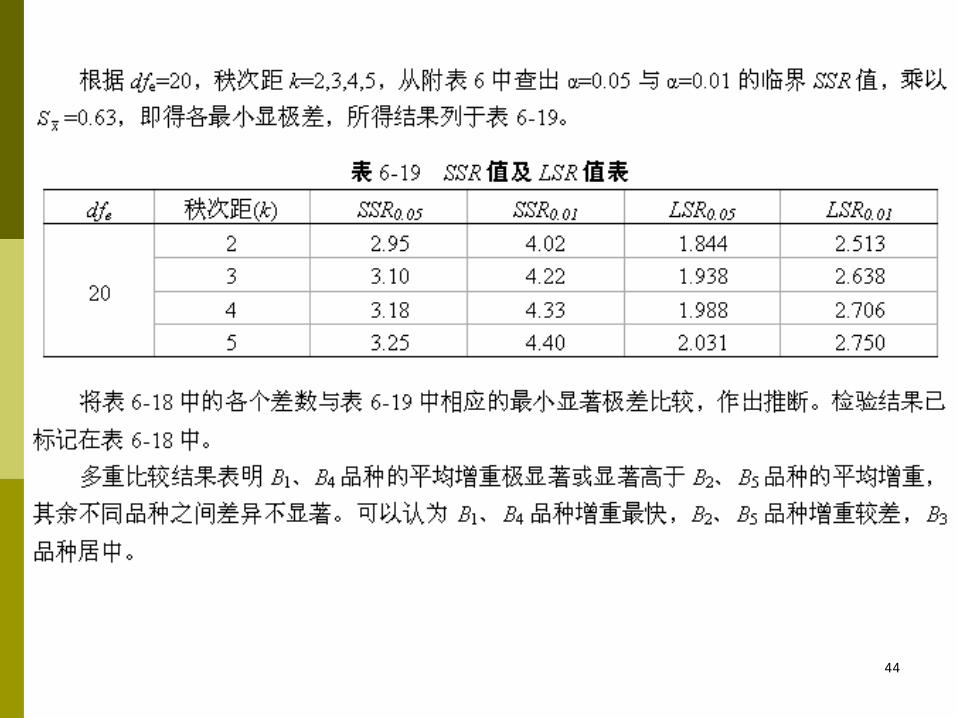
44
45
第三节两因素方差分析

46
一、前言
47
前言 两因素试验资料的方差分析是指对试验指标同时
受到两个试验因素作用的试验资料的方差分析 两因素试验按水平组合的方式不同,分为交叉分组和系统分组两类
对试验资料的方差分析方法也分为交叉分组方差分析和系统分组方差分析两种
48
前言 设试验考察 A 、 B 两个因素, A 因素分 a 个水平,B 因素分 b 个水平 。
所谓交叉分组是指 A 因素每个水平与 B 因素的每个水平都要碰到 ,两者交叉搭配形成 ab 个水平组合即处理 ,试验因素 A 、 B 在试验中处于平等地位 。 试验单位分 成 ab 个组,每组随机接受一种处理 ,因而试验数据也按两因素两方向分组。这种试验以各处理是单独观测值还是有重复观测值又分为两种类型

49
二、随机化完全区组设计Randomized Complete Block
Design ANOVA
50
前言 概念
为配对 t 试验设计的推广 这时每个试验单位的处理多于两个 试验动物随机选择,处理随机安排
如: 对于 A 、 B 两个试验因素的全部 ab 个水平组
合,每个水平组合只有一个观测值, 全试验共有 ab 个观测值

51
数据结构
区组处理 区组
1 2 … k 和 平均1 X11 X21 … Xk1 T.1
2 X12 X22 … Xk2 T.2
… … … … … … …
b X1b X2b … Xkb T.b
处理和 T1. T2. … Tk. 总和平均 ….1X .2X .kX
1.X
2.X
bX .
.... XT

52
数学模型ijjiij ebaX
= 总体平均
ai = 第 i 个处理效应, i. –
bj = 第 j 个区组的效应, .j –
eij = 随机误差项, Xij – ij

53
模型假定1. 每个观察值为一个从平均值等于 ij 的群体随机、
独立的抽样。共有 k b 个样本。2. 处理效应和区组效应是加性的( additive )。处
理和区组没有互作 ij = + ( i. – ) + (.j – )
3. 数据的方差相等 eij 为随机误差,相互独立,且服从 N(0 , 2)

54
方差剖分交叉分组两因素单独观测值的试验
A 因素的每个水平有 b 次重复, B 因素的每个水平有 a 次重复,每个观测值同时受到 A 、 B 两 因素及随机误差的作用。因此全部 ab 个观测值的总变异可以剖分为 A 因素水平间变异、B 因素水平间变异及试验误差三部分
自由度也相应剖分

55
平方和计算
i j
iji j
ijTotal N
TXXXSS
2..22
..
i
i
i jiTreat N
T
b
TXXSS
2..
2.2
...
j
j
i ijBlock N
T
k
TXXSS
2..
2.2
...
1bkdfTotal
1kdfTreat
1bdfBlock
BlockTreatTotalError SSSSSSSS
)1)(1( kbdfdfdfdf BlockTreatTotalError

