电子政务数据库基础 -...
TRANSCRIPT

面向 21 世纪电子政务专业核心课程系列教材
全国高等院校电子政务联编教材
电子政务数据库基础
E-Government Database Primer
潘 郁 主编
陆敬筠 菅利荣 胡 桓 潘 芳 参编

内 容 提 要
本书是根据电子政务本专科专业教学体系的基本要求编写的。本书针对电子政务系统的特点,较全面
地介绍了信息管理的模型和关系数据库的相关理论,基于 Web 的电子政务数据库技术的基本概念、开发
方法和工作内容。重点阐述 SQL 语言和集成开发工具、政务数据库设计方法和政务信息挖掘利用等基础
知识,详细地介绍了政务数据库的信息共享、信息发布、信息维护和数据处理等主要技术内容。并且通过
实验教学和案例分析,为读者全面了解数据库技术在电子政务中的应用,运用数据库技术从事政府行政管
理和公共事业管理,应用、维护和开发电子政务系统打下坚实的基础。
本书以介绍电子政务入门实务知识为目的,内容丰富,通俗易懂,针对性强。适用于作为电子政务本
专科专业或公共管理类、经济管理类等相近各专业本专科生、MPA、研究生的教材和自学参考书,也可供
广大从事电子政务系统应用和开发的各类人员参考。
图书在版编目(CIP)数据
电子政务数据库基础/潘郁主编.—北京:北京大学出版社,2005.7
(面向 21 世纪电子政务专业核心课程系列教材)
ISBN 7-301-08935-X
I.电··· II.潘··· III.电子政务—数据库-高等学校-教材 IV.①D035.1-39②TP311.13 中国版本图书馆 CIP 数据核字(2005)第 031835 号 书 名:电子政务数据库基础
著作责任者:潘郁 主编
责 任 编 辑:王妍
标 准 书 号:ISBN 7-301-08935-X/TP·0785
出 版 者:北京大学出版社
地 址:北京市海淀区成府路 205 号 100871
电 话:邮购部 62752015 发行部 62750672 编辑部 62765013
网 址:http://cbs.pku.edu.cn
电 子 信 箱:[email protected]
印 刷 者:
发 行 者:北京大学出版社
经 销 者:新华书店
787 毫米×1092 毫米 16 开本 14.5 印张 335 千字
2005 年 7 月第 1 版 2005 年 7 月第 1 次印刷
定 价:24.00 元

前 言
20 世纪 80 年代初,西方一些国家开始了包括管理创新在内的政府创新运动。进入 90 年
代后,以互联网为代表的信息科技的发展对政府创新起到了催化作用。与此同时,基于互联
网的电子政务与政府管理创新呈现出强大的互动态势。自 1999 年我国实施政府上网工程以
来,经过多年的发展,电子政务建设已经日趋成熟。特别在 2003 年,电子政务成为社会信息
化最为火热的领域。《国家信息化领导小组关于我国电子政务建设指导意见》对电子政务建
设和软件产业发展提出了具体的指导意见。据预计,未来三至五年内,中国电子政务的市场
需求将达到 5000 亿元的规模。电子政务建设开始从网络基础建设向功能应用层面和社会服务
层面转变,注重应用已经成为电子政务建设的主题。作为电子政务主要功能的政务公开和网
上办公等将涉及到大量政务信息的采集、传输、存储、发布、共享、维护和分析,需要有相
应的网络数据库系统进行技术支撑。这本《电子政务数据库基础》是全国高等院校电子政务
专业课程系列教材之一,并附有配套的电子教案。全书以 SQL Server 2000 为数据库背景,面
向公共管理和社会工作实际应用,重点在于阐述基于 Web 的电子政务数据库技术入门知识和
实现方式,对读者的先修课程和知识领域没有特别要求。
全书由南京工业大学管理科学与工程学院潘郁教授主编,执笔撰写的有潘郁(第 1 章、
第 8 章)、陆敬筠(第 2 章、第 3 章、第 4 章)、菅利荣(第 5 章、第 9 章)、胡桓(第 6 章、
第 7 章)、潘芳(第 10 章),最后由潘郁教授负责统稿审定。姚国章老师为本书的出版做了大
量的工作,在此表示感谢。由于是系列教程,在本套丛书中其他教程涉及到的内容,恕不赘
述。
本书运用了作者长期以来积累的科研成果和技术经验,同时也参考了国内外有关的书籍
和资料以及大量的网站信息,在每一章节的末尾以参考文献的形式列出,对相关的作者和机
构表示诚挚的谢意。由于作者水平有限,疏漏之处难免,敬请广大读者批评指正。
作 者
2005年 1 月

目 录
第 1 章 政务数据库技术 ......................................................................................................1
1.1 电子政务的数据特征 .................................................................................................1
1.2 政务基础数据库.........................................................................................................3
1.3 政务数据库应用开发过程 .........................................................................................6
1.4 本章小结 ..................................................................................................................10
1.5 本章习题 ..................................................................................................................10
1.6 本章参考文献...........................................................................................................10
第 2 章 数据库系统概论 ....................................................................................................12
2.1 数据库技术发展 ...................................................................................................12
2.1.1 数据处理技术的演变.................................................................................12
2.1.2 数据库系统的发展过程.............................................................................14
2.2 数据模型...............................................................................................................15
2.2.1 基本概念 ....................................................................................................15
2.2.2 概念数据模型 ............................................................................................18
2.2.3 逻辑数据模型的类型.................................................................................21
2.3 数据库系统的结构 ...............................................................................................25
2.3.1 数据库系统的组成 ....................................................................................25
2.3.2 DBMS ........................................................................................................27
2.4 关系数据库管理系统实例 ...................................................................................27
2.4.1 Access.........................................................................................................28
2.4.2 Oracle .........................................................................................................29
2.5 电子政务数据库技术新发展................................................................................31
2.6 本章小结...............................................................................................................33
2.7 本章习题...............................................................................................................34
2.8 本章参考文献.......................................................................................................34
第 3 章 数据库设计基础 ....................................................................................................35
3.1 关系数据库设计理论 ...........................................................................................35
3.1.1 关系数据库设计缺陷.................................................................................36
3.1.2 函数依赖和多值依赖.................................................................................37
3.1.3 关系模式的规范化 ....................................................................................39
3.1.4 关系规范化的基本原则.............................................................................41
- 2 - 电子政务数据库基础
3.1.5 规范化小结 ..................................................................................................42
3.2 数据库设计中的关系范式 ...................................................................................44
3.3 电子政务数据库应用系统的结构........................................................................45
3.3.1 客户机/服务器的组成 ...............................................................................46
3.3.2 二层客户机/服务器的结构........................................................................46
3.3.3 三层客户机/服务器的结构........................................................................48
3.3.4 浏览器/服务器(B/S)结构......................................................................49
3.3.5 电子政务数据库应用系统的实现技术 .....................................................53
3.4 本章小结...............................................................................................................55
3.5 本章习题...............................................................................................................55
3.6 本章参考文献.......................................................................................................55
第 4 章 SQL........................................................................................................................56
4.1 SQL 概述..................................................................................................................56
4.1.1 SQL 的发展及主要特点....................................................................................56
4.1.2 SQL 支持的数据库体系结构............................................................................57
4.1.3 SQL 的组成 .......................................................................................................58
4.2 SQL 中的数据定义语言...........................................................................................58
4.2.1 基本数据类型....................................................................................................58
4.2.2 基本表的创建、修改和撤销 ............................................................................59
4.2.3 视图的创建和撤销 ............................................................................................62
4.2.4 索引的创建和撤销 ............................................................................................64
4.3 SQL 中的数据查询语言...........................................................................................65
4.3.1 查询语句的一般格式及功能 ............................................................................65
4.3.2 单表查询............................................................................................................65
4.3.3 多表查询............................................................................................................67
4.3.4 嵌套子查询........................................................................................................67
4.3.5 集合查询............................................................................................................69
4.3.6 库函数及算术表达式值的查询.........................................................................69
4.3.7 分组查询............................................................................................................70
4.4 SQL 中的数据操作语言...........................................................................................71
4.4.1 数据插入............................................................................................................71
4.4.2 数据删除............................................................................................................72
4.4.3 数据更新............................................................................................................73
4.5 SQL 中的数据控制语言...........................................................................................73
4.5.1 授权 ...................................................................................................................74
4.5.2 收回授权............................................................................................................74
4.6 本章小结 ..................................................................................................................75
4.7 本章习题 ..................................................................................................................75
4.8 本章参考文献...........................................................................................................76

目录 - 3 -
第 5 章 SQL Server 2000 ....................................................................................................77
5.1 SQL Server 2000 概述 ..............................................................................................77
5.1.1 SQL Sever 2000 简介.........................................................................................77
5.1.2 SQL Server 2000 服务管理器............................................................................78
5.1.3 SQL Sever 2000 企业管理器.............................................................................80
5.1.4 SQL 查询分析器(SQL Query Analyzer) ......................................................80
5.2 SQL Server 2000 身份认证模式..............................................................................81
5.2.1 SQL Server 2000 身份认证模式.......................................................................81
5.2.2 用户账号的建立和管理 ....................................................................................82
5.3 数据库和表的创建、修改和删除............................................................................84
5.3.1 SQL Server 2000 数据库对象............................................................................84
5.3.2 数据库和表的创建、修改和删除.....................................................................85
5.3.3 表数据操作........................................................................................................92
5.4 数据库的查询和视图 ...............................................................................................95
5.4.1 基本概念............................................................................................................95
5.4.2 视图的创建........................................................................................................96
5.4.3 视图的查询和更新 ............................................................................................99
5.5 索引和数据完整性.................................................................................................100
5.5.1 索引 .................................................................................................................100
5.5.2 默认值约束及默认值对象 ..............................................................................101
5.5.3 数据完整性......................................................................................................104
5.6 存储过程 ................................................................................................................109
5.7 备份与还原............................................................................................................. 112
5.8 本章小结 ................................................................................................................ 115
5.9 本章习题 ................................................................................................................ 115
5.10 本章参考文献....................................................................................................... 115
第 6 章 电子政务数据库系统设计 .................................................................................. 117
6.1 电子政务数据库的特点 ......................................................................................... 117
6.1.1 电子政务数据库的特点 ..................................................................................117
6.1.2 信息系统生命周期 ..........................................................................................119
6.1.3 数据库生命周期 ..............................................................................................119
6.1.4 数据库设计流程 ..............................................................................................120
6.2 政务数据库概念设计 .............................................................................................121
6.2.1 数据库调研......................................................................................................122
6.2.2 数据库概念设计 ..............................................................................................127
6.3 DBMS 的选择、逻辑数据库设计及实现 .............................................................128
6.3.1 DBMS 的选择 .................................................................................................128
6.3.2 逻辑数据库设计 ..............................................................................................130
6.3.3 物理设计..........................................................................................................135

- 4 - 电子政务数据库基础
6.3.4 数据库实现、测试和调整 ..............................................................................136
6.4 电子政务平台数据中心 .........................................................................................136
6.4.1 电子政务平台数据交换中心建设背景...........................................................137
6.4.2 数据交换中心概述 ..........................................................................................137
6.4.3 数据交换中心架构描述 ..................................................................................138
6.5 本章小结 ................................................................................................................141
6.6 本章习题 ................................................................................................................142
6.7 本章参考文献.........................................................................................................142
第 7 章 电子政务数据库保护 ..........................................................................................144
7.1 数据库保护基础.....................................................................................................144
7.1.1 电子政务数据库安全分析 ..............................................................................144
7.1.2 电子政务数据库保护常规技术.......................................................................146
7.2 数据库保护相关技术 .............................................................................................153
7.2.1 数据库备份与恢复 ..........................................................................................153
7.2.2 容灾管理技术..................................................................................................155
7.2.3 数据库保护的法律相关问题 ..........................................................................158
7.3 本章小结 ................................................................................................................161
7.4 本章习题 ................................................................................................................162
7.5 本章参考文献.........................................................................................................162
第 8 章 CGI 和 ODBC 互联技术 .....................................................................................164
8.1 CGI 的基本内容.....................................................................................................164
8.2 ODBC 的基本原理.................................................................................................168
8.3 数据源与 Web 的 ODBC 连接 ...............................................................................170
8.4 本章小结 ................................................................................................................173
8.5 本章习题 ................................................................................................................173
8.6 本章参考文献.........................................................................................................173
第 9 章 电子政务数据仓库与数据挖掘...........................................................................174
9.1 数据仓库 .................................................................................................................174
9.1.1 数据仓库的概念及特性 ..................................................................................174
9.1.2 数据仓库中的数据组织 ..................................................................................177
9.1.3 数据仓库的体系环境 ......................................................................................180
9.1.4 数据仓库的关键技术 ......................................................................................183
9.2 数据挖掘 .................................................................................................................185
9.2.1 数据挖掘概述..................................................................................................186
9.2.2 数据挖掘的常用技术 ......................................................................................187
9.2.3 数据挖掘的分析方法 ......................................................................................189
9.2.4 数据挖掘内容..................................................................................................191
9.2.5 数据挖掘工具..................................................................................................192

目录 - 5 -
9.2.6 数据挖掘流程..................................................................................................192
9.3 基于数据仓库的电子政务资源库建设...................................................................193
9.3.1 电子政务数据仓库建设 ..................................................................................193
9.3.2 基于数据仓库的电子政务决策支持系统 .......................................................194
9.4 本章小结 .................................................................................................................195
9.5 本章习题 .................................................................................................................195
9.6 本章参考文献 .........................................................................................................195
第 10 章 数据库在电子政务中的应用实例.....................................................................197
10.1 实例一:政府信息发布子系统........................................................................197
10.1.1 概述........................................................................................................197
10.1.2 数据库表设计 ........................................................................................200
10.1.3 典型程序段分析 ......................................................................................206
10.2 实例二:就业招聘子系统................................................................................208
10.2.1 概述........................................................................................................208
10.2.2 数据库表设计 ........................................................................................213
10.2.3 典型程序段分析 ....................................................................................215
10.3 本章小结...........................................................................................................219
10.4 本章习题...........................................................................................................219
10.5 本章参考文献 ...................................................................................................219

第 1 章 政务数据库技术
电子政务(E-Government)是在经济调节、市场监管、社会管理和公共事务等公共管理领域
中运用现代信息和通信技术,打破行政机关的组织界限,建构一个电子化的虚拟机构和施政
渠道,使得各级政府和事业机构的政务处理电子化。主要包括政务电子化、信息公布与发布
电子化、信息传递与交换电子化、公众服务电子化等。以适应虚拟的、全球性的、以知识为
基础的数字经济,同时也适应社会的根本转变。
电子政务系统在数字化、网络化的技术集成平台上,实现政府组织结构和工作流程的重
组优化,将政府资源、企业资源、社会资源和社会服务无缝连接在一起,使大量行政管理和
日常事务都能通过计算机网络和软硬件得到实施。其实质就是构造能实现社会增值和电子社
区化的电子政府。电子政务运作过程在计算机系统内的表现形式是大量地运用 Web 技术,在
计算机网络上以声音、图像、视频、虚拟现实等形态传播政务信息。其中直接服务于公民的
各类应用系统和数据资源的“电子政务基础数据库”和“电子政务信息交换平台”等是整个
电子政务的神经中枢。设计规划好各个层面的数据库及其数据流转是电子政务系统建设的关
键所在。
本章主要内容:
� 电子政务的数据结构和信息形式
� 电子政务基础数据库
� 建立电子政务网站平台的步骤
1.1 电子政务的数据特征
根据国家标准管理委员会和国务院信息化工作办公室颁布的《电子政务标准指南》,电
子政务的总体框架由网络基础设施层、应用支撑层、应用层和公众服务层组成。电子政务系
统主要包括以下三部分:政府机关内部的办公自动化系统;政府对外信息发布和反馈平台;
政府部门间的信息共享和通信系统。政务信息数据资源流转和共享关系如图 1.1 所示。电子
政务主要面对公众服务的应用形式有政府公告、政务咨询、网上申报、网上反馈、投诉受理、
网上审批 、电子化政府采购及招标、网上福利支付、 电子邮递、电子资料库、电子化公文系
统、网上报税、网上身份认证和电子社区等;对内则是构筑具有综合业务处理、并联审批和
协同办公、公文处理、分布式档案库、政府内务管理、数字城市应用、视频会议、远程办公、
消息通知、辅助预测和决策等功能的应用平台。

- 2 - 电子政务数据库基础
图 1.1 电子政务系统信息数据共享结构
电子政务系统中的数据信息具有如下特征。
(1)数据来源复杂。政务系统建设是逐步发展起来的,有个时间进程。由于早期电子政
务建设没有统一的规划,各政府部门的信息建设没有统一的标准。由于技术标准、设计规范
和使用方式等各不相同,在计算机体系结构和操作系统、数据库管理系统、数据库逻辑结构
和物理结构等方面整体上呈现出异构性,形成了政务数据库建设的技术障碍。电子政务应用
的首要基本功能就是制定通用信息交换格式标准,把不同载体、不同类型的办公文献资料经
过数字化、标准化以及自动化处理,形成支持数据库管理的统一的标准格式,从而成为政府
系统共建共享的电子信息资源库。在实现电子政务数据报文传送、管理以及报文转换和应用
集成的过程中,要面对各种需求不同的报文,它们会具有不同的格式和标准;还要面对多种
不同的计算环境、结构、体系以及各种不同的网络通信协议的差异。这就要求数据交换能支
持多种协议。
(2)数据表现形式多样化。政务数据库中有表征国家经济状况的数值型数据,也有描述
自然资源和城市地理的遥感影像数据和矢量地形数据,还有在政务办公中将图像、声音、文
字、动画等多种媒体整合在一起的动态多媒体数据。政务信息的载体大多以文件、报表、信
函、传真等形式出现,常常是一种非结构化数据,有别于传统的结构化数据类型信息。需要
外网
企业网
公网
居民个人
公众服务门户系统
防火墙
数据交换平台
政务办公平台公共基础数
据库
内网
第 1 章 政务数据库技术 - 3 -
应用基于文档型数据库和多媒体数据库的群件系统,例如 Notes/Domino 等。
(3)广域分布。电子政务寄生在计算机网络上,其服务覆盖整个地域。在这个网络虚拟
空间中,存储、传递、获取和服务信息的方式发生根本性变化,已经没有空间物理距离的概
念了。政务信息数据被广泛散布在各个政府部门节点上。每个节点具有独立处理信息的能力
(场地自治),可以执行局部应用,也能通过网络执行全局应用。这些数据库虽然分布在不同
的节点上,但在逻辑上是相互关联在一起的。
(4)海量数据处理。政务基础数据库作为城市或区域的信息资源,其数据规模与城市的
信息化程度、人口规模、信息系统应用时间、区域社会经济的发展等因素相关。在基础数据
库的建设中需要充分预测其数据的增长幅度,建立有效的海量数据管理机制、历史数据管理
机制来提供对大容量历史数据的有效管理。我国是一个政府主导型的社会。政府是社会的主
导者,又是社会信息资源的最大拥有者,80%以上的信息资源掌握在政府手中。随着政务信
息源源不断地增加和政务系统运用的拓广,各个部门、单位和个人之间信息交互数量急剧上
升。这对网络传输和数据库信息综合管理功能提出了很高的要求。通过高性能的信息检索和
内容管理系统对海量且种类繁多的政府信息资源进行科学地收集、筛选、分类、检索,建立
和完善各级政务信息资源目录体系(包括服务目录、数据目录、安全目录和服务体系),才能
真正实现资源共享,使电子政务发挥最大效用。
(5)完备的安全性。电子政务是治理国家和地区的组织方式和应用工具,其中将涉及到
大量非公开性信息。政务数据库应具备包括防止非法用户侵入、权限控制、存储和传输加密
以及电子签名等在内的安全性控制功能。并且需要建立完善的数据备份与灾难恢复制度,在
数据服务的各个环节做好冗余备份机制。
(6)信息的时效性和深度利用。政务数据不但带有很强的时效性,而且还隐含着大量的
增值信息。政务数据库系统必须能够支持实时信息传输和存取,还能运用数据仓库和数据挖
掘技术,挖掘大量历史数据的挖掘进行现状分析、预测未来发展趋势、为政府的宏观决策提
供决策支持。上述电子政务信息特征对政务数据管理系统提出了一系列苛刻的要求。数据库
系统(Database System)是指一个完整的、能为用户提供信息服务的系统,它由计算机系统
和计算机网络、数据库与数据库管理系统和基于数据库的应用软件系统三部分组成。数据库
技术从 20 世纪 60 年代中期产生到现在,虽然只有短短几十年的历史,但发展速度很快,已
得到广泛的应用。数据库系统已经从第一代的网状、层次数据库系统,第二代的关系数据库
系统,发展到第三代以面向对象模型为主要特征的数据库系统。分布式数据库、多媒体数据
库、工程数据库、演绎数据库、模糊数据库、并行数据库、主动数据库等新型数据管理方法
和工具的应用为电子政务的数据处理和信息共享提供了良好的技术支撑平台。
1.2 政务基础数据库
2002 年 7 月,国务院信息化领导小组在《我国电子政务建设总体框架》中提出我国电子
政务建设工作将主要以“两网”(政务内网和政务外网)、“一站”(政府门户网站)、“四库”
(人口基础信息库、法人单位基础数据库、自然资源和空间地理信息数据库、宏观经济数据

- 4 - 电子政务数据库基础
库)和“十二金”(办公业务资源系统、宏观经济管理、金关、金税、金财、金卡、金审、金
盾、社会保障、金农、金水和金质)为核心内容。国家、省市电子政务统一支撑平台作为区
域信息资源整合集成的总节点,由相应的电子政务中心或数据中心负责建设和维护,并负责
提供各所属下级节点的信息资源目录。由各级政府和社区等部门及其下属的信息中心作为数
据产生节点,负责数据建设、更新、维护,并为其他部门提供服务。数据使用部门通过信息
资源目录系统进行信息资源的发现、定位及访问等操作,到数据产生单位获取数据。各级政
府部门和社区业务系统应用数据库和基础信息资源库在重点建设的四大战略性政务数据库基
础上进行。其业务数据库中的数据将通过元数据采集、增量数据采集引擎,以增量的方式组
成部门基础数据库。基础数据库建设的主要内容如下。
(1)人口基础数据库
人口基础数据库的基础是公安部门人口信息库,通过比对、整合数据项提供部门的信息,
建立城市分布式人口基础数据库。以劳动、公安、民政、卫生、教育、地税、国税、公积金
中心等部门信息来源为基础的人口基础信息库将针对衡量城市人口整体状况的各项基本指
标,特别是人口结构、人口素质、人口动态变化、个人身份识别、个人信用档案、人的户籍
管理、人的基本生理指标、人的职业流动等进行全过程追踪记录。人口基础数据库数据项包
括公安户籍信息、劳动就业信息、社会保障信息、教育信息、卫生健康信息、计划生育信息、
民政信息、住房公积金信息、个人纳税信息、住房状况信息等。
我国 13 亿人口的人口基础信息库已经开始建设。据介绍,人口基础信息库由公安部联合
计划生育委员会、国家税务总局、劳动和社会保障部以及国家民政部等部委共同建造。国家
为此直接投入的资金达 60 亿人民币。该数据库的核心内容将包括我国 13 亿常住公民的姓名、
性别、身份证号码、出生年月、出生地和民族等 6 项基本信息。更多的信息将在相关部委的
协作下在基本信息的基础上做进一步的扩展。到 2006 年将建立一个完整的全国人口基础信息
数据库。
(2)法人单位基础数据库
建立以工商、税务、计监等部门信息资源为基础的法人单位基础数据库,对法人单位的
基本情况进行采集、整理、登记、存储、分析,为国民经济和社会生活提供信息服务。法人
单位基础信息数据库系统涵盖各企业、事业、机关部门、社会团体等法人单位的基础信息。
该库是在组织机构代码数据库的基础之上,由工商局、质检部门的组织机构代码库,工商部
门的企业注册登记库,地区编办的事业单位注册登记和民政社团登记库,地税、国税部门的
税务数据库,统计部门的基本单位普查库等整合建立起来的。
法人单位基础数据库由国家质检总局牵头组织建设。3 年内将建成以组织机构代码为惟
一标识的全国法人单位基础信息库和查询服务系统。国务院发出通知,决定于 2004 年进行第
一次全国经济普查,标准时点为 2004 年 12 月 31 日,时期资料为 2004 年度。定于 2003 年进
行的第二次全国第三产业普查推迟,与计划在 2005 年开展的第四次全国工业普查和 2006 年
开展的第三次全国基本单位普查合并,同时将建筑业纳入普查范围。今后全国经济普查将每
10 年进行两次,分别在逢 3、逢 8 的年份实施。此次经济普查的对象是在我国境内从事第二
产业和第三产业的全部法人单位、产业活动单位和个体工商户。具体范围包括采矿业,制造
业,电力、燃气及水的生产和供应业,建筑业,交通运输、仓储和邮政业,信息传输、计算
机服务和软件业,批发和零售业,住宿和餐饮业,金融业,房地产业,租赁和商务服务业,

第 1 章 政务数据库技术 - 5 -
科学研究、技术服务和地质勘查业,水利、环境和公共设施管理业,居民服务和其他服务业,
教育,卫生、社会保障和社会福利业,文化、体育和娱乐业,以及公共管理和社会组织等。
普查的主要内容包括单位标志、从业人员、财务收支、资产状况,以及企业的主要生产经营
活动和生产能力、主要原材料和能源消耗及科技开发的投入状况等。此次经济普查,主要是
为了全面掌握我国第二产业和第三产业的发展规模、结构和效益等信息,建立健全覆盖国民
经济各个行业的基本单位名录库(含编码)及其数据库系统。
(3)自然资源和空间地理信息数据库
以规划、土管、房管部门信息来源为基础的基础地理空间信息库以电子地图为背景,主
要描述城市规划、土地利用、地形地貌特征、城市空间布局、城市图形、地产价格及其动态
变化、城市土地级差地租动态变化等,一直到门牌、户型、街道、城市基础设施(能源、交
通、通讯、自来水及排污管道等)的动态记录和识别。整合道路、行政区划、建筑物、植被、
地下管线、土地利用与园林绿化、地籍、规划用地、城市生态环境、居民生活服务、交通服
务、教育机构、科技研究、医疗卫生、体育设施、党政机关等具有基础性的大地控制数据、
遥感影像数据、高程数据、矢量地形数据,建立起来的分布式自然资源和空间地理基础信息
库。
电子政务的地理空间框架主要包括四大体系:基础数据体系、数据交换服务网络体系、
政策法规和标准体系以及组织机构体系。基础数据体系是电子政务地理空间基础框架的核心
内容,主要包括 5 个方面:国家空间定位基准、国家基础地理信息数据库、省级基础地理信
息数据库、城市综合地理信息数据库和专用数据库。空间基础地理信息是描述关于人类赖以
生存的地球的重要信息,对社会持续发展起着重要作用。现代社会生产力的迅速发展以及社
会活动的增强,使人类对于环境作用的强度更加突出,社会和经济等重大问题的决策无不与
基础地理信息相关。国家空间数据基础设施由建立国家空间数据委员会、制定空间数据标准
和法规、建设空间数据交换网和建立基础地理信息数据库等任务组成。随着我国信息产业的
发展和国民经济信息化进程的推进,基础地理信息已成为宏观决策、规划和管理、微观生产
建设、科学研究和日常生活所需要的空间支撑信息。
(4)宏观经济数据库
以统计部门为信息来源基础的分布式宏观经济基础库是通过整合统计政府研究室、发改
委、经委、国税、地税、工商、商务、劳动保障、中国人民银行营业管理部、财政、海关等
部门有关经济的数据项建立起来的。其建设目标和任务是:能够满足政府宏观经济调控决策
时对信息的需要,满足各个层面管理决策的需要;使社会各界可以方便地获取、查询政府宏
观经济数据信息;确保政府数据来源的惟一、全面和权威性,把政府宏观经济信息作为国家
的长期资源管理好。宏观经济数据库由两个主要部分构成:宏观经济数据库核心系统和支撑
子系统。宏观经济数据库核心系统主要由宏观经济数据库的基础架构系统及基础设施运行、
控制子系统和决策支持子系统所组成,包括多种工具和多种应用模型,对国民经济运行和社
会发展态势提供分析和决策支持。支撑子系统由宏观经济数据中心(主要功能构成包括宏观
经济信息和技术标准元数据库、宏观经济数据交换中心、可靠的存储备份、数据的整理净化
系统、用户权限及安全管理子系统等)和宏观经济数据库的信息发布子系统(既是政府提供
服务和管理的窗口,又以信息门户形式建立支撑宏观经济数据库的信息发布、查询子系统)
所组成。

- 6 - 电子政务数据库基础
2002 年 9 月,国家成立了宏观经济数据库项目领导小组,由国家统计局牵头承担国家宏
观经济数据库的建设,统计部门已成为我国电子政务重点建设项目的主要实施单位之一。2002
年 11 月初,国务院信息办听取了宏观经济数据库进展情况的汇报,并对宏观经济数据库的建
设提出了重要意见,其中涉及如何确定宏观经济数据库的边界、重点需求、与其他电子政务
建设项目的关系、数据的管理保存、协调机制及服务模式等问题。2002 年 12 月中旬完成了
《宏观经济数据库建设项目建议书》(初稿)的编写。2003 年 1 月初,举行了宏观经济数据
库建设项目领导小组办公室指标组第一次工作会议;2 月末,举行了宏观经济数据库建设项
目领导小组办公室技术组第一次工作会议,通报宏观经济数据库工作进展情况及工作设想,
介绍宏观经济数据库指标体系初步框架及今后的工作思路,并基本确认了宏观经济数据库建
设方案(草案)。目前,宏观经济数据库正在建设过程中。
(5)其他相关重要基础数据库
根据城市经济发展的需要,可以将对促进经济发展有重要作用的信息作为城市基础信息
库建设的目标。如法律法规数据库、旅游资源数据库、就业信息数据库、个人诚信数据库等
与城市经济、社会生活密切相关的基础性信息资源和以社区管理和服务为基础的居民信息库
个人数据等。
1.3 政务数据库应用开发过程
电子商务系统仅局限于企业有限的经营领域。而电子政务系统的建设则是一项涉及面广、
资源投入巨大、长期的、复杂的系统工程。从国家、省、地区到市县等的各级电子政务系统
与政府组织一样呈现金字塔式的分层结构。其建设必须统一规划、分步实施。如果以数据库
为中心来认识政务系统,可以认为是受数据库驱动的 Web 站点。通常情况下,对用户来说数
据库是不可见的,它在后台支持着 Web 虚拟窗口。如信息发布是将 Web 与数据库集成,用户
通过浏览器与动态超文本标记语言(HTML)、应用服务器向数据库提出查询请求。Web 通过
使用开放式数据库互连(ODBC),由后台数据库动态生成查询结果,按照要求采用多种形式
在用户的客户端上显示数据库数据。又如,政府部门与公众进行网上报关和网上招标等双向
信息交流是通过 Web 界面与数据库交换信息,实现双向地分享数据和数据结构。政府部门要
从事电子政务活动,首先要建立自己的数据库驱动 Web 站点。这些 Web 站点的集成就构成了
在 Internet 上的虚拟政府。一般说来,政务系统的构建是在总体规划的前提下,采用应用原型
化方法进行的。从数据库建设的角度阐述,政府建立电子政务网站的步骤如图 1.2 所示。
(1)总体规划。进行战略规划,确定城市电子政务建设的总体目标、安全目标、性能目
标和经济目标等基本目标。针对地区电子政务的基本功能需求,设计网站建设的基本原则、
建设规范、业务流程重组方案,并完成功能需求和费用预算报告。对涉及到的数据流向、流
量、数据结构(数据项、记录、标识、定义、类型等)、存储要求、访问方式、存取单位、存
取权限和安全保密进行详细设计。在计算机软硬件和网络基础设施的技术平台上,构筑一个
精简、高效、廉洁、公平的政府运作模式。

第 1 章 政务数据库技术 - 7 -
图 1.2 建立电子政务网站步骤
(2)网页设计制作。Web 可以理解为是通过超级链接将各种文档链接进来的一个大规模
的信息集合。网页(Web 页)是用超文本标记语言(Hyper Text Markup Language,HTML)表
示出来的。浏览器的作用主要是将这些标记语言“翻译”过来,并按照定义的格式显示出来。
网站是由网页组成的,在对建立政务网站的目的和网站的内容通盘规划后,就可以开始设计
制作网页、搭建网站了。网页的设计制作离不开网页制作工具。目前的网页制作工具分为两
种:一种以 Netscape 公司的 Navigator、Communicator 和微软公司的 Frontpage 为代表,称为可
见型网页编辑工具;另一种以 HomeSite 为代表,称为非可见型网页编辑工具。初学者大都采
用第一种网页编辑工具,因为它们有“所见即所得”的特性,容易掌握。而且它们不仅可以
作为网页编辑器,还能管理站点,是一个将编辑、管理、出版集成在一起的 Web 工具软件。
目前比较流行的网站制作软件是 Macromedia 公司被称为“网页三剑客”的 Dreamweaver、
Y
网站正式运行
N
功能细化
功能扩充 原型效果
选择 ISP 和 DSP
注册域名和选择接入方式
网页设计制作
创建和维护数据库
整合数据库和网站
业务流程重组和网站试运行
总体规划
政务系统维护 原型完成
Y
Y
N
N

- 8 - 电子政务数据库基础
Fireworks 和 Flash。非可见型的网页编辑工具直接编辑 HTML 代码,不是所见即所得的。此
类编辑程序开始于 HotDog,现在常用的是 HomeSite。政务网站上需要大量的能实时交互存取
数据的动态网页。ASP(Active Server Pages)和 PHP(Personal Home Page)等动态网页脚本
语言提供了这种功能。
(3)创建和维护数据库。在数据访问需求分析、数据交换需求分析和流程控制需求分析
的基础上创建数据库。数据库驱动 Web 站点的核心是网络数据库软件。网站的后台数据库技
术是网站建设的重要技术,几乎没有一个政务网站可以离开后台的数据库而独立存在。网站
的后台数据库性能的好坏关系到整个网站的性能。因此,选择的数据库软件首先必须能满足
电子政务工作性能要求,此外还必须为政府的数据库服务提供商和应用服务器所支持。数据
库软件扩展出了许多不同类型,分别介绍如下。
① 桌面型。包括 Microsoft Access、File MakerPro 和 Xbase(FoxBase 等)。经过应用和开
发,这些产品通过 ODBC 已经扩展并强化到可以支持网络和多用户配置。
② 中小型面向对象型。某些由 JAVA 写成,许多这样的产品被专门设计用于在因特网上
使用。
③ 大型分布型。像 DB2、Oracle、Informix、SQL Server 和 Sybase 这样的企业级数据库产
品,作为数据库的主力已有多年了。这些产品近来已经配备了应用服务器的接口,而且某些
还拥有应用服务器的功能,这类功能嵌入到其服务附件中。
④ 数据仓库型。它与远端数据库结成了庞大的数据库系统。数据库设计的内容是:对于
一个给定的环境,进行符合应用语义的逻辑设计,以及提供一个确定存储结构的物理设计,
建立实现系统目标并能有效存取数据的数据模型。
在选择和创建政务网络数据库时,必须满足以下条件。
① 要适应电子政务对数据处理的需求。能够实现对政务过程中出现的各种非结构化、半
结构化数据的有效管理和查询。并能支持用户需要进行的所有业务处理。
② 提供联网和远程服务,能够进行远程数据控制和数据关联操作,并留有异构数据库通
讯接口。支持海量存储和大流量并发操作。
③ 要具有较高的安全可靠性,易于维护、易于理解、效率较高等。
(4)整合数据库和网站。数据库与动态网页的整合应用,是创建动态网页的另一个重点
技术。从网页上取得数据后,运用数据库可以直接对数据加以存储,这样对于各种数据的需
求与应用将相当便利。数据库也可以成为连接对外开放网站与政府内部管理系统间的数据交
换中心。给 HTML 编写脚本不依赖于语言,因而可以将标准的 HTML 脚本语法与用 JavaScript、
Visual Basic 或者其他脚本语言编写的脚本结合在一起。ISP(Internet、Service、Provider)、数
据库驱动 Web 站点、数据库和应用服务器在 Internet 标准和协议的匹配下,整合在一起协调
地运作。
(5)选择 ISP 和 DSP。政府开展电子政务时,首先要选择一个 Internet 服务提供商(ISP)。
ISP 是可以让用户连入 Internet 并提供网络服务的主机系统。用户向 ISP 申请了账号后,才能
够得到 Internet 服务。ISP 可以分为互联网内容提供商(Internet Content Provider,ICP)和互联
网接入提供商(Internet Access Provider,IAP)两类。ICP 为客户提供各种网上信息服务,如
网络新闻、搜索引擎、网页制作、电子商务等。IAP 专门为用户提供上网服务。国外一般不
强调 ICP 和 IAP 的区别,服务商一般都能为客户提供完整的 ISP 服务。但在我国,由于受基

第 1 章 政务数据库技术 - 9 -
础设施建设等因素的影响,仅有中国电信下属的分支机构等少数服务商能够提供快捷的接入
服务(IAP)。目前我国许多著名的网站,例如新浪、搜狐、网易等,都只能算是 ICP。政府
部门在根据自己的实际情况选择 ISP 时,应注意下面的问题。
① ISP 能够提供的技术条件,例如可用的网络带宽和提供给用户使用的存储空间的大小。
ISP 还可以提供用户域名形式,级别高的域名有利于提高政府部门的形象。
② ISP 能够提供的网络设施与结构。ISP 的设施情况,如服务器的容量、主机速率、软件
情况以及 CGI 支持等,将在很大程度上影响政府所建政务网站的质量。
③ ISP 能够提供的服务种类、技术实力、服务质量和信用。ISP 自身的行为往往是商业行
为,因此服务质量和信用就显得十分重要。在出现网络故障时,实力强大的 ISP 能够迅速解
决问题,而势单力薄的 ISP 则可能会使政府部门延误时机。
④ ISP 综合使用成本。因为 Internet 网络费用取决于 ISP 费用和电信费用。政府部门通过
ISP 和电话公司与 Internet 建立物理连接,接受提供的服务,所以最好选择能就近上网的地点。
从事电子政务的政府部门除按上述要求选择 ISP 外,还必需选择能够提供数据库服务的
ISP。这类 ISP 是数据库服务提供商(Database Service Provider,DSP),其强项在于提供政府
所需要的数据库服务。
(6)注册域名和选择接入方式。域名是政府在 Internet 上的地址,并且具有标志的性质。
只有通过注册域名,才能在互联网里确立自己的一席之地。国际域名在全世界是统一注册的,
负责审批 Internet 域名的机构是位于美国的 Internet 网络信息中心(InterNIC)及其下属的分支
机构。为了保证和促进我国互联网络的健康发展,加强我国互联网络域名系统的管理,我国
有关部门制定颁布了《中国互联网络域名注册暂行管理办法》,在中国境内注册域名,应当依
照该办法办理。办法规定:国务院信息化工作领导小组办公室是我国互联网络域名系统的管
理机构,中国互联网络信息中心工作委员会协助国务院信息办管理我国互联网络域名系统。
政府在建立网站时,应根据自身的实际情况选择网站接入 Internet 的形式。目前,许多 ISP 都
能提供虚拟主机、托管服务器和专线接入 3 种服务方式。因为政务过程中很多是涉密信息,
所以政府内网常常采用专网的形式搭建。
(7)业务流程重组和网站试运行。电子政务打破业务壁垒、共享数据资源,势必需要重
组和优化政府职能和业务流程,才能够充分发挥电子政务系统的实效。通过培训学习,采取
措施,以使政府工作人员从心理上和工作技能上都能适应新的工作方式。网站通过测试验收
就可以运行、开展对外服务了。
(8)政务系统维护。虽然电子政务系统的基本框架都差不多,但根据所在地区和部门的
不同,专业性和专有性都很强。电子政务系统的开发者等采用应用原型化方法,根据用户对
系统提出的主要需求与功能,确定计算机系统管理的范围和应具有的基本功能、人机界面的
基本形式等,最快速地对用户做出需求应答。初始原型建成后,交给用户立即投入试运行,
开通发布。然后与用户不断沟通,反复修改完善,直到用户满意为止。由于政务网站具有实
时性、多向交互等特点,需要专人不断更新网站内容和信息,包括反馈意见处理、计算机软
硬件系统管理、备份和故障排除等。

- 10 - 电子政务数据库基础
1.4 本 章 小 结
在完整的电子政务运行平台支持下,数据库承担着对政务信息资源的存储、管理、查询、
结算和处理等功能,在 Internet 上发挥作用。建立合理的政务数据的组织方法和机构体系,实
现政务数据的合理规划和优化配置是电子政务系统建设的关键性环节。各地区政府部门的专
业数据库都是建立在国家四大基础数据库基础之上的。基于 Web 的电子政务数据库应用开发
过程通常采用应用原型化方法进行。
1.5 本 章 习 题
1.电子政务和电子政府的概念有什么联系?有什么区别?
2.电子政务对数据管理系统提出了哪些特别的要求?
3.国家基础数据库建设的牵头单位有哪些?为什么确定是这些部门?
4.分布式数据存储模型有哪些类型?有哪些优缺点?
5.你认为我国阻碍实现政府信息化的最大障碍是什么?
6.试分析网上某城市政务网站功能结构,并画出网站功能图。
7.采用了电子政务系统就是实现了电子政务吗?为什么?
8.举出几个你身边电子政务应用的例子。
1.6 本章参考文献
1.张维迎等·中国地级市电子政务研究报告·北京:经济科学出版社,2003.11
2.武汉市电子政务生产力促进中心等·城市电子政务软件平台技术与系统设计·湖北:
武汉大学出版社,2003.7
3.潘郁等·电子商务数据库技术(第二版)·北京:北京大学出版社,2004.5
4.钱毅·政务数据库系统·北京:中国人民大学出版社,2004.2
5.陈瑞莲等·珠江三角洲公共管理模式研究·北京:中国社会科学出版社,2004.5
6.朱荣辉·电子政务不是“面子工程”·http://www.e-works.net.cn/ewkArticles/Category-
16/Article3962.htm
7.(美)Gunnit S.Khurana 等著,Web 数据库的建立与管理·陈银山等译·北京:机械工
业出版社,1997.6
8.(美)Jesse Feiler 著,数据库驱动的 Web 站点设计·张玮等译·北京:机械工业出版
社,2001.4
9.张延松等·电子政务建设中的基础数据库建设规划研究·广东:厦门大学学报(自然

第 1 章 政务数据库技术 - 11 -
科学版),2004.8,43:293~299
10.国家信息安全工程技术研究中心·电子政务总体设计与技术实现·北京:电子工业
出版社,2003.7
11.王银杰等·电子政务数据交换平台的技术和架构·计算机应用,V2004.6,24
12.刘越男等·政府网站的构建与运作·北京:中国人民大学出版社,2004.2
13.Karen Layne,Jungwoo Lee·Developing fully functional E-government:A four stage
model·Government Information Quarterly,2001,18:122~136
14.Duncan Aldrich,John Carlo Bertot and Charles R. McClure·E-Government: initiatives,
developments, and issues·Government Information Quarterly,2002,19: 349~355
15.George Cairns·Exploring e-government futures through the application of scenario planning,
Technological Forecasting & Social Change,2002,5538:1~22
16.Paul Raj Devadoss·Structurational analysis of e-government initiatives: a case study of
SCO·Decision Support Systems ,2002,34:253~269

第 2 章 数据库系统概论
“没有卓越的数据管理,就没有成功高效的数据处理,更建立不起整个企业的计算机信
息系统”。企业信息化如此,政府信息化更是如此。电子政务的建设离不开数据管理。以数
据为中心的数据库系统,是当代数据管理的主要方式。“数据库管理是现代计算机系统提供
的最重要的功能,事实上,其重要性已经达到了这样的程度,即它已普遍成为购买计算机的
主要出发点”。从 20 世纪 60 年代中期开始萌芽到现在,数据库技术的重要性已愈来愈来为
人所熟知。数据库技术是计算机科学技术中发展最快的领域之一。数据库系统已在当代社会
生活中获得了广泛的应用。现在,不仅在大、中、小、微型机等各种机型都配有数据库系统,
而且各行各业的信息系统,乃至因特网上的信息系统也都离不开数据库的支持。数据库技术
渗透到工农业生产、商业、行政管理、科学研究、教育、工程技术和国防军事等各行各业,
而且围绕着数据库技术形成了一个巨大的软件产业,也就是数据库管理系统和各类工具软件
的开发和经营。
本章主要内容:
� 数据库技术发展
� 数据模型
� 数据库系统的结构
� 关系数据库管理系统实例
� 电子政务数据库技术新发展
2.1 数据库技术发展
随着社会的发展,人们需要掌握和处理的信息越来越多,然而要想充分地开发与利用这
些信息资源,就必须对大量信息进行识别、存储、处理与传递。尽管人脑在信息识别、信息
的分析与综合、推理及联想等方面具有很强的优势,但在记忆信息、快速处理信息等的能力
较弱。而由于以计算机为基础的数据库技术具有信息存储量大、处理和传输速度快、逻辑推
理严密、重复性强而不会疲劳、能够有效合理地存储各种信息并能够准确快速地提供有用信
息的特点,刚好弥补了人脑加工处理信息等方面能力的不足,于是很快成为信息处理强有力
的工具。
2.1.1 数据处理技术的演变
数据处理技术的发展,是与信息技术的整体发展水平同步的。软硬件技术和信息市场的
客观需求共同推动着数据库技术的发展。存储器类型的不断推陈出新,以及呈几何级数攀升

第 2 章 数据库系统概论 - 13 -
的 CPU 速度为数据库技术提供了良好的硬件基础,高级语言的出现带来了过程、控制、函数
等概念,大大提高了处理各种数据的能力,从物质技术方面极大地推动了数据库技术的研究
和发展;从客观需求来看,应用范围的不断扩大也提供了充足的动力。使得数据库技术从仅
用于科学计算,扩展到用于行政管理和技术控制,发展更加全面。
数据管理是数据库的核心任务,其内容包括对数据的分类、组织、编码、存储、检索和
维护。数据库技术随着计算机硬件和软件的发展而不断地发展。从数据管理技术的发展来看,
到目前为止,数据管理共经历了人工管理阶段、文件系统阶段和数据库系统阶段 3 个阶段。
(1)人工管理阶段
20 世纪 50 年代中期以前为人工管理阶段,这是数据管理的初级阶段。当时计算机刚刚
诞生不久,主要用于科学计算。
从硬件看,没有磁盘等直接存取的存储设备,只有磁带、纸带、卡片等;从软件看,没
有操作系统和管理数据的软件,只有简单的管理程序。数据处理方式是批处理。
这个时期数据管理的特点如下。
① 数据不保存。由于该时期的计算机主要用于科学计算,通常不需要长期保存数据,只
是在计算某一课题时将有关数据输入,用完后不保存原始数据,也不保存计算结果。
② 数据缺乏管理软件。没有专门对数据进行管理的软件系统,程序员不仅要规定数据的
逻辑结构,而且还要在程序中设计物理结构,包括存储结构、存取方法、输入输出方式等。
③ 数据冗余度高。数据与程序不具有独立性,一组数据对应于一个程序,数据是面向应
用的。即使两个程序用相同的数据,也必须各自定义、各自组织,数据无法共享、无法相互
利用和互相参照,从而导致程序和程序之间有大量重复的数据。
在这个时期,数据的管理基本上是手工的、分散的,计算机还没有在数据管理中发挥应
有的作用。所以,这种管理方式严重影响了计算机的使用效率。
(2)文件系统管理阶段
20 世纪 50 年代后期到 60 年代中期为文件系统阶段。这一阶段,计算机技术有了很大的
发展,出现了计算机的联机工作方式,计算机开始大量用于管理。在硬件方面,外存储器有
了磁盘、磁鼓等可以直接存储的设备。在软件方面,出现了操作系统以及包含于其中的文件
管理系统,专门对大量数据进行管理。不过文件系统也只是简单地存放数据,它们之间并没
有有机的联系。数据的存储依赖于应用程序的使用方法,不同的应用程序仍然很难共享同一
数据文件。另外,文件系统对数据存储没有一个相应的模型约束,所以数据冗余大。
文件系统阶段数据管理的特点如下。
① 数据冗余度大。文件系统中的文件都与某个应用程序相对应,数据仍是面向应用的,
当不同应用程序所需要的数据有部分相同也必须独立建立各自的文件,而不能共享相同的数
据。
② 数据不一致。由于同一信息在不同的应用范围内采集,有可能造成采集标准不一样,
在不同的应用程序中有不同的数据表示。
③ 程序和数据具有物理独立性,但不具有逻辑独立性。文件系统可以提供的存取方法是
程序与数据之间进行转换,而不需要程序员维护,使得程序和数据具有物理独立性。文件系
统中的文件是为某一个特定应用程序服务的,文件的逻辑结构相对于该应用程序是优化的。
但这样使得系统难以扩充,一旦数据的逻辑结构改变,则对应的应用程序必须修改。应用程

- 14 - 电子政务数据库基础
序的改变,也会影响到文件数据结构的改变。所以程序和数据之间缺乏逻辑独立性。
(3)数据库系统阶段
数据库系统阶段是从 20 世纪 60 年代后期开始的。由于计算机用于管理,从而使数据量
急剧增加,其中非数值数据占据的比例较大,且比数值数据复杂得多,不仅要知道各项数据
的本身内容,而且还需要知道它们之间的关系,这需要一个高度组织化的数据管理系统。另
外,随着计算机硬、软件技术的飞速发展,网络通信的出现使得各种用户共享一个数据集合
成为可能,在这种情况下,出现了数据库系统。在这一阶段中,数据库中的数据不再是面向
某个应用或某个程序,而是面向整个企业(组织)或整个应用的。
数据库系统解决了人工管理和文件系统的弊端,它把数据的定义和描述从应用程序中分
离出去,程序对数据的存取全部由数据库管理系统(DBMS)统一管理,从而保证了数据和
程序的逻辑独立性。这样,数据就可以供各种用户共享且具有最小冗余度,若建立了一个良
好的数据库管理系统,就可以为多种程序并发地使用数据库提供及时有效的处理,并保证数
据的安全和完整性。其特点如下。
① 使用复杂的数据模型来表示结构。数据库通过数据模型来描述数据本身的特征以及数
据之间的关系。其管理不仅要考虑在一个程序中数据的结构,还要考虑在整个工程中应用处
理的数据的结构。数据的结构化是数据库的重要特征之一,是其与文件系统的根本区别所在。
② 具有很高的数据独立性。用户可以使用简单的逻辑结构来操作数据而不需要考虑物理
结构,同时,物理结构的改变也不影响数据的逻辑结构和应用程序。
③ 数据共享度高、冗余度小。由于数据库是从整体上来描述数据的,数据不再面向某一
应用,所以大大减小了数据的冗余度,从而节省了存储空间、减少了存取时间、避免了数据
的不一致性。在具体使用时,可以抽取整体数据的子集用于不同的应用系统。当应用改变时,
只要重新选择子集或者稍加改变,数据即可有更多的用途。
2.1.2 数据库系统的发展过程
数据库系统的发展始终是以数据模型的发展为主线的,所以按照数据模型的发展情况,
数据库系统的发展又可划分为如下 3 个阶段。
(1)第一代数据库系统,即层次数据库系统和网状数据库系统。这一代数据库系统主要
支持层次和网状数据模型,其主要特点是支持三级抽象模式的体系结构;用存取路径(指针)
来表示数据之间的联系;数据定义语言(DDL)和数据操纵语言(DML)相对独立;数据库
语言采用过程性(导航式)语言。第一代数据库系统发展过程如下。
� 1964 年,美国通用电气公司的 Bachman 等人成功开发世界上第一个 DBMS��IDS(Integrated Data Store),奠定了网状数据库系统的基础。
� 1969 年,美国 IBA 公司成功地研制了世界上第一个商品化 DBMS 产品��IMS(Information Management System),这是一个层次数据库系统。
� 1969~1970 年,美国 CODASYL(Conference On Data System Language)协商会下
属的 DBTG(DataBase Task Group)对数据库方法进行了系统地研讨,提出了 DBTG报告,建立了以网状数据模型为基础的数据库系统概念。
(2)第二代数据库系统,即关系数据库系统(RDBMS)。这一代数据库系统主要支持

第 2 章 数据库系统概论 - 15 -
关系数据模型,这种模型有严格的理论基础,概念简单、清晰,易于用户理解和使用。因此,
关系模型一经提出,便迅速发展,成为实用性最强的产品。该系统的主要特点是:概念单一
化,数据及数据间的联系都用关系来表示;以关系代数为理论基础;数据独立性强;数据库
语言采用说明性语言,大大简化了用户的编程难度。第二代数据库系统的发展过程如下。
� 1970 年,美国 IBM 公司 San Jose 研究实验室的研究员 E.F.codd 提出了关系数据模型,
开创了关系数据库系统的研究,奠定了关系数据模型的理论基础。E.F.codd 因此在
1981 年获得了 ACM 图灵奖。
� 1974 年,美国 IBM 公司 San Jose 研究实验室研制成功 System R,并在 IBM System/370
计算机上运行,这是世界上最早的、功能强大的关系数据库系统。以后又陆续推出了
SQL/DS 和 DB2 等商用化产品。
� 1980 年以后,RDBMS 产品迅速推出,比如 Oracle、Informix、Sybase、dBASE、
FoxBASE、FoxPro 等。
� 1990 年以后,RDBMS 产品的版本不断更新,功能更强大,支持分布式数据库和客户
机/服务器数据库以及客户/浏览器/服务器数据库等,同时实现了开放式网络环境下异构
数据库的互联操作,以及在整个企业/行业范围内的 OLTP(在线事务处理)应用支持。
(3)第三代数据库系统,即新一代数据库系统��面向对象数据库系统。这一代数据库
系统是基于扩展的关系数据模型或面向对象数据模型的,是尚未完全成熟的一代数据库系统。
其主要特点是支持包括数据、对象和知识的管理;在保持和继承第二代数据库系统的技术基
础上引入新技术(比如面向对象技术);对其他系统开放,具有良好的可移植性、可连接性、
可扩充性和可互操作性。第三代数据库系统的代表性例子包括 Servio 公司的 Gemstone、
OWTOS 公司的 ONTOSTOS、Object Design 公司的 Objectstone 、Objectivity 公司的
Objectivity/DB、Versant Object Technology 公司的 Versant、Intellitic International(法国)的
Matisse、Itasca Systems 公司的 Itasca、O2 Technology(法国)的 O2 等,它们都支持严格面
向对象的数据模型。与此同时,面临新的应用领域的挑战,许多商品化的关系数据库系统也
对支持的数据模型进行了扩充,发展成了对象关系数据库系统(ORDBMS)。
2.2 数 据 模 型
政府部门的日常运作离不开各种各样的数据,随着电子政务的发展,政务数据库存储着
大量的、日益增多的、重要的政务数据,保证数据的长期有效性是对数据库技术的基本要求。
数据库相对稳定的数据模型从根本上保证了这一需求的实现。数据库的发展经历了几十年,
数据模型基本固定为网状、层次和关系模型,尤其是关系模型。
2.2.1 基本概念
1.数据模型的概念
数据模型是数据库系统的数学形式框架,是用来描述数据的一组概念和定义,包括如下

- 16 - 电子政务数据库基础
几个方面的内容。
(1)数据的静态特征。包括多数据结构和数据间联系的描述。
(2)数据的动态特征。它是一组定义在数据上的操作,包括操作的含义、操作符、运算
规则及其语言等。
(3)数据的完整性约束。这是一组规则,数据库中的数据必须满足这组规则。数据库系
统的数据模型有很多种,大体可分成两类。一类是面向值的数据模型,如目前用的最多的关
系数据模型。在关系模型中,数据库的数据被看做是若干关系,关系则被看做是简单的二维
表格。另一类是面向对象的数据模型,这是新一代的数据模型,比如语义数据模型和面向对
象数据模型。这一数据模型对现实环境的数据有很强的表现力,是适应计算机应用发展需要
的新模型。早先的层次模型和网状模型用有向图描述数据及其联系,可归入完善的面向对象
数据模型。
不同的数据模型适合不同的应用环境,所以在众多的数据模型中不存在所谓的最好的数
据模型。不同的数据模型在以下几个方面的特征不同,而这些不同决定了数据模型的适用范
围。
(1)面向对象和面向值:传统的关系模型是面向值的数据模型,允许用说明性数据语言。
面向对象的数据模型提供了对象标识,所以被称为面向对象的。
(2)冗余处理:所有的数据都以某种方式帮助用户避免多次重复存储同一数据。重复存
储造成了数据冗余,冗余不仅浪费空间,而且可能因为同一数据在一处修改而另一处不变造
成数据的不一致。面向对象的数据模型在数据冗余方面处理得更好。可以通过为一个对象建
立一份副本,在其他要用到该对象的地方通过对象标识或指针指向这个副本。
(3)对多对多联系的处理:在关系模型中这个问题留给了物理设计层解决,网状模型则
禁止多对多联系。
在实际应用中,为了更好地描述现实世界中的数据特征,常常针对不同的场合或不同的
目的,采用不同的方法描述数据特征,统称为数据模型。一般说来,有如下几种。
(1)概念数据模型(Conceptual Data Model),这是面向数据库用户的现实世界的数据模
型,与具体的 DBMS 无关。概念数据模型主要用来描述现实世界的概念化结构,它使数据库
设计的初始阶段摆脱计算机系统及 DBMS 的具体技术问题,集中精力分析数据、数据间联系
等。概念数据模型必须转换成逻辑数据模型才能在 DBMS 中实现。最常用的概念数据模型是
E-R 模型。它是将现实世界的信息结构转换成数据库的数据模型的桥梁。
(2)逻辑数据模型(Logical Data Model),这是用户从数据库所看到的数据模型,是具
体的 DBMS 所支持的数据模型。如网状数据模型、层次数据模型、关系数据模型和面向对象
数据模型等。逻辑数据模型既要面向用户,也要面向系统,一般由概念数据模型转换而来。
(3)物理数据模型(Physical Data Model)。这是描述数据在存储介质上的组织方式的数
据模型,它不仅与具体的 DBMS 有关,而且与操作系统和硬件有关。每一种逻辑数据模型在
实现时都有对应的物理数据模型,一般说来都由 DBMS 自动完成物理数据模型的实现工作,
设计者则只负责设计索引、聚集等特殊结构。
2.其他相关概念
数据库存储的是数据,这些数据反映了现实世界中有意义、有价值的信息,数据库不仅

第 2 章 数据库系统概论 - 17 -
反映数据本身的内容,而且也反映数据之间的联系。数据模型就是用来抽象表示、处理现实
世界的数据和信息的工具,它是数据库中用于提供信息表示和操作手段的形式框架,也是将
现实世界转换为数据世界的桥梁。有关数据模型的基本概念是数据库理论的基础。在介绍几
种数据模型之前,先介绍与其相关的一些概念。
从人们对现实生活中事物特性的认识到计算机数据库里的具体表示要经历 3 个领域,即
现实世界��概念世界��机器世界。有时也将概念世界称为信息世界;将机器世界称为存
储世界或数据世界。 (1)现实世界。现实世界是指存在于人脑之外的客观世界。现实世界是客观存在的。在
现实世界中存在着各种运动着的事物,一个客观存在且可以识别的事物称为个体。个体可以
是一个具体的事物,也可以是抽象的概念。每个个体都有自己的特征,这些特征是人们区分
个体的根据。一个个体具有多方面的特征,通常选择人们感兴趣的以及最能够表征该个体的
若干特征来描述该事物。以单位职工为例,通常选用姓名、年龄、性别、籍贯、部门以及职
务等来描述一个职工的特征。在现实世界里,个体及个体之间存在着联系,这种联系是客观
存在的。例如,职工和部门,职工在部门中就职。事物之间的联系也是多方面的,人们仅选
择那些感兴趣的联系。 (2)概念世界。概念世界又称信息世界,是现实世界在人们头脑中的反映,是对客观事
物及其联系的一种抽象描述。它不是现实世界的简单复制,而要经过选择、命名、分类等抽
象过程产生概念模型。概念模型是现实世界到机器世界必然经过的中间层次。建立概念模型
涉及到下面几个术语。 � 实体(Entity)。客观存在并可相互区别的事物称为实体。实体可以是实际事物,也
可以是抽象事件,还可以是事物之间的联系。比如,一个职工、一个部门属于实际事
物;一次订货、借阅若干本图书、一场考试则是比较抽象的事件。具有相同类型和相
同特征的实体集合称为实体集。属性的集合表征一种实体的类型,称为实体型,如可
以用工号、姓名、年龄、性别、部门等属性来表征职工这一实体型。实体型“职工”
表示全体职工的整体,并不具体指某个职工。以后在不致引起混淆的情况下,我们说
实体即是指实体型而言。 � 属性(Attribute)。属性是用来描述实体的某一方面特性的。例如,职工实体用若干
属性(职工号、姓名、性别、出生日期、职务、部门)来描述。属性的具体取值称为
属性值,用以描述一个具体实体。如属性组合(0986、张洋、男、01/06/53、处长、
审计部门),在职工花名册中就表征了一个具体的人。 � 实体标识符。如果某个属性或属性组合的值能够惟一地标识出实体集中的每一个实
体,则可以选择该属性或属性组合作为实体标识符。上例中的“职工号”可以作为实
体标识符,由于可能有重名者存在,“姓名”就不宜作实体标识符。 � 联系(Relationship)。现实世界中的事物是存在普遍联系的。这种联系反映到信息世
界里可以分成两类。一类是实体内部各属性之间的联系;另一类是实体之间的联系。
实体之间的联系用 E-R 模型来反映,对于实体内部各个属性之间的联系通常在数据
库的规范化过程进行处理。 (3)机器世界。信息经过加工编码进入机器世界,机器世界的处理对象是数据。机器世
界常用到以下几个概念。 � 字段(Field)。相应于属性的数据称为字段,或者叫数据项,又叫数据元素或初等项。

- 18 - 电子政务数据库基础
� 记录(Record)。相应于每一实体的数据叫记录。
� 文件。相应于实体集的叫文件,它是同类记录的集合。
� 记录型。相应于实体型的为记录型。
� 关键字。相应于实体标识符的为关键字,关键字又称为码。
上述概念对应关系如下:
信 息 世界 机器世界
实 体 记 录
属 性 字 段
实 体 集 文 件
实 体 型 记 录 型
实体标识符 关 键 字
实体、属性、记录、字段均有型与值之分。例如,职工是一个实体型,林玫、王芮则是
实体值。属性中的性别、年龄是属性型,而男或女、23 或 30 则分别为性别、年龄的属性值。
2.2.2 概念数据模型
数据库设计工作比较复杂,它将现实世界的数据组织成符合具体数据库管理系统所采取
的数据模型,一般情况下不可能一次到位。在实际应用中,很少直接采用传统数据模型进行
数据库设计。P.P.S.Chen 于 1976 年提出了实体—联系方法。这种方法简单、实用,所以得
到了非常普遍的应用,也是目前描述概念模型最常用的方法。它所使用的工具即为 E-R 图。
E-R 所描述的现实世界的信息结构称为组织模式或企业模式,同时把这种描述结果称为 E-R
模型。E-R 模型可以进一步转换为任何一种 DBMS 所支持的数据模型。因此,提出 E-R 模
型的目的如下。
(1)企图建立一个统一的数据模型以概括 3 种传统数据模型(层次模型、网状模型和关
系模型)。
(2)作为 3 种传统模型之间互相转换的中间模型。
(3)作为超脱 DBMS 的一种概念数据模型,以比较自然的方式模拟现实世界。
E-R 模型不同于传统数据模型,它不是面向实现的,而是面向现实世界的。设计 E-R
模型的出发点是有效和自然地模拟现实世界,而不是首先考虑它在计算机中如何实现。
(1)实体联系类型。实体间的联系类型是指一个实体型所表示集合中的每一个实体与另
一个实体型中多少个实体存在联系,并非指一个矩形框通过菱形框与另外几个矩形框画连线。
实体间的联系虽然复杂,但都可以分解为少数几个实体间的联系,最基本的是两个实体间的
联系。联系抽象化后可归结为以下 3 种类型。
① 一对一联系(1:1)。设 A、B 为两个实体集。若 A 中的每个实体至多和 B 中的一个
实体有联系,反过来 B 中的每个实体至多和 A 中的一个实体有联系,称 A 和 B 是 1:1 联系。
例如,一个公司只有一个总经理,同时一个总经理不能在其他公司兼任。注意“至多”一词
的含义,1:1 联系不一定都是一一对应的关系。图 2.1 所示为一对一的联系。

第 2 章 数据库系统概论 - 19 -
② 一对多联系(1:n)。如果 A 中的每个实体可以和 B 中的几个实体有联系,而 B 中
的每个实体至多和 A 中的一个实体有联系,那么 A 对 B 属于 1:n 联系。这类联系比较普遍,
例如,部门与职工是一对多联系,因为一个部门有多名职工,而一名职工只在一个部门就职。
又如,一个学生只能属于一个班级,而一个班级有很多个学生。图 2.2 所示为一对多的联系。
一对一的联系可以看做是一对多联系的一个特殊情况,即 n=1 时的特例。
�③ 多对多联系(m:n)。若 A 中的每个实体可与 B 中的多个实体有联系,反过来 B 中
的每个实体也可以与 A 中的多个实体有联系,则称 A 对 B 或 B 对 A 是多对多联系(m:n),
如图 2.3 所示。例如,研究人员和科研课题之间是 m:n 联系:一个人可以参加多个课题,一
个课题可以由多个人参加。
(2)E-R 图中的联系类型。E-R 图中的联系类型有:递归联系、二元联系和多元联系。
① 递归联系,即一个实体集合与其本身的联系。如机关职工实体集,某些职工处在领导
岗位上,他们与其他职工是管理与被管理的关系。用 E-R 图表示如图 2.4 所示。
② 二元联系,两个实体集合之间的联系。图 2.1、图 2.2、图 2.3 中的联系都是二元联系。
③ 多元联系,是指三个以上实体集之间的联系如图 2.5 所示。
研究人员
科研课题
参加
实体集 A
m
n
图 2.3 多对多联系
联系
实体集 B
m
n
图 2.2 一对多的联系
1
联系
实体集 A
n
部门
职工 实体集 B
属于
n
1
图 2.1 一对一的联系
联系
实体集 A
实体集 B
1
部门
领导
1 1
1
总经理

- 20 - 电子政务数据库基础
图 2.4 递归关系 图 2.5 三个实体间的多对多联系
(3)E-R 图的基本画法。E-R 图有如下三要素。
① 实体(型)��用矩形框表示,框内标注实体名称。 ② 属性��用椭圆形表示,并用连线与实体连接起来。如果属性较多,为使图形更加
简明,有时也将实体与其相应的属性另外用列表表示。 ③ 实体之间的联系��用菱形框表示,框内标注联系名称,并用连线将菱形框分别与
有关实体相连,且在连线上注明联系类型。 E-R 方法为抽象地描述现实世界提供了一种有力工具,它所表示的概念模型是各种数据
模型的共同基础,进行数据库设计时必然要用到此方法。做实体——联系图的具体步骤如下: � 确定所有的实体集合。 � 确定实体集之间的联系。 � 选择实体集应包含的属性。 � 确定实体集的关键字,用下划线在属性上表明关键字的属性组合。 � 确定联系的类型,在用线将表示联系的菱形框联系到实体集时,在线旁注明是 1 或 n
(多)来表示联系的类型。 当 E-R 图比较复杂、实体与联系都较多时,为了简洁也可不在同一张图上画出属性,只
在一张图上绘出实体与联系的图形,另外再分别给出每个实体或联系的属性。怎样确定实体、
联系和属性,没有一个固定的方法,它取决于数据库设计人员对于所分析的应用模式中的对
象重要程度的理解。因此,一个数据库的 E-R 图不是惟一的,强调不同的侧面,按照不同的
理解,可以得到不同的 E-R 图。 (4)E-R 图设计讨论。 ① 真实性。E-R 图是用于描述现实世界的概念模型,因此必须真实反映现实世界,不能
无中生有。对于复杂的实体和联系,必须先弄清它们的“来龙去脉”,对于它们的属性也要
逐一考查,看是否确有必要考虑这方面的特征,以免给以后的数据库设计带来隐患。 ② 简单性原则。现实世界是很复杂的。事物之间都是普遍联系的。但是在绘制 E-R 模
型时,需要对客观现实进行简化,只对与系统设计目的相关的部分进行建模。 ③ 实体与属性确定规则。由于实体属性之间在形式上并没有明显的界限,所以在确定
实体或属性时,通常遵循着以下原则。 � 作为属性,不能再具有需要描述的信息,属性必须是不可再分的数据项,不能包含
其他属性。
供应商
材料项目
供货
m
n p
职工
管理

第 2 章 数据库系统概论 - 21 -
� 属性不能与其他实体具有联系,在 E-R 图中,只有实体与实体之间才能有联系。
2.2.3 逻辑数据模型的类型
在 20 世纪 60 年代末 70 年代初相继出现了层次模型、网状模型、关系数据模型,它们的
特点是能有效地存储和处理数据,但表达能力有限,不能描述和模拟现实世界中的复杂应用,
基本上是面向计算机的。所以,对于决策支持系统和计算机辅助制造这样的复杂应用,其描
述和建模能力显然不足。随着面向对象技术和人工智能的发展,在传统的数据模型基础上产
生了一批面向用户的语义模型,如前面所述的 E-R 模型和函数数据模型等。尽管如此,三大
传统模型,特别是关系数据模型,仍是当今使用的主流模型。
(1)层次模型
在现实世界中,许多事物之间的联系可用一种层次结构表示出来。如一个学校由若干学
院组成,一个学院由若干系组成,一个系由若干专业组成等。层次数据模型就是根据现实世
界中存在的这些层次结构特点而提出的一种数据模型。它是三大传统数据模型中出现最早的
一个。基于层次模型的数据库管理系统 IMS 是 IBM 公司于 1968 年推出的世界上第一个数据
库管理系统。
层次模型(Hierarchical Model)是用树型结构来表示实体之间联系的模型。它可以看做
是一棵以记录型为结点的有向树,它把整个数据库的结构表示成一个有序树的集合,而这些
有序树的每一个结点是一个有若干数据项组成的逻辑记录型。
图 2.6 给出的是一个层次数据模型的例子。它表示的是一个学校教务管理系统的信息。
学校设有若干学院,每个学院设有若干系,每个系设有若干专业并有若干教师,每个专业和
教师只属于一个系;另外,每个专业开设若干课程并有若干个学生,而一个学生只能属于某
一个专业,一门课程也只能由一个专业开设。
图 2.6 教务管理系统的层次模型
专业 教师
学生
学院
系
学号 姓名 性别 年龄 课号 课程名 学时
学院代号 学院名 负责人
教师编号 姓名 职称
系名系号 负责人
专业代号 专业名