56
ANOVA 表变异来源
SS Df MS F c.v.
处理 SSTreat k-1 SSTreat/(k-1) MSTreat/MSE 查表
区组 SSBlocks b-1 SSBlock/(b-1)
误差 SSError (k-1)(b-1)
和 SSTotal kb-1
说明:感兴趣的是处理效应的检验结果
57
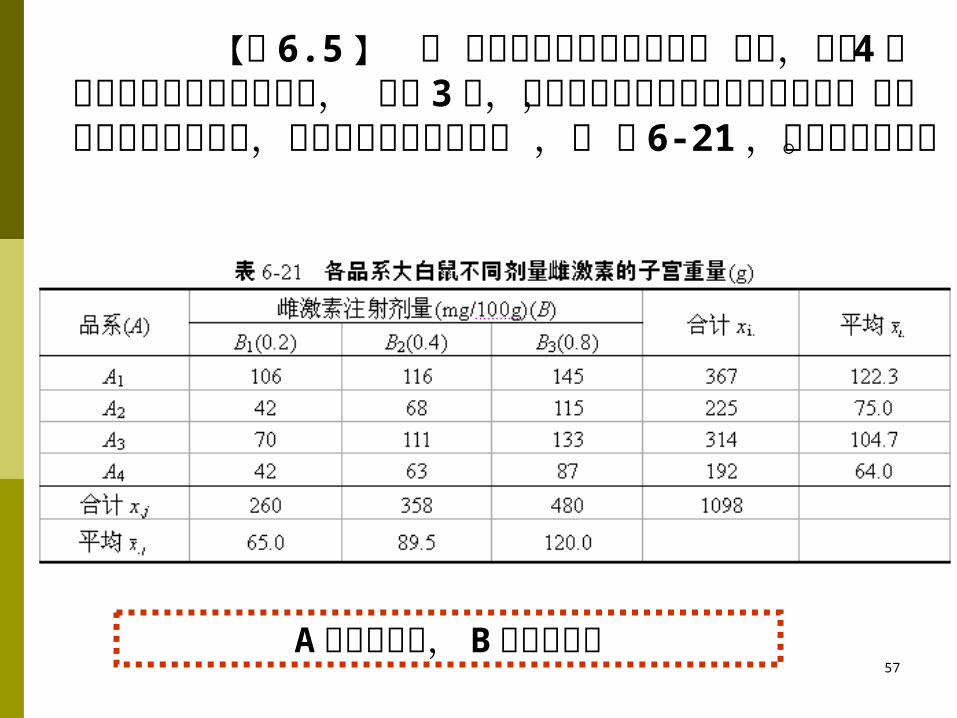
【例 6.5 】 为 研究雌激素对子宫发育的 影响,现有 4窝不同品系未成年的大白鼠, 每窝3 只,随机分别注射不同剂量的雌激素,然后在相同条件下试验,并称得它们的子宫重量 ,见 表 6-21 ,试作方差分析。
A 因素为区组, B 因素为处理

58
0000.100467)34/(1098/.. 22 abxC
0000.60740000.1004670000.106541
0000.100467)480358260(4
11
6667.64570000.1004676667.106924
0000.100467)192314225367(3
11
0000.130750000.100467113542
0000.100467)8763116106(
2222.
22222.
22222
Cxa
SS
Cxb
SS
CxSS
jB
iA
ijT

59
62311
,2131
3141
,111341
3333.543
60700006667.64570000.13075
BATe
B
A
T
BATe
dfdfdfdf
bdf
adf
abdf
SSSSSSSS

60
ANOVA 表变异来源 平方和 自由度 均方 F 值A 因素 ( 品
系 )6457.6667 3
B 因素 ( 剂量 )
6074.0000 2 3037.0000 33.54**
误差 543.3333 6 90.5556
总变异 13075.0000 11
根据 df1=dfB=2 , df2=dfe=6 查临界 F 值, F0.01(2,6)=10.
92
61
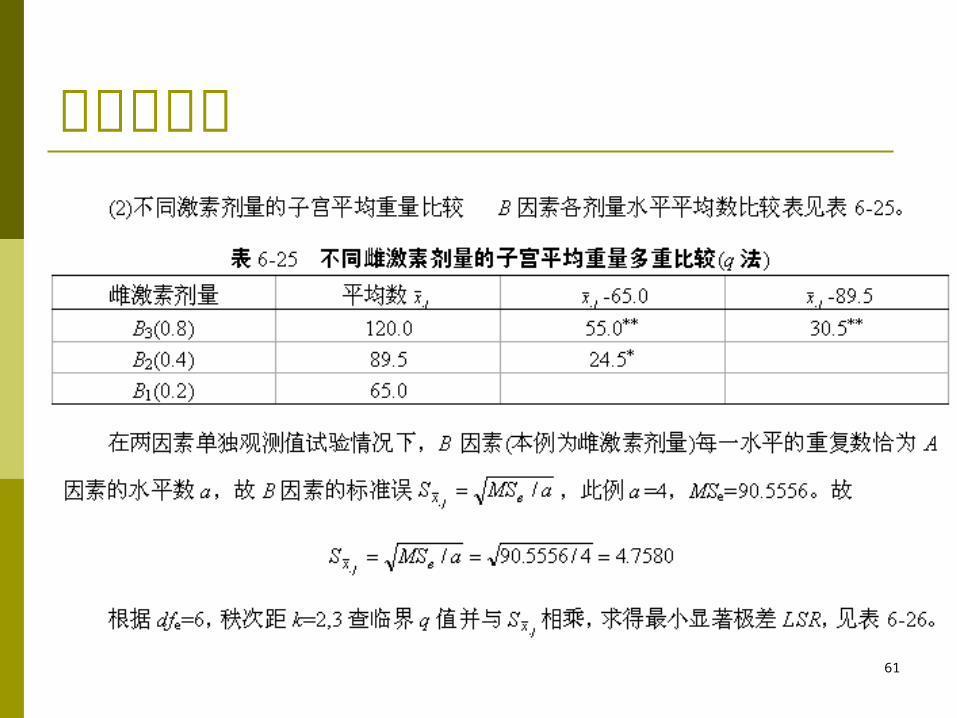
多重比较表

62
多重比较
63
三、析因试验

64
概念 析因试验 factorial experimental: 多个因素( fa
ctors )对反应变量的效应 效率比一次一个因素高,因为每个因素都提供试验中
其它因素信息 可研究不同因素间的关系
65
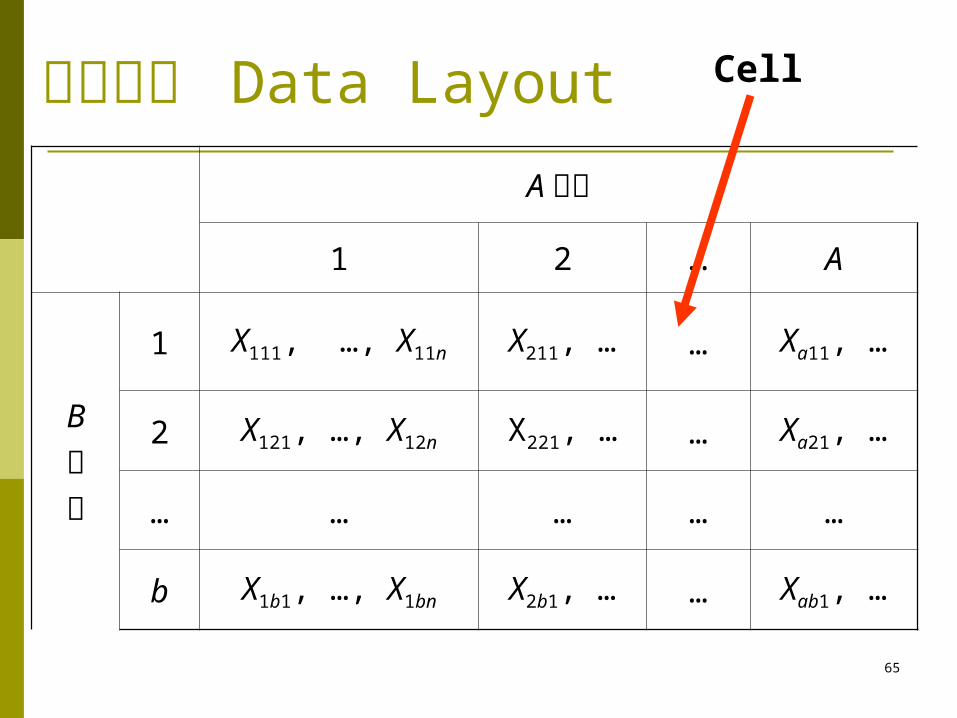
数据模式 Data LayoutA 因素
1 2 … A
B因素
1 X111, …, X11n X211, … … Xa11, …
2 X121, …, X12n X221, … … Xa21, …
… … … … …
b X1b1, …, X1bn X2b1, … … Xab1, …
Cell
66
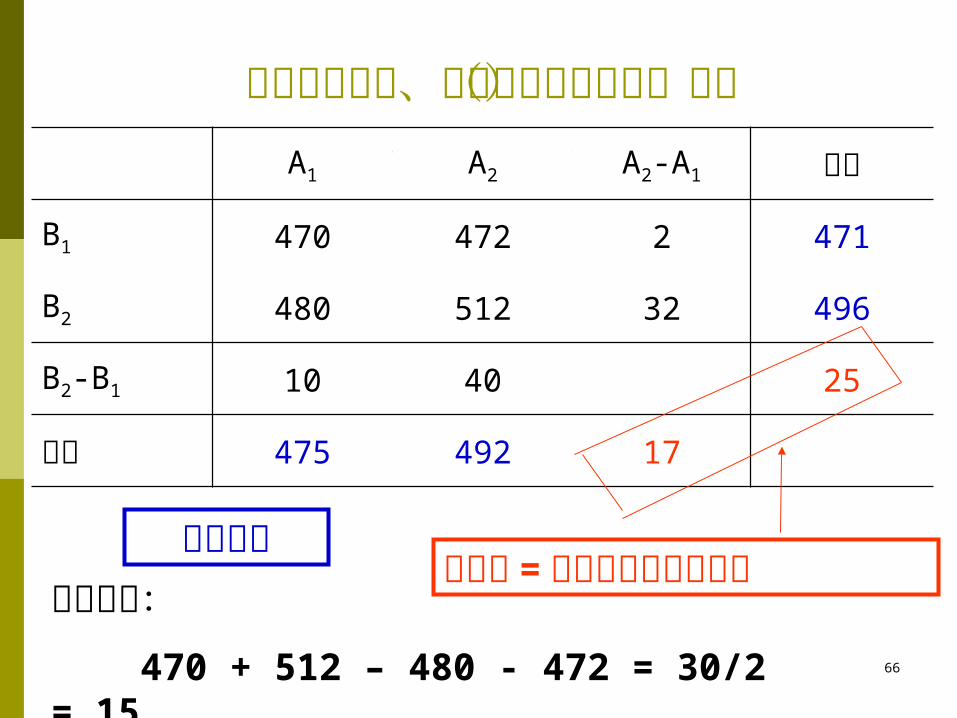
日粮中添加赖、蛋氨酸雏鸡的增重(克)A1 A2 A2-A1 平均
B1 470 472 2 471
B2 480 512 32 496
B2-B1 10 40 25
平均 475 492 17
互作效应:
470 + 512 – 480 - 472 = 30/2 = 15
主效应 = 等于简单效应的平均简单效应

67
概念 在某因素同一水平上,另一因素不同水平对试验
指标的影响称为简单效应。如上表中, 在 A1( 不加赖氨酸 ) 上, B2- B 1=480-470=10 ;在 A2 ( 加赖氨酸 ) 上, B2- B1=512-472=40 ;在 B1 ( 不加蛋氨酸 ) 上, A2-A1=472-470=2 ; 在 B2 ( 加蛋氨酸 ) 上, A2-A1=512-480=32 等就是简单效应。简单效应实际上是特殊水平组合间的差数。

68
概念 主效应 (main effect) 由于因素水平的改变而引起的平
均数的改变量称为主效应。
如上表中,当 A 因素由 A1 水平变到 A2水平时, A 因素的主效应为 A2水平的平均数减去 A1 水平的平均数,即
A 因素的主效应 =492-475=17 同理 B 因素的主效应 =496-471=25 主效应也就是简单效应的平均,如 (32+2)÷2=17 , (40+10)÷2=25