- 22 - 电子政务数据库基础
由图 2.6 所示,该层次模型有 6 个记录类型:学院、系、专业、教师、学生和课程。学
院称为根记录类型,它是系记录类型的父记录类型,而系则是学院记录类型的子记录类型。
在层次模型中只有一个结点无父结点,该结点称为根结点(学院记录类型)。其他结点是依
据根结点而存在的,它们有且仅有一个父结点。同一个父结点下的子结点称为兄弟结点,无
子结点的结点则称为叶结点。在层次模型中父结点与子结点的联系都是一对多的联系,且总
是从父结点指向子结点。所以记录之间的联系可以不用命名,只要指出父结点,就可以找到
其子节点。在层次模型中,从根结点开始,按照父—子联系,依次连接的记录序称为层次路
径。在层次模型中,数据是按层次路径存取的。
层次模型只能表示一对多的联系,而现实世界中事物
之间的联系往往是很复杂的,既有一对多的联系,也有多
对多的联系。为了反映多对多的联系,层次模型引入一种
辅助数据结构��虚拟记录类型和逻辑指针,将其转换成
一对多联系。如学校教务系统中,如果要反映学生选修课
程的情况,因为学生和课程之间为多对多的联系,所以要
引进一个虚拟记录型“选修”和逻辑指针,将其转换成一
对多联系。如图 2.7 所示。层次模型是一种简单的模型,
无法描述复杂的联系,表达能力弱,所以适用范围受限。 (2)网状模型 美国负责开发 COBOL 语言的委员会 CODASYL 的一个小组 DBTG,在其发表的一个报
告中提出了网状模型。网状模型中的每一个结点代表一个记录类型,联系用链接指针来实现。
网状模型突破了层次模型的两点限制,即允许结点有多于一个的父结点,可以有一个以上的
结点没有父结点。在网状模型中子女到双亲的联系不是惟一的,即在网状模型中可以很容易
实现多对多的联系,可以描述更复杂的现实世界。在网状模型中给每一对父结点与子结点之
间的联系都要指定名字,这种联系称为系。系中的父结点称为首记录型或主记录型,子记录
型称为属记录型。如图 2.8 中有 4 个系,分别为学生—成绩系,课程—成绩系,专业—学生
系,专业—课程系。
图 2.8 学生选课网状模型
专业(m)
课程号 课程名 学生
(s)
专业-学生系(m-s)
专业代码 专业名称
课程(c)
课程-成绩系(c-sc) 学生-成绩系(s-sc)
成绩(sc)
学号 姓名 年龄 性别
学号 课程号 成绩
学生 课程
选修 选修
图 2.7 多对多层次表示法

第 2 章 数据库系统概论 - 23 -
网状模型的主要缺点是数据结构本身及其相应的数据操作语言都极为复杂。一般说来,
结构越复杂,其功能越强,所要处理的操作也越多,因此相应的数据操作语言也就越复杂。
而且由于其结构复杂,给数据库设计带来了困难。
(3)关系模型
基于层次模型和网状模型的数据库系统开发出来以后,在继续开发新型数据库系统的工
作中,研究人员发现层次模型和网状模型缺乏坚实的理论基础,难以开展深入的理论研究。
于是人们开始寻求具有严格的理论基础的数据模型。在这种背景下于 1970 年 E.F.codd 提出
了关系模型。关系模型是目前数据库系统普遍采用的数据模型,也是应用最广的数据模型。
自 1980 年以来,计算机厂商推出的数据库管理系统的产品几乎都是支持关系模型的。关系模
型流行的主要原因在于关系模型对数据及数据联系的表示非常简单,无论是数据还是数据间
的联系都用关系来表示;关系模型支持高度非过程化的说明型语言表示数据的操作;同时,
关系数据模型具有严格的理论基础��关系代数。 关系模型是通过表格数据,而不是通过指针连接来表示和实现两个实体间的联系。或者
可以通俗地说,关系就是二维表格,表格中的每一行称做一个元组,它相当于一个记录值;
每一列是一个属性值,列可以命名,称为属性名,此处的属性与前面所讲的实体属性相同,
属性值相当于记录中的数据项或字段值。关系是元组的集合,如果表格有 n 列,则称该关系
为 n 元关系。关系具有如下属性。 ① 表格中的每一列都是不可再分的基本属性。 ② 各列的名字不同,列的顺序不重要。 ③ 行的次序无关紧要。 ④ 关系中不允许有完全相同的两行存在。 表 2-1 就是一个关系模型的例子。
表 2-1 员工信息表
员工编码 姓 名 部 门 性 别 职 务
70002 文韬 办公室 男 科员
70003 章文 人事科 男 科长
70004 陆晓风 财务科 女 科员
70005 王莉莉 后勤处 女 处长
关系模型与层次模型、网状模型相比,关系模型可以看做是数据库理论的起点,它提供
了理解和比较其他两种方法的极好基础和评价任何现有系统的方便的标准或尺度。即使关系
模型没有任何别的优点,仅仅理论上的正确性,也使之成为数学上的理想工具。 通常,将关系名及其属性名集合称为关系模式,具体的关系是实例。如上述的员工信息
表的关系模式。员工信息表(员工编码、姓名、部门、性别、职务),其中“员工信息表”为
关系名。这个关系描述了某单位员工的数据结构。 在支持关系模型的数据库中,数据被看做是一个个的关系,描述数据库全部关系的一组
关系模式称为关系数据库的数据库模式。任何时刻数据库的所有具体的关系组成关系数据库
的一个实例。

- 24 - 电子政务数据库基础
(4)三种数据模型的比较
前面讨论的层次模型、网状模型和关系模型由于它们结构上的不同,都有各自的特点。
为了比较它们,首先要给出比较的标准,这样才能看出一个模型的好坏。对于数据模型,一
般人们主要关心这样两个方面。
① 使用容易程度。数据库系统的用户是多种多样的。因此,为用户提供一个良好接口
的数据库系统将是十分受欢迎并具有生命力的。所以在选择数据模型时,需要选择一个用户
使用方面(即能使程序设计和表达询问很容易)的模型。
② 实现效率。这方面要考虑系统的实现难易和系统的效率如何。要求一个数据模型允
许 DBMS 方便地把概念模式和概念到物理的映像转换成一种既能节省空间又能快速响应询
问的实现。
就使用方便来说,关系模型是最佳的。它对用户的要求很低。它有功能丰富的、容许表
达对关系数据库进行各种询问的高级语言,这些语言对于那些不熟悉程序设计的人来说,是
十分合适的。相对而言,对于层次模型和网状模型这样的格式化数据模型,要求用户既要了
解记录类型存取路径,又要了解它们之间的相互关系,这些都增加了用户的负担。
从实现效率来看,层次模型和网状模型要优于关系模型。格式化数据模型的存取路径事
先都是规定好的,链技术可以大显身手。这样存取的效率就比较高,而且实现起来相对也容
易些。
从存储空间上说,格式化模型较关系模型更能合理利用空间。在关系模型中是靠冗余来
实现连接的。
以前,商品化的数据库系统几乎全都是基于层次和网状模型。因为这样的数据库系统着
眼于大型数据库的维护,而这些数据模型又很容易支持它们对高效率实现的要求。但是,现
在关系模型已经被人们重视了。一方面是因为适用于设计大型数据库的概念,也适用于中小
型数据库,而小型数据库比大型的要多得多。随着小型数据库的应用,关系模型固有的容易
使用的特点越来越突出。另一方面,关系模型那些表面上的低效性,许多是能够消除的。如
可以通过优化技术来提高效率。此外,用层次和网状方法设计的数据库系统,是通过指针链
来查找数据,而用关系方法设计的数据库系统,则是通过查表来查找数据。改进指针链的查
找收效甚微,而加快查表速度则大有潜力可挖。所有这些都促使人们采用关系模型。
人们将层次模型、网状模型和关系模型统称为传统数据模型。由于历史和技术条件的限
制,传统数据模型存在如下弱点。
(1)以记录为基础,不能很好地面向用户和应用。传统数据模型的基本结构是记录,而
人们对现实世界的认识往往通过实体,实体不一定与记录相对应。一个记录中可能包含多个
实体,同样一个实体也可能分在多个记录中加以描述。有些实体也可能仅仅作为某个记录中
的属性出现,无记录。记录的划分往往从实现考虑,而不一定反映人们对现实世界的认识。
另外,记录中的属性以及每个属性的域都是事先定义好了的,无法灵活描述纷繁的现实世界。
(2)不能以自然的方式表示实体间的联系。实体的描述是数据模型的一个方面,实体间
联系也是数据模型的一个重要方面。层次和网状数据模型虽然提供了描述联系的手段,但这
些描述联系的方式不是实体间联系的自然表现,而是联系在数据库中的物理实现。把本来应
该对用户隐蔽的物理实现的细节当做数据模型的组成部分呈现在用户面前,这不但不便于用
户的理解和使用,而且也有损于数据的物理独立性。尽管关系数据模型避免了这个缺点,实

第 2 章 数据库系统概论 - 25 -
体间的联系或通过一个表示联系的关系来表示、或通过公共属性来体现,但是关系模型表示
联系的方式不是显式的,用户很难从数据模式看出实体间的全面联系,现实世界中的实体联
系被湮没在关系和属性之中。所以三种传统数据模型都不能自然表示实体间的联系。 (3)数据类型太少,难以满足应用需要。传统数据模型原来都是面向事物处理的。它们
一般只提供最常用的一些简单的数据类型,如整数、实数、字符串等。随着计算机应用的发
展,不但要求数据库系统提供更丰富的数据类型和允许用户定义新的数据类型,还希望属性
值不直接给出,而由规则或过程导出。随着时态和空间数据库的发展,要求数据附有时间和
空间属性,这些都是传统的数据模型不能直接支持的。 由于传统数据模型存在上述的不足,从 20 世纪 70 年代后期开始,陆续出现了各种非传
统数据模型,这些数据模型出现在关系数据模型之后,因此又称为后关系数据模型。如前面
介绍的 E-R 模型以及面向对象的数据模型。
2.3 数据库系统的结构
2.3.1 数据库系统的组成
数据库系统是一个复杂的系统,因为数据库系统不仅是指数据库和数据库管理系统本
身,而且是指计算机系统引进数据库技术后的整个系统,是数据、硬件、软件和相关人员的
组合体。它由 5 个部分组成:硬件资源、软件资源、数据库结构、数据库管理员和用户。
(1)硬件资源。数据库系统的硬件资源包括 CPU、内存、磁盘、磁带及其他外部设备等。
(2)软件资源。数据库系统软件如下。
① 操作系统(OS),如 DOS 系统、UNIX 系统、Windows 系统及 Linix 系统等。
② 数据库管理系统(DBMS),如 FoxPro、Oracle、Ingres、Sybase 等。
③ 高级语言编译系统,如 Fortran、C++、VB 等。
核心为 DBMS。
(3)数据库体系结构。实际的数据库系统软件产品多种多样,它们支持不同的数据模型,
使用不同的数据库语言,建立在不同的操作系统之上,数据的存储结构也各不相同,但是大
多数数据库系统在总的体系结构上都具有相同的三级模式结构。数据库系统的三级模式结构
由用户级数据库、概念级数据库、物理级数据库组成,如图 2.9 所示。
用户级数据库是用户看到和使用的数据库,所以也称为用户视图,又称为子模式、外模
式、用户模式等。对应于外模式,它是单个用户看到并获准使用的那部分数据的逻辑结构(称
为局部逻辑结构),用户根据系统给定的子模式,用查询语言或应用程序去操作数据库中的
数据。
概念级数据库是 DBA(数据库管理员)看到的数据库,因此也称为 DBA 视图,又称为
模式。它是用于把用户视图有机地结合成一个逻辑整体,描述的是数据的全局逻辑结构,不
涉及数据的物理存储细节和硬件环境,也与具体的应用程序及使用的高级程序语言无关。

- 26 - 电子政务数据库基础
�物理级数据库又称为存储模式、内模式,是数据在数据库系统内部的表示,即对数据的
物理结构和方式的描述。内模式是全体数据库数据的内部表示或低层描述,用来定义数据的
存储方式和物理结构。从计算机的角度看,它们是指令操作处理的位串、字符和字;从系统
程序员的角度看,这些数据是它用一定的文件组织方法组织起来的一个个物理文件(或存储
文件),系统程序员编制专门的访问程序,实现对文件中数据的访问,所以物理级数据库也
称为系统程序员视图。对一个数据库系统来说,实际上存在的只是物理级数据库,它是数据
访问的基础。概念级数据库只不过是物理级数据库的一种抽象(逻辑)描述,用户级数据库
是数据库用户看到的数据视图,是概念级数据库的子集。用户根据子模式进行操作,数据库
管理系统通过子模式到模式的映射将操作与概念级连续起来,又通过模式到存储模式的映射
与物理级联系起来。这样,用户可以在较高的抽象级别上处理数据,而把数据组织的物理细
节留给系统。
(4)DBA。为了保证数据库能够高效正常地运行,一般大型数据库都设专门人员负责数
据库系统的管理和维护工作。这种专门人员称为 DBA。他们是一些懂得和掌握数据库全局并
设计和管理数据库的骨干人员。其主要职责如下。
① 负责数据库核心及其开发工具的安装及升级。
② 为数据库系统分配存储空间并规划未来的存储需求。
③ 协助开发者建立基本的对象(表、视图、索引)。
④ 负责注册用户并维护系统的安全性。
⑤ 负责数据库系统的备份和恢复。
(5)用户。数据库系统的用户分为两类:一类是最终用户,这类用户无须熟悉程序语言
和数据处理技术,他们通过终端的人机对话,主要对数据库进行联机查询或通过数据库应用
系统提供的界面来使用数据库,这些界面包括菜单、表格、图形和报表;另一类用户是专业
用户,即应用程序员,这类用户应熟悉 DBMS 接口语言及 DBMS 提供的数据操纵语言,他
们负责设计应用系统的程序模块,对数据库进行操作。
用户组 1 用户组 n 用户组 2
视图 1 视图 2 视图 3
概念数据库
物理数据库
┅
┅
图 2.9 数据库系统的三级结构模式

第 2 章 数据库系统概论 - 27 -
2.3.2 DBMS
DBMS 是对数据库进行定义、管理、维护和检索的一个软件系统。它总是基于某种数据
模型的,因此,可以看成是某种数据模型在计算机系统上的具体实现。
用户使用的各种数据库命令以及应用程序的执行,都要通过数据库管理系统。另外,数
据库管理系统还承担着数据库的维护工作,必须按照数据库管理员所规定的要求,保证数据
库的安全性和完整性。DBMS 的功能如下。
(1)数据库的定义。DBMS 总是提供数据定义语言 DDL 来描述模式、子模式和存储模
式及其模式之间的映射,描述的内容包括数据的结构、数据的完整性约束条件和访问控制条
件等,并负责将这些模式转换成目标形式,存在系统的数据字典中,供以后操作或控制数据
时查用。
(2)数据库的操作及查询优化。DBMS 通过提供数据操作语言实现对数据库的操作,基
本操作包括检索、插入、删除和修改。用户只需根据子模式给出操作要求,而其处理过程的
确定和优化则由 DBMS 完成,并且查询处理和优化机制的好坏直接反映 DBMS 的性能。
(3)数据库的控制运行。DBMS 提供并发访问控制机制和数据完整性约束机制,从而避
免多个读写操作并发执行可能引起的冲突、数据失密或安全性、完整性被破坏等一系列问题。
(4)数据库的恢复和保护。DBMS 一般都要保存工作日志、运行记录等若干恢复用数据,
一旦出现故障,使用这些历史和维护信息可将数据库恢复到一致状态。此外,当数据库性能
下降,或系统软硬件设备变化时也能重新组织或更新数据库。
(5)数据库的数据管理。数据库中物理存在的数据包括两部分:一部分是元数据,即描
述数据的数据,主要是上述的 3 种模式,它们构成数据字典的主体,数据字典由 DBMS 管理
和使用;另一部分是原始数据,它们构成物理存在的数据库,DBMS 一般提供多种文件组织
方法,供数据库设计人员使用。数据一旦按某种组织方法装入数据库,其后对它的检索和更
新都由 DBMS 的专门程序完成。
2.4 关系数据库管理系统实例
20 世纪 70 年代是关系数据库理论研究和原型开发的时代,关系模型以其突出的优点迅
速成为数据库系统的主流。据初步统计,在 20 世纪 80 年代以后诞生的 DBMS 产品中,大约
有 90%都是关系数据库管理系统,其中有许多性能优良的数据库产品,如小型数据库 FoxPro、
Access、Paradox,大型数据库 DB2、Oracle、Sybase、Informix、Ingres 等。同时,RDBMS
的功能和利用范围也在不断扩展,从单机环境到网络应用,从集中式管理到分布式系统,从
支持信息管理到联机事务处理,再发展到联机分析处理,关系数据库产品在信息系统中的作
用越来越大。本小节中简单介绍 Access 和 Oracle,在后面的章节中将详细讨论 SQL Server
的特点和使用。

- 28 - 电子政务数据库基础
2.4.1 Access
这里介绍 Access 2000 版本。它是微软公司 Office 2000 系列软件之一,是 Windows 环境
下非常流行的桌面型数据库管理系统。一般用户使用 Access 可以不必编写任何代码,只需要
通过直观的可视化操作就可以完成大部分数据库管理任务,因而受到普通用户的欢迎。
Access2000 采用面向对象的设计方法,是采用事件驱动机制进行管理的 RDBMS。它可以通
过 ODBC(开放数据库互联)与其他数据库相连,实现数据交换与共享;也能非常方便地与
Word、Excel 等办公软件进行数据交换;可以使用 OLE(对象链接和嵌入)技术在数据库中
嵌入和链接声音、图像等多媒体数据。同时,高级用户还可以使用 Access 内置的各种函数进
行定制开发。Access 的特点如下。
(1)对资源要求不高,适应性强。Access 2000 只需要下列条件就可安装运行:奔腾 75MH
-z 以上的 PC、Windows 95/98 操作系统、32MB 内存、100MB 的磁盘空间、VGA 适配器等
设备。
(2)数据共享性好。Access 2000 不仅可以与 Office 软件中的其他应用程序交换数据,而
且能与 Xbase、FoxPro、Lotus 等和其他配置 ODBC 的数据库系统交换数据,实现更大范围
的资源共享。
(3)可方便地与 Internet 连接,利用因特网与任一节点交流信息。Access 能将表、查询、
窗体和报表导出为 HTML 格式,又能直接访问 Internet 和 Intranet,显示 Web 页面,实现超
级链接。
(4)Access 的数据类型有 Binary、Bit、Byte、Counter、Currency、Datetime、Single、
Double、Short、Long、Text、Longtext、Longbinary 等 13 种。其中,Longtext 可以链接 1.2GB
的数据;Longbinary 也能链接多媒体对象。
在 Access 2000 系统中,数据库拥有如下多种基本对象。
(1)表。用于存储基本信息。它是特定实体的数据集合,例如员工、部门、工资表等。
每一种实体使用不同的表,表以行列二维形式组织数据,具有“数据表”和“设计”两种视
图。在设计视图中,可以对表进行创建、结构修改等操作,包括字段定义、关键字设置、字
段有效性约束、索引建立等功能。在数据表视图中,可以对表中的数据进行增、删、改、查
等操作,并能进行数据排序和筛选。
(2)窗体。窗体是 Access 2000 系统最灵活的部分,是显示人机交互的界面。利用窗体
可以使用户非常轻松地操作数据库。窗体既可以显示表中的数据,也能简化用户向表中输入
数据的过程。窗体依据其功能不同,可以分为数据输入窗体、开关面板和自定义对话窗体等。
数据输入窗体用于向表中输入数据;开关面板窗体用于打开其他窗体或报表,实现控制程序
的流转;自定义对话窗体用于接收用户输入,根据用户的输入信息执行相应的操作。
(3)Access。是用查询作为信息检索的手段。查询类似于视图的概念。使用查询还可以
实现数据的插入、删除和修改。可以将查询作为窗体和报表的数据源。查询具有 SQL 视图、
数据表视图和设计视图,可以在 SQL 视图中直接书写 SQL 语句获得查询;也可以通过设计
视图直接选择查询的表、列、选择条件、排序方式等,并通过数据表视图观察查询结果。
(4)报表。是 Access 的信息输出载体。报表的数据来源是表或者查询,它可以将数据进
行分组、排序、计算的结果以更人性化的方式输出,还可以将数据以图表的方式输出。报表

第 2 章 数据库系统概论 - 29 -
文件保留报表设计的内容,与查询一样,在输出报表时才从相关数据对象中获得数据。
(5)宏。在 Access 中,宏能够控制程序的执行流程,包括执行查询、打开表、修改表、
查看和打印报表等操作。宏是一个或多个操作的集合,它在宏设计窗口中创建。
(6)模块。是由多个 VBA(Visual Dasic for Application)过程组成的数据库对象。它包
括类模块和标准模块两个基本类型。窗体和报表模块都是类模块。标注模块包含通用过程,
通用过程不与任何对象相关联,可以直接在数据库的任何位置执行。
(7)数据访问页。使用数据访问页,用 Access 开发的系统可以非常方便地通过网络发布。
所以,数据访问页实际就是 Web 页,利用它可以在网络上实现数据的输入、编辑和查看。
2.4.2 Oracle
Oracle 公司成立于 1977 年,因为完成了美国政府代号为“Oracle”的招标项目而得名,
是著名的专门从事研究、生产 RDBMS 的专业厂家。其拳头产品 Oracle 是著名的大型数据库
管理系统之一。
Oracle 较早采用 SQL 语言作为数据库语言。自创建以来,Oracle 不断推陈出新。1983
年,Oracle 的第三版内核用标准 C 语言编写,使其独立于硬件和操作系统,可以在几十种操
作系统平台上运行。Oracle 的第三版是一个开放性的系统,从而占据了较多的市场份额。1984
年,Oracle 的第四版率先推出与数据库结合的第四代语言开发系列工具。1986 年的 Oracle 5.1
是一个具有分布处理能力的关系数据库系统。1988 年 Oracle V6 再次修改,加强了事务处理
功能,对用户配置的多个联机事务的处理能力大大提高。1992 年的第七版实现了关系型数据
库和分布式数据库的所有主要特征功能,几乎可以在所有硬件平台上运行。在 V7.3 版本中,
又增加了多媒体的应用,支持数据仓库和联机事务处理(OLTP),进一步提高了系统性能和
应用程序开发效率。1997 年的 Oracle 第八版则主要增强了对象功能。成为对象——关系数据
库系统。目前,Oracle 产品覆盖了大、中、小型机几十种计算机系统,成为世界上使用非常
广泛的、著名的关系数据库管理系统。
1.Oracle 系统的特点
(1)兼容性。Oracle 采用标准的数据库语言 SQL,它与 IBM 的 SQL/DS、DB2、Ingres
等完全兼容,可以使用现有的 IBM 的数据库系统的数据和软件资源,用户开发的应用软件可
以在其他基于 SQL 的数据库上运行。
(2)可移植性。Oracle 可以在 70 多类计算机系统上运行,支持 20 多种操作系统环境,
具有很宽的硬件和操作系统适应性,不仅能在大、中、小型计算机上运行,而且可以通过裁
剪技术,将它移植到多种微型机上,从而得到了广泛的应用。
(3)可联结性。由于 Oracle 在各类机型上使用相同的软件,所以联网和分布式处理功能
更容易实现。它支持 TCP/IP、DECnet、X.25 等多种标准网络协议,提供与非 Oracle 的 DBMS
接口;它能够使在某些 Oracle 工具上建立的 Oracle 应用连接到非 Oracle 的 DBMS 上,具有
存储地址的独立性,从而得到了广泛的应用。
(4)高生产率。Oracle 为程序员提供两类编程接口:预编译程序接口 Pro* Oracle 和子程
序调用接口 Pro*SQL。它为应用开发人员提供多种工具,包括应用生成(Oracle Forms)、菜

- 30 - 电子政务数据库基础
单管理(Oracle Menu)、报表生成(Oracle Report)、电子表格(Oracle Calc)接口等一批开
发工具。
2.Oracle 的主要工具
为方便用户开发应用程序,Oracle 提供许多工具,其中最常用的就是 Developer 2000。
它的正式名称是协同开发环境版本 2(Cooperative Development Environment Version 2,
CDE2)。它与 Designer 2000 一起为用户提供一套 Oracle 客户机所需要的设计、编程、运行
和维护完整性的解决方案;提供了在 Windows 环境下快速开发客户机/服务器应用的方法;
其高级功能包括支持业务过程重组以及充分使用有 Oracle 数据库引擎支持的服务器处理方
式。
(1)Developer 2000。在 Developer 2000 中集成了以下几种产品。
① Oracle Forms
② Oracle Report
③ Oracle Book
④ Oracle Graphics
⑤ Oracle Browser
⑥ Oracle Procedure Builder
⑦ Oracle Open Client For ODBC
⑧ SQL*Plus
⑨ SQL * Net
在 Developer 2000 中,每种开发工具都可以单独使用,其中 Oracle Forms 是快速生成基
于屏幕的复杂应用的工具。所生成的应用程序具有查询和操纵数据的功能,具有图形用户界
面。Oracle Report 是快速生成报表的工具,如普通报表、主从式报表、矩阵式报表等类型。
Oracle Graphics 是快速生成图形的工具,可以根据数据库中的数据生成直方图、饼图、线图
等。同时,各工具与各种单独使用的工具不同,它们共同构成一个协同工作环境。用它们开
发出来的表格、图形、报表、应用可以集成一体,不同应用程序之间可以传递参数,并提供
多种共享手段,方便不同项目的开发人员共同使用。
(2)Designer 2000。Designer 2000 是 Oracle 提供的计算机辅助软件工程(Computer Assisted
Software Engineering,CASE)工具,用于帮助用户定义需求、设计系统、生成数据录入和报
表模式。它包括以下 4 个部件。
① CASE Dictionary
② Oracle Forms Generator
③ Oracle Reports Generator
④ CASE Designer
CASE Dictionary 由 Oracle Forms 屏幕生成,它控制所有针对 CASE 产品的访问需求,
由管理员决定用户修改的权限。Oracle Forms Generator 将信息放在 Dictionary 库中,并建立
数据录入和查询屏幕。当系统升级或修改后,用户可以使用 Oracle Forms Generator 重新建立
相应的界面。Oracle Reports Generator 使用户可返回并重新生成自己的报表,修改后的报表能
体现出 Dictionary 中数据的变化。CASE Designer 是一个图形化、鼠标驱动的工具,用户可以

第 2 章 数据库系统概论 - 31 -
用它建立一个应用系统组织结构总的关系网络图。在 Designer 中定义的工作流程和对象将修
改 Dictionary 中的数据。CASE Designer 是用于系统分析和系统工程的工具,其作用贯穿于系
统开发周期的全过程。
2.5 电子政务数据库技术新发展
进入 20 世纪 90 年代,随着计算机应用技术的发展,数据库技术也快速发展。数据库支
持的数据模型越来越复杂,包含越来越多的语义,而且还出现许多新的发展方向。如各类支
持特殊领域应用要求的数据模型的数据库技术,包括空间数据库、时间数据库、演绎数据库、
模糊数据库技术等得到迅速发展;又如对数据分散及不同数据类型数据库互联的需求推动了
分布式数据库的发展;多媒体技术推动了多媒体数据库的发展;联机分析的需求则引起了数
据仓库技术的发展。本节将简单介绍数据库技术的这些新进展。
1.分布式数据库
分布式数据库系统是在两台或多台地理上或物理上分散而逻辑上集中的数据库系统。管
理这样的数据库系统的软件称为分布式数据库管理系统(DDBMS)。分布式系统通常由计
算机网络(局域网或广域网)联结起来,被联结的逻辑单位(包括硬件如计算机、外部设备
和软件如操作系统、数据库管理系统等)称为结点或站点。所谓地理上分散是指各个站点分
布在不同的地方。所谓逻辑上统一是指网络联结的各站点共同组成单一的数据库。
分布式数据库始于 20 世纪 70 年代,繁荣于 80 年代,在 90 年代由于其在分布性和开放
性方面的优势,获得了青睐。这一切并不是偶然的。一方面是受到应用需求的刺激,另一方
面是硬件环境的发展。在应用方面,如银行的通存通兑及划汇、全球性民航订票系统、水陆
空联运系统、连锁店的管理系统、军事上的情报系统、旅游订票系统等,都涉及到地理上分
散的统一组织的管理,集中式的数据库系统已经无法提供合适的支持。在硬件方面,计算机
及通信网络更是突飞猛进地发展。功能强大的计算机、微型机和工作站,以及日益广泛装备
的公用数据网和局域网,为 DDBMS 的研制提供了一个成熟的实用的环境。在两方面的推动
下,DDBMS 得到了迅猛发展。现在,分布式数据库的应用领域已不再局限于联机事务处理,
它已经广泛应用于分布式计算、互联网应用以及数据仓库等。
2.面向对象的数据库系统
面向对象(Object-Oriented,OO)数据库系统是数据库技术与面向对象技术相结合的产
物,它是数据库的应用从传统的商业或管理中的事务处理扩展到 CAD、CAM 及 CIMS、CAI
和办公自动化等新的领域的需要而产生和发展起来的。在这些领域中,传统的关系数据库系
统支持的数据模型的关系太简单,不能很好地描述这些应用领域的数据结构,这样,面向对
象的数据库就应运而生了。OO 数据模型比传统的数据模型具有如下优势。
(1)具有表示和构造复杂对象的能力。
(2)通过封装和消息隐藏技术提供了程序的模块化机制。
(3)继承和类层次技术不仅能表示 is-a 联系,还提供了软件重用的机制。

- 32 - 电子政务数据库基础
(4)通过滞后联编等概念提供系统扩充能力。
(5)提供与宿主语言的无缝(Seamless)连接。
OO 数据模型支持以下的基本概念:对象和对象标识、封装、类型(或类)、继承、重
载、滞后联编、多态性。OO 数据模型支持的基本数据类型较多,从简单的字符、数字、发
展到图像、声音、视频和动画等多媒体数据。OO 数据模型允许用户定义数据类型,它有下
列类(或对象)的结构机制:聚集(元件)、集合、列表、数据等,任一构造机制可以作用
到任一种对象上,使用户能定义十分复杂的数据类型(类),并且能够描述关系很难,甚至
不能描述的、前述的新应用领域中的数据。
面向对象数据库管理系统也具有传统的 DBMS 所具有的功能,如并发控制、用户及授权
管理、从故障中恢复等。但仅仅这样是不够的,传统的事务一般在零点几秒到几秒之内完成
一事务对数据的处理,事务具备原子性、持久性以及可串行性等特殊性质。而新的应用技术
如 CAD、CAI 等的数据处理可以持续几个小时、几天,甚至更长,它们使得传统的事务处理
技术不再适用,而需要新的事务模型,如长事务、嵌套事务等。所以,面向对象数据库管理
系统还应支持长事务处理和嵌套事务,当故障发生时不应回滚整个事务。面向对象的数据库
系统(OODB)所面临的问题是,建立一个健壮的、商用的、面向对象的数据库应用系统开
销很大,所以 OODB 必须能在现有的关系型数据库中直接使用而不是花很大代价去转换,目
前尚不能达到这一步。当前的许多研究都是建立在数据库已有的成果和技术上的。针对不同
的应用,对 RDBMS 进行不同层次上的扩充。
3.多媒体数据库
当今社会存在着各种形态的信息,计算机要以图形、印刷文字、手写文字、声音、图像、
动画和身体语言等多种媒体作为处理对象。能够管理数值、文件、表格、图形、图像、声音
等多种媒体的数据库称为多媒体数据库(MDB)。近年来,大容量光盘、高速 CPU、高速信
号处理器以及宽带网络等硬件技术的发展为多媒体技术的应用奠定了基础。对多媒体数据库
管理的应用主要有以下 3 种方式。
(1)基于关系模型加以扩充,使之支持多媒体数据库类型。
(2)基于 OO 模型来实现对多媒体信息的描述和操作。
(3)基于超文本模型。
针对多媒体信息的特点,多媒体数据库一般支持以下特殊功能。
(1)支持图形、图像、动画、声音、动态视频、文本等多媒体字段类型及用户定义的特
殊类型。
(2)支持定长数据和非定长数据的集成管理。
(3)支持复杂实体的表示和处理,要求有表示和处理实体间复杂关系(如时空关系)的
能力。
(4)有保证实体完整性和一致性的机制。
(5)支持同一实体的多种表现形式。
(6)具有良好的用户界面。
(7)支持多媒体的特殊查询及良好的接口处理。
(8)支持分布式环境。

第 2 章 数据库系统概论 - 33 -
多媒体数据库系统的关键技术有如下。
(1)数据模型技术,如 OO 数据模型、语义数据模型等。
(2)数据的存储管理和压缩/解压技术。
(3)多媒体信息的再现和良好的用户界面技术。
(4)多媒体信息的检索与查询及其他处理技术。
(5)分布式环境与并行处理技术。
4.数据仓库、联机分析处理和数据挖掘
快速、准确、高效地收集和分析信息是企业提高决策水平和增强企业竞争力的重要手段。
企业数据就像埋藏在深山中的金矿,如果不能供企业决策人员使用,就不能充分发挥其应有
的价值,建立以数据仓库技术为基础、以数据库的联机分析处理技术和数据挖掘技术为实现
手段的决策支持系统是解决上述问题的一种行之有效的系统化解决方案。
(1)数据仓库是利用计算机和数据库技术的最新进展,它面向复杂的数据分析以支持决
策过程,而且可以集成企业范围内的数据,无论其地理位置、格式和通信要求。它把支持决
策的数据进行收集、归纳、整理,使企业的业务环境和信息分析环境分离,从而有效地提供
实时的信息服务。数据仓库不是单一的产品,而是由软硬件技术组成的环境,它把各种数据
库集成为一个统一的数据仓库,并且把各种数据库中的数据进行合理的重组、转换和集成,
以适应数据仓库面向主题的要求。
(2)联机分析处理技术是以超大规模数据库或数据仓库为基础对数据进行多维化和综合
分析,构建面向分析的多维数据模型,再使用多维分析方法从若干不同角度对多维数据进行
分析、比较,找出它们之间的内在联系。OLAP 使分析活动从方法驱动转向了数据驱动,分
析方法和数据结构实现了分离。
(3)数据挖掘是从大型数据库或数据仓库中发现并提取深藏于其中的信息的一种新技
术,目的在于帮助决策者找寻数据间潜在的关联,发现未被注意的信息,而这些信息对预测
趋势和决策行为或许很有用。数据挖掘技术涉及数据库、人工智能、机器学习和统计分析等
多种技术。数据挖掘技术能从数据仓库中自动分析数据,进行归纳推理,从中挖掘出潜在的
模式或产生联想,建立新的业务模型,帮助决策者做出正确的决策。数据仓库、联机分析处
理技术和数据挖掘是 3 种独立的信息处理技术。数据仓库用于数据存储和组织;OLAP 集中
于数据分析;数据挖掘则致力于知识的自动发现。它们可以分别应用到信息系统的设计和实
现中,以提高相应部分的处理能力。在现代电子政务决策支持系统解决方案中,3 种技术的
综合是最有前途的选择。
2.6 本 章 小 结
当前,数据库已经成为计算机信息系统和应用系统的组成核心,数据库技术已成为现代
信息系统和应用系统开发的核心技术,更是“信息高速公路”的支撑技术之一。本章在简述
了数据库技术的发展历史的基础上,介绍了数据库技术的相关概念以及几种重要的数据模型,

- 34 - 电子政务数据库基础
并对它们进行了比较。另外介绍了两种数据库管理系统 Oracle 和 Access,最后对当前比较成
熟的新一代数据库技术如面向对象的数据库技术、分布式数据库技术等进行了简单描述,以
形成一个完整的体系。
2.7 本 章 习 题
1.什么是数据模型?一个完整的数据模型应该包括哪些方面的内容?
2.E-R 模型有何作用?
3.解释以下术语:实体、实体集、属性、关键字、联系。
4.网状模型、层次模型和关系模型各有何特点?
5.正确理解数据库的三级模式结构。
6.为什么说数据库管理系统是数据库系统的核心?
7.试分析电子政务系统中数据的特点以及数据管理对于电子政务的重要性。
8.根据学校实际建立学校教务管理系统的 E-R 模型。
2.8 本章参考文献
1.张龙祥,黄正瑞,龙军·数据库原理与设计·人民邮电出版社,2002.7
2.王鹏,董群·数据库技术及其应用·人民邮电出版社,2000.8
3.苏新宁,吴鹏,朱晓峰等·电子政务技术·国防工业出版社,2003.1
4.庄成三,洪玫,杨秋挥·数据库系统原理及其应用·电子工业出版社,2000.6
5.陈佳·信息系统开发方法教程·清华大学出版社,1998.5
6.胡晓惠,陈欣,周莺·电子政务实用技术读本·电子工业出版社,2002.11
7.钱毅·政务数据库系统·人民大学出版社,2004.2
8.张健沛·数据库原理及应用系统开发·中国水利水电出版社,1999.4
9.郑若忠,宁洪,阳国贵等·数据库原理·国防科技大学出版社,1998.8
10.薛华成·管理信息系统(第三版)·清华大学出版社,1999.5
第 3 章 数据库设计基础
在电子政务平台中,数据库系统的应用体现在很多场合,其中主要是在政府内网中作为
政务应用系统的平台,负责各个职能部门和上下级之间的业务处理、公文流转、人事管理等
模块的数据管理工作。如何实现数据组织与管理性能的最佳结合,如何有效控制数据的完整
性、一致性,如何防止数据冗余,以及如何评价数据库系统的性能都离不开关系数据库的规
范化理论,数据库的规范化理论是进行事务管理型数据库设计的必备基础知识。
这套关系模式的规范化理论是根据现实世界存在的数据依赖进行关系模式的规范化处
理,从而得到一个很好的数据库结构。目前流行的关系数据库设计方法是先得到 E-R 模型,
然后转化成关系模式,再进行关系模式的规范化处理。
电子政务系统是基于 Internet 平台的应用系统,随着 Internet 上 Web 数据库应用的不断
发展,电子政务数据库应用系统的体系结构通常有客户机/服务器体系结构和浏览器服务器体
系结构两种。
本章主要内容:
� 关系数据库设计理论
� 数据库设计中关系范式的应用
� 电子政务数据库应用系统的结构
3.1 关系数据库设计理论
数据库设计的一个最基本的问题是如何建立一个好的数据库模式,亦即给出一组数据,
如何构造一个适合于它们的数据模式,使数据库系统无论是在数据存储方面,还是在数据操
纵方面都有较好的性能。第 2 章讨论数据模型时指出,建立 E-R 模型通常被作为描述现实世
界的数据模型。除了面向对象的数据库设计,E-R 模型是目前设计数据库的基本方法。一般
说来,总是先从现实世界得到 E-R 模型,再将 E-R 模型转换成各类数据库系统支持的数据库
模式。这样得到的数据库设计,有可能有数据冗余,由于存在冗余,可能会引起一些不希望
出现的异常,从而难以保证设计的数据库具有好的性能。
关系数据库是以关系模型为基础的数据库。它利用关系来描述现实世界。关系具有概念
单一性的特点,一个关系既可以描述一个实体,也可以描述实体之间的联系。一个关系模型
包括一组关系模式,各个关系模式之间并不是完全孤立的。只有它们之间相互关联,才能构
成一个模型。这些关系模式的全体定义构成关系数据库模式。在 E-R 模型提出以前,Codd
就提出了关系数据库理论,并发展了一套关系数据库设计的理论,即关系的规范化理论。这
套理论根据现实世界存在数据依赖关系进行关系模式的规范化处理,从而得到一个好的数据

- 36 - 电子政务数据库基础
库设计。规范化后的关系模式至少可以避免许多异常。不过找出所有的数据依赖关系并不是
一件容易的事,且纯粹根据存在的数据依赖关系进行规范化,所得到的数据库设计也不一定
是最优的,因为并没有考虑关系的实际大小和对关系要做哪些操作。
但是,关系数据库理论还是有它的实用价值的。关系数据库设计理论提供了分析和判别
一个好的数据库设计的标准;其次,从 E-R 模型转化得到的关系模式可再用关系规范化理论
进行优化;再次,由于将 E-R 模型转换所得到的关系模型有时很繁琐,关系数据库设计理论
可以指导我们合并关系模式,以精简设计。所以,当前流行的关系数据库设计方法是先得到
现实世界的 E-R 模型,然后转化成关系模式,再进行关系模式的规范化。
关系数据库设计理论主要包括 3 方面的内容:函数依赖、范式和模式设计方法。下面主
要讨论函数依赖和关系模式的规范化,即范式。
3.1.1 关系数据库设计缺陷
如何建立一个好的关系数据库模型呢?在解决如何设计一个好的数据库模型之前,先通
过一个例子来看看某些不恰当的关系模型可能导致的问题。
设有一个“员工信息表”关系如下:
员工信息表(员工姓名,政治面貌,籍贯,性别,⋯⋯,社会关系(与本人关系,姓名,
工作单位),本人简历(起始至终止年月,所在单位,证明人))。表 3-1 是该关系的一个
实例(只给出部分数据)。
表 3-1 “员工”关系的一个实例
社会关系 本人学习简历
员工姓名 性别 政治
面貌 籍贯 与本人
关系 姓名
工作
单位
起始至终
止年月
所在
单位 证明人
张亚楠 男 党员 江苏 父亲 张其 南京 1976/09~1982/08 小学
张亚楠 男 党员 江苏 母亲 李青 南京 1982/09~1988/07 中学
张亚楠 男 党员 江苏 姐姐 张亚平 杭州 1988/09~1992/07 大学
从表 3-1 中,可以看出“社会关系”和“本人学习简历”两个数据元素各自包含 3 个数
据元素。这样使得同一员工的姓名、性别、籍贯政治面貌等数据元素的值在关系中的多个记
录中重复存储,产生了大量的数据冗余。同时,由于数据的重复存储,会给更新带来麻烦。
如果某个员工政治面貌发生改变,则关系中所有有关该员工的记录都要更改,如有一个不改
就会导致数据的不一致。除此之外,这样的关系还会带来其他一些异常情况,如插入、删除
异常等。这些异常的产生主要是因为关系模式的结构,即关系中的属性之间存在过多的数据
依赖关系。
在现实世界中任何一个实体或实体之间联系的属性之间都存在一定的联系。如“员工信
息表”中假设没有重名现象,则员工姓名“张亚楠”决定了他的性别、性别、政治面貌等属
性值;员工姓名“张亚楠”和与本人关系“父亲”值决定了张亚楠父亲的姓名、工作单位;

第 3 章 数据库设计基础 - 37-
员工姓名“张亚楠”和“1988/09~1992/07”值决定了张亚楠的所在单位及证明人。这些数
据元素之间的依赖关系表示如下:
员工姓名→性别;员工姓名→政治面貌;员工姓名→政治面貌;员工姓名+与本人关系
→姓名;员工姓名+与本人关系→工作单位;员工姓名+起始至终止年月→所在单位;员工
姓名+起始至终止年月→证明人。
如果将上面例子中的关系模式分解成 3 个新的关系模式。
(1)员工(姓名,性别,政治面貌,籍贯)。
(2)员工社会关系(员工姓名,与本人关系,工作单位)。
(3)员工学习简历(员工姓名,起始至终止年月,所在单位,证明人)。
则上述所提到的存储异常问题都不存在了。这样的分解将更加符合现实世界的客观情
况。所以,为了避免数据冗余、更新异常、插入异常和删除异常等情况,就要对关系模型进
行合理分解,即进行关系数据模型的规范化。
结合前面,规范化的目的可以概括为以下 4 点。
(1)把关系中的每一个数据项都转换成一个不能再分的基本项。
(2)消除冗余,并使关系的检索简化。
(3)消除数据在进行插入、修改和删除时的异常情况。
(4)关系模型灵活,易于使用非过程化的高级查询语言进行查询。
3.1.2 函数依赖和多值依赖
1.函数依赖(Functional Dependency)
函数依赖反映了数据之间的内部联系,它是进行关系分解时的指导和依据,也是本章的
讨论中心。
为了方便起见,假设 R(A1,A2,A3,⋯,An)是一个关系模型,U={A1,A2,A3,⋯,
An}是 R 的所有属性集合,X、Y 和 Z 分别表示 R 中的属性子集。
定义 1:若对于 R 中的 X 的任何一个具体值,Y 仅有惟一的具体值与之对应,则称 R 的
属性 Y 函数依赖于属性 X,记做 X→Y,X 称为决定因素(Determinant)。
如果 X→Y,且 Y 不是 X 的子集,则称 X→Y 是非平凡的函数依赖(Nontrivial Functional
Dependency)。我们讨论的都是非平凡的函数依赖。
例如:在例子“学生”关系模型中,学号→姓名,系号→系负责人,{学号,课程名}→成绩。
定义 2:在 R 中,如果属性集 Y 函数依赖于属性集 X,且不函数依赖于 X 的任何真子集,
则称 Y 完全函数依赖于 X(Full Functional Dependency),记做 X → f Y,否则 Y 部分函数
依赖于 X(Partial Functional Dependency),记做 X →p Y。
上述的学生关系中,属性“成绩”完全函数依赖于属性集{学号,课程名},而属性“姓
名”则部分依赖于属性集{学号,课程名}。 定义 3:在 R 中,对于属性子集 X、Y、Z,若 X → �Y,Y ⊄ X,Y→Z,则称 Z 对 X
传递函数依赖(Transitive Functional Dependency),记做 X →t Z。 设有关系配件��供应商��库存(配件编号,配件名称,规格,供应商名称,供应商

- 38 - 电子政务数据库基础
地址,价格(厂价),库存量,库存占用资金),其中每个供应商只有一个地址。在该关系
中,{配件编号,供应商名称}是关系的主关键字。因为配件编号能惟一确定一种配件的名称
及其规格,所以属性“配件名称”、“规格”部分函数依赖于主关键字{配件编号,供应商名
称},由于一种配件可以由多家供应商供货,而不同的供应商所提供的价格是不一样的,所以
只有知道了配件编号和供应商名称,才能确定配件价格(厂价),因此,价格(厂价)完全
函数依赖于主关键字{配件编号,供应商名称}。同样,“库存量”也完全函数依赖于主关键
字。另外,库存占用资金=价格×库存量,所以,库存占用资金函数依赖于价格和库存量,
这样,库存占用资金则传递依赖于{配件编号,供应商名称}。
2.关键字
前面已经介绍过关键字的概念,介绍了函数依赖的概念后,就可以给关键字进行精确的
定义。
(1)候选关键字(候选码)
定义 4:在 R 中,设 K 是 U 的属性或属性集合。如果 K → f U,则称 K 是关系 R 的一
个候选关键字。若 R 中有一个以上的关键字,则选定其中一个作为主关键字(主码),如果
K 是属性集合,则称为组合关键字或合成关键字。
包含在任意一个候选关键字中的属性,称为主属性。不包含在任何候选关键字中的属性
称为非主属性。
在极端情况下,若关系的全部属性作为关键字,则称为完全关键字。此时关系中没有非
主属性。候选关键字具有以下两个性质。
① 标识的惟一性:对于 R 中的每一元组,K 的值确定后,该元组就确定了。
② 无冗余性:当 K 是属性集合时,K 的任何一个部分都不能标识该元组。
(2)外关键字(外码)
定义 5:在关系 R 中,若属性或属性集合 X 不是 R 的关键字,但 X 是其他关系中的关
键字,则称 X 是关系 R 的外关键字或外码。
主关键字和外关键字提供了表示关系之间联系的手段。
设有“职工”关系:
职工(职工号,职工姓名,年龄,姓名,部门编号)
“部门”关系:
部门(部门编号,部门名称,部门负责人)
在“职工”关系中,部门编号不是它的关键字,但部门编号是“部门”关系的主关键字,
所以部门编号是职工关系的外关键字。
3.多值依赖(Multivalent Dependency)
属性之间的关系中除了函数依赖,还有多值依赖。和函数依赖相比,多值依赖不大直观,
较难理解。关系模式中如果存在多值依赖,和函数依赖一样,也会造成数据冗余,导致数据
操作异常。
定义 6:在关系 R 中,X、Y、Z 是属性子集,且 Z=U − X − Y,多值依赖 X→→Y 成立
当且仅当对 R 中给定的一对(X,Z)值有一组 Y 的值与之对应,这组值仅仅决定于 X 值而
与 Z 值无关。

第 3 章 数据库设计基础 - 39-
某单位的供应部门直接将各工程所需要的物资从供应商的仓库发往工程所在地,为了规
划运输方案,可以定义如下的关系存储所有零件的可能的运输源和目的地。
运输(工程名称,工程地址,物资名,供应商名,供应商地址)
这个关系模式的关键字为{物资名,工程名称,供应商名},其中除了有函数依赖关系
工程名称→工程地址,供应商名→供应商地址,还有多值依赖物资名→→{工程名称,工程
地址},物资名→→{供应商名,供应商地址}。因为这一关系中,一种物资可以被多个工
程使用,与该物资由谁提供无关;同样,一种物资可以由多个供应商提供,与哪些工程使用
该物资无关。可以看出,由于多值依赖的存在,这个关系有冗余。
另外,很明显,关系模式中至少有 3 个属性,才有可能存在多值依赖。函数依赖可以看
成多值依赖的一种特殊情况,即函数依赖一定是多值依赖;而多值依赖是函数依赖的概括,
即存在多值依赖的关系,不一定存在函数依赖关系。
3.1.3 关系模式的规范化
关系数据库中的关系是要满足一定规范化要求的,对于不同的规范化要求程度,可以用
“范式”来衡量,记做 NF(Normal Formulation)。范式是表示关系模型的级别,是衡量关
系模型规范程度的标准,达到范式的关系才是规范化的。满足最低要求的为第一范式,简称
1NF;在第一范式的基础上,进一步满足一些要求的为第二范式,简称 2NF;⋯⋯,依次类
推。
1.第一范式(1NF)
如果关系 R 的每一个属性的值为不可分离的原子值,即每个属性都是不可再分的基本数
据项,则 R 是第一范式,记做 R∈1NF。
这是关系模式必须达到的最低要求,不满足该条件的关系模式称为非规范化关系,即非
第一范式。目前大部分商用的 RDBMS 处理的关系要求至少是 1NF 的。下面的两个关系中,
“部门”关系是 1NF 的,而“职工”关系是非 1NF 的。
部门:
部门编号 部门名称 部门负责人
职工:
工资 职工
编号
职工
姓名 基本工资 补贴 奖金
将“职工”关系转换为1NF:
职工编号 职工姓名 基本工资 补贴 奖金
即将属性“工资”分解成 3 个不可再分的属性:基本工资,补贴,奖金。

- 40 - 电子政务数据库基础
2.第二范式(2NF)
如果关系 R∈1NF,且 R 中每一非主属性完全函数依赖于主关键字,则 R 是第二范式,
即 R∈2NF。
设有一关系职工情况表(职工工号,职工姓名,性别,出生年月,起始至终止年月,工
作单位,证明人),其关键字为{职工工号,起始至终止年月},而在非主属性中,只有属性
“工作单位”和“证明人”是完全函数依赖于主关键字,职工姓名、性别、出生年月对主关
键字都是部分函数依赖,因为只要有了职工工号就可以确定它们的值。所以“职工情况表”
关系模式不是 2NF。
通过简单的投影分解可以使非 2NF 的关系转化为 2NF 的关系,其方法为:将部分函数
依赖关系中的主属性(决定方)和非主属性从关系模式中提出,单独构成一个关系模式;将
关系模式中的余下的属性,加上主关键字,构成另一个关系模式。如“职工”关系模式可分
解成如下两个 2NF 的关系模式。
(1)职工情况(职工工号*,职工姓名,性别,出生年月)
(2)职工履历(职工工号*,起始至终止年月*,工作单位,证明人)
(3)这里所说的投影分解,是指所得关系是原关系的投影。
而在分解后的关系模式中,仍存在着分解前的函数依赖关系。
(1)职工工号 → 职工姓名,职工工号 → 性别,职工工号 → 出生年月,每个职工的工号
是惟一的;
(2){职工工号,起始至终止年月}→ 工作单位,{职工工号,起始至终止年月}→ 证
明人。
3.第三范式(3NF)
如果 R∈2NF,且它的任何一个非主属性都不传递依赖于任何主关键字,则 R 是第三范
式,记做 R∈3NF。
将非 3NF 的关系转化为 3NF 的关系可以用如下的方法。
(1)将起传递作用的函数依赖关系中的主属性(决定方)和非主属性提出单独构成一个
关系模式,再将它的决定方和关系模式中余下的属性,加上主关键字,构成另一个关系模式。
(2)去掉关系模式中的多余项。
设有一个“配件库存”关系:配件库存(配件编号,供应商名称,价格(厂价),库存
数量,库存占用资金)。其中同一种配件可以由不同的供应商提供,不同的供应商提供的同
一种配件的价格是不一样的,库存数量也是不一样的,所以该关系模式中存在的函数依赖是
{配件编号,供应商名称} → 价格,{配件编号,供应商名称} → 库存数量,{价格,库存数量} →库存占用资金,该关系是 2NF,但非主属性“库存占用资金”传递依赖于主关键字{配件编
号,供应商名称},因为库存占用资金=价格×库存数量,而价格和库存数量是函数依赖于主
关键字的,所以,“库存占用资金”传递依赖于主关键字,该关系模式不是 3NF。可将关系
模式中非主属性“库存占用资金”去掉,使其成为如下的 3NF:
配件库存(配件编号,供应商姓名,价格(厂价),库存数量)
第 3 章 数据库设计基础 - 41-
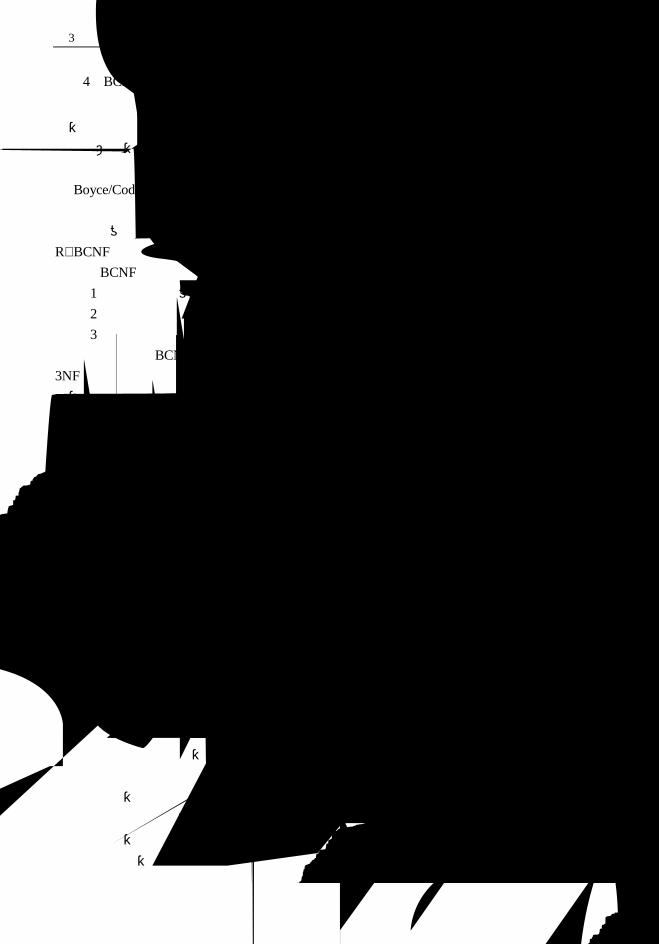
4.BCNF
第三范式的关系模式消除了非主属性对关键字的传递依赖和部分函数依赖,但并不很彻
底,因为在存在多个关键字或关键字为属性组时,仍有可能存在主属性对关键字的部分和传
递函数依赖,由此也会造成数据的冗余,从而给操作带来问题。
为了解决第三范式的不彻底性,Boyce 和 Codd 于 1974 年共同提出了改进的第三范式,
即 Boyce/Codd 范式,简记为 BCNF。Boyce/Codd 范式通过消除决定因素不含关键字,从而
消去主属性之间的部分和传递函数依赖。
如果关系 R∈3NF,X、Y⊆U,若 X→Y,且 Y⊄X 时,X 必含有码,则 R 是 BCNF,即
R∈BCNF。
从 BCNF 的定义可以看出,一个满足 BCNF 的关系模式一定满足如下条件。
(1)非主属性对关键字完全函数依赖;
(2)主属性对不包含它的关键字完全函数依赖;
(3)没有属性完全函数依赖于一组非主属性。
第三范式和 BCNF 有一定的关系。一个关系模式属于 BCNF 则一定属于 3NF,BCNF 是
3NF 的特例。但反之则不然,属于 3NF 的关系不一定是 BCNF,3NF 是对 BCNF 放宽一个限
制,即允许决定因素中不包含码。
5.第四范式
第四范式是 BCNF 的推广,它适用于多值依赖的关系模式。如果关系模式 R∈BCNF, 若
X→→Y(Y⊄X)是非平凡的多值依赖,且 X 含有码,则称 R 是第四范式,即 R∈4NF。
一个关系范式如果属于 4NF,则一定属于 BCNF,但是一个 BCNF 的关系模式不一定是
4NF。使关系模式达到 4NF 的方法是消除非平凡、非函数依赖的多值依赖:
如果关系模式 R(X,Y,Z)满足多值依赖 X→→Y,Y→→Z,那么可以将其投影分解为
R1(X,Y)和 R2(Y,Z)两个关系模式。
到目前为止,规范理论已经提出五级范式,但在实际应用中最有价值的是 3NF 或 BCNF。
所以,一般分解到 3NF 就可以了。
3.1.4 关系规范化的基本原则
一个低级范式的关系模式,通过关系模式的投影分解,可以转换成若干个高一级范式的
关系模式的集合,这种过程就叫规范化。其基本思想是:逐步消除数据依赖中不合适的部分,
使各关系模式达到一定程度的分离,即“一事一地”的模式设计原则,使概念单一化,也就
是让一个关系描述一个概念、一个实体或者实体间的一种联系。
规范化的程度越高,数据的冗余和更新异常相对减少,但由于连结运算费时,查询时所
花的时间也就越多。因此,规范化应根据具体情况权衡利弊,适可而止,对于数据变动不频
繁的数据库,其规范化程度可以低一些。实际工作中,一般达到多数关系模式为 3NF 即可。
另外要注意的是,规范化仅仅从一个侧面提供了改善关系模式的理论和方法。一个关系
模式的好坏,规范化是衡量的标准之一,但不是惟一的标准。数据库设计者的任务是在一定
的制约条件下,寻求较好地满足用户需求的关系模式。规范化的程度不是越高越好,它取决

- 42 - 电子政务数据库基础
于应用。
根据关系数据库设计理论,优化关系数据库设计的过程,实际上是对关系模式进行规范
化的过程,即不断通过投影分解使非规范化的关系模式达到规范化的要求。一般说来,关系
模式 R(A1,A2,A3,⋯,An)的分解就是用 R 的一组子集{R1,R2,R3,⋯,Rk}来
代替 R,且这组子集满足条件:
R=R1 R2 R3 ⋯ Rk
其中,任意两个子集 Ri 和 Rj 相互的交集不要求为空,即它们可以有共同的属性。通过分解,
可消除数据冗余,从而消除插入、删除或更新的异常。对于关系分解,我们不仅要求消除数
据冗余,还要求分解后的关系模式和分解前的关系模式能表示出相同的信息,即所谓的无损
连接分解。在关系的规范化过程中,一般都采用无损连接分解。可以证明,利用函数依赖和
多值依赖所做的投影分解都是无损连接分解。
在关系模式规范化时,一般要遵循以下原则。
(1)关系模式进行无损连接分解。关系模式分解过程中数据不能丢失或增加,必须把全
局关系模式中的所有数据无损地分解到各个子关系模式中,以保证数据的完整性。
(2)合理选择规范化程度。从存取效率考虑,低级范式造成的冗余度很大,既浪费了存
储空间,又影响了数据的一致性,因此希望一个子模式的属性越少越好,即取高级范式;从
查询效率考虑,低级范式又比高级范式好,此时连接运算的代价小。这是一对矛盾,所以应
根据实际情况,合理选择规范化程度。
(3)正确性和可实现性原则。
3.1.5 规范化小结
规范化的过程是逐步消除关系模式中不合适的数据依赖的过程,使关系模型中的各个关
系模式达到某种程度的分离。可用图 3.1 概括规范化的过程。
图 3.1 规范化过程
以简单的关系模式为例,将其逐级规范化。例如有“教师任课”关系模式(教师工号,
姓名,职称,系号,系名称,教学情况(课程号,课程名,教学水平,学分))。
分析上述关系模式可知该关系模式为非规范化的关系模式,所以要对其进行规范化。具
消去重复组项,将关系模式分解成若干个规范化的关系模式,并指定一个或若干个属性作为主关键字
消除非主属性对主关键字的传递函数依赖
消除非主属性对主关键字的部分函数依赖
消除主属性对不包含它的主关键字的部分函数依赖
非规范化的关系模式
1NF
2NF
3NF
BCNF

第 3 章 数据库设计基础 - 43-
体步骤如下所述。
(1)消去重复组
以教师讲授一门课作为一条记录,合并所有的有关属性,得到如下的关系模式:
教师任课(教师工号,姓名,性别,职称,系号,系名称,课程号,课程名,教学水平,
学分)
其中,{教师工号,课程号}为关键字,此关系为 1NF。
(2)消去部分函数依赖
在教师任课关系模式中,一些非主属性对关键字{教师工号,课程号}部分函数依赖,如
姓名、性别、职称部分函数依赖于关键字{教师工号,课程号},因为它们实际上是由教师工
号决定的。因此,需要对关系进行分解,使非主属性完全函数依赖于关键字,从而得到如下
3 个关系模式。
① 教学情况(教师工号,课程号,教学水平);关键字为{教师工号,课程号}
② 教师(教师工号,姓名,性别,职称,系号,系名称);关键字为教师工号
③ 课程(课程号,课程名,学分);关键字为课程号
3 个关系模式都是 2NF。但是在“教师”关系模式中,教师工号→ 系号,系号 → 系名
称,所以非主属性系名称传递依赖于关键字教师工号,因此关系模式不是 3NF。
(3)消去传递依赖
为消除传递依赖,将“教师”关系模式进一步分解成如下两个关系模式。
① 教师(教师工号,姓名,性别,职称,系号);关键字为教师工号
② 系(系号,系名称);关键字为系号
所以,可以用下面的 4 个关系模式代替最初的关系模式“教师任课”。
① 教师(教师工号,姓名,性别,职称,系号);关键字为教师工号
② 系(系号,系名称);关键字为系号
③ 教学情况(教师工号,课程号,教学水平)
④ 课程(课程号,课程名,学分)
在这 4 个关系模式组成的关系模型中消除了传递依赖,达到了 3NF。在任一个模式中,
每个决定因素都是关键字,因此也同时满足了 BCNF 的要求。
一个关系模式达到 BCNF,说明在函数依赖的范畴内,已经实现了彻底分离,可以消除
插入、删除和更新的异常。
对关系模式的规范化可以小结如下。
(1)目的:规范化的目的是使结构合理,清除存储异常并使数据冗余尽量小,便于插入、
删除和更新。
(2)原则:遵从概念单一化“一事一地”原则,即一个关系模式描述一个实体或实体间
的一种联系。规范的实质是概念单一化。
(3)方法:将关系模式投影分解成两个或两个以上的关系模式。
(4)要求:分解后的关系模式集合应当与原关系模式等价,即经过自然连接可恢复原关
系而不丢失信息,并保持属性间合理的联系。

- 44 - 电子政务数据库基础
3.2 数据库设计中的关系范式
前面提到的关系模式规范化的过程是:假定先用某种方法得到一个关系数据库模式,然
后分析和确定这个数据库模式中的所有存在的函数依赖及多值依赖关系,再用介绍的方法相
对机械地进行关系模式的分解,消除关系模式中的一些不适当的数据依赖关系,从而将关系
数据库模式规范化。理论上的做法如此,而在实际应用中并非完全这样做。主要原因如下:
(1)复杂的关系模式,找出其中所有的函数依赖关系并不是一件容易之事,若漏掉或错
误地确定一些函数依赖关系,按前述方法进行关系规范化,并不能得到一个在理论上被认为
是好的数据库设计。
(2)即使能正确地找到所有的函数依赖关系,采用机械地分解模式的方法,并不考虑关
系的具体大小,以及数据的动态特征(是否经常更新),将其全部规范到同样的程度,也是
不合适的。
(3)数据库设计一般采用先得到现实环境的 E-R 模型,再由 E-R 模型转换得到关系模式
的方法。从 E-R 模型转换而来的关系模式,一般很少含有很多的属性。因为 E-R 模型中实体
一般分得较细,转换得到的关系模式较小,为了以后数据库查询的方便,很多情况下是要合
并关系模式,而不是分解关系。所以在实际应用中,要想得到一个好的数据库设计,应根据
具体情况对关系模式进行处理,既有可能要分解关系模式,也有可能要合并关系模式。
然而这并不意味着关系规范化理论在实际数据库设计中是没有意义的,它对我们进行关
系数据库模式的设计仍然具有指导作用。在我们进行 E-R 模型设计时,以及由 E-R 模型转换
成关系模式后,进行关系模式优化设计时,关系模式规范化理论能够帮助我们得到较好的数
据库设计。在设计 E-R 模型时,要仔细分析实体间存在的关系,这样能使我们最后从 E-R 模
型得到的关系数据库模式基本达到 3NF 的规范程度。数据之间的函数依赖是现实世界中客观
存在的,所以数据依赖关系的确定最好在进行系统分析、生成 E-R 模型的过程中完成,而无
须在得到关系数据库模式后,再去寻找存在哪些数据依赖关系。其实,在生成 E-R 模型时确
定数据之间的函数依赖关系更为容易,因为 E-R 模型更接近现实世界。例如,在确定一个实
体集和其相应的属性后,也就确定了属性对实体集的依赖关系,以及实体集中非关键字属性
对关键字属性的依赖关系;又如,如果联系 R 表示从实体集 E1 到实体集 E2 的一对多联系,
广义地说,是实体集 E2 决定了实体集 E1,在转换成关系模式后,联系 R 形成的关系模式的
集合中有 E2 的关键字 X 和 E1 的关键字 Y,则 X→Y 成立,而且 X 决定了 R 中任何一个属
性集,若 E1 和 E2 之间是一对一联系,则 Y→X 也成立,可见,在 E-R 模型中隐含着许多数
据依赖关系。
在 E-R 模型中,任何事物、数据或知识都可以是实体,实体的属性是对实体某一方面特
征的描述,它也有可能具有非常复杂的结构,而且属性之间也可能存在各种各样的数据依赖
关系。由于我们建立 E-R 模型的最终目的是生成关系数据库模式,但在关系模式中是不能描
述具有复杂结构的属性,所有在发现实体某一属性结构复杂时,通常要在 E-R 模型中加入新
的实体来解决这个问题,即将一个实体分解成多个实体,将具有复杂结构的属性处理成实体。
同样,当发现某实体的属性之间除了存在对关键字属性的完全函数依赖关系外,还有其他的
函数依赖关系,或在分析插入、删除、更新等动态特性时发现有可能发生异常时,也可以通

第 3 章 数据库设计基础 - 45-
过发现新实体,将其添加到 E-R 模型中,从而消除这些函数依赖关系。当然是否一定要消除
这些函数依赖关系,还要综合考虑数据冗余和数据的动态特性,函数依赖多,数据冗余就多,
但查询代价小。所以对于因为保留函数依赖关系而造成数据冗余时,应设计数据库触发器或
采取别的措施,来保证在插入、删除、修改时的数据一致性,避免数据操作异常的产生。
从 E-R 模型转化成关系模型后,常合并一些关系以求模型简单、易用。合并关系时要避
免产生多余的数据依赖关系,以免造成数据冗余。合并关键字相同的关系模式不会产生数据
冗余;合并存在外关键字约束的两个关系时,会产生数据冗余,因此是否进行合并也要全面
考虑。
那么,如何从将 E-R 模型转换为关系模型呢?可以将 E-R 模型转换成关系数据模式,用
关系数据模型提供的方式描述现实世界的数据。具体转换规则如下。
(1)E-R 图中的每个实体集,都相应地转换成一个关系,实体集的名称就作为关系的名
称,实体集的属性则作为关系的属性,实体集的关键字作为关系的关键字。
(2)对于 E-R 图中的联系,一个转化成一个关系,联系的名称作为关系的名称,联系的
属性作为关系的属性,所有参加联系的实体集的关键字也作为关系的属性,关系的关键字由
联系的类型决定如下。
① 若是 1:1 联系,则任选一参加联系的实体集的关键字作为关系的关键字。
② 若是 m:n 联系,所有参加联系的实体集的关键字作为联系所对应的关系的关键字。
③ 若是 1:n 关系,则将多方的实体集的关键字作为关系的关键字。
经过上述转换而来的数据库模式一般说来不是最好的,关系的个数太多,太烦琐,数据
重复存储,浪费空间,且使许多查询不方便,牵涉到几个表,所以有必要将一些关系进行合
并。我们前面讲过,可以将具有相同关键字的关系合并,合并后的关系包含两关系的所有属
性。对照关系范式的要求,使每一关系都应满足第三范式的要求。
3.3 电子政务数据库应用系统的结构
计算机的应用结构经历了集中式结构、文件服务器、客户机/服务器的网络结构,发展到
现在的浏览器/服务器结构。
在集中式结构中,所有的资源(数据)和处理(程序)都在一台称为主机的计算机上完
成,用户输入的信息通过客户机终端传到主机上。这种结构可以实现集中管理,安全性好,
但是由于应用程序和数据库都存放在主机上,所以无法真正划分应用程序的逻辑,开发和维
护都非常困难,不在同一地点上的数据无法共享,系统庞大复杂,无法展开计算机间的协作。
在文件服务器系统结构中,应用程序在客户工作站上运行,而不是在服务器上运行,文件服
务器只提供资源(数据)的集中管理和访问途径。这种结构配置灵活,在一个局域网内可以
方便地增减客户端工作站。但是,由于文件服务器只提供文件服务,所有的应用处理都在客
户端完成,这样就要求客户端的个人计算机必须有足够的能力,以便执行需要的任何程序。
这可能需要客户端的计算机经常升级,否则无法改进应用程序的功能或提高应用程序的特性。
因此,便产生了客户机/服务器结构。

- 46 - 电子政务数据库基础
客户/服务器(简称 C/S)模式是以网络环境为基础、将计算应用有机分布在多台计算机
中的结构。其中一个或多个计算机提供服务,称为服务器(Servers),其他的计算机负责接受
服务,称为客户机(Clients)。C/S 模式把系统的任务进行了划分,它把用户界面和数据处理
操作分开在前端(客户端)和后端(服务器端),服务器负责数据的存储、检索与维护,而客
户机负责提供 GUI 接口,承担诸如处理与显示检索所得的数据、解释和发送用户的请求等任
务。客户机提出数据服务请求,由服务器把按照请求处理后的数据传送给客户。因此在网络
中传输的数据仅仅是客户需要的那部分数据,而不是全部。这个特点使得客户/服务器的工作
速度主要取决于进行大量数据操作的服务器,而不是前端的硬件设备;同时大大降低了对网
络传输速度的要求,使系统性能有了较大的提高。客户/服务器方式增加了数据库系统数据共
享能力,服务器上存放着大量的数据,用户只需要在客户机端用标准的 SQL 语言访问数据库
中的数据,便可方便地得到所需要的各种信息。
3.3.1 客户机/服务器的组成
客户机/服务器系统有 3 个基本组成部分:客户机、服务器、客户机与服务器的连接。
(1)客户机
客户机是一个面向最终用户的接口或应用程序。它通过向一个设备或应用程序(服务器)
发出请求信息,然后将信息显示给用户。客户机把大部分的工作留给服务器,让服务器上的
高档硬件和软件充分施展其特长。通过网络把数据分析和图形表示从服务器上分离下来,这
样客户机硬件就能大大减少网络上的传输事务,使网络能为用户提供更为有效的信息流。
(2)服务器
服务器的主要功能是建立进程和网络服务地址、监听用户的调用、处理客户的请求、将
结果交给客户机和释放与客户机的连接。服务器多是大型机或高档微机。要求服务器配有高
档的处理器、大容量内存、稳定快速的总线和网络传输以及完整的安全措施。
(3)连接件
客户机与服务器之间的链接是通过网络连接实现的。对于应用系统来说,这种链接多是
指一种软件通信过程;对应用开发人员来说,客户机/服务器之间的链接主要是它所能使用的
软件工具和编程函数。目前,各种链接客户机和服务器的标准接口和软件很受欢迎,如开放
的数据库链接(ODBC)就是基于 SQL 访问组织规范的数据库链接应用程序接口,该接口可
在应用程序与多个数据库服务器之间进行通信。客户机应用只需与标准的 ODBC 函数打交
道,采用标准的 SQL 语言来编程,而不必关心服务器软件的要求及完成方式。关于 ODBC
将在以后的章节予以讨论。
客户机/服务器结构的关键在于任务的划分。一般地,客户端完成用户接口任务,主要是
输入/输出和任务的提交;服务器端则主要完成数据的存储、访问和复杂的计算任务。连接件
主要完成客户与服务器间的数据交换。客户机与服务器软件通常在客户方屏蔽掉服务器的地
址信息,做到定位透明性,因而从应用的观点看它们之间的交互是无缝的。
3.3.2 二层客户机/服务器的结构
客户机/服务器起源于 20 世纪 80 年代,是一种存储、访问和处理数据的分布式模型。一
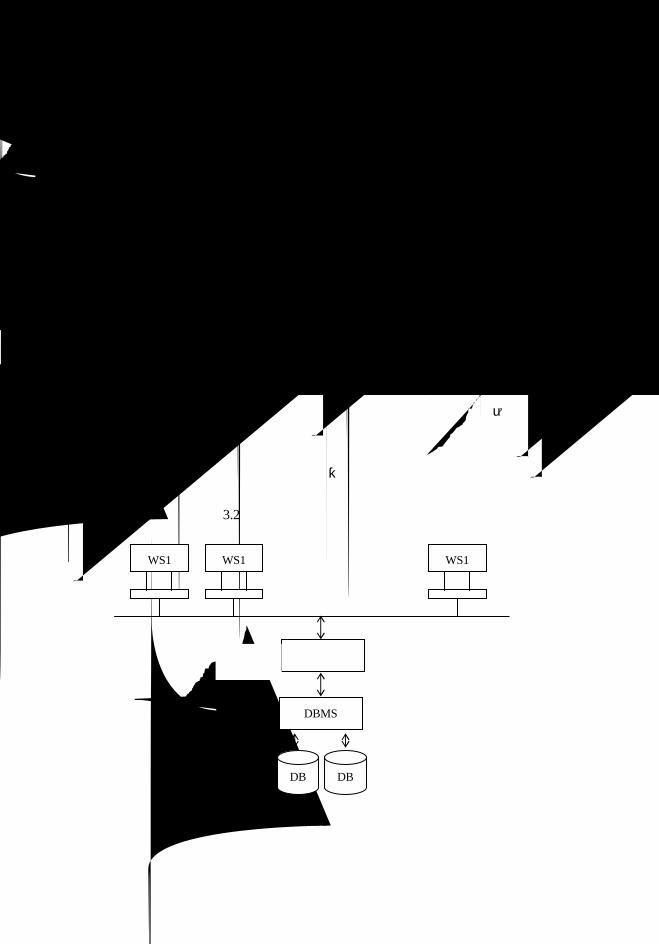
第 3 章 数据库设计基础 - 47-
个客户机服务器系统一般需要两台计算机。
客户/服务器模型中计算机执行一个或多个数据存储、访问或处理操作,这与终端的概念
是不同的,因为终端只能传递和显示字符,而客户机/服务器的功能更为强大。
当个人计算机与服务器连接时,整个处理将被分配在客户机和服务器系统之间,通过对
任务进行合适的分组,可以使整个系统保持高效地运作。
客户机/服务器系统是由客户机和服务器以及连接两者之间的网络构成,客户机与服务器
体现了分工的差异。它们完成的处理是不同的。一般来说,服务器速度快、数据存储量大,
较客户机系统执行更多的工作,主要负责向客户机提供数据服务,实现数据管理和事务逻辑;
而客户机的性能要求则相对较低一些,客户机只完成整个工作的较小部分,主要负责应用逻
辑的处理、用户界面的处理和显示通过网络与服务器交互,大量的数据处理是由服务器完成
的。
客户机/服务器结构既可指硬件的结构也可指软件的结构。硬件的客户机/服务器结构是
指某项任务在两台或多台计算机之间进行分配。客户机在完成某一项任务时,通常要利用服
务器上的共享资源和服务器提供的服务。在一个客户机/服务器体系结构中可以分为多台客户
机和多台服务器。
软件的客户机/服务器结构是把一个软件系统或应用系统按照逻辑功能划分为若干个组
成部分,如用户界面、表示逻辑、事务逻辑、数据访问等。这些软件成分按照其相对角色的
不同,区分为客户端软件和服务器端软件。客户软件能够请求服务器软件的服务。如客户软
件负责数据的表示和应用,请求服务器软件为其提供数据的存储和检索服务。客户软件和服
务器软件可以分布在网络的不同计算机节点上,也可以放置在同一台计算机上。客户端软件
和服务器端软件的功能划分可以有多种不同的方案。
客户机/服务器结构如图3.2所示。
图 3.2 C/S 结构
WS1 WS1 WS1
接 口
DBMS
DB DB
网络电缆
客户机
服务器

- 48 - 电子政务数据库基础
客户机/服务器结构是一个开放体系结构,因此数据库不仅要支持开放性,而且还要开放
系统本身,包括用户界面、软硬件平台和网络协议。利用开放性在客户机一侧提供应用程序
接口(API)及网络接口,这样用户仍可按照他们熟悉的、流行的方式开发客户机应用。在
服务器一侧,通过对核心 RDBMS 的功能调用,使网络接口满足了数据完整性、保密性及故
障恢复等要求。有了开放性,数据库服务器就能支持多种网络协议,运行不同厂家的开发工
具,而对于某一应用程序开发工具也可以在不同的数据库服务器上存取不同数据源中的数据,
这样就给应用系统的开发带来很大的灵活性。
当今,客户机/服务器体系结构已经成为计算机体系结构的主流,并迅速成为 Internet 的
主干。
3.3.3 三层客户机/服务器的结构
在传统的两层客户机服务器结构中,开发工作主要集中在客户方,客户方软件不但要完
成用户交互和数据显示的工作,而且还要完成对应用逻辑的处理工作,即使用户界面与应用
逻辑位于同一平台上。这样就带来了两个突出的问题,即系统的可伸缩性较差和安装维护较
为困难。
因为在一个系统中并不是所有的客户机要求都一样,所以它们要求程序的功能也不尽相
同。使用两层结构应用软件时,开发人员提供的所有程序都是相同的,除非开发人员根据不
同用户的需求将大的软件裁剪成不同的小软件分发给不同的用户。
另外,在系统开发完毕后,整个系统的安装也非常繁杂。在每一台客户机上不但要安装
应用程序,而且还必须安装相应的数据库连接程序,并要完成大量的系统配置工作。所有的
客户端都要配置好几层软件,因而变得很庞大,被称为“肥客户机”。这样如果系统有大量
用户,并且用户是分布的和流动的,如广域网环境下的应用系统,则整个系统的安装和维护
将非常困难。在系统进行修改后,所有客户机上的软件都要受到影响。
为了解决两层结构应用软件中存在的问题,人们又提出了三层结构应用软件。在三层结
构的应用软件中,整个系统由 3 个部分组成:客户机、应用服务器和数据库服务器。客户机
上只需安装应用程序,它负责处理与用户的交互和与应用程序的交互。应用服务器负责处理
应用逻辑,即接受客户机方应用程序的请求,然后根据应用逻辑将这个请求转化为数据库请
求后与数据库服务器进行交互,并将与数据库服务器交互的结果传送给客户机方的应用程序。
数据库服务器软件根据应用服务器发送的请求进行数据库操作,并将操作结果传送给应用服
务器。三层结构应用软件的模型如图 3.3 所示。
图 3.3 中可以看出,三层结构应用软件的特点是用户界面与应用逻辑位于不同的平台上,
并且应用逻辑被所有用户共享。由于用户界面和应用逻辑位于不同的平台上,所以系统应提
供用户界面与应用逻辑之间的连接,两者之间的通信协议是由系统自行定义的。
应用逻辑被所有用户共享是两层结构应用软件与三层应用软件之间最大的区别。中间层
即应用服务器是整个系统的核心,它必须具有处理系统的具体应用的能力,并提供事务处理、
安全控制以及满足不同数量客户机的请求而进行性能调整的能力。应用服务器软件可以根据
应用逻辑的不同被划分为不同的模块,从而使客户机方应用程序在需要某种应用服务时只与
应用服务器上处理这个应用逻辑的模块通信,并且一个模块能够同时响应多个客户机方应用
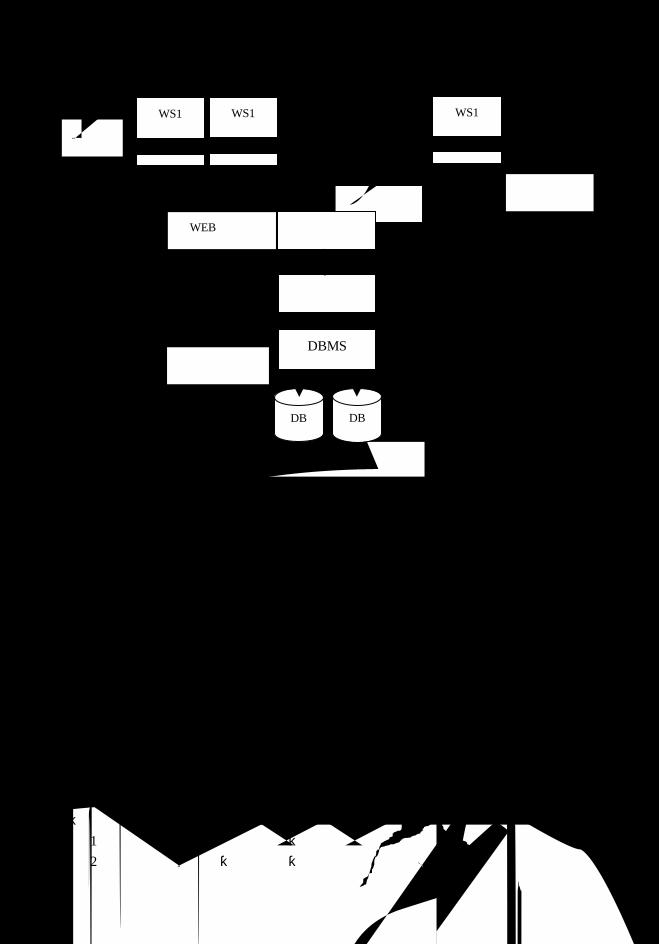
第 3 章 数据库设计基础 - 49-
程序的请求。
使用三层结构应用软件开发系统的优点是非常明显的,主要有以下几点。
(1)整个系统被分为不同的逻辑块,层次非常清晰。
(2)能够使“肥客户机”变成“瘦客户机”。
(3)开发和管理的工作向服务器方转移,使得分布数据处理成为可能。
(4)管理和维护变得相对简单。
另外,引进三层结构体系,客户机便可省去与数据库系统直接互动的麻烦。客户机直接
调用服务器上的应用逻辑,应用逻辑则代表客户机对数据库进行存取,这样就可减少向服务
器发出的 SQL 查询和更新要求,使性能比两层结构更优。此外,由于客户机不直接连接数据
库系统,而服务器能够实现更细致的授权定义,因此,三层结构能加强整个系统的安全。
3.3.4 浏览器/服务器(B/S)结构
1.客户/服务器结构面临的问题
近几年来,国内许多按照客户/服务器结构建设的机关办公信息系统,力图改善其管理水
平和办公效率,但往往事倍功半、收效甚微,无法满足用户要求及机关单位的开发环境要求,
原因是客户/服务器结构下的信息系统有一些方面尚不够完善,不能适应不断增长的多方面需
求,主要表现在如下几个方面。
(1)开放性不够,封闭式单项系统,不同系统之间无法交流。
(2)用户界面风格不一,使用繁杂,不利于推广。
图 3.3 三层 C/S 结构
自定义协议
WS1
应用逻辑
接 口
DBMS
网络电缆
客户机
WEB 服务器
数据库服务器
WS1 WS1
DB DB
⋯⋯

- 50 - 电子政务数据库基础
(3)系统开发、维护和移植困难,升级麻烦。
(4)重复投资严重,无法包容已有系统,造成重复投资。
(5)扩展性差,不能接纳新技术。
(6)缺乏系统性和具有前瞻性的结构框架。
2.基于 Internet/Intranet 的浏览器/服务器(B/S)结构的产生
进入 20 世纪 90 年代,数字信号处理技术、网络通信技术、多媒体技术和产业发展逐渐
成熟并汇合,奠定了智能联网的技术基础, Internet 技术掀起了全球信息产业的一场深刻革
命,它不仅改变了人们的生活方式,改变了人们的商业行为,而且改变了人们的办公方式。
Internet 已经步入政府机关而成为 Intranet。
Intranet 在各个技术领域都为政府内部的应用创造了条件,它具有下述特点。
(1)安全性强:Intranet 可以理解为防火墙后面的政府部门内部 Internet。从安全性方面
考虑,Intranet 是在政府部门内部,它和 Internet 之间有一道防火墙,保证企业的信息不受外
界攻击,同时又不是与外界隔绝的。通过防火墙可以在政府部门内部对信息进行严格控制,
保证信息在有控制、有监视的状态下,被适当的人使用。
(2)Web 技术的应用:Intranet 很重要的一个技术就是 Web 技术。Web 技术在政府办公
和业务处理中的应用使得政府信息系统的开发、维护、升级产生了一个飞跃性、根本性的变
化。
(3)管理信息的“集中器”:Hub 是一个把物理设备、网卡连接在一起的“集中器”。而
Intranet 实际上是个政府内部管理信息的 Hub,是在更高层次上的一种集中器。它把信息集中
管理起来,让大家能够在适当的时候得到适当的信息。
Intranet 独创性地将客户/服务器结构扩展为浏览器/服务器结构,以不变应万变。基于
Intranet 的浏览器/服务器结构的发展为信息系统开发人员提供了一个新的框架结构,使它们
能很快地把注意力从用户界面等细节问题转移到更核心的问题上去,不管开发的是哪种应用
程序、哪种平台,在浏览器上都能使用。通过 Internet,信息系统的维护、培训、分销变得很
容易,软件版本的升级更新也无需牵扯到用户,只需将服务器端的软件更新,所有用户就都
能自动更新应用。
基于 Internet/Intranet 的浏览器/服务器结构从本质上讲,与传统的 C/S 结构都是用一种请
求和应答方式来执行应用的。但传统的 C/S 结构模式在客户端集中了大量应用软件,而 B/S
是一种基于 Hyperlink(超链接)、HTML(超文本标记语言)、Java 的三层或多层 C/S 结构,
客户端仅需要单一的浏览器软件,是一种全新的体系结构。它解决了跨平台问题,通过浏览
器可访问几个应用平台,形成一种一点对几点、多点对多点的结构模式。早期的 B/S 系统也
是两层,Web 服务器只是简单地接受 Web 浏览器通过 HTTP 提交的请求,进行所需要的处理,
并且以 HTML 格式化的文档作为响应。浏览器上见到的是静态的 HTML 页面。
随着应用的扩大和技术的发展,两层的 B/S 结构自然延伸为三层的浏览器/Web 服务器/
数据库服务器模式,或多层的结构模式。浏览器/Web 服务器、数据库服务器的三层体系结构
如图 3.4 所示。
第 3 章 数据库设计基础 - 51-
图 3.4 浏览器/Web 服务器、数据库服务器的三层体系结构示意图
在三层模式结构中,表示层存在于客户端(Client),只需安装一个浏览器软件,客户端
的工作很简单,负担很轻。Web 服务器既作为一个浏览服务器,又是应用服务器。应用逻辑
层存在于这个中间服务器中,可以把整个应用逻辑和商业规则驻留其上,而且支持多种DBMS
和数据结构。Web 服务器的主要功能是:作为一个 HTTP 服务器,处理 HTTP 协议,接受请
求并按照 HTTP 格式生成响应;执行服务器端脚本(如 VBScript、JavaScript 等);对于数据
库应用,能够创建、读、修改、删除(CRUD)视图实例。Web 服务器通过对象中间件技术
(Java、DCOM、CORBA 等),在网络上寻找对象应用程序,完成对象间的通信。数据层存
在于数据库服务器上,安装有 DBMS,提供 SQL 查询、数据库管理等服务。Web 服务器与
数据库服务器的接口方式有 ODBC、ADO、OLE/DB、JDBC、Native Call 等。与传统的 C/S
结构相比,B/S 结构有许多优点如下。
(1)B/S 是一种瘦客户机模式,客户端软件仅需安装浏览器,应用界面单一,客户端硬
件配置要求较低,可由相对价廉的 NC(网络计算机)替代。
(2)B/S 具有统一的浏览器客户端软件,易于管理和维护。在 C/S 模式中,操作人员必
须熟悉不同的界面,为此需要多操作员进行大量培训,而在 B/S 中,因客户端浏览器的人机
界面风格单一,系统的开发和维护工作变得简单易行,有利于提高效率。不仅节省了开发,
减少了维护客户端软件的时间和精力,而且方便了用户的使用。客户端的数量几乎不受限制,
具有极大的可扩展性。
(3)无须开发客户端软件,浏览器软件容易从网上下载或升级。
(4)B/S 应用的开发效率高,开发周期短,见效快。对于开发人员的技术要求低,其版
本更新只需集中维护放在服务器端的代码即可。
(5)平台无关性。B/S 系统具有极强的伸缩性,可以透明地跨越异质网络、计算机平台,
无缝地联合使用数据库、超文本、多媒体等多种形式的信息;可以选择不同的厂家提供的设
备和服务。
(6)开放性。B/S 系统采用公开的标准和协议,系统资源的冗余度小,可扩充性良好。
3.浏览器/服务器结构的工作方式
采用浏览器/服务器结构的系统有 3 种工作方式。
(1)简单式。即基于浏览器的浏览器/服务器模式,利用 HTML 页面在用户的计算机上
表示信息。在静态页面中,Web 浏览器需要一个 HTML 页时,提交一个 URL 地址到 Web
服务器。Web 服务器从 Internet 上检索到所需要的本地或远程的网页,并将所需网页返回到
Web 浏览器上。Web 浏览器显示由 HTML 写成的文档、图片、声音和图像,而 Web 服务器
则是将 Web 页发送至浏览器的具有特殊目的的文件服务器。浏览器打开一个和服务器的连
接,服务器返回页面结果并关闭连接。有时也可以使用 Java Applet(Java 小应用程序)、ActiveX
和 Java Bean(Java 豆)来加强表达能力。通常,Applet 给网页带来了动态特性,可将其和静
数据请求
检索的数据
HTTP 请求
响应 用户浏览器 Web 服务器 数据库服务器

- 52 - 电子政务数据库基础
态页面放置在同一个应用中。
(2)交互式。在这种方式中,浏览器显示的不只是静态的服务器端传送来的页面信息。
在打开与服务器的连接及传输数据以前,HTML 页面显示供用户输入的表单、文本域、按钮,
通过这些内容与用户交互。HTTP 服务器将用户输入信息传递给客户服务器程序或脚本进行
处理,Web 服务器再从 DBMS 服务器中检索数据,然后把结果组成新页面返回给浏览器,最
后中断浏览器和服务器的本次连接。这个模型允许用户从各种后端服务器中请求信息。通过
使用 HTTP 作为中间件,通过调用 CGI 服务器程序和脚本,该模型支持简单的客户/服务器
通信方式。由于每一个浏览器和服务器间的通信都要建立一个连接,因此相对于服务器资源
而言,这种模型造价昂贵。Web 服务器就像检索一个普通的 HTML 页一样,将检索到的内容
返回到浏览器中并显示出来。在用户填完并提交输入表单后,就返回到服务器中执行 CGI 程
序。一个典型的 CGI 程序把从表单中取出的键入值汇入文件,或组成一个包含键入值的 E-mail
信息,再将它发送出去。从被访问的数据来看,该模型所访问的数据往往是只读的,如帮助
文件、文档、用户信息等。这些非核心数据一般没有处理能力,它们总是处在低访问率上。
这种模型已是一个三层结构了,浏览器通过中间层软件 CGI 间接操作 Server 程序,CGI 与服
务器端的数据库互相沟通,再将查询结果传送至客户端,而不是一味地将服务器端的资料全
部接受过来。
(3)分布式。这种模型将机构中目前已有的设施与分布式数据源结合起来,最终会代替
真正开放的客户/服务器应用程序。它无需下载 HTML 页面,客户程序是由可下载的 Java 编
写的,并可以在任何支持 Java 的浏览器(目前流行的 IE 或 Navigator)上执行 Applet。当 HTTP
服务器将含有 Java Applet 的页面下载到浏览器时,Applet 在浏览器端运行并通过构件
(Component)支持的通信协议(IIOP,DCOM)与传输服务器上的小服务程序(Servlet)通
信会话。这些小程序按构件的概念撰写,它收到信息后,经过 JDBC、ODBC 或本地方法向
数据库服务器发出请求,数据库服务器接到命令后,再将结果传送给 Serlet,最后将结果送
至浏览器显示出来。
4.浏览器/服务器系统的实施方案
目前,在浏览器上发布信息常用的文件格式有两种:HTML 文件和 Java Applet 类。
(1)HTML 文件只能发布超文本格式的信息。HTML 是 Web 上的第一个标记语言,用
于编制 Web 网页。在其基础上发展出了功能更为强大的 DHTML(动态标记语言)和 XML
(可扩展标记语言)。尤其是 XML 具有许多优点,如提供了表达数据库视图的标准方法,明
确区分了结构、内容和实例化,能够对文档进行有效性检查,允许各行业定制自己的专用 XML
等。因此,有人认为 XML 是从关系模型以来对数据库应用的最重要的发展。
(2)Java Applet 类嵌入在 HTML 文件中,可发布图形信息。HTML 文件和 Java Applet
类文件与数据库相联系的方法基本相同,都可以通过 CGI 方式、API 方式、ODBC 方式来发
布数据库中的数据。另外,在 Java Applet 中,还可以通过 JDBC 方式来与数据库建立联系。
下面以 Microsoft 的解决方案为例来说明浏览器/服务器系统的实现方法。
浏览器/服务器系统的 Microsoft 解决方案为:在客户端配置 Windows 95/98 或 Windows
2000 操作系统(或以上版本),Internet Explorer 4.0 以上浏览器。在 Web 服务器端配置 Windows
Server 2000 操作系统,Internet Information Server 4.0,Active Server Page。在数据库服务器端

第 3 章 数据库设计基础 - 53-
配置 Windows Server 2000 和 SQL Server 2000。
Web 服务器的构成中 ASP 可以配合使用 JavaScript、VBScript、Perl、ActiveX 等代码。
定制的应用程序可用 Java 或 C++编写。
数据库服务器可以选择 Oracle、Sybase、MS SQL Server、DB2 等 DBMS,用于存放和管
理政府部门共享数据。
3.3.5 电子政务数据库应用系统的实现技术
随着 Web 数据库系统的不断应用和发展,数据库系统的实现技术也日益重要。电子政务
数据库系统实现技术至少包括两项技术:数据库性能优化技术和数据库互联技术。
1.数据库性能优化技术��SQL 语言
SQL 语言又称结构化查询语言,是专门为数据库而建立的操作命令集,是一种功能齐全
的数据库语言。在使用 SQL 时,只需要发出“做什么”的命令,而“怎么做”则无需使用者
考虑。SQL 的功能强大、简单易学、使用方便,已经成为数据库操作的基础。目前,国际上
所有关系数据库管理系统都采用 SQL 语言,包括 DB2 以及 Oracle、SQL Server、Sybase、
Informix 等大型数据库管理系统。 SQL 不仅包括查询功能,还涉及到数据定义、数据操作和数据控制等 3 个方面功能。其
中,SQL 的数据定义功能是指对基表以及视图进行定义;SQL 的数据操纵功能是指在基表上
的查询、删除、插入、修改等功能;SQL 的数据控制功能是指基于基表上的完整性、安全性
及并发控制功能。 SQL 语言有两种使用方式:一种是联机交互方式,在该方式下,SQL 可以独立使用(称
为自含式语言);另一种是嵌入式方式,在这种方式下,以某些高级程序设计语言(如 COBOL、
C 等)为宿主语言,而将 SQL 嵌入其中依附于宿主语言(称为嵌入式语言)。不管采用哪种
使用方式,SQL 语言的基本语法结构都不变,只是在嵌入式结构中增加若干语句以建立宿主
语言与 SQL 之间的联系。关于 SQL 后面有专门的章节介绍。
2.Web 数据库访问技术
在 Internet 中,Web 用户和发布 Web 的服务器通过 HTTP 协议建立联系。Web 用户向服
务器发送一个包含 URL 题头字段和其他用户数据的 HTTP 请求,而服务器则返回包含请求
内容的 HTTP 响应。 Web 服务器与数据库服务器之间的通信通常有两种解决方案:一种是 Web 服务器端提供
中间件连接 Web 服务器与数据库服务器;另一种是把应用程序下载到客户端直接访问数据
库。后一种方法在程序的编写、调试上较为烦琐,网络安全也难以保证。相比较而言,中间
件技术更具有优势,而且代表着一种发展方向。 中间件负责管理 Web 服务器和数据库之间的通信并提供相应服务,它可以依据 Web 服
务器提出的请求对数据库进行操作,把结果以超文本的形式输出,然后由 Web 服务器将此页
面返回到 Web 浏览器、从而把数据库信息提供给用户。这里简单介绍以下几种部分访问技术。 (1)CGI。CGI 即公共网关接口,是最早实现与数据库接口的方法之一,它规定了浏览
器、Web 服务器、数据库服务器和外部应用程序之间数据交换的标准接口。CGI 程序设计可

- 54 - 电子政务数据库基础
以使用诸如 C++、Visual Basic 等流行编程语言,除程序设计的输入/输出部分外,CGI 程序
的设计与一般的程序设计一样,因此采用 CGI 是实现互联网用户与 Web 服务器信息交互的
一种快速简洁的方案。
基于 CGI 接口应用较简单、灵活,开发工具丰富,功能范围广,技术也相对成熟,但是
用它编程比较复杂,程序的编译、连接是与某个具体的数据库管理系统相联系的。也就是说,
平台无关性差,尤其对功能强大的网络数据库的应用,显得有些力不从心。
(2)Web API。Web 服务器提供商为扩展其服务器的性能,都各自开发 API 应用程序接
口来取代 CGI。目前最流行的两种 API 分别是 ISAPI(Internet Server Application Program
Interface)和 NSAPI(Netscape Server Application Program Interface)。这两种接口技术可以用
标准方式编写与 Web 服务器交互的应用程序。现在 Netscape 宣布其 NSAPI 也支持 ISAPI 标
准,则意味着只有一种 Web API 标准了。
API 由于是由各厂商与各自的服务器绑定而各自开发的,所以兼容性较差,仅适用于
Windows 系统,其次其交互性差且开发难度大,使开发人员望而却步。
(3)ASP。由于 Web API 开发的难度大,于是微软推出 ASP 技术。它的出现是动态交互
式 Web 网站的创建变得轻松容易起来,只需要几行脚本语言,就能将后台数据库信息发布到
WWW 网站上去,在变成和网页脚本的可读性方面大大优于传统接口技术。
ASP 是一个服务器端的命令执行环境,它完全摆脱了 CGI 的局限性,使用户可以轻松使
用 HTML、脚本语言和 ActiveX 组件创建可靠的、功能强大的、与平台无关的 Web 应用系统。
它不但可以进行复杂的数据库操作,而且生成的页面具有很强的交互性,允许用户方便地控
制和管理数据。
(4)JSP。JSP(Java Server pages)是有 Sun Microsystem 公司于 1999 年 6 月推出的新技
术,是基于 Java Servlet 以及整个 Java 体系的 Web 开发技术,是由 Sun Microsytem 公司倡导
的,许多公司参与建立的一种动态网页访问技术标准。利用这一技术可以建立先进、安全和
跨平台的动态网站。
在传统的网页 HTML 文件中加入 Java 程序片段(Scriptlet)和 JSP 标记,就构成了 JSP
网页。Web 服务器在遇到访问 JSP 网页的请求时,首先执行其中的程序片断,然后将执行结
果以 HTML 格式返回给客户。程序片段可以操作数据库等相关功能。所有程序操作都在服务
器端执行,网络上传送给客户端的仅是得到的结果,对客户浏览器的要求很低,可以实现无
Plugin、无 ActiveX、无 Java Applet,甚至无 Frame。
总的说来,JSP 和微软的 ASP 在技术方面有许多相似之处。两者都是为基于 Web 应用服
务实现动态交互网页制作提供的技术环境支持,两者都能够为为程序开发人员提供实现应用
程序的编制与自带组件设计网页从逻辑上分离的技术,而且两者都能够替代 CGI 使网站建设
与发展变得较为简单和快捷。当然它们也存在不同之处,其中最本质的区别在于:两者是来
源于不同的技术规范组织,其实现的基础是 Web 服务器平台要求不相同。ASP 是基于
Windows 平台的技术,而 Java 和 JSP 是跨平台的。在设计电子政务数据库应用系统时,往往
需要根据实际的应用规模、已有的软硬件投资和将来可能的发展等多种因素来综合考虑。

第 3 章 数据库设计基础 - 55-
3.4 本 章 小 结
电子政务数据库设计的一个基本问题是如何建立一个好的数据库模式,也就是给出一组
数据,如何构造一个适合于它们的数据模式,使数据库系统无论是在数据存储方面,还是在
数据操作方面都有较好的性能。本章在讨论了函数依赖的概念的基础之上,重点介绍了根据
关系中属性之间的函数依赖关系对关系模式进行规范化的规范化理论,并讨论了在实际过程
中如何进行数据库设计,最后结合电子政务系统的特点,介绍了电子政务数据库应用系统的
两种体系结构 C/S 和 B/S 及相应的实现技术。
3.5 本 章 习 题
1.解释下列术语:函数依赖,部分函数依赖,传递函数依赖,多值函数依赖。
2.试举出具有多值函数依赖关系的例子。
3.什么是范式?它有哪些类型?这些范式之间的关系是什么?
4.在实际进行关系模式规范化时应注意哪些?
5.试分析电子政务数据库应用系统采用 C/S 或 B/S 体系结构的原因。
6.数据库应用系统的实现技术有哪些?各有何特点?
7.将第 2 章第 8 题的 E-R 模型转换成关系模式,并对其进行规范化,使每一个关系都
为 3NF。
3.6 本章参考文献
1.张龙祥,黄正瑞,龙军·数据库原理与设计·人民邮电出版社,2002 年 7 月
2.王鹏,董群·数据库技术及其应用·人民邮电出版社,2000 年 8 月
3.苏新宁,吴鹏,朱晓峰等·电子政务技术·国防工业出版社,2003 年 1 月
4.庄成三,洪玫,杨秋挥·数据库系统原理及其应用·电子工业出版社,2000 年 6 月
5.陈佳·信息系统开发方法教程·清华大学出版社,1998 年 5 月
6.胡晓惠,陈欣,周莺·电子政务实用技术读本·电子工业出版社,2002 年 11 月
7.钱毅·政务数据库系统·人民大学出版社,2004 年 2 月
8.张健沛·数据库原理及应用系统开发·中国水利水电出版社,1999 年 4 月
9.孙正兴,戚鲁·电子政务原理与技术·人民邮电出版社,2003 年 4 月
10.王曰芬,丁晟春·电子商务网站设计与管理·北京大学出版社,2002 年 1 月
第 4 章 SQL
结构化查询语言(Structured Query Language,SQL)是一种介于关系代数与关系演算之
间的语言,是一个通用的功能极强的关系数据库标准语言。目前,SQL 已被确定为关系数据
库系统的国际标准,被绝大多数商品化关系数据库系统采用。SQL 是非过程化语言,在 SQL
中,不需要告诉 SQL 如何访问数据库,只要告诉 SQL 需要数据库做什么。SQL 的影响现已
超出了数据库领域,在人工智能、软件工程等领域的产品中也开始采用 SQL 作为数据、图形
及其他对象的检索工具。
本章主要内容:
� SQL 概述
� SQL 中的数据定义语言
� SQL 中的数据查询语言
� SQL 中的数据操纵语言
� SQL 中的数据控制语言
� 数据库应用系统的结构
� 数据库应用开发工具
4.1 SQL 概 述
4.1.1 SQL 的发展及主要特点
1.SQL 的发展
SQL 是一种操纵数据库的结构查询语言,SQL 是 1974 年由 Chamberlin 和 Boyce 提出的,
由于它功能丰富、使用方式灵活、语言简洁易学等突出优点,在计算机工业界和计算机用户
中倍受欢迎。1986 年 10 月,美国国家标准局(ANSI)的数据库委员会批准了将 SQL 作为关
系数据库语言的美国标准。1987 年 6 月国际标准化组织(ISO)将其采纳为国际标准。这个
标准也称为 SQL86。随着 SQL 标准化工作的不断修订完善,相继出现了 SQL89、SQL92(也
称为 SQL2),现在,以增加面向对象功能为主要特征的新标准 SQL3 也在起草过程中。当前
流行的关系数据库管理系统,如:Oracle、SQL Server、Sybase、FoxPro 以及 Microsoft Access
等都支持 SQL,可以说学好 SQL 是学习关系型数据库的重要基础。SQL 成为国际标准后,
对数据库以外的领域也产生很大影响,不少软件产品将 SQL 的数据查询功能与图形功能、软
件工程工具、软件开发工具、人工智能程序等结合起来。

第 4 章 SQL - 57 -
2.SQL 的主要特点
(1)非过程化语言。SQL 是一个非过程化的语言,因为它一次处理一个记录,对数据提
供自动导航。SQL 允许用户在高层的数据结构上工作,而不对单个记录进行操作,可操作记
录集。所有 SQL 的语句接受集合作为输入,返回集合作为输出。SQL 的集合特性允许一条
SQL 语句的结果作为另一条 SQL 语句的输入。SQL 不要求用户指定对数据的存放方法。这
种特性使用户更易集中精力于要得到的结果。所有 SQL 语句均使用查询优化器,它是 RDBMS
的一部分,由它决定对指定数据存取的最快速度的手段。查询优化器知道存在什么索引,哪
儿使用合适,而用户从不需要知道表是否有索引,表有什么类型的索引。
(2)统一的语言。SQL 可用于所有用户的 DB 活动模型,包括系统管理员、数据库管理
员、应用程序员、决策支持系统人员及许多其他类型的终端用户。SQL 为许多任务提供了命
令,包括:查询数据;在表中插入、修改和删除记录;建立、修改和删除数据对象;控制对
数据和数据对象的存取;保证数据库一致性和完整性。以前的数据库管理系统为上述各类操
作提供单独的语言,而 SQL 将全部任务统一在一种语言中。
(3)是关系数据库的公共语言。由于所有主要的关系数据库管理系统都支持 SQL 语言,
用户可将使用 SQL 的技能从一个关系数据库管理系统(RDBMS)转到另一个。用 SQL 编写
的程序是可以移植的。
(4)是一种面向集合的语言。每一个 SQL 命令的操作对象是一个或多个关系,操作的结
果也是一个新关系,这使 SQL 语言结构简练且使用灵活。
4.1.2 SQL 支持的数据库体系结构
SQL 支持的关系数据库的体系结构是三级逻辑结构,如图 4.1 所示。
-----------------------------------------------------------------------------------------------------------
外模式
----------------------------------------------------------------------------------------------------------
模式
-----------------------------------------------------------------------------------------------------------
存储模式
图 4.1 SQL 语言支持的数据库体系结构
在 SQL 中,外模式对应于视图,模式对应于基本表,存储模式对应于存储文件。基本表
SQL 用户 1 SQL 用户 2 SQL 用户 3 SQL 用户 4
视图 1 视图 2
基本表 1 基本表 3 基本表 2 基本表 4
存储文件 1 存储文件 2 存储文件 3 存储文件 4

- 58 - 电子政务数据库基础
是实际存储在数据库中的表,每一个表在存储中可用一个存储文件来表示(一个基本表就是
一个关系),它不是由其他表导出的表。视图不是直接存在于物理存储器上的表,而是从基本
表或其他视图中导出的表,它本身不独立存储在数据库中,也就是说数据库中只存放视图的
定义而不存放视图的数据,这些数据仍存放在导出视图的基本表中,因此视图是一个虚表。
每个基本表用一个存储文件来表示,一个表可以带若干索引,索引也存放在存储文件中。每
个存储文件与外部存储器上一个物理文件对应。存储文件的逻辑结构组成了关系数据库的存
储模式也称为内模式。
SQL 支持的数据库体系结构具有如下特征。
(1)一个 SQL 模式是表和约束的集合。一个表是行的集合,每行是列的序列,每列对应
一个数据项。一个表可以是一个基本表,也可以是一个视图。
(2)用户可以用 SQL 语句对视图和基本表进行查询等操作。用户所看到的可以是基本
表,可以是视图,也可以是基本表+视图。在用户看来,视图和基本表是一样的,都是关系,
即二维表。
(3)SQL 用户可以是应用程序,也可以是终端用户。SQL 语句可嵌入在宿主语言的程序
中使用,宿主语言有 FORTRAN、COBOL、PASCAL、PL/I、C 和 Ada 等语言;SQL 也能
作为独立的用户接口,供交互环境下的终端用户使用。
4.1.3 SQL 的组成
SQL 集定义、查询、操作、与控制等功能于一体,主要分为 4 个部分:数据查询语言(Data
Query Language,DQL)、数据定义语言(Data Definition Language,DDL)、数据操纵语言(Data
Manipulation Language,DML)、及数据控制语言(Data Control Language,DCL)。
(1)DQL。这一部分也称为 SQL DQL,用于对已经存在的基本表(即关系)及视图(虚
表)进行数据检索。
(2)DDL。这一部分也称为 SQL DDL,用于定义 SQL 模式、基本表、视图和索引等。
(3)DML。这一部分也称为 SQL DML。DML 分成数据查询和数据更新两类。其中数据
更新又分成插入、删除和修改三种操作。
(4)DCL。这一部分也称为 SQL DCL。DCL 包括对基本表和视图的授权、完整性规则
的描述、事务控制语句等。
4.2 SQL 中的数据定义语言
SQL 的数据定义语言(SQL DDL)包括对基本表(关系)、视图(View)、索引(Index)、
等数据库对象的创建和撤销操作。
4.2.1 基本数据类型
不同数据库管理系统中的 SQL 支持的数据类型稍有区别,但一般都支持数值型、字符串

第 4 章 SQL - 59 -
型、位串型、时间型等基本数据类型。:
(1)数值型
① INTEGER(INT) 长整数,字长为 32 位
② SMALLINT 短整数,字长为 16 位
③ DOUBLE PRECISION 双精度浮点数,字长为 64 位
④ FLOAT(n) 浮点数,精度至少为 n 位数字
⑤ NUMERIC(p,d) 定点数,由 p 位数字组成,其中小数位数为 d,也可写
DECIMAL(P,d)或 DEC(P,d)。
(2)字符串型
① CHAR(n) 长度为 n 个西文字符的定长字符串
② VARCHAR(n) 具有最大长度为 n 个西文字符的变长字符串
(3)位串型
① BIT(n) 长度为 n 个西文字符的二进制位串
② BIT VARYING(n) 最大长度为 n 个西文字符的变长二进制位串
(4)时间型
① DATE 日期,包含年、月、日,格式为:YYYY-MM-DD
② TIME 时间,包含时、分、秒,格式为:HH:MM:SS
③ TIMESTAMP 日期时间
4.2.2 基本表的创建、修改和撤销
基本表即关系模式,是关系数据库的基本组成单位,它物理地存储于数据库的存储文件
中,定义一个基本表相当于建立一个新的关系模式,系统将基本表的数据描述存入数据字典
中,供系统或用户查阅。
1.基本表的创建
SQL 使用 CREATE TABLE 语句创建基本表,其一般格式如下:
CREATE TABLE <表名> (<列名> <数据类型> [(<列宽度>)][<列级完整性约束条件
>] [,<列名> <数据类型> [<列宽度>] [<列级完整性约束条件>]]�[,<表级完整性约束条件>]) 其中,列宽度仅用于某些数据类型中,表中可以包括如下的约束。
(1)NULL 或 NOT NULL。NOT NULL 意味着在每一行中该列必须有一个值,而 NULL则是在给定的行中该列可以为空值。
(2)UNIQUE。在该列中,没有两行有相同的值。 (3)PRIMARY KEY。指定该列为主键(Primary Key)列,主键的值是惟一的,一个关
系仅能有一个主键。 (4)CHECK。当该列中的数据被更新或插入时,允许检查一个条件。例如 CHECK(Score
≥0)。 在该列接受一个值之前,将触发系统检查 Score 列是否大于等于 0。有时作为
CONSTRAINT 语句来执行:

- 60 - 电子政务数据库基础
(5)DEFAULT。当插入一行时没有插入该列数据,则将该缺省值插入数据库中。
(6)FOREIGN KEY。外键(Foreign Key)作用类似于主键,外键不是本关系的键,而
是引用其他关系或本关系的键。引用格式为: REFERENCES <TABLE NAME> (<COLUMN
NAME>)。为说明 SQL 的功能,现给出几个关于公务员信息的基本表,如表 4-1(staff)、表
4-2(salary)和表 4-3(rank)所示。
表 4-1 公务员基本情况表
bh xm xb bmdh jzdh xl nl csrq 00011 王明 男 01 C 大学本科 32 1972 年 3 月 1 日 00051 李彬 男 02 D 大学本科 28 1976 年 2 月 11 日 00006 赵华 女 03 B 研究生 46 1958 年 10 月 25 日 00031 张伟 男 01 A 博士研究生 45 1959 年 3 月 16 日 00009 陈淑萍 女 04 E 大学本科 24 1980 年 10 月 13 日 00076 路红 女 02 B 大学本科 38 1966 年 2 月 12 日 00023 王海龙 男 04 C 34 1970 年 4 月 2 日 00098 刘莉 女 02 D 大学本科 26 1978 年 3 月 6 日 00019 王婷 女 01 B 研究生 37 1967 年 4 月 12 日
表 4-2 公务员工资表
Bh jbgz gwjt jwjt Zfbt zfgjj sdf grsds sfgz 00051 432 146 210 100 120 20 00076 698 320 360 40 206 42 00011 487 198 298 32 190 34 00019 675 300 360 38 206 28 00031 689 320 430 56 242 54
表 4-3 级职表
jzdh jz A 处级 B 副处级 C 科级 D 副科级 E 科员
例 4.1 建立包含完整性定义的公务员基本情况表 4-1 所示,表名为 Staff。
CREATE TABLE Staff(bh CHAR(5)NOT NULL,
xm CHAR(8)NOT NULL,
xb CHAR(2)DEFAULT’男’,
bmdh CHAR(2),
jzdh CHAR(1),
xl CHAR(10),
nl SMALLINT,
csrq DATE,
PRIMARY KEY(bh))

第 4 章 SQL - 61 -
这里定义的关系 Staff 有 8 个属性,分别是编号 bh、姓名 xm、性别 xb、部门代号 bmdh、
级职代号 jzdh、学历 xl、年龄 nl、出生日期 csrq。前 6 个属性均为字符型,长度分别是 5、8、
2、2、1 和 10 个字符,第 7 个属性 nl 为短整型,第 8 个属性 csrq 为日期型,宽度由系统指
定。主键是编号 bh。在 SQL 中允许属性值为空值,当规定某一属性值不能为空值时,就要
在定义该属性时写上保留字 NOT NULL。本例中,规定编号、姓名和出生日期不能取空值。
由于已规定编号为主键,所以对属性 bh 的定义中的 NOT NULL 可以省略不写。定义中还使
用了 DEFAULT 子句,指出 xb 的默认值为“男”。
例 4.2 建立包括完整性定义的基本表 4-2 所示,表名为 Salary。
CREATE TABLE Salary(bh CHAR(5) NOT NULL,
jbgz NUMERIC(7,2)NOT NULL,
gwjt NUMERIC(7,2),
jwjt NUMERIC(7,2),
zfbt NUMERIC(7,2),
zfgjj NUMERIC(7,2),
sdf NUMERIC(7,2),
grsds NUMERIC(7,2),
sfgz NUMERIC(7,2),
PRIMARY KEY(bh),
FOREIGN KEY(bh)REFERENCES staff(bh)on DELETE CASCADE,
CONSTRAINT jbgz_chk CHECK(jbgz>0));
基本表 gz 定义了 9 个属性,编号(bh)、基本工资(jbgz)、岗位津贴(gwjt)、职务津贴
(jwjt)、住房补贴(zfbt)、住房公积金(zfgjj)、水电费(sdf),个人所得税(grsds),实发
工资(sfgz)。主键是(bh)。还定义了一个外键,并指出外键 bh 和基本表 Staff 中 bh 属性相
对应,此处对应的属性名恰好同名,实际上也可以不同名,只要指出其对应性即可。外键体
现了关系数据库的参照完整性。定义中还使用了一个检查子句,指出基本工资在 0~5000 之
间。
例 4.3 对于基本表 Rank 可以用下列语句创建。
CREATE TABLE Rank (jzdh CHAR(1) NOT NULL,
Jz CHAR(6)NOT NULL,
PRIMARY KEY(jzdh))
2.基本表的修改
基本表建立后,可根据需要对基本表结构进行修改,如增加新的属性、修改列的宽度和
数据类型、增加列名、完整性约束及删除原有的属性等。在 SQL 中可以通过 ALTER TABLES
语句修改基本表。
(1)增加新的列
ALTER TABLE <表名>
ADD (<新列名> <数据类型> [<完整性约束>])
例 4.4 在基本表 Staff 中增加一个电话号码(Tele)列。

- 62 - 电子政务数据库基础
ALTER TABLE Staff
ADD (Tele CHAR(12))
例 4.5 在 Staff 表中增加一个完整性约束定义,使 bmdh 的取值在 01 到 12 之间。
ALTER TABLE Staff
ADD (CHECK)bmdh BETWEEN’01’AND’12’))
注意:新增加的列不能定义为 NOT NULL。基本表在增加一列后,原有元组在新增加的
列上的值都被定义为空值(NULL)。
(2)修改原有的列
ALTER TABLE <表名>(MODIFY (<列名> <数据类型>))
例 4.6 将表 Staff 中 bh 列加宽到 8 字符。
ALTER TABLE Staff
MODIFY (bh CHAR(8))
(3)删除完整性约束定义
ALTER TABLE <表名>
DROP <完整性约束名>
例 4.7 删除 Staff 表中的主键。
ALTER TABLE Staff
DROP PRIMARY KEY
例 4.8 在基本表 Staff 中删除 xl 属性,并且将引用该属性的所有视图和约束也一起删除,
可用下列语句。
ALTER TABLE Staff
DROP xl CASCADE
此处 CASCADE 方式表示,在基本表中删除某属性时,所有引用到该属性的视图和约束
也要一起自动地被删除。而 RESTRICT 方式表示在没有视图或约束引用该属性时,才能在基
本表中删除该属性,否则拒绝删除操作。
3.基本表的撤销
DROP TABLE <表名>
例 4.9 撤销 Staff 表。
DROP TABLE Staff
4.2.3 视图的创建和撤销
在 SQL 中,当创建一个视图时,系统把视图的定义存放在数据字典中,而并不存储视图
对应的数据,在用户使用视图时才去找对应的数据。创建视图主要有两个功能:一个功能可
简化查询命令,这是由于在定义视图时已经对数据做了一定范围的限定;另一个功能可限制
某些用户的查询范围,这个功能是通过对用户授权体现出来的,未经授权的用户不能访问任
何基本表或视图,在基本表上建立局部视图之后再将视图授权给用户,就可以避免暴露全部
基本表。

第 4 章 SQL - 63 -
1.视图的创建
SQL 用 CREATE VIEW 命令建立视图,其一般格式为:
CREATE VIEW <视图名> [(<列名>[,<列名>]⋯)]AS <子查询>
[WITH CHECK OPTION]
WITH CHECK OPTION 是可选择项,当要求通过视图更新或插入元组时,元组必须满足
视图定义条件时选用。
注意:子查询不允许含有 ORDER BY 子句和 DISTINCT 短语。
例 4.10 建立 Staff 表中有关男职工情况的视图 Staff_view。
CREATE VIEW Staff_view AS
SELECT bh,xm,xb
FROM Staff WHERE xb=’男’
WITH CHECK OPTION
本例中省略了视图 Staff_view 的列名,隐含了由子查询中 SELECT 子句中的 3 个列名组
成。
例 4.11 应用基本表 Staff、Salary 及 Rank 创建一个有关公务员工资的视图。
CREAT VIEW st_sa_r(bh,xm,jbgz,jwjt,jwjz)
AS SELECT staff.bh,xm,jbgz,jwjt,jz
FROM Staff,Salary,Rank
WHERE staff.bh=salary.bh AND staff.jzdh=rank.jzdh
本例中定义的视图 st_sa_r 是由 staff 表、 salary 表及 rank 表连接后的投影。由于 bh 是
staff 表和 salary 表的公共列,所以需指出视图的列名,视图列名可不同于查询块结果列名,
在该例中,将 jz 的列名改为了 jwjz。
例 4.12 创建一个按部门汇总基本工资的视图 b_sum。
CREATE VIEW b_sum(部门代号,部门工资汇总)
AS SELECT bmdh,sum(jbgz)
FROM staff,salary
WHERE staff.bh=salary.bh
Group by bmdh
本例说明,在创建视图的查询中可以用表达式及库函数,同时使用 GROUP BY 子句。
需要注意的是,执行 CREATE VIEW 语句的结果只是把视图定义存入数据库字典中,其中的
SELECT 语句并不执行,只有当用户对这个视图进行操作(如查询)时,数据库系统才会把这
个操作和视图定义中的 SELECT 语句合并在一起,形成一个修改的语句,再使用这个修改后
的语句对基本表进行操作。
2.视图的撤销
句法:DROP VIEW <视图名>
例 4.13 撤销 b_sum 视图,可用下列语句实现:
DROP VIEW b_sum
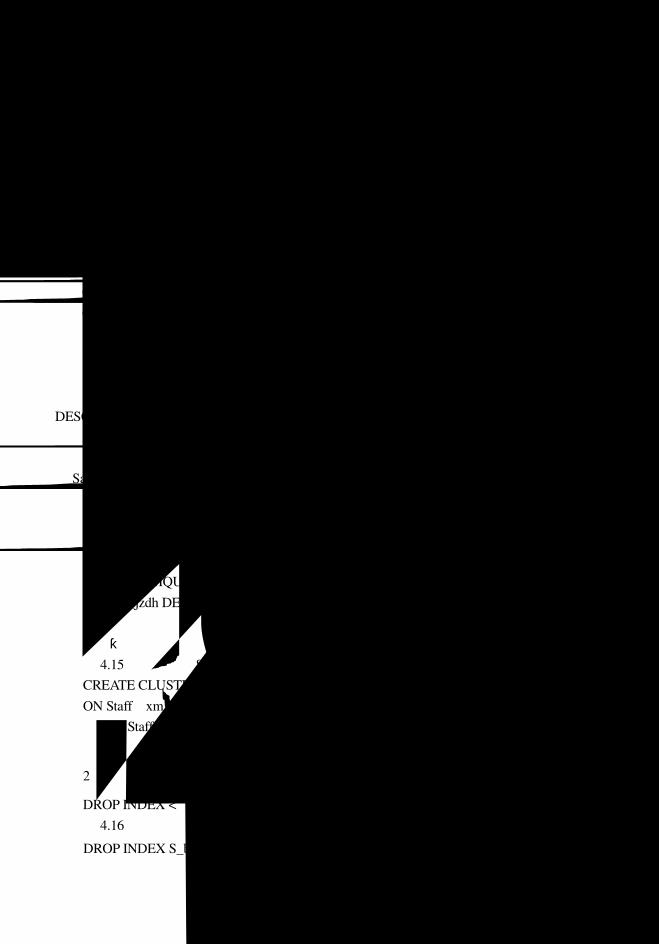
- 64 - 电子政务数据库基础
执行此语句后,视图 b_sum 将从数据库字典中删除,而与该视图有关的基本表中的数据
不会受任何影响。
4.2.4 索引的创建和撤销
为了提高数据的检索效率,可根据实际应用情况为一个基本表建立若干个索引,当表很
大时,索引查询可大大提高查询速度。索引属于物理存储的路径概念,而不是逻辑的概念。
在创建基本表时定义索引,就把数据库的物理结构和逻辑结构结合在一起了。
1.索引的创建
SQL 中,建立索引使用 CREATE INDEX 语句,其一般格式为:
CREATE [UNIQUE][CLUSTER] INDEX <索引名>
ON <表名>(<列名> [<次序>][,<列名> [<次序>]]�) 其中,UNIQUE 表明此索引的每一个索引值只对应惟一的数据记录,CLUSTER 表示要
建立的索引是聚簇索引,所谓聚簇索引是指索引项的顺序与表中记录的物理顺序一致的索引
组织。表名指定要建索引的基本表的名称。索引可以建在该表的一列或多列上,各列名之间
用逗号分隔。每个<列名>后面还可以用<次序>指定索引值的排列顺序,包括 ASC(升序)和
DESC(降序)两种,默认值为 ASC。UNIQUE 表示此索引的每一个索引值只对应惟一的数
据记录。 例 4.14 为 Staff、Salary 和 Rank3 个基本表建立索引。其中 Staff 表按 bmdh 升序建索引,
表 Salary 按 bh 升序和 jbgz 降序建惟一索引,Rank 表按 jzdh 降序建惟一索引。 CREATE INDEX S_bmdh ON Staff(bmdh); CREATE UNIQUE INDEX bh_jbgz ON Salary(bh ASC,jbgz DESC); CREATE UNIQUE INDEX s_jzdh ON rank(jzdh DESC)。 SQL 中的索引是非显式索引,也就是说在索引创建以后,用户在索引撤销前不会再用到
该索引名,但是索引在用户查询时会自动起作用。 例 4.15 为基本表 Staff 建立一个聚簇索引。 CREATE CLUSTER INDEX Staff_c ON Staff(xm)。 将会在 Staff 表的 xm(姓名)列上建立一个聚簇索引,而且 Staff 表中的记录将按照 xm
值的升序存放。
2.索引的撤销
DROP INDEX <索引名> 例 4.16 撤销索引 S_bmdh 和 bh_jbgz。 DROP INDEX S_bmdh,bh_jbgz。

第 4 章 SQL - 65 -
4.3 SQL 中的数据查询语言
SQL 中最常使用的是从表中获取数据,即查询。查询不改变数据本身,仅仅是检索数据,
是对已经存在的基本表及视图进行数据检索。
4.3.1 查询语句的一般格式及功能
查询的基本结构是 SELECT-FROM-WHERE 组成的查询块,其一般格式为:
SELECT [ALL|DISTINCT] <列表达式> [AS <新列名>] [,<列表达式> [AS <新列名
>]]FROM<表名或视图名> [,<表名或视图名>]
[WHERE <条件表达式>]
[GROUP BY<列名 1>[HAVING<条件表达式>]]
[ORDER BY<列名 2>[ASC|DESC]]
其中,列表达式部分包含了查询结果要显示的列名清单,列名之间用逗号分开。要选择
表中所有列名,可用∗代替。如果所选定的列名要更名,则需在该列名后用 AS <别名>实现;
FROM 子句用于指定一个或多个表或视图,如果所选的列名来自不同的表或视图,则列名前
应加表名前缀。WHERE 子句用于限制记录的选择,构造查询条件可使用 SQL 特有的运算符
构成表达式。GROUP BY 和 HAVING 子句用于分组和分组过滤处理。它能将指定列名中有
相同值的记录合并成一条记录,若选择 GROUP BY 进行记录分组,则可选择 HAVING 来显
示由 GROUP BY 子句分组的且满足 HAVING 子句条件的所有记录,HAVING 子句格式类似
于 WHERE 子句。ORDER BY 子句决定了查找出来的记录的排列顺序,在 ORDER BY 子句
中,可以指定一个或多个字段作为排序键,ASC 选项代表升序,DESC 代表降序。在 SELECT
语句中,SELECT 和 FROM 子句是必须的。可在 SELECT 子句内使用合计函数对记录进行操
作,它返回一组记录的单一值。例如,AVG 函数可以返回记录集的特定列中所有值的平均数。
4.3.2 单表查询
1.投影检索
例 4.17 查询 Staff 表中全体员工的 bh(编号)与 xm(姓名)。
SELECT bh AS 编号,xm AS 姓名
FROM Staff
例 4.18 查询 Staff 中全体员工的详细情况。
SELECT *
FROM Student
例 4.19 查询 Staff 中公务员的 bmdh。

- 66 - 电子政务数据库基础
SELECT DISTINCT bmdh
FROM staff
SELECT 子句后面的 DISTINCT 表示要在结果中去掉重复的部门代号 bmdh。
2.选择检索
例 4.20 查询部门代号为 01 的员工编号及姓名。
SELECT bh,xm
FROM staff
WHERE bmdh=’01’
例 4.21 查询 Staff 中姓李的员工姓名。
SELECT xm
FROM Staff
WHERE xm LIKE ’李%’。
在这个例子的条件表达式中,用到了字符串匹配操作符 LIKE。LIKE 谓词的一般形式是:
列名 LIKE 字符串常数
这里,列名的类型必须是字符串或可变字符串。在字符串常数中字符的含义如下。
(1)%(百分号):表示可以与任意长度(可以为零)的字符串匹配。
(2)_(下划线):表示可以与任意单个字符匹配。所有其他的字符只代表自己。
例 4.22 查询缺少 xl(学历)的员工编号及姓名。
SELECT bh,xm from staff where xl is NULL
涉及空值的一般语句形式为:
IS NULL 或 IS NOT NULL
3.排序检索
例 4.23 检索 salary 表中基本工资在 500~600 元间的员工 bh(编号)和姓名,结果按 bh
升序排序。
SELECT bh,xm FROM salary
WHERE jbgz BETWEEN 500 AND jbgz 600
ORDER BY BH
例 4.24 检索 Staff 中 bmdh 为 02、03、04 的 bh、xm、xb,且查询结果按 bh 排序。
SELECT bh,xm,xb
FROM staff
WHERE bmdh IN(’02’,’03’,’04’)
ORDER BY bh
此例中的 IN 运算符指可选择匹配若干指定值的元组。

第 4 章 SQL - 67 -
4.3.3 多表查询
对多表数据的检索,是通过表与表之间满足一定条件的行连接来实现的。实现来自多个
关系的查询时,如果要引用不同关系中的同名属性,则在属性名前加关系名,即用“关系名
属性名”的形式表示,以便区分。
例 4.25 检索男公务员的编号(bh)、姓名(xm)及基本工资(jbgz)。
SELECT bh,xm,jbgz
FROM staff,salary
WHERE staff.bh=salary.bh and xb=’男’
该查询语句要对关系 Staff 和 Salary 做连接操作。执行连接操作的表示方法是 FROM 子
句后面的表名 Staff 和 Salary,及 WHERE 子句后的连接的条件 Staff.bh=Salary.bh。
例 4.26 查询基本工资(jbgz)在 500 元以上的所有员工编号(bh)、姓名(xm)、基本
工资(jbgz)及级职(jz)。
SELECT bh,xm,jbgz,jz
FROM staff,salary,jz
WHERE staff.bh=salary.bh AND staff.jzdh=rank.jzdh AND jbgz>=500
例 4.27 检索所有比编号为 00051 的基本工资(jbgz)高的员工编号(bh)、基本工资(jbgz)
及 00051 的基本工资(jbgz)。
SELECT x.bh,x.jbgz,y.jbgz
FROM salary x,salary y
WHERE x.jbgz>y.jbgz AND y.bh=’00051’
该例是一个表和它自身的大于连接。查询块 FROM 子句中定义了表 salary 的两个别名 X
和 Y,则将一个表的自身连接看成为两个表的连接。当表名太长时,为简化输入,也常用表
的别名。
4.3.4 嵌套子查询
嵌套子查询指将一个查询块嵌套在另一个查询块的WHERE子句或HAVING短语条件中
的查询,并允许多层嵌套。
1.带有 IN 谓词的子查询
例 4.28 查询与李彬在同一个部门的员工。
SELECT bh,xm,bmdh
FROM Student
WHERE bmdh IN
(SELECT bmdh
FROM staff
WHERE xm=’李彬’)

- 68 - 电子政务数据库基础
类似地可以定义 NOT IN 操作
2.带有比较运算符的子查询
例 4.29 查询其他部门中比 02 部门某一员工年龄小的员工姓名(xm)和年龄(nl)
SELECT xm,nl
FROM staff
WHERE nl=(SELECT nl
FROM staff
WHERE bmdh=’02’)
该例的内部子查询是一个普通的子查询,它只执行一次以获取 02 部门的值,外部查询
和子查询是对同一个表的查询,且查询结果仅返回一个值。若子查询返回一组值,则必须在
比较运算符和子查询间插入 ANY 或 ALL 等操作符。
3.带有 ANY 或 ALL 谓词的子查询
例 4.30 查询其他部门中比 02 部门某一员工年龄小的员工姓名(xm)和年龄(nl)。
SELECT xm,nl
FROM staff
WHERE nl<ANY(SELECT nl
FROM staff
WHERE bmdh=’02’)
类似地,可定义<>ANY;>=ANY,<ANY,<=ANY 等操作符,该例也可用连接操作运
算方法表达相同的结果。
SELECT xm,nl FROM staff,salary WHERE staff.bh=salary.bh and bmdh=’02’
可用=ANY 代替 IN,例 4.28 可写为如下形式:
SELECT bh,xm,bmdh
FROM Student
WHERE bmdh=ANY(SELECT bmdh
FROM staff
WHERE xm=’李彬’)
IN 和=ANY 完全可以互换,它们都可以看做集合中的“属于”运算,一般多采用 IN 运
算。!=ALL 和 NOT IN 可互换。
4.带有 EXISTS 谓词的子查询
EXISTS 代表存在量词。带有 EXISTS 谓词的子查询不返回任何数据,只产生逻辑真值

第 4 章 SQL - 69 -
true 或逻辑假值 false。
例 4.31 查询所有基本工资(jbgz)低于 500 元的的员工姓名。
SELECT xm FROM staff
WHERE EXISTS
(SELECT *
FROM salary
WHERE bh=staff.bh AND jbgz<=500)
类似地可以定义 NOT EXISTS 的操作。
需要注意的是,任何含有 IN 的查询通常可用 EXISTS 表达,但反过来不一定。
4.3.5 集合查询
关系是元组的集合,多个 SELECT 语句的结果可进行集合操作。集合操作主要包括并
UNION、交 INTERSECT、差 MINUS。
例 4.32 查询 Staff 表中部门代号(bmdh)为 01 员工及年龄不大于 35 岁员工。
SELECT *
FROM Staff
WHERE bmdh=’01’
UNION
SELECT *
FROM Staff
WHERE nle<=35;
使用 UNION 将多个查询结果合并起来时,系统会自动去掉重复元组。类似地可以定义
INTERSECT 与 MINUS 的操作。
4.3.6 库函数及算术表达式值的查询
SQL 提供的集函数主要有如下几种。
COUNT([DISTINCT|ALL]*):统计元组个数
COUNT([DISTINCT|ALL]<列名>):统计一列中值的个数(空值不计)
SUM([DISTINCT|ALL]<列名>):计算一列值的总和(此列必须是数值型)
AVG([DISTINCT|ALL]<列名>):计算一列值的平均值(此列必须是数值型)
MAX([DISTINCT|ALL]<列名>):求一列值中的最大值
MIN([DISTINCT|ALL]<列名>):求一列值中的最小值
例 4.33 查询 Staff 表的总人数。
SELECT COUNT(*) FROM Student

- 70 - 电子政务数据库基础
例 4.34 计算部门代号(bmdh)为“02”的员工平均年龄、最大年龄、最小年龄。
SELECT AVG(nl)AS 平均年龄,MAX(nl)AS 最大年龄,MIN(nl)AS 最小年龄。
FROM staff
WHERE bmdh=’01’
例 4.35 检索 01 部门最高基本工资、最低基本工资、及最高基本工资与最低基本工资
的差值。
SELECT MAX(jbgz)AS 最高基本工资,MIN(jbgz)AS 最低基本工资。
MAX(jbgz)−Min(jbgz)AS 差值
FROM staff,salary
WHERE staff.bh=salary.bh and bmdh=’01’
4.3.7 分组查询
SQL 允许对关系表按属性列或属性列组合在行的方向上进行分组,然后再对每个分组执
行 SELECT 操作(如投影、库函数等),SQL 提供了 GROUP BY 子句和 HAVING 子句来实
现分组统计。GROUP BY 子句将查询结果表按某一列或多列值分组,值相等的为一组。如果
分组后还要求按一定的条件对这些组进行筛选,最终只输出满足指定条件的组,则可以使用
HAVING 短语指定筛选条件。
例 4.36 检索各部门代号(bmdh)及相应部门的人数,且只输出超过 3 人的部门代号
(bmdh)。
SELECT bmdh,COUNT(bh)
FROM staff
GROUP BY bmdh
HAVING COUNT(bh)>3
例 4.37 统计各部门的基本工资(jbgz)总和以及平均基本工资。要求查询结果按基本
工资总和的升序排列。
SELECT bmdh as 部门代号,AVG(jbgz)AS 基本工资,SUM(jbgz)AS 基本工资总
和
FROM staff,salary
WHERE staff.bh=salary.bh
GROUP BY staff.bmdh
ORDER BY 3
在这个例子中,首先,根据 WHERE 子句的条件,对关系 Staff 和 Salary 执行联接操作,
再按部门代号(bmdh)的值对员工进行分组,将 bmdh 列的值相同的元组分为一组;对每一
个分组进行合计操作;最后,再对结果进行排序。

第 4 章 SQL - 71 -
4.4 SQL 中的数据操作语言
SQL 中数据操作语言(SQL DML)也称为数据存储操作,包括插入数据、修改数据和删
除数据 3 种语句。
4.4.1 数据插入
SQL 的数据插入语句 INSERT 通常有 3 种形式:插入单个元组、插入多个元组及插入子
查询结果。
1.插入单个元组
插入单个元组的 INSERT 语句的格式为:
INSERT INTO <表名> [(<列名> [,<列名>])]
VALUES (<常量> [,<常量>])
VALUES 子句常量的排列顺序必须和列名表中的列名输入顺序一致、个数相等、数据类
型相对应。如表后不跟列名表,表示在 VALUES 后的常量中提供插入元组的每个分量的值,
分量的顺序和关系模式中列名的顺序一致。如表后有列名表,则表示在 VALUES 后的元组值
中只提供插入元组对应于列名中的分量的值。
例 4.38 staff 表中插入一条记录(’00062’,’李阳’,’女’,’38’)。
INSERT INTO staff(bh,xm,xb,nl)
VALUES(’00062’,’李阳’,’女’,’38’)
该例中,新插入的记录在其他的列上取空值。
例 4.39 在 staff 表中插入一新元组。
INSERT INTO staff
VALUES(’00069’,’王一丹’,’女’,’06’,’C�,’专科’,48,1956-01-01)
2.插入多个元组
插入多个元组的 INSERT 语句的格式为: INSERT INTO <表名> [(<列名表>)] VALUES(<元组值> [,<元组值>][,<元组值>]) 例 4.40 在 staff 表中连续插入 3 个元组 INSERT INTO staff VALUES((’00060’,’赵伟’,’男’,’05’,’D’,’本科’,26,1978-08-12),(’00061’,’张刚’,’男’,’03’, ’B’,’本科
’,40,1964-07-24),(’0062’,’郭明’,’男’,’03’,’C’,’研究生’,32,1974-08-36)
3.插入子查询结果
插入子查询结果的 INSERT 的语句格式为: INSERT INTO<表名>[<属性列 1>[,<属性列 2>...)]