69
概念 交互作用 ( 互作, interaction) 在多因素试验中,一个
因素的作用要受到另一个因素的影响,表现为某一因素在另一因素的不同水平上所产生的效应不同,这种现象称为该两因素存在交互作用。如上表中:
A 在 B1 水平上的效应 =472-470=2
A 在 B2水平上的效应 =512-480=32
B 在 A1 水平上的效应 =480-470=10
B 在 A2水平上的效应 =512-472=40

70
概念 显而易见, A 的效应随着B 因素水平的不 同而不同,反之亦然,此时称 A 、 B 两因素间存 在交互作用,记为 A×B 。或者说,某一因素的 简单效应随着另一因素水平的变化而变化时,则称该 两 因 素 间 存 在 交互作用。 互作
效应可由 (A1B1+A2B2-A1B2-A2B1)/2 来估计。
上表中的互作效应为:
(470+512-480-472)/2=15

71
数学模型 ijkijjiijk eabbaX
..iia
.. jjb
..... jiijijab
.ijijkijk Xe
,0)()()(,0,01 1 1 11 1
n
i
b
j
a
i
b
jijijij
a
i
b
jji abababba

72
模型假定 试验组合( cell )中的每个数据都是一个独立抽样 数据服从正态分布且方差相等
........ ijijkijijk XXXXXX
观察值与总平均值的差异
试验组合均值与总均值的差
观察值与因素组合均值的差
...................... XXXXXXXXXX jiijjiij
能解释的变异
A 因素第 i个水平的主效应
A 因素第 i 个水平和 B 因素第 j个水平的互作
B 因素第 j个水平的主效应

73
平方和的计算
i j k
ijki j k
ijkTotal CXXXSS 22
...
N
T
abn
TC
2...
2...
i j k i
iiA C
bn
TXXSS
2..2
.....
j
j
i j kjB C
an
TXXSS
2..2
.....
i j
ij
i j kijCells C
n
TXXSS
2.2
....

74
平方和的计算
BABACells SSSSSSSS BACellsBA SSSSSSSS
...................... XXXXXXXXXX jiijjiij
........ ijijkijijk XXXXXX
CellsTotalError SSSSSS

75
ANOVA 表
变异来源 SS 自由度 MS
Cells SSCells ab-1 MSCells
A 因素 SSA a-1 MSA
B 因素 SSB b-1 MSB
互作 SSAB (a-1)(b-1) MSAB
误差 SSError ab(n-1) MSError
Total SSTotal abn-1

76
期望均方与 F 检验变异来源 自由度 期望均方 F
A 因素 (a-1) bn2A+ 2 MSA/MSE
B 因素 (b-1) an2B+ 2 MSB/MSE
AB (a-1)(b-1) n2A B + 2 MSA B /MSE
误差 ab(b-1) 2
总变异 abn-1

77
自由度
11 NabndfTotal
1adf A
1bdfB
1abdfCells
1abndfError
11 badf BA

78
因素间互作的测验 首先,应该检验两个因素互作是否显著。假设是: H0 : (ab)ij=0 所有 i, j
Ha: (ab)ij=0 有些 i, j
FAB = MSAB /MSE
df1 = (a – 1)(b – 1), df2 = ab(n – 1)

79
互作的检验结果为不显著 进行主效应的方差分析
A 因素
H0 : 所有 i.. 都相等
Ha: 至少有一对 i.. 不相等
FA=MSA/MSE
自由度: df1 = a – 1, df2 = ab(n – 1)