- 72 - 电子政务数据库基础
子查询;
例 4.41 对每一个部门,求员工的平均年龄,并把结果存入数据库 bmnl。
CREATE TABLE bmnl
(bmdh CHAR(2)
Average SMALLINT)
然后对表按部门分组求平均年龄,再把部门名和平均年龄存入新表中。
INTERT
INTO bmnl(bmdh,Average)
SELECT bmd,AVG(nl)
FROM staff
GROUP BY bmdh
4.4.2 数据删除
删除语句的一般格式为:
DELETE
FROM<表名>
[WHERE<条件>]
1.删除某一个元组的值
例 4.42 删除表 staff 中编号(bh)为 0031 的员工记录。
DELETE
FROM staff
WHERE bh=’0031’
2.删除多个元组的值
例 4.43 删除表 staff 中的所有员工记录。
DELETE
FROM staff
例 4.44 删除表 staff 中学历(xl)为 NULL 的元组。
DELETE
FROM staff
WHERE xl is NULL
3.带子查询的删除语句
例 4.45 删除赵华的工资记录。
DELETE
FROM salary
WHERE bh IN
(SELECT bh

第 4 章 SQL - 73 -
FROM staff
WHERE xm=’赵华’)
4.4.3 数据更新
SQL 使用 UPDATE 语句对表中指定元组的某些值进行修改,数据更新操作语句的一般
格式为:
UPDATE <表名>
SET<列名>=<表达式>[,<列名>=<表达式>]
[WHERE<条件表达式>]
该语句的功能是:修改指定表中满足条件表达式的元组中的指定属性值,其中 SET 子句
用于指定修改方法,即用(表达式)的值取代相应的属性列值。如果省略 WHERE 子句,表
示要修改表中的所有元组。
1.修改某一个元组的值
例 4.46 将编号(bh)为“00023”的员工年龄改为 35 岁。
UPDATE staff
SET nl=22;
WHERE bh=’00023’;
2.修改多个元组的值
例 4.47 将 salary 表中基本工资都提高 6%。
UPDATE salary
SET jbgz=jbgz*1.06’
3. 带子查询的修改语句
子查询也可以嵌套在 UPDATE 语句中。
例 4.48 将 02 部门的全体员工基本工资都增加 50 元。
UPDATE salary
SET jbgz=jbgz+50
WHERE bh IN
(SELECT bh
FROM staff
WHERE bmdh=’02’)
4.5 SQL 中的数据控制语言
现在的数据库系统大都提供了非常完善的安全机制,一般采用基于角色的多级授权安全
机制,即根据用户的特性,把用户分为不同的类别,如管理员、数据库备份管理员、数据库

- 74 - 电子政务数据库基础
用户管理员、普通用户等。所有对数据库的操作都需要更高一级的授权,任何级别的用户在
使用数据库系统时,除了必须拥有的授权外,还必须提供正确的用户名和用户口令。在数据
库系统中,数据库系统管理员(DBA)负责完成整个系统的管理工作,获得 DBA 授权的用
户可以创建数据库、表等而成为这些数据库对象的拥有者。拥有者对自己所拥有的对象有完
全控制权,同时拥有者也可以授权其他用户使用其所拥有的对象,当然,也可以收回授权。
SQL 的数据控制功能是控制用户对数据的存取权力,语句有两条:授权语句(GRANT)和
收权语句(REVOKE)。授权语句是使某个用户具有某些权限,收权语句是收回已授给用户
的权限。用户对数据的存取操作包括:增(INSERT)、删(DELETE)、改(UPDATE)、查
(SELECT)。只有被授予了某项操作权限的用户才能进行某项操作。
4.5.1 授权
GRANT <权限> [<列名>[,<列名>]][,<权限>][<列名>[,<列名>]]] ON <表名> TO <用
户> [,<用户>] [WITH GRANT OPTION]
� 权限包括 SELECT、INSERT、ALTER、INDEX、UPDATE、REFERENCES 等权力。
数据库用户可以将特定数据对象上的某个权限或某几个权限或所有权限(用 ALL 表
示)授予其他用户。
� 只有当授予 INSTERT、REFERENCES、UPDATE 权限时才需要指定列名,列名用于
指定要授权的数据库对象中的一个或多个列。若不指定列名,被授权的用户将在指定
数据库对象的全部列上拥有指定的权限。
� ON 子句用于指定拥有上述对象权限的对象名(可以是基本表名、视图名等)。
� 若选定了 WITH GRANT OPTION 子句时,被授权的用户有权将获得的权限再授予其
他用户。
例 4.49 将对表 staff 的所有操作权限授权给用户 ROSE。
GRANT ALL ON staff TO ROSE
例 4.50 将对表 staff 查询及修改 bh 的权限授权给用户 ROSE,并给 ROSE 有再授权的
权力。
GRANT SELECT,UPDATE(bh)ON staff TO ROSE
WITH GRANT OPTION
4.5.2 收回授权
REVOKE <权力> [,<权力>] ON <表名> FROM <用户> [,<用户>]
例 4.51 将授予用户 ROSE 对表 staff 的更新权(包括 INSERT、UPDATE、DELETE)
收回。
REVOKE INSERT,UPDATE,DELETE ON staff FROM rose
例 4.52 将授予用户 ANN 修改员工 bh 的权限收回。
REVOKE UPDATE(bh)ON staff FROM ANN

第 4 章 SQL - 75 -
4.6 本 章 小 结
本章介绍了结构化查询语言 SQL,通过示例讲解了 SQL 的使用方法。SQL 集定义、查
询、操作、与控制等功能于一体,SQL 中的数据定义语言用于定义 SQL 模式、基本表、视
图和索引等;SQL 中的数据查询语言主要用于对已经存在的基本表及视图进行数据检索;SQL
中的数据操纵语言分成数据查询和数据更新两类。其中数据更新又分成插入、删除和修改三
种操作;SQL 中的数据控制语言包括对基本表和视图的授权,完整性规则的描述,事务控制
语句等。
4.7 本 章 习 题
1.对于教学数据库的 3 个基本表:学生 S、成绩 SC、课程 C
S(SNO,SNAME,AGE,SEX,SDEPT)
SC(SNO,CNO,GRADE)
C(CNO,CNAME,CDEPT,TNAME)
试用 SQL 查询语句完成下列查询。
(1)检索 LIU 老师所授课程的课程号和课程名。
(2)检索年龄大于 25 岁的男学生的学号和姓名。
(3)检索选修课程包含 LIU 老师所授课程的学生学号。
2.试用 SQL 查询语句完成下列对教学数据库的 3 个基本表 S、SC、C 的查询。
(1)统计所有学生选修的课程门数。
(2)求选修 C4 课程的学生的平均年龄。
(3)求 LIU 老师所授的每门课程的学生平均成绩。
(4)检索姓名以 WANG 打头的所有学生的姓名和年龄。
(5)在 SC 表中检索成绩为空值的学生学号和课程号。
3.试用 SQL 更新语句完成下列对教学数据库的 3 个基本表 S、SC、C 的更新操作。
(1)往基本表 S 中插入一个学生元组(“S9”,“WU”,18)。
(2)在基本表 SC 中删除尚无成绩的元组。
(3)WANG 同学的选课和成绩全部删去。
(4)把 MATHS 课不及格的成绩全改为空值。
(5)把低于总平均成绩的女同学成绩提高 5%。
4.假设某“仓库管理”关系模型有下列 5 个关系模式。
零件 PART(PNO,PNAME,COLOR,WEIGHT)
项目 PROJECT(JNO,JNAME,DATE)
供应商 SUPPLIER(SNO,SNAME,SADDR)
供应 P_P(JNO,PNO,TOTAL)
采购 P_S(PNO,SNO,QUANTITY)

- 76 - 电子政务数据库基础
试用 SQL DDL 语句定义上述 5 个基本表,并说明主键和外键。
5.针对 4 题创建的表,用 SQL 进行下列各项操作。
(1)向 PART 表增加“PDATE”列,数据类型为日期型。
(2)删除 PART 表中的 WEIGHT 属性。
(3)将表 P_P 中 TOTAL 的数据类型改为短整型。
(4)撤销表 P_S。
6.说明授予和收回对象特权和角色的 SQL 语法格式,并举例说明。
4.8 本章参考文献
1.姚卿达·数据库设计·北京:高等教育出版社,1987
2.萨师煊等·数据库系统概论(第 2 版)·北京:高等教育出版社,1987
3.李大友等·数据库原理及应用·北京:清华大学出版社,1997
4.潘郁等·电子商务数据库技术·北京:北京大学出版社,2002
5.王能斌·数据库系统原理·北京:电子工业出版社,2000
6.王鹏等·数据库技术及其应用·北京:人民邮电出版社,2000
7.庄成三等·数据库系统原理及其应用·北京:电子工业出版社,2000
8.李昭原·数据库原理与应用·北京:科学出版社,2001
9.俞盘祥等·数据库原理与技术·北京:清华大学出版,1988
10.龙祥等·数据库原理与设计·北京:人民邮电出版社,2002

第 5 章 SQL Server 2000
关系数据模型在理论上的日渐成熟,激发起计算机厂商和软件公司对关系数据库管理
系统(RDBMS)的研制和开发热情,导致短短二十几年间一百多个 RDBMS 应运而生。
SQL Server 是 Microsoft 的一个分布式关系数据库管理系统产品,它运行在 Windows
NT/2000 和 Windows 9x 两类操作系统之上,并且具有易用性强、分布式查询处理、数据发
布功能、数据仓库功能、与其他服务器软件的集成性、良好的性能价格比等许多优点,所
以一经推出就获得了广泛的应用。SQL Server 2000 作为 SQL Server 数据库管理系统的最新
版本,扩展了 Microsoft SQL Server 7.0 的性能、可靠性、质量和易用性。它在 Microsoft SQL
Server 7.0 基础上又增加了几种功能,由此成为大规模联机事务处理(OLTP)、数据仓库和
电子商务等应用程序的优秀数据库平台。
本章主要内容:
� SQL Server 2000 概述
� SQL Server 认证模式
� 数据库和表的创建
� 数据库的查询和视图
� 索引和数据完整性
� 存储过程
� 备份和还原
5.1 SQL Server 2000 概述
5.1.1 SQL Sever 2000 简介
SQL Server 2000 是一种基于客户端/服务器模式(Client/Server 模式,C/S 模式)的新
一代大型关系型数据库管理系统(DBMS)。它在电子商务、数据仓库和数据库解决方案等
应用中起着非常重要的核心作用。除了支持传统关系数据库组件(如数据库、表)和特性
外,也支持当今关系数据库常用的组件,如存储过程(Stored Procedure)、视图(View)等,
另外还支持目前关系数据库都支持的标注查询语言-SQL。SQL Server 另外一个重要特点
是支持数据库复制(Replication)功能,即当用户在一个数据库上执行操作时,可以将其操
作结果传至远程 SQL Server 2000 相同的数据库上,让两边数据库的数据保持同步。
SQL Server 2000 是 Microsoft 公司推出的 SQL Server 数据库管理系统的最新版本。它
继承了 SQL Server 7.0 的优点,同时它又在 SQL Server 7.0 的基础上增加了许多更为先进的
功能。它具有使用方便、可伸缩性好、与相关软件集成度高等优点,可运行于 Microsoft

- 78 - 电子政务数据库基础
Windows 98、Microsoft Windows NT 及 Microsoft Windows 2000 等多种操作平台上。
SQL Server 2000 扩展了 SQL Server 7.0 的性能、可靠性、质量和易用性。它在 SQL Server
7.0 的基础上新增加了几种功能,由此成为联机事务处理(OLTP)、数据仓库和电子商务等
应用的优秀数据库平台。
SQL Server 2000 的新特性如下。
(1)与 Internet 集成。SQL Server 2000 数据库引擎提供完整的 XML 支持。通过使用
Web,而不需要额外的编程就可以建立 SQL Server 2000 数据库和 OLAP 立方体的连接,在
Web 应用程序中包含了用户友好的查询和强大的搜索功能。SQL Server 2000 将用户的数据
存储在多个服务器上,扩大了数据库的规模。
(2)数据仓库。SQL Server 2000 中包括析取和分析汇总数据以进行联机分析处理
(OLAP)的工具,满足用户所有的商业分析需求;可以在不同的数据源之间自动提取、转
换和加载数据;可以对数据仓库中的数据进行挖掘,发现商业模式和趋势,为科学决策提
供支持。
(3)可伸缩性和可用性。同一个数据库引擎可以在多个不同的平台上运行;SQL Server
2000 企业版支持联合服务器、索引视图和大型内存等功能,使其能够升级到最大 Web 站点
所需的性能级别。
(4)易于安装、部署和使用。SQL Server 2000 中包含了一系列管理和开发工具,这些
工具可改进在多个站点上安装、部署、管理和使用 SQL Server 的过程。SQL Server 2000 还
支持基于标准的、与 Windows DNA 集成的程序设计模型,使得 SQL Server 数据库和数据
仓库的使用成为生成强大的可伸缩系统的无缝部分。这些功能使得程序开发者得以快速交
付 SQL Server 应用程序,使客户能够以最少量的安装和管理开销就可以实现这些应用程序。
5.1.2 SQL Server 2000 服务管理器
SQL Server 2000 服务器组件是 SQL Server 2000 系统的服务单元,主要包括 SQL Server
数据库引擎(MSSQL Server 服务)、SQL Server 代理程序(SQL Server Agent 服务)、Microsoft
搜索服务和分布式事务处理协调器(MS DTC 服务)。SQL Server 2000 服务器组件可由 SQL
Server 2000 服务管理器启动停止和暂停。这些组件在 Windows NT、Windows 2000 上作为
服务运行,在 Windows 9x 上则作为单独的可执行程序运行。
(1)SQL Server 服务管理器的运行。SQL Server 服务管理器是一个任务栏应用程序,
SQL Server 服务管理器的图表最小化时,将显示在任务栏右边的任务栏时钟区。可以通过
右击任务栏上的最小化图标获得 SQL Server 服务管理器所支持的所有任务的菜单;而双击
其图标,则使 SQL Server 服务管理器最大化。可以通过右击图标,然后选择“退出”菜单
项。
(2)停止和启动 SQL Server 服务管理器实例有 4 个方法。
① 在 Windows NT 和 Windows 2000 操作系统启动时自动启动每个服务。
② 用 SQL Server 服务管理器启动或停止服务。
第 1 步,选择“开始”→ “程序”→ Microsoft SQL Server → “服务管理器”,进入
到服务管理器界面,见图 5.1
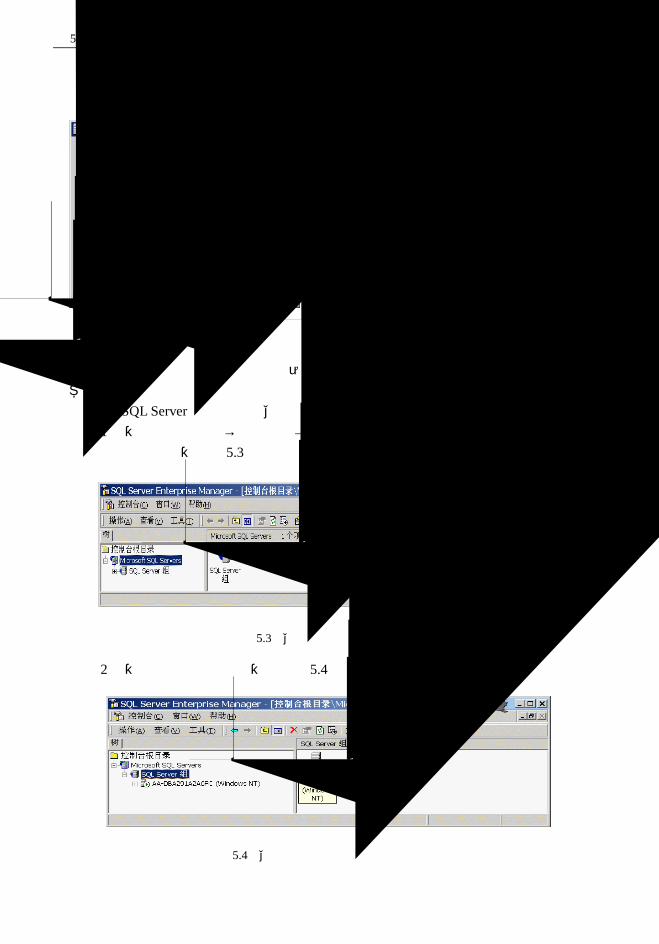
第 5 章 SQL Server 2000 -79-
第 2 步,单击“开始/ 继续”按钮,则启动 SQL Server 服务管理器服务。见图 5.2 所
示。
图 5.1 服务管理器界面 图 5.2 启动 SQL Server 服务后的服务管理器界面
第 3 步,单击“停止”或“暂停”按钮,则终止或暂停 SQL Server 服务管理器实例的
运行。
③ 用 SQL Server 企业管理器启动或停止服务。
第 1 步,选择“开始”→“程序”→Microsoft SQL Server→“企业管理器”
进入企业管理器界面,见图 5.3 所示。
图 5.3 启动企业管理器后的界面
第 2 步,双击服务器组图标,进入图 5.4 界面。图中的服务器实例处于启动状态。
图 5.4 启动服务器服务时企业管理器界面

- 80 - 电子政务数据库基础
第 3 步,双击服务器实例图标,系统启动 SQL Server 服务器的服务,并建立企业管理
器与该实例的连接。见图 5.5 所示。
图 5.5 启动服务器并建立连接的企业管理器界面
5.1.3 SQL Sever 2000 企业管理器
企业管理器( Enterprise Manager )是SQL Server 中最重要的管理工具,在使用SQL
Server的过程中,大部分的时间都是和它打交道,通过企业管理器可以管理所有的数据库系
统和服务器的工作,也可以调用其他的管理开发工具。从图5-5可以看出,企业管理器通过
易于使用的图形界面,将所有SQL Server对象展现在一个分层结构的控制台树中。企业管
理器是按照“数据库服务器组→数据库服务器→数据库→数据库对象(表、视图等)”这
样一个层次结构组织对象并进行有效管理的。利用企业管理可对数据库服务器、数据库及
数据库对象(表、视图等)进行有效管理。企业管理器的主要功能如下。
� 注册服务器。
� 配置服务器(包括本地、远程服务器)。
� 设置登录安全性。
� 对数据库、数据库对象进行管理和操作。
� 创建警告。
� 建立操作员。
� 为独立的环境创建和安排作业。
� 创建和管理复制方案。
� 为企业管理器设置轮询间隔。
5.1.4 SQL 查询分析器(SQL Query Analyzer)
SQL 查询分析器用于交互输入 T-SQL 语句和存储过程,可以以图形的形式提供图形查
询分析功能,包含集成的 T-SQL 调试器、对象浏览器,可用于确定数据库中的表、视图、
存储过程和其他对象的特性,并可支持用于加快复杂语句生成速度的模板。查询分析器使
程序员能够交互地开发和测试 T-SQL 语句。进入查询分析器用两种方法。
(1)从 SQL Server 企业管理器调用 SQL 查询分析器

第 5 章 SQL Server 2000 -81-
选择“工具”→“SQL 查询分析器”。
(2)由“任务”任务栏进入查询分析器
从“开始”任务栏,选择“程序”→Microsoft SQL Server→“查询分析器”。图 5.6 为
进入 SQL 查询分析器,并与 SQL Server 服务器建立连接后的界面。
图 5.6 查询分析器界面
当然,也可以连接到其他的 SQL Server 服务器。在查询分析器中,选择“文件”→“连
接”,出现连接对话框,在对话框中选择要连接的服务器和认证方式,并输入相应的用户名
和密码。
5.2 SQL Server 2000 身份认证模式
5.2.1 SQL Server 2000 身份认证模式
SQL Server 2000 的身份认证模式是指系统确认用户的方式。SQL Server 2000 有两种身
份认证模式:Windows NT 认证模式和 SQL Server 认证模式。
(1)Windows NT 认证模式。用户登录 Windows NT 时进行身份验证,登录 SQL Server
时不再进行身份验证。对于 Windows NT 认证模式登录有两点重要说明。
① 必须将 Windows NT 网络账号加入到 SQL Sever 中,才能采用 Windows NT 网络账
号登录 SQL Server。
② 如果使用 Windows NT 网络账号登录到另一个网络的 SQL Server,必须在 Windows
NT 网络中设置彼此的托管权限。
(2)SQL Server 认证模式。在 SQL Server 认证模式下,SQL Server 服务器要对登录的
用户进行身份验证。
对于 Windows 9x 系列的操作系统只能使用 SQL Server 认证模式,而当 SQL Server 在

- 82 - 电子政务数据库基础
Windows NT 或 Windows 2000 上运行时,系统管理员可设定两种登录认证模式:Windows
NT 认证模式和混合认证模式。在采用混合认证模式时,SQL Server 系统既允许使用
Windows NT 账号登录,也允许使用 SQL Server 账号登录。
5.2.2 用户账号的建立和管理
无论采用哪种认证模式,用户都必须具备有效的 Windows NT 或 Windows 2000 的用户
登录账号,SQL Server 有 3 个默认的用户账号:sa(系统管理员,在 SQL Server 中拥有系
统和数据库的所有权限)、BUILTIN\Administrators(SQL Server 为每个 NT 系统管理员提供
的默认用户账号,在 SQL Server 中拥有系统和数据库的所有权限)和 guest(访问系统的默
认用户账号)。
(1)Windows NT 认证账号的建立和取消。可以通过企业管理器和命令两种方法建立和
取消 Windows NT 账号。在这里仅介绍前一种方法。
通过企业管理器建立 Windows NT 认证模式的登录账号。对于 Windows NT 和 Windows
2000 操作系统,在安装 SQL Sever 2000 的过程中,允许选择认证模式。如果安装时选择
Windows NT 认证方式,此时,若要增加一个 Windows NT 或 Windows 2000 的新用户 shao,
如何授权该用户,使其能够通过信任连接访问 SQL Server 呢?步骤如下(以 Windows 2000
为例)。
第 1 步,创建 Windows 2000 的用户。以管理员身份登录到 Windows 2000,选择“我
的电脑”→“控制面板”→“管理工具”→“计算机管理”,进入界面,见图 5.7,右击“用
户”,弹出快捷菜单,选择“新用户”菜单项,打开“新用户”界面,如图 5.8,输入用户
名和密码,单击“创建”按钮,然后单击“关闭”按钮。
图 5.7 Windows 2000 本地计算机管理界面
第 2 步,将 Windows NT 网络账号加入到 SQL Server 中:以管理员身份登录到 SQL
Server,进入到企业管理器,右击“登录”图标,在弹出的快捷菜单中选择“新建登录”,
出现如图 5.9 所示的界面。单击“常规”选项卡的“浏览”按钮,选择用户名添加到 SQL Server
登录用户列表中。本例中用户名为 BILLGATES\shao。其中 BILLGATES 为计算机名。取消
登录账号很简单,进入企业管理器,单击“登录”,右击相应的账号,在弹出的快捷菜单中

第 5 章 SQL Server 2000 -83-
选择“删除”菜单项。
图 5.8 Windows 2000 本地计算机创建新用户的界面 图 5.9 SQL Server 信任连接设置界面
(2) 混合认证模式下 SQL Server 登录账号的建立和删除。在 Windows NT 或 Windows
2000 环境下,如果要使用 SQL Server 账号登录 SQL Server,要首先将 SQL Server 的认证模
式设置为混合认证模式。步骤如下。
第 1 步,在企业管理器中,右击要登录的 SQL Server,在弹出的快捷菜单上选择“属
性”,出现如图 5.10 所示的 SQL Server 服务器属性配置窗口。
第 2 步,选择“安全性”选项卡,选择身份验证为 SQL Server 和 Windows,然后单击
“确定”按钮。见图 5.11 所示。
图 5.10 SQL Server 服务器属性配置界面 图 5.11 SQL Server 身份认证方式配置界面
设置为混合认证模式后,可在企业管理器中创建 SQL Server 的登录账号。如要创建一
个名为 ding 的账号,步骤如下。
第 1 步,进入企业管理器,在其中右击“登录”图标右击,在弹出的快捷菜单上选择
“新建登录”,出现如图 5.12 所示的界面。
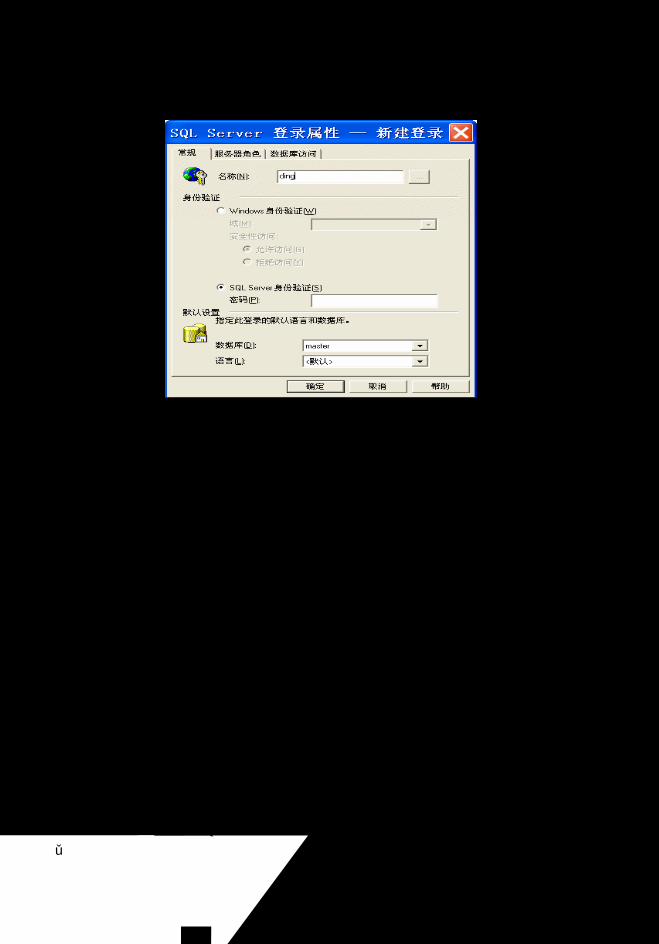
- 84 - 电子政务数据库基础
第 2 步,输入账号和密码,选择“SQL Server 身份验证”方式,单击“确定”按钮即
可。
图 5.12 SQL Server 新建登录界面
5.3 数据库和表的创建、修改和删除
5.3.1 SQL Server 2000 数据库对象
从用户角度看,数据库是一个由存放数据的表和支持这些数据的存储、检索、安全性
和完整性的逻辑成分所组成的集合,称之为逻辑数据库。而组成数据库的逻辑成分称为数
据库对象。SQL Server 2000 的数据库对象主要包括表、视图、索引、存储过程、触发器和
约束等。下面分别对各种数据库对象做简单的介绍。
� 表:由行和列构成的集合,用来存储数据。
� 数据类型:用来定义列或变量的类型,SQL Server 提供了系统数据类型,并允许用
户自定义数据类型。
� 视图:由表或其他视图导出的虚拟表。
� 索引:为数据快速查找提供支持,且可以保证数据惟一性。
� 约束:用于为表中的列定义完整性的规则。
� 默认值:为列提供默认值。
� 存储过程:存放于服务器的预先编译好的一组 T-SQL 语句。
� 触发器:一种特殊的存储过程,用户表中的数据改变时,触发器自动被执行。
用户经常要通过 T-SQL 语句对数据库对象进行操作,包括查询、更新等,在 T-SQL 语
句中需要给出对象的名称。用户可以用两种方法来引用对象。

第 5 章 SQL Server 2000 -85-
(1)完全限定名
一个完整的数据库对象的名称,包含 4 个部分:服务器名、数据库名、数据库所有者
名、对象名。其格式为:
server.database.owner.object
在 SQL Server 2000 上创建的每个对象都必须有一个惟一的完全限定名。
(2)部分限定名
在使用 T-SQL 编程时,使用完全限定名很烦琐且有时也没有必要,所以常省略全名中
某些部分,其中对象全名中的前 3 个部分均可省略。当省略中间部分时,圆点“.”不能省
略。在使用部分限定名时,省略的部分使用默认值。其中服务器的默认值为本地服务器,
数据库默认为当前数据库,所有者默认为在数据库中与当前连接会话的登录标识相关联的
数据库用户名或者数据所有者(dbo)。
SQL Server 2000 有两类数据库:系统数据库和用户数据库。系统数据库存储有关 SQL
Server 的系统信息,它们是 SQL Server 管理系统的依据;用户数据库是用户创建的数据库。
两类数据库在结构上相同。 在安装 SQL Server 2000 时,将创建 4 个系统数据库:master、
model、msdb 和 tempdb。其中,master 包含了 SQL Server 诸如登录账号、系统配置、数据
库位置及数据库错误信息等,用于控制用户数据库和 SQL Server 的运行;model 为新创建
的数据库提供模板;msdb 为 SQL Server Agent 调度信息和作业记录提供存储空间;tempdb
为临时表和临时存储过程提供存储空间。所有与系统连接的用户的临时表和临时存储过程
都存储于 msdb 中。
5.3.2 数据库和表的创建、修改和删除
创建数据库和表是 SQL Server 2000 最重要的功能。有两种途径来创建数据库:一是通
过界面方式,二是通过命令方式。
1.数据库的创建、修改和删除
在此仅仅介绍用界面方式创建数据库。下面建立一个 zggl 数据库:其中有一个 zgxx
表。
(1)通过企业管理器创建数据库
第 1 步,启动企业管理器,单击服务器旁的加号(+),其中包含了已有的数据库。
第 2 步,右击“数据库”文件夹,选择“新建数据库”菜单项。打开“数据库属性”
对话框,如图 5.13 所示。
第 3 步,选择“常规”选项卡(如图 5.13 所示,该标签在初始时已默认被选中),在
“名称(N)�的文本框中输入一个数据库名,这里输入的是 zggl(即是创建后的数据库名)。 第 4 步,选择“数据文件”选项卡,输入文件名、位置、初始大小和文件组信息(可
按照默认的设置)。如图 5.14 所示。 第 5 步,选择“事务日志”选项卡,设置日志文件的初始大小、位置、增长方式等信
息(也可按照默认的设置)。 第 6 步,单击“确定”按钮,以完成创建数据库。

- 86 - 电子政务数据库基础
上述步骤创建的数据库中,包含了一个主数据文件和一个日志文件。主数据文件是数
据库的关键文件,包含了数据库的启动信息,并且存储数据,每个数据库必须有且仅有一
个主文件,默认扩展名为.mdf;日志文件用于保存恢复数据库所需的事务日志信息,每个
数据库至少有一个日志文件,日志文件的扩展名为.ldf;另外还有辅数据文件,用于存储包
括在主文件内的其他数据,扩展名为.ndf。
图 5.13 “数据库属性”界面 图 5.14 设置主数据文件属性的界面
还可以使用向导创建数据库,进入企业管理器后,选择 SQL Server 服务器,在“工具”
菜单中选择“向导”菜单项,进入“选择向导”对话框,展开“数据库”,选择“创建数据
库向导”,单击“确定”按钮。进入“创建数据库向导”界面,以后按照“数据库向导”引
导的步骤逐步进行。
(2)修改数据库
数据库创建以后,并不是一直不变的,总会因为种种原因要修改其某些属性。如改变
数据文件的大小、增长方式等。当然,数据库创建以后,数据文件和日志文件的文件名就
不能改变了。下面以修改 zggl 数据库为例,说明在企业管理器中如何对已创建的数据库进
行修改。
第一步,进入企业管理器,选择要修改的数据库,右击该数据库名,出现快捷菜单,
选择“属性”,进入“数据库属性”对话框。
第 2 步,改变数据文件的大小和增长方式,在“数据库属性”对话框选择“数据文件”
选项卡,可以对数据文件的已分配空间、增长方式和最大大小等属性进行修改。
第 3 步,增加数据文件。在“数据库属性”对话框中选择“数据文件”选项卡,再紧
随已有文件名后的空白行输入相应的文件名、文件的初始大小、位置等,并可以设置文件
相关其他属性。添加的数据文件为辅数据文件。
第 4 步,删除数据文件。在 SQL Server 中只能删除辅数据文件,而不能删除主数据文
件,因为,在主数据文件中存放着数据库的启动信息,若将其删除,数据库将无法启动。

第 5 章 SQL Server 2000 -87-
操作方法:在“数据文件”选项卡中选择需要删除的数据文件,单击“删除”按钮,
在弹出的对话框中选择“确定”,即可删除该文件。
(3)删除数据库
进入企业管理器,选定要删除的数据库,右击该数据库名,在弹出的快捷菜单上选择
“删除”即可。
2.表的创建、修改和删除
在 SQL Server 2000 中,一个数据库可以创建多达 20 亿个表,每个表最多可达 1024 列,
每行最多 8092 个字节(不包括 image、text 或 ntext 数据)。在创建表中的列时,必须为其
指定数据类型。列的数据类型决定了数据的取值范围和存储格式。所以在创建表之前,先
来介绍 SQL Server 支持而且常用的系统数据类型。
(1)SQL Server 支持的常用的数据类型
① 字符型数据。字符型数据非常有用。当需要存储短的字符串信息时,总是要用到字
符型数据。例如,可以把从 HTML form 的文本框中搜集到的信息放在字符型字段中。字符
型数据分为定长(char)和变长(varchar)两类。
② 文本型数据。字符型数据限制了字符串的长度不能超过 255 个字符。而使用文本型
数据,可以存放超过 20 亿个字符的字符串。当需要存储长串的字符时,应该使用文本型数
据。
③ 数值型数据。SQL Server 支持许多种不同的数值型数据。可以存储整数、小数等。
通常,当需要在表中存放数字时,要使用整型(INT)数据。INT 型数据的表数范围是
从- 2147483647 到 2147483647 的整数。为了节省内存空间,可以使用 SMALLINT 型数据。
SMALLINT 型数据可以存储从- 32768 到 32768 的整数。这种数据类型的使用方法与 INT
型完全相同。
最后,如果实在需要节省空间,可以使用 TINYINT 型数据。同样,这种类型的使用方
法也与 INT 型相同,不同的是这种类型的字段只能存储从0到 255 的整数。TINYINT 型字
段不能用来存储负数。
通常,为了节省空间,应该尽可能地使用最小的整型数据。一个 TINYINT 型数据只占
用一个字节;一个 INT 型数据占用 4 个字节。这看起来似乎差别不大,但是在比较大的表
中,字节数的增长是很快的。另一方面,一旦已经创建了一个字段,要修改它是很困难的。
因此,为安全起见,应该预测一下,一个字段所需要存储的数值最大有可能是多大,然后
选择适当的数据类型。
为了能对字段所存放的数据进行更多的控制,可以使用 NUMERIC 型数据来同时表示
一个数的整数部分和小数部分。NUMERIC 型数据能表示非常大的数��比 INT 型数据要
大得多。一个 NUMERIC 型字段可以存储从- 1038 到 1038 范围内的数。NUMERIC 型数据还
能表示有小数部分的数。 当定义一个 NUMERIC 型数据时,需要同时指定整数部分的大小和小数部分的大小。 ④ 货币型数据。SQL Server 提供了两种专门用于处理货币的数据类型:MONEY 和
SMALL MONEY , 用 十 进 制 数 表 示 货 币 值 。 MONEY 型 数 据 可 以 存 储 从
- 922337203685477.5808 到 922337203685477.5807 的钱数。如果需要存储比这还大的金额,

- 88 - 电子政务数据库基础
可 以 使 用 NUMERIC 型数 据 。 SMALLMONEY 型 数 据 只 能 存储 从 - 214748.3648 到
214748.3647 的钱数。同样,如果可以的话,应该用 SMALLMONEY 型来代替 MONEY 型
数据,以节省空间。
⑤ 位型数据。位型(bit)数据就是其他语言中的逻辑型数据,只有两个值:0 和 1。
⑥ 日 期 时 间 型 数 据 。 用 于 存 储 日 期 和 时 间 信 息 。 包 括 DATETIME 和
SMALLDATETIME。一个 DATETIME 型的字段可以存储的日期范围是从 1753 年 1 月 1 日
第 1 毫秒到 9999 年 12 月 31 日最后 1 毫秒。而一个 SMALLDATETIME 型的字段能够存储
从 1900 年 1 月 1 日到 2079 年 6 月 6 日的日期,它只能精确到秒。
(2)用界面方式创建表、修改表、删除表
创建表其实就是定义表结构及约束等属性。在使用工具或用 T-SQL 语句创建之前,首
先要设计表结构,即确定表的名称、表中的各列名、列的数据类型和长度以及是否可为空
值、默认值情况、是否要使用及何时使用约束、哪些列需要索引及索引的类型、主键及外
键等。这里空值(NULLl)用来表示未知、不可用或将在以后添加的数据。若定义一个列
允许为空值,则在向表中输入数据时可不给出该列的具体值;而一个列要是不允许为空值,
则在输入时必须给出具体值。
注意:表的关键字不允许为空值。空值不等同于 0,也不是空字符。任意两个空值都不
相等。
① 职工信息表的创建。在 zggl 数据库中创建员工信息表 zgxx,表结构如表 5-1 所示。
表 5-1 表 zgxx 的结构
列名 数据类型 长度 是否允许为空 默认值 说明
工号 CNAR 6 × 无 主键
姓名 CNAR 8 × 无
性别 BIT 1 × 1 男 1,女 0
出生时间 SMALLDATEIME 4 × 无
职务 CNAR 10 v 无
部门 CNAR 16 × 无
备注 TEXT 16 v 无
通过企业管理器创建表 zggl 过程如下:
第 1 步,启动企业管理器,右击数据库 zggl,出现快捷菜单,选择“新建”→“表”。
进入表设计窗口。
第 2 步,在表设计窗口中分别输入各列的名称、数据类型、长度等属性,并将“性别”
的默认值设置为 1。见图 5.15 所示。
第 3 步,在表的各列的属性都编辑完毕后,单击工具栏上的“保存”按钮,弹出“选
择名称”对话框,见图 5.16 所示。在对话框中输入表名 zgxx,单击“确定”按钮。zgxx
表即建好。

第 5 章 SQL Server 2000 -89-
图 5.15 创建 zgxx 表界面
图 5.16 “选择名称”对话框
② 修改表。在创建表后,还可以对表结构进行修改。包括修改表名、增加列、删除列、
修改已有列的属性等。
� 更改表名。SQL Server 允许改变一个表的名称,但是表名更改后,与此相关的一些
对象如视图以及通过表名与表相关的存储过程将无效。所以一般表建好后,建议不
要改表名。在企业管理器修改表名的过程如下:选择表所在数据库,展开数据库对
象(单击数据库左边“+”),选择“表”,右击要改名的表,出现快捷菜单,选择
“重命名”,在表名位置上输入新的表名,按回车键;在弹出的对话框中单击“确
定”按钮。
� 增加列。如向 zgxx 表中增加新列“学历”。过程如下:进入企业管理器,右击需要
添加列的表 zgxx,在弹出的快捷菜单上选择“设计表”。入表设计窗口。如图 5.17。
在窗口中,单击第一个空白行,输入列名“学历”,选择数据类型等属性。可以连
续向表中增加多列。全部列添加完毕后,单击关闭窗口按钮,在弹出如 5.18 所示
的对话框中,单击“是”按钮,保存修改后的表。还可以直接按工具栏上的“保存”
按钮保存修改后的结果。

- 90 - 电子政务数据库基础
图 5.17 增加新列
图 5.18 保存对表的修改
� 修改已有列的属性。在表中尚无数据时,可以更改表的结构,但当表中有了记录以
后,建议不要轻易修改表结构,尤其是不要改变数据类型,以免产生错误。进入企
业管理器,右击需要进行修改列的表 zgxx,在弹出的快捷菜单上选择“设计表”。
进入 zgxx 表设计窗口。在窗口中单击需要修改的列,进行相应的修改。修改完毕
后,单击设计表窗口的关闭按钮,弹出图 5.18 所示的对话框,单击“是”按键保
存设计窗口,也可以直接按工具栏上的“保存”按钮保存修改后的结果。
③ 删除表。删除表时,表的定义、表中所有的数据以及表的索引、触发器、约束等均
被删除。不能删除系统表和有外键约束的表。操作过程如下:在企业管理器中展开要删除
的表所在的数据库,展开表,右击要删除的表,在弹出的快捷菜单上选择“删除”,系统弹
出“除去对象”对话框,单击“全部除去”按钮,就删除了选择的表。
(3)用命令方式创建表
除了可以通过 SQL Server 企业管理器用界面方式创建数据库和表以外,还可以使用
T-SQL 语句即命令方式来创建数据库和表。在此仅介绍通过命令方式对表的创建和修改。
① 创建表的基本语法格式。
CREATE TABLE 表名

第 5 章 SQL Server 2000 -91-
(列名 1 列的数据类型 [NULL|NOT NULL]PRIMARY KEY],
列名 2 列的数据类型 [NULL|NTO NULL][PRIMARY KEY],
� � � � )
其中: 表名是指所要创建的表的名称,一般默认为在当前数据库中创建该表,若不是,则应
使用含限定的表名; 列名表示在所要创建的表中的列的名字,列名在表中必须惟一; 数据类型是指该列的数据类型及其长度; NULL|NTO NULL 是指该列是否允许为空; PRIMARY KEY 是指是否设置该列为主键,在表中主键只有一个,且该列不能为空;
多个列定义之间用逗号分隔。 例 5.1 在已创建的数据库 zggl 中用 T-SQL 语句创建 zgxx 表。 USE zggl /*使数据库 zggl 成为当前数据库 */ CREATE TABLE(工号 CHAR(6)NOT NULL,姓名 CHAR(8)NOT MULL,性别 bit not
null,出生时间 SMALLDATIME NOTMNULL,职务 CHAR(10)NULL,部门 CHAR(16)NOT NULL,备注 text null)
② 修改表的命令格式 可以使用 ALTER 命令来修改表。可以改变已有列的属性、增加新列及删除列。ALTER
TABLE 的基本语法格式: ALTER TABLE 表名 ALTER COLUMN 列名 新的数据类型 [NULL| NOT NULL] /*修改已有列的属性*/ |ADD 新列名 数据类型 [NULL| NOT NULL] /*增加新列*/ |DROP COLUMN 列名 /* 删除列*/ 例 5.2 在表 zgxx 中修改已有列的属性:将“部门”列的长度由原来的 16 改为 10,
将“出生时间”列的数据类型由原来的 SMALL DATETIME 改为 DATETIME。 USE zggl ALTER TABLE zgxx ALTER COLUMN 部门 CHAR(10) GO ALTER TABLE zgxx ALTER COLUMN 出生时间 DATETIME 例 5.3 在表 zgxx 中增加新列“学历”。 USE zggl ALTER TABLE zgxx ADD 学历 CHAR (10) NULL 例 5.4 删除表 zgxx 中新增列“学历”。 USE zggl ALTER TABLE zgxx

- 92 - 电子政务数据库基础
DROP COLUMN 学历
③ 用命令方式删除表
删除表的命令为 DROP TABLE。其语法格式为:
DROP TABLE 表名
例 5-5 要删除表 zgxx,相应的 T-SQL 语句为:
USE zggl
DROP TABLE zgxx
5.3.3 表数据操作
创建数据库和表以后,总是需要对表中的数据进行操作。对表中的数据操作包括:插
入、修改和删除。可以通过命令和界面两种方式对表中数据进行操作。
1.界面操作表数据
现在以对已创建的数据库 zggl 中的表 zgxx 进行插入、修改和删除操作为例,说明通
过企业管理器操作表数据的过程。
进入企业管理器,展开需要。操作的表所在的数据库,展开表,右击需操作的表名,
在弹出的快捷菜单中选择“打开表”→“返回所有行”,进入操作所选择的表数据窗口。如
图 5.19,在该窗口中,记录按行显示,每个记录一行,可插入、修改和删除记录。
图 5.19 操作表数据界面
(1)插入记录。插入记录是将新记录添加在表尾,可以向表中添加多条记录。操作方
法如下:将光标定位在当前表尾的下一行,然后逐列输入列的值,输完一列,以回车结束,
光标自动跳到下一列,若当前列是最后一列,编辑完毕按回车键,光标自动跳到下一行的
第一列,这样可以开始下一条记录的输入。
要注意的是,当某列不允许为空,则必须给该列输入值;若某列允许为空,则若不输
入该列值,在表格中将显示<NULL>字样,见图 5.19。
(2)修改记录。在企业管理器修改记录时,先定。位被修改的记录字段,然后再修改
该字段。
(3)删除记录。当不需要表中的某些记录时,可以将其删除。在企业管理器中删除记

第 5 章 SQL Server 2000 -93-
录的过程是:在表数据操作窗口将光标定位在需被删除的记录行,则该行反相显示。单击
鼠标右键,在弹出的快捷菜单上选择“删除”菜单项,在弹出的确认对话框中,单击“是”
按钮将删除所选的行。
(4)界面操作表数据的另一种方法。进入企业管理器,展开需要操作的表所在的数据
库,展开表,右击需操作的表名,在弹出的快捷菜单中选择“打开表”→ “查询”,进入
如图 5.20 所示的界面,可以进行相应的操作。
图 5.20 企业管理器的查询界面
2.命令操作表数据
使用 T-SQL 语句也可以对表中的数据进行插入、修改和删除操作。
(1)插入记录
向表中插入数据使用 INSERT 命令。INSERT 语句的基本格式为:
INSERT 表名[(列名 1,列名 2, 列名 3,�)] VALUES(值 1,值 2,值 3,�) 该语句的作用是向指定表中加入有 VALUES 指定的各列值的行。 例 5.6 向 zggl 数据库的表 zgxx 中插入如下一行。 012 杨建龄 1 科员 002 NULL 1978/10/20 则相应的 T-SQL 命令语句为: USE zggl INSERT INTO zgxx(工号,姓名,性别,职务,部门,备注,出生年月) VALUES(’012’,’杨建龄’,1,’科员’,’ 002’,NULL,’10/20/1978’)
执行该命令后,进入企业管理器,展开 zggl 数据库,展开表,右击表 zgxx,在弹出的
快捷菜单上选择“打开表”→ “返回所有行”,可以看出表中已增添了工号 012 这一行。
见图 5.21 所示。

- 94 - 电子政务数据库基础
图 5.21 执行插入命令后的表数据
如果需要对表中该行的所有列插入数据,则可以省略表名后的列表,则上例可写成:
USE zggl
INSERT INTO zgxx
VALUES(’012’,’杨建龄’,1,’科员’,’002 ’,NULL,’10/20/1978’)
但如果只给表中该行的部分列插入数据,则需要指出这些列。如当加入到表中的记录
的某些列为空值或为默认值时,可以在 INSERT 语句中给出列表时省略这些列的值,一般
是具有默认值的列或允许为空值的列,或具有 IDENTITY 属性的列。当某列被定义为标识
列时,其值可以由系统根据种子值和增量值来确定,二者的默认值都为 1,每个表只能有
一个标识列。如上例也可写成:
USE zggl
INSERT INTO zgxx(工号,姓名,性别,职务,部门,出生年月)
VALUES(’012’,’杨建龄’,1,’科员’,’ 002’,’10/20/1978’)
(2)修改记录
可以使用 update 命令来修改表中的数据。update 语句的基本语法是:
UPDATE 表名
SET 列名=表达式
[WHERE 条件表达式]
表名是需要被修改的表;“列名=表达式”表示用表达式的值来对列名所指定的列进行
更新;可以同时对多个列进行更新,中间用逗号分隔开;条件表达式用于指定要更新的记
录,若没有条件表达式,则对所有的记录进行修改。
例 5.7 将数据库 zggl 的表 zgxx 中的工号为 102 的记录职工的部门改为 004:
USE zggl
UPDATE zgxx
SET 部门=’004’
WHERE 工号=’102’
例 5.8 将姓名为“杨建”的职工工号改为 109,部门改为 001,则相应的命令为:
USE zggl
UPDATE zgxx

第 5 章 SQL Server 2000 -95-
SET 工号=’109’,
部门=’001’
WHERE 姓名=’杨建’
(3)删除数据
可以使用 DELETE 或 TRUNCATE TABLE 命令来删除数据。
① 使用 DELETE 语句删除数据
DELETE 命令的基本格式:
DELETE [FROM] 表名
[WHERE 条件表达式]
例 5-9 将 zgxx 表中部门 001 的行删除。T-SQL 语句为:
USE zggl
DELETE FROM zgxx
WHERE 部门=’001’
可以用 SELECT 语句进行查询,可以发现表中已经没有部门为 001 的职工数据。
② 使用 TRUNCATE TABLE 语句删除数据
使用 TRUNCATE TABLE 语句将删除指定表中的所有行。所以称其为清除表数据语
句。其语法格式为:
TRUNCATE TABLE 表名
5.4 数据库的查询和视图
在数据库应用中,最常用的操作是查询,它是数据库的其他操作(如插入、删除、修
改及统计)的基础。在 SQL Server 2000 中对数据库的查询使用第 4 章所介绍 SQL 语句,
它的功能非常强大,使用灵活。可以将 SELECT 语句输入到查询分析器中,通过执行查询
获得查询结果。这也可用来测试,在把查询包含到 ASP 网页中之前,用 Query Analyzer 对
其进行测试是非常有用的。由于第 4 章已详细介绍过 SQL 语句,在此不做过多讨论。
5.4.1 基本概念
视图是从一个或多个表(或视图)导出的表,是数据库用户使用数据库的观点。如对
于一个政府机构,其员工信息保存在数据库的一个或多个表中,而不同的职能部门所关心
的员工数据的内容是不同。即使是同样的数据,也可能有不同的操作要求,可以根据不同
职能部门的不同要求,在物理数据库上定义他们对数据库所要求的数据结构,这种根据用
户观点定义的数据结构就是视图。
视图与表是不同的。视图是一个虚表,即视图所对应的数据不进行实际存储。数据库
只存储对视图的定义,对视图的数据进行操作时,系统根据视图的定义去操作与视图相关
联的的表。
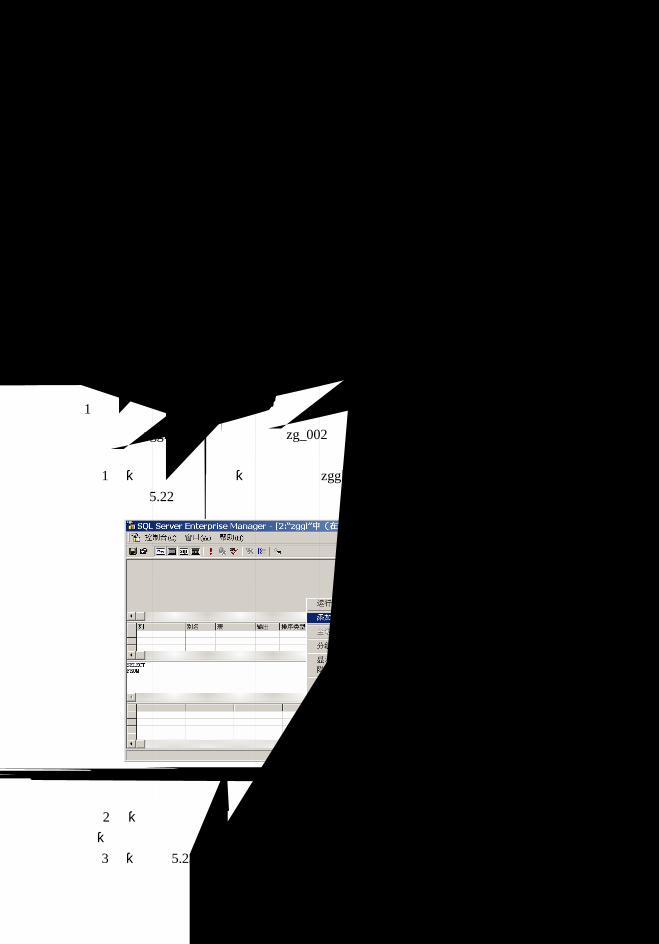
- 96 - 电子政务数据库基础
视图一经定义后,就可以像表一样被查询、修改和删除。使用视图有如下优点。
(1)为用户集中数据,简化用户的数据查询和处理。当用户所需要的数据是来自于几
个表时,定义视图可以将它们集中在一起,从而方便用户的数据查询和处理。
(2)屏蔽数据的复杂性。用户无须了解数据库中复杂的表结构,并且数据库表的更改
也不影响用户对数据库的使用。
(3)简化用户权限的管理。只需授予用户使用视图的权限,而不必指定用户只能使用
数据库的特定列,同时增加了数据的安全性。
(4)便于数据共享。多个用户不必各自定义和存储自己所需的数据,可共享数据库中
的数据,这样同样的数据只需要存储一次。
(5)通过视图可以重新组织数据以便输出到其他应用程序中。
5.4.2 视图的创建
视图是数据库的一个对象。在创建视图前,使用 CREATE VIEW 语句可确保创建视图
的用户被数据库所有者授权,并且有权操作视图所涉及的表或其他视图。可以通过界面或
使用 T-SQL 语句来创建视图。
1.在企业管理器中创建视图
下面以在 zggl 数据库中创建视图 zg_002(描述 002 部门职工信息)说明在企业管理器
中创建视图的过程。
第 1 步,打开企业管理器,右击数据库 zggl,在弹出的快捷菜单上选择“新建”→“视
图”。出现如图 5.22 所示对话框。
图 5.22 “添加表”界面
第 2 步,右击所出现的窗口的第 1 个子窗口,在弹出的快捷菜单中选择“添加表...”
菜单项,出现“添加表”对话框,如图 5.23 所示。
第 3 步,在图 5.23 所示的“添加表”对话框中选择与视图相关联的表、视图或函数,
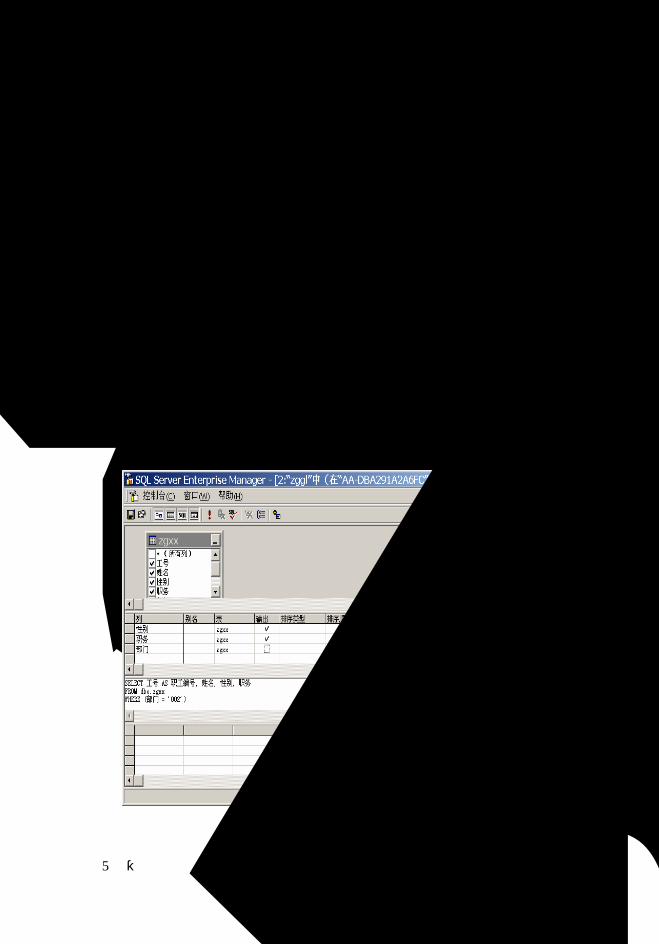
第 5 章 SQL Server 2000 -97-
可以用 Ctrl 或 Shift 键进行多选,选择完毕后,单击“添加”按钮,如图 5.24 所示。
图 5.23 “添加表”对话框 图 5.24 选择表或视图
第 4 步,在图 5.22 图所示的窗口的第 2 个子窗口选择创建视图所需要的字段,可以指
定列的别名、排序方式和准则(本例中指定“部门”字段的准则为 002)等。如图 5.25 所
示。在图中,可以看到这一步所选的字段、准则等情况相对应的 SELECT 语句将会自动显
示在第 3 个小窗口中。所以也可以在该小窗口中直接输入 SELECT 语句。
图 5.25 选择列
第 5 步,选择完毕后,单击“保存”按钮,出现“另存为”对话框,见图 5.26。在其

- 98 - 电子政务数据库基础
中输入视图名,单击“确定”按钮,即完成对视图的创建。
视图创建成功后,可以查看其结构和内容:
在企业管理器中,展开数据库 zggl,展开视图,
右击视图 zg_002,在弹出的快捷菜单上(见 5.27
图)选择“设计视图”可以查看并修改视图结构,
见图 5.25;选择“打开视图”→“返回所有行”
可以查看视图中的数据内容,见图 5.28 所示。
图 5.27 视图快捷菜单
图 5.28 查看视图中数据
另外还可以通过视图向导创建视图。在企业管理器中,选择“工具”菜单中的“向导”
菜单项,出现“选择向导”对话框。在对话框中,“展开数据库”,选择“创建视图向导”
项,单击“确定”按钮,出现欢迎使用向导界面,以后按照向导引导的步骤逐步进行。
图 5.26 保存视图


- 100 - 电子政务数据库基础
(3)删除数据。使用 UPDATE 语句可以通过视图删除表中的数据。
也可以通过企业管理器的界面来完成对视图的更新操作,操作方法同对表数据操作方
法一样。
3.删除视图
删除视图也可以用两种方法进行:界面方法和命令方法。界面方法删除视图同界面方
法删除表方法一样。
使用 DROP VIEW 语句来删除视图。格式为:
DROP VIEW 视图名 1[,视图名 2⋯]
例 5.12 删除视图 zg_002。
USE zggl
DROP VIEW zg_002
5.5 索引和数据完整性
5.5.1 索引
索引是根据表中一列或若干列按照一定的顺序建立的列值与记录行之间的对应关系
表。
在 SQL Server 2000 支持在任何列上定义索引,按索引的组织方式,可将 SQL Server
索引分为两类:聚集索引和非聚集索引。
聚集索引是将数据行的键值在表内排序并存储对应的数据记录,这样数据表的物理顺
序和逻辑顺序一致。一个表中只有一个聚集索引。
非聚集索引是与数据行完全独立的结构。非聚集索引中存放了数据行的键值,每个键
值通过指针指向表中包含该键的数据行。表中的数据行不按聚集索引指定的顺序存储。一
个表中可以有多个非聚集索引。
如果一个表既要创建聚集索引,又要创建非聚集索引,则要先创建聚集索引,然后创
建非聚集索引。因为创建聚集索引将改变数据行的物理存放顺序。
1.索引的创建
在 SQL Server 中,可以通过企业管理器创建索引,也可以利用 SQL 命令,通过查询分
析器来创建索引。
(1)通过企业管理器创建索引。以在数据库 zggl 的表 zgxx 中创建索引为例。
第 1 步,进入企业管理器,打开 zggl 数据库。
第 2 步,右击 zgxx 表,在弹出的快捷菜单上,选择“设计表”菜单项,出现 zgxx 表
设计器窗口。
第 3 步,右击表设计器窗口,在弹出的快捷菜单上选择“索引/键”菜单项,出现 zgxx
属性对话框。如图 5.29 所示。第 4 步,在“索引/键”选项卡上单击“新建”按钮,选定新

第 5 章 SQL Server 2000 -101-
索引的名称(可以采用系统默认的名称,也可以自定);在“列名”下选择要创建索引的列,
最多可选择 16 列。选择以后,单击“关闭”按钮即创建好索引,见图 5.30 所示。对于 UNIQUE
索引,是指表中任意两行的索引值不能相同。
图 5.29 表 zgxx 的属性对话框 图 5.30 为表 zgxx 创建新索引
(2)通过命令来创建索引。用 SQL 命令创建索引已在第 4 章介绍过了,在 SQL Server
2000 中,只需要把创建索引的 T-SQL 语句输入到查询分析器中并执行即可。
2.索引的删除
删除索引也有两种方法,即界面删除和命令删除。
(1)通过界面删除索引
第 1 步,进入企业管理器,建立和相应数据库的信任连接。
第 2 步,进入要删除索引的表设计器,右击表设计器,在弹出的快捷菜单中选择“属
性”菜单项。
第 3 步,在打开的“属性”窗口,选择“索引/键”选项卡,从“选定的索引”列表中
选择要删除的索引,单击“删除”按钮。
(2)命令删除索引
同命令创建索引方法类似。
5.5.2 默认值约束及默认值对象
前面介绍过,数据库对象中有一个“默认”对象,它是用来为字段提供默认值的。为
一个字段设置默认值可用两种方法,在定义或修改表结构时,设置默认值约束;先定义默
认值对象,然后将该对象绑定到表中相应的字段。
(1)在表中创建及删除默认值约束
① 默认值约束的定义。在创建表时定义:
- 102 - 电子政务数据库基础
CREATE TABLE 表名
(列名 1 列的数据类型 [NULL|NOT NULL][PRIMARY KEY][DEFAULT 默认值约束
表达式],
列名 2 列的数据类型 [NULL|NOT NULL][PRIMARY KEY][DEFAULT 默认值约束
表达式],
� � � � )
例 5.13 在定义表时定义一个默认值约束。 USE zggl /*使数据库 zggl 成为当前数据库 */ CREATE TABLE zgxx1(工号 CHAR(6)NOT NULL, 姓名 CHAR(8)NOT NULL, 性别 BIT DEFAULT1, /*定义性别的默认值为 1*/ 出生时间 SMALLDATETIME NOT NULL, 职务 CHAR(10)NULL, 部门 CHAR(16)NOT NULL, 备注 TEXT NULL) 例 5-14 在修改表结构时定义一个默认值约束。 USE zggl /*使数据库 zggl 成为当前数据库 */ ALTER TABLE zgxx1 ADD 学历 CHAR(10)DEFAULT’本科’/*定义新增字段学历的默认值为本科*/ ② 删除默认值约束。默认值约束可在企业管理中删除。 打开企业管理器,进入需要删除默认值约束的表的表设计器,单击对应的列,删除对
应的默认值约束,单击表设计器的“关闭”按钮,在弹出的“SQL Server 企业管理器”对
话框中,单击“是(Y)”即可。见图 5.31。
图 5.31 SQL Server 企业管理器对话框
(2)默认值对象的定义、使用和删除 通过企业管理器来定义默认值对象。以为表 zgxx1 的“学历”字段定义一个默认值为
“本科”为例。进入企业管理器,连接相应的数据库 zggl;展开数据库,右击“默认”,在
出现的快捷菜单中选择“新建默认”,进入“默认属性”对话框如图 5.32 所示。在对话框
中输入默认值对象名 xl_default 及默认值“本科”,单击“确定”按钮即定义了一个默认值
对象。

第 5 章 SQL Server 2000 -103-
图 5.32 默认属性对话框
通过企业管理器将一个字段绑定到定义的默认值对象。将表 zgxx1 的“学历”字段绑
定到默认值对象 xl_default 的步骤如下。
第 1 步,打开企业管理器,进入 zgxx1 表设计器。
第 2 步,定位光标到学历字段,从默认值对象下拉表中选择对应的默认值对象即可。
(3)使用 SQL 语句创建和绑定默认值对象
① 定义默认值对象
命令格式:
CREATE DEFAULT 默认值对象名 AS 表达式
其中:表达式只能是常量表达式,不能含有字段名或其他的数据库对象。默认值对象
必须与列的数据类型相兼容。CREATE DEFAULT 命令应该是批命令的第一条语句。
② 绑定默认值对象
默认值对象定义以后,若要使其发挥作用,应该将其绑定到相应的列,可以通过系统
存储过程 sp_bindefault 来完成。
基本命令格式:
EXECUTE sp_bindefault �默认值对象名� 注意不能将默认值对象绑定到带有 IDENTITY 属性的列或已经有了默认值约束的列。 例 5.15 用命令方式将 zgxx1 表的学历字段的默认值设置为“本科”。 CREATE DEFAULT xl_default as ’本科’ GO USE zgll EXECUTE sp_bindefault �xl_default�,�zgxx1.[学历]� GO
(4)默认值对象的删除 在删除一个默认值对象之前,首先要解除表字段和该对象之间的绑定关系,然后再删
除。

- 104 - 电子政务数据库基础
① 界面删除默认值对象
第 1 步,进入企业管理器的 zgxx 表设计器,定位学历字段,删除默认值下拉框的对象
名,即解除了学历字段和默认值对象的绑定关系。
第 2 步,在企业管理器中,展开数据库 zggl,展开“默认”,右击 xl_default,在弹出
的快捷菜单中选择“删除”,系统弹出“除去对象”对话框,单击“全部除去”按钮,则就
删除了所选择的默认值对象。
② 命令删除默认值对象
第 1 步,利用系统存储过程解除绑定关系。
命令格式:
EXECUTE sp_unbindefault ’表名.[列名] ’
第 2 步,删除默认值对象。
命令格式:
DROP DEFAULT 默认值对象名
例 5.16 解除默认值对象 xl_default 与 zgxx1 的学历字段的绑定关系,并删除它。
USE zggl
EXECUTE sp_unbindefault ’zgxx1.[学历]’
DROP default xl_default
GO
5.5.3 数据完整性
数据完整性是指数据库中的数据在逻辑上的一致性和准确性,一般包括 3 种。
(1)域完整性。又称列完整性,指给定列的输入的有效性。可以通过定义相应的规则、
约束、默认值对象等方法实现。
(2)实体完整性。又称行的完整性,要求表中有一个主键,其值不能为空且能惟一地
表示对应的实体。通过索引、UNIQUE 约束、PRIMARY KEY 约束或 IDENTITY 属性可实
现数据的完整性。
(3)参照完整性。参照完整性又称引用完整性。参照完整性保证主表(被参照表)中
的数据与从表(参照表)中数据的一致性。通过定义外键(外码)与主键(主码)之间或
外键与惟一键之间的对应关系来实现参照完整性。参照完整性确保键值在所有表中一致。
如果两个表之间定义了参照完整性,则要注意发下几点。
① 从表不能引用不存在的键值。
② 如果主表中的键值更改了,那么整个数据库中,对从表中该键值的所有引用要进行
一致的更改。
③ 如果主表中没有相关联的记录,则不能将记录添加到从表。
④ 如果要删除某一记录,应先删除从表中与该记录相匹配的记录。
这里仅介绍界面方式实现完整性约束的方法。
(1)域完整性的实现
SQL Server 2000 通过定义约束、规则等对象来实现数据完整性,以保证数据的正确性、
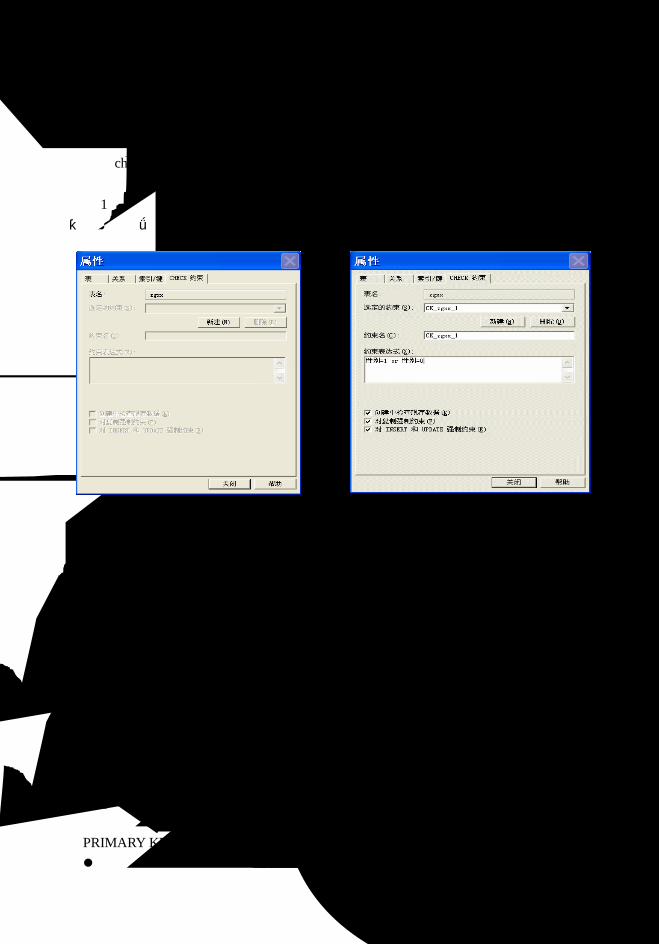
第 5 章 SQL Server 2000 -105-
相容性和一致性。这里仅介绍约束的定义和删除。
① check 约束的定义与删除。check 约束实际是字段输入内容的验证规则,表示一个字
段的输入内容必须满足 check 约束的条件,若不满足,则数据无法正常输入。创建 check
约束有两种方法:通过企业管理器创建与删除 check 约束和利用 SQL 语句在创建表或修改
表时创建 check 约束。
② 利用企业管理器定义 check 约束和删除。过程如下:
第 1 步 进入企业管理器,进入需要建立 check 约束的列所在的表设计器,单击鼠标右
键,在弹出的快捷菜单中选择“CHECK 约束”,进入“属性”窗口,见图 5.33 所示。
图 5.33 CHECK 约束选项卡属性窗口 图 5.34 CHECK 约束输入窗口
第 2 步 选择“CHECK 约束”选项卡,选择“新建”,进入 CHECK 约束的输入窗口,
输入约束表达式和约束名称,选择“关闭”,见图 5.34。要删除 CHECK 约束,只要进入
CHECK 约束窗口,见图 5.33,删除相应的约束表达式,然后单击“关闭”。
(2)实体完整性的实现
通过选择表中的一列或多列作为主键可以实现表的实体完整性,可以通过定义
PRIMARY KEY 约束来创建主键。一个表只能有一个 PRIMARY KEY 约束,而且 PRIAMRY
KEY 约束中的列不能取空值。由于 PRIMARY KEY 约束能够确保数据的惟一,所以经常用
来定义表示列。当为表定义 PRIMARY KEY 约束时,SQL Server 2000 为主键创建惟一索引,
实现数据的惟一性,在查询中使用主键时,该索引可用来对数据进行快速访问。如果
PRIMARY KEY 约束是由多列组合定义的,则某一列的值可以重复,但 PRIMARY KEY 约
束定义中所有列的组合值必须惟一。
如果要保证非主键列不输入重复值,可以在该列上定义惟一约束(UNIQUE 约束)。例
如在 zggl 数据库的 zgxx 表中,“工号”列为主键列,在表中增加一列“身份证号码”,则
可以定义一个惟一约束来要求表中的“身份证号码”列的取值是惟一的。
PRIMARY KEY 约束和 UNIQUE 约束的主要区别:
� 一个数据表中只能有一个 PRIMARY KEY 约束,但一个表中可根据需要对不同的

- 106 - 电子政务数据库基础
列创建若干个 UNIQUE 约束;
� PRIMARY KEY 列的值不允许为空值,而 UNIQUE 列的值可以取空值;
� 一般创建 PRIMARY KEY 约束时,系统会自动产生索引,索引的默认类型为聚集
索引。创建 UNIQUE 约束时,系统会自动产生一个 UNIQUE 索引,索引的默认类
型为非聚集索引。
PRIMARY KEY 约束和 UNIQUE 约束共同点是:两者均不允许表中对应列存在重复值。
① 利用企业管理器创建和删除 PRIMARY KEY 约束。利用企业管理器创建 PRIMARY
KEY 约束对 zgxx 表的工号建立 PRIMARY KEY 约束过程如下:
第 1 步,选择 zgxx 表图标,单击鼠标右键,打开 zgxx 表设计器,进入表设计器界面。
第 2 步,选择“工号”所在的行,单击主键图标,在“工号”所在行的前面出现一主
键图标。
如果主键为多列组成,则先选中这些列所在的行,然后单击主键图标。创建主键时,
系统自动创建一个名称以“PK_”为开头,后跟表名的主键索引。可以修改默认主键名称。
② 用企业管理器删除 PRIMARY KEY 约束。删除上面对“工号”列建立的 PRIMARY
KEY 约束步骤如下:
第 1 步,选择 zgxx 表,点击鼠标右键,打开表设计器,进入表设计器界面。
第 2 步,选择“工号”所在的行,单击工具栏上的“设置主键”图标,则取消了原来
定义的主键。
③ 利用企业管理器创建和删除 UNIQUE 索引。利用企业管理器对 zgxx 表的“身份证
号码”列创建 UNIQUE 索引过程如下:
第 1 步,选择 zgxx 表,点击鼠标右键,打开表设计器,在表设计器中点击鼠标右键,
在弹出的快捷菜单中选择“属性”菜单项,出现属性窗口,在窗口中选择“索引/键”选项
卡,如图 5.29 所示。
第 2 步,在图 5.29 所示的属性窗口,选择“新建”按钮,键入新建索引的名称或使用
系统默认的名称。在“列名”下拉框中选择“身份证号码”,并设置索引顺序,将“创建
UNIQUE 约束”复选框设置为选中状态。然后单击“关闭”按钮。
④ 利用企业管理器删除 UNIQUE 索引。进入图 5.29 所示的属性窗口,在“选定的索
引”中选中要删除的 UNIQUE 约束的索引名,单击“删除”按钮。
(3)参照完整性的实现
对两个相关联的表(主表和从表)进行数据插入和删除时,通过参照完整性可以保证
它们之间数据的一致性。
利用 FOREIGN KEY 定义表的外码,PRIMARY KEY 或 UNIQUE 约束定义主表中的
主码或惟一码(不能为空)。可实现主表和从表之间的参照完整性。先定义主表主码或惟一
码,再定义对从表的外码约束。
① 利用企业管理器定义表间参照完整性
若要建立 zgxx 表和 zggz 表(存放职工的工资信息)之间的参照完整性。具体步骤如
下:
第 1 步,按照前面介绍的方法定义主表的主码(或惟一码)。此处定义 zgxx 表中的工
号字段为主码。
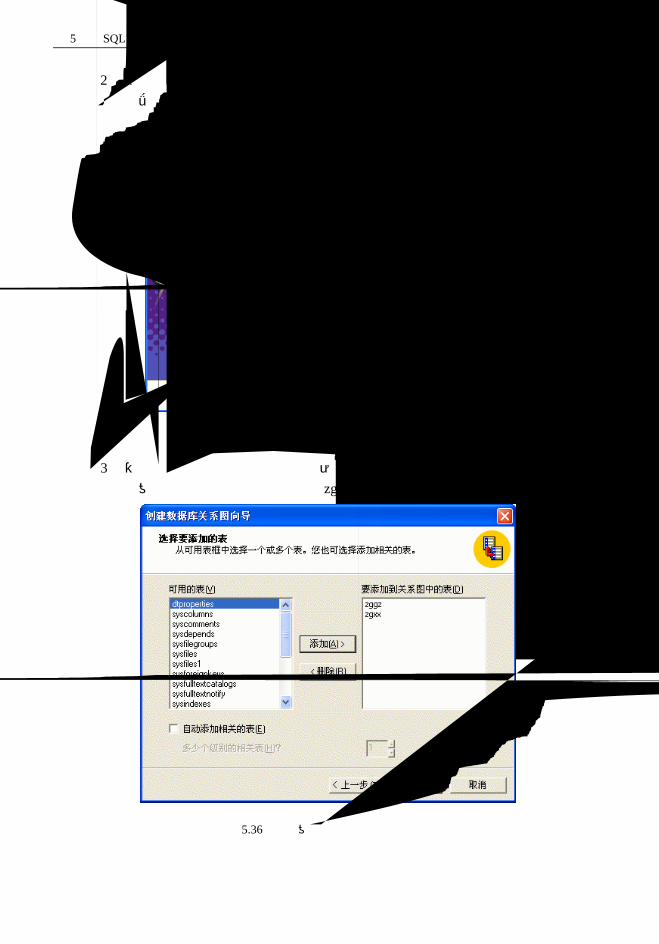
第 5 章 SQL Server 2000 -107-
第 2 步,选择企业管理器目录树中 zggl 数据库目录下的“关系图”图标并点击鼠标右
键。在弹出的快捷菜单上选择“新建数据库关系图”菜单项。进入如图 5.35 所示的欢迎界
面。
图 5.35 创建数据库关系图的欢迎界面
第 3 步,单击欢迎界面中的“下一步”按钮,进入如图 5.36 所示的界面,从可用表中
选择要添加到关系图中的表。本例中选择了 zgxx 表和 zggz 表。
图 5.36 创建关系图的“添加表”界面
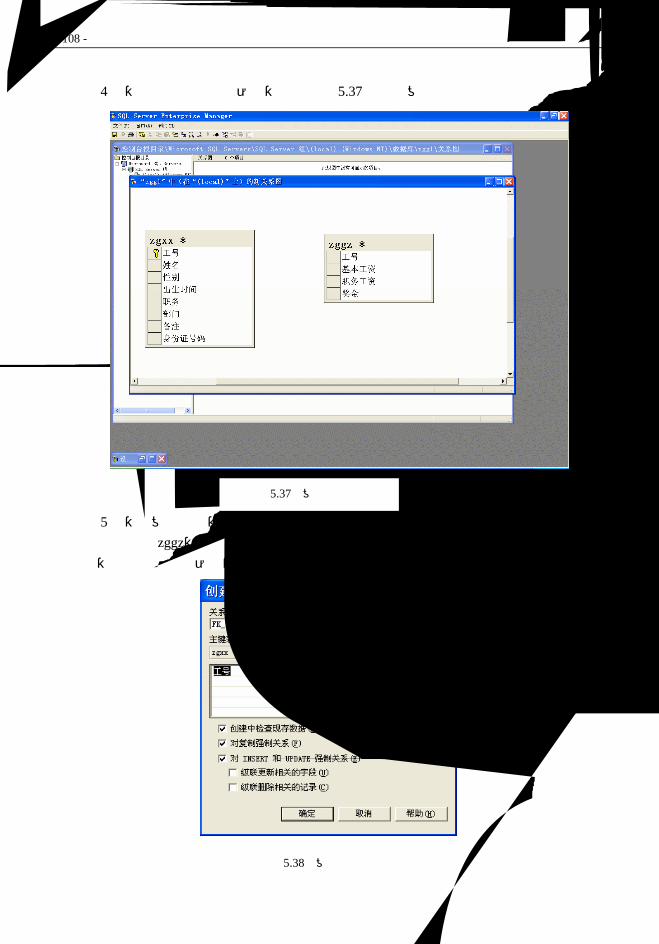
- 108 - 电子政务数据库基础
第 4 步,单击“下一步”按钮,进入如图 5.37 所示的关系图界面。
第 5 步,在关系图上,将鼠标指向主表的主键并拖动到从表。本例中,将 zgxx 表的工
号字段拖到从表 zggz,出现如图 5.38 的关系创建界面。 在其中选择主表中的主键和从表
的外键,单击“确定”按钮,出现图 5.39 所示关系图。
图 5.38 关系设置界面
图 5.37 关系图界面
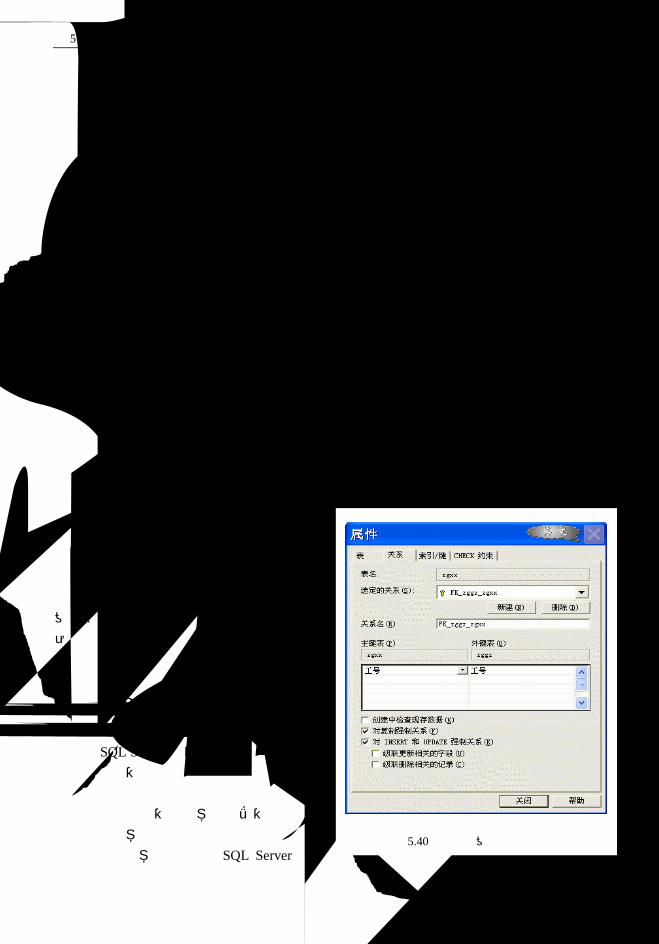
第 5 章 SQL Server 2000 -109-
图 5.39 主表和从表的参照关系图
第 6 步,关闭关系图界面,根据提示,将关系图的相关信息存盘,即创建了主表和从
表之间的参照完整性。
② 利用企业管理器删除表间参照完整性
删除前面建立的 zgxx 表和 zggz 表之间的参照关系步骤如下:
第 1 步,进入 zgxx 表设计器,在空白处
点击鼠标右键,在弹出的快捷菜单上选择“关
系”菜单项,出现如图 5.40 所示界面。
第 2 步,在图 5.40 所示的“属性”窗口
的“选定的关系”下拉列表中选择要删除的
关系,单击“删除”按钮。选择单击“关闭”
按钮。
5.6 存 储 过 程
在 SQL Server 中,可以定义子程序存放
在数据库中,这样的子程序就是存储过程。
存储过程也是数据库的对象之一。使用存储
过程有很多优点,如执行速度快,因为它在
服务器端执行;保证数据库的安全;自动完
成需要预先执行的任务等。SQL Server 共支
图 5.40 主从表关系的属性界面

- 110 - 电子政务数据库基础
持 5 种存储过程:系统存储过程、本地存储过程、临时存储过程、远程存储过程和扩展存
储过程。不同情况下执行不同的存储过程。
(1)系统存储过程。由系统提供的存储过程,可以作为命令执行各种操作,系统存储
过程定义在系统数据库 master 中,前缀为“sp_”。如前面我们用过的存储过程 sp_bindfault
和 sp_unbindefault。展开 master 和 msdb 数据库,展开存储过程,可以看到 SQL Server 带
有很多系统存储过程。若要了解系统存储过程的功能,请读者参考相关资料。
(2)本地存储过程。指在用户数据库中创建的存储过程,其名称不能用 sp_做前缀。展
开 zggl 数据库,展开存储过程,可以看到 zggl 数据库的本地存储过程。
(3)临时存储过程。属于本地存储过程。如果本地存储过程的名称前面有一个“#”,
该存储过程就称为临时存储过程,如果其名称前面有两个“#”,该过程为全局临时存储过
程,可以在所有的用户会话中使用。
(4)远程存储过程。远程存储过程指从远程服务器上调用的存储过程。
(5)扩展存储过程。在 SQL Server 环境之外执行的动态链接库称为扩展存储过程,其
前缀为“sp_”。Master 数据库中有很多扩展存储过程。创建存储过程也可以采用两种方法:
通过企业管理器和利用 SQL 语句。在此仅介绍通过企业管理器建立存储过程的方法:
① 企业管理器创建存储过程。以创建查询 pubs 数据库中所有男职工的信息的存储过
程为例说明过程:
第 1 步 打开企业管理器,展开数据库 zggl,在存储过程上单击右键,弹出如图 5.41
所示的快捷菜单。
图 5.41 存储过程的快捷菜单
第 2 步,单击“新建存储过程”,进入存储过程的属性窗口。在“文本”中输入要定义
的存储过程,输入完毕后,可以进行语法检查,然后按“确定”。也可以直接按“确定”按
钮,若有语法错误,会弹出错误信息提示框。
② 用命令方式创建和执行存储过程。用 CREATE PROCEDURE 语句来创建存储过程。
基本语法格式:
CREATE PROCEDURE 存储过程名
[{@参数 数据类型}][=DEFAULT][OUTPUT]

第 5 章 SQL Server 2000 -111-
AS SELECT 语句
其中:
存储过程名表示新建存储过程的名称;@参数是存储过程的形参,@作为第一个字符
来指定参数名称。创建存储过程时,可以定义一个或多个参数,在过程执行时则要提供相
应的值(实参)(除非已为该形参提供了一个默认值);数据类型是指参数的数据类型;
DEFAULT 表示参数的默认值;output 表示该参数是返回参数,返回值给调用该过程的
execute 语句;select 语句指明过程要执行的操作。CREATE PROCEDURE 语句必须是批处
理的第一条语句。
③ 存储过程的执行。使用 execute 语句来执行存储过程。
基本语法格式:
EXECUTE 存储过程名
[@参数]|@变量[output]|[default]
其中:
@参数=参数值是给在存储过程创建语句中定义的形参传递实参,@变量用于保存
output 参数返回的值,DEFAULT 表示不提供实参,使用相应的默认值。
例 5.16 创建从 SQL Server 2000 带的示例数据库 pubs 的 authors 表中查询作者信息的
存储过程,并执行。
定义存储过程:
USE PUBS
GO
CREATE PROCEDURE auth
as
SELECT * FROM authors
执行存储过程:
USE pubs
EXECUTE auth
查询结果如图 5.42 所示。
上面的存储过程中没有使用参数。下给出使用参数的例子。
例 5.17 从数据库 pubs 的表 authors 查询某个人的电话和地址。
定义存储过程:
USE pubs
GO
CREATE PROCEDURE auth1
@auname VARCHAR(40)
AS
SELECT phone,address FROM authors where au_lname=@auname
存储过程创建完以后,可以进行修改。一是直接在企业管理中进行修改,在企业管理
中,选择要修改的存储过程并双击,打开存储过程属性窗口即可进行修改;二是利用 alter
procedure 进行修改。

- 112 - 电子政务数据库基础
图 5.42 存储过程执行结果
④ 删除用户存储过程。使用 DROP PROCEDURE 语句来删除存储过程,基本格式:
DROP PROCEDURE 存储过程名
可以同时删除若干个存储过程。
例 5.18 删除上例的 auth 存储过程
USE pubs
DROP PROCEDURE
当然,也可以在企业管理器中删除存储过程,读者可以自己试一试。
还有一种特殊的存储过程,它和表的关系密切,用来保护表中的数据,这种存储过程
称之为触发器。当某个操作影响到触发器所保护的数据时,触发器自动执行,保护数据。
利用触发器可以保证数据库中数据的完整性、多个表之间数据的一致性。
对表数据的操作有插入、删除和修改三种,所以,相应的触发器也有三种:INSERT、
DELETE 和 UPDATE。一个表中可以同时存在多个触发器。触发器可以用 SQL 语句 CREATE
TRIGGER 和企业管理器来创建,感兴趣的读者可以参考相关的资料。
5.7 备份与还原
尽管为了保证数据库的安全性和完整性采取了各种措施,但是总会有些故障造成事务
运行的异常中断,如媒体故障、软件出错、病毒以及恶意攻击等,使得数据的正确性受到
影响,甚至破坏数据库,造成数据库中数据部分或全部丢失。所以一般的数据库管理系统
都有将数据库从错误状态还原到某一正确状态的功能,即还原功能。要还原数据库,先要
做备份,即制作数据库的副本。SQL Server 2000 的备份和还原功能为数据库中的数据提供
了保护作用。
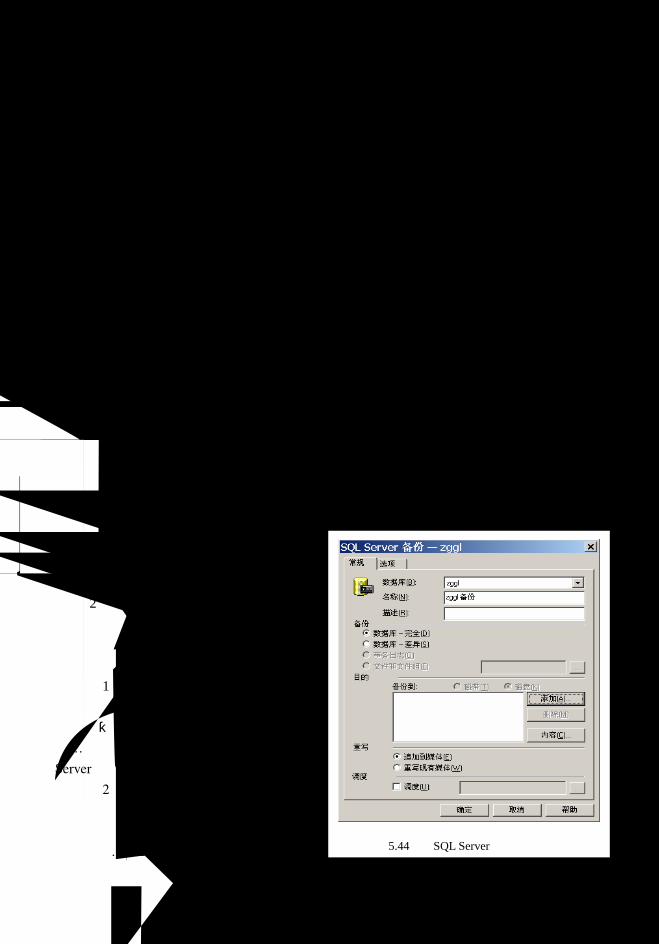
第 5 章 SQL Server 2000 -113-
1.备份
在对数据库进行备份之前,要创建用来存储备份数据的备份设备。备份设备可以是磁
盘、磁带或命名管道,分为命名备份设备和临时备份设备。所谓命名备份设备是指操作系
统可以用备份设备的逻辑名来访问,比较方便;而只能用物理名称访问的备份设备就是临
时备份设备。
(1)创建命名的备份设备。要使用命名备份设备,必须先创建它。可以通过企业管理
器来进行。步骤如下:
第 1 步 以系统管理员账号登录 SQL Server 2000。
第 2 步 打开企业管理器,展开相关的服务器组和服务器,展开“管理”,在“备份”
上单击鼠标右键,选择“新建备份设备”,出现图 5.43 所示的备份设备属性对话框。
图 5.43 “新设备”对话框
第 3 步 在出现的对话框中,输入备份
设备的逻辑名和完整的物理路径,单击“确
定”即创建了一个命名备份设备。
(2)利用企业管理器进行备份。进行数
据库备份可以通过界面和命令两种方式,其
中界面又包括企业管理器界面和备份向导。
这里仅介绍用企业管理器进行备份的方法。
第 1 步 进入企业管理器展开服务器组
和服务器,展开“管理”,在“备份”上点
击右键,在弹出的菜单上选择“备份数据
库�”菜单项,出现如图 5.44 所示的“SQL Server 备份”对话框。
第 2 步 在上步的对话框中选中要备份
的数据库名,输入备份的目的、备份的描述、
备份的类型等,若需要的备份设备不在,单
击“添加�”按钮,弹出“选择备份目的”
图 5.44 “SQL Server 备份”对话框
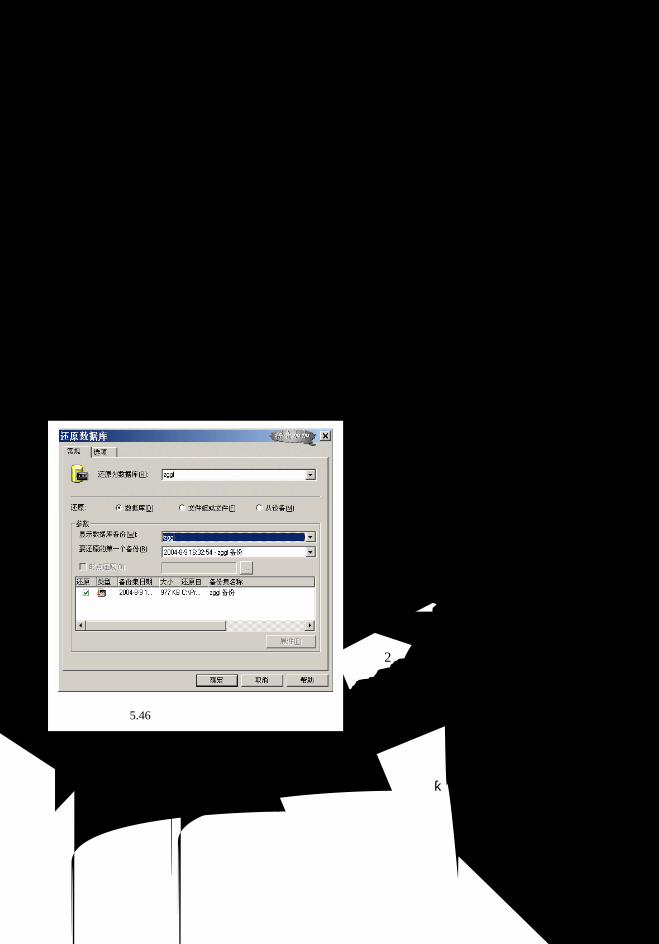
- 114 - 电子政务数据库基础
对话框。图 5.45 所示。
图 5.45 “选择备份目的”对话框
第 3 步 若要备份到临时备份设备,选择“文件名”单选钮,在文本框中输入完整的文
件路径或通过单击文本框右边进行路径选择;若使用命名备份设备,选择“备份设备”单
选钮,此时,也可以新建一个备份设备,
选择“<新建备份设备>”,在随后出现的
“备份设备属性”对话框输入相应的内
容。
第 4 步 完成上述整个过程后,在
“SQL Server 备份”对话框中单击“确
定”,系统开始执行备份操作,在执行过
程中,会出现一个“备份进度”对话框。
备份结束后,在随后出现的“SQL Server
企业管理器”消息提示框中单击“确定”
即可。
2.还原
这里只介绍使用企业管理器还原数
据库的过程:
第 1 步 打开企业管理器,选择菜单
项“工具”→“还原数据库”,出现如图 5.46 所示的“还原数据库”对话框。
第 2 步 单击“常规”选项卡,选择要恢复的数据库和相应的数据库备份,单击“确定”,
系统开始还原数据库,并显示还原进度信息,还原操作结束后,单击出现的“SQL Server
企业管理器”的消息框中的“确定”,结束还原过程。
图 5.46 “还原数据库”对话框
第 5 章 SQL Server 2000 -115-
5.8 本 章 小 结
SQL Server 是微软推出的大型数据库系统,是目前最常用的网络数据库系统之一。本
章简单介绍了 SQL Server 的最高版本 SQL Server 2000 的特性、认证和相关概念之后,就
一个实例详细介绍了在 SQL Server 2000 中数据库、表和视图的创建、删除和修改的操作方
法以及相应的语法结构,介绍了 SQL Server 2000 中数据完整性的概念和分类以及在 SQL
Server 2000 中如何保证数据的完整性,另外还简单介绍了存储过程的相关内容,由于 SQL
Server 提供了强大的备份和还原功能,所以本章最后还介绍通过企业管理器备份和还原数
据库的过程。
5.9 本 章 习 题
1.SQL Server 2000 有哪些数据库对象?
2.如何对 SQL Server 2000 的数据库对象进行引用?
3.SQL Server 2000 4 个系统数据库分别是什么?各用于存放什么样的信息?
4.在 zggl 数据库中建立一个表 zgll 用于存放职工的履历信息并定义其主键。zgll 的表
结构如下:
列名 数据类型 长度 是否允许为空 默认值
工号 Char 6 × 无
起始至终止年月 Char 20 × 无
工作单位 Char 20 × 无
证明人 Char 4 × 无
备注 Text 16 v 无
5.用命令和界面两种方法在上题建立的 zgll 表中输入若干条记录,记录内容自定。
6.结合前一章的内容,对 zgxx 表和 zgll 表进行各种查询。
7.索引的概念和作用分别是什么?
8.什么是数据的完整性?各有哪些类型?
9.在 SQL Server 2000 中如何实现数据完整性要求?
10.用命令方式创建存储过程并调用。
5.10 本章参考文献
1.张龙祥,黄正瑞,龙军·数据库原理与设计·人民邮电出版社,2002.7

- 116 - 电子政务数据库基础
2.陆昌辉,吴晓华·SQL Server 2000 开发人员指南·宇航出版社,北京希望电子出
版社,2002.6
3.曾国清·Windows 2000+ASP+SQL Server·中科多媒体电子出版社,2002.7
4.郑阿奇,刘启芬,顾韵华·SQL Server 实用教程·2002.8
5.潘郁等·电子商务数据库技术·北京大学出版社,2002.1

第 6 章 电子政务数据库系统设计
前面的章节中,已经详细介绍了数据库系统的基本设计理论和 SQL。如何将这些理论运
用到电子政务数据库的设计和实现过程中,是本章关注的重点。
作为电子政务系统的数据组织基础,政务数据库与传统数据库具有很多相似之处。特别
是在处理一些结构化的数据方面,传统的关系数据库理论仍然具有很好的指导意义。但是,
由于政务数据库目前的发展方向是建立在以 Internet 为中心的平台上,因此也具有非常独特
的数据处理需求。
数据库系统作为目前大型系统的主要构成部分,它的开发过程遵循一般的系统开发指导
方法,政务数据库系统开发也不例外。遵循信息系统生命周期和数据库生命周期,政务数据
库系统的开发一般可以分为概念设计、逻辑设计、物理设计以及系统的实现。
电子政务系统的建设已经历经了多年发展,但由于种种原因,形成了严重的“信息孤岛”
现象,各个地区的政府部门中存放了大量无法共享的数据,既造成了信息资源的浪费,又严重
阻碍了政府部门效率的提高,与电子政务建设的初衷不相符合。因此,有必要探索一条道路,
建设一个可以跨平台使用的电子政务平台数据交换中心,使电子政务的应用与其底层的数据结
构和存储方式无关,既可以实现数据的无缝交换和共享访问,保证各业务系统的有效协同,同
时又能保证各应用系统的相互独立性和低耦合性,从整体上提高系统运作效率和安全性。
本章主要内容:
� 电子政务数据库的特点
� 电子政务数据库概念设计
� 电子政务数据库概念设计和物理设计
� 电子政务平台数据中心
6.1 电子政务数据库的特点
电子政务数据库与传统数据库有很多类似之处。它作为电子政务平台的数据基础,既负
责存储和处理一些结构化非常强的业务数据,同时也要处理诸如图形图像、语音输入等多媒
体信息。为了更好地开展电子政务数据库系统的设计工作,除了要了解电子政务数据库的一
些基本分类和建设现状,还要了解一般的数据库设计流程。
6.1.1 电子政务数据库的特点
1.电子政务数据库的分类
作为电子政务系统的数据组织基础,政务数据库与传统数据库具有很多相似之处。在政

- 118 - 电子政务数据库基础
府的人事管理、财务管理、档案管理和固定资产管理等业务中,其处理的对象大多是结构化
数据,通过关系数据库完备的关系理论和操作方法,这些业务数据的处理是相对容易的。但
是,随着以 Internet 为中心的电子政务系统应用的不断发展,对于诸如公文流转管理、会议
管理、日程管理、计划管理、信息送报等业务活动,关系数据库就显得比较简单,不利于表
达复杂的数据结构。为了处理图形、图像、声音、时间序列等非结构化数据,数据库技术衍
生出许多新的发展方向,如分布式数据库、多媒体数据库、面向对象的数据库等。
电子政务要向更高层次发展,就必须对政府数据库进行科学的分类管理。从政府信息资
源的性质来看,电子政务数据库可分为:保密性信息,主要指那些关系国计民生的重要数据;
公益性信息,主要包括气象、地震、水文、人口、自然资源等内容;商业性信息,包括商贸、
投资、金融、科技、人才、企业、产品、娱乐等具有商业开发价值的信息。从数据可发布的
对象来看,电子政务数据库分为政府机构内部数据、政府机构共享数据和社会共享数据。根
据数据库提供数据的性质,可以将政务数据库分为文件数据库、数值数据库、事实数据库、
多媒体数据库等类型。文件数据库指数据内容为各种文件资料的数据库,包括著录型数据库
和全文数据库。前者仅仅以简略形式记录存储文件的有关信息,提供查找文件和档案的线索,
后者则存储文献全文或其主要部分,用户可以从中直接检索出所需的全文信息。数值数据库
指数据内容以自然数值形式为主,主要记录和提供特定事务的性能、数量特征等信息的数据
库。通过数值数据库,可以进行各种统计分析,定量研究,管理决策和预测,因此建立数值
数据库是政府部门实现宏观调控和微观管理的基础信息设施。事实数据库指数据内容既有数
字,又有文字,共同描述和反映有关事务的描述性的参考数据库。这些数据库是政府部门了
解民情的重要工具,因此需要长期不懈地加以建设。相对传统的数据库而言,多媒体数据库
将图像、声音、文字、动画等多种媒体数据和为一体,统一进行存取、管理和应用,从而更
加生动和全面地描绘客观世界。
从现阶段电子政务建设的规划来看,电子政务数据库主要是按照重点行业来划分的。这
种划分是在部门分割的基础上形成的,具有便于管理的特点,但是却不利于信息共享。
2.电子政务数据库的建设现状
通过十几年的信息化建设,电子政务数据库已经初具规模,从最初的仅能提供数据存储、
文档存储服务,发展到能够提供联网和远程访问服务。同时,数据库系统的应用形式也从面
向小范围的集中式结构发展为更复杂的网络化结构,并与许多其他新兴的计算机技术和管理
思想逐渐融合,向提供辅助决策功能的智能化数据库方向发展,为电子政务的应用提供了良
好的基础。但是,在建设和发展过程中,仍然存在很多突出的问题,如:
(1)部门发展不均衡。由于国内经济发展不均衡,发达地区和落后地区在政府信息化建
设及社会信息基础设施建设方面差距巨大。部分发达地区和某些重要政府职能部门,如海关,
税务,公安等信息化建设较为完善,人员素质较高,电子政务的基础设施较好,因而数据库
建设也相对成熟。而在许多经济欠发达的中小城市,大量的公文流转,业务处理仍然靠纸质
+电话方式进行。不同的政府部门之间进行信息交流时,仍靠电话传真、传统的邮寄和专人
投递。现代政府管理理念和信息化知识更是缺乏,电子政务建设资金紧张,IT 基础设施极为
薄弱。
(2)缺乏宏观调控机构,“信息孤岛”现象突出。政府部门由于采用条块分割的二维模

第 6 章 电子政务数据库系统设计 - 119 -
式,网络之间不能互联互通,没有统一的电子政务数据平台实现业务协同和资源整合,一方
面导致大量的数据以不同的格式分散存在于各个政府部门的数据库和应用系统中,数据互不
共享,无法为领导和公务员提供有效的政务分析和决策支持等服务,造成了信息资源的荒置
和浪费,另一方面无法实现一站式办公,行政效率低下,使得各个政府部门变成了一座座“信
息孤岛”,成为制约电子政务进程的瓶颈。
(3)数据处理流程复杂。数据处理流程依赖于政务部门业务流程的设置,而我国政府的
行政组织结构是由区域性的管理机构和行业性管理体系构成,这就造成了政务活动业务处理
流程非常复杂,因此数据处理流程也变得相对复杂。
6.1.2 信息系统生命周期
信息系统对于组织相关的所有信息资源进行收集、管理、使用和传播。在 20 世纪 60 年
代,信息系统主要是指文件系统,但从 20 世纪 70 年代开始,数据库系统逐渐成为信息系统
的主要组成部分。一个计算机化的环境包括数据本身、DBMS(数据库管理系统)软件、计
算机系统的硬件和存储介质、对数据进行使用和管理的人员、存取和更新这些数据的应用软
件以及开发应用软件的编程人员。因此可以说,数据库系统已经成为大型组织信息系统的有
机组成部分。为适应这种系统,许多机构创建了 DBA(数据库管理员)的职位甚至专门的数
据库管理部门,以便对数据库的生命周期活动进行监控。数据库的生命周期与信息系统的生
命周期密切相关,本节首先介绍信息系统的生命周期。
通常我们把信息系统的生命周期称为宏观生命周期,把数据库系统的生命周期称为微观
生命周期。对于主要组成部分是数据库的信息系统,这两者之间的差别不是那么明显。宏观
生命周期通常包括如下几个阶段:
(1)可行性分析:主要对潜在的应用领域进行分析,确定信息收集和传播的经济效益、
进行初步的成本收益研究,确定数据和处理的复杂程度并设置应用的优先级别。
(2)需求收集和分析:通过和潜在用户进行交流从而确定他们的一些特殊问题和需求,
收集用户的详细需求。在这一阶段,要确定各应用相互间的依赖关系、通讯问题和报表程序。
(3)设计:这个阶段包含两方面,一是数据库系统自身的设计,一是对数据库进行使用
和处理的应用程序的设计。
(4)实现:对信息系统进行实现,装载数据库,实现并测试数据库事务。
(5)确认和测试:确认系统是否满足用户需求和性能指标。根据性能标准和行为说明对
系统进行测试。
(6)实施、运行和维护:在系统投入应用前应对用户进行培训。当确定所有系统功能都
可操作时,系统进入运行阶段。对于新出现的需求或应用需要重复上述步骤,直到系统中实
现了这些新的需求和应用。在运行阶段,系统的性能监控和维护工作都很重要。
6.1.3 数据库生命周期
与数据库应用系统(微观)的生命周期相关的活动包括:
(1)系统定义:对数据库系统、系统用户和系统应用的范围进行定义。确定各类用户的
不同界面、响应时间的约束及存储和处理需求。

- 120 - 电子政务数据库基础
(2)数据库设计:该阶段结束后,得到一个在选定的 DBMS 上关于数据库系统的完整的
逻辑和物理设计。
(3)数据库实现:该阶段包括确定概念数据库、外部数据库和内部数据库的定义、创建
空数据库文件及实现软件应用。
(4)装载和数据转换:通常有两种方式装载数据库,直接向数据库装载数据,或者把现
存文件转换成数据库系统格式。
(5)应用转换:把原来系统下的软件应用转换到新系统下。
(6)测试和确认:对信息系统进行测试并确认。
(7)运行:运行数据库系统及其相关应用。通常情况下,旧系统和新系统需要并行运行
一段时间。
(8)监控和维护:在运行阶段,不断对系统进行监控和维护。与此同时,数据内容和软
件应用都会不断增长和扩充,有时可能需要进行一些大的修改和重组。
上述第 2、3、4 阶段共同组成大型信息系统生命周期的设计和实现阶段的一部分。通常
组织中的大部分数据库都要经历上述生命周期的全过程,如果数据库和应用都是新的,则转
换阶段不需要。另外,由于每一阶段都会出现一些新的需求,因此不同阶段之间需要经常进
行相互反馈,图 6.1 描述了系统实现和调整的结果对概念设计和逻辑设计阶段的的影响。
6.1.4 数据库设计流程
数据库设计具有两个基本特点:一方面,数据库设计是硬件、软件、技术与管理的结合;
另一方面,数据库设计必须与应用系统相互结合。因此,如图 6.1 所示,我们可以把设计过
程看做两个并行的活动:第一个活动是进行数据库数据内容和结构设计,第二个活动则主要
和数据库应用的设计相关。这两个活动过程是密切相关的。
数据库设计遵循软件工程规范化设计方法,基本步骤如下:
(1)需求分析。这是解决“要求系统做什么”这个问题的阶段,也是整个设计的基础。
这一阶段比较困难,也很耗费时间,因为能否明确反映用户需求,将直接影响到之后的各个
设计阶段。
(2)概念结构设计。是整个数据库设计的关键。通过对用户需求进行综合、归纳、抽象,
形成一个独立于具体 DBMS 的概念模型。在这个阶段,通常使用一些高级数据模型,如前面
学过的 E-R 模型等。
(3)逻辑结构设计。这一阶段将设计好的基本 E-R 图转换成能够被所选择的 DBMS 支
持的结构数据模型,并对它进行优化处理。
(4)物理结构设计。根据物理存储结构、记录位置和索引设计存储数据库的规格,包括
存取方法和存取结构。
(5)数据库实施。运用 DBMS 提供的数据语言及相关的应用系统语言,根据逻辑设计和
物理设计的结果建立数据库,编写有关程序,组织数据入库。
(6)数据库运行和调试。拟定运行方案和调试计划,对数据库系统的运行进行有目的的
检测。数据库系统的设计突出了数据库设计的过程,其中应用系统的数据模型设计是整个设
计的根基。

第 6 章 电子政务数据库系统设计 - 121 -
6.2 政务数据库概念设计
从数据库设计的一般流程可以看到,后期的工作都要建立在前期的需求分析的基础上。
因此比较准确地把握用户的真实需求,是首先应当完成的工作。之后再利用一定的工具,将
现实世界的用户需求转换成数据库的概念模型。
数据内容和结构 数据库应用
阶段 1:需求收集和分析
阶段 2:概念数据库设计
阶段 3:DBMS 的选择
阶段 4:数据模型映射
(逻辑设计)
阶段 5:物理设计
阶段 6:系统实现和调试
数据需求
概念模式设计
(DBMS 无关)
逻辑模式设计和视图
(DBMS 相关)
内模式设计
(DBMS 相关)
DDL 语句
SDL 语句
处理需求
事务和应用设计
(DBMS 无关)
频率性
能约束
事务和应用实现
图 6.1 大型数据库设计流程

- 122 - 电子政务数据库基础
6.2.1 数据库调研
1.数据库初步调研
在有效设计数据库之前,要尽可能详细地了解和分析用户的需求和数据库的用途。前面
已经提到,这个过程是信息系统开发活动中最困难的任务之一。在软件工程中,常根据用户
需求的稳定性将信息系统分为两大类:预先指定的系统和用户驱动的系统。政务信息数据库
系统大多数属于用户驱动类型,因为它的需求是经常变动的。因此,必须发挥用户的积极性,
鼓励他们直接参与系统的分析与设计工作。实践证明,这样可以增加用户对未来交付系统的
满意程度,这种方式也被称为联合应用设计。
通常,这个阶段包括下面的活动:
(1)确定主要的应用领域和用户组。这些用户组是数据库的未来用户,或者他们的工作
将会受到数据库的影响。这个活动将分析组织机构和业务活动的情况,从而确定系统边界。
(2)通过多种途径,获得数据需求的第一手资料。获得资料的途径多种多样。首先可以
对已有的和应用相关的文档进行研究和分析,其次可以对当前的操作环境和信息的使用计划
进行研究,另外也可以从潜在的数据库用户那里获得针对某些问题的书面回答。一般可采用
跟班作业、专人介绍、调查问卷、咨询、收集原始记录等方法展开调查。
案例:如何通过会谈进行有效的需求调研
某市地区建设工程质量安全监督站(下面简称安检站)的业务主要是对全市的建设工程
质量、安全进行监督管理,反映到电子政务系统中来,就是对大量工程文件、文档、数据等
的集合进行处理。在这些文件中既有格式化的数据如工程登记表,也有非格式化材料如图片、
Word 文件、Excel 文件及其他文件等。文书工作繁杂、大量数据经常需要变更。这些问题严
重阻碍了办公效率的提高。针对这些问题,开发人员进行了有效的需求调研,为后期开发提
供了良好的基础。在初期数据调研阶段,主要采用了系统会谈的方式。
系统会谈
会谈是获得有关现行系统及其运作方式等情况的最重要的信息来源,因此开发人员首先
组织了几次局部会谈作为初步调研。虽然经常采用这种方法,但并非总能见效。参与会谈的
人员可能会感到分析人员对其现有工作带来了威胁,或者由于时间紧迫,匆匆结束,提供一
些不相干的信息,以下总结的是一些成功进行会谈的指导原则:
① 准备会谈,了解参与会谈的每个人的情况和在组织中的职能
② 设计人员自我介绍并概述会谈的目的和范围
③ 开始询问时,可以提一些部门或办公室的总体职能、组织形式、工作手段和处理过程
等概括性的问题,使参与者放松
④ 对于工作过程提一些专门的问题,了解需要改进部分的情况
⑤ 抓住由参与会谈者提出的主题和问题进一步讨论
⑥ 不要记太多笔记,以免分散与会人的注意力,可以采用录音和录像的方式辅助记录
⑦ 会谈结束时尽快总结这次会谈所收集的信息,提出下一步建议。
开发人员易犯的一种错误是没有了解工作方式和工作程序的细节情况,从而忽略了一些
隐藏的重要问题。分析员们应当问一些能发现事实的问题,以此加深对现有系统的理解。这
类问题不具有威胁性,还可能鼓励与会者检查自己的行为活动。发现事实的问题涉及工作量、

第 6 章 电子政务数据库系统设计 - 123 -
工作过程、数据、控制、组织因素等方面,下表 6-1 所示为安检站系统调研中上述问题的举例。
表 6-1 安检站系统初步调研
工作量 每月收到多少工程登记表?
每月有多少报表需要提交?
处理过程 组织一次质量安全检查活动经过哪些步骤?
参与各检测机构的资质审查和计量认证工作如何开展?
数据 工程登记表需要保存哪些数据?
对工程质量鉴定需要提交哪些材料?
控制 对保密信息的访问有什么防护措施?
哪些处理过程是用来确保申请者呈报的材料准确性的?
组织因素 安检站的工作流程由谁负责?
2.数据与数据流程分析
在系统调查中收集的大量的信息资料,基本上是由每个调查人员按组织结构或业务过程
收集的,它们往往只是从局部反映了某项管理业务对数据的需求和现有的数据管理状况,对
这些数据资料必须加以汇总、整理和分析,使之协调一致。这个过程称为数据与数据流程分
析,它的主要任务是数据汇总;数据流程分析;将数据及信息的内容、特征用数据字典的形
式进行定义:
(1)调查数据的汇总分析。系统调查掌握的资料可以分为三类:系统输入数据类(主要
指上报的报表),本系统内要存储的数据类(主要指各种记录文件),系统产生的数据类(主
要指系统运行所产生的各类数据)。这个过程分两步进行,首先从某项业务的角度对数据进行
分类整理,接着进行数据特征分析,包括分析数据的类型及长度、合理的取值范围、相关的
业务有哪些以及数据量大小(单位时间内的业务量、使用频率、存储和保存的时间周期等),
从而为以后的设计工作做准备。
(2)数据流程分析。在实践中往往有很多数据需求是通过间接的方式表达的,或者数据
的表达不规范,这都需要进一步整理。一般采用结构化分析方法,从最上层的结构入手,采
用逐层分解的方式分析系统,并用数据流图和数据字典描述系统。通常我们采用一些图表工
具辅助设计,如采用业务流程图来描述系统的物理概况,用数据流图来具体描绘系统的逻辑
模型,最后用数据字典存储在数据流图中的元素定义。
数据流图是分解和表达用户需求的工具,也是对原系统进行分析和抽象的工具。它从数
据传递和加工的角度,利用图形符号通过逐层细分描述系统内各个部件和数据在它们之间传
递的情况。
数据流图中采用的符号如表 6-2 所示。很多实际的数据处理过程非常复杂,所以数据流
图的绘制遵循自顶向下逐层求精的方法。先将整个系统当做一个处理功能,划出它和周围实
体的数据联系过程,获得一个粗略的数据流图。然后逐层分解,直到把系统分解为详细的低
层次的数据流图。这个过程能够发现处理过程中不合理、数据不匹配、数据流通不畅等问题。

- 124 - 电子政务数据库基础
表 6-2 数据流图符号说明
符 号 名 称 含 义
处理 即数据加工、变换过程,表示对数据的操作
文件 表示系统内需要保存的数据,是系统内处于静止状态的数据
数据流 说明系统内数据的流动,箭头指向为数据流动方向,箭头旁标明
数据流名称
外部对象 是向系统输入数据和接收系统输出的外部事物,也是数据流的源
点和终点
案例:公文审批的数据流程图绘制
我们以公文审批为例,简单说明数据流程图的一般绘制方法。公文审批主要包括收文管
理、发文管理、事务督办、档案管理和领导审阅这些业务流程。
① 收文管理。收文管理主要实现公文传递的流程设置,自动归档,自动催办,实现公文
签报管理电子化,提高工作效率,改善管理手段。会议、收文、重要文件的下发。主要实现
机关人员直接在电脑上进行文件的登记、传阅、下发等操作。
② 发文管理。执行发文拟稿、核稿、会签、签发、批阅流转、归档管理等工作。文件送
阅和批复完全在网络上进行,可实现对文档的密级管理、区分、控制。
③ 档案管理。对文件进行管理、分类,然后组卷,对案卷可以进行封卷、拆卷、标引、
检索、借阅、归还等工作。
它的分层数据流程图见下图 6.2~图 6.4 所示。
秘书
发文
归档文件
收文 档 案
管 理
新的文件
接受的文件
发文文件
收文文件 处理信息
图 6.2 公文审批顶层数据流图
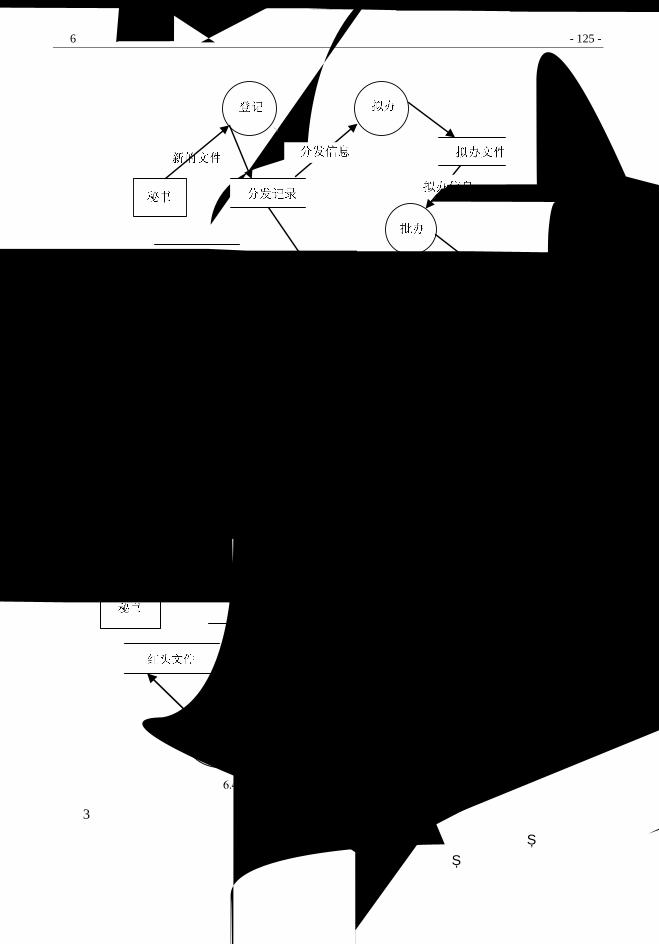
第 6 章 电子政务数据库系统设计 - 125 -
图 6.3 公文审批第二层数据流图��收文管理
图 6.4 公文审批第二层数据流图��发文管理
3.数据字典
数据字典是数据分析的主要工具之一,它对数据明确的含义、结构和组成进行具体说明。
数据流图和数据字典可以从图形及文字两方面对系统的逻辑模型进行完整的描述。

- 126 - 电子政务数据库基础
一般来说,数据字典的结构应该包括下列 5 类元素的定义:数据流、数据项、数据结构、
数据存储(文件)、处理。数据字典的条目结构和组成如表 6-3 所示。
表 6-3 数据字典的条目与组成
条 目 类 型 组 成 备 注
数据流名称
数据结构
数据流量
[来源]/[去向] 方括号[ ]代表可选项
数据流
[用途]
文件名称 文件
[别名]
文件结构
存取频率
[存取峰值]
数据项名称
数据项类型
取值范围
长度
数据项
有关的数据结构
数据结构名称
说明 数据结构
数据结构的组成
处理名称
输入数据流 处理
输出数据流
建立数据字典有两种方式:一种是建立数据字典卡片,如图 6.5 所示,另一种是利用数
据库系统提供的数据字典软件,自动生成和编排数据字典。
图 6.5 卡片式数据字典数据存储

第 6 章 电子政务数据库系统设计 - 127 -
6.2.2 数据库概念设计
在初步调研基础上,需要对整个应用系统进行一个概念化的描述,也就是说,利用概念
设计将现实世界中的具体需求抽象成信息世界中实体以及实体之间的联系,之后再将这种结
构转换为适合数据世界的数据模型。因此,概念设计是实际需求和最终数据结构之间一个非
常重要的设计步骤。
1.概念模式设计特点
概念模式设计一般具有以下特点:
(1)概念模式设计的目标是获得对数据库结构、含义、相互联系和各种约束的全面了解。
(2)它与今后采用哪种 DBMS 无关,因此便于修改和扩充。
(3)它的图示描述方式对与数据库用户、设计人员和分析人员来讲,是一种良好的交流
工具,易于理解,使得各方的交流更为准确和直接。
(4)与关系、网状、层次等结构的数据模型之间的转换简便易行。
2.概念模式设计方法
对于概念模式的设计,必须确定模式的基本组成:实体类型、联系类型和属性。常用的
概念模式设计方法有两种。
(1)集中模式设计方法。首先把前一阶段获得的不同用户组的需求合并到一个单独的需
求集中,然后根据这个需求集,设计全局逻辑模式,并为每个用户组设计数据库模式。需求
如何合并一般由 DBA 决定。
(2)视图集成方法。这个方法不要求对用户需求进行合并,而是根据每个用户组的各自
需要,为其分别设计相应的模式。这些模式就是各用户组自身的视图。之后,以这些视图为
基础,集成出整个数据库的全局概念模式。
这两个方法的主要不同之处在于,对各用户组的多个视图或需求进行合并的方式和时机
不相同。在集中式方式中,DBA 必须在模式设计之前,对用户的需求进行手动调整,如果用
户组较多时,这个工作量会相当大。正因为存在这种问题,视图集成方法逐渐获得了人们的
认可。
3.概念模式设计策略
设计概念模式存在多种策略。多数策略遵循增量方法,即先根据需求创建一些模式构造,
然后在此基础上增量地修改或扩大。
(1)自顶向下策略:首先创建该部分应用的全局概念结构,然后逐步细化。例如可以先
定义几个大的实体类型,然后在确定其属性时,再把这些实体分解成更低一层的实体类型和
联系。
(2)自底向上策略:先定义各局部应用概念结构,然后将其集成,得到总体结构。
(3)自内向外策略:先定义最核心的概念结构,然后逐步向外围扩展。这是自底向上策
略的一个特例。
(4)混合策略:先按照自顶向下的策略对需求进行划分,再根据自底向上的策略对每个
划分的需求设计部分模式,最后将各个部分组合起来。

- 128 - 电子政务数据库基础
4.通过 E-R 图进行概念结构设计
在概念结构设计中,一般先进行局部 E-R 图设计,然后通过集成 E-R 图获得整体应用的
概念结构。
在进行局部 E-R 图设计时,可借助中间层次的数据流图,并从相应的数据字典中标明该
部分的实体、属性、关键字等信息。当然,实体和属性并非截然分开的。有时一个事物是实
体,有时又会被作为属性。具体过程我们将在后续章节中进一步介绍。
合并 E-R 图时,要注意解决各分 E-R 图之间的冲突。典型的冲突类型有:
(1)属性冲突:各分 E-R 图中相同属性的类型和取值范围有差异。如性别的表示,有的
以“男”、“女”分别,有的以逻辑型规定。
(2)命名冲突:同一事物可能在不同的 E-R 图中称呼不同,不同事物在不同的应用中可
能命名相同。
(3)结构冲突:有些对象在某一应用中被当做实体,而在另一应用中被当做属性。最好
采用一定的规则将其统一起来。
冲突处理后进行的 E-R 图合并往往需要一个非常严格和系统化的方法。对于一些简单情
况,主要是将相同实体在不同应用中的属性收集起来,取并集作为该实体对应的数据库文件
的字段来源。
6.3 DBMS 的选择、逻辑数据库设计及实现
数据库概念模式设计将用户的实际需求抽象出来,借助一定的表达工具(常用的是E-R
图)反映出来。下面的工作就是将这种抽象的表达映射到具体选定的DBMS上,以便进行物
理实现。
6.3.1 DBMS 的选择
第 2 章中我们已经学习了 DBMS 的基本概念。和传统的文件系统相比,DBMS 具有不少
优点,如操作的简易性、对系统内部数据维护的一致性、更好的数据可用性以及支持信息快
速存取的功能。借助目前基于 Web 的存取技术,人们可以从全球各个地方轻松地对数据库中
的某些数据进行存取。同时,采用 DBMS 的系统可以相应地降低应用开发成本、减少数据冗
余,同时加强了安全和控制性能。但是在进行 DBMS 选择的时候仍然要仔细考虑各方面的因
素,包括技术方面的、经济方面的和组织方面的因素。
1.技术方面的影响因素
技术方面主要应当考虑选择的 DBMS 是否能胜任需要完成的工作。目前占主导地位的
DBMS 产品家族主要是 RDBMS 和 ODBMS。RDBMS 作为商业化应用非常成熟的产品受到
了大多数用户的喜爱,但是随着数据库新应用的不断发展,早期的 RDBMS 越来越显得无能
为力。对它的挑战主要来自多种数据类型的广泛交叉使用。例如计算机辅助桌面排版系统中
的大文本,气象预报中的图像信息,各种地图、污染控制系统中的大量空间和地理数据。在

第 6 章 电子政务数据库系统设计 - 129 -
电子政务等系统中,除了大量的文字和图片信息,还需要处理很多音频和视频数据流(如重
要会议的录音、录像资料等)。在处理这些特殊数据类型时,面向对象的 DBMS 就显示出了
相当的优势。当然,由于电子政务系统应用的层次和范围差异极大,很难提出一个统一的数
据管理方法,但是,不论选择哪种类型的 DBMS,都需要同时考虑以下一些技术方面的因素,
包括 DBMS 支持的存储结构和存取路径、用户界面和开发界面、高级查询语言的种类、选取
的开发工具、通过标准接口和其他 DBMS 交互的能力,以及整个应用系统所采用的架构平台
(如两层客户机/服务器模式或是三层客户机/服务器模式)。除此之外,对于系统中应用数据
特征的分析也相当重要,这主要集中在对数据的复杂性、对各种应用间数据共享的要求、数
据实时检索的需求的分析,以及对数据更新频率和增长速度的预计等方面。
2.经济方面的影响因素
经济方面主要考虑获的是使用某种 DBMS 需要花费的成本,通常需要考虑以下几种成
本:
(1)软件获得成本:这是购买软件时需要花费的成本。值得注意的是,针对不同应用和
不同的操作系统,同一种 DBMS 可能有若干种版本和功能选项供选择,选择的时候既要充分
考虑经济因素,也要为今后系统转换预留余地。
(2)维护成本:这是为了获得厂商的售后服务以及今后 DBMS 版本升级所需要花费的成
本。
(3)硬件获得成本:某些情况下,为了使 DBMS 更好的工作,可能需要添置新的硬件设
备,如额外的终端、硬盘驱动器、大容量存储设备等。
(4)数据库创建和转换成本:如果组织中原来没有任何 DBMS,就需要完全新建数据库
系统。通常情况下则是从老系统向新的 DBMS 转换。一般新老系统会并行一段时间,直到新
的应用程序能够完全工作正常。这种转换间也必须花费相应的成本,如为保持两套系统同时
运作而额外增加的人力成本等。对这种成本很难准确测度,但在实践中通常会低估它。
(5)培训成本:由于 DBMS 的操作相对复杂,相关人员必须经常接受一些培训,从而更
加熟练地操作和使用它,这些培训包括在 DBMS 基础上进行应用系统开发、进行数据库管理
等。
(6)运行成本:无论选择哪种 DBMS,都必须支出一定的成本保证数据库系统能够连续
运行。
3.组织方面的影响因素
从组织的方面来看,影响 DBMS 选择的因素也很多,包括:
(1)机构文化:由于不同的 DBMS 是相对不同的数据库模型和开发方法而选择的,因此,
机构的成员对某种开发方法(如原型化开发方法或是生命周期法)的接受程度也可能影响对
某种 DBMS 的选择。
(2)相关人员对系统的熟悉程度:如果机构内部的开发人员对某个特定的 DBMS 比较熟
悉,就可以减少培训成本和学习时间。
(3)厂商提供的服务:除了产品本身的性能外,使用某种 DBMS 的机构往往希望获得厂
商长期和优质的售后服务,减少使用的后顾之忧。特别是电子政务数据库系统中保存着大量

- 130 - 电子政务数据库基础
有关国家、社会和公众的重要信息,保证数据库的长期平稳运行更显得极其重要。
6.3.2 逻辑数据库设计
概念设计阶段使我们对数据库的结构、数据含义、数据间的相互关系等有了一个全面的
了解,它的结果通常用 E-R 模型来表示。为了使它和我们选定的 DBMS 协同工作,必须将概
念模式进行映射,在选定的 DBMS 的数据模型基础上创建数据库的概念模式和外模式,实现
用户的需求。这就是逻辑设计阶段需要完成的工作。
逻辑设计的映射过程可以分为以下两个阶段。
1.将 E-R 模型向关系模型转化
这种转化的主要工作是将 E-R 图转化为等价的关系模式,这个过程比较直接,在前面的
章节中已经介绍过,我们简单回顾一下一些通用步骤:
(1)将 E-R 图中不被 DBMS 支持的数据类型做适当的修改。
(2)将 E-R 图中某个实体的复合属性转换为简单属性。
(3)将每一个实体转换为一个关系,将实体的属性和码作为关系的属性和关键字。
(4)将每个一对一的联系转换为一个独立的关系,或者和任意一端的关系合并。转换成
独立的关系时,与该联系相连的实体的码以及联系本身的属性均转换成关系的属性,各实体
的码都可以作为该关系的关键字。如果与某一端关系合并,则需要在该关系中加入另一端关
系的关键字和联系本身的属性。
(5)将每一个多对多的联系转换为一个新的关系,将与该联系相连的实体的码以及联系
本身的属性作为新关系的属性,将各实体的码组合成该关系的联合关键字。
(6)对于一对多的联系一般不单独建立关系,而是将一方的关键字放入多方关系的属性
集中并设为外关键字。下表 6-4 是对 E-R 模型与关系模型之间对应关系的简单总结。
表 6-4 E-R 模型与关系模型之间对应关系
ER 模型 关系模型 实体类型 1:1 或 1:N 联系类型 M:N 联系类型
“实体”关系 外码(或“联系”关系) “联系”关系和两个外码
2.优化关系模型
优化处理主要对上面获得的逻辑模式雏形进行规范化处理,同时根据选定的 DBMS 在实
现数据模型时的特性和约束“裁剪”模式,使它更好地与选定的数据模型融合。规范化处理
主要借助前面学习的规范化理论,一般要求达到第三范式,但并不是规范化程度越高越好。
为了使数据库的合理性和性能达到最优平衡,往往要反复调整第一阶段获得的模式,对各关
系和关系中的属性作进一步改进。
案例:政府机构数据库应用实例��ORGANIZATION 我们通过一个名为ORGANIZATION的模拟政府机构数据库应用实例,深入了解一下E-R
图在数据库模式设计中的作用。我们将首先列出 ORGANIZATION 的数据需求,然后通过 E-R模型建模,一步一步创建该数据库的概念模式。之后再利用我们上面介绍的步骤,将 E-R 图
第 6 章 电子政务数据库系统设计 - 131 -
转换成相应的关系模式。
ORGANIZATION 数据库主要记录某政府机构中工作人员、部门以及各部门负责的主要
事务的情况。假设经过需求收集和分析后,数据库设计人员列出了对这个“微观世界”的主
要描述:
(1)该机构包括六个部门,每个部门有惟一的名称、惟一的编号,并且有一位特定的工
作人员(部门管理者)来管理这个部门。当然部门管理者会有一定的任期,我们需要记录该
管理者开始担任领导职务的日期。
(2)一个部门会负责多项事务,每件事务有惟一的名称、惟一的编号和惟一的发生地点。
(3)对于每位工作人员,都需要记录他(她)的姓名、性别、出生日期、联系住址、联
系电话、身份证号、社会保险号和收入情况。每位工作人员只在某个部门有岗位编制,但可
以参与到多项事务的处理中,有些事务也可能需要多个部门联合负责和处理。另外,还需要
记录每位工作人员参与某个事务处理的起止时间,同时记录每位工作人员的直接领导者。
(4)另外,由于特殊原因,还需要掌握每位工作人员的主要社会关系的情况,包括主要
社会关系的姓名、性别、出生年月、工作单位以及与该工作人员的关系。
首先我们来分析在这个“微观世界”中存在哪些实体,各实体又具有哪些属性。实体是
现实世界中独立存在的“事物”,仔细分析上面的描述,我们看到,在 ORGANIZATION 中,
存在以下四个实体:工作人员(employee)、部门(department)、事务(transaction)和工作
人员的主要社会关系(relative)。参见图 6.6 所示。
图 6.6 ORGANIZATION 中的实体及其属性值
e:工作人员
d:部门
t:事务
r:直系亲属
093
M
事务名称=科技成果申报
事务编号=南科 号
����tl �32 303
1967 12 20
=84563987
M
姓名=陈倩
住址=南京市马台街龙
仓巷 号 室
出生年月= 年 月 日
联系电话������el
= M
姓名 陈倩
性别=女
与本人关=配偶
����rl �=942
=
32 1202
M
部门名称=科技处
部门编号
地址 南京市北京东
路 号 室
���dl

- 132 - 电子政务数据库基础
(1)实体类型部门(department):具有属性部门名称、部门编号、地址、管理者和上任
时间。部门名称和部门编号都可以作为实体的码属性,因为它们中的每一个都被指定为具有
惟一的值。
(2)实体类型事务(transaction):具有属性事务名称、事务编号、事务发生地点、和事
务负责部门。名称和编号都可以作为实体的码属性
(3)实体类型工作人员(employee):具有属性姓名、身份证号、社会保险号、性别、联
系住址、联系电话、出生日期、收入情况、所属部门和直接领导等。其中联系地址和联系电
话是复合属性,因为联系地址中除了实际地址外可能还有邮政编码等,联系电话则可分为家
庭电话、办公电话、移动电话等。这些可能没有在用户需求中体现出来,因此必须向用户去
了解一下有没有这样划分的必要。
(4)实体类型主要社会关系(relative):具有属性姓名、性别、出生年月、工作单位、
相关的工作人员以及与该工作人员的关系。
另外,需求描述中还要求表述以下两个事实,即工作人员可以参与到多项事务的处理中,
以及记录每位工作人员参与某个事务处理的起止时间。我们可以通过在相关实体的某个多值
复合联系属性中表示的方法来解决。具体的方法我们将在后面详细介绍。
接着我们来分析各实体之间存在怎样的联系。在我们的例子中可以确定以下的联系类
型:
(1)管理:这是工作人员和部门之间的一个一对一的联系类型。这里的工作人员特指部
门管理者,通常一个部门只有一个最高管理者,一个管理者也只负责一个部门。另外我们在
这个联系类型上增加一个属性“上任时间”表明某管理者从何时开始负责该部门,参见图 6.7。
(2)编制:这是部门和工作人员之间的一个一对多的联系类型。一个部门可以包含多个
工作编制,一个工作人员只在一个部门有编制。
(3)负责:这是部门和事务之间的一个一对多的联系类型。一个部门可以负责多项事务,
一项事务只能由一个部门负责。
(4)领导:这是工作人员(充当领导角色)和工作人员(充当下属角色)之间的一个一
对多的联系类型。一个领导可能有多个下属,一个下属则只有一个直接领导。
(5)处理:这是工作人员和事务之间的一个多对多的联系类型。可以有多人共同处理一
个项目,一人也可以同时参与到多项事务处理中。
(6)主要社会关系:这是工作人员与主要社会关系间的一个一对多的联系类型。即使两
个不同的工作人员的主要社会关系可能相同(如兄弟同时在同一机构工作且未婚),我们仍然
将其主要社会关系视作不同的实体。
图 6.7 1:1 的联系类型:管理

第 6 章 电子政务数据库系统设计 - 133 -
在确定以上 6 个联系类别后,还有很重要的一步:将联系中已有的所有属性从前面定义
的实体类型属性中删除,需要删除的属性包括:部门中的管理者和上任时间;事务中的事务
负责部门;工作人员中的所属部门和直接领导;主要社会关系中的相关的工作人员。这样可
以尽量避免数据库概念模式中的冗余。
在实体、实体间的联系和它们的属性都分析清楚后,就可以采用规范的符号画出
ORGANIZATION 数据库的整体 E-R 图了(见图 6.8)。
图 6.8 ORGANIZATION 数据库的整体 E-R 图
下面我们利用前面介绍的从 ER 图向关系模型转换的基本步骤将 ORGANIZATION 数据
库的 ER 图映射到关系模式。得到的关系如下图 6-9 所示:
(1)实体类型“工作人员”、“部门”、“事务”和“主要社会关系”直接转换为 4 个实体
关系“工作人员”、“部门”、“事务”和“主要社会关系”。
(2)1:1 的二元联系类型”管理”,我们采用将它与和它相关联的“部门”关系进行合
- 134 - 电子政务数据库基础
并。而与它相关联的另一个关系“工作人员”的主码变成”部门”关系的外码,并重新命名
为管理者身份码。“管理”联系类型自身的属性上任时间也被并入“部门”中,重新命名为管
理者上任时间。
(3)1:N 的二元联系类型”编制”、”负责”和领导处理方式同 2 中的”管理”,其中”
编制”并入”工作人员”关系,并将”部门”关系的主码��部门��编号,改名为所属部
门编号后作为“工作人员”关系的一个外码;“负责”并入项目关系,并将“部门”关系的主
码部门编号改名为负责部门编号后作为项目关系的一个外码;“领导”是一种递归的联系类型,
因此将“工作人员”的主码作为其自身的外码,并改名为领导者身份码。 (4)M:N 的二元联系类型”处理”直接转换成关系“处理”,并将与它相连的项目关系
和“工作人员”关系中的主码更名后作为它的外码。它自身的属性参与时间也被并入。
图 6.9 ORGANIZATION 数据库的关系
身份证号 姓名 出生年月 联系地址 移动电话 家庭电话 办公电话 收入情况所属
部门号
领导者身
份码性别 邮政编码
工作人员
部门名称 部门编号 管理者
上任时间地址
管理者
身份码
部门
事务名称事务编号
事务
负责部门
事务
发生地点
事务
姓名关联人员身份码
工作单位 性别出生年月与本人
关系
主要社会关系
事务编号工作人员
身份码参与时间
处理