80
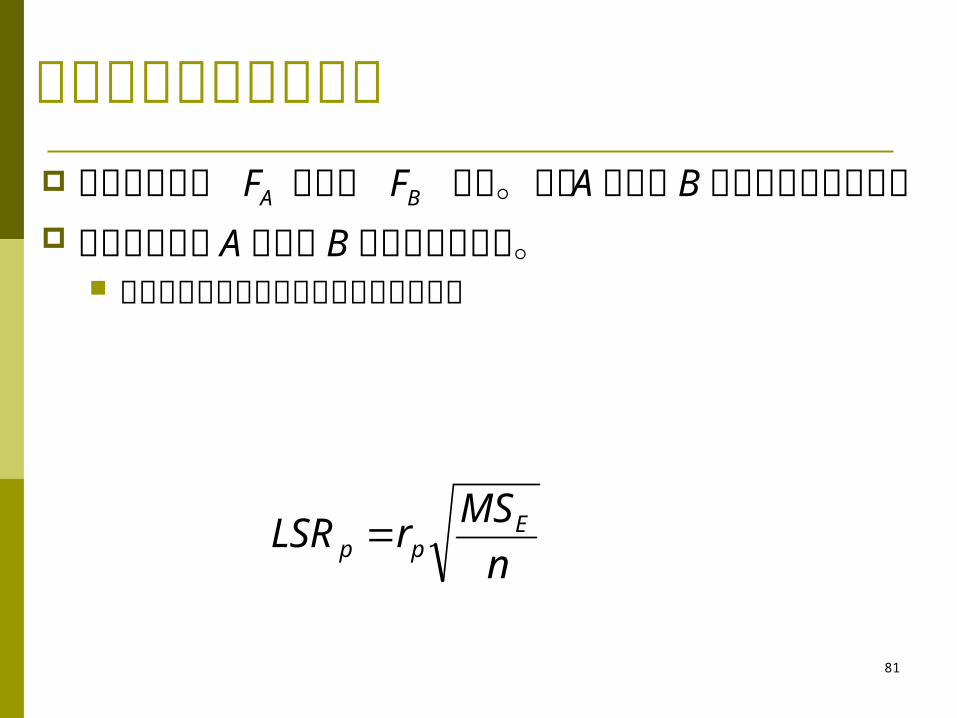
互作的检验结果为不显著 B 因素:与 A 因素相似H0 :所有 .j. 都相等
Ha: 至少有一对 .j. 不相等
FB=MSB/MSE
自由度: df1 = b – 1, df2 = ab(n – 1)
81
互作的检验结果为显著 这时不用进行 FA 检验和 FB 检验。因为 A 因素和 B
因素不再单独起作用 我们需要检验 A 因素和 B 因素的最佳组合。
次级样本含量不等时的校正同单因素分析
n
MSrLSR E
pp
82
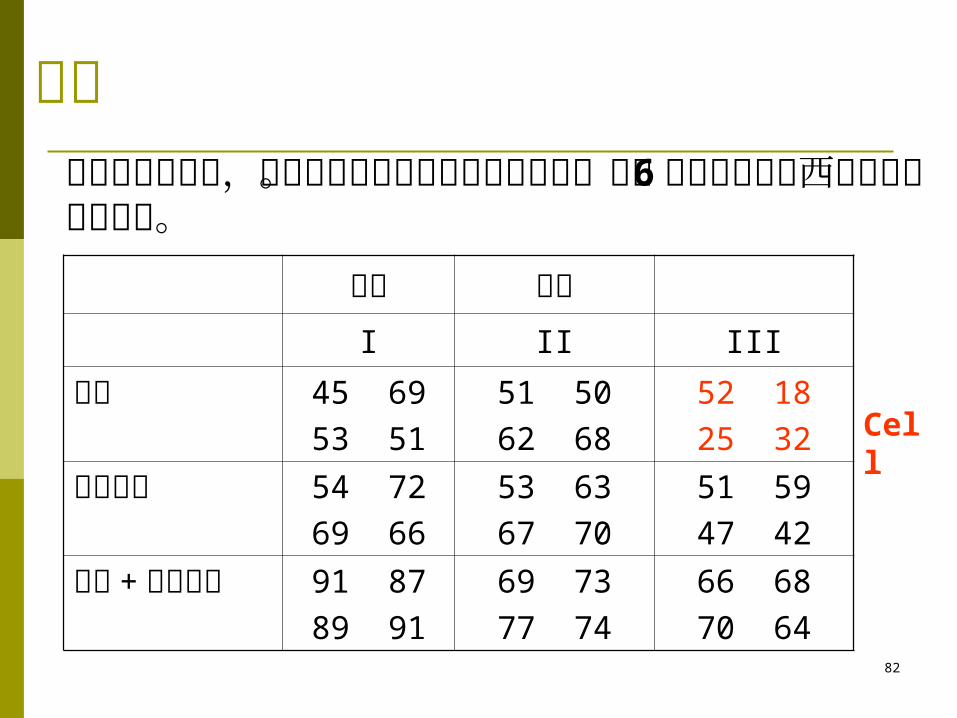
例题
训练 方法I II III
表扬 45 6953 51
51 5062 68
52 1825 32
物质奖励 54 7269 66
53 6367 70
51 5947 42
表扬 +物质奖励
91 8789 91
69 7377 74
66 6870 64
警察在训练狗时,有三种训练方法和三种奖励办法。训练 6 个月后找回东西的能力分数如下表。
Cell
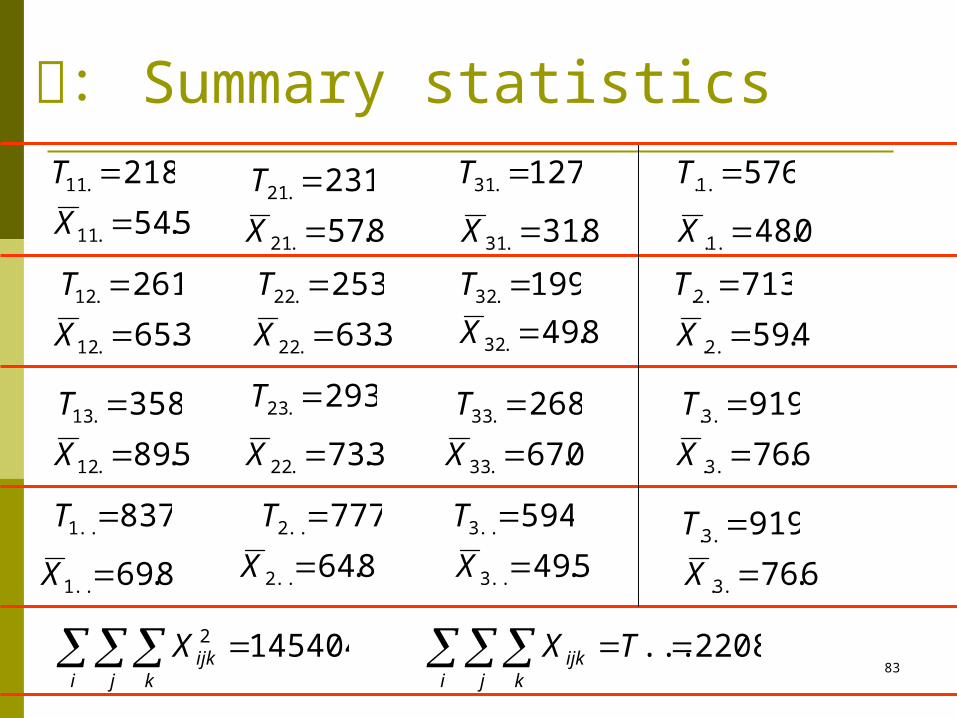
83
解: Summary statistics218.11 T 231.21 T 127.31 T
5.54.11 X 8.57.21 X 8.31.31 X
576.1. T
0.48.1. X
261.12 T
3.65.12 X
253.22 T
3.63.22 X
199.32 T
8.49.32 X
713.2. T
4.59.2. X
358.13 T
5.89.12 X
293.23 T
3.73.22 X
268.33 T
0.67.33 X
919.3. T
6.76.3. X
837..1 T
8.69..1 X
777..2 T
8.64..2 X
594..3 T
5.49..3 X919.3. T
6.76.3. X
1454042 i j k
ijkX 2208... TXi j k
ijk