第 6 章 电子政务数据库系统设计 - 135 -
6.3.3 物理设计
1.物理设计决策中的影响因素
物理数据库设计就是为数据库文件确定存储结构和存取路径,为各种数据库应用提供一
个最合适的物理结构一般而言,每个 DBMS 都提供了多种文件组织和存取路径,包括多种索
引类型、相关记录的聚集、使用指针连接相关记录等。一旦确定使用哪种 DBMS,物理数据
库的设计就只能从给定的 DBMS 提供的方案中选择一个最为合适的了。我们首先来认识一些
在物理设计决策中经常会用到的一些指标:
(1)响应时间:即提交数据库事务后到收到相应结果所花费的时间。影响响应时间的主
要因素是事务在调用数据项时数据库的存取时间,这是由 DBMS 控制的。一些非 DBMS 因
素也会影响响应时间,如系统负荷、操作系统调度以及通讯延迟等。
(2)空间利用:这是磁盘上数据库文件及其存取路径结构所占用存储空间的大小,包括
索引和其他存取路径。
(3)事务吞吐量:即每分钟系统处理事务的平均数量。这个参数对于一些实时操作系统
非常重要。
在不同的物理设计中,可以利用分析技术和实验技术来估计上面这些指标的平均值和最
坏值,以确定物理设计是否满足性能需求。
2.索引设计策略和数据库调整
首先,我们来看看索引的设计问题。在关系数据库中,数据存取方式的设计主要指索引
设计。数据库的索引就像我们常见的图书索引类似,主要是为了方便在大量数据中快速查询
某些特定记录。我们常常根据需要在记录的某一属性上建立索引。索引的物理设计涉及如下
几个问题:
(1)是否为某个属性建立索引:如果该属性是主码或是外码,或者经常在查询条件中出
现,就应当考虑为该属性(组)建立索引。
(2)是否要建立多个索引:如果某些表是以读为主或是只读的,应当在存储空间允许的
情况下多建索引,这样查询时就可以只扫描索引而不需要检索数据,查询效率可以提高。
(3)是否使用聚簇索引:许多 DBMS 为了提高某个属性(组)的查询速度,会将在这些
属性上取值相同的元组集中放在连续的物理块上,这种操作称为聚簇,该属性称为聚簇码,
通常,大部分 DBMS 还会使用关键字 CLUSTER 在聚簇码上建立一个聚簇索引。使用聚簇索
引可以大大提高按聚簇码进行查询的效率。但是,聚簇方法改变了元组存放的物理结构,为
了建立和维护它需要很大的开销。聚簇的改动,会引起相关的索引失效和元组存储位置的变
动,因此对聚簇的使用应当仔细权衡。一般当查询只涉及索引的搜索时不应当将相应的索引
聚簇。
随着数据库的运行,可能会发现一些初始物理设计所忽视的问题,这时就需要对数据大
小及活动量做出评测,不断监控并修改物理数据库设计。这就是数据库调整。物理设计和调
整之间的分界线非常模糊,调整是设计的一个不断修正的过程。下面简单讨论一下各种数据
库设计策略的调整问题:
(1)索引的调整。有时由于下列情况的出现,必须对索引的设计进行修改:

- 136 - 电子政务数据库基础
� 由于缺少索引,某些查询的执行时间过长;
� 某些索引自始至终未被使用;
� 由于索引所在的属性频繁改动,导致索引的系统开销过大。这时可能需要删除某些索
引,同时增加一些新的索引。
(2)数据库设计调整。我们通常会对关系模式进行规范化处理,从而将逻辑相关的属性
分散到不同的表中,使得数据库冗余最小化,避免更新异常,保证数据库的一致性。但有些
时候,为了使频繁用到的查询和事务处理能够高效率地执行,必须牺牲规范化目标,将符合
较高范式的数据库设计转换为符合较低的范式,这个过程叫做逆规范化。这是数据库设计中
经常发生的一种调整。
另外,我们还会根据实际情况,对某个关系进行垂直划分或水平划分。如我们前面介绍
的 ORGANIZATION 数据库中的工作人员关系表(身份证号、姓名、性别、联系电话、收入
情况、所在部门),因为查询工作人员收入情况时,很少需要知道他的联系电话,因此我们将
它划分成两个表:工作人员表 1(身份证号、姓名、性别、联系电话)和工作人员表 2(身份
证号,所在部门,收入情况)。这样,查询工作人员收入情况的效率就会提高。这种划分称为
垂直划分。而如果我们将工作人员关系表按照部门划分成多个不同的表,每张表具有相同的
属性集,但元组不同,这种划分称为水平划分。
6.3.4 数据库实现、测试和调整
在逻辑设计和物理设计结束后,就可以着手对数据库系统进行实现了。通常借助 DDL
(数据定义语言)和选定的 DBMS 的 SDL(存储定义语言)语句,创建数据库模式以及空的
数据库文件,然后向数据库装载数据。既可以让专门的录入人员进行人工输入,也可以将以
往系统中的数据导入新数据库中,一般的 DBMS 都提供了相应的工具。实现阶段顺利完成后
就进入试运行和调试阶段。
随着数据库需求的改变,常常需要增加或删除现有的某些数据库文件,创建新索引,或
对某些文件重组织。只要数据库或系统的性能有了变动,就需要对数据库不断进行调整,这
是无法避免的。具体的调整方法与物理设计阶段的数据库调整方法类似,我们就不再重复了。
6.4 电子政务平台数据中心
正如本章开始部分所述,电子政务系统的 “信息孤岛”现象既造成了信息资源的浪费,
又严重阻碍了政府部门效率的提高,与电子政务建设的初衷不相符合。因此,有必要探索一
条道路,建设一个可以跨平台使用的电子政务平台数据交换中心,使电子政务的应用与其底
层的数据结构和存储方式无关,既可以实现数据的无缝交换和共享访问,保证各业务系统的
有效协同,同时又能保证各应用系统的相互独立性和低耦合性,从整体上提高系统运作效率
和安全性。下面我们主要以北京慧点科技开发有限公司和倍多科技提出的数据中心解决方案
为基础,介绍数据中心的基本概念和架构。

第 6 章 电子政务数据库系统设计 - 137 -
6.4.1 电子政务平台数据交换中心建设背景
前面的章节中我们已经指出,经过多年的政府上网工程和一批�金�字工程等电子政务建
设,各级政府职能部门已经基本构建了办公管理系统和内、外网网站。但是由于技术、业务、
需求、经费和管理等方面的问题,加上时间和历史等原因,各政府职能部门常常根据自身的
情况与需要,采用不同的技术和体系结构来建立自己的信息系统,造成了各系统的开发平台
不同、操作系统不同,特别是数据库管理系统千差万别,从而形成了一个个信息孤岛。国务
院信息化工作办公室明确指出 “当前电子政务的重点是解决‘信息孤岛’问题,有计划、有
步骤地建设和整合统一的电子政务网络平台,为在网络环境下实现各主要业务系统的互联交
换和资源共享,以及规范政府管理和服务创造必要条件,��”。 如何在保证信息安全的前提下,摆脱目前各部门、各系统的信息无法沟通、各自为政的
局面,实现局域、广域、异构操作系统和数据库环境下的信息集成,将分散的信息资源更好
地统一、整合、管理,并通过电子政务信息门户呈现出来,实现以政务公开、行政审批、政
府采购及以综合数据仓库为基础的综合查询、统计分析、数据挖掘、政务协同系统开发和对
政务办公的监察审计,已成为提高各类电子政务应用水平的关键考虑。政务信息的存储、加
工、传递和使用已经不能仅仅采用独立的数据库系统,建设一个可以跨平台使用的电子政务
平台数据交换中心,使电子政务的应用与其底层的数据结构和存储方式无关,既可以实现数
据的无缝交换和共享访问,保证各业务系统的有效协同,同时又能保证各应用系统的相互独
立性和低耦合性,从整体上提高系统运作效率和安全性,不失为一种有效的解决“信息孤岛”
问题的途径。 基于数据交换中心的统一政务交换平台不同于传统的点对点互连的方式。以有 6 个应用
系统的情况为例,如果采用传统的点对点互连的方式,则需要 30 个接口。如果采用数据交换
中心技术,则只需要 12 个接口(见图 6.10)。传统的点对点互连方式,接口标准是因连线两
端的系统而异的。而采用数据交换中心技术,则可以为不同的应用系统制定统一的接口标准。
图 6.10 基于数据交换中心的统一政务交换平台和传统的点对点互连的方式
6.4.2 数据交换中心概述
数据交换中心是: � 政府信息资源数据库的存储中心和管理服务中心。

- 138 - 电子政务数据库基础
� 政府数据交换服务中心——在上级政府和各下级政府间、各级政府相互间、同级政府
各部门间、各级政府和公众间实现业务数据共享等应用的数据交换。
� 网上政务服务系统的公众数据交换中心。
� 政府决策支持中心——进行数据挖掘、分析和比较,提供辅助决策信息。
数据交换中心与传统意义上的数据中心有什么区别呢?传统意义上的数据中心实质上是
一个数据存储中心(DSC),或者是数据仓库(DW)。应用系统所能够提供的数据服务先以
某种形式转移到数据存储中心,其他应用系统再从数据存储中心获得数据。数据存储中心存
在着实时性差、应用系统与存储中心之间及应用系统之间的耦合程度比较严重、系统安全性
较低等不足。 数据交换中心采用 Web 服务技术进行组件和应用系统的包装,将系统的数据展示和需
求都看做一种服务,通过服务的请求和调用实现系统间的数据交换和共享。应用系统所能提
供的数据并不需要先复制到数据交换中心的中心数据库,而只是以 Web 服务的形式发布出
来,只有当用户发出服务请求的时候,数据才从应用系统经过数据交换中心直接传递到用户。
这样,用户所得到的永远是最新的信息。
当应用系统中的数据格式变更或增加了新的数据,只需要以新的 Web 服务发布出来,
用户通过数据交换中心使用服务并获得相应数据。数据交换中心和客户端都不需要做任何改
动,这就实现了系统之间的低耦合性。
数据交换中心利用电子政务安全平台所提供的安全机制来保证系统和数据的安全。当应
用系统申请进行数据查询和更新操作时,必须通过安全可信的 Web 服务在权限管理的控制下
来进行数据交换和数据传输,提高了系统和数据的安全性。
6.4.3 数据交换中心架构描述
1.数据交换中心的相关技术
数据交换中心的架构与以下技术密切相关��Web 服务、XML 和数据仓库。 (1)Web 服务。很多 IT 人士认为,Web 服务是指支持某组织的应用软件通过互联网与
其他应用进行通信所需的软件工具。Web 服务平台是一套标准,它定义了应用程序如何在
Web 上实现互操作性。可以用任何你喜欢的语言,在不同的平台中编写 Web 服务 ,而通过
Web 服务的标准来对这些服务进行查询和访问。这种计算机间的通信常用的格式是 HTML,
但现在新的 Web 服务往往用 XML 实现。 (2)XML。XML(扩充标注语言)和 HTML(超文本标注语言)一样,也是在 SGML
(标准通用标注语言)的基础上发展起来的,XML 包含有 HTML 没有的数据管理能力,它
和 HTML 有两个重要区别: ① XML 不是已定义标记的标注语言,它只是一个框架,任何人都可以在这个框架下创
建自己的标记集。 ② XML 标记不是用来指定文字的页面显示形式,而是用来表示文字信息的含义(语义)。
XML 通过提供更灵活和更容易被接收的信息标识方法来改进 Web 的功能。 (3)数据仓库。著名的数据仓库专家 W. H. Inmon 在其著作《Building the Data Warehouse》
一书中对数据仓库给予如下描述:数据仓库(Data Warehouse)是一个面向主题的(Subject

第 6 章 电子政务数据库系统设计 - 139 -
Oriented)、集成的(Integrate)、相对稳定的(Non-Volatile)、反映历史变化(Time Variant)
的数据集合,用于支持管理决策。对于数据仓库的概念我们可以从两个层次理解:首先,数
据仓库用于支持决策,面向分析型数据处理,它不同于操作型数据库;其次,数据仓库是对
多个异构的数据源有效集成,集成后按照主题进行了重组,并包含历史数据,而且存放在数
据仓库中的数据一般不再修改。
2.数据交换中心的一般架构
整个体系结构是一个星型结构,数据交换中心处于中心位置,它是实现数据共享和交换
的中心,通过标准化的 Web 服务接口为每个数据交换节点提供服务。每个数据交换节点只需
要与数据中心通过 Web 服务进行交互,并通过 XML 进行数据转换,而不需要相互直接连接
访问就可以获取到所需要的数据。数据中心的整体行为就像一个虚拟的中心数据库, 同时又
像一个交换机。整个数据共享和交换的底层实现和存储机制对各应用节点是透明的。该结构
耦合性低,并且很容易扩展为层次的雪花型结构,构建出多级的数据中心结构,以支持更大
范围的广域方案。
电子政务数据交换中心完成数据的存储、格式转换和数据交换,它由一系列中间件、服
务、Web Service 接口以及中心数据仓库组成。其核心组件包括数据交换引擎、安全管理、系
统管理、Web 服务管理以及 Web 服务接口。(如下图 6.11 所示)
(1)数据交换引擎��实现数据交换的核心功能,提供模式管理、数据变换和交换等服
务。 (2)安全管理服务��借助于电子政务的安全和信任服务平台实现用户管理、身份认证
和授权管理等服务,安全管理服务中的安全中间层还提供安全的 Web Service 服务,管理 Web服务会话,实现安全的数据交换。
(3)系统管理服务��实现对系统的配置管理和状态监控。通过系统管理服务配置数据
中心各部分的运行参数,服务的启停控制,监控整个系统的运行状态。 (4)Web 服务管理��提供对 Web 服务的注册管理和发布功能。通过 Web 服务管理,
各数据交换节点代理向数据中心注册自己的数据交换 Web 服务,数据中心根据注册的信息进
行 Web 服务的路由,主动调用数据交换节点的数据访问服务来向数据交换节点传送数据或
从数据交换节点获取数据。 (5)Web 服务接口��向外部应用程序和数据交换节点展示数据交换的相关 Web 服务,
Web 服务的实现可以是基于 HTTP、邮件 SMTP 以及 SOAP 等各种协议的,可以是异步的也
可以是同步的。Web 服务接口通过安全管理服务来实现可信的 Web 服务调用。 (6)中心数据仓库��中心数据仓库提供数据转储和数据仓库功能。采集和交换过程中
的数据可以转储到中心数据仓库,并在转储过程中提供数据的正确性和一致性校验功能,保
证了数据权威性;中心数据仓库还为传统应用程序提供了一个全局的关系数据共享视图,利
用本地数据库连接工具可进行复杂关系数据的批量检索、统计查询和数据管理。基于中心数
据仓库还可提供数据挖掘、分析、比较等功能,提供决策辅助信息。 数据交换代理代表业务应用系统主动参与数据交换事务。根据信息服务要求,触发业务
应用系统的内部处理流程,并反馈相应结果。

- 140 - 电子政务数据库基础
图 6.11 电子政务平台数据交换中心总体架构
3.数据交换中心的优点
数据交换中心以目前最流行的 Web 服务技术和 XML 数据库为核心,建立起一个标准和
开放的信息平台,通过统一的数据管理模式,将传统的结构化信息和像文档、表格、声音、
图像等非结构化信息全部整合。同时它还具有很强的扩展性,能够灵活地根据实际需求调整
层次,对于电子政务数据处理是非常合适的选择。
(1)强大的数据集成功能
数据交换中心能够完成跨平台异构应用系统的数据共享和集成,它支持两种类型的数据
共享和集成,即分布式的数据集成和集中式的数据共享。
对于新的应用系统,以及已有的采用中间件的 J2EE 应用,可以实现分布式的数据集成。
在这种情况下,数据存放在应用系统自己的数据库中,每个应用节点通过建立 Web 服务来展

第 6 章 电子政务数据库系统设计 - 141 -
示自己所能提供的数据的模式,在接到数据服务请求时,通过 Web 服务调用来向外提供数据
服务,在交换过程中使用 XML 来封装数据。 对于网络状况不好的一些应用(如公安系统的数据不能直接连接到政务网上),或者原来
是基于 C/S 结构的构造的应用,改造成 Web 服务的成本会比较高,这时可以采用一个集中的
中心数据仓库来实现数据共享。相关应用把自己可以在政务网范围内公开的数据更新到中心
数据仓库,其他应用通过数据交换代理提出数据请求,从中心数据仓库中获取需要的数据。 (2)支持跨平台异构应用系统 数据交换中心利用 Web 服务技术来实现,以 SOAP 作为安全通信的基础,以 XML 为跨
平台数据交换的技术,以 Java 为跨平台代码交换的技术,建立了各政务应用系统沟通和对社
会服务的接口标准和服务标准,实现了良好的数据封装、交换和共享,提供了很好的互操作性。 (3)完善的安全机制 数据交换中心利用电子政务安全平台来保证数据交换和传输中的安全。利用电子政务安
全平台的身份认证和授权管理,可以控制用户的数据请求和访问权限。通过严格的身份验证
和权限管理,可以很好地保证系统的安全。
4.数据交换中心的应用前景
在电子政务应用中,政府各职能部门的业务系统常常需要进行数据的交换和共享,
如公安、计生、民政、社保等系统通常需要用到公民的身份等信息,而工商、税务、海
关等系统又需要对企业的经营数据进行处理。利用数据交换中心,可以只在一个最相关
的系统中存储数据,其他系统通过数据交换中心提供的数据服务来获取相应的数据,从
而实现数据的集成与整合,并且最大程度地保证数据的一致性以及安全性。利用数据交
换中心,能够更好地支持电子政务中的一站式服务,通过数据的交换和集成实现各业务
系统的业务集成。 基于数据交换平台构建的政府信息门户网站,可以快速集成各种信息、数据和应用,
如 MS Exchange、Lotus Notes 等非结构化的协作办公系统;Oracle、SQL Server、DB2
等关系型数据库:以及类似 SAP 的 ERP 系统等的应用系统,从而形成可伸缩的应用集
成体系结构,保证以往投资得以重复利用,降低信息化成本。另外,通过设计强大的 XML
检索引擎,可以实现高性能的 XML 电子公文交换。除此之外,还可以利用内容和风格
的个性化定制、智能化的推送服务和快速信息发布等 XML 技术的先天优势,实现个性
化的快速信息发布。
6.5 本 章 小 结
本章介绍了数据库系统的设计过程。首先介绍了信息系统生命周期和数据库生命周期的
概念,以图示的方式说明数据库设计流程,包括初步调研、概念设计、DBMS 的选择、逻辑
设计、物理设计以及系统的实现、测试和调整等环节。结合实例重点介绍了数据流程图、数
据字典等分析工具的使用。之后,通过一个模拟的 ORGANIZATION 数据库的例子,详细说
明了如何利用 E-R 图这个重要的工具逐步完成系统从初始数据需求到逻辑模式实现的过程。

- 142 - 电子政务数据库基础
在了解了数据库设计的基本理论和方法的基础上,本章针对目前电子政务数据库开发中
凸现的“信息孤岛”问题,介绍了一种新型的数据管理模式��电子政务平台数据交换中心。
着重介绍了数据交换中心提出的背景和与传统模式相比具有的优点,给出了一个一般性的总
体架构示意图。最后,对数据交换中心的应用前景作了展望。
6.6 本 章 习 题
1.数据库设计分为哪几个阶段?对每个阶段进行讨论。 2.在初步调研过程中,开发人员容易犯什么样的错误?收集资料进一步说明如何开展
有效的需求调研。 3.考虑一个你感兴趣的现实的数据库系统应用。按照所需的数据、查询类型和待处理
的事务,定义不同层次用户的需求。 4.概念模式设计有哪些策略?概念模式设计时,获得的数据模型是与系统相关的么?
目前常用的工具是什么? 5.讨论组织内影响信息系统 DBMS 选择的因素。 6.影响物理数据库选择的重要因素是什么? 7.讨论关系数据库中索引的调整。 8.讨论“信息孤岛”出现的主要原因。 9.查阅资料了解关于 Web 服务、XML 和数据仓库等更多的信息。
6.7 本章参考文献
1.钱毅·政务数据库系统·北京:中国人民大学出版社,2004 2.刘越南等·政府网站的构建与运作·北京:中国人民大学出版社,2004 3.赵杰等·SQL Server 数据库管理、设计与实现教程·北京:清华大学出版社,2004 4.[美]Ramez Elmasri 等,邵佩英 等译·数据库系统基础(第三版)·北京:人民邮电
出版社,2002 5.国家信息安全工程技术研究中心·电子政务总体设计与技术实现·北京:电子工业
出版社,2003 6.张国锋等·管理信息系统·北京:机械工业出版社,2004 7.电子商务研究·http://www.dzsw.org 8.电子政务服务工程网·http://www.echinagov.com 9.东软·http://www.neusoft.com 10.电子商务直通车·http://www.ectook.com 11.国家软件与集成电路公共服务平台·http://www.csip.cn 12.计世网·http://www.ccw.com.cn

第 6 章 电子政务数据库系统设计 - 143 -
13.湖南省信息产业厅·http://www.hnii.gov.cn
14.灰狐动力·http://www.huihoo.com
15.中软银通·http://www.sqlmine.com

第 7 章 电子政务数据库保护
对于数据库而言,安全问题可以从两方面来控制,一是物理安全��防止数据库硬件遭
到人为的盗窃或破坏;一是逻辑安全��既包括对数据保密性的保护,也包括保证数据库内
部逻辑一致,即通过良好的设计和管理手段,保证数据库的完整性、一致性、可恢复性、可
审查性等,防止因为内部逻辑混乱造成数据库损坏。 电子政务数据库常规的保护技术主要涉及安全性约束、完整性约束和并发控制,这些技
术主要利用了数据库系统自带的一些机制。如安全性约束主要借助数据库系统对权限和角色
的划分以及相应的用户认证和授权进行,完整性约束则借助隐式或显式说明进行,并发控制
则强调了事务管理机制和事务锁的使用。 由于电子政务数据库中的数据大多关系到国计民生,因此除了利用常规技术对数据库安
全进行保护以外,为了防范意外事故的发生,还必须采取适当的备份和恢复策略,这样才能
够以最短的系统停机时间、最少的数据损失量来恢复数据。数据备份和恢复技术为数据库数
据日常的安全使用提供了一定的保障,但是随着信息系统和网络应用的飞速发展,计算机世
界也越来越频繁的发生一些重大灾害,因此,重视电子政务数据库系统的容灾管理技术研究,
也是目前电子政务数据库研究的一个新兴热点。 电子政务数据库保护作为电子政务安全体系中的一环,与国家信息安全密切相关。除了
需要从技术方面加强保护外,还应当建立起一套完整规范的法律体系,从而提高信息安全保
障能力。 本章主要内容: � 数据库保护基础
� 数据库保护相关技术
7.1 数据库保护基础
计算机技术和数据库技术的飞速发展,为我们进行数据库保护提供了良好的技术支持。
但是,首先要对电子政务数据库系统面临的安全威胁和安全需求做出清晰的描画,才能够“对
症下药”,制定出合理完善的保护策略。
7.1.1 电子政务数据库安全分析
1.安全概述
对于数据库而言,安全问题可以从两方面来控制,一是物理安全��防止数据库硬件遭

第 7 章 电子政务数据库保护 - 145 -
到人为的盗窃或破坏;一是逻辑安全��既包括对数据保密性的保护,也包括保证数据库内
部逻辑一致,即通过良好的设计和管理手段,保证数据库的完整性、一致性、可恢复性、可
审查性等,防止因为内部逻辑混乱造成数据库损坏。 要保护数据库安全,所有的组织都要有一个明确的安全策略。安全策略明确描述了哪些
资产需要保护、保护的原因、谁负责进行保护、哪些行为可以接受、哪些不可以接受。安全
策略一般要陈述物理安全、网络安全、病毒保护和灾难恢复等内容。这个策略应当随时间而
变化,由负责数据库安全的人员��一般是 DBA 定期修改安全策略。安全策略包含了对安
全问题的多方面考虑因素,一般包括以下内容: (1)认证:谁想访问数据库。 (2)访问控制:允许谁登录数据库并进行访问。 (3)保密:谁有权查看特定信息。 (4)数据完整性:允许谁修改数据,不允许谁修改数据。 (5)审计:何时由何人导致了何事的发生。
下面介绍的一些数据库保护技术,主要就是围绕上述安全策略在数据库保护中的应用展
开的。
2.安全要求
电子政务的总体安全目标是,保护政务信息资源价值不受侵犯,保证信息资产的拥有者
面临最小的风险和获取最大的安全利益,使政务的信息基础设施、信息应用服务和信息内容
为抵御上述威胁而具有保密性、完整性、真实性、可用性和可控性的能力。具体到政务数据
库系统来看,主要的的安全需求包括: (1)明确责任。领导和责任制是政务机关基本运行制度,区分和追究责任是电子政务系
统必须提供的安全功能之一。政务数据库的安全首先需要建立合理完备的安全制度,明确管
理人员的职责。 (2)确保政务信息的保密。电子政务系统将生成、传输、处理和保存大量的信息,这些
信息既有政务机关内部的信息,也有各类社会信息,其中包括大量的不同密级的信息。因此,
“确保政务信息的保密性”实际是确保信息在电子政务、存储、传输、处理过程中,信息被
访问的时间、地点、人员、方式 4 个要素满足信息保密性的规定。政务数据库作为存储、管
理政务信息的主要对象,要特别注重保密性能。 (3)保证身份正确识别。领导制度和责任制度都是政务机关基本运行制度,两种制度的
基础都是对公务员身份的确认。与传统模式不同,电子政务系统完全建立在信息技术之上,
因此信息系统中的用户身份识别、安全保护成为电子政务安全的重要目标。在实施上,基于
信息技术的用户身份识别、安全保护体系是电子政务系统最重要的安全组成部分之一。 (4)确保用户权限。政务机关的正常运行很大程度上依赖于建立一套行之有效的“权限”
划分和管理体制。无论政务机关按照行政级别划分“纵向”职能定位,还是业务部分按照业
务性质划分部门结构,或是根据“首长负责制”来定义权限,政务机关的“权限”管理是政
务机关正常运行的基本安全保证。电子政务系统必须保证“权限”分配和管理得到良好的实
现。同样,政务数据库的使用要以合理分配权限为前提,否则无法保障数据库的安全使用。
事实上,绕过“权限”控制和管理是许多攻击者攻击成功的关键一步。

- 146 - 电子政务数据库基础
(5)确保政务业务连续运转。电子政务是目前国内重要的信息系统工程之一。伴随其建
设的进一步开展,将会有更多的政务业务依靠电子政务系统开展。电子政务系统的安全正常
运行是政务业务连续运行的保障。电子政务系统也像所有的复杂系统一样,难免发生故障,
其后果就是影响政务机关的正常、连续运行。对政务数据库而言,如何保证数据库的连续运
行,保证数据库数据的安全与恢复,为电子政务活动提供安全的数据保障,始终是一个关键
性的问题。为此,政务数据库系统必须对“连续性”保障体系进行设计,确保政务数据库系
统不会影响政务机关的连续运行。
(6)系统的安全备份与恢复机制。鉴于政务信息的重要性和特殊性,建立必要的备份制
度和有效的数据恢复机制是保障政务数据库安全的基本要求。
3.安全策略指导原则
(1)国家主导、社会参与。电子政务安全关系到政府的办公决策、行政监管和公共服务
的高质量和可信实施的大事,必须由国家统筹规划、社会积极参与,才能有效保障电子政务
安全。
(2)全局治理、积极防御。电子政务安全必须采用法律威慑、管理制约、技术保障和安
全基础设施支撑的全局治理措施,并且实施防护、检测、恢复和反制的积极防御手段,才能
更为有效。
(3)等级保护、保障发展。要根据信息的价值等级及所面临的威胁等级,选择适度的安
全机制强度等级和安全技术保障强壮性等级,寻求一个投入和风险可承受能力间的平衡点,
保障电子政务系统健康和积极的发展。
7.1.2 电子政务数据库保护常规技术
1.安全性约束
(1)视图
一般的数据库管理系统中都会提供视图这一基本的数据库对象,它既是查询一个表或多
个表的一种方法,也是加强数据安全的常用手段。利用视图,可以在政务数据库系统中“限
制”用户的视线,即隐藏用户无权存取的数据,而显示其应该看到的部分,以此达到保护敏
感数据的目的。例如,为了保护职工工资收入数据,可以定义一个不包含经济收入属性的视
图。不过,视图机制的主要目的是提供数据独立性,它虽然有一部分安全功能,但往往达不
到实际应用系统的要求。在实际使用时往往还要和访问控制相结合,才能提供更为精细、灵
活、严格的保护功能。
(2)访问控制
① 权限和角色。首先以 SQL Server 为例,来了解一下用户访问数据的一般过程.
(a)用户登录到 SQL Server 的实例,进行身份鉴别,被确认为合法时才能进入;
(b)用户在每个要访问的数据库里必须有一个账号,SQL Server 实例将 SQL Server 登录
映射到数据库用户账号上,在这个账号上定义数据库管理和数据对象访问的安全策略;
(c)检查用户是否具有访问数据库对象、执行动作的权限,经过语句许可权限的验证,
才能够实现对数据的操作。

第 7 章 电子政务数据库保护 - 147 -
上述过程中,数据库对象包括数据库、表、视图、数据字典、索引、应用程序等,执行
动作的权限则包括用户对各种数据库对象进行创建、撤销、查询、增加、删除、修改、执行
等。把对用户权限的控制称为访问控制。由此可见,访问控制由数据库对象和操作类型两个
要素之间的组合决定。对于特定用户而言,他在数据库资源上具有的权限的集合就构成了他
的访问权限。在安全数据库系统中,用户注册 DBMS 时就会被赋予相应的权限。系统根据其
访问权限来监督操作,保证该用户只执行符合其权限定义的操作。
另一个很重要的概念是角色。试想,如果要对每个用户都进行如此繁琐的权限设置,那
么授权表会变得十分复杂,对用户都进行授权检查也会很繁琐。一般的数据库中需要保密的
数据毕竟是少数,对于大部分的可公开数据,可以一次性的将公开权限授予 PUBLIC,而不
必对每个用户进行个别授权。这里的 PUBLIC 实际上是一个“角色”的概念(见图 7.1)。一
个角色实质上是访问控制权限的一个集合,可以分为固定服务器角色、固定数据库角色和用
户定义数据库角色。在一个单位中,往往很多人的工作是一样的,应对其授予同样的访问权
限。比如在行政机构中,其行政职务就具有“角色”的意味。办公室主任这个职务就代表其
相应的权利与义务的集合;技术主管、会计等都是角色的概念。
图 7.1 SQL Server 2000 中的角色和权限
(a)固定的服务器角色。这是在服务器安全模型中定义的管理员组,当几个用户共同完
成一个公共的活动时,管理员可以将他们指定到某个固定的服务器角色中。用户不能增加、
修改和删除固定的服务器角色。不同的固定服务器角色具有不同的操作数据库的权限。例如,
在 SQL Server 中,sysadmin(系统管理员)角色可以执行任何活动,而 dbcreator(数据库创
建者)角色只能创建、更改和删除数据库,不能执行服务器的链接和启动。
(b)固定的数据库角色。预定义了数据库的安全管理权限和数据对象的访问权限,存在
于每个数据库中,在数据库级别提供管理特权分组。管理员可以将任何有效的数据库用户添

- 148 - 电子政务数据库基础
加为固定数据库角色成员,每个成员获得应用于固定数据库角色的权限。用户不能增加、修
改和删除固定数据库角色。
(c)用户自定义数据库角色。通过创建用户自定义数据库角色,可以建立具有某种公共
许可权限的用户组。例如某机构中的人事管理部门中有多位职员,他们都需要访问数据库中
的人员基本情况表,因此可以添加一个自定义的数据库角色“人事管理”,并授予该角色访问
人员基本情况表的权限。之后,再将人事管理人员的数据库用户账号添加到该角色下,这样
用户就获得了对该表的访问权限。
由上可知,不同的用户对数据库拥有不同的访问权限,DBMS 要按照用户的访问权限来
控制用户的操作,必须先解决用户标识和授权的问题。
② 标识用户。前面提到,用户在登录到 SQL Server 的实例时需要进行身份鉴别,用户
标识及其鉴定是系统提供的最外层的安全控制。一般是由系统提供一定的方式让用户标识自
己的名字或身份,由系统内部记录用户的合法标识。用户标识符是用户的公开的标识,它不
足以成为鉴别用户的凭证。为鉴别身份,一般采用口令或者其他只有用户知道的私有信息。
但有时口令容易被窃取,所以可选择更为复杂的方法,如每个用户都事先约定好一个计算函
数或表达式,由系统提供随机数,用户根据约定的算法给出结果,这样每次输入的值也不会
相同,比静态口令要安全。
目前商品化的 DBMS 大都采用口令方式来识别用户。口令由用户进行选择,既要便于本
人记忆,又要防止别人猜出。口令越长越难于猜破,有些系统鼓励用户在口令中加入一些非
打印字符或者在口令首末加一些空格,这样即使口令被显示和打印,别人也难以推测。为防
止猜测口令,有的系统对于连续几次(一般少于 3 次)登录而没有通过鉴定的用户,将中止
服务,并记录在报告上。
③ 授权。授权就是给予用户一定的访问特权,是对用户权限的规定和限制。在 SQL 中,
存在两种授权:一种是授予某用户成为数据库用户的权限,这只能由 DBA 授予;一种是授
予某用户成为数据库用户的权限,这可以由 DBA 授予,也可以由数据对象创建者授予。在
SQL 的介绍中,对权限的分配和回收做了比较详细的介绍,这里就不详细介绍了。
前面讲到的角色其实是一系列权限的集合,具体到每个单位应当设置多少角色,每个角
色的权限如何界定是由各单位自行规定的。
2.完整性约束
数据库的完整性是指数据的正确性和相容性。数据库具备完整性约束是保证数据库数据
真实性的一个重要条件,能有效地防止“脏”数据的产生。为维护数据库的完整性,DBMS
提供相应的机制来检查数据库中的数据,检查其是否满足约束定义的条件。这些条件往往在
数据模式定义时与数据模式一起保存在数据字典中。
完整性控制最核心的元素是完整性约束条件。完整性约束条件作用的对象可以是属性、
元组、关系等几种对象。其中对属性的约束主要指对其取值类型、精度、范围等的约束条件。
对元组的约束是指对记录中各字段之间的联系的约束。对关系的约束是指对若干记录间、关
系间的联系的约束。
完整性约束条件涉及的这 3 种对象,其状态既可以是静态的,也可以是动态的。静态约
束就是反映数据库状态合理性的约束。而动态约束则是反映数据库从一个状态变为另一个状

第 7 章 电子政务数据库保护 - 149 -
态时应遵守的约束。如在更新职工表时,年龄、工龄等属性值一般只会增加,不会减少。
(1)完整性约束说明
完整性约束的说明有隐式和显式两种,隐式说明包括在 SQL 中讲述的主键和外键、属性
的类型等。
① 主键约束。在数据库建模中,最重要的约束就是声明某个属性(组)是该关系的主键,
其含义是禁止关系中的两个元组在主键属性上的取值一致。在 SQL 中,主键使用 PRIMARY
KEY 说明。与主键类似的还有候选关键字,它使用 UNIQUE 说明。两者的区别在于一个关
系中主键只能有一个,且不允许取空值;候选关键字则可以有多个,并允许为空值。
② 外键约束。外键表示现实世界中实体之间的关系,它实现两个关系之间相应属性之间
的依赖关系。在 SQL 中使用 REFERENCES 说明,具体语法参见 SQL 相关部分。使用外键
可以表达两个实体之间一对一和一对多的关系。
③ 非空约束。在 SQL 中使用 NOT NULL 进行说明,表示该属性不能为空。
④ 数据类型说明。在关系创建时用于说明属性的数据类型就是一种隐含的约束条件,像
性别选项,选择逻辑数据类型就决定了性别只能有两种选择。
显式说明有以下几种。
① 用过程说明约束。这种方法将约束的说明和检验交给应用程序进行。即在应用程序中
插入一些过程,检验数据库更新是否违反给定的约束,如果违反则卷回事务。检验约束的过
程一般用通用高级语言编写,可以表达各式各样的约束。虽然这种方法会造成约束检验分散
在应用程序中,不便于维护,但由于此法容易实现,目前应用较多。
② CHECK 约束。利用 CREATE TABLE 的 CHECK 子句可以实现对一个表中属性或属性
之间的关系的约束。
CREATE TABLE worker(
id char (8),
sex char(2) CHECK (’sex’=’男’OR ’sex’=’女’),
department char (16))
③ 用断言说明。断言表示数据库状态必须满足的条件,数据库完整性约束可以看做一系
列断言的集合。断言可以实现多个关系间的约束条件,比如要求各部门负责人的年龄应当在
30 岁以上的约束,就可以使用断言,如下所示:
CREATE ASSERTION header-age CHECK
(NOT EXISTS
(SELECT Pname FROM personnel
WHERE year (DATE(�))-year(Pbirth)<30 AND
Pname=
(SELECT Dheader FROM department)))
该语句创建了一个名为 header-age 的断言约束;NOT EXISTS 及其后的语句表示不存
在年龄小于 30 岁的部门负责人,否则该条件不满足。
采用此方法的 DBMS 必须提供断言说明语言, 系统对数据管理的有关规则定义成断言
的形式,并加以集中组织构成约束库。这样,就避免了程序员分散考虑完整性约束的问题,
减少了编程和维护的麻烦。可以看到,使用断言约束可以对主键、外键等约束形式无能为力

- 150 - 电子政务数据库基础
的约束进行说明。不过这种方法实现起来比较复杂,会降低数据库更新的性能。
④ 用触发器表示约束。触发器是 SQL 的一个扩充,是特殊的存储过程。其中的动作是
由合法的 SQL 语句表示的。表示当触发事件发生时,激活相应的触发器程序按照拟定的规则
执行。其中触发事件仅仅限于数据库的 UPDATE、INSERT、DELETE 3 种操作。触发器本身
是关系模式的一部分,其定义存放在数据字典中。由此可见,可以很容易地将完整性约束检
验置入触发器规则中,由系统自动调用,主动执行一些事先安排的处理,从而增强 DBMS 的
主动功能。
(2)完整性约束的实施
在关系系统中,最重要的完整性约束是实体完整性和参照完整性,其他完整性约束条件
则可以归入用户定义完整性。目前多数关系 DBMS 都提供定义和检查实体完整性、参照完整
性和用户定义完整性的功能。随着计算机性能的提高和约束检验方法的改进,在 DBMS 商品
中,比较全面的完整性约束检验有望成为标准功能。
对于不同类型的完整性约束,系统提供的反应方式有所不同。对于违反实体完整性和用
户定义完整性约束的操作,系统一般拒绝进行。而对于违反参照完整性的操作,则不是简单
地加以拒绝,而是提供一些附加操作,以保证数据库的正确状态。
3.并发控制
目前很多数据库系统都是支持多用户的,可以同时运行多个事务并行存取数据,从而充
分利用系统资源,发挥数据库共享资源的特点。因此并发控制机制是衡量一个数据库系统性
能的重要标志之一。数据库系统的并发控制机制协调并发操作以保证事务的隔离性和数据的
一致性。当今流行的关系数据库系统(如 Oracle,SQL Server 等)是通过事务隔离级别
(Transaction Isolation Level)与封锁机制来定义并发控制所要达到的目标的。
事务和锁是两个紧密联系的概念。事务就是一个单元的工作,包括一系列的操作。这些
操作要么全部成功,要么全部失败。事务能够确保多个数据的修改作为一个单元来处理。例
如,在银行业务中,有一条记账原则,即有借有贷、借贷相等。那么为了保证这种原则,就
得确保借和贷的登记要么同时成功,要么同时失败。如果出现只记录了借,或者只记录了贷,
那么就违反了记账原则,就会出现记错账的情况。系统通过支持事务机制管理多个事务,保
证事务的一致性。事务使用锁来防止其他用户修改另外一个还没有完成的事务中的数据,使
用事务日志来保证修改的完整性和可恢复性。
(1)并发异常问题。通过下面几个示例,模拟共享系统中的并发事务数据处理情况。可
以看到,尽管事务本身的执行是正确的,但是如果没有合适的并发处理机制,由于相互间的
干扰,可能会产生错误的总体结果。
① 丢失更新。当两个事务 T1 和 T2 同时更新某条记录时,它们读取记录并修改。事务
T2 提交的结果将破坏 T1 提交的结果,导致 T1 的修改结果丢失,因此出现“丢失更新”的问
题。例如表 7-1 是银行数据库中一个经过简化的账户表(account)信息的数据字典定义。
某会计人员在银行前台取款 2000 元,银行出纳 A 查询用户的存款信息显示银行存款余
额 30000 元;正在这时,另一银行账户转账支票支付该账户 5000 元,机器查询也得到当前用
户存款 30000 元。这时出纳员 A 看到用户存款超过了取款额,就支付了客户 2000 元并将用
户存款改为 28000 元,而银行的另一名操作员 B 根据支票,将汇入的 5000 元加上,把用户

第 7 章 电子政务数据库保护 - 151 -
的余额改为 35000 元。很明显银行将会损失 2000 元,因为出纳员 A 所做的修改被操作员 B
覆盖了。
表 7-1 银行数据库账户表信息的数据字典定义
② “脏”数据。“脏”数据是指事务 T1 修改某一条记录,将其写入数据库,事务 T2 读
取同一条记录后,T1 由于某种原因被撤销,此时 T1 已修改过的数据恢复原值,但 T2 读到的
数据却和数据库中的数据不一致了,这个数据被称为“脏”数据。
例如,在办公自动化系统中进行会议日程安排,办公人员甲向会议日程安排表中录入一
个会议安排:定于 2004 年 12 月 11 日下午一点在 302 室开会,同时办公室主任乙在打印本周
会议安排,结果打印清单中已经包括了甲刚刚录入的信息。但甲临时收到通知取消会议,因
此他取消了插入的提交,该记录被取消。这时,乙的打印清单中会议信息已经和数据库中的
不一致了。
③ 不可重复读取。不可重复读取也成为不一致的分析,是指事务 T1 读取数据后,事务
T2 对同一数据执行更新操作,使 T1 再次读取该数据时,得到与前一次不同的值。
例如,资金转账过程中需要打印票据,系统中事务活动顺序如下。
(a)事务 T1 打印 A 账户转账前的余额,设 A=10 万元。
(b)事务 T1 从 A 账户转出 1 万元,A=9 万元。
(c)事务 T2 从 B 账户转入 A 账户两万元,A=11 万元,T2 提交。
(d)事务 T1 打印 A 账户转账后的余额,设 A=11 万元,T1 提交。
因为 T2 在 T1 操作过程中,更新了 A 账户的余额,使得 T1 在第 2 次读取 A 账户余额时得
到的结果与它的转账操作结果不相符合,多了两万元。
④ 幻影数据。事务 T1 按一定条件从数据集中读取数据后,事务 T2 对该数据集删除或插
入了一些记录,这时事务 T1 再按相同条件读取数据时,发现少了或多了一些记录。
例如,办公人员甲统计本月迟到人数,他首先打印了一份迟到人次清单。与此同时,办
公人员乙向迟到情况记录表中插入了一条新的记录并提交成功。甲发出指令统计表中的迟到
人次总数并提交。这时他发现,统计出来的人次比他刚刚打印出来的清单上的记录数多了一
个。
产生并发异常问题的主要原因是并发操作破坏了事务的隔离性,导致数据不一致。并发
控制的目的是要用正确的方式调度并发操作,使一个事务的执行不受其他事务的干扰,保证
数据一致性。
(2)锁。用加锁的方法实现并发控制,就是在操作前先对数据对象加锁。为保证调度的
可串行化,加锁必须遵守一定的规定,这就叫做加锁协议。不同的 DBMS 提供的锁的类型不
列 名 称 列 代 码 列 类 型
账户号 Id(键值列) Char(10)
户主 Uname Char(10)
存入金额 Mdeposit Currency
支出金额 Mpayout Currency
存款余额 Mbalance Currency

- 152 - 电子政务数据库基础
完全一致,加锁协议也有所区别。例如,Microsoft Sql Server 系统中有 4 种锁:共享锁、排
它锁、意向锁(又分为共享意向锁、排它意向锁、共享意向排它锁)、更新锁。前两者为基本
锁,后两者为特殊情况的专用锁。
① 排他锁(X 封锁)。又称为“写锁”。如果事务 T 对数据对象 R 加上 X 锁,则只允许
T 读取和修改 R,其他任何事务都不能再对 R 加任何类型的锁,直到 T 释放 R 上的 X 锁。使
用加排他锁,可以有效防止“丢失更新”和读“脏”数据。
② 共享锁(S 封锁)。又称为“读锁”。如果事务 T 对数据对象 R 加上 S 锁,则其他事
务也可以对数据对象 R 加 S 锁,但不能对 R 加 X 锁,直到 R 上的所有 S 锁都被释放为止。
使用加共享锁,可以避免数据一致性被破坏,但是降低了并发性。它主要防止在读数据期间
对数据进行其他修改,通过多个事务同时加 S 锁,能够完成对同一数据的并行读取操作,可
以防止“幻影数据”的出现。
③ 锁的粒度。锁的粒度指封锁目标的大小。下表 7-2 列出了 SQL Server 能够锁定的各
种资源。
表 7-2 SQL Server 能够锁定的各种资源
资 源 描 述
RID 表中的单个行
KEY 索引中的行
PAGE 一个数据页或索引页
EXTENT 一组数据页或索引页
TABLE 整个表
DATABASE 整个数据库
封锁的粒度与并行度和系统并发控制的开销有关。为了最小化锁的成本,SQL Server 自
动地以与任务相应等级的锁来锁定资源对象。锁定比较小的对象,例如锁定行,虽然可以提
高并发性,但是却有较高的开支,因为如果锁定许多行,那么需要占有更多的锁。锁定比较
大的对象,例如锁定表,会大大降低并发性,因为锁定整个表就限制了其他事务访问该表的
其他部分,但是成本开支比较低,因为只需维护比较少的锁。
④ 死锁。在事务和锁的使用中,死锁是一个不可避免的现象。例如,事务 T1 具有表 1
上的排他锁,之后要求对表 2 进行锁定。事务 T2 具有表 2 上的排他锁,之后需要对表 1 进行
锁定。事务 T1 无法对表 2 加锁,因为事务 T2 已经锁定表 2 了。同样事务 T2 也无法对表 1 加
锁,因为事务 T1 已经锁定了表 1。T1 和 T2 互相阻塞,都在等待对方释放已锁定的资源,因
为需要被对方锁定的资源才能将当前事务继续下去,但事务在提交或回滚之前又不能释放自
己持有的锁,所以它们既不能提交又不能回滚,从而形成死锁,如图 7.2 所示。
当发生死锁时,系统可以自动监测到,然后通过自动取消其中一个事务来结束死锁。一
般根据事务处理时间的长短来确定它们的优先级。处理时间长的事务具有较高的优先级,因
此发生死锁时,一般会取消处理时间短的事务。
为了预防死锁的发生,可以参照下述方式进行。
� 按照统一顺序访问资源。如果所有并发事务按预先规定的一个顺序封锁资源,则发生
死锁的可能性会降低。但当数据库中封锁的数据对象很多时,就很难按预定顺序实施

第 7 章 电子政务数据库保护 - 153 -
封锁了。
图 7.2 死锁
� 避免事务中的用户交互。因为运行没有用户交互的处理的速度会大大缩短,也避免因
用户的突发事件(如用户长时间离开)使得某个事务一直被挂起而无法释放它锁定的
资源。
� 保持事务简短。事务运行时间越长,持有排他锁的事件就越长,从而阻塞了其他活动
并可能导致死锁。
通常说的并发控制是指在 DBMS(数据库管理系统)内部进行的并发控制。而并发控制
的方法非常丰富,远不止此。可以借助于数据库本身的能力,也可以利用开发工具,还可以
通过调整自己的程序来实现。在数据库应用中,进行并发控制的方法、实现途径多种多样。
在选择时所依据的基本原则就是:数据一致性一定要合乎应用的需要,在此基础上,尽量提
高并发度。
7.2 数据库保护相关技术
由于电子政务数据库中的数据大多关系到国计民生,因此,除了利用常规技术对数据库
安全进行保护以外,为了防范意外事故的发生,还必须采取适当的备份和恢复策略,这样才
能够以最短的系统停机时间、最少的数据损失量来恢复数据。同时,随着信息系统和网络应
用的飞速发展,计算机世界也越来越频繁地发生一些重大灾害,因此,重视电子政务数据库
系统的容灾管理技术研究,也是目前电子政务数据库研究的一个新兴热点。另外,电子政务
数据库保护作为电子政务安全体系中的一环,与国家信息安全密切相关。除了需要从技术方
面加强保护外,还应当建立起一套完整规范的法律体系,从而提高信息安全保障能力。下面
将分别从这 3 个方面做详细介绍。
7.2.1 数据库备份与恢复
计算机系统的各种软硬件故障、用户误操作以及恶意破坏是不可避免的,这将影响到数
据的正确性甚至造成数据损失、服务器崩溃的致命后果。备份和恢复对于保证系统的可靠性

- 154 - 电子政务数据库基础
具有重要的作用。经常备份可以有效防止数据丢失,使管理员能够把数据库从错误的状态恢
复到已知的正确状态。如果用户采取适当的备份策略,就能够以最短的系统停机时间、最少
的数据损失量来恢复数据。
备份和恢复还有其他用途。例如:可以将一个服务器上的数据库备份下来,再把它恢复
到其他的服务器上,实现快速移动数据库。
1.恢复技术
(1)转储
转储简单来讲就是备份,可以将整个数据库复制到磁盘或磁带设备上以保存备用。一旦
系统发生介质故障,数据库遭到破坏后就能够将备份副本重新装入,恢复数据库。转储是数
据库恢复技术中经常采用的技术,但通过重新装入备份文件只能将数据库恢复到转储时的状
态,而不能恢复到发生故障时的状态。要想恢复到发生故障时的状态,还必须重新运行自转
储以来所进行的所有更新操作。对于这些更新操作,一般根据日志记录来恢复。
(2)日志记录
为了能够从影响事务的故障状态中恢复,系统维护一个日志来记录所有影响数据库项的
值的事务操作。日志保存在磁盘上,也会定期备份到归档存储设备(磁带)中以预防磁盘和
灾难性故障。表 7-3 列出的是日志的条目类型和每个类型涉及的相关动作。
表 7-3 日志的条目类型和每个类型涉及的相关动作
条 目 类 型 描 述
[start_transaction,T] 表示事务 T 开始执行
[write_item,T,X,旧值,新值] 表示事务 T 已将数据项 X 的值从旧值改为新值
[read_item,T,X] 表示事务 T 已读取数据项 X 的值
[commit,T] 表示事务 T 已成功完成,其结果已被永久提交给数据库
[abort,T] 表示事务 T 已被撤销
2.备份和恢复策略
(1)传统 DBMS 的恢复策略
不同的 DBMS 的恢复策略是不同。例如,SQL Server 2000 提供了 3 种恢复模型:简单
恢复模型、完全恢复模型和大容量日志记录恢复模型。Sybase 数据库的备份则可分为冷备和
热备。冷备方法是在数据库启动的时候,利用 DUMP DATABASE 命令,将数据库备份到指
定的磁盘或磁带设备上。当系统失效时,利用 LOAD DATABASE 命令便可以启动磁盘或磁
带上的数据恢复系统。冷备的方法虽然简单,但实施起来却有较大的难度。因为当数据库备
份运行时,所有运行的在线业务都必须停顿下来,因此数据库备份对运行系统的影响非常大,
并且需要消耗大量的处理器资源,对主机上的其他应用影响比较大。这也是冷备的最大缺点。
另外,由于当前对业务系统的可用性要求越来越严格,备份窗口变得越来越小,这对实施冷
备带来了极大的挑战。SYBASE 数据库的热备,一般是通过 SYBASE 公司的复制服务器产品
来实现,很多其他的数据库产品也提供类似的技术。利用复制服务器实现热备来维护一对数
据库服务器,这两个数据库在平时都是激活的,并且在复制系统中如同一个逻辑的整体,其

第 7 章 电子政务数据库保护 - 155 -
中一个数据库为另一个数据库的备份。客户端应用通常修改主数据库,复制服务器通过 LTM
读取主数据库日志,并通过 LAN 或 WAN 不断地将日志的变化同时实施到备份数据库上。热
备需要占用网络带宽,这在主数据库数据变化不大的情况下没有问题,当数据变化较大时,
就会对其他的一些网络应用造成影响。
(2)数据库恢复技术新进展
① 基于多副本的恢复技术。多用于分布式数据库系统中,出于对性能和其他因素的考
虑,在不同的节点上设置数据副本,并且它们都有独立的失效模式。所谓独立的失效模式是
指各个副本不会因为同一故障而一起失效。为获得独立的失效模式,各副本的支撑环境应尽
可能的独立,例如不共用电源、磁盘、CPU、控制器等。
② 远程磁带库、光盘库备份。将数据传送到远程备份中心制作完整的备份磁带或光盘。
③ 远程关键数据+磁带备份。采用磁带备份数据,生产机实时向备份机发送关键数据。
④ 远程数据库备份。就是在与主数据库所在生产机相分离的备份机上建立主数据库的
一个复制。
⑤ 网络数据镜像。这种方式是对生产系统的数据库数据和所需跟踪的重要目标文件的
更新进行监控与跟踪,并将更新日志实时通过网络传送到备份系统,备份系统则根据日志对
磁盘进行更新。
⑥ 远程镜像磁盘。通过高速光纤通道线路和磁盘控制技术将镜像磁盘延伸到远离生产
机的地方,镜像磁盘数据与主磁盘数据完全一致,更新方式为同步或异步。
目前很多数据库和存储方案提供商都推出了各自的备份方案。例如 HP 公司推出的 HP
磁带库备份方案,就是基于数据镜像与磁带库结合的备份方式,主要针对 Sybase 数据库用户
开发。它利用磁带库与备份软件建立了一套全面的数据库备份方案,能够为 Sybase 数据库用
户提供各种方式的备份,包括在线备份、打开文件的备份和零停机备份、零影响备份,消除
了计划内的停机时间,完全消除了 Sybase 数据库传统冷备与热备时的不尽人意之处。 (3)数据库备份操作策略
一般建议的备份操作策略为:在安装完成或做了新加 Login、增加数据库设备和数据库
空间等操作后,应做 master 库的备份;3 天至一周做一次用户数据库的全库备份,每天做用
户数据库的增量(日志)备份;建议在每次备份前对要备份的数据库做检查以确保其备份的
可用性。在条件许可时,应定期对用户数据库中的关键用户数据表做数据备份。
当然还可以根据各个行业的实际应用情况,制定个性化的备份方案,针对中小型数据库,
用户可以每天做一次数据库全备份(DUMP DATABASE);对于大型数据库(如大于 40GB),
用户应当每周做一次数据库全备份��如选择周日,其他时间做增量备份��如周一至周
六。另外也可以为每天做一次数据库全备份(DUMP DATABASE),但每天使用不同的磁带
或其他设备,同时保持 7 个备份,以确保某一个备份失败时,其他的备份能顶替。
7.2.2 容灾管理技术
1.数据备份与容灾
数据备份和恢复技术为数据库数据日常的安全使用提供了一定的保障,但是随着信息系
统和网络应用的飞速发展,计算机世界也越来越频繁地发生一些重大灾害,下面列举的都是

- 156 - 电子政务数据库基础
一些触目惊心的真实例子。
(1)1993 年,世贸中心大楼发生爆炸。爆炸前,约有 350 家企业在该楼中工作,一年后,
回到世贸大楼的公司变成了 150 家,有 200 家企业由于无法恢复重要的信息系统而倒闭、消
失。
(2)1995 年 1 月,日本神户地区大地震,摧毁了 1700 余部电脑系统,造成一千多亿美
元的损失。
(3)1999 年 6 月,美国一家著名的商业交易网站的主机宕机,由于 24 小时内未能恢复
访问,两个星期后,该公司的股票市值下跌了 36%。
(4)2003 年,国内某电信运营商的计费存储系统发生两个小时的故障,造成 400 多万元
的损失。这些还不包括导致的无形资产损失。
据 IDC 的统计数字表明,美国在 2000 年以前的 10 年间发生过灾难的公司中,有 55%
当时倒闭,剩下的 45%中,因为数据丢失,有 29%也在两年之内倒闭,生存下来的仅占 16
%。Gartner Group 的数据也表明,在经历大型灾难而导致系统停运的公司中有 2/5 再也没有
恢复运营,剩下的公司中也有 1/3 在两年内破产。
不过与此形成鲜明对比的是,在 2001 年世贸大厦倒塌后,在世贸大厦租有 25 层的金融
界巨头摩根斯坦利公司事发后几个小时就宣布:全球营业部第二天可以照常工作。这是因为
该公司建立的数据备份和远程容灾系统,保护了重要的数据。数据备份和远程容灾系统在关
键时刻挽救了摩根斯坦利,同时也在一定程度上挽救了全球的金融行业。
容灾是一个范畴比较广泛的概念,广义上,可以把所有与业务连续性相关的内容都纳入
容灾。容灾是一个系统工程,它包括支持用户业务的方方面面。而容灾对于 IT 而言,就是提
供一个能防止用户业务系统遭受各种灾难影响破坏的计算机系统。容灾还表现为一种未雨绸
缪的主动性,而不是在灾难发生后的“亡羊补牢”。
从技术上看,衡量容灾系统有两个主要指标:RPO(Recovery Point Object)和 RTO
(Recovery Time Object),其中 RPO 代表了当灾难发生时允许丢失的数据量,而 RTO 则代表
了系统恢复的时间。RPO 与 RTO 越小,系统的可用性就越高,当然用户需要的投资也越大。
备份与容灾是存储领域两个极其重要的部分,二者既有紧密的联系,又是两个不同的概
念。首先,两者关注的对象有所不同,备份关心数据的安全,容灾关心业务应用的安全,可
以把备份称做是“数据保护”,而容灾称做“业务应用保护”。备份最多表现为通过备份软件
或使用磁带机和磁带库将数据进行复制,也可以使用磁盘、光盘作为存储介质;容灾则表现
为通过高可用方案将两个站点连接起来。
两者的联系则表现在:首先,在备份与容灾中都有数据保护工作,备份大多采用磁带方
式,性能低,成本低,容灾采用磁盘方式进行数据保护,数据随时在线,性能高,成本高;
其次,备份是存储领域的一个基础,一个完整的容灾方案必然包括备份的部分;同时备份还
是容灾方案的有效补充,因为容灾方案中的数据始终在线,因此存储有完全被破坏的可能,
而备份提供了额外的一条防线,即使在线数据丢失也可以从备份数据中恢复。
2.容灾的等级划分
大体上讲,容灾可以分为 3 个级别:数据级别、应用级别以及业务级别。从对用户整个
业务连续性的保障程度来看,它们的可用级别也逐渐提高(见图 7.3)。

第 7 章 电子政务数据库保护 - 157 -
%
) ’ ’ ,��������$ 7 0 �6ZLWFKHV�+ XEV
? ? ? ?
? ? ? ?
? ?
? ?
$
� � � �
图 7.3 容灾的三个级别
(1)数据级别
数据级容灾较为基础,其中,较低级别的数据容灾方案仅需利用磁带库和管理软件就能
实现数据异地备份,达到容灾的功效;而较高级的数据容灾方案则是依靠数据复制工具,例
如卷复制软件,或者存储系统的硬件控制器,实现数据的远程复制。数据级别容灾是保障数
据可用的最后底线,当数据丢失时能够保证应用系统可以重新得到所有数据。从这种意义上
讲,数据备份属于该级别容灾,用户把重要的数据存放在磁带上,如果考虑到高级别的安全
性还可以把磁带运送到远距离的地方保存,当灾难发生后再从磁带中获取数据。
该级别灾难恢复时间较长,仍然存在风险,尽管用户原有数据没有丢失,但是应用会被
中断,用户业务也被迫停止。这种方案花费较低,构建简单。
(2)应用级别
对于业务应用繁多、并且系统需要保持 7×24 小时连续运行的企业来说,显然需要高级
别的应用容灾系统来满足他们的需求。 应用级容灾是在数据级容灾的基础上,再把执行应用处理能力复制一份,也就是说,在
备份站点同样构建一套应用系统。应用级容灾系统能提供不间断的应用服务,让用户应用的
服务请求能够透明地继续运行,而感受不到灾难的发生,保证信息系统提供的服务完整、可

- 158 - 电子政务数据库基础
靠、安全。
一般来说,应用级容灾系统需要通过更多软件来实现,它可以使企业的多种应用在灾难
发生时进行快速切换,确保业务的连续性。
(3)业务级别
用户构建的数据级容灾和应用级容灾都是在 IT 范畴之内,然而对于正常业务而言,仅有
IT 系统的保障还是不够的。用户需要构建最高级别的业务级别容灾。业务级容灾的大部分内
容是非 IT 系统,比如电话、办公地点等。因为当一场大的灾难发生时用户原有的办公场所都
会受到破坏,用户除了需要原有的数据、原有的应用系统,更需要工作人员在一个备份的工
作场所能够正常地开展业务。
在电子政务系统中,随着越来越多的重要文件和数据存储在电脑系统里,一旦发生大规
模的病毒侵害,以及其他一些天灾人祸,都将对电脑系统中的数据安全构成直接威胁,因此,
政务系统的容灾系统建设刻不容缓。目前我国电子政务应用比较先进的大中型城市相继开始
重视容灾系统的建设。2004 年 4 月 22 日北京市电子政务和信息安全工作会议提出,北京市
将集中统一建设异地容灾备份中心。从 2004 年起,北京市准备用 3 年的时间建立这种保障体
系。首先选择工商、税务、医疗、交通、水电热气等 20 个信息系统推行安全风险评估和安全
等级保护,并积极准备集中统一建设异地容灾备份中心。同时,北京市信息化工作领导小组
将全面实施信息安全等级制度,对重要信息系统实现同城备份,全面启动应急保障和容灾备
份体系建设。2004 年 8 月上海市信息委已着手研究建设电子政务容灾备份系统,以确保每份
网上公共数据都可以得到复制备份,安全存储。预计年内将启动容灾备份平台建设,并鼓励
有条件的企业和社会组织取得信息安全服务资质,积极参与信息系统的灾难备份设施建设并
提供技术支持,为广大中小企业及部分市民提供容灾备份的社会化服务,切实提高上海市的
信息安全应急反应的整体水平。
3.恢复演习
无论怎样的容灾方案,最终目的都是在
于灾难发生后能够在可以接受的时间内快
速恢复系统的正常运行。那么建立的系统在
灾后能不能快速恢复呢?这就需要系统在
正常运行时能够进行灾难恢复演习,只有这
样才能保证容灾系统确实可行。至于怎样确
定恢复演习的频率,什么时间进行恢复演
习,怎样进行恢复演习,就需要首先对系统
进行风险评估,了解自己的需求,以此来制
定灾难恢复演习计划。
7.2.3 数据库保护的法律相关问题
电子政务数据库安全只是电子政务安
全体系中的一环(见图 7.4),并且与国家信
图 7.4 电子政务安全体系总体结构

第 7 章 电子政务数据库保护 - 159 -
息安全密切相关。国家信息安全实际上是由两方面构成的。其一是国家在信息安全方面采取
的一系列组织措施及有关政策、法规;其二是强有力的、切实可行的技术手段及有关技术装
备。前者反映了一个国家在信息安全方面的决心、意志和战略、策略;后者反映了一个国家
在信息安全方面的实力。信息技术是信息安全的前提和基础,信息安全的国家发展战略(包
括信息安全法律制度),早已从一个产业问题上升为一个事关国家的社会、文化、军事等各方
面的核心问题。在信息安全中其地位举足轻重,尤其作为信息技术相对落后的我国如何调整
信息安全战略,完善信息安全保障法律规范,不仅是提高信息安全保障能力的手段和方法,
而且是提高信息安全技术的前提和保证。
1.世界各国信息安全法律政策现状
纵观各国信息安全法律政策,其主要特征如下。
(1)明确职责,分工协调。各国在其信息安全法律政策中都明确规定了国家信息安全工
作的管理机构以及各个机构的职责范围,在各个层次上都力求做到分工负责、各司其责。如
美国的《计算机安全法》明确规定,由商务部所属的国家标准和技术局(NIST)负责有关敏
感信息的信息安全工作,具体负责主持制定和推广计算机安全标准和指导方针,为联邦政府
解决各种信息安全问题,其中包括安全规划、风险管理、应急计划、安全教育培训、网络安
全加密技术、身份认证、智能卡应用、计算机病毒检测与防治等;由国防部所属的国家安全
局(NSA)负责例如“国家安全系统”,即由政府及其合同单位或代理机构管理的信息系统
中保密信息的信息安全工作,其中包括国家保密信息。
(2)通力配合,全面保障。信息安全是个巨大的系统工程,需要各方面力量的综合协调,
全面保障涉及信息活动的人员、信息系统的实体、信息系统的运行和系统中的信息的安全。
因此,信息安全保障应当以全面、严密为基础。如美国政府出版的《信息系统安全产品和服
务目录》中提出:对信息系统的各个环节以及各机构信息安全管理工作的效率加以评估;全
力支持对安全措施的投入;协调各个机构的信息安全工作;监督政府信息安全管理原则、标
准、指导方针的制定和推广工作;强化计算机信息系统人员的安全法律培训。
(3)制定准则,有章可循。20 世纪 80 年代,美国率先在计算机保密模型(Bel& La padula
模型)的基础上制定了《可估计算机系统安全评价准则》(TCSEC),随后又制定了关于网络
系统、数据库等方面的系列安全解释,形成了安全信息系统体系结构的最早原则。20 世纪 90
年代初,欧洲英、法、德、荷 4 国共同提出了包括保密性、完整性、可用性等性质的《信息
技术安全评价准则》(ITSEC)。近年来,美国国家安全局、美国国家技术标准研究所和加、
英、法、德、荷等 6 国 7 方共同提出了《信息技术安全评价通用准则》(CC for ITSEC),综
合了国际上已有的评价准则和技术标准的精华,给出了信息安全保护的框架和原则要求。
2.我国电子政务中信息安全的保护对策
针对我国信息安全的现状,结合我国电子政务的实际,当前在政府信息安全的保护方面
的当务之急如下。
(1)尽快建立我国信息安全的保护体系
① 健全信息安全保护的组织机制。目前国家级的信息化工作领导组织是国家信息化工作
领导小组,它主要负责对网络信息的国家发展总体战略进行规划、设计、研究,组织、协调、

- 160 - 电子政务数据库基础
配合有关部门进行立法调研,使国家在网络信息方面的立法成为一个有机的整体,但地方政
府和重点保护的重要领域相应的组织机构还不健全。《中华人民共和国计算机信息系统安全
保护条例》中确立了公安部主管全国计算机信息系统安全保护工作,但由于编制等原因许多
地方公安机关没有成立专门的机构,目前随着互联网迅速发展,网络犯罪行为日益猖狂,网
络安全问题亟待解决,而适应计算机信息技术高速发展的警力配备却严重不足。最好能组建
国家信息安全委员会,组织和协调国家安全、公安、保密等职能部门,在信息化建设中进行
信息安全的分工,对国家信息安全政策统一步调、统筹规划。因此尽快健全相应的信息安全
保障的组织机构是信息安全保护的组织保证。
② 完善国家信息安全基础设施建设。我国目前信息安全基础设施的建设还处于初级阶
段,需要逐步完善。当前迫切需要建立的国家信息安全基础设施包括:国际出入口监控中心、
安全产品评测认证中心、病毒检测和防治中心、关键网络系统灾难恢复中心、系统攻击和反
攻击中心、电子保密标签监管中心、网络安全紧急处置中心、电子交易证书授权中心、密钥
恢复监管中心、密钥基础设施与监管中心、信息战防御研究中心等。其中,国际出入口监控
中心和安全产品评测认证中心已初步建成。安全产品评测认证中心由安全标准研究、产品安
全测试、系统安全评估、认证注册部门和信息安全专家委员会组成。国家信息安全基础设施
建设是信息安全技术保证。
③ 确立信息安全产业的策略。目前我国的信息产业无论是技术、管理,还是生产规模、
服务观念,都不具备力量在短时间内使国产信息产品占领国内的主要市场。但是我国必须建
立起独立自主的信息安全产业。自主的信息产业或信息产品国产化是信息安全的根本。国产
化不等于绝对安全,而绝对安全却需要国产化。国家可集中人力、物力和给以相应政策,大
力发展自主的专用芯片、自主嵌入式操作系统和自主的密码技术产品等,以确保关键部门的
信息系统的安全。信息安全产业的策略是信息安全的基本保证。
(2)进一步完善我国信息安全保障的法律体系
虽然我国已颁布相当数量的信息安全方面的法律规范,国家级的包括《计算机病毒防治
管理办法(总管理员)》、《电子政务信息安全保障体系(admin)》、《中华人民共和国计算机信
息系统安全保护条例》、《中华人民共和国计算机信息网络国际联网管理暂行规定实施办法
(admin)》、《计算机信息网络国际联网安全保护管理办法(admin)》、《金融机构计算机信息
系统安全保护工作暂行规定(admin)》、《联网单位安全员管理办法(试行)》、《信息技术安全
标准目录(admin)》、《全国人民代表大会常务委员会关于维护互联网安全的决定》等,省市
级的有《北京市国家机关信息安全事件定级指南(试行)(服务中心))、《北京市国家机关重
大信息安全事件调查处理办法(试行)(服务中心)》等。另外还出台了一些自律法规,如《互
联网站禁止传播淫秽色情等不良信息自律规范(服务中心)》和《搜索引擎服务商抵制违法和
不良信息自律规范(服务中心)》。可以看到,目前我国在信息安全立法方面正逐步向发达国
家靠拢,已经较 20 世纪 90 年代有了不小的进步,但存在的问题主要体现在:立法层次不高,
现行的有关信息安全的法律规范大多只是国务院制定的行政法规或国务院部委制定的行政规
章;法律规定之间不统一;立法理念和立法技术相对滞后等。因此,要进一步完善我国信息
安全的法律保障体系应当做到:
① 确立科学的信息安全法律保护理念。为了使国家的政策法律能够适应社会存在的现实
和需求,需要确立起法制建设要保障和促进国家的信息化发展、法制建设为社会信息化发展