84
平方和00.9980
36
2208145404
2
TotalSS
50.822136
2208
4
268...
4
231
4
218 2222
CellsSS
50.1758 CellsTotalError SSSSSS
50.267036
2208
12
594
12
777
12
837 2222
ASS训练方法
奖励制度17.4968
36
2208
12
919
12
713
12
576 2222
BSS
互作 83.582 BACellsBA SSSSSSSS
85
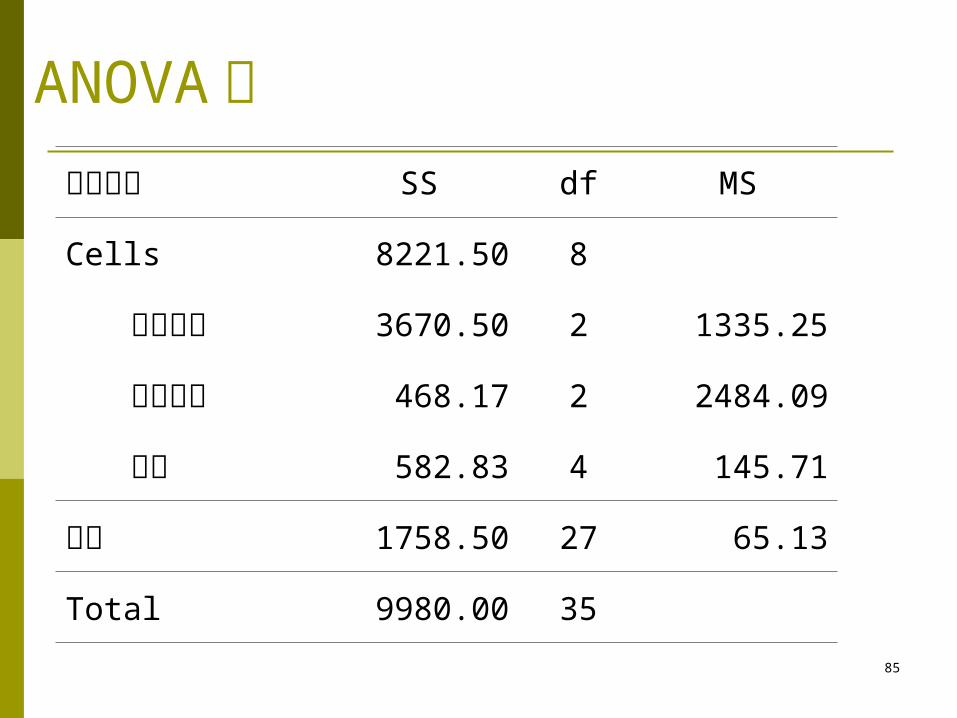
ANOVA 表变异来源 SS df MS
Cells 8221.50 8
训练方法 3670.50 2 1335.25
奖励制度 468.17 2 2484.09
互作 582.83 4 145.71
误差 1758.50 27 65.13
Total 9980.00 35

86
互作的检验 FA×B =145.71/65.13=2.24 c.v.: F0.05(4,27)=2.73 结论:互作不显著

87
主效应训练方法: H0: I=II= III Ha: 至少有一对平均数不等 FA=1335.25/65.13=20.50 c.v.: F0.05(2,27)=3.35 显著训练方法不同会造成效果不同

88
主效应奖励制度 H0: P=T= P+T
Ha: 至少有一对平均数不等 FB=2484.0964.13=38.14 c.v.: F0.05(2,27)=3.35 显著奖励方法不同效果不同

89
多重比较
330.243
13.64
bn
MSE
平均数数量2 3
rp 2.919 3.066
LSRp 6.801 7.144
训练方法 i-49.5 i-64.8
I 69.8 20.3* 5.0ns
II 64.8 15.3*
III 49.5

90
多重比较
330.243
13.64
an
MSE
平均数数量2 3
rp 2.919 3.066
LSRp 6.801 7.144
奖励办法 i-48.0 i-57.4
P+T 76.6 28.6* 17.2*
T 57.4 11.4*
P 48.0

91
第五节数据转换

92
方差分析假定 三个假定
效应可加 处理效应与误差效应应该是“可加的”,正是由于这一“可加
性”,才有了样本平方和的“可加性”,亦即有了试验观测值总平方和的“可剖分”性。
数据服从正态分布 是指所有试验误差是相互独立的,且都服从正态分布 N(0 , σ
2) 数据方差同质 : 差异不显著
各个处理观测值总体方差 σ2应是相等的
93
处理方法 如果在分差分析前发现有某些异常的观测值、处
理或单位组,只要不属于研究对象本身的原因,在不影响分析正确性的条件下应加以删除
有些资料就其性质来说就不符合方差分析的基本假定 应该进行数据转换