第 7 章 电子政务数据库保护 - 161 -
提供全面服务的指导思想,修正传统的立法理念,从彻底改革国家传统的经济体制和保障机
制入手,改变落后的调整方法,把信息安全法制保障的重点从单纯的“规范”、“控制”转移
到首先为信息化的建设与发展“扫清障碍”上来,以规范发展达到保障发展,由保障发展实
现促进发展,构筑促进国家信息化发展的社会环境,形成适于信息网络安全实际需要的法治
文化。
② 构建完备的信息安全法律体系。信息化的社会秩序主要由三个基础层面的内容所构
成,即信息社会活动的公共需求,信息社会生活的基本支柱和信息社会所特有的社会关系。
信息社会活动的公共需求往往是以政府意志的形式代为表现的社会公众的共同意愿,其主要
包括国家信息化建设的基本目标、发展纲领、建设规划、行动策略、工作计划等等,是指导
国家信息化发展的基本内容,也是国家信息化建设的公共需求;信息社会生活的基本支柱是
由信息化的技术属性所决定的、国家信息化建设赖以萌芽、生成和发展的信息技术及其应用,
包括计算机技术、网络技术、通信技术、安全技术、电子商务技术等等,它是信息社会生活
必不可少的基本支柱;信息社会所特有的社会关系是指在国家信息化建设的过程中,参与其
中的各个主体之间由于其信息化活动而产生的各种社会关系,具体将表现为相应的法律关系,
其中主要包括信息民事法律关系、信息刑事法律关系、信息经济法律关系、信息行政法律关
系、信息科技法律关系以及信息社会所特有的各种法律关系。与之相适应,国家信息化建设
所应有的政策法律环境也就必然是由对应的指导政策、技术标准和法律规范等三项内容所共
同构建的三位一体的且能够发挥促进、激励和规范作用的有机的体系。
③ 强化超前的信息安全法律效率。信息技术突飞猛进,信息安全政策、法律的促进作用
不应仅仅是被动适应和滞后,在国家信息化建设中,更多地还应表现为对技术的主动规范性
和前瞻性。信息安全政策法律必须促进信息技术的进步,因此要强化超前的信息安全政策法
律的效率。在制订政策和创设法律时应当借鉴国际社会关于“技术中立”的主流思想,注意
政策和法律符合技术的特殊要求,同时为技术的发展和完善预留空间,排除可能窒息技术发
展的可能性,提高法律自身对信息社会的适应性。在具体做法上,则可以吸取外国的“明示
式”和“开放式”立法模式中有益的成分,参照“准则式”的立法模式解决技术和法律之间
的矛盾,鼓励技术创新,开发自主的知识产权,加强技术标准体系的建立和完善,提高国家
信息法律规范的效率。
④ 主动融入国际信息安全的法律体系。世界经济一体化,使得“法律全球化不仅有条件,
有可能,而且有必要,更是一种发展趋势”。由于信息化是建筑在例如因特网的国际互联基础
之上,人类信息社会是全球范围内的各国一体的信息化。因此,信息的政策和法律就必然具
有国际化的属性,具体表现为有关的“国际游戏规则”。我们在制订政策和法律的时候,要特
别注意和现有的国际规则的兼容。包括在立法思想、方式方法上和具体法律规定等各方面的
相互兼容;要积极主动地参与国际规则的创设,以维护我国的实际利益。在主动参与和合作、
促进、创设的过程中,真正地主动融人国际大环境。
7.3 本 章 小 结
本章介绍了电子政务数据库保护的主要技术和手段。首先对电子政务数据库的安全目标

- 162 - 电子政务数据库基础
做了概括性的介绍,之后,从电子政务数据库保护常规技术和高级技术两个层面详细阐述了
现有的各种保护手段。在常规技术中,侧重从数据库自带的一些保护措施,如视图、权限、
完整性约束和并发控制等方面介绍。通过实例,重点阐述了完整性约束和并发控制的实现方
式。在高级技术中,首先介绍了数据备份和恢复的基本技术和最新进展,接着着重分析了目
前数据库研究和应用领域的一个热门技术——容灾管理。在分析了容灾管理的必要性和重要
性后,介绍了容灾管理的一般分级,并对目前我国电子政务领域容灾管理的现状做了简要介
绍。
除了介绍数据库保护的相关技术手段外,本章还探讨了如何从法律政策层面对数据库安
全提供保障。首先分析了世界各国在信息安全立法方面的进展,接着针对我国的现状,提供
了一些可采用的保护对策。
7.4 本 章 习 题
1.如何理解数据库安全?一般的安全策略包括哪些方面的内容?
2.结合 SQL,举例说明如何通过视图来控制数据安全。
3.在数据库系统中,一般将权限分为哪几类?
4.结合 SQL,说明隐式说明的完整性约束如何实现?
5.查阅相关资料,了解并发异常问题有哪些,会带来什么样的影响。
6.查阅相关资料,了解 Microsoft Sql Server 系统中的意向锁和更新锁的基本原理。
7.简述数据备份和容灾管理之间的关系。
8.查阅相关资料,了解数据备份策略的最新进展。
9.查阅相关资料,了解目前世界各国在信息安全方面政策法规的新进展。
7.5 本章参考文献
1.钱毅·政务数据库系统·北京:中国人民大学出版社,2004
2.褚峻等·电子政务安全技术保障·北京:中国人民大学出版社,2004
3.赵杰等·SQL Server 数据库管理、设计与实现教程·北京:清华大学出版社,2004
4.Ramez Elmasri·邵佩英等译·数据库系统基础(第三版)·北京:人民邮电出版社,
2002
5.Gary P. Schneider·成栋等译·电子商务(第四版)·北京:机械工业出版社,2004
6.电子商务研究. http://www.dzsw.org
7.电子政务服务工程网. http://www.echinagov.com
8.国家软件与集成电路公共服务平台. http://www.csip.cn
9.计世网. http://www.ccw.com.cn
10.湖南省信息产业厅. http://www.hnii.gov.cn

第 7 章 电子政务数据库保护 - 163 -
11.中国科技信息. http://www.chinainfo.gov.cn
12.方案中心. http://www.grp.com.cn
13.计算机世界. http://www.ccw.com.cn
14.TPub 网. http://www.itpub.net
15.存储在线. http://www.dostor.com

第 8 章 CGI 和 ODBC 互联技术
电子政务系统是基于 Web 的数据库系统。用户从客户端浏览器界面通过计算机网络与数
据库服务器通讯,存取数据,处理信息。网页一般用 HTML(超文本标记脚本语言)编写,
采用网页浏览工具 IE 等就可以解释运行这些文件。由于 HTML 文件都是由标签(Tag)集合
而成的,虽然可以利用 Java Script 或 VB Script 在浏览器中完成一些简单功能,但是 HTML
无法直接对数据库进行操作。例如将数据库中指定的资料提取出来并显示在浏览器窗口中。
这时就必须使用 CGI(通用网关接口)程序。
本章主要内容:
� CGI 的基本概念
� 数据库访问中间件的基本工作原理
� 数据库与 Web 的 ODBC 连接实现
8.1 CGI 的基本内容
Internet 在操作系统和网络软件的支持下,提供的主要技术有 WWW、电子邮件、FTP
与 Telnet 等等。目前一般采用 Client/Server 或者 Browser/Server 模式去开发用户端应用程序。
用户可以很方便地访问 Internet,使用各种 Internet 提供的服务。Internet 最主要的应用系统是
WWW。WWW 服务器(Web Server)用于存储、管理 Web 页以及提供 WWW 服务。在实际
应用中,与 WWW 服务器配套的一类服务器是代理服务器(Proxy Server)。代理服务器主要
有防火墙和充当 WWW 服务的本地缓冲区的作用;另一类服务器是数据库服务器(Database
Server),它也是 Internet 的重要组成部分。目前,WWW 服务器一般通过通用网关接口(CGI,
Common Gateway Interface)同一个外部程序(又称为 CGI 程序)进行通信,通过开放式数
据库接口(ODBC,Open DataBase Connection)与数据库连接。开放数据库接口(ODBC)
是微软公司制定的一种数据库标准接口,目前已被大多数数据库厂家所接受。无论是大型数
据库(如 Oracle、Informix、SQL Server),还是小型数据库(dBASE、Access、Visual FoxPro),
它们都提供了相应的 ODBC 接口。各种常见的数据库都可以通过信息页的形式显示。信息页
制作人员在 WWW 网页中嵌入 SQL 语句,用户就可以直接通过信息页去访问数据库文件。
为了适应 WWW 与数据库链接的要求,很多公司纷纷推出了数据库 WWW 数据转换工具、
数据库 WWW 开发工具、报表生成工具等。
电子政务活动中的信息通常以多媒体的形式在 Internet 上传播。多媒体是文本、声音、
图像的综合。最常用的多媒体信息发布应用就是 WWW,可以用电子数据交换(EDI,Electronic
Data Interchange)、超文本链接语言(HTML)或 JAVA 将多媒体内容发布在 Web 服务器上,

第 8 章 CGI 和 ODBC 互联技术 - 165 -
然后通过一些传输协议将发布的信息传送到接收端。
一般业务服务是实现网上政务活动的标准化服务,包括信息发布、电子化服务、网上采
购和招标、网上福利支付、目录服务、电子资料库、电子公文化系统、网上税务、网上身份
认证等等。上述技术内容构成了完整的电子政务运行平台。其中数据库承担着对政务信息的
存储、管理、查询、结算和处理等功能。数据库添加了 Web 访问能力后,就可以在 Internet
上发挥作用。例如,在 Web 站点发布新闻信息时,用不着制作上百个网页,只需准备一个模
板页,然后与后台数据库链接,就可以使客户方便地浏览所需的新闻信息。
虽然我们可以用 HTML 文件在客户端浏览器中展现文字、图形、声音、影视等多媒体信
息,不需要再使用其他的资源。但由于其格式统一、弹性不大,是服务器单向发布信息。客
户端无法与服务器双向交互、“自由对话”,例如进行数据库查询操作等。要达到这种功能,
就必须依靠外部程序的帮助,因为外部程序具有处理资料并输出结果的能力。外部程序执行
复杂任务时,通常利用 ODBC(开放数据库连接),将浏览器客户的请求传送到网络服务器上,
然后在网络服务器上运行事先编写好的程序,并将运算结果从网络服务器传送回浏览器。这
种处理方式的基本特点是几乎所有的任务都是在网络服务器上完成的,浏览器只负责发送、
接收和显示数据。使用 CGI 时,服务器可以读取并显示在客户端无法读取的格式(例如访问
关系数据库等)。
通用网关接口(CGI,Common Gate Interface)就是 Web 服务器与一个外部程序(又称
为 CGI 程序)进行通信的接口协议,这个接口协议规定了 Web 服务器与 CGI 程序传送信息
的方式、信息的内容和格式,同时也规定了 CGI 程序返回信息的内容和输出标准。在 Web
页面中,主要通过超链接或者指定表格或图形的方法来执行 CGI 程序。Web 客户终端向企业
Web 服务器发送一个包含 URL 题头字段和其他一些用户数据的 HTTP 请求,Web 服务器则
返回包含所请求的内容的 HTTP 应答。当客户机请求一个驻留在服务器机器上的外部程序或
者一个可运行 Script 的服务时,Web 服务器就把关联的 HTTP 请求信息传送到外部程序,然
后把程序做出的应答发送给请求的客户终端上去,过程如图 8.1 所示。
图 8.1 CGI 工作过程
在网络服务器上,通常有许多外部程序,用来完成不同的任务。在技术上,网络服务器
上的这些程序统称为 CGI 程序。CGI 程序原则上可以用任何计算机语言编写,所有可执行的
二进制文件都可以作为 CGI 程序来运行。但在实际工作中,考虑到运行速度等因素,CGI 程
序往往用 C 语言、C++、Perl、Shell Script、Visual Basic 等来编写。这些语言虽然功能强大,
但过于复杂,不容易学习、掌握。因此,过去,CGI 程序通常只由专业编程人员编写。为了
解决这个问题,软件公司不断开发出可视化和面向对象的 CGI 程序语言。例如微软公司开发
了一种称做 ASP(Active Server Page)的语言。与传统的 CGI 编程语言相比,ASP 语言使用
Web 客
户终端
Web 服务
器 / 数据
库客户机
外部
程序
HTTP 请求 HTTP 请求
HTTP 应答 HTTP 应答
处理操作
数据库
服务器
操作结果

- 166 - 电子政务数据库基础
简便,特别适合非专业编程人员。以下用一个 ASP 文件片段为例,简要介绍 CGI 程序的一
些特点。该 ASP 文件的文件名为 information,作用是从位于网络服务器的数据库
information.mdb 中获取客户指定的记录,并在客户浏览器中显示。
< % @ Language="VBScript" % > <!--声明在本 ASP 文件中混合使用了 ASP 和
VBScript。-->
<html >
< head >
< title > 政务信息</title >
</head >
<body>
< center >
< % id= Request. QueryString("id")
Select Case id
Case 1
Response. Write("会议通知")
Case 2
Response. Write("政策法规")
Case3
Response. Write("新闻动态")
End Select
strSQL= "SELSET [title], [price] FROM catalog WHERE [id] =" & id <!--SQL 语句,分
配一个变量 strSQL,以简化后面语句-->
Set objConn = Server. CreateObject ("ADODB. Connection") <!--在网络服务器上创建
一个数据库连接对象 objCorm,以便访问数据库 information.mdb。-->
objConn. Open "information" <!--请求 objConn 打开数据源名(DSN)为 information 的
数据库。-->
Set objRS = objConn. Execute(strSQL) % > <!--请求 objConn 执行上面的 SQL 语句,
从数据库 information.mdb 的 catalog 表中,将字段内容等于 1(或者 2、或者 3)的所有记录
提取出来,存放在记录集合对象 objRS 中。-->
< table >
< % objRS. MoveFirst <!--首先将第一个记录从数据库中提取出来,准备在浏览器窗
口中显示。-->
Do While Not objRS.EOF <!--检查这个记录的后面是否还有记录,如果有,稍后继续
提取,继续显示。-->
title = objRS. Fields("title") <!--将这个记录中 title 字段的内容分配给同名变量 title。-->
price = objRS.Fields("price")% > <!--将这个记录中 price 字段的内容分配给同名变量
price。-->
< tr>
< td>

第 8 章 CGI 和 ODBC 互联技术 - 167 -
< % =title % > <!--在浏览器窗口中显示变量 title 的内容。-->
</td >
< td>
< % =price % > <!--在浏览器窗口中显示变量 price 的内容。-->
</td>
<td>
< a href = . ./order, htm? title = < % = title % > &price = < % = price % > > 下载</a >
<!--将两个参数 title 和 price 传递给网页 order.htm。-->
</td>
</tr >
< % objRS. MoveNext <!--这个记录的后面如果还有记录,则将下一个记录从数据
库中提取出来,准备在浏览器窗口中显示。-->
Loop <!--与 Do While Not objRS.EOF 语句联合使用,没有独立的含义。-->
objConn. Close <!--关闭 objConn。-->
objRS. Close <!--关闭 objRS。-->
objConn = Nothing <!--释放 objConn 所占用的资源。-->
objRS = Nothing % > <!--释放 objRS 所占用的资源。-->
</table >
< a href = .. \index. htm> 返回网站主页 </a>
</center >
</body>
</html >
在客户端启动浏览器,并在地址栏中输入“政务信息”的虚拟网址,这时浏览器窗口中
将出现“政务信息”的主页(程序略)。用鼠标选择书目类别中的“会议通知”,则参数 id=
1 将会传递给 information.asp。information.asp 从数据库 information.mdb 的 catalog 表中,将 id
字段内容等于 1 的所有记录提取出来,显示在浏览器的窗口中。
ASP 将专门的语句放置在 HTML 文件中,分别以 <%与%> 为开始和结束标记。HTML
文件的后缀是 .htm,而 ASP 文件(实际上是包含 ASP 语句的 HTML 文件)的后缀是 .asp。
由于 ASP 文件本质上是一个可以运行的 CGI 程序,所以 ASP 文件只能放置在网络服务器上
运行,并且该网络服务器必须能够支持 ASP 语言。像 ASP 这类在服务器或客户端运行的解
释性文本称为脚本描述语言。脚本描述语言比程序设计语言简单,并带有适合于 Internet 网
络开发的特殊函数或组件。常见的脚本描述语言有 JavaScript VBScript 和 PHP 等。这些脚本
描述语言通常利用 ODBC 对数据库进行访问。

- 168 - 电子政务数据库基础
8.2 ODBC 的基本原理
国内外数据库软件开发者开发出越来越多的不同类型和不同用途的数据库管理系统,有
在不同操作平台上运行的,有桌面、多用户和分布式的等等。不同的用户根据自己的需要分
别选用不同的数据库管理系统,这对在电子政务运作过程中实现在不同 DBMS 上的移植性以
及异构数据库间数据访问、数据交换和信息共享增加了难度。异构型数据库之间的数据共享
多年来一直是人们研究的课题,SQL(Structured Query Language)标准的制定为应用程序的
移植带来一线希望,但各个 DBMS(DataBase Management Systems)定义出来的 SQL 却在不
同的 DBMS 之上的应用软件之间形成通信障碍。
为了对多种数据库系统进行统一的集成管理,需要采用标准的数据库应用界面。在这种
情况下,Microsoft 公司于 1991 年底推出的 ODBC 解决了这些问题。ODBC(Open DataBase
Connectivity,开放数据库互联)应用数据通信方法、数据传输协议、DBMS 等多种技术定义
了一个标准的接口协议,允许应用程序以 SQL 为数据存取标准,来存取不同 DBMS 管理的
数据。ODBC 实际上是一个数据库访问函数库,使应用程序可以直接操纵数据库中的数据。
它解决了嵌入式 SQL 接口非规范核心,免除了应用软件随数据库的改变而改变的麻烦。开放
数据库互联(ODBC)为数据库应用程序访问异构型数据库提供了统一的数据存取接口 API
(Application Interface),应用程序不必重新编译、连接,就可以与不同的 DBMS 相联。一个
基于 ODBC 的应用程序对数据库的操作不依赖于任何 DBMS,不直接与 DBMS 打交道。所
有的数据库操作由对应的 DBMS 的 ODBC 驱动程序完成。目前支持 ODBC 的有 Oracle、
Access、X-Base 等 10 多种流行的 DBMS。ODBC 作为开放式数据库程序设计界面标准,对
数据库应用软件的开发提供有力的支持。用户可针对各种数据库核心和服务器编写可移植的
应用程序,并使应用人员在编程时不必关心底层的 DBMS,相同的代码可以同时作用于不同
的 DBMS。用户可以用同样的 SQL 语句或命令对不同的 DBMS 的数据库进行操作。同时,
这也大大简化了不同 DBMS 之间的数据交换。ODBC 具有最大的互操作性,可以使用一个单
独的程序来提取数据库信息,再提供一种方法让应用程序读取数据。一个应用程序可以存取
不同的数据库管理系统,而应用程序不必和 DBMS 绑在一起进行编译、连接、运行,而只要
在应用程序中通过选择一个叫做数据库驱动程序的模块就可以把应用程序与所选的 DBMS
连接在一起了。
ODBC 包括如下四个组件:
(1)应用程序(Application)负责调用 ODBC 函数来提交 SQL 语句,提取结果。
(2)驱动程序管理器(Driver Manager)为应用程序加载驱动程序。
(3)驱动程序(Driver)处理 ODBC 函数调用,向数据源提交 SQL 请求,向应用程序返
回结果,必要时驱动程序将 SQL 语法翻译成符合 DBMS 语法规定的格式。
(4)数据源(Data Source)由用户想要存取的数据、操作系统、DBMS、网络平台等组
成。
窗口环境下的 ODBC 使用动态链接库 DLL(Dynamic Link Library)结构,以及—个可
装载的数据库驱动器和一个驱动器管理器。
此外,还需要其他一些文件,如帮助文件、INI 文件、ODBC 程序员应用程序等等。ODBC
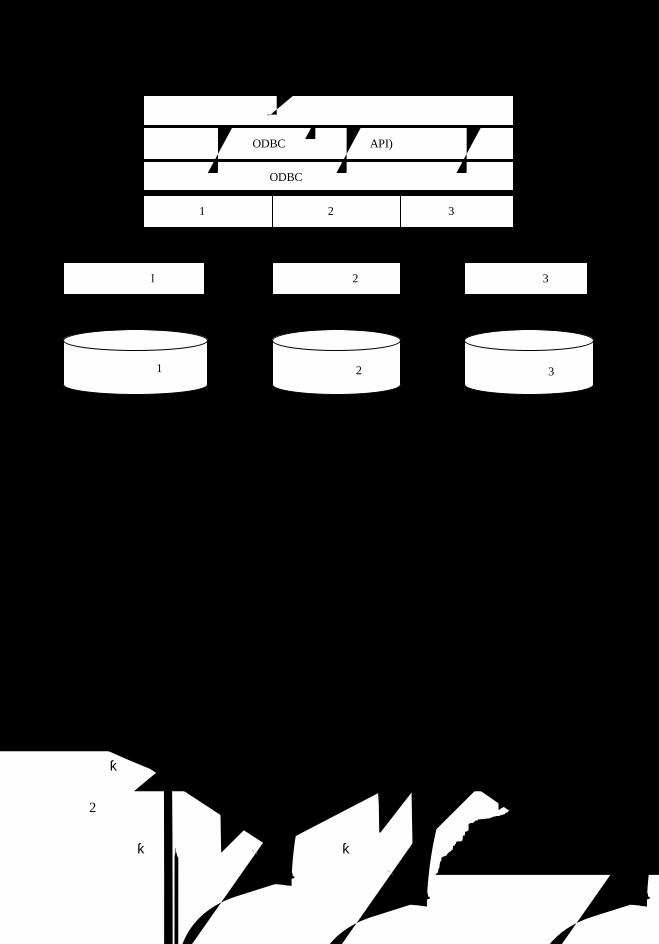
第 8 章 CGI 和 ODBC 互联技术 - 169 -
的层次结构如图 8.2 所示。
图 8.2 ODBC 的层次结构
ODBC 的结构是层次化的,它描述了嵌入 ODBC 的应用程序和 ODBC 组成部件之间的
关系。应用程序与 ODBC 驱动器管理器进行信息交互。ODBC 驱动器管理器是一个共享的程
序库管理器,称为 ODBC.DLL。对于任何 DBMS,只要提供了该数据库管理系统的驱动程序
DLL,并符合 ODBC.DLL 的接口规范,则该数据库的文件便可被 ODBC 所访问和处理。
ODBC.INI 文件中存放着各个数据源及其信息。ODBC 的实现采用动态链接库(DLL)技术,
在系统运行时被动态地装入和链接。ODBC.DLL 通过 ODBC.INI 文件可以知道对某个数据库
文件,应调用哪一个 DLL 程序。ODBC.DLL 把应用程序的调用分配给一个或多个数据库驱
动器。ODBC.DLL 可以装载或卸载驱动器、检查状态、管理多个应用和数据源之间的链接。
ODBC 是独立于网络层的数据库访问界面,可以在单机或互联计算机上使用具有各种网络协
议的 ODBC。无论哪种情况,ODBC.DLL 都能够处理应用程序的调用,并把它们传送到适合
的可装载的驱动器。数据库管理系统的驱动程序 DLL 通常由数据库管理系统的开发商提供。
ODBC 有如下两个基本用途:
(1)在电子政务实际过程中,涉及到各级政府机构、企业、公民、银行、社区和国内外
团组织等部门和单位。它们的应用平台不一致,需要同时访问多种异构数据库。如果按照传
统的程序开发方式,设计人员必须熟悉多种数据库的编程语言,以便为多种数据库分别编写
程序版本,这大大增加了程序开发的难度和设计人员的负担。使用 ODBC 技术,设计人员只
需要编写一个程序版本,就可以访问任何数据库,从而使程序具有更好的兼容性和适应性。
(2)有些应用程序需要访问某种数据库,这就要求程序所在的计算机上安装相应的的数
据库软件。但有些数据库软件极其庞大,并且对计算机的硬件、软件配置有非常严格的要求,
即使能够安装,也会占用大量的系统资源。另外,历史上大量使用过单用户版的数据库,如
ODBC 应用程序接口(API))
ODBC 驱动程序管理器
数据源 l 数据源 3
数据库 1 驱动程序 数据库 2 驱动程序 数据库 3 驱动程序
数据源 2
数据库 1 数据库 2 数据库 3
客户端数据库应用程序

- 170 - 电子政务数据库基础
Visual FoxPro 等等,需要与 Web 链接利用网络共享数据。为此,ODBC 提供了一批常用数
据库软件的驱动程序。这样,计算机上即使没有安装相应的数据库管理系统,但只要安装了
相应的驱动程序,CGI 程序就可以访问。应用程序不必关心 ODBC 与 DBMS 之间的底层通
信协议。
8.3 数据源与 Web 的 ODBC 连接
数据源是数据库位置、数据库类型和 ODBC 驱动程序等信息的集成。数据源负责应用程
序与数据库的连接、通信,并将结果返回应用程序。应用程序通过数据源找到要操作的数据
库。在开发 ODBC 数据库应用程序时首先应用建立数据源。ODBC 数据源有 3 种类型:
(1)用户数据源:只有创建该数据源的用户才能在指定计算机上使用的数据源。这种是
专用数据源;
(2)系统数据源:当前系统的所有用户和所运行的应用程序都能使用的数据源。这种是
公用数据源;
(3)文件数据源:由于专项应用所建立的数据源。这种数据源相对独立。ODBC 的目的
是为 Windows 应用程序提供存取数据库的透明性。就像打印驱动一样,只要加入对应的驱动
程序就行了。因此有必要理解如何配置 ODBC 界面(profile),以及使用方法。ODBC 的配置
可分为静态配置和动态配置。静态配置通常是在开发阶段通过 Windows 提供的 ODBC Data
Sources(32 位)进行。动态配置是在应用系统初始安装时,由应用系统自动完成其配置。两
者原理是一样的。关于后者,读者可以参考专门资料。
下面以在 Windows 2000 Server 环境中,PHP(Personal Home Page)服务器端内嵌 HTML
脚本编程语言调用 SQL Server 数据库为例,说明 ODBC 静态配置和链接的过程:
(1)创建数据源名 DSN(Data Source Name)。在使用 ODBC 建立与后台数据库的链接
时,必须通过数据源名指定使用的数据库。这样当使用的数据库改变时,不用改变程序,只
要在系统中重新配置 DSN 就可以了。DSN 是应用程序和数据库之间连接的桥梁。在设置 DSN
时需设置包括 DSN 名、ODBC 驱动程序类型以及数据库等信息。进入“控制面板”运行“ODBC
数据源”,如图 8.3 所示。
(2)数据源文件有三种类型,其中“用户 DSN”和“系统 DSN”是我们常用的两种数
据源。“用户 DSN”和“系统 DSN”的区别是前者用于本地数据库的连接,后者是多用户和
远程数据库的连接方式。以“用户 DSN”为例加以说明,首先选择数据库的类型 SQL Server,
按下“完成”按钮,如图 8.4 所示。
(3)创建 ODBC 名称,如“my_odbc”;选择数据库服务器,默认为(local)。按下“下
一步”按钮,如图 8.5 所示。
(4)登录方式有两种,我们选择第二种方式“使用用户输入登录 ID 和密码的 SQL Server
验证”方式。按下“下一步”按钮,如图 8.6 所示。
(5)输入数据库的用户名称和密码。用户名密码一定要正确。按下“下一步”按钮,如
图 8.7 所示。
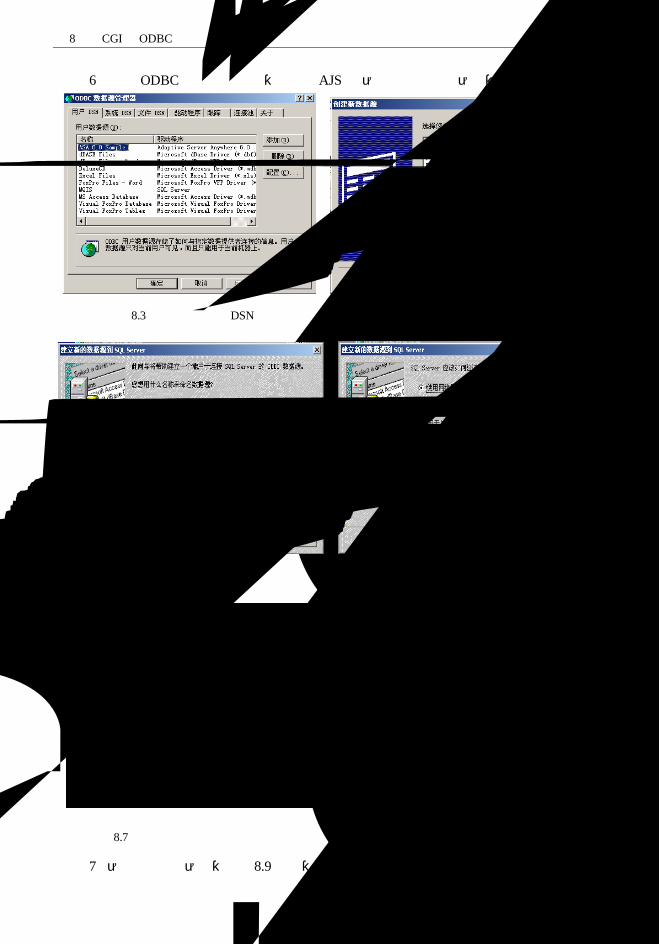
第 8 章 CGI 和 ODBC 互联技术 - 171 -
(6)选择 ODBC 控制的数据库,例如“AJS”。按下“下一步”按钮,如图 8.8 所示。
图 8.3 创建数据源名 DSN 图 8.4 安装数据源的驱动程序
图 8.5 创建 ODBC 名称 图 8.6 选择登录方式
图 8.7 输入数据库的用户名称和密码 图 8.8 选择 ODBC 控制的数据库
(7)按下“完成”按钮,如图 8.9 所示,屏幕显示新的 ODBC 数据源配置信息,如图 8.10

- 172 - 电子政务数据库基础
所示。
图 8.9 ODBC 参数设置 图 8.10 ODBC 数据源配置信息
(8)按下“测试数据源”按钮,测试数据源,返回“测试成功的信息”,如图 8.11 所示。
(9)按下“确定”按钮,看到“用户 DSN”中的新数据源:my_odbc,如图 8.12 所示。
图 8.11 数据源测试信息 图 8.12 数据源列表
到此为止,新的“用户 DSN”配置成功。同样“系统 DSN”的配置方法与“用户 DSN”
的配置方法相同。
ODBC 数据源配置完成后,就可以与 Web 页的连接了。连接用来保持正在访问数据的一
些状态信息,以及连接者的信息。在脚本中要访问数据库必须先创建与数据库的连接,然后
打开连接,该数据库才真正可用。例如,在 PHP 文件 abc.php 中写入以下程序代码:
<?php
$conn=odbc_connect("my_odbc","dba","sql"); <!--第一个参数是 DSN 数据源名称,
第二个参数是访问数据库的用户名,第三个参数是访问数据库的用户口令。用户名和用户口
令为可选项。-->
$query="select name, tel from phponebook" <!--查询字段-->
$result_id=odbc_do($conn,$query); <!--运行 odbc-->
⋯ <!--数据处理代码段,通过引入 SQL 语句

第 8 章 CGI 和 ODBC 互联技术 - 173 -
的方法执行对数据库数据的插入、修改和删除等操作。-->
odbc_close($conn); <!--关闭 odbc。关闭数据对象和连接,在
使用完 ADO 对象后要通过调用方法 close 关闭对象,以释放所占用的服务器资源。-->
?>
注意:当数据源为系统数据源时只需要给出数据源名,而数据源为文件数据源时必须给
出数据源的完整路径。
在数据处理代码段中,可以根据需要实现查询、计算、显示和其他数据处理等功能。这
样,ODBC 数据源通过 PHP 实现了与 Web 的连接。实际上,PHP 文件就是 CGI 可执行程序。
8.4 本 章 小 结
本章介绍在电子政务运作过程中,将 Web 站点与关系数据库管理系统相关联的方法和解
决异构型数据库之间的数据共享的问题。
8.5 本 章 习 题
1.解释 CGI 的含义和特点。
2.试举例说明 ODBC 的两个基本用途。
3.简述 ODBC 的工作原理和工作流程。
4.实践本章 ODBC 配置,在 abc.php 程序中补充全数据处理代码段以实现对指定数据库
的查询功能。
5.设计利用 ODBC 技术从一个 Microsoft Access 数据库中取出数据,存入一个 Visual
FoxPro 数据库中的过程。
8.6 本章参考文献
1.文必龙等·开放数据库互联(ODBC)技术与应用·北京:科学出版社,1997
2.潘郁等·电子商务数据库技术(第二版)·北京:北京大学出版社,2004.5
3.黄志球等·数据库应用技术基础·北京:机械工业出版社,2003.10
4.洪志全等·数据库原理及应用·北京:电子工业出版社,2004.8
5.张健沛·数据库原理及应用系统开发·北京:中国水利水电出版社,1999.4
6.(美)Gunnit S.Khurana 等,陈银山等译·Web 数据库的建立与管理·北京:机械工业
出版社,1997.6
7.(美)Jesse Feiler 著,张玮等译·数据库驱动的 Web 站点设计·北京:机械工业出版

- 174 - 电子政务数据库基础
社,2001.4

第 9 章 电子政务数据仓库与数据挖掘
随着政府政务建设内部发展的需要和外部竞争压力的不断增加,政府机关建成的各种应
用系统也在不断地增加,同时相应的各种业务数据与日俱增,但是这样的数据不处理是没有
应用价值的,政府需要的是能够辅助于政务决策的相关信息。这就遇到了当今所有行业面临
的所谓的“海量的数据,贫乏的知识”问题。此外,从公众角度来看,使用这些数据的手段
应是多方面和多层次的,应包含帮助使用者从多种角度分析数据、进行对比,自动地生成相
关报告的工具,而且能够提供非常方便的人性化界面。针对这种数据庞大和知识无法有效获
取的矛盾,惟一的解决办法就是构建电子政务资源库系统。数据仓库(DW)与数据挖掘(DM)
是 20 世纪 90 年代中期兴起的新技术,数据仓库用于决策分析,数据挖掘用于从数据库中发
现知识。数据仓库和数据挖掘的结合是实现政府决策支持的核心技术。
本章主要内容:
� 数据仓库
� 数据挖掘
� 基于数据仓库与数据挖掘的电子政务资源库建设
9.1 数 据 仓 库
传统的数据库技术是以单一的数据资源,即数据库为中心,进行事务处理、批处理、决
策分析等各种数据处理工作,主要可划分为两大类:操作型处理和分析型处理(或信息型处
理)。操作型处理也叫事务处理,是指对数据库联机的日常操作,通常是对一个或一组记录的
查询和修改;分析型处理则用于管理人员的决策分析,经常要访问大量的历史数据。随着市
场竞争的加剧和信息社会需求的发展,从大量数据中提取制定市场策略的信息显得越来越重
要了,这种需求既要求联机服务,又涉及大量用于决策的数据。传统型数据库已经无法满足
数据处理多样化的要求,操作型处理和分析型处理的分离成为必然。随着数据库技术的应用
和发展,人们尝试对数据库中的数据进行再加工,形成了综合的,面向分析型数据处理的数
据仓库技术(Data Warehousing,DW),以更好地支持决策分析。
9.1.1 数据仓库的概念及特性
1.数据仓库的概念
业界公认的数据仓库概念是创始人 W.H.Inmon 在《Building the Data Warehouse》一书中
对数据仓库的定义:数据仓库就是面向主题的(Subject Oriented)、集成的(Integrate)、稳定
的(Non-Volatile)、随时间不断变化(Time Variant)的数据集合,用以支持企业或组织的管

第 9 章 电子政务数据仓库与数据挖掘 - 175 -
理决策。对于数据仓库的概念可以从两个层次予以理解,首先,数据仓库用于支持决策,面
向分析型数据处理,它不同于企业现有的操作型数据库;其次,数据仓库是对多个异构的数
据源有效集成,集成后按照主题进行了重组,并包含历史数据,而且存放在数据仓库中的数
据一般不再修改。
2.数据仓库的特点
根据数据仓库概念的含义,数据仓库拥有以下四个特点:
(1)面向主题的。数据仓库中的数据面向主题,与传统数据库面向应用相对应。操作型
数据库的数据组织面向事务处理任务,各个业务系统之间各自分离,而数据仓库中的数据是
按照一定的主题域进行组织。主题是一个抽象的概念,是一个在较高层次上将数据归类的标
准,指用户使用数据仓库进行决策时所关心的重点方面,每一个主题对应一个宏观的分析领
域,一个主题通常与多个操作型信息系统相关,不同类型的公司主题集合是不同的。例如对
一个保险公司来说,公司的主要主题域可能是顾客、保险单、保险费与索赔;而对一个生产
商来说,主要主题域可能是产品、定单、销售商、材料单与原货物(raw goods );对一个零
售商来说,主要主题域可能是产品、库存单位、销售、销售商等。
(2)集成的。在数据仓库的所有特性之中,这是最重要的。面向事务处理的操作型数据
库通常与某些特定的应用相关,数据库之间相互独立,并且往往是异构的。而数据仓库中的
数据是从多个不同的数据源传送来的,当这些数据进入数据仓库时,需进行转换,重新格式
化,重新排列以及汇总等操作。以保证数据仓库内的信息是一致的全局信息。如图 9.1 所示,
说明了当数据由面向应用的操作型环境向数据仓库传送时所进行的集成。
图 9.1 集成问题
(3)稳定的。数据仓库的稳定性是指数据仓库反映的是历史数据,而不是日常事务处理
产生的数据。操作型数据库中的数据通常实时更新,数据根据需要及时发生变化,而数据经
加工和集成进入数据仓库后是极少或根本不修改的。数据仓库的数据主要用于决策分析,所
涉及的数据操作主要是数据查询,一旦某个数据进入数据仓库以后,一般情况下将被长期保
留,也就是说,数据仓库中一般有大量的查询操作,但修改和删除操作很少,通常只需要定
期的加载、刷新。数据的相对稳定性说明如图 9.2 所示。从 9.2 可以看出,对操作型数据的访
问和处理,一般按一次一条记录的方式进行。操作型环境中的数据一般必然是要更新的,但
数据仓库中的数据呈现出一组非常不同的特性。数据仓库的数据通常是以批量方式载入与访
问的,但在数据仓库环境中并不进行一般意义上的数据更新。数据仓库中的数据在进行装载
时是以静态快照的格式进行的。当产生后继变化时,一个新的快照记录就会被写入数据仓库。
这样在数据仓库中就保存了数据的历史状况。
应用 A 描述
应用 B 描述
应用 C 描述
应用 D 描述
?
多个数据源
描述

- 176 - 电子政务数据库基础
图 9.2 稳定的问题
(4)随时间变化的。数据仓库的最后一个显著特性是它是随时间变化的,即数据仓库中
的每个数据单元都只是在某一时间是准确的。操作型数据库主要关心当前某一个时间段内的
数据,而数据仓库中的数据通常包含历史信息,数据仓库内的信息不只是关于企业当时或某
一时点的信息,而是系统记录了企业从过去某一时点(如开始应用数据仓库的时点)到目前的
各个阶段的信息。在一些情况下,记录中加有时戳,而在另外一些情况下记录则包含一个事
务的时间。总之,任何情况下记录都包含某种形式的时间标志,用以说明数据在哪一时间是
准确的。通过这些信息,可以对企业的发展历程和未来趋势做出定量分析和预测。不同的环
境中有不同的时间范围,时间范围是环境中表示时间的参数。数据仓库中的数据时间范围要
远远长于操作型系统中的时间范围,操作型系统的时间范围一般是 60~90 天,而数据仓库中
数据的时间范围通常是 5~10 年。由于这种在时间范围上的差异,数据仓库含有比任何其他
环境中都多的历史数据。数据仓库中数据随时间变化特性的几种表示方法如图 9.3 所示。 �
图 9.3 随时间的变化问题
删除
插入
修改
数据的逐个
记录方式处理
访问
插入
修改
删除
操作型环境
相对性稳定性
数据的批量
载入/访问
访问载入
数据仓库
*时间范围��当前到 60~90 天
*记录更新
*关键字结构可能包括/也可能
不包括时间元素
操作型环境 时间的变化 数据仓库
*时间范围��5~10 年
*数据的复杂快照
*关键字结构包括包括时间元素

第 9 章 电子政务数据仓库与数据挖掘 - 177 -
企业或组织数据仓库的建设,是以现有企业或组织业务系统和大量业务数据的积累为基
础。数据仓库不是静态的概念,只有把信息及时交给需要这些信息的使用者,供他们做出改
善其业务经营的决策,信息才能发挥作用,信息才有意义。而把信息加以整理归纳和重组,
并及时提供给相应的管理决策人员,是数据仓库的根本任务。因此,从产业界的角度看,数
据仓库建设是一个工程,是一个过程。
9.1.2 数据仓库中的数据组织
数据仓库中的数据分为四个级别:早期细节级、当前细节级、轻度综合级(数据集市级)、
高度综合级。一个典型的数据仓库的数据组织结构如图 9.4 所示。
图 9.4 数据仓库的数据组织结构
数据是由操作型环境导入数据仓库的,相当数量的数据转换通常发生在数据由操作层向
数据仓库层传输的过程中,源数据经过综合后,首先进入当前细节级,并根据具体需要进行
进一步的综合,由当前细节级进入轻度综合数据级,然后由轻度综合数据级进入高度综合数
据级。一旦数据过期,就由当前细节级进入早期细节级。由此可见,数据仓库中存在着不同
的综合级别,一般称之为“粒度”。粒度越大,表示细节程度越低,综合程度越高。
1.粒度
粒度是数据仓库的重要概念。粒度是指数据仓库中数据单元的细节程度或综合程度的级
别。粒度问题对数据仓库环境所处的整个体系结构都有影响。细节程度越高,粒度级就越低;
相反,细节程度越低,粒度级就越高。
粒度可以分为两种形式:
(1)粒度是对数据仓库中的数据的综合程度高低的一个度量,它既影响数据仓库中的数
据量的多少,也影响数据仓库所能回答询问的种类,需要在数据仓库中的数据量大小与所能
� �
�
高度综合级
轻度综合级
(数据集市)
当前细节级
操作型转换
早期细节级

- 178 - 电子政务数据库基础
回答查询的细节级别之间做出权衡。大多数情况下,数据在进入数据仓库时的粒度级别太高,
就意味着必须花费大量资源对这些数据进行拆分。然而也有一些时候,数据进入数据仓库时
的粒度级别太低,在网络电子商务环境中产生的网络日志就是一个粒度级别太低的例子。要
使得网络日志中的点击流数据适合于数据仓库环境,必须先对这些数据进行编辑,过滤和汇
总。显然,在数据仓库中,多维粒度是必不可少的。由于数据仓库的主要作用是决策支持系
统(DSS)分析,因而绝大多数查询都基于一定程度的综合数据之上的,只有极少数查询涉及到
细节。所以应该将大粒度数据存储于快速设备,如磁盘上,小粒度数据存于低速设备如磁带
上。
(2)还有一种粒度形式,即样本数据库。它根据给定的采样率从细节数据库中抽取出一
个子集。这样样本数据库中的粒度就不是根据综合程度的不同来划分的,而是由采样率的高
低来划分,采样粒度不同的样本数据库可以具有相同的数据综合程度。
2.分割
分割是数据仓库中的另一个重要概念,数据分割是指将数据分散到各自的物理单元中去,
以便能分别独立处理。它的目的同样在于提高效率,因为运行维护人员和设计者在管理小的
物理单元时将比管理大的物理单元时享有更大的灵活性。当数据存放在大的物理单元中时,
一些任务,如索引、顺序扫描、重组、恢复、监控等将无法轻松地进行。有许多数据分割的
标准可供参考,如:日期、地域、业务领域等,也可以是其组合。一般而言,分割标准总应
包括日期项,它十分自然而且分割均匀。恰当地进行分割可以给数据仓库在多方面带来好处,
如:数据装载、数据访问、数据存档、数据删除、数据监控、及数据存储等,使得数据可以
增长并且可以进行管理。反之,如果数据分割不适当,则会为数据增长和管理造成许多困难。
通常,分割是在应用层而非系统层上进行的。
3.数据仓库的组织形式
数据仓库中有多种数据组织形式,常见的有:简单堆积文件、轮转综合文件、简化直接
文件、连续文件等:
(1)简单堆积文件。简单堆积文件指将每日由数据库中提取并加工的数据逐天积累并存
储起来。如图 9.5 所示的简单堆积文件,给出了从操作型环境中得到的日常事务记录,然后
综合成数据仓库记录。这个综合可根据顾客、账目或者根据任何组织到数据仓库的主题域来
进行。图 9.5 中的事务处理是以天来进行综合的。换句话说,对一个顾客的一个账号每天的
所有活动进行合计,并在一天一天的基础上进入数据仓库。
(2)轮转综合数据文件。轮转综合数据存储是简单逐日堆积数据的一个变种,轮转综合
数结构如图 9.6 所示。数据存储单位被分为日、周、月、年等几个级别。在一个星期的 7 天
中,数据被逐一记录在每日数据集中;然后,7 天的数据被综合并记录在周数据集中;接下
去的一个星期,日数据集被重新使用,以记录新数据。同理,周数据集达到 5 个后,数据再
一次被综合并记入月数据集。以此类推。轮转综合结构十分简捷,数据量较简单堆积结构大
大减少。当然,它是以损失数据细节为代价的,越久远的数据,细节损失越多。
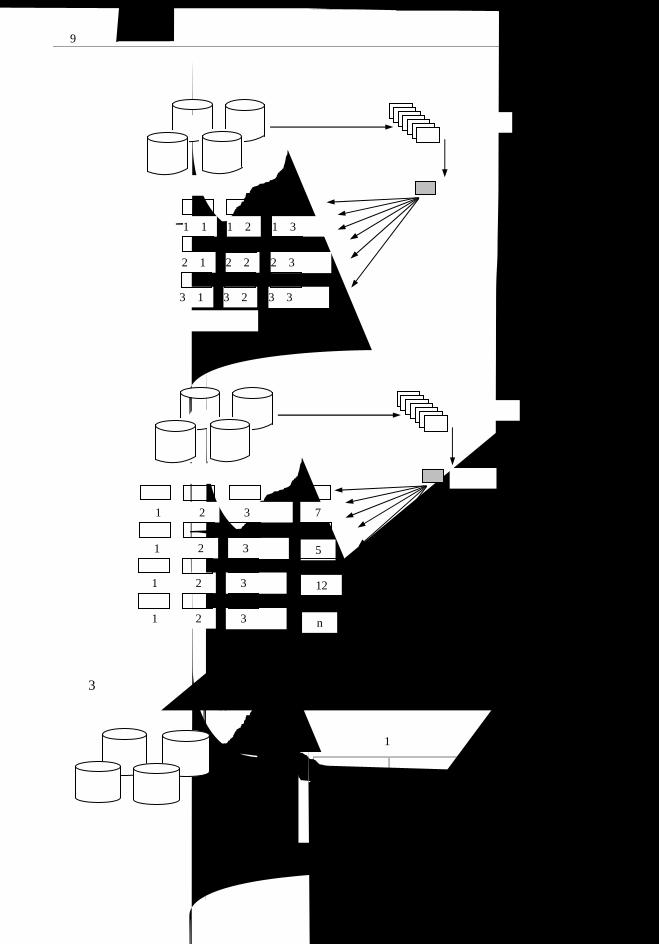
第 9 章 电子政务数据仓库与数据挖掘 - 179 -
图 9.5 简单堆积文件结构
图 9.6 转轮综合文件结构
(3)简化直接文件。它类似于简单堆积文件,但它是间隔一定时间的数据库快照,比如
每隔一星期或一个月做一次,如图 9.7 所示。
图 9.7 简化直接文件结构
姓名 公众号 地址 王平 N760100 南京 李明 N660222 四川 陈达 N728963 河北
⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯⋯
1 月份公众信息表
操作型数据
每日事务处理
每日综合 操作型数据
简单堆积数据
2月1日 2月2日 2月3日⋯⋯
1月1日 1月2日 1月3日⋯⋯
3月1日 3月2日 3月3日⋯⋯
⋯⋯⋯⋯⋯⋯
每日事务处理
每日综合操作型数据
第 1 周
第 2 周 第 3 周⋯⋯
第 1 天 第 2 天
第 3 天⋯⋯
第 1 月 第 2 月 第 3 月⋯⋯
第 7 天
第 5 周
第 12 月
第 n 年第 1 年 第 2 年 第 3 年⋯⋯

- 180 - 电子政务数据库基础
由图 9.7 可以看出,数据仅仅是从操作型环境被拖入数据仓库环境中,并没有任何累积。
另外,简化直接文件不是在每天的基础上组织的,而是以较长时间为单位的,比如一个星期
或一个月。因此,简化直接文件是操作型数据的间隔一定时间的一个快照。
(4)连续文件。通过两个连续的简化直接文件,可以生成另一种连续文件,它是通过比
较两个简化直接文件的不同而生成的,如图 9.8 所示。当然,连续文件同新的简化直接文件
也可生成新的连续文件。
��
图 9.8 连续文件
对于各种文件结构的最终实现,在关系数据库中仍然要依靠“表”这种最基本的结构。
在关键字层中,数据仓库的关键字总是复合关键字。这是由于日期几乎总是关键字的一部分,
此外数据仓库分割的不同部分也是关键字的一部分。
9.1.3 数据仓库的体系环境
1.元数据
建立数据仓库一个重要的工作是元数据管理。按照传统的定义,元数据(Metadata)是
关于数据的数据。自从有了程序和数据,元数据就是信息处理环境的一部分。但是在数据仓
库系统中,元数据扮演一个新的重要角色。元数据是描述数据仓库内数据的结构和建立方法
的数据,用于建立、管理、维护和使用数据仓库。元数据可以帮助用户及数据仓库的 DSS 分
析人员非常方便地找到他们所关心的数据。也正因为有了元数据,使得数据仓库被最有效地
利用。如果一个数据仓库中没有元数据,那么用户就不知道如何着手进行分析,用户必须首
先对数据仓库进行各种试探才能确认其中有哪些数据和没有哪些数据,这样就浪费了大量时
1 月份公众表
姓名 公众号 地址
王平 李明 李强 陈达
N760100 N660222 N440111 N728963
南京 四川 湖南 武汉
2 月份公众表
姓名 公众号 地址 王平 李明 李强 陈达
N760100 N660222 N440111 N728963
南京 西安 上海 武汉
1-2 月份公众表
姓名 公众号 时间 地址 李明 李明 李强 李强 陈达
N760100 N660222 N660222 N440111 N440111 N728963
1-2 月 1-1 月 2-2 月 1-1 月 2-2 月 1-2 月
南京 四川 西安 湖南 上海 武汉
第 9 章 电子政务数据仓库与数据挖掘 - 181 -
间。并且即使用户对数据仓库进行了一些试探,仍然不能保证他能找到正确的数据,也不能
保证他能对所见到的数据正确地做出解释。如果有元数据,最终用户就可以很快找到所需数
据或确认这些数据没在数据仓库中。元数据贯穿于建立数据仓库的整个过程,元数据与指向
数据仓库内容的索引相似,处于数据仓库的上层,并且记录数据仓库中对象的位置。元数据
存储对以下各项进行了记录:程序员所知的数据结构、DSS 分析员所知的数据结构、数据仓
库的源数据、数据进入数据仓库时进行的转换、数据模型、数据模型和数据仓库的关系、及
抽取数据的历史记录等。通常把元数据分为技术元数据(Technical Metadata)和业务元数据
(Business Metadata)。技术元数据是描述关于数据仓库技术细节的数据,这些元数据应用于
开发、管理和维护数据仓库;业务元数据从商业和业务的角度描述数据仓库的数据,提供了
良好的语义层定义,业务元数据使业务人员能够更好地理解数据仓库分析出来的数据。
2.数据仓库的体系结构化环境
数据仓库的主题需要不断完善,不断调整,综合数据的内容和形式也要灵活多变,另外
随着数据不断载入,数据仓库将越来越庞大,分析工作若完全基于单一层次的数据仓库,性
能将十分低下。因而需要建立起分层的数据仓库,如图 9.9 所示。
图 9.9 数据仓库的体系化结构环境
图 9.9 是对数据仓库的体系结构化环境的一个简单描述,它分为四个层次:操作型环境、
全局级数据仓库、部门级局部仓库(或数据集市层)和个人级数据仓库。在这个体系化环境中,
操作型环境存放的是一些细节的操作型数据,服务于高性能事务处理领域。全局数据仓库中
除了存放不可更新的集成的原始数据外,还包含大量导出数据;部门级局部仓库是根据最终
用户的需求而为满足部门的特殊需要而建立的,一般仅包含导出数据;而个人级数据仓库的
数据都是暂时的,用于启发式分析。数据从操作型环境经过综合整理进入全局数据仓库,企
业或组织中的有关部门再从全局数据仓库中组织适合自己特殊分析需求的数据,建立自己的
局部仓库;而个人不仅可以从全局数据仓库中提取数据,而且可以从部门级局部仓库中提取
所需数据。这样,不同层次的数据构成了一个更高层次的体系化实体集合,由于数据在全局
数据仓库中都已经是集成的、一致的,所以部门和个人的抽取工作效率将会很高。
操作型环境 数据仓库 局部仓库 个人仓库
操作型环境 全局级 部门级 个人级
注:“ ”表示数据的抽取方向

- 182 - 电子政务数据库基础
3.数据仓库的体系结构
数据仓库是从多个信息源中获取原始数据,经整理加工后,存储在数据仓库中,通过数
据仓库访问工具,向数据仓库的用户提供统一、协调和集成的信息环境,支持组织或企业全
局的决策过程及对组织或企业经营管理的深入综合分析。数据仓库的典型结构由操作环境层、
数据仓库层和业务层等组成,如图 9.10 所示。
图 9.10 数据仓库的典型体系结构
操作环境层是指整个企业内有关业务的 OLTP 系统和一些外部数据源;数据仓库层是指
通过把操作环境层的相关数据抽取到一个中心区而组成的数据仓库层;业务层是为了完成对
业务数据的分析而由各种工具组成的层。数据仓库体系一般来说包含以下 7 个主要组成部分:
(1)数据源。数据源指为数据仓库提供的各种源数据(source data),如各种生产系统数据
库,联机事务处理系统(OLTP)的操作型(operational)数据,及外部数据源等都可以作为数据仓
库的数据源。
(2)数据抽取、转换、装载及刷新工具。数据抽取(extraction)、转换(transformation)、
装载(load)及刷新(refresh)工具的功能是从数据源中抽取数据,对数据进行检验和整理,
并根据数据仓库的设计要求,对数据进行重新组织和加工,装载到数据仓库的目标数据库中,
并且可以周期性地刷新数据仓库。
(3)数据建模工具。数据建模工具(modeling tools)用于为数据仓库的源数据库(source
database)和目标数据库建立信息模型,以描述数据检验、整理、加工的需求和相应过程及步骤。
(4)元数据仓储。元数据仓储(metadata repository)用于存储数据模型和元数据。其中,
元数据描述了数据仓库中源数据和目标数据本身的信息,定义了从源数据到目标数据的转换
过程。
(5)数据仓库监控和管理工具。数据仓库监控(monitoring)和管理(administration)工
具指对数据仓库的运行提供监控和管理手段,包括系统资源的使用情况、用户操作的合法性、
即席查询 OLAP 分析 数据挖掘
企业数据模型、多维数据模型
数据仓库
外部数据源 RDBMS
业务层
数据仓库层
操作环境层
元数据
知识库
业务元数据
技术元数据

第 9 章 电子政务数据仓库与数据挖掘 - 183 -
安全管理、存储管理等多方面的内容。
(6)数据仓库及数据集市的目标数据库。数据仓库及数据集市(data marts)的目标数据
库(target database)存储经检验、整理、加工和重新组织后的数据。它可以是关系数据库或
多维数据库。
(7)前端数据访问和分析工具。前端数据访问和分析工具供业务分析和决策人员访问目
标数据库中的数据,并做进一步的深入分析之用。数据访问和分析工具不但要提供一般的数
据访问功能,如查询、汇总、统计等,还要提供对数据的深入分析功能,主要包括联机分析
处理与数据挖掘。
联机分析处理(OLAP)是针对特定问题的联机数据访问和分析,通过对信息进行快速、
稳定、一致和交互式的存取,对数据进行多层次、多阶段的分析处理,以获得高度归纳的分
析结果。联机分析处理是一种自上而下、不断深入的分析工具。在用户提出问题或假设之后,
它负责提取出关于此问题的详细信息,并以一种比较直观的方式呈现给用户。联机分析处理
是功能强大的多用户的数据操纵引擎,特别用来支持和操作多维数据结构,为前端工具提供
多维数据视图及服务。目前,联机分析处理的工具可分为两大类,一类是基于多维数据库的,
另一类是基于关系数据库的。两者的相同点是基本数据源仍是数据库和数据仓库,都向用户
显示多维数据视图;不同点在于,前者是把分析所需的数据从数据仓库中抽取出来,物理地
组织成多维数据库,而后者则是利用关系表来模拟多维数据,并不是物理地生成多维数据库。
数据挖掘的基本思想是从数据中抽取有价值的信息,其目的是帮助决策者寻找数据间潜在的
关联,发现被忽略的要素,而这些信息对预测趋势和决策行为可能是十分有用的。从而帮助
企业或组织的决策者调整市场策略,减少风险,辅助做出正确的决策。
9.1.4 数据仓库的关键技术
数据仓库与关系数据库不同,并没有严格的数学理论基础,它更偏向于工程。由于数据
仓库的这种工程性,因而在技术上可以根据它的工作过程分为:数据的抽取、存储和管理、
数据的表现、数据仓库设计的技术咨询等方面。
1.数据的抽取
数据的抽取是数据进入仓库的入口。由于数据仓库是一个独立的数据环境,它需要通过
抽取过程将数据从联机事务处理系统、外部数据源、脱机的数据存储介质中导入到数据仓库。
数据抽取在技术上主要涉及互连、复制、增量、转换、调度和监控等几个方面。数据仓库的
数据并不要求与联机事务处理系统保持实时的同步,因此数据抽取可以定时进行,但多个抽
取操作执行的时间、相互的顺序、成败对数据仓库中信息的有效性则至关重要。在技术发展
上,数据抽取所涉及的单个技术环节都已相对成熟,其中有一些是避不开编程的,整体的集
成度还很不够。目前市场上所提供的大多数据抽取工具是通过用户选定源数据和目标数据的
对应关系,来自动生成数据抽取的代码。但数据抽取工具支持的数据种类是有限的;同时数
据抽取过程涉及数据的转换,它是一个与实际应用密切相关的部分,其复杂性使得不可嵌入
用户编程的抽取工具往往不能满足要求。因此,实际的数据仓库实施过程中往往不一定使用
抽取工具,通过使用工具而使整个抽取过程纳入有效的管理、调度和维护则更为重要。从市

- 184 - 电子政务数据库基础
场发展来看,以数据抽取、异构互连产品为主项的数据仓库厂商一般都很有可能被其他拥有
数据库产品的公司吞并。在数据仓库的世界里,它们只能成为辅助的角色。
2.数据的存储和管理
在数据仓库的数据存储管理领域,从当今的技术发展来看,面向决策支持扩充的并行关
系数据库将是数据仓库的核心。将普通关系数据库改造成适合担当数据仓库的服务器已成为
关系数据库技术的一个重要研究课题和发展方向,对于决策支持的扩充是传统关系数据库进
入数据仓库市场的重要技术措施。
(1)对大量数据的存储和管理。数据仓库的组织管理方式决定了它有别于传统数据库的
特性,同时也决定了其对外部数据的表现形式。数据仓库所涉及的数据量比传统事务处理大
得多,且随时间的推移而累积。要决定采用什么产品和技术来建立数据仓库核心,则需要从
数据仓库的技术特点着手分析。从现有技术和产品来看,只有关系数据库系统能够担当此任。
关系数据库经过近 30 年的发展,在数据存储和管理方面已经非常成熟,非其他数据管理系统
可比。目前不少关系数据库系统已支持数据分割技术,能够将一个大的数据库表分散在多个
物理存储设备中,进一步增强了系统管理大数据量的扩展能力。采用关系数据库管理数百个
GB 甚至到 TB 的数据已是一件平常的事情。一些厂商还专门考虑大数据量的系统备份问题,
数据仓库对联机备份的要求并不高。
(2)并行处理。在传统联机事务处理应用中,用户访问系统的特点是短小而密集;对于
一个多处理机系统来说,能够将用户的请求进行均衡分担是关键,这便是并发操作。而在数
据仓库系统中,用户访问系统的特点是庞大而稀疏,每一个查询和统计都很复杂,但访问的
频率并不是很高。此时系统需要有能力将所有的处理机调动起来为这一个复杂的查询请求服
务,将该请求并行处理。因此,并行处理技术在数据仓库中比以往更加重要。
(3)针对决策支持查询的优化。这个问题主要针对关系数据库而言,因为其他数据管理
环境连基本的通用查询能力都还不完善。在技术上,针对决策支持的优化涉及数据库系统的
索引机制、查询优化器、连接策略、数据排序和采样等诸多部分。普通关系数据库采用 B 树
类的索引,对于性别、年龄、地区等具有大量重复值的字段几乎没有效果。而扩充的关系数
据库则引入了位图索引的机制,以二进制位表示字段的状态,将查询过程变为筛选过程,单
个计算机的基本操作便可筛选多条记录。由于数据仓库中各数据表的数据量往往极不均匀,
普通查询优化器所得出的最佳查询路径可能不是最优的。因此,面向决策支持的关系数据库
在查询优化器上也做了改进,同时根据索引的使用特性增加了多重索引扫描的能力。
以关系数据库建立的数据仓库在应用时会遇到大量的表间连接操作,而连接操作对于关
系数据库来说是一件耗时的操作。扩充的关系数据库中对连接操作可以做预先的定义,我们
称之为连接索引,使得数据库在执行查询时可直接获取数据而不必实施具体的连接操作。数
据仓库的查询常常只需要数据库中的部分记录,如最大的前 50 家客户,等等。普通关系数据
库没有提供这样的查询能力,只好将整个表的记录进行排序,从而耗费了大量的时间。决策
支持的关系数据库在此做了改进,提供了这一功能。此外,数据仓库的查询并不需要像事务
处理系统那样精确,但在大容量数据环境中需要有足够短的系统响应时间。因此,一些数据
库系统增加了采样数据的查询能力,在精确度允许的范围内,大幅度提高系统查询效率。
(4)支持多维分析的查询模式。这也是关系数据库在数据仓库领域遇到的最严峻的挑战
之一。用户在使用数据仓库时的访问方式与传统的关系数据库有很大的不同。对于数据仓库

第 9 章 电子政务数据仓库与数据挖掘 - 185 -
的访问往往不是简单的表和记录的查询,而是基于用户业务的分析模式,即联机分析。它的
特点是将数据想像成多维的立方体,用户的查询便相当于在其中的部分维上施加条件,对立
方体进行切片、分割,得到的结果则是数值的矩阵或向量,并将其制成图表或输入算法。关
系数据库本身没有提供这种多维分析的查询功能,而且在数据仓库发展的早期,人们发现采
用关系数据库去实现这种多维查询模式非常低效、查询处理的过程也难以自动化。为此,提
出了多维数据库的概念。多维数据库是一种以多维数据存储形式来组织数据的数据管理系统,
它不是关系型数据库,在使用时需要将数据从关系数据库中转载到多维数据库中才可访问。
采用多维数据库实现的联机分析应用称之为 MOLAP。多维数据库在针对小型的多维分析应
用有较好的效果,但它缺少关系数据库所拥有的并行处理及大规模数据管理扩展性,因此难
以承担大型数据仓库应用。关系数据库若采用“星型模式”来组织数据就能很好地解决多维
分析的问题。“星型模式”只不过是数据库设计中数据表之间的一种关联形式,它的巧妙之处
在于能够找到一个固定的算法,将用户的多维查询请求转换成针对该数据模式的标准 SQL 语
句,而且该语句是最优化的。“星型模式”的应用为关系数据库在数据仓库领域打开绿灯。采
用关系数据库实现的联机分析应用称为 ROLAP,目前,大多数厂商提供的数据仓库解决方
案都采用 ROLAP。
3.数据的表现
数据表现主要集中在多维分析、数理统计和数据挖掘方面。多维分析是数据仓库的重要
表现形式,由于 MOLAP 系统是专用的,因此,关于多维分析领域的工具和产品大多是 ROLAP
工具。这些产品近两年来更加注重提供基于 Web 的前端联机分析界面,而不仅仅是网上数据
的发布。数理统计原本与数据仓库没有直接的联系,但在实际的应用中,客户需要通过对数
据的统计来验证他们对某些事物的假设,以进行决策。与数理统计相似,数据挖掘与数据仓
库也没有直接的联系,数据挖掘强调的不仅仅是验证人们对数据特性的假设,而且它更要主
动地寻找并发现蕴藏在数据之中的规律。
4.数据仓库设计的技术咨询
在数据仓库的实施过程中,有一些基本的问题需要解答。它们包括:数据仓库提供给哪
些部门使用,不同的部门如何发挥数据仓库的决策效益,数据仓库需要存放哪些数据,这些
数据以什么样的结构存放,数据从哪里装载,装载的频率多少为合适,需要购置哪些数据管
理的产品和工具来建立数据仓库等。这些问题的解决依赖于特定的数据仓库系统,属于技术
咨询的范畴。数据仓库不是简单的产品堆砌,它是综合性的解决方案和系统工程。在数据仓
库的实施过程中,技术咨询服务至关重要,是一个不可缺少的部分,它甚至于比购买产品更
为重要。目前,数据仓库的技术咨询主要来自数据仓库软件产品的供应商和独立的针对数据
仓库技术的咨询公司。
9.2 数 据 挖 掘
随着数据库技术的迅速发展以及数据库管理系统的广泛应用,人们积累的数据越来越
多。激增的数据背后隐藏着许多重要的信息,人们希望能够对其进行更高层次的分析,以便

- 186 - 电子政务数据库基础
更好地利用这些数据。目前的数据库系统可以高效地实现数据的录入、查询、统计等功能,
但无法发现数据中存在的关系和规则,无法根据现有的数据预测未来的发展趋势。缺乏挖掘
数据背后隐藏的知识的手段,导致了“丰富的数据,贫乏的知识”的现象。为了帮助人们智
能化地分析如山的数据量,自动地分析一些事例,出现了新一代的技术和工具,这些技术和
工具主要用于数据挖掘(data mining)和知识发现(Knowledge discovery in database,KDD)
领域。数据挖掘使数据库技术进入了一个更高级的阶段,它不仅能对过去的数据进行查询和
遍历,并且能够找出过去数据之间的潜在联系,从而促进信息的传递。
9.2.1 数据挖掘概述
1.数据挖掘概念
数据挖掘就是应用一系列技术从大型数据库或数据仓库中提取人们感兴趣的信息和知
识,这些知识或信息是隐含的,事先未知而潜在有用的,提取的知识表示为概念、规则、规
律、模式等形式。也可以说,数据挖掘是一类深层次的数据分析。数据挖掘的实质是将人工
智能技术(神经网络、模糊逻辑、粗糙集、遗传算法等)应用到大规模数据,以发现隐含的
趋势模式和关系。
数据挖掘是数据库研究中的一个很有应用价值的新领域,融合了数据库、人工智能、机
器学习、统计学等多个领域的理论和技术。数据挖掘工具能够对将来的趋势和行为进行预测,
从而很好地支持人们的决策。
2.数据挖掘的演变过程
数据挖掘是一个逐渐演变的过程,电子数据处理的初期,人们就试图通过某些方法来实
现自动决策支持,当时机器学习成为人们关心的焦点。机器学习的过程就是将一些已知的并
已被成功解决的问题作为范例输入计算机,机器通过学习这些范例总结并生成相应的规则,
这些规则具有通用性,使用它们可以解决某一类的问题。随后,随着神经网络技术的形成和
发展,人们的注意力转向知识工程,知识工程不同于机器学习那样给计算机输入范例,让它
生成出规则,而是直接给计算机输入已被代码化的规则,计算机通过使用这些规则来解决某
些问题。专家系统就是这种方法所得到的成果,但它有投资大、效果不甚理想等不足。80 年
代人们又在新的神经网络理论的指导下,重新回到机器学习的方法上,并将其成果应用于处
理大型商业数据库。知识发现(KDD)一词首次出现在 1989 年举行的第十一届国际联合人
工智能学术会议上。研究重点也逐渐从发现方法转向系统应用,注重多种发现策略和技术的
集成,以及多种学科之间的相互渗透。1998 年在美国纽约举行有关数据挖掘国际学术会议不
仅进行了学术讨论,而且已有 30 多家软件公司展示了他们的数据挖掘软件产品,不少软件已
在北美、欧洲等国得到应用。数据挖掘方法现已成为当前人工智能和数据库技术的一个活跃
的研究领域。数据挖掘属于典型交叉学科领域。在数据挖掘中需要计算机科学、统计、认知
科学等相关领域的知识。
3.数据挖掘与数据仓库的关系
数据挖掘和数据仓库作为决策支持新技术在近十年来得到了迅速的发展。数据仓库的发