94
数据转换 平方根转换 (square root transformation)
此法适用于各组均方与其平均数之间有某种比例关系的资料,尤其适用于总体呈泊松分布的资料。转换的方法是求出原数据的平方根 。若原观测值中有为 0 的数或多数观测值小于 10 ,则把原数据变换成 ,对于稳定均方,使方差符合同质性的作用更加明显。变换也有利于满足效应可加性和正态性的要求
x
1x
95
数据转换 对数转换 (logarithmic transformation)
如果各组数据的标准差或全距与其平均数大体成比例,或者效应为相乘性或非相加性,则将原数据变换为对数 (lgx 或 lnx) 后,可以使方差变成比较一致而且使效应由相乘性变成相加性。
如果原数据包括有 0 ,可以采用 lg(x+1) 变换的方法。 一般而言,对数转换对于削弱大变数的作用要比平方根转换更强。
96
数据转换 反 正 弦 转 换 (arcsine transformation)
也称角度转换 适用于 如发病率、 感染率、病死率、受胎率等服从 二项
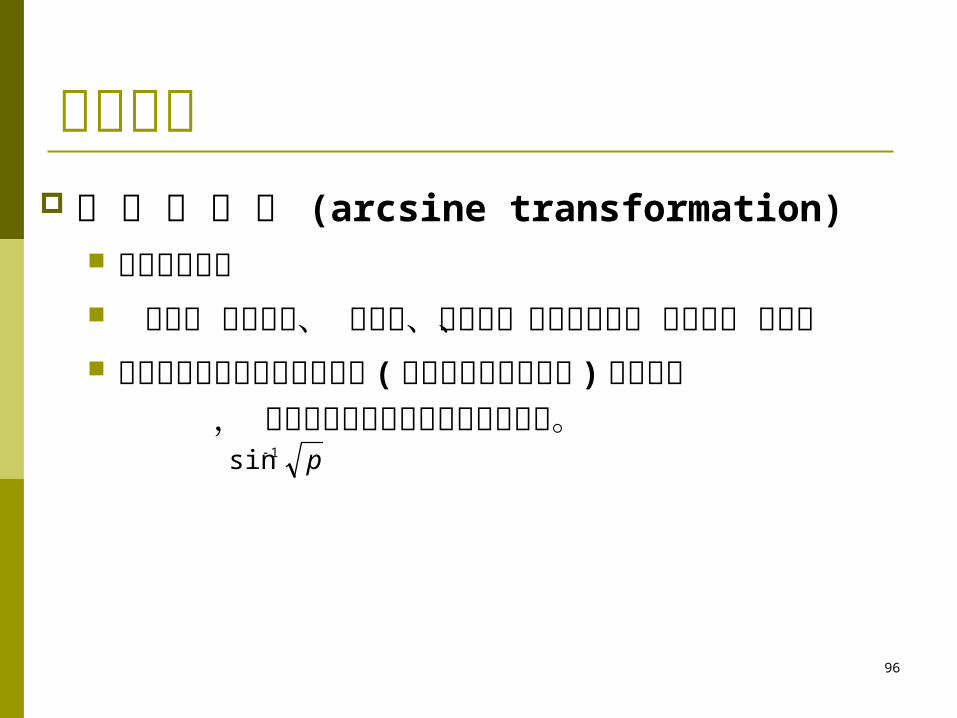
分布 的资料 转换的方法是求出每个原数据 ( 用百分数或小数表示 ) 的反正弦 , 转换后的数值是以度为单位的角度。p1sin

97
数据转换 二项分布的特点是其方差与平均数有着函数关系。这
种关系表现在,当平均数接近极端值 ( 即接 近 于 0 和 100% ) 时,方 差 趋 向 于 较 小 ; 而 平均数处于 中 间 数 值 附 近 ( 50% 左 右 ) 时 ,方 差 趋 向 于 较 大 。把 数 据 变 成 角 度 以后,接近于 0 和 100% 的数值变异程度变大,因此使方差较为增大,这 样 有利于满足方差同质性的要求。一 般,若 资 料 中 的 百 分数介于 30%—70%之间时,因资料的分布接近于正态分布,数据变换与否对分析的影响不大