第 9 章 电子政务数据仓库与数据挖掘 - 187 -
展为数据挖掘技术开辟了新的领域,同时也提出了新的要求和挑战。把数据挖掘建立在数据
仓库之上,一方面能够提高数据仓库系统的决策支持能力,另一方面,由于数据仓库完成了
数据的清理、ETL(抽取,转换,装载),数据挖掘面对的是经过初步处理的数据,更加有利
于数据挖掘功能的发挥。这方面的研究集中在基于数据仓库的数据挖掘系统结构的探讨上。
数据仓库技术的发展与数据挖掘有着密切的关系。数据仓库的发展是促进数据挖掘越来
越热的原因之一。但是,数据仓库并不是数据挖掘的先决条件,因为有很多数据挖掘可直接
从操作数据源中挖掘信息。
4.数据挖掘的分类
数据挖掘涉及的学科领域和方法很多,有多种分类法:
(1)根据挖掘任务分类。根据挖掘任务可分为:分类或预测规则发现、总结规则挖掘、
特征规则挖掘、聚类、关联规则发现、序列模式发现、依赖关系或依赖模型发现、模式分析、
异常和趋势发现等。
(2)根据挖掘数据对象分类。根据挖掘对象可分为:关系数据库、面向对象数据库、数
据仓库、主动型数据库、空间数据库、时态数据库、文本数据源、多媒体数据库、异质数据
库、以及 Web 数据库等。
(3)根据挖掘技术分类。根据挖掘方法可分为:机器学习、统计、神经网络、决策树、
遗传算法、模糊集和粗糙集等方法。其中,机器学习中可细分为:归纳学习方法(决策树、
规则归纳等)、基于范例学习、遗传算法等。统计方法可细分为:回归分析(多元回归、自回
归等)、判别分析(贝叶斯判别、费歇尔判别、非参数判别等)、聚类分析(系统聚类、动态
聚类等)、探索性分析(主元分析法、相关分析法等)等。神经网络方法可细分为:前向神经
网络(BP 算法等)、自组织神经网络(自组织特征映射、竞争学习等)等。
9.2.2 数据挖掘的常用技术
1.人工神经网络
神经网络是一种被广泛用于模式识别及机器学
习的人工智能技术,神经网络方法具有较强的适应能
力和学习能力,它用于数据分类和预测中的精度是非
常高的。与经典统计方法的区别在于,它能够被应用
于小样本的数据分析,而不必满足正态分布的假设。
由于包含在隐层中的非线性转换,神经网络对于模拟
具有复杂模式的数据执行效果较好。构成神经网络的
单个计算单元称为节点、单元或神经元,一般而言,
神经网络是一个并行和分布式的信息处理网络结构,
神经网络由许多并行运算的功能简单的神经元组成,
这些神经元类似于生物神经系统的神经元,神经元模
型如图 9.11 所示。
每一个神经元只有一个输出,它可以连接到许多其他的神经元,每个神经元输入有多个
输入 一般神经元
b
∑ fM
����PPPPM�n a
( )a f w p b= ⋅ =
1
1,Rw
11w
图 9.11 神经元模型

- 188 - 电子政务数据库基础
连接通路,每个连接通路对应于一个连接权系数。同时运行或并行运行的神经元的集合称为
层,层分为输入层、输出层及隐层。严格地说,神经网络是一个具有下列性质的有向图:
(1)每个节点有一个状态变量 xj;
(2)节点 i 到节点 j 有一个连接权系数 wji;
(3)每个节点有一个阈值θj;
(4)每个节点定义一个变换函数 fj [xi, wji,θj (i≠j)],最常见的形式为:
)( jii
ji xwf θ−∑
虽然单个神经元的结构极其简单,功能有限,但大量神经元构成的网络系统所能实现的
行为却是极其丰富多采的。和数字计算机相比,神经网络系统具有集体运算的能力和自适应
的学习能力。此外,它还具有很强的容错性和鲁棒性,善于联想、综合和推广。
2.决策树
数据挖掘中决策树是一种经常要用到的技术,可以用于分析数据,同样也可以用来做预
测。常用的算法有 CHAID、CART、Quest、ID3 和 C5.0 等。决策树提供了一种展示类似在
何种条件下会得到何种值这类规则的方法,并把数据归入可能对一个目标变量有不同效果的
规则组。决策树由决策节点、分支和叶子组成,代表着决策集的树形结构。其中,叶结点是
类名,中间结点是带有分枝的属性,分枝对应该属性的某一可能值。带有分枝的属性决策树
的每个节点的子节点的个数与决策树所用的算法有关。如 CART 算法得到的决策树每个节点
有两个分支,这种树称为二叉树。允许节点含有多于两个子节点的树称为多叉树。每个分支
要么是一个新的决策节点,要么是树的结尾,称为叶子。在沿着决策树从上到下遍历的过程
中,每个节点都会遇到一个问题,对每个节点上问题的不同回答导致不同的分支,最后会到
达一个叶子节点。这个过程就是利用决策树进行分类的过程,利用几个变量(每个变量对应
一个问题)来判断所属的类别(最后每个叶子会对应一个类别)。例如,我们希望发现可能
会对直邮有反应的个人特点,这些特点可以解释为一组规则。假设您是一个销售一种新的银
行服务的直邮计划研究的负责人。为最大程度地获益,您希望确定基于前次促销活动的家庭
细分最有可能响应相似的促销活动。通常这可以通过查找最能响应前次促销的家庭和没有响
应的家庭,区分开的人口统计信息变量的组合来实现,这种技术称为“数据分段”或“分段
建模”。这一过程提供了诸如谁会最好地响应新的促销等重要线索,并通过只邮寄给最有可
能响应的人来最大程度地获得直邮效益,提高整体响应率,并极有希望同时增加销售。用
CHAID 算法简化的决策树分段过程如图 9.12 所示。
由图 9.12 可以看出所有收到直邮信件的人中有 7%有响应。但是,如果分为有住房和无
住房两组,则 15%的租户有响应,而房主则只有 5%。继续分组可以发现最有可能响应的组
群。这一组群可以表示为一个规则,如“如果收件人是租户,有较高的家庭收入,没有储蓄
存款账户,那么他有 45%的响应概率”。简单地说,有这些特点的组群中有 45%可能会对直
邮有响应。建立决策树的过程是不断地把数据进行切分的过程,每次切分对应一个问题,也
对应着一个节点。对每个切分都要求分成的组之间的“差异”最大。建立一棵决策树可能只
要对数据库进行几遍扫描之后就能完成,这也意味着需要的计算资源较少,而且可以很容易
地处理包含很多预测变量的情况,因此决策树模型可以建立得很快,并适合应用到大量的数

第 9 章 电子政务数据仓库与数据挖掘 - 189 -
据上。决策树擅长于处理非数值型数据,这与神经网络只能处理数值型数据比起来,就免去
了很多数据预处理工作。
图 9.12 决策树
3.遗传算法
遗传算法是模拟生物进化过程的算法,由三个基本算子(或过程)组成:
(1)选择。即从一个旧种群(父代)选出生命力强的个体,产生新的种群(后代)的过
程。
(2)重组。即选择两个不同的个体(染色体)的部分(基因)进行交换,形成新个体的
过程。
(3)变异。即对某些个体的某些基因进行变异(0 变 1,或 1 变 0),形成新个体的过程。
遗传算法可起到产生优良后代的作用。这些后代需满足适应值,经过若干代的遗传,将
得到满足要求的后代(即问题的解)。遗传算法已在优化计算和分类机器学习等方面发挥了显
著的作用。在数据挖掘中应用的人工智能技术还有邻近搜索方法(Nearest Neighbor Method)、
粗糙集方法(Rough Sets)、规则推理(Rule Induction)、模糊逻辑(Fuzzy Logic)等。数据
挖掘除了应用人工智能技术外,还综合应用了其他的技术,如统计学等。
9.2.3 数据挖掘的分析方法
数据挖掘的任务是从数据中发现模式。模式有很多种,按功能可分两大类:预测型
(Predictive)模式和描述型(Descriptive)模式。预测型模式是可以根据数据项的值精确确
定某种结果的模式,挖掘预测型模式所使用的数据都可以明确知道结果。描述型模式是对数
据中存在的规则做一种描述,或者根据数据的相似性把数据分组,它不能直接用于预测。在
实际应用中。模式往往根据其实际作用细分为以下 6 种:分类模式、回归模式、时间序列模
式、聚类模式、关联模式和序列模式等。在解决实际问题时,经常要同时使用多种模式,分
类模式和回归模式是其中使用最普遍的二种模式。

- 190 - 电子政务数据库基础
从功能上可以将数据挖掘的分析方法划分为以下五种:
(1)自动预测趋势和行为。数据挖掘自动在大型数据库中寻找预测性信息,以往需要进
行大量手工分析的问题如今可以迅速直接由数据本身得出结论。一个典型的例子是市场预测
问题,数据挖掘使用过去有关促销的数据来寻找未来投资中回报最大的用户,其他可预测的
问题包括预测破产以及认定对指定事件最可能做出反应的群体等。
(2)关联分析。数据关联是数据库中存在的一类重要的可被发现的知识。若两个或多个
变量的取值之间存在某种规律性,就称为关联。关联可分为简单关联、时序关联、因果关联。
关联分析的目的是找出数据库中隐藏的关联网。有时并不知道数据库中数据的关联函数,即
使知道也是不确定的,因此关联分析生成的规则带有可信度也称为支持度,以表示这种规则
发生的概率。例如在一个商场中,某天共有 1000 笔业务,其中有 100 笔业务同时买了微波炉
和微波炉专用器皿,则购买微波炉的同时购买微波炉专用器皿的关联规则的支持度为 10%。
设 T 是交易数据,T={t1, t2, t3,�,tm},其中 ti (1≤i≤m)是每笔交易的数据,若一笔交
易中既含有 X,又含有 Y,X∩Y=Φ,则称 x→y 在此交易中成立。若 x→y 在 T 的 s%的交易
中成立,即称 x→y 的支持度(Support)为 s%,即:
support(x→y)= | { | , } |100% %
| |
t t X Ys
T× =
中含有
支持度表示 x→y 在 T 交易数据中出现的普遍程度。 关联规则挖掘的一个典型例子是购物篮分析。市场分析员要从大量的数据中发现顾客放
入其购物篮中的不同商品之间的关系。如果顾客买牛奶,他也购买面包的可能性有多大?什
么商品组或集合顾客多半会在一次购物时同时购买?例如,买牛奶的顾客有 80%也同时买面
包,或买铁锤的顾客中有 70%的人同时也买铁钉,这就是从购物篮数据中提取的关联规则。
分析结果可以帮助管理人员设计不同的商店布局。一种策略是:经常一块购买的商品可以放
近一些,以便进一步刺激这些商品一起销售,例如,如果顾客购买计算机又倾向于同时购买
财务软件,那么将硬件摆放离软件陈列近一点,可能有助于增加两者的销售。另一种策略是:
将硬件和软件放在商店的两端,可能诱发购买这些商品的顾客一路挑选其他商品。 (3)聚类分析。数据库中的记录可被化分为一系列有意义的子集,即聚类。聚类是一个
将数据集划分为若干类的过程,并使得同一个组内的数据对象具有较高的相似度;而不同组
中的数据对象是不相似的。相似或不相似的描述是基于数据描述属性的取值来确定的。聚类
增强了人们对客观现实的认识,是概念描述和偏差分析的先决条件。聚类技术主要包括传统
的模式识别方法和数学分类学。20 世纪 80 年代初,Mchalski 提出了概念聚类技术,其要点
是:在划分对象时不仅考虑对象之间的距离,还要求划分出的类具有某种内涵描述,从而避
免了传统技术的某些片面性。 (4)概念描述。概念描述就是对某类对象的内涵进行描述,并概括这类对象的有关特征。
概念描述分为特征性描述和区别性描述,前者描述某类对象的共同特征,后者描述不同类对
象之间的区别。生成一个类的特征性描述只涉及该类对象中所有对象的共性。生成区别性描
述的方法很多,如决策树方法、遗传算法等。 (5)偏差检测。数据库中的数据常有一些异常记录,从数据库中检测这些偏差很有意义。
偏差包括很多潜在的知识,如分类中的反常实例、不满足规则的特例、观测结果与模型预测
值的偏差、量值随时间的变化等。偏差检测的基本方法是,寻找观测结果与参照值之间有意

第 9 章 电子政务数据仓库与数据挖掘 - 191 -
义的差别。
9.2.4 数据挖掘内容
数据挖掘所发现的知识最常见的有以下四类:
(1)广义知识(Generalization),广义知识指类别特征的概括性描述知识。根据数据的微
观特性发现其表征的、带有普遍性的、具有较高层次概念的知识,反映同类事物共同性质,
是对数据的概括、精炼和抽象。广义知识的发现方法和实现技术有很多,如数据立方体、面
向属性的归约等。数据立方体还有其他一些别名,如“多维数据库”、“实现视图”、“OLAP”
等。该方法的基本思想是实现某些常用的代价较高的聚集函数的计算,诸如计数、求和、平
均、最大值等,并将这些实现视图存储在多维数据库中。由于很多聚集函数需经常重复计算,
在多维数据立方体中存放预先计算好的结果将能保证快速响应,并可灵活地提供不同角度和
不同抽象层次上的数据视图。另一种广义知识发现方法是加拿大 SimonFraser 大学提出的面
向属性的归约方法。这种方法以类 SQL 表示数据挖掘查询,收集数据库中的相关数据集,然
后在相关数据集上应用一系列数据推广技术进行数据推广,包括属性删除、概念树提升、属
性阈值控制、计数及其他聚集函数传播等。
(2)关联知识(Association),关联知识反映一个事件和其他事件之间依赖或关联的知识。
如果两项或多项属性之间存在关联,那么其中一项的属性值就可以依据其他属性值进行预测。
最为著名的关联规则发现方法是 R.Agrawal 提出的 Apriori 算法。关联规则的发现可分为两步。
第一步是迭代识别所有的频繁项目集,要求频繁项目集的支持率不低于用户设定的最低值;
第二步是从频繁项目集中构造可信度不低于用户设定的最低值的规则。识别或发现所有频繁
项目集是关联规则发现算法的核心,也是计算量最大的部分。
(3)分类知识(Classification),分类是反映同类事物共同性质的特征型知识和不同事物
之间的差异型特征知识。最为典型的分类方法是基于决策树的分类方法。此外,数据分类还
有统计、粗糙集(Rough Set)等方法。线性回归和线性辨别分析是典型的统计模型。为降低
决策树生成代价,人们还提出了一种区间分类器。最近也有人研究使用神经网络方法在数据
库中进行分类和规则提取。
(4)预测型知识(Prediction),预测型知识指根据时间序列型数据,由历史的和当前的
数据去推测未来的数据,也可以认为是以时间为关键属性的关联知识。目前,时间序列预测
方法有经典的统计方法、神经网络和机器学习等。1968 年 Box 和 Jenkins 提出了一套比较完
善的时间序列建模理论和分析方法,这些经典的数学方法通过建立随机模型,如自回归模型、
自回归滑动平均模型、求和自回归滑动平均模型和季节调整模型等,进行时间序列的预测。
由于大量的时间序列是非平稳的,其特征参数和数据分布随着时间的推移而发生变化。因此,
仅仅通过对某段历史数据的训练,建立单一的神经网络预测模型,还无法完成准确的预测任
务。为此,人们提出了基于统计学和基于精确性的再训练方法,当发现现存预测模型不再适
用于当前数据时,对模型重新训练,获得新的权重参数,建立新的模型。也有许多系统借助
并行算法的计算优势进行时间序列预测。
(5)偏差型知识(Deviation),偏差型知识是对差异和极端特例的描述,揭示事物偏离常
规的异常现象,如标准类外的特例,数据聚类外的离群值等。所有这些知识都可以在不同的

- 192 - 电子政务数据库基础
概念层次上被发现,并随着概念层次的提升,从微观到宏观,以满足不同用户不同层次决策
的需要。
9.2.5 数据挖掘工具
(1)基于神经网络的工具。由于对非线性数据的快速建模能力,基于神经网络的数据挖
掘工具现在越来越流行。其挖掘过程基本上是将数据聚类,然后分类计算权值。神经网络很
适合非线性数据和含噪声数据,所以在市场数据库的分析和建模方面应用广泛。
(2)基于规则和决策树的工具。大部分数据挖掘工具采用规则发现或决策树分类技术来
发现数据模式和规则,其核心是某种归纳算法。这类工具通常是对数据库的数据进行开采,
生产规则和决策树,然后对新数据进行分析和预测。这类工具的主要优点是,规则和决策树
都是可读的。
(3)基于模糊逻辑的工具。其发现方法是应用模糊逻辑进行数据查询、排序等。该工具
使用模糊概念和最近邻搜索技术的数据查询工具,它可以让用户指定目标,然后对数据库进
行搜索,找出接近目标的所有记录,并对结果进行评估。
(4)综合多方法工具。不少数据挖掘工具采用了多种开采方法,这类工具一般规模较大,
适于大型数据库(包括并行数据库)。这类工具开采能力很强,但价格昂贵,并要花很长时间
进行学习。
9.2.6 数据挖掘流程
数据挖掘的基本过程如图 9.13 所示。
(1)数据准备
① 数据集成。指从数据库或数据仓库等数
据源中提取并集成数据,例如解决语义二义性
问题、消除脏数据等
② 数据的选择。搜索所有与业务对象有关
的内部和外部数据信息,并从中选择出适用于
数据挖掘应用的数据。
③ 数据的预处理。数据清理、过滤等,研
究数据的质量,为进一步的分析做准备,并确
定将要进行的挖掘操作的类型。
④ 数据的转换。将数据转换成一个分析模
型。这个分析模型是针对挖掘算法建立的一个
真正适合挖掘算法的分析模型,是数据挖掘成
功的关键。
(2)数据挖掘
对所得到的经过转换的数据进行挖掘。除
了选择合适的挖掘算法外,其余一切工作都能
自动地完成。 图 9.13 数据挖掘的基本过程
用户界面
模式评价
数据挖掘机
数据库或数据仓库
数据清理与数据集成 过滤
知识库
数据仓库
数据库

第 9 章 电子政务数据仓库与数据挖掘 - 193 -
(3)模式评价
解释并评估结果,并将分析所得到的知识集成到业务信息系统的知识库中。使用的分析
方法一般应随数据挖掘操作而定,通常会用到可视化技术。
9.3 基于数据仓库的电子政务资源库建设
政府部门是一个国家最重要的信息机构。在工作过程中,政府部门建立了庞大的信息收
集系统并积累了大量政务数据,这些政务数据的开发利用对于政府科学决策非常重要。同时,
政府数据资源的开发利用有助于打破各级政府部门对信息的垄断和封闭,推动政务公开的实
施,使政务数据资源发挥巨大的社会效益和经济效益。利用电子政务综合数据库中存储的大
量数据,通过数据仓库、数据挖掘技术建立正确的决策体系和决策支持模型,可以为各级政
府的决策提供科学的依据,提高各项政策制定的科学性和合理性,增强政府在应对突发事件
时的快速响应能力,以达到提高政府办公效率、促进经济发展的目的。
9.3.1 电子政务数据仓库建设
数据仓库能够完成数据的集中和信息整理,提升信息管理水平和业务决策管理水平,加
强管理者对其服务业状况、资源分布等的全面了解,从而提高决策的科学性和快速的反应能
力。电子政务数据仓库所用数据来自办公文档、资源环境、人口治安、财政经济等各事务处
理数据库,如图 9.14 所示。
图 9.14 电子政务数据仓库
电子政务数据仓库中的数据来源于不同的业务数据库,这些系统由于建立时间不同,系
统选型不同,开发人员不同等原因,使得各个业务系统的硬件环境和软件环境各不相同,数
��元
素
据
(原子数据层和具体的历史数据)
数据采集(抽取、转化、传输、装载)
统计
报表
办公
文档
财政
经济
党务
社团
社会
事务
资源
环境
人口
治安
数据仓库

- 194 - 电子政务数据库基础
据结构不统一。如数据库中表示“性别”的字段,有的系统使用“0”和“1”表示,有的系
统却使用“F”和“M”表示。这些不同的字段在数据仓库中最终要以统一的类型和格式表示。
所以要将这些系统中的有用数据提取出来,首先需做清理、转换、整合等处理,去掉没用的
数据项,将数据转换成统一格式加载到数据仓库中。在这过程中,主要是将政务系统中各个
面向应用的数据重新组织出若干主题。通过设计转换模式去除不同数据源之间的不一致,转
换的工作不仅要完成言语数据模式上的转换,还要打上数据仓库用于数据记录的时间戳。
9.3.2 基于数据仓库的电子政务决策支持系统
决策支持系统是综合利用各种数据、信息和模型技术的信息处理系统。决策支持系统建
立在大量的数据基础上,利用各种模型及技术对数据进行分析,从而为决策者提供及时、准
确、科学的决策信息,解决半结构化或结构化的决策问题。电子政务中的决策支持系统建立
在电子政务平台基础上,通过对政务数据进行定性和定量分析,为高层管理者提供决策信息。
基于数据仓库与数据挖掘的电子政务决策系统体系结构包括三个主体:政务决策模型库、政
务数据仓库、数据分析与挖掘工具,如图 9.15 所示。
图 9.15 电子政务的决策支持体系结构
(1)政务决策模型库存放解决行政管理问题的经验模型,政务数据仓库存放从日常行政
管理和政府职能部门业务系统中抽取的数据,数据分析与挖掘工具根据模型库对数据仓库的
数据进行分析挖掘,产生决策信息。
(2)数据仓库技术可以极大地提高决策支持系统能够存储的信息量和基于时间的信息分
析能力,为有效支持用户管理决策提供了全局一致的数据环境,帮助政府决策者再通过其他
分析工具方便地使用这些数据。数据仓库解决方案,不仅从功能上,而且在实现的过程中,
都能适应决策人员需求的不断变化。为政府的各种决策分析系统提供基础的数据平台。这对
于各级党政机关充分利用已有的历史数据、提高决策的可信度有重要意义。
(3)数据分析与挖掘工具主要有两种:联机分析处理(OLAP)与数据挖掘(DM)。OLAP 从
政务数据集合中收集信息,并运用数学运算和数据处理技术,灵活、交互式地提供统计、趋
势分析报告。通过数据分析和展现工具对数据仓库中的数据进行多维分析、汇总,形成图表
� �
� �
�
用 户
数据分析与挖掘工具
政务决策模型库 政务数据仓库
政务数据资源
集成、清理
第 9 章 电子政务数据仓库与数据挖掘 - 195 -
或报表的形式,使决策者可以清晰、直观地看到分析结果。数据挖掘技术较适合于信息形式
繁多的政府部门。对电子政务系统中的各种数据,特别是非结构化数据进行检索、分析、评
价,挖掘出相关知识,预测未来发展趋势,为政府重大政策出台提供决策支持。比如在灾害
预警系统中使用数据挖掘的关联分析和回归预测技术对历史数据进行分析,可以预测与灾害
相关的因素、灾害发生发展的趋势,并制定急救措施及财政支出。税务管理系统的所得税缴
税方面容易出现欺诈行为,如使用数据挖掘的孤立点分析法,可以很容易地发现哪些地方存
在欺诈。利用我国国际贸易和美国股市交易的历史数据,可以分析确定美国股市波动对我国
经济的影响以及应该采取的措施。
电子政务决策支持系统是政务信息化的一项重要内容。随着电子政务建设的深入开展,
政府对于信息系统决策支持的要求也在逐步提高,电子政务在运行过程中会产生很多有价值
的数据,为了使电子政务系统的建设具有前瞻性,在构建电子政务基础架构时,应该充分利
用数据仓库技术建设政府内部管理系统与决策支持系统,通过数据挖掘手段,获得更多可供
高层管理人员决策的知识。提高政府部门决策的准确性和科学性,使政府为整个社会的发展
提供科学规划和宏观调控。
9.4 本 章 小 结
本章主要介绍了数据仓库技术、数据挖掘技术、及数据仓库与数据挖掘在电子政务中的
应用。数据仓库技术在电子政务资源库中的应用极其重要,以数据仓库技术为基础的电子政
务资源库,将成为整个电子政务系统的核心。应用数据仓库、数据挖掘技术,将有效提高对
现有政务数据资源的利用深度和广度,为各级政府的决策提供科学的依据。
9.5 本 章 习 题
1.数据仓库的特点
2.数据仓库的数据组织形式。
3.数据仓库体系化环境的构成。
4.数据挖掘的常用技术
5.数据挖掘的基本流程。
6.基于数据仓库与数据挖掘的电子政务决策支持系统构建方法。
9.6 本章参考文献
1.W. H. Inmon 著,王志海等译·Building the Data Warehouse,Thrid Edition·北京:机

- 196 - 电子政务数据库基础
械工业出版社,2003
2.王珊等· 数据仓库技术与联机分析处理·北京:科学出版社,1999
3.陈侃·基于数据仓库技术的电子政务资源库·计算机工程,30(3)·2004
4.王能斌等·数据库系统原理·北京:电子工业出版社,2000
5.陈靖等·面向电子政务的决策支持系统设计与实现·空军工程大学学报,4(2)·2003
6.杨剑锋·浅淡电子政务中的决策支持·计算机时代,(12)·2003
7.JiaweiHanMichelineKamber·数据挖掘概念与技术·北京:机械工业出版社,2001
8.陈京民·数据仓库与数据挖掘技术·北京:电子工业出版社,2002
9.金江军等·电子政务数据资源的开发利用·地理与地理信息科学,19(6)·2003
10.高人伯等·数据仓库与数据开采相结合的决策支持新技术·计算机世界专题综
述·1997
11.Inmon W H,王海志译·数据仓库·北京:机械工业出版,2000
12.Ralph Kimball,谭明金译·数据仓库工具箱:维度建模的完全指南·北京:电子工
业出版社,2003
13.闻新等·Matlab 神经网络仿真与应用·北京:科学出版社,2003

第 10 章 数据库在电子政务中的应用实例
10.1 实例一:政府信息发布子系统
10.1.1 概述
1.系统背景
政府信息发布子系统源于中国南方某省会市政务信息网中的一部分。随着办公信息的复
杂化,和对高效率的要求,提供集中管理政务信息发布的平台应运而生。整个信息网把各级
部门组织成一个具有很高的信息增值空间的网络,极大地节约了人力物力,加强了人与人之
间的沟通,使得信息流程畅通,组织清晰,政府行为规范,工作透明度大大增加,最终达到
政府职能的高效实现。
2.系统实现目标
信息发布子系统是整个政务信息网的主要组成部分,包括了对信息的编辑、审核、管理
等模块。具体完成了授权用户发布多样化的信息,不同权限的用户对后台进行维护,信息的
跟踪、汇总等处理。通过对政务各种信息的采集、编辑、发表的电子化过程的统一化管理,
加强它们在政府各部门间的快速有效的传播、共享,从而使信息得以充分的利用。
3.使用角色设计
(1)信息发布者:指专门负责发布文档的人员,可以编辑信息的正文,包括正文起草、
起草中的正文修改、起草中的正文提交。他的权限由管理员在权限管理时赋予。
(2)信息审批者:指有权发布并负责审核文档的人员。文档经过审核后才能真正发布。
(3)部门管理者:管理前两种使用者的账号,且设置系统内部发布组、浏览组、信息管
理等工作的人员。
(4)系统管理员:管理前三种使用者的账号,进行系统初始化和系统管理工作的人员。
(5)信息浏览者:最普通的账号,可能本部门内所有人员必须拥有一个账号。除了可以
进行信息发布和审核的账号外,其余账号都是信息浏览者身份的普通账号。
(6)权限的判断:select issuegrp_id from t_topic where topic_id =topicId
4.子系统数据库设计流程
子系统数据库设计流程如图 10.1 所示。
- 198 - 电子政务数据库基础
5.子系统框架及流程
子系统框架及流程如图 10.2、图 10.3 所示。
图 10.2 子系统框架
送审 合格的文章发布
不合格的文章退回
发布中过期的文章冻结
图 10.3 子系统流程图
6.各个模块的功能描述
(1)信息编辑:由信息发布者进行信息编辑工作。
调研,了解组织结构,分析要处理的数据
分析,用数据流图和数据字典描述系统
绘制 E-R 图,建立关系模型,选取合适应用环境的物理结构
数据库建立、使用、维护
图 10.1 子系统数据库设计流程
信
息
发
布
子
系
统
信息编辑
信息审核
信息管理
信息编辑 信息审核 信息管理
第 10 章 数据库在电子政务中的应用实例 - 199 -
图 10.4 信息发布模块层次结构图
(2)信息审核:由信息审批者进行信息审核,审核通过后的信息才可以发布。 �
图 10.5 信息审批模块层次结构图
(3)信息管理:由管理员对发布后的过期信息进行冻结和退回处理。
信息送审 信息删除 移动信息
移动保存
信息修改
修改保存
信息列表
增加信息
相关信息列表
信息搜索 信息提交
增加保存
信息提交
待审信息及相关评论列表
信息发布 信息修改 信息退回 信息删除 评论删除
信息 评论
评论发布 信息移动

- 200 - 电子政务数据库基础
图 10.6 信息管理模块层次结构图
10.1.2 数据库表设计
1.建表语言
(1)用户表
create table t_user (
user_id integer not null,
user_regname varchar(120) not null,
user_name varchar(120) not null,
user_pwd varchar(60) not null,
user_type char(1) not null,
innerorgan_id integer not null,
managergrp_id integer not null,
user_dutyname varchar(60),
dutylevel_id integer not null,
user_sort integer,
face_id integer not null,
user_contact varchar(765),
user_logcount integer,
user_issuecount integer,
user_lastlogIP varchar(45),
user_lastlogTime varchar(57),
primary key(user_id)
)
(2)管理组表
create table t_manager_group(
managergrp_id integer not null,
managergrp_name varchar(120)not null,
managergrp_memcount integer not null,
managergrp_issuecount integer not null,
managergrp_lasttime varchar(57),
primary key(managergrp_id)
)
信息列表
信息冻结 信息退回 信息删除

第 10 章 数据库在电子政务中的应用实例 - 201 -
(3)发布组表
create table t_issue_group(
issuegrp_id integer not null,
issuegrp_name varchar(120) not null,
issuegrp_memcount integer not null,
issuegrp_issuecount integer not null,
issuegrp_lasttime varchar(57),
managergrp_id integer not null,
primary key(issuegrp_id)
)
(4)发布组成员表
create table t_issue_group_user(
issuegrp_id integer not null,
issuegrp_user_postright varchar(1) not null,
user_name varchar(120) not null,
user_id integer not null,
primary key(issuegrp_id,user_id)
)
(5)文章表
create table t_article(
article_id integer not null,
topic_id integer not null,
topic_name varchar(120) not null,
article_title varchar(240) not null,
article_key varchar(180),
article_url varchar(765),
article_content clob(2M),
readergrp_id integer not null,
readergrp_name varchar(120) not null,
article_createtime varchar(57) not null,
article_posttime varchar(57) not null,
create_user_id integer not null,
create_user_name varchar(120) not null,
modify_user_id integer,
modify_user_name varchar(120),
article_readcount integer not null,
article_imgflag varchar(1) not null,
article_editstatus varchar(1) not null,
about_article_id varchar(765),

- 202 - 电子政务数据库基础
article_author varchar(120),
article_derivation varchar(240),
article_statustime varchar(57) not null,
managergrp_id integer,
managergrp_name varchar(120),
issuegrp_id integer,
issuegrp_name varchar(120),
report_id integer,report_data_id integer,
primary key(article_id)
)
(6)评论表
create table t_comment(
comment_id integer not null,
article_id integer not null,
topic_id integer not null,
topic_name varchar(120) not null,
article_title varchar(240) not null,
user_id integer,user_name varchar(120),
comment_postemail varchar(765),
comment_postright varchar(1) not null,
comment_ip varchar(45),
comment_time varchar(57) not null,
comment_title varchar(240) not null,
comment_content clob(2M),
primary key(comment_id)
)
(7)内设机构表
create table t_inner_organ (
innerorgan_id integer not null,
innerorgan_name varchar(90) not null,
innerorgan_desc varchar(765),
innerorgan_leader varchar(30),
innerorgan_address varchar(765),
innerorgan_contact varchar(765),
innerorgan_sort integer,
innerorgan_memsum integer not null,
innerorgan_childsum integer not null,
parent_innerorgan_id integer not null,
managergrp_id integer not null,

第 10 章 数据库在电子政务中的应用实例 - 203 -
primary key(innerorgan_id)
);
2.表结构
(1)t_user 账号用户表
表 10-1 信息发布子系统“账号用户表”表结构
字 段 名 类型(长度) 说 明 空否
user_id(关键字段) int id(自动加1),系统初始化时有一个值0 not
user_regname varchar(40) 登录名(输入),在系统管理,部门管理,机构人员维护中
均要维护,添加时要做重名检查。
N
user_name varchar(40) 用户名(输入),用处 N
user_pwd varchar(20) 密码(最小4位)(输入) N
user_type char(1) 用户类型1:系统 2:部门 3:审批 4:发布 5:登录用户
(人员树上的一般用户)
N
innerorgan_id Int 内部机构ID,此机构部门为他的直接上级机构(程序中会
调用表t_innerorgan)
N
managergrp_id int 管理组id,通过此_ID汇集发布组供栏目树维护此管理组中
的成员。(程序从其他表),系统管理员维护时赋值为0。
N
user_dutyname varchar(20) 工作职务描述(输入)
dutylevel _id int 工作职务等级(从职务表中选择) N
user_sort int 显示序号(输入)
face_id int 政治面貌(从面貌表中选择) N
user_contact varchar(255) 用户联系办法(输入)
user_logcount int 登录次数(程序)
user_issuecount int 发布正文次数(程序)
user_lastlogIP varchar(15) 最后一次登录IP地址(程序)
user_lastlogTime varchar(19) 最后登录时间yyyy-mm-dd hh:mm:ss(程序)
(2)t_manager_group 部门管理组信息表(表 10-2)
表 10-2 信息发布子系统“部门管理组信息表”表结构
字 段 名 类型(长度) 说 明 空否
managergrp_id(关键字段) int 组_id,系统管理组id为0,不可变,系统初始化
就有了此ID(自动加1)
N
managergrp_name varchar(40) 组名称,也相当于部门名称(输入),需要重名
检查。
N
managergrp_memcount Int 部门总人数(程序) N
managergrp_issuecount Int 发布信息总数,每此部门成员做一条信息审核
通过加1(程序)
N
managergrp_lasttime varchar(19) 最后更新时间(审核通过后)(程序)

- 204 - 电子政务数据库基础
(3)t_issue_group 发布组信息表(表 10-3)
表 10-3 信息发布子系统“发布组信息表”表结构
字 段 名 类型(长度) 说 明 空 否
issuegrp_id(关键字段) Int 组id(自动加1) N
issuegrp_name Varchar(40) 组名称(输入) N
issuegrp_memcount Int 人数(程序) N
issuegrp_issuecount Int 发布信息总数,每此组成员做一条信息审核通
过加1(程序)
N
issuegrp_lasttime Varchar(19) 最后更新时间(审核通过后)(程序)
managergrp_id Int 管理此组的管理组名称,通过连接也可以知道
此发布组是属于真正意义上的哪个部门。此字
段=0 表示是系统管理组建立的公共发布组(程
序从其他表)
N
(4)t_issue_group_user 发布组成员表(表 10-4)
表 10-4 信息发布子系统“发布组成员表”表结构
字 段 名 类型(长度) 说 明 空 否
issuegrp_id(关键字段) int 组_id(程序中会调用到其他的表) N
issuegrp_user_postright char(1) 审批权(从固定值选择)0,1 N
user_name varchar(40) 用户姓名(程序从其他表) N
user_id(关键字段) int 用户_ID(程序从其他表) N
(5)t_article 文章信息表(表 10-5)
表 10-5 信息发布子系统“文章信息表”表结构
字 段 名 类型(长度) 说 明 空否
article_id(关键字段) Int 正文_id(自动加1) N
topic_id Int 栏目_ID(程序从其他表) N
topic_name Varchar(40) 栏目名称(程序从其他表) N
article_title Varchar(80) 标题(输入) N
article_key Varchar(60) 关键词,格式为�key1�,�key2�(输入) article_url Varchar(255) URL(输入) article_content clob(2M) 内容(输入) readergrp_id Int 浏览组id(从其他表选择) N readergrp_name Varchar(40) 浏览组名称(程序从其他表) N article_createtime Varchar(19) 建立时间(程序) N article_posttime Varchar(19) 审批通过时间(程序),审核时的服务器时间 N

第 10 章 数据库在电子政务中的应用实例 - 205 -
(续表)
字 段 名 类型(长度) 说 明 空否
create_user_id Int 建立者_ID(程序),建立者session(user_id) N
create_user_name Varchar(40) 建立者名称(程序) N
modify_user_id Int 修改者_ID(程序)
modify_user_name Varchar(40) 修改者名称(程序)
article _readcount Int 阅读记数(程序) N
article_imgflag char(1) 控制标记 0:文章无图片;1:有图片;2:报表
类型的栏目
N
article _editstatus char(1) 0:起草 1:送审 2:通过 3:冻结 4:退回(程序) N
about_article_id Varchar(255) 相关文章列表(id1,id2,id3,id4)(从其他表选择)
article_statustime Varchar(19) 状态变更时间 N
article_author Varchar(40) 作者
article_derivation Varchar(80) 出处
managergrp_id integer 管理组ID即部门ID,表明这篇文章的发布部门
managergrp_name varchar(40) 部门名称,避免连接查询的冗余字段
issuegrp_id integer 发布组ID,表明这篇文章由哪个组发布的
issuegrp_name varchar(40) 发布组名称,避免连接查询的冗余字段
Report_id 报表型正文ID
Report_data_ID 报表型正文对应某模板数据表data_id
(6)t_comment 文章评论表(表 10-6)
表 10-6 信息发布子系统“文章评论表”表结构
字 段 名 类型(长度) 说 明 空否
comment_id(关键字段) int ID(自动加1 ) N
user_id int 用户ID(程序)
user_name varchar(40) 用户姓名(程序从其他表)
article_id 发表评论相关的article_id
comment_postemail varchar(255)
article_title varchar(80) not null
topic_id Integer not null
topic_name varchar(40) not null
comment_postright char(1) 是否审批通过 0:未审核 1:审核通过 N
comment _ip varchar(15) 发表评论用户所用IP(程序)
comment_time varchar(19) 用户发表时间(程序) N
comment_title varchar(80) 评论标题(输入) N
comment_content clob(2M) 发表内容(输入)

- 206 - 电子政务数据库基础
(7)t_inner_organ 内设机构表(表 10-7)
表 10-7 信息发布子系统中调用的“内设机构表”表结构
字 段 名 类型(长度) 说 明 空否
innerorgan _id(关键字段) Int id(自动加1) N
Innerorgan _name Varchar(30) 内设机构名称(输入) N
innerorgan_desc varchar(255) 内设机构描述,包括职能(输入)
innerorgan_leader varchar(10) 内设机构领导(输入)
innerorgan_address varchar(255) 内设机构地址(输入)
innerorgan_contact varchar(255) 内设机构管理联系方法(人,电)(输入)
innerorgan _sort Int 排列序号(输入)
innerorgan_memsum Int 内设机构人数(程序) N
innerorgan_childsum Int 内设机构子机构数(程序) N
parent_innerorgan_id Int 上级内设机构表(程序) N
managergrp_id Int 管理组_id(从其它表选择) N
10.1.3 典型程序段分析
1.信息编辑
只有部门管理员才能进入(UserType= 2)
(1)获取参数 topic_name
sql_Topic = "select topic_name from t_topic where topic_id = "+topicId;
(2)获取参数 readergrp_name
sql_Readergrp = "select readergrp_name from t_reader_group where readergrp_id =
"+readergrpId;
(3)获取参数 issuegrp_name
sql_Issuegrp = "select issuegrp_name from t_issue_group where issuegrp_id = "+issuegrpId;
(4)判断表中记录是否为空
select count(article_id) from t_article
(5)插入新增记录
① sql.append("insert into t_article(article_id,topic_id,topic_name,article_title,
article_key,article_url,readergrp_id,readergrp_name,");
② sql.append("article_createtime,article_posttime,create_user_id,create_user_name,
modify_user_id,modify_user_name,article_readcount,article_imgflag,");
③ sql.append("article_editstatus,about_article_id,article_author,article_derivation,
article_statustime,managergrp_id,managergrp_name,issuegrp_id,issuegrp_name) values(");
sql.append("(select max(article_id)+1 from t_article)");
④ sql.append(","+topicId+",’"+str_TopicName+"’,’"+str_ArticleTitle+"’,
’"+str_ArticleKey+"’,’"+str_ArticleUrl+"’,");

第 10 章 数据库在电子政务中的应用实例 - 207 -
⑤ sql.append(readergrpId+",’"+str_ReadergrpName+"’,’"+str_ArticleCreateTime+"’,
’"+str_ArticlePostTime+"’,"+createUserId+",");
⑥ sql.append("’"+str_CreateUserName+"’,"+str_ModifyUserId+",
’"+str_ModifyUserName+"’,"+str_ArticleReadCount+",’"+str_ArticleImgFlag+"’,’"+str_ArticleEdit
Status+"’,");
⑦ sql.append("’"+str_AboutArticleID+"’,’"+str_ArticleAuthor+"’,’"+str_ArticleDerivation+"’,
’"+str_ArticleStatusTime+"’,"+managergrpId+",’"+str_ManagergrpName+"’,"+issuegrpId+",’"+
str_IssuegrpName+"’)");
(6)文章状态的变更为“起草”
String sql_status="update t_article set article_editstatus = ’"+articleEditStatus+"’ where
article_id="+str_ArticleId[CurrentNum-1];
(7)更新文章的 topic_id 和 topic_name 字段
str_Sql="update t_article set article_key=’"+str_ArticleKey+"’,topic_id = "+aimTopic_id+
",topic_name = ’" + str_aimTopicName+ "’ where article_id in (" + str_ArticleListString + ")";
2.信息审核
只有部门管理员才能进入(UserType= 2)
(1)将文章状态为“送审”的更新为“已发布”
sql.append("update t_article set article_editstatus = ’2’,article_statustime =
’"+str_ArticleStatusTime+"’ where article_editstatus = ’1’ and article_id=");
(2)更新 t_manager_group 表中 managergrp_issuecount,managergrp_lasttime 字段
if(str_ArticleId.length>0)
{int managergrpId = Integer.parseInt(c_SessionValues.getManagerID(request));
String sql_Managergrp = "update t_manager_group set managergrp_issuecount =
managergrp_issuecount + "+int_rows+",managergrp_lasttime = ’" +c_Date.getDate()+"’ where
managergrp_id = "+managergrpId;
(3)送审文章列表
StringBuffer sql = new StringBuffer();
sql.append("select article_id,article_url,article_title,topic_name,readergrp_name,");
sql.append("create_user_name,article_posttime from t_article where article_editstatus=’1’");
sql.append("and issuegrp_id in("+issueList+")");
(4)本人可审批的栏目列表(移动)
StringBuffer sql1 = new StringBuffer();
sql1.append("select topic_id,topic_name from t_topic where ");
sql1.append("issuegrp_id in("+issueList+")");
(5)送审评论列表
① 获取有操作权限且已有评论的 article_id 列表
StringBuffer sql2 = new StringBuffer();
sql2.append("select article_id from t_comment where comment_postright=’0’ and article_id

- 208 - 电子政务数据库基础
in (select article_id from t_article where ");
sql2.append("issuegrp_id in("+issueList+"))");
② 获取 article_id 相对应的评论列表
sql3.append("select comment_id,comment_title,article_title,topic_name,");
sql3.append("comment_time from t_comment where comment_postright=’0’");
sql3.append("and article_id in("+str_ArticleId+")");
(6)文章状态更新为“退回”
sql.append("update t_article set article_editstatus = ’4’ where article_id=");
3.信息管理
只有系统管理员或部门管理员才能进入(UserType= 1 或 2)
(1)文章状态更新为“冻结”
sql.append("update t_article set article_editstatus = ’3’ where article_id=");
(2)文章状态更新为“通过”
sql.append("update t_article set article_editstatus = ’2’,article_posttime =
’"+str_ArticlePostTime+"’ where article_id=");
(3)文章状态更新为“退回”
sql.append("update t_article set article_editstatus = ’4’ where article_id=");
(4)送审评论列表
StringBuffer sql3 = new StringBuffer();
sql3.append("select comment_id,comment_title,article_title,topic_name,");
sql3.append("comment_time from t_comment where comment_postright=’1’");
sql3.append("and article_id=");
10.2 实例二:就业招聘子系统
10.2.1 概述
1.系统背景及目标
就业服务是政府服务的基本职能之一,也是维护社会稳定和促进经济增长的重要条件。
政府可充分利用网络这一手段在求职者和用人单位之间架起一座服务的桥梁,使传统的、在
特定时间和特定地点举行的人才和劳动力的交流突破时间和空间的限制,做到随时随地都可
以使用人单位发布用人信息、调用相关资料,应聘者可以通过网络发送个人资料,接受用人
单位的相关信息,并可直接通过网络办妥相关手续。政府网上人才市场还可以在就业管理和
劳动部门所在地或其他公共场所建立网站入口,为没有计算机的公民提供接入互联网寻找工
作职位的机会,帮助他们进行就业形势分析,指导就业方向等。就业服务子系统的设计正是
作为政府电子化服务的一个部分,在利用互联网这个平台为广大社会公众提供简单、实用、
可靠、个性化的就业服务已经成为了一个求职者和供职者都共同关心的问题,与之相关的理

第 10 章 数据库在电子政务中的应用实例 - 209 -
论研究与实践应用正成为目前电子政务网站以及政府服务创新的一个热点。
图 10.7 就业服务子系统页面显示图
2.系统框架
基于以上就业服务子系统的建设目标及原则,就业服务子系统的框架设计如图 10-8 所
示:
图 10.8 就业服务子系统的框架设计图
供求查询
招聘信息
简历中心
招聘查询
求职查询
人工搜索
模糊搜索
就
业
服
务
系
统
最新动态
职场打拼
国际交流
信息搜索
就业培训
智能搜索
- 210 - 电子政务数据库基础
3.流程设计
在就业服务子系统中,网站建设的主要模式有:公民求职与企业(包括各种所有制的企
事业单位或者个人)招聘。下面具体描述了这两种模式的设计流程图(图 10.9):公民求职
流程图和企业(包括各种所有制的企事业单位或者个人)招聘流程图(图 10.10)。
图 10.9 求职流程图
N 请填写注册登记表
Y
简历中心 (发布个人简历)
求职查询
选择合适信息, 发送求职请求
查收,回复信息
招聘信息 信息搜索
询问是否已注册求职者
提交,登记成功
������
������
����
�� �
�� �
�� �
����
����
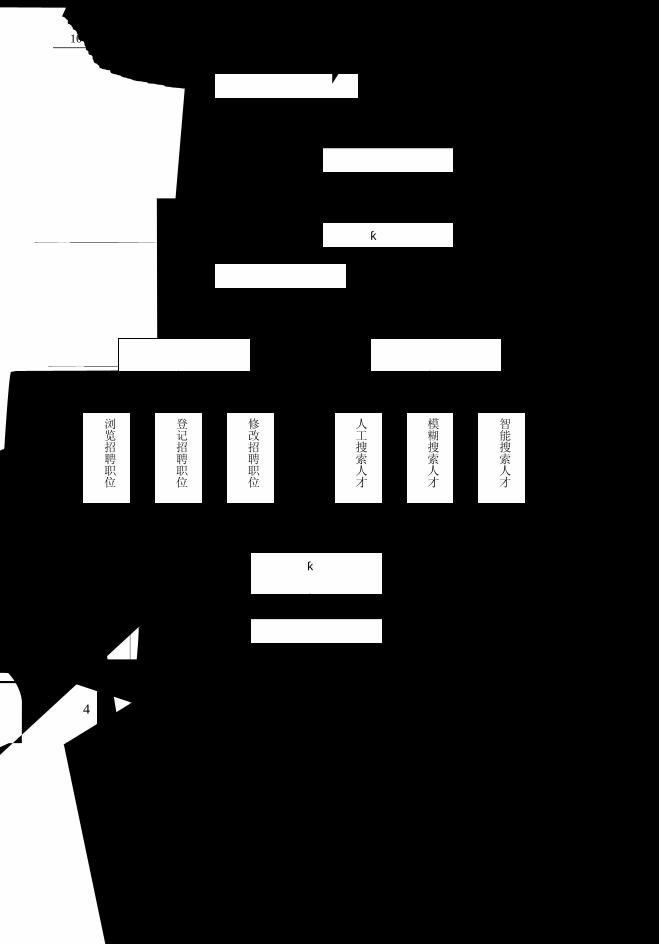
第 10 章 数据库在电子政务中的应用实例 - 211 -
图 10.10 企业(包括各种所有制的企事业单位或者个人)招聘流程图
4.各个子模块的功能描述
(1)最新动态模块。最新动态模块建设的主要目的是为广大求职的公民提供就业政策指
导,其中包括:最新的有关职场求职过程中所涉及到的职场变化走向,人才需求走向,公民
择业走向以及各个企事业单位的择人动态,甚至还包括国家政府、劳动和社会保障等有关部
门提供的就业政策与相关的政府新闻,可以让选择进入就业服务模块的公民能够在第一时间
内掌握到自己所关心的就业动向,同时也能够使企事业单位充分把握到公民择业的动态,从
而为下面选择到合适的人才做好信息准备工作。
(2)职场打拼模块。职场打拼模块在建设的过程中,摆在了比较醒目的位置,其色彩构
N
发布招聘信息
招聘查询
选择合适,发送招聘请
求消息
等待对方回复
信息搜索
询问是否已注册招聘者
请填写注册登记表
提交,登记成功
������
������
������
������
����
������
Y

- 212 - 电子政务数据库基础
成类似于最新动态模块。一方面这是由于职场打拼与最新动态有着密切的联系,就业动态决
定了公民的求职和企事业单位的招聘需求,另一方面,它又是帮助公民如何去选择职业、如
何去面对求职过程中所遇到的难题、甚至如何去制作求职简历等的关键一环。职场打拼主要
提供有关就业的心理指导、求职运作指导以及求职技巧等细小环节。关心求职过程和求职技
巧的公民完全可以在这一模块中选择查找到合适的介绍,同时,进行招聘的单位也可以及时
了解最新的信息,充分做到有备无患。
(3)国际交流模块。目前,许多的公民已经纷纷在关心着有关留学海外、国际经济、贸
易信息、以及出国考察等方面的信息。然而,对当前出现的很多鱼目混珠等欺诈行为又心有
余悸。所以国际交流模块的建设目的,正是代表政府向广大关心留学、考察和国际经济的公
民提供放心的资料、中介介绍甚至相关的国家政策信息。由于受到本系统建设的资源和条件
限制,在这一模块中拟建设的部分主要包括:海外市场人才招聘、海外人才推荐、签证指南
等等,旨在开展国际间人才交流、向境外派遣劳务、国际经济、贸易信息咨询、境外考察等
业务,本着“遵守合约、互惠互助、共同发展”的原则为广大公民提供最周到的服务。
(4)就业培训模块。面对广大需要求职的公民,政府有必要提供相关的就业培训信息,
使求职人员充分了解到自己想从事的岗位职责及工作内容,从而应聘成功,及早进入工作岗
位。就业服务子系统中,将会对电工、焊工、制冷工、电脑、无线电、彩电维修、美容、美
发、保健按摩、物业管理、家政服务、商业、旅游业、厨师、点心师、劳资管理、营销员、
创业等多个专业开设在线就业培训班。采取社会招生、送教上门、联合办学、企业委培、专
业讲座等方式,对机关、企、事业单位职工及社会青年进行各类培训。
(5)信息搜索模块。在就业服务子系统的信息搜索模块中,从搜索方式上分为:人工搜
索、模糊搜索和智能搜索,功能上包括了为公民求职服务的职位查询以及为企事业单位服务
的人才招聘查询两个部分。求职公民或者需要招聘的企事业单位都可以选择需要查询的职位
以及需要查询的城市来进行选择。系统如果在数据库中找到了合适的对应项,会显示出来,
否则就会在相应的表格中显示空白。在搜索方式上,系统提供了多种方式进行选择,访问者
可以通过阅读搜索说明,选择合适的搜索方式进行搜索,进而在最短的时间内得到满意的结
果。一旦找到合适的职位或者需要的人才,系统会首先列出简单的信息和资料,如有需要可
供详细查询。如果觉得比较合适,可以直接向其发送相关信息,在 15 天内双方合适则约见,
可以共同商讨面试或者详细事宜。
(6)简历中心模块。简历中心是就业服务子系统中一个比较庞大的模块。主要为求职公
民在线登记有关个人信息、求职需求信息以及个人联系方式等各方面的内容,进而使公民的
个人信息加入到就业服务子系统的数据库中,为企事业单位选择人才、进行招聘提供相应的
数据和连接。所以,公民在登记个人信息的时候需要客观、实际,并且能够比较全面地概括
自己的个性特点和工作教育经历,从而为企事业单位招聘提供全面的资料信息,也为本身的
求职提供可靠的依据。
(7)供求查询模块。就业服务子系统的供求查询模块主要有两个部分:一个是求职公民
进行的求职查询模块,另一个是企事业等招聘单位进行的招聘查询模块。求职查询模块中,
可以进行有关个人简历的登记、修改、浏览,还能进行搜索求职职位,另外对个人用户注册
信息进行更改,同时对个人资料进行保密存放。在招聘查询模块中,类似地可以进行有关招
聘职位的登记、修改、浏览等操作,并且搜索需要的人才信息,更改企业用户的注册信息,
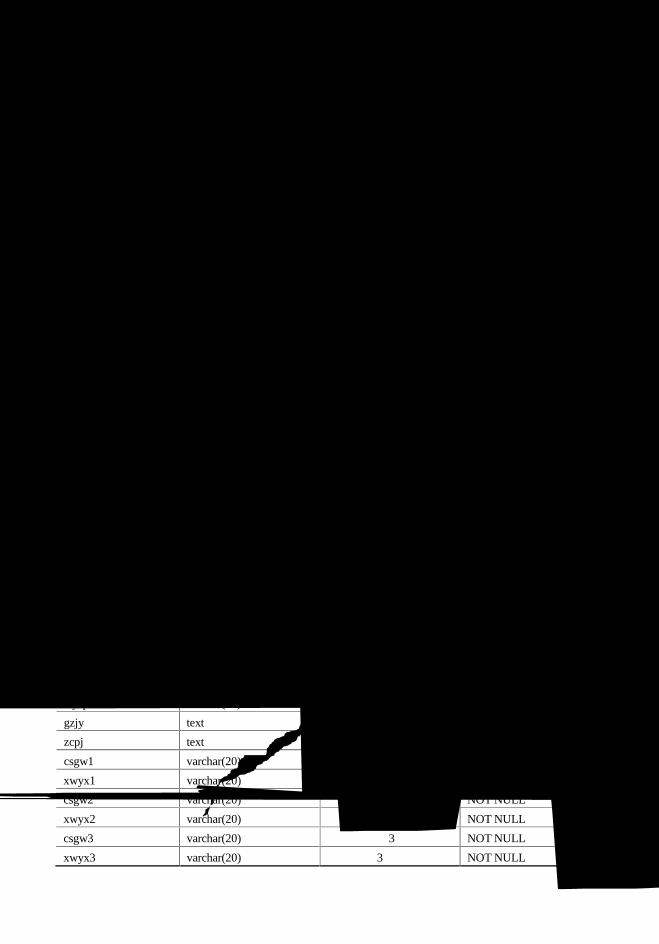
第 10 章 数据库在电子政务中的应用实例 - 213 -
对企业的相关资料进行保密存放。
(8)招聘信息模块。在就业服务子系统中,招聘信息模块设在了就业服务的首页,这是
本系统从充分为求职公民服务的目的和原则出发,在醒目的位置提供出本就业服务系统中已
经进行登记的企事业单位名称和需求的人数。这样,在本网站进行浏览的公民,如果有需要
可以进行点击查看详细信息,同时也可以获得在本站登记的最新知名企事业单位。
10.2.2 数据库表设计
1.简历表
表 10-7 就业服务子系统“简历表”表结构
字 段 名 称 类 型 长 度 字 段 含 义 说 明
dm varchar(30) 代码 NOT NULL
date date 登记日期 NOT NULL
xm varchar(30) 姓名 NOT NULL
xb varchar(10) 性别 NOT NULL
csny varchar(20) 出生年月 NOT NULL
mz varchar(10) 民族 NOT NULL
sg varchar(10) 身高 NOT NULL
tz varchar(10) 体重 NOT NULL
hyzk varchar(20) 婚姻状况 NOT NULL
sfhm varchar(30) 身份证号码 NOT NULL
jg varchar(20) 籍贯 NOT NULL
xjzd varchar(20) 现居住地 NOT NULL
zgxl varchar(20) 最高学历 NOT NULL
sxzy varchar(20) 所学专业 NOT NULL
yyyx varchar(20) 毕业院校 NOT NULL
yjgz varchar(20) 应届或工作 NOT NULL
jsj varchar(20) 计算机水平 NOT NULL
wyyz1 varchar(20) 外语语种 1 NOT NULL
wysp1 varchar(20) 外语水平 1 NOT NULL
wyyz2 varchar(20) 外语语种 2 NOT NULL
wysp2 varchar(20) 外语水平 2 NOT NULL
gzjy text 工作与教育经历 NOT NULL
zcpj text 专长与自我评价 NOT NULL
csgw1 varchar(20) 欲从事岗位 1 NOT NULL
xwyx1 varchar(20) 希望月薪 1 NOT NULL
csgw2 varchar(20) 欲从事岗位 2 NOT NULL
xwyx2 varchar(20) 希望月薪 2 NOT NULL
csgw3 varchar(20) 欲从事岗位 3 NOT NULL
xwyx3 varchar(20) 希望月薪 3 NOT NULL

- 214 - 电子政务数据库基础
(续表)
字 段 名 称 类 型 长 度 字 段 含 义 说 明
lxdh1 varchar(16) 联系电话 1 NOT NULL
lxdh2 varchar(16) 联系电话 2 NOT NULL
txdz text 通讯地址 NOT NULL
yzbm varchar(10) 邮政编码 NOT NULL
qtfs text 其他联系方式 NOT NULL
2.招聘表
表 10-8 就业服务子系统“招聘表”表结构
字 段 名 称 类 型 长 度 字 段 含 义 说 明
dm varchar(30) 代码 NOT NULL
date date 登记日期 NOT NULL
mcz varchar(30) 企业名称(中) NOT NULL
mcy varchar(30) 企业名称(英) NOT NULL
dwxz varchar(30) 单位性质 NOT NULL
cxms varchar(30) 查询密匙 NOT NULL
gzdd varchar(20) 职位工作点 NOT NULL
qygm varchar(20) 企业规模 NOT NULL
clrq date 成立日期 NOT NULL
zstj varchar(10) 住宿条件 NOT NULL
qywz varchar(30) 企业网站 NOT NULL
jjjs text 简要介绍 NOT NULL
zpzw1 varchar(20) 招聘职位 1 NOT NULL
yxrq1 date 有效日期 1 NOT NULL
sszy1 varchar(20) 所属专业 1 NOT NULL
xqrs1 varchar(20) 需求人数 1 NOT NULL
xl1 varchar(20) 学历 1 NOT NULL
zy1 varchar(20) 专业 1 NOT NULL
xyyx1 varchar(20) 毕业院校 1 NOT NULL
xb1 varchar(10) 性别 1 NOT NULL
wyyz1 varchar(20) 外语语种 1 NOT NULL
wysp1 varchar(20) 外语水平 1 NOT NULL
jsj1 varchar(20) 计算机水平 1 NOT NULL
yjgz1 varchar(20) 应届或工作 1 NOT NULL
qtyq1 text 其他要求 1 NOT NULL
zpzw2 varchar(20) 招聘职位 2 NOT NULL
yxrq2 date 有效日期 2 NOT NULL
sszy2 varchar(20) 所属专业 2 NOT NULL
xqrs2 varchar(20) 需求人数 2 NOT NULL

第 10 章 数据库在电子政务中的应用实例 - 215 -
(续表)
字 段 名 称 类 型 长 度 字 段 含 义 说 明
xl2 varchar(20) 学历 2 NOT NULL
zy2 varchar(20) 专业 2 NOT NULL
byyx2 varchar(20) 毕业院校 2 NOT NULL
xb2 varchar(10) 性别 2 NOT NULL
wyyz2 varchar(20) 外语语种 2 NOT NULL
wysp2 varchar(20) 外语水平 2 NOT NULL
jsj2 varchar(20) 计算机水平 2 NOT NULL
yjgz2 varchar(20) 应届或工作 2 NOT NULL
qtyq2 text 其他要求 2 NOT NULL
lxdh1 varchar(16) 联系电话 1 NOT NULL
lxdh2 varchar(16) 联系电话 2 NOT NULL
txdz text 通讯地址 NOT NULL
yzbm varchar(10) 邮政编码 NOT NULL
qtfs text 其他联系方式 NOT NULL
3.个人用户表
表 10-9 就业服务子系统“个人用户表”表结构
字段名称 类型长度 字段含义 说明
yhmc varchar(20) 求职用户名称 NOT NULL
yhmm varchar(20) 求职用户密码 NOT NULL
yhdh varchar(18) 用户联系电话 NOT NULL
yhxx varchar(30) 用户电子信箱 NOT NULL
4.企业用户表
表 10-10 就业服务子系统“企业用户表”表结构
字段名称 类型长度 字段含义 说明
dwdm varchar(20) 招聘单位代码 NOT NULL
dwmm varchar(20) 招聘单位密码 NOT NULL
dwfz varchar(20) 负责人 NOT NULL
dwdh varchar(18) 联系电话 NOT NULL
dwdz varchar(18) 常住地址 NOT NULL
dwxx varchar(30) 常用电子信箱 NOT NULL
10.2.3 典型程序段分析
本文此处将主要针对简历中心模块进行简单的程序分析,进而具体阐述系统功能的实现。
简历中心模块主要是针对求职公民登记个人信息、求职信息、个人联系方式等涉及到应
聘简历的各种相关信息,同时要求公民在登记个人信息的时候需要客观、实际,并且能够比

- 216 - 电子政务数据库基础
较全面地概括自己的个性特点和工作教育经历,不但为企事业单位招聘提供全面的资料信息,
也为自身的求职提供可靠依据。所以,简单地讲简历中心模块在程序设计上,主要分为填写
个人简历表格、提交个人简历表格等等。另外涉及到查询或修改个人简历等操作,本系统已
将其放入个人查询模块中,所以有关个人简历的查询或修改等其他功能此处不再赘述。
1.填写个人简历程序分析
需要填写的个人简历主要有五个框架:个人基本信息、学历与专业、主要工作和教育培
训经历、求职意向和个人联系方式。
图 10.11 填写个人简历显示图
如图 10.11:填写个人简历的网页在设计上,主要是由表单来完成的。一个完整的表单包
括两个组件:一个是表单对象,它在网页中进行描述;另一个是应用程序,它可以是服务器
端的应用程序,也可以是客户端的脚本等。通过这些应用程序就可以实现对个人简历信息的
处理。任选以填写个人联系方式的表格为例介绍填写个人简历表格的程序。下面就是这段网
页表格的设计程序:
<table width="778" border="1" cellspacing="0" cellpadding="0" bordercolorlight=
"#666666" bordercolordark="#FFFFFF">
<tr bgcolor="#c5d2e2">
<td colspan="4">
<div align="center"><font size="2">个人联系方式</font></div>
</td>

第 10 章 数据库在电子政务中的应用实例 - 217 -
</tr>
<tr>
<td width="194" height="15">
<div align="center"><font size="2">联系电话 1</font></div>
</td>
<td width="194" height="15">
<div align="center">
<input type="text" name="ilxdh1" size="20" maxlength="20">
//添加一个单行的、名字为“ilxdh1”的文本框,大小为“20”,最大长度为“20”
<font size="2"><font color="#FF0000">*</font></font></div>
</td>
<td height="15" width="194">
<div align="center"><font size="2">联 系 电 话 2</font></div>
</td>
<td height="15" width="195">
<input type="text" name="ilxdh2" size="20" maxlength="20">
//添加一个单行的、名字为“ilxdh2”的文本框,大小为“20”,最大长度为“20”
</td>
</tr>
<tr>
<td>
<div align="center"><font size="2">通 讯 地 址</font></div>
</td>
<td colspan="3">
<div align="center">
<input type="text" name="itxdz" size="80" maxlength="80">
//添加一个单行的、名字为“itxdz”的文本框,大小为“80”,最大长度为“80”
<font size="2"><font color="#FF0000">*</font></font></div>
</td>
</tr>
<tr>
<td>
<div align="center"><font size="2">邮 政 编 码</font></div>
</td>
<td>
<div align="center">
<input type="text" name="iyzbm" size="20" maxlength="15">
//添加一个单行的、名字为“iyzbm”的文本框,大小为“20”,最大长度为“15”
<font size="2"><font color="#FF0000">*</font></font></div>

- 218 - 电子政务数据库基础
</td>
<td colspan="2"> ;</td>
</tr>
<tr>
<td>
<div align="center"><font size="2">其他联系方式</font></div>
</td>
<td colspan="3">
 ; ; ;
<input type="text" name="iqtlx" size="20" maxlength="20">
//添加一个单行的、名字为“iqtlx”的文本框,大小为“20”,最大长度为“20”
<font size="2">(如电子信箱等)
<font color="#FF0000">*</font></font></td>
</tr>
</table>
同时,为了实现使用者在填写完毕后实现表单的跳转,在表单属性的设置上,需要使用
如下语句:
<form name="form1" method="post" action="jlzx_submit.asp">
//点击“提交”按钮后,页面跳转到 jlzx_submit.asp。
另外,还需要在所有必要填写的表格之后插入“提交”和“全部清除“按钮:
<input type="submit" name="Submit3" value="提 交">
<input type="reset" name="Submit22" value="全部清除">
这样才能完成填写个人简历的实现。
最后,为了保证填写的有效性,网页制作中加入了如下的代码,并特别提示了需要求职
者必须填写带“*”的空格,如果有一项带“*”的空格没有填写,系统会自动返回“尚未输
入”的相关信息。
<script language=javascript>
function form_submit(theform){
if (theform.ixm.value==’’){alert(’您尚未输入姓名!’);return false;}
if (theform.ixb.value==’’){alert(’您尚未输入性别!’);return false;}
if (theform.icsny.value==’’){alert(’您尚未输入出生年月!’);return false;}
��� �� } </script>
2.提交个人简历程序分析
当求职公民的个人简历完毕以后,需要进行确认,并使系统自动存储到相应的数据库中。 sql="insert into jlk(dm, date, xm, xb, csny, mz, sg, tz, hyzk, sfhm, jg, xjzd, xl, zy, byyx, yjgz,
jsj, wyyz1, sp1, wyyz2, sp2, gzjy, ywzc, csgw1, xwyx1, csgw2, xwyx2,

第 10 章 数据库在电子政务中的应用实例 - 219 -
csgw3, xwyx3, lxdh1, lxdh2, txdz, yzbm, qtlx)
values(’"&number&"’, ’"&idate&"’, ’"&ixm&"’, ’"&ixb&"’, ’"&icsny&"’,
’"&imz&"’, ’"&isg&"’, ’"&itz&"’, ’"&ihyzk&"’, ’"&isfhm&"’, ’"&ijg&"’,
’"&ixjzd&"’, ’"&ixl&"’, ’"&izy&"’, ’"&ibyyx&"’, ’"&iyjgz&"’, ’"&ijsj&"’,
’"&iwyyz1&"’, ’"&isp1&"’, ’"&iwyyz2&"’, ’"&isp2&"’, ’"&igzjy&"’,
’"&iywzc&"’, ’"&icsgw1&"’, ’"&ixwyx1&"’, ’"&icsgw2&"’, ’"&ixwyx2&"’,
’"&icsgw3&"’, ’"&ixwyx3&"’, ’"&ilxdh1&"’, ’"&ilxdh2&"’, ’"&itxdz&"’,
’"&iyzbm&"’, ’"&iqtlx&"’)";
//在简历库中插入相应的数据信息
至此,完成了个人简历的填写与提交功能。
10.3 本 章 小 结
本章通过两个以数据库驱动的 Web 政务网站后台数据库的设计开发实例,将本书介绍的
主要教学内容运用到实际中。第一个实例从系统的设计开始详细地介绍了系统的实施流程和
各个模块的功能,并给出了典型程序段。读者可以仿照第一个实例,尝试完成就业服务子系
统,或是中的一部分,理论联系实际,真正掌握好本书的内容。
10.4 本 章 习 题
1.从应用需求出发,建立 E-R 图,补充完善“就业服务子系统”数据库的设计。
2.设计“就业服务子系统”主程序文件,上机调试整个系统并写出设计文档。
10.5 本章参考文献
1.曹锦芳·信息系统分析与设计·北京:北京航空航天大学出版社,1987
2.张龙祥等·数据库原理与设计·北京:人民邮电出版社,2002
3.杨健·寻觅推进电子政务建设中的商机·赛迪网:软件世界,2002
4.李大友等·数据库原理及应用·北京:清华大学出版社,1997
5.袁晓洁等·数据库系统教程·天津:南开大学出版社,1995
6.师玛莉·典型电子政务的解决方案及其实现·南京:南京工业大学硕士学位论文,2003
7.王鹏等·数据库技术及其应用·北京:人民邮电出版社,2000
8.庄成三等·数据库系统原理及其应用·北京:电子工业出版社,2000
9.张健沛·数据库原理及应用系统开发·北京:中国水利水电出版社,1994