98
数据转换 在对转换后的数据进行方差分析时,若经检验差
异显著,则进行平均数的多重比较应用转换后的数据进行计算。但在解释分析最终结果时,应还原为原来的数值
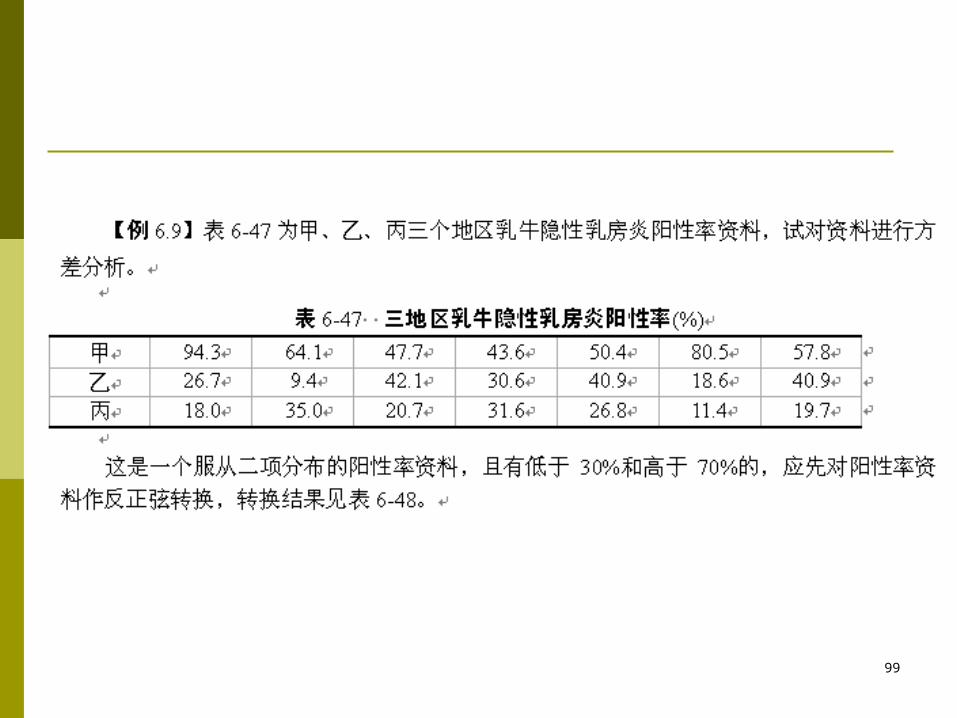
99
100
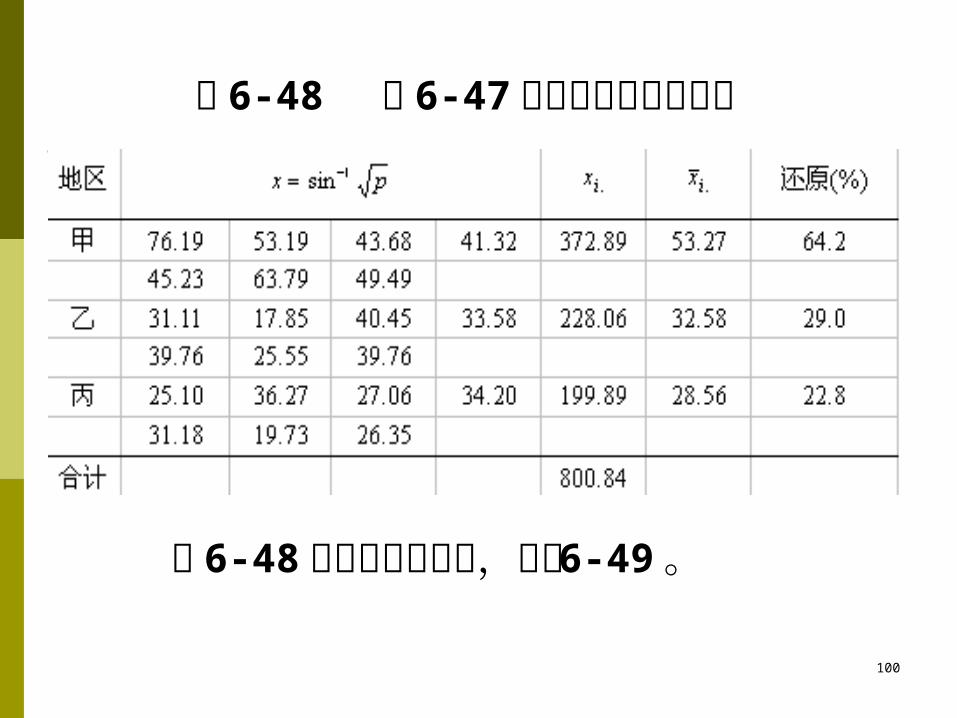
表 6-48 表 6-47 资料的反正弦转换值
表 6-48 资料的方差分析,见表 6-49 。
101
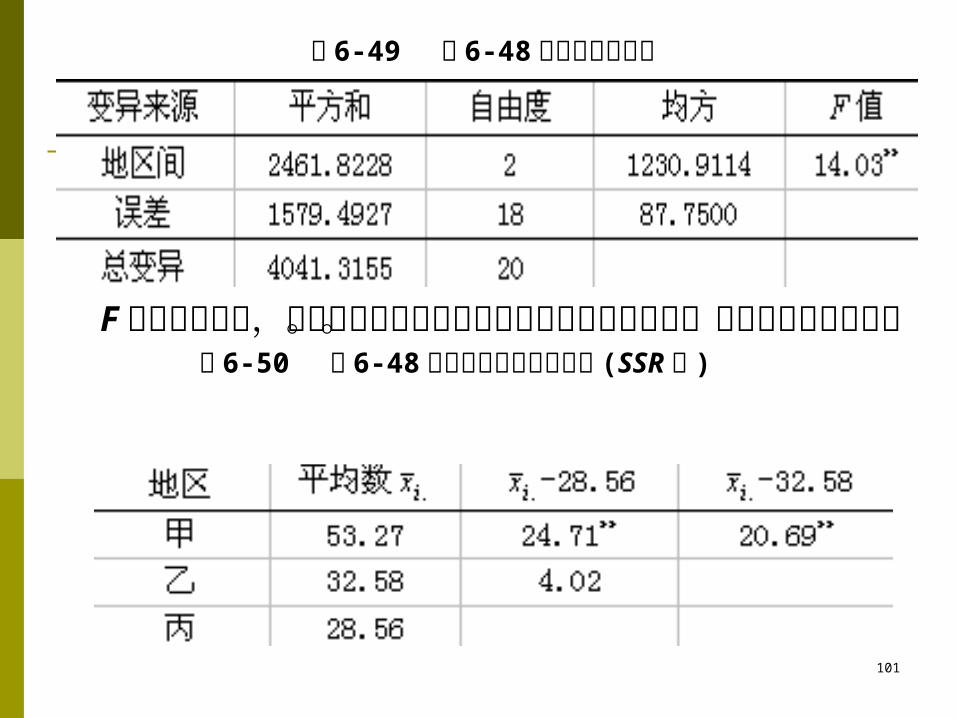
表 6-49 表 6-48 资料的方差分析
F 检验结果表明,各地区间乳牛隐性乳房炎阳性率差异极显著。下面进行多重比较。
表 6-50 表 6-48 资料平均数多重比较表 (SSR 法 )

102
因 , SSR 值 LSR 值见表 6-51
表 6-51 SSR 值与 LSR 值
18,54.37/7500.87 ex dfS

103
对结论作解释时,应将各组平均数还原为阳性率。如表 6-50 中 平 均 数 53.27 根 据 P=sin2
x ,还原为 64.2% ;均数 32.58 还原为 29.0% ;均数 28.56 还原为 22.8% 。但从变换过的数据所算出的方差或标准差不宜再换回原来的数据。
检验结果表明,甲地区乳牛隐性乳房炎阳性率极显著高于丙地区和乙地区,乙地区与丙地区阳性率差异不显著。

104
以上介绍了三种数据转换常用方法。对于一般非连续性的数据,最好在方差分析前先检查各处理平均数与相应处理内均方是否存在相关性和各处理均方间的变异是否较大。如果存在相关性,或者变异较大,则应考虑对数据作出变换。 有 时 要确定适当的转换方法并不容易, 可事先在试验中选取几个其平均数为大、中、小的处理试验作转换。哪种方法能使处理平均数与其均方的相关性最小,哪种方法就是最合适的转换方法。

105
另外,还有一些别的转换方法可以考虑。例如当
各处理标准差与其 平均数 的 平 方 成 比 例 时 ,
可 进 行 倒 数转换 (reciprocal transformatio
n) ;对于一些分 布 明 显 偏 态 的 二项分布资料,
有人进行
的转换,可使 x 呈良好的正态分布。
2/11 )(sin